
The bread and butter of the test crate is the Bencher struct [59]. An instance of it is passed automatically to every function annotated with the #[bench] attribute [63] when running cargo bench. Its iter method takes a closure [65], and runs it multiple times to determine how long one iteration of it takes. While doing this, it also discards time measurements that are far off the others to eliminate one-off extremes.
Another useful part of the test crate is its black_box struct [68], which wraps any value and tells the compiler and LLVM to not optimize it away, no matter what. If we didn't use it in our benchmarks, they might get optimized away and result in a rather optimistic and unhelpful measurement of 0 ns/iter, or zero nanoseconds per execution of the closure.
We can use the tools at our disposal to test out some theories. Remember the recursive Fibonacci implementation discussed in Chapter 7, Parallelism and Rayon; Running two operations together? Well, it is repeated here as slow_fibonacci_recursive[6].
This implementation is slow because both calls to slow_fibonacci_recursive(n - 1) and slow_fibonacci_recursive(n - 2) need to recalculate all values individually. Worse yet, every call also splits up into a call to slow_fibonacci_recursive(n - 1) and slow_fibonacci_recursive(n - 2) once more, recalculating everything again and again! In terms of Big O, this is an efficiency of  (proof at https://stackoverflow.com/a/360773/5903309). In comparison, the imperative algorithm, fibonacci_imperative [14] is a simple loop, so it's at
(proof at https://stackoverflow.com/a/360773/5903309). In comparison, the imperative algorithm, fibonacci_imperative [14] is a simple loop, so it's at 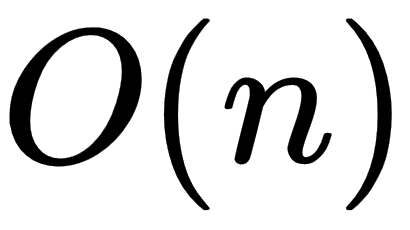 . By this theory, it should be a lot faster than the slow, recursive one. Running cargo bench lets us verify these assertions easily:
. By this theory, it should be a lot faster than the slow, recursive one. Running cargo bench lets us verify these assertions easily:

What a difference! On my computer, the slow, recursive implementation is more than 7,000 times slower than the imperative one! Surely, we can do better.
StackOverflow user Boiethios helpfully provided us with memoized_fibonacci_recursive at https://stackoverflow.com/a/49052806/5903309. As the name suggests, this implementation uses a concept known as memoization. This means that the algorithm has some way of passing around already-calculated values. An easy way of doing this would be to pass around a HashMap with all calculated values, but that would again bring its own overhead, as it operates on the heap. Instead, we go for the route of accumulators. This means that we just pass the relevant values directly as parameters, which in our case are penultimate, which represents the Fibonacci of n-2, and last, which represents the Fibonacci of n-1. If you want to read more about these functional concepts, check out http://www.idryman.org/blog/2012/04/14/recursion-best-practices/.
Checking the benchmarks, we can see that we managed to improve the algorithm quite a bit with memoized_fibonacci_recursive. But it's still a bit slower than fibonacci_imperative. One of many possible ways to further improve the algorithm is by extracting the n == 1 match that would be checked in every recursive call outside, as demonstrated in fast_fibonacci_recursive [43], which clocks in at a great three nanoseconds per iteration!