
Chapter 9: Displaying Users' Post
In this chapter, we are going to implement displaying user posts. Along with displaying user posts, we are going to learn about generic data types and trait bounds to group types that behave similarly and so reduce the creation of similar code. We are also going to learn about the most important part of the Rust programming language: the memory model and its terminologies. We are going to learn more about ownership, moving, copying, cloning, borrowing, and lifetime, and how we can implement those in our code.
After completing this chapter, you will understand and implement those concepts in Rust programming. Generic data types and trait bounds are useful to reduce repetitions, while the Rust memory model and concepts are arguably the most distinctive features of the Rust language and make it not only fast but one of the safest programming languages. Those concepts also make people say that Rust has a steep learning curve.
In this chapter, we are going to cover these main topics:
- Displaying posts – text, photo, and video
- Using generic data types and trait bounds
- Learning about ownership and moving
- Borrowing and lifetime
Technical requirements
For this chapter, we have the same technical requirements as the previous chapter. We need a Rust compiler, a text editor, an HTTP client, and a PostgreSQL database server.
You can find the source code for this chapter at https://github.com/PacktPublishing/Rust-Web-Development-with-Rocket/tree/main/Chapter09.
Displaying posts – text, photo, and video
In the previous chapters, we implemented user management, including listing, showing, creating, updating, and deleting user entities. Now, we want to do the same with posts. To refresh your memory, we are planning to have User posts. The posts can be either text, photos, or videos.
When we implemented the application skeleton, we created a Post struct in src/models/post.rs with the following content:
pub struct Post {pub uuid: Uuid,
pub user_uuid: Uuid,
pub post_type: PostType,
pub content: String,
pub created_at: OurDateTime,
}
The plan is to use post_type to differentiate a post based on its type and use the content field to store the content of the post.
Now that we have rehashed what we wanted to do, let's implement showing the posts:
- The first thing we want to do is to create a migration file to change the database schema. We want to create a table to store the posts. In the application root folder, run this command:
sqlx migrate add create_posts
- We should then see a new file in the migrations folder named YYYYMMDDHHMMSS_create_posts.sql (depending on the current date-time). Edit the file with the following lines:
CREATE TABLE IF NOT EXISTS posts
(
uuid UUID PRIMARY KEY,
user_uuid UUID NOT NULL,
post_type INTEGER NOT NULL DEFAULT 0,
content VARCHAR NOT NULL UNIQUE,
created_at TIMESTAMPTZ NOT NULL DEFAULT CUR-
RENT_TIMESTAMP,
FOREIGN KEY (user_uuid) REFERENCES "users" (uuid)
);
- After editing the file, run the migration in the command line to create the database table:
sqlx migrate run
- We have also created a DisplayPostContent trait in src/traits/mod.rs, which has the raw_html() method. We want to show content in Post by converting content to HTML snippets and rendering the snippets in the Tera template. Change the signature of raw_html() so we can use Post as the source of HTML snippets:
fn raw_html(&self) -> String;
- Now, we can implement each of the types in src/models/text_post.rs, src/models/photo_post.rs, and src/models/video_post.rs. Start with changing src/models/text_post.rs:
pub struct TextPost(pub Post);
impl DisplayPostContent for TextPost {
fn raw_html(&self) -> String {
format!("<p>{}</p>", self.0.content)
}
}
The implementation is very simple, we are just wrapping the Post content inside a p HTML tag.
- Next, modify src/models/photo_post.rs:
pub struct PhotoPost(pub Post);
impl DisplayPostContent for PhotoPost {
fn raw_html(&self) -> String {
format!(
r#"<figure><img src="{}" class="section
media"/></figure>"#,
self.0.content
)
}
}
For PhotoPost, we used the Post content as the source of the img HTML tag.
- The last type we modify is src/models/video_post.rs:
pub struct VideoPost(pub Post);
impl DisplayPostContent for VideoPost {
fn raw_html(&self) -> String {
format!(
r#"<video width="320" height="240" con-
trols>
<source src="{}" type="video/mp4">
Your browser does not support the video tag.
</video>"#,
self.0.content
)
}
}
For VideoPost, we are using the Post content as the source of the video HTML tag.
We need to create templates for the posts. Let's start with a template that will be used in a single post or multiple posts.
- Create a posts folder in the src/views folder. Then, create a _post.html.tera file inside the src/views/posts folder. Add the following lines to the file:
<div class="card fluid">
{{ post.post_html | safe }}
</div>
We are wrapping some content inside a div and filtering the content as safe HTML.
