
8. Executing a Program Increment
Vision without execution is hallucination.
—Thomas Edison
Improving Team Flow with Kanban
Overview
The Big Picture illustrates how the Agile Release Train (ART) teams and stakeholders continuously deliver value in a series of Program Increments (PIs).
As we described in the previous chapter, each PI starts with a planning session and is followed by four (the default number)1 execution iterations.
1. Although this is the default pattern, there is no fixed rule for how many iterations are in a PI. Experience has shown that PIs with a duration of between eight and twelve weeks work best, with a bias toward the shorter end of the range.
Each PI concludes with an Innovation and Planning (IP) iteration. During each PI, team and program activities help “keep the train on the tracks,” as shown in Figure 8-1.
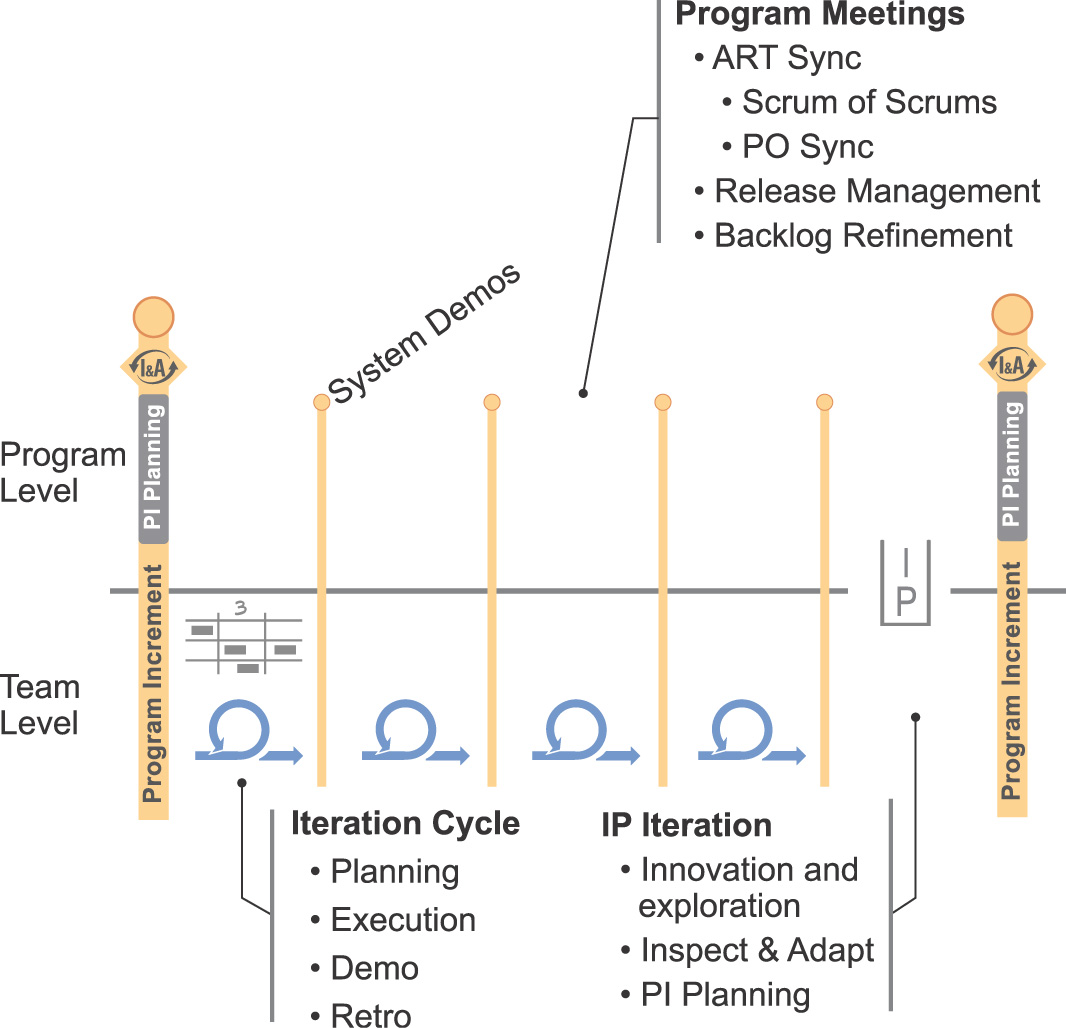
In this chapter, we’ll describe the typical Scrum cycle first and then address how to improve flow in Scrum using kanban techniques. Then we describe the SAFe kanban model, for systems teams and others who operate with more of a response mandate. Even then, we’ll apply cadence and synchronization to assure alignment and full system integration with other teams on the train. Finally, we describe the other program-level meetings and events, concluding with Inspect and Adapt (I&A).