- In the src/views/posts folder, create a show.html.tera file as a template to show a single post. Add the following lines to the file:
{% extends "template" %}
{% block body %}
{% include "posts/_post" %}
<button type="submit" value="Submit" form="delete-
Post">Delete</button>
<a href="/users/{{user.uuid}}/posts" class="but-
ton">Post List</a>
{% endblock %}
- Create an index.html.tera file inside the src/views/posts folder to show user posts. Add the following lines:
{% extends "template" %}
{% block body %}
{% for post in posts %}
<div class="container">
<div><mark class="tag">{{ loop.index
}}</mark></div>
{% include "posts/_post" %}
<a href="/users/{{ user.uuid }}/posts/{{
post.uuid }}" class="button">See Post</a>
</div>
{% endfor %}
{% if pagination %}
<a href="/users/{{ user.uuid }}/posts?pagina
tion.next={{ pagination.next }}&paginat-
ion.limit={{ pagination.limit }}" class="button">
Next
</a>
{% endif %}
<a href="/users/{{ user.uuid }}/posts/new"
class="button">Upload Post</a>
{% endblock %}
- After creating the views, we can implement methods for the Post struct to get the data from the database. Modify the src/models/post.rs file to include use declarations:
use super::bool_wrapper::BoolWrapper;
use super::pagination::{Pagination, DEFAULT_LIMIT};
use super::photo_post::PhotoPost;
use super::post_type::PostType;
use super::text_post::TextPost;
use super::video_post::VideoPost;
use crate::errors::our_error::OurError;
use crate::fairings::db::DBConnection;
use crate::traits::DisplayPostContent;
use rocket::form::FromForm;
use rocket_db_pools::sqlx::{FromRow, PgConnection};
use rocket_db_pools::{sqlx::Acquire, Connection};
- We need to derive FromRow for the Post struct to convert database rows into Post instances:
#[derive(FromRow, FromForm)]
pub struct Post {
...
}
- Create an impl block for Post:
impl Post {}
- Inside the impl Post block, we can add functions to query the database and return the Post data. As the functions are similar to the User functions, you can copy the code for steps 14 to 17 in the Chapter09/01DisplayingPost source code folder. First, we add the find() method to get a single post:
pub async fn find(connection: &mut PgConnection, uuid: &str) -> Result<Post, OurError> {
let parsed_uuid =
Uuid::parse_str(uuid).map_err(Our
Error::from_uuid_error)?;
let query_str = "SELECT * FROM posts WHERE uuid =
$1";
Ok(sqlx::query_as::<_, Self>(query_str)
.bind(parsed_uuid)
.fetch_one(connection)
.await
.map_err(OurError::from_sqlx_error)?)
}
- Add the find_all() method:
pub async fn find_all(
db: &mut Connection<DBConnection>,
user_uuid: &str,
pagination: Option<Pagination>,
) -> Result<(Vec<Self>, Option<Pagination>), OurError> {
if pagination.is_some() {
return Self::find_all_with_pagination(db,
user_uuid, &pagination.unwrap()).await;
} else {
return Self::find_all_without_pagination(db, user_uuid).await;
}
}
- Add the find_all_without_pagination() method:
async fn find_all_without_pagination(
db: &mut Connection<DBConnection>,
user_uuid: &str,
) -> Result<(Vec<Self>, Option<Pagination>), OurError> {
let parsed_uuid =
Uuid::parse_str(user_uuid).map_err(Our-
Error::from_uuid_error)?;
let query_str = r#"SELECT *
FROM posts
WHERE user_uuid = $1
ORDER BY created_at DESC
LIMIT $2"#;
let connection = db.acquire().await.map_err(Our-
Error::from_sqlx_error)?;
let posts = sqlx::query_as::<_, Self>(query_str)
.bind(parsed_uuid)
.bind(DEFAULT_LIMIT as i32)
.fetch_all(connection)
.await
.map_err(OurError::from_sqlx_error)?;
let mut new_pagination: Option<Pagination> = None;
if posts.len() == DEFAULT_LIMIT {
let query_str = "SELECT EXISTS(SELECT 1 FROM
posts WHERE created_at < $1 ORDER BY
created_at DESC LIMIT 1)";
let connection = db.acquire().
await.map_err(OurError::from_sqlx_error)?;
let exists = sqlx::query_as::<_,
BoolWrapper>(query_str)
.bind(&posts.last().unwrap().created_at)
.fetch_one(connection)
.await
.map_err(OurError::from_sqlx_error)?;
if exists.0 {
new_pagination = Some(Pagination {
next: posts.last().unwrap()
.created_at.to_owned(),
limit: DEFAULT_LIMIT,
});
}
}
Ok((posts, new_pagination))
}
- Add the find_all_with_pagination() method:
async fn find_all_with_pagination(
db: &mut Connection<DBConnection>,
user_uuid: &str,
pagination: &Pagination,
) -> Result<(Vec<Self>, Option<Pagination>), OurError> {
let parsed_uuid =
Uuid::parse_str(user_uuid).map_err(
OurError::from_uuid_error)?;
let query_str = r#"SELECT *
FROM posts
WHERE user_uuid = $1 AND☐created_at < $2
ORDER BY created_at☐DESC
LIMIT $3"#;
let connection = db.acquire().await.map_err(
OurError::from_sqlx_error)?;
let posts = sqlx::query_as::<_, Self>(query_str)
.bind(&parsed_uuid)
.bind(&pagination.next)
.bind(DEFAULT_LIMIT as i32)
.fetch_all(connection)
.await
.map_err(OurError::from_sqlx_error)?;
let mut new_pagination: Option<Pagination> = None;
if posts.len() == DEFAULT_LIMIT {
let query_str = "SELECT EXISTS(SELECT 1 FROM
posts WHERE created_at < $1 ORDER BY
created_at DESC LIMIT 1)";
let connection = db.
acquire().await.map_err(
OurError::from_sqlx_error)?;
let exists = sqlx::query_as::<_,
BoolWrapper>(query_str)
.bind(&posts.last().unwrap().created_at)
.fetch_one(connection)
.await
.map_err(OurError::from_sqlx_error)?;
if exists.0 {
new_pagination = Some(Pagination {
next: posts.last().unwrap().
created_at.to_owned(),
limit: DEFAULT_LIMIT,
});
}
}
Ok((posts, new_pagination))
}
- We need to add methods to convert a Post instance into TextPost, PhotoPost, or VideoPost. Add the following lines inside the impl Post block:
pub fn to_text(self) -> TextPost {
TextPost(self)
}
pub fn to_photo(self) -> PhotoPost {
PhotoPost(self)
}
pub fn to_video(self) -> VideoPost {
VideoPost(self)
}
- When the view and model implementations are ready, we can implement the function for showing user posts. In src/routes/post.rs, add the required use declarations:
use crate::models::{pagination::Pagination, post::Post, post_type::PostType, user::User};
use crate::traits::DisplayPostContent;
use rocket::http::Status;
use rocket::serde::Serialize;
use rocket_db_pools::{sqlx::Acquire, Connection};
use rocket_dyn_templates::{context, Template};
- Modify the get_post() function inside src/routes/post.rs:
#[get("/users/<user_uuid>/posts/<uuid>", format = "text/html")]
pub async fn get_post(
mut db: Connection<DBConnection>,
user_uuid: &str,
uuid: &str,
) -> HtmlResponse {}
- Inside the get_post() function, query the user information and the post information from the database. Write the following lines:
let connection = db
.acquire()
.await
.map_err(|_| Status::InternalServerError)?;
let user = User::find(connection, user_uuid)
.await
.map_err(|e| e.status)?;
let connection = db
.acquire()
.await
.map_err(|_| Status::InternalServerError)?;
let post = Post::find(connection, uuid).await.map_err(|e| e.status)?;
if post.user_uuid != user.uuid {
return Err(Status::InternalServerError);
}
- In src/views/posts/show.html.tera and src/views/posts/_post.html.tera, we have set two variables: user and post. We have to add those two variables into the context passed to the template. Append two structs that will be passed to templates:
#[derive(Serialize)]
struct ShowPost {
post_html: String,
}
#[derive(Serialize)]
struct Context {
user: User,
post: ShowPost,
}
- And finally, we can pass the user and post variables into context, render the template along with context, and return from the function. Append the following lines:
let mut post_html = String::new();
match post.post_type {
PostType::Text => post_html =
post.to_text().raw_html(),
PostType::Photo => post_html =
post.to_photo().raw_html(),
PostType::Video => post_html =
post.to_video().raw_html(),
}
let context = Context {