The Iteration Cycle
Most teams use Scrum, which has a routine set of activities, including iteration planning, execution, review, and retrospective.
Iteration Planning
Iteration planning is a standard and well-defined Scrum activity. In the Scaled Agile Framework (SAFe), it also involves refining the details and adjusting the initial iteration plans that were created during the PI planning event.
Attendees include the Product Owner, Scrum Master, Development Team, and other stakeholders. The meeting is timeboxed to a maximum of four hours (for a two-week sprint). Planning inputs include the following:
• The team and program PI objectives
• Stories that were identified during PI planning
• Existing stories from the team’s backlog, defects, enablers, and so on
The Product Owner presents the highest-priority stories. The team discusses implementation options, technical issues, Nonfunctional Requirements (NFRs), and dependencies. The team elaborates acceptance criteria, estimates the effort to complete the story, and puts it in the iteration backlog.
When the team reaches the limit of its velocity for that period, it summarizes the stories into a set of iteration goals and adjusts as needed to achieve the larger purpose of making progress toward the PI objectives.
The output of iteration planning includes the following:
• The iteration backlog, consisting of the stories and acceptance criteria the team committed to in the iteration
• Iteration goals—the business and technical objectives of the iteration
• A commitment to the work needed to achieve the iteration goals
Figure 8-2 shows that the team’s commitment has two parts, which helps maintain a healthy balance between commitment and adaptability.

Iteration Execution
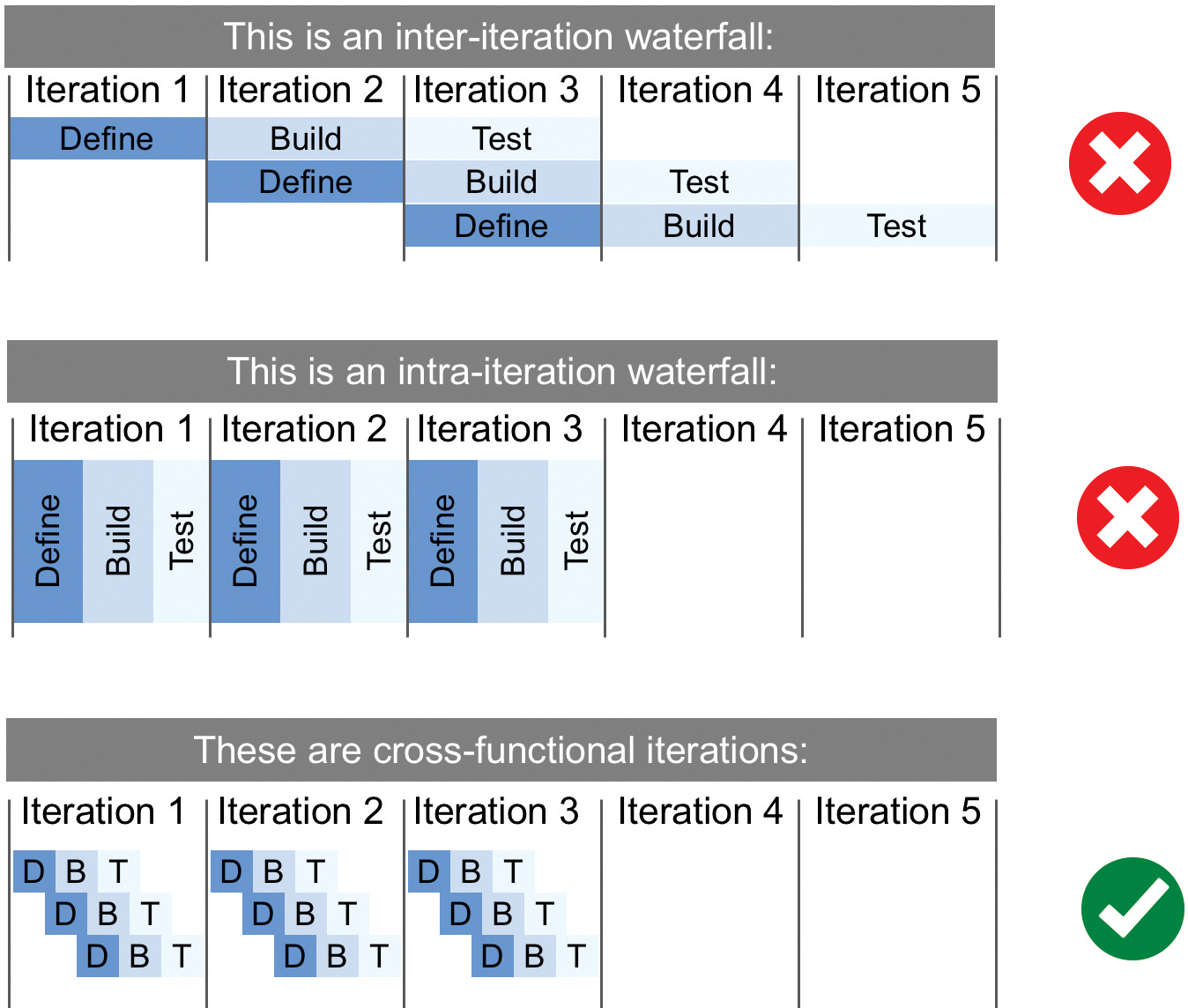
After planning, the team starts implementing new user stories, each of which creates a new baseline of functionality. Teams avoid “waterfalling” the iteration by ensuring that they are completing full define-build-test cycles for each story, as Figure 8-3 illustrates.
Further, implementing stories in thin, vertical slices is the foundation for fine-grained incremental development, integration, and testing, as shown in Figure 8-4.
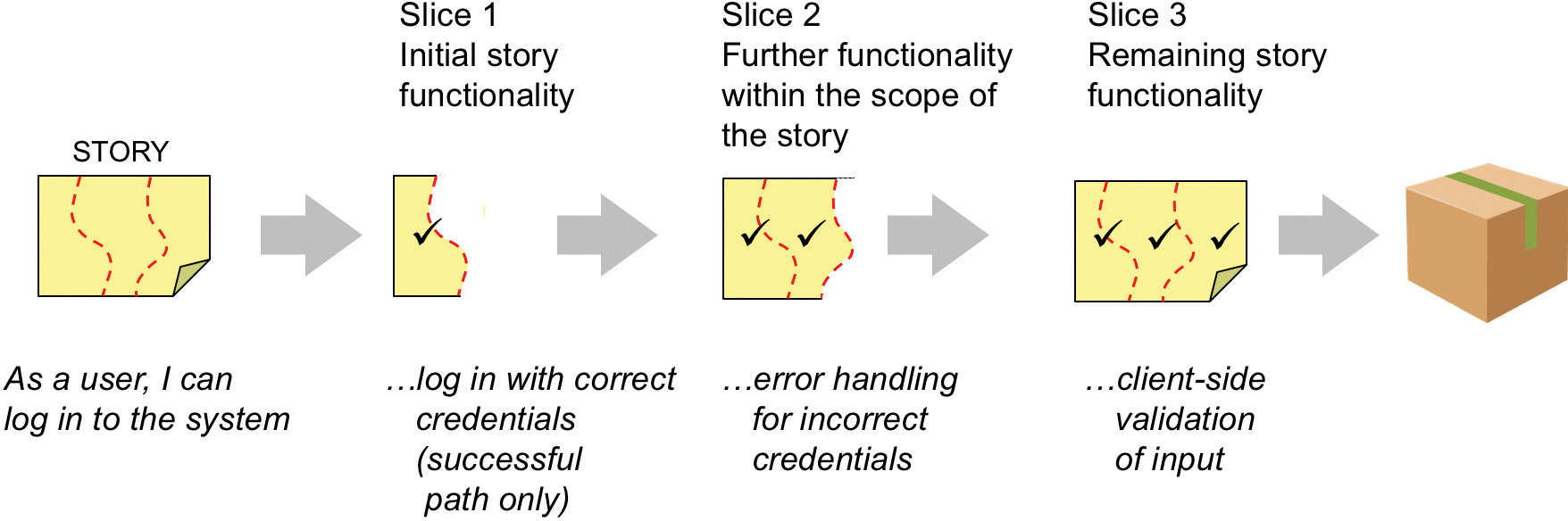
This approach enables the shortest possible feedback cycle and allows the teams to integrate and test a small increment of the working system.