user,
post: ShowPost { post_html },
};
Ok(Template::render("posts/show", context))
- For the get_posts() function in src/routes/post.rs, we want to get the posts data from the database. Modify the function into the following lines:
#[get("/users/<user_uuid>/posts?<pagination>", format = "text/html")]
pub async fn get_posts(
mut db: Connection<DBConnection>,
user_uuid: &str,
pagination: Option<Pagination>,
) -> HtmlResponse {
let user = User::find(&mut db,
user_uuid).await.map_err(|e| e.status)?;
let (posts, new_pagination) = Post::find_all(&mut
db, user_uuid, pagination)
.await
.map_err(|e| e.status)?;
}
- Now that we have implemented getting the posts data, it's time to render those posts as well. Inside the get_posts() function, append the following lines:
#[derive(Serialize)]
struct ShowPost {
uuid: String,
post_html: String,
}
let show_posts: Vec<ShowPost> = posts
.into_iter()
.map(|post| {
let uuid = post.uuid.to_string();
let mut post_html = String::new();
match post.post_type {
PostType::Text => post_html =
post.to_text().raw_html(),
PostType::Photo => post_html =
post.to_photo().raw_html(),
PostType::Video => post_html =
post.to_video().raw_html(),
};
ShowPost { uuid, post_html }
})
.collect();
let context =
context! {user, posts: show_posts, pagination:
new_pagination.map(|pg|pg.to_context())};
Ok(Template::render("posts/index", context))
Now we have finished the code for get_post() and get_posts(), it's time to test those two endpoints. Try adding images and videos to a static folder and add an entry in the database. You can find a sample image and video in the static folder in the source code in the GitHub repository for this chapter. Here is an example:

Figure 9.1 – Testing the endpoints
When we open a web browser and navigate to the user posts page, we should be able to see something similar to this screenshot:
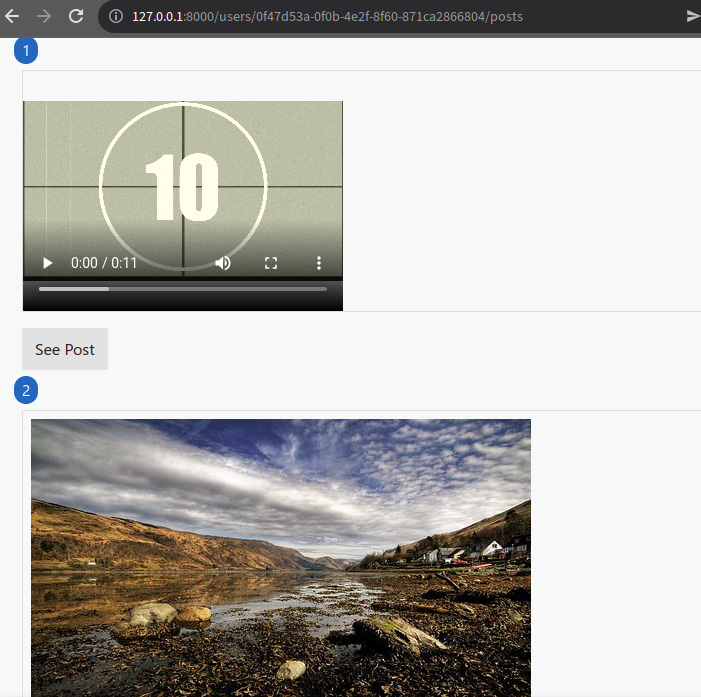
Figure 9.2 – Example user posts page
We have implemented the functions to show posts, but if we look back at the code, we can see that all three types (Text, Photo, and Video) have the same method because they are all implementing the same interface.
Let's convert those into generic data types and trait bounds in the next section.
Using generic data types and trait bounds
A generic data type, generic type, or simply, generic, is a way for programming languages to be able to apply the same routine to different data types.
For example, we want to create a multiplication(a, b) -> c {} function for different data types, u8 or f64. If a language does not have a generic, a programmer might have to implement two different functions, for example, multiplication_u8(a: u8, b: u8) -> u8 and multiplication_f64(a: f64, b: f64) -> f64. Creating two different functions might look simple, but as the application grows in complexity, the branching and figuring out which function to use will be more complex. If a language has a generic, then the problem of multiple functions can be solved by using a single function that can accept u8 and f64.
In the Rust language, we can make a function to use generics by declaring the generics inside angle brackets after the function name as follows:
fn multiplication<T>(a: T, b: T) -> T {}We can also use generics in a struct or enum definition. Here is an example:
struct Something<T>{a: T,
b: T,
}
enum Shapes<T, U> {Rectangle(T, U),
Circle(T),
}
We can also use generics inside method definitions. Following Something<T>, we can implement the method as follows:
impl<T, U> Something<T, U> { fn add(&self, T, U) -> T {}}
At compile time, the compiler identifies and changes the generic code into specific code by using the concrete type (u8 or f64 in our multiplication example), depending on which type is used. This process is called monomorphization. Because of monomorphization, code written using a generic will produce a binary that has the same execution speed as binary generated using specific code.
Now that we have looked at an introduction to generics, let's use generics in our existing application:
- In the src/models/post.rs file, add another method to convert Post instances into media:
pub fn to_media(self) -> Box<dyn DisplayPostContent> {
match self.post_type {
PostType::Text => Box::new(self.to_text()),
PostType::Photo => Box::new(self.to_photo()),
PostType::Video => Box::new(self.to_video()),
}
}
We are telling the to_media() method to return the type that implemented DisplayPostContent and put TextPost, PhotoPost, or VideoPost into the heap.
- In the src/routes/post.rs file, inside the get_post() function, and after the Context struct declaration, add the following lines:
struct Context {
…
}
fn create_context<T>(user: User, media: T) -> Context {
Context {
user,
post: ShowPost {
post_html: media.raw_html(),
},
}
}
Yes, we can create a function inside another function. The inner function will have local scope and cannot be used outside the get_post() function.
- We need to change the context variable from initiating the struct directly, as follows:
let context = Context {...};
We need to change it into using the create_context() function:
let media = post.to_media();
let context = create_context(user, media);
At this point, we can see that create_context() can use any type, such as String or u8, but String and u8 types don't have the raw_html() function. The Rust compiler will show an error when compiling the code. Let's fix this problem by using trait bounds.
We have defined and implemented traits several times, and we already know that a trait provides consistent behavior for different data types. We defined the DisplayPostContent trait in src/traits/mod.rs, and every type that implements DisplayPostContent has the same method, raw_html(&self) -> String.
We can limit the generic type by adding a trait after the generic declaration. Change the create_context() function to use trait bounds:
fn create_context<T: DisplayPostContent>(user: User, media: T) -> Context {...}Unfortunately, using DisplayPostContent alone is not enough, because the T size is not fixed. We can change the function parameters from media: T into a media: &T reference, as a reference has a fixed size. We also have another problem, as the DisplayPostContent size is not known at compile time, so we need to add another bound. Every T type is implicitly expected to have a constant size at compile time, implicitly trait bound to std::marker::Sized. We can remove the implicit bound by using a special ?Size syntax.
We can have more than one trait bound and combine them using the + sign. The resulting signature for the create_context() function will be as follows:
fn create_context<T: DisplayPostContent + ?Sized>(user: User, media: &T) -> Context {...}Writing multiple trait bounds inside angle brackets (<>) can make the function signature hard to read, so there's an alternative syntax for defining trait bounds:
fn create_context<T>(user: User, media: &T) -> Context
where T: DisplayPostContent + ?Sized {...}Because we changed the function signature to use a reference, we have to change the function usage as well:
let context = create_context(user, &*media);
We get media object by dereferencing using the * sign and referencing media again using the & sign.
Now, the Rust compiler should be able to compile the code again. We will learn more about reference in the next two sections, but before that, we have to learn about Rust's memory model called ownership and moving.
Learning about ownership and moving
When we instantiate a struct, we create an instance. Imagine a struct as being like a template; an instance is created in the memory based on the template and filled with appropriate data.
An instance in Rust has a scope; it is created in a function and gets returned. Here is an example:
fn something() -> User {let user = User::find(...).unwrap();
user
}
let user = something()
If an instance is not returned, then it's removed from memory because it's not used anymore. In this example, the user instance will be removed by the end of the function:
fn something() {let user = User::find(...).unwrap();
...
}
We can say that an instance has a scope, as mentioned previously. Any resources created inside a scope will be destroyed by the end of the scope in the reverse order of their creation.
We can also create a local scope in a routine by using curly brackets, {}. Any instance created inside the scope will be destroyed by the end of the scope. For example, the user scope is within the curly brackets:
...
{let user = User::find(...).unwrap();
}
...
An instance owns resources, not only in stack memory but also in heap memory. When an instance goes out of scope, either because of function exits or curly brackets scope exits, the resource attached to the instance is automatically cleaned in reverse order of the creation. This process is called resource acquisition is initialization (RAII).
Imagine that computer memory consists of a stack and a heap:
Stack: ☐☐☐☐☐☐☐☐☐☐☐☐
Heap: ☐☐☐☐☐☐☐☐☐☐☐☐
An instance owns memory from stack memory:
Stack: ☐☒☒☒☐☐☐☐☐☐☐☐
Heap: ☐☐☐☐☐☐☐☐☐☐☐☐
Another instance may own memory from the stack and the heap. For example, a string can be a single word or a couple of paragraphs. We cannot say how large a String instance is going to be, so we cannot store all of the information in stack memory; instead, we can store some in stack memory and some in heap memory. This is a simplification of what it looks like:
Stack: ☐☒☐☐☐☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
In other programming languages, there's a function called a destructor, which is a routine executed when an object is removed from the memory. In Rust, there's a similar trait called Drop. In order to execute a function when an object destroyed, a type can implement the std::ops::Drop trait. But, most types don't need to implement the Drop trait and are automatically removed from memory when they're out of scope.
In Rust, if we create an instance and set the instance to another instance, it is called move. To see why it's called move, let's modify our application code. In the src/routes/post.rs file, inside the get_posts() function, modify it into the following:
let show_posts: Vec<ShowPost> = posts
.into_iter()
.map(|post| ShowPost {post_html: post.to_media().raw_html(),
uuid: post.uuid.to_string(),
})
.collect();
let context = ...
If we compile the program, we should see an error similar to the following:
error[E0382]: borrow of moved value: `post`
--> src/routes/post.rs:78:19
|
76 | .map(|post| ShowPost {
| ---- move occurs because `post` has type `models::post::Post`, which does not implement the `Copy` trait
77 | post_html: post.to_media().raw_html(),
| ---------- `post` moved due to this method call
78 | uuid: post.uuid.to_string(),
| ^^^^^^^^^^^^^^^^^^^^^ value borrowed here after move
What is moving? Let's go back to the simplification of memory. When an instance is assigned to another instance, some of the second instance is allocated in stack memory:
Stack: ☐☒☐☐☒☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
Then, some of the new instance points to old data in the heap:
Stack: ☐☒☐☐☒☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
If both instances point to the same heap memory, what happens if the first instance gets dropped? Because of the possibility of invalid data, in Rust, only one instance may have its own resources. The Rust compiler will refuse to compile code that uses an instance that has been moved.
If we look at our code, the to_media() method in Post moved the post instance and put it inside either TextPost, PhotoPost, or VideoPost. As a result, we cannot use the post instance again in post.uuid.to_string() because it has been moved. Right now, we can fix the code by changing the order of the lines:
let show_posts: Vec<ShowPost> = posts
.into_iter()
.map(|post| ShowPost {uuid: post.uuid.to_string(),
post_html: post.to_media().raw_html(),
})
.collect();
There's no moving when we use post.uuid.to_string(), so the code should compile.
But, how we can create a copy of an instance instead of moving it? If a type implements the std::marker::Copy trait, then when we assign an instance from another instance, it will create a duplicate in the stack. This is the reason why simple types such as u8, which don't require a lot of memory or have a known size, implement the Copy trait. Let's see the illustration of how this code works:
let x: u8 = 8;
let y = x;
Stack: ☐☒☐☐☒☐☐☐☐☐☐☐
Heap: ☐☐☐☐☐☐☐☐☐☐☐☐
A type may automatically derive the Copy trait if all members of that type implement the Copy trait. We also have to derive Clone, because the Copy trait is trait bound by the Clone trait in its definition: pub trait Copy: Clone { }). Here is an example of deriving the Copy trait:
#[derive(Copy, Clone)]
struct Circle {r: u8,
}
However, this example will not work because String does not implement Copy:
#[derive(Copy, Clone)]
pub struct Sheep {...
pub name: String,
...
}
This example will work:
#[derive(Clone)]
pub struct Sheep {...
pub name: String,
...
}
Cloning works by copying the content of the heap memory. For example, let's say we have the preceding code and the following code:
let dolly = Sheep::new(...);
We can visualize dolly as follows:
Stack: ☐☒☐☐☐☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
Let's say we assign another instance from dolly, as follows:
let debbie = dolly;
This is what the memory usage looks like:
Stack: ☐☒☐☐☐☐☒☐☐☐☐☐
↓ ↓
Heap: ☐☒☒☒☒☐☒☒☒☒☐☐
As allocating heap memory is expensive, we can use another way to see the value of an instance: borrowing.
Borrowing and lifetime
We have used references in our code. A reference is an instance in the stack that points to another instance. Let's recall what an instance memory usage looks like:
Stack: ☐☒☐☐☐☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
A reference is allocated in stack memory, pointing to another instance:
Stack: ☐☒←☒☐☐☐☐☐☐☐☐
↓
Heap: ☐☒☒☒☒☐☐☐☐☐☐☐
Allocating in the stack is cheaper than allocating in the heap. Because of this, using references most of the time is more efficient than cloning. The process of creating a reference is called borrowing, as the reference borrows the content of another instance.
Suppose we have an instance named airwolf:
#[derive(Debug)]
struct Helicopter {height: u8,
cargo: Vec<u8>,
}
let mut airwolf = Helicopter {height: 0,
cargo: Vec::new(),
};
airwolf.height = 10;
We can create a reference to airwolf by using an ampersand (&) operator:
let camera_monitor_a = &airwolf;
Borrowing an instance is like a camera monitor; a reference can see the value of the referenced instance, but the reference cannot modify the value. We can have more than one reference, as seen in this example:
let camera_monitor_a = &airwolf;
let camera_monitor_b = &airwolf;
...
let camera_monitor_z = &airwolf;
What if we want a reference that can modify the value of the instance it referenced? We can create a mutable reference by using the &mut operator:
let remote_control = &mut airwolf;
remote_control.height = 15;
Now, what will happen if we have two remote controls? Well, the helicopter cannot ascend and descend at the same time. In the same way, Rust restricts mutable references and only allows one mutable reference at a time.
Rust also disallows using mutable references along with immutable references because data inconsistency may occur. For example, adding the following lines will not work:
let last_load = camera_monitor_a.cargo.last(); // None
remote_control.cargo.push(100);
What is the value of last_load? We expected last_load to be None, but the remote control already pushed something to cargo. Because of the data inconsistency problem, the Rust compiler will emit an error if we try to compile the code.
Implementing borrowing and lifetime
Now that we have learned about ownership, moving, and borrowing, let's modify our code to use references.
- If we look at the current definition for TextPost, PhotoPost, and VideoPost, we can see we are taking ownership of post and moving the post instance into a new instance of TextPost, PhotoPost, or VideoPost. In src/models/text_post.rs add the following struct:
pub struct TextPost(pub Post);
- And in src/models/post.rs , add the following function:
pub fn to_text(self) -> TextPost { // self is post instance
TextPost(self) // post is moved into TextPost instance
}
- We can convert the TextPost field to be a reference to a Post instance. Modify src/models/text_post.rs into the following:
pub struct TextPost(&Post);
- Since we are converting the unnamed field into a private unnamed field, we also need an initializer. Append the following lines:
impl TextPost {
pub fn new(post: &Post) -> Self {
TextPost(post)
}
}
Since we changed the initialization of TextPost, we also need to change the implementation of to_text() and to_media(). In src/models/post.rs, change the to_text() method to the following:
pub fn to_text(&self) -> TextPost {
TextPost::new(self)
}
Change the to_media() method to the following:
pub fn to_media(self) -> Box<dyn DisplayPostContent> {
match self.post_type {
PostType::Text => Box::new((&self).to_text()),
...
}
}
- Let's try compiling the code. We should see an error as follows:
error[E0106]: missing lifetime specifier
--> src/models/text_post.rs:4:21
|
4 | pub struct TextPost(&Post);
| ^ expected named lifetime parameter
The reason for this error is that the code needs a lifetime specifier. What is a lifetime specifier? Let's see an example of a very simple program:
fn main() {
let x;
{
let y = 5;
x = &y;
} // y is out of scope
println!("{}", *x);
}
- Remember, in Rust, any instance is removed automatically after we reach the end of the scope. In the preceding code, y is created inside a scope denoted by curly brackets, {}. When the code reaches the end of the scope, }, the y instance is cleared from the memory. So, what will happen with x? The preceding code will fail to compile because x is not valid anymore. We can fix the code as follows:
fn main() {
let x;
{
let y = 5;
x = &y;
println!("{}", *x);
}
}
- Now, let's take a look at our code in src/models/text_post.rs:
pub struct TextPost(&Post);
Because Rust is multithreaded and has a lot of branching, we cannot guarantee that the reference to the Post instance, &Post, can exist for as long as the TextPost instance. What will happen if &Post is already destroyed while the TextPost instance is not destroyed? The solution is that we place a marker called a lifetime specifier or lifetime annotation. Let's modify the code definition for TextPost as follows:
pub struct TextPost<'a>(&'a Post);
We are telling the compiler that any instance of TextPost should live as long as the referenced &Post, which indicated by lifetime indicator, 'a. If the compiler finds out that &Post is not living as long as the TextPost instance, it does not compile the program.
The convention for a lifetime specifier is using a small, single letter such as 'a, but there's also a special lifetime specifier, 'static. A 'static lifetime specifier means the data referenced is living as long as the application. For example, we are saying the data referenced by pi will live as long as the application:
let pi: &'static f64 = &3.14;
- Let's modify the rest of the application. We have seen how we use a lifetime specifier in the type definition; let's use it in an impl block and method as well. Modify the rest of src/models/text_post.rs into the following:
impl<'a> TextPost<'a> {
pub fn new(post: &'a Post) -> Self {...}
}
impl<'a> DisplayPostContent for TextPost<'a> {...}
- Let's change PhotoPost in src/models/photo_post.rs to use lifetime as well:
pub struct PhotoPost<'a>(&'a Post);
impl<'a> PhotoPost<'a> {
pub fn new(post: &'a Post) -> Self {
PhotoPost(post)
}
}
impl<'a> DisplayPostContent for PhotoPost<'a> {...}
- Let's also change VideoPost in src/models/video_post.rs:
pub struct VideoPost<'a>(&'a Post);
impl<'a> VideoPost<'a> {
pub fn new(post: &'a Post) -> Self {
VideoPost(post)
}
}
impl<'a> DisplayPostContent for VideoPost<'a> {...}
- And in src/models/post.rs, modify the code as follows:
impl Post {
pub fn to_text(&self) -> TextPost {
TextPost::new(self)
}
pub fn to_photo(&self) -> PhotoPost {
PhotoPost::new(self)
}
pub fn to_video(&self) -> VideoPost {
VideoPost::new(self)
}
pub fn to_media<'a>(&'a self) -> Box<dyn
DisplayPostContent + 'a> {
match self.post_type {
PostType::Photo => Box::new(self.to_photo()),
PostType::Text => Box::new(self.to_text()),
PostType::Video => Box::new(self.to_video()),
}
}
...
}
Now, we are using a borrowed Post instance for TextPost, PhotoPost, or VideoPost instances. But, before we end this chapter, let's refactor the code a little bit by following these instructions:
- We can see the ShowPost struct is duplicated inside get_post() and get_posts(). Add a new struct into src/models/post.rs:
use rocket::serde::Serialize;
...
#[derive(Serialize)]
pub struct ShowPost {
pub uuid: String,
pub post_html: String,
}
- Add a method to convert Post into ShowPost:
impl Post {
...
pub fn to_show_post<'a>(&'a self) -> ShowPost {
ShowPost {
uuid: self.uuid.to_string(),
post_html: self.to_media().raw_html(),
}
}
...
}
- In src/routes/post.rs, add ShowPost to a use declaration:
use crate::models::{
pagination::Pagination,
post::{Post, ShowPost},
user::User,
};
- Modify the get_post() function by removing these lines to remove unnecessary struct declarations and functions:
#[derive(Serialize)]
struct ShowPost {
post_html: String,
}
#[derive(Serialize)]
struct Context {
user: User,
post: ShowPost,
}
fn create_context<T: DisplayPostContent + ?Sized>(user: User, media: &T) -> Context {
Context {
user,
post: ShowPost {
post_html: media.raw_html(),
},
}
}
let media = post.to_media();
let context = create_context(user, &*media);
- Replace those lines with the context! macro:
let context = context! { user, post: &(post.to_show_post())};
- In the get_posts() function, remove these lines:
#[derive(Serialize)]
struct ShowPost {
uuid: String,
post_html: String,
}
let show_posts: Vec<ShowPost> = posts
.into_iter()
.map(|post| ShowPost {
uuid: post.uuid.to_string(),
post_html: post.to_media().raw_html(),
})
.collect();
Replace those lines with this line:
let show_posts: Vec<ShowPost> = posts.into_iter().map(|post| post.to_show_post()).collect();
- Also, change the context instantiation:
let context = context! {user, posts: &show_posts, pagination: new_pagination.map(|pg|pg.to_context())};
- And finally, remove the unnecessary use declaration. Remove these lines:
use crate::traits::DisplayPostContent;
use rocket::serde::Serialize;
The implementation of showing posts should be cleaner now we are using the borrowed Post instance. There should be no difference in the speed of the application because we are just using the reference of a single instance.
In fact, sometimes it's better to use an owned attribute instead of a reference because there's no significant performance improvement. Using references can be useful in complex applications, high-memory usage applications, or high-performance applications such as gaming or high-speed trading with a lot of data, at the cost of development time.
Summary
In this chapter, we have implemented get_post() and get_posts() to show Post information in a web browser. Along with those implementations, we have learned about reducing code duplication through generics and trait bounds.
We have also learned about the most distinct and important feature of Rust: its memory model. We now know an instance owns a memory block, either in the stack or in both the stack and heap. We have also learned that assigning another instance to an instance means moving ownership unless it's a simple type that implements the Copy and/or Clone trait. We have also learned about borrowing, the rules of borrowing, and the use of the lifetime specifier to complement moving, copying, and borrowing.
Those rules are some of the most confusing parts of Rust, but those rules are also what make Rust a very safe language while still having the same performance as other system languages such as C or C++. Now that we have implemented showing posts, let's learn how to upload data in the next chapter.