Tracking Progress
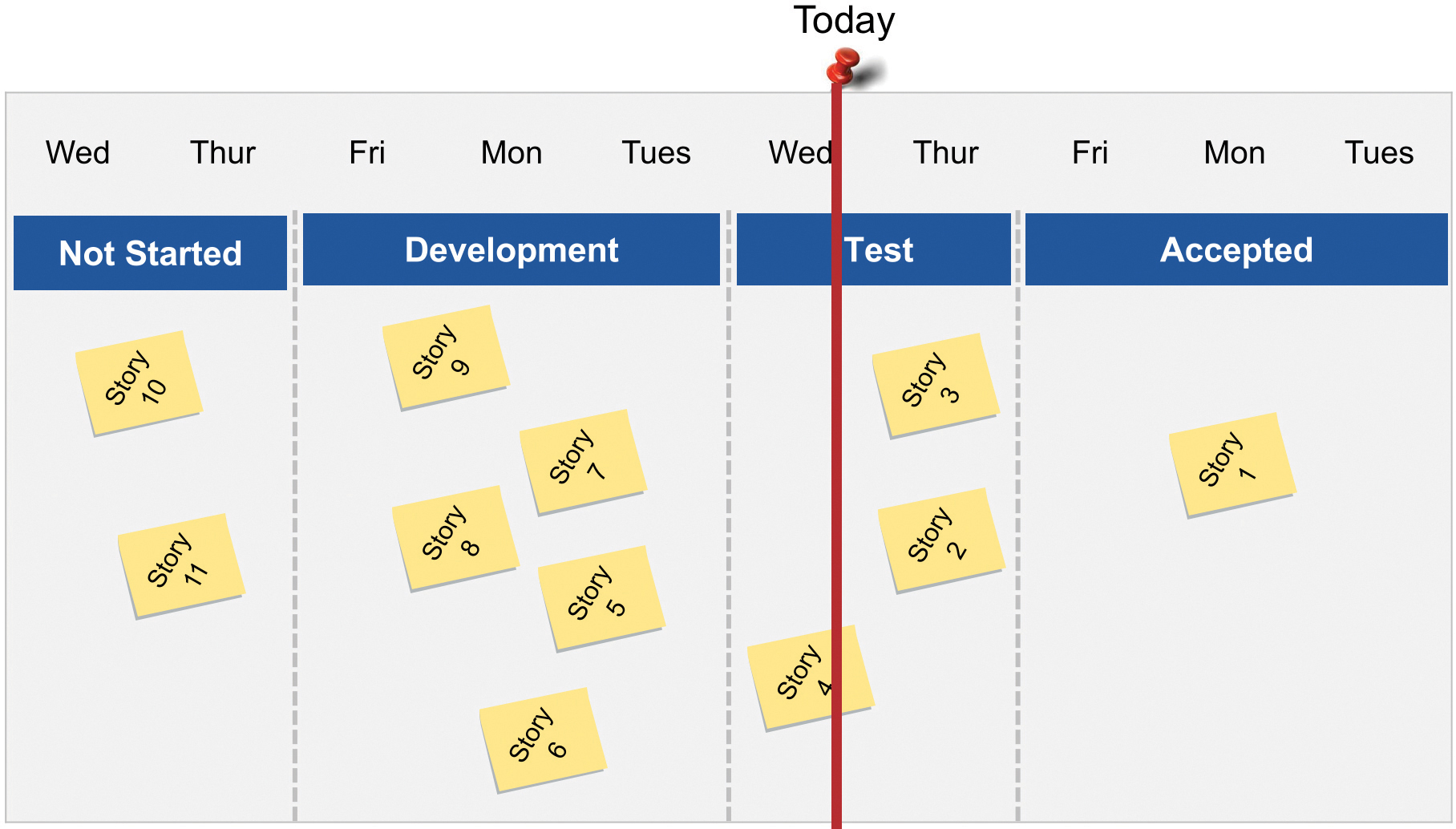
Iteration tracking provides visibility into the status of the stories, defects, and other activities that the team is working on. Most teams use a Big Visible Information Radiator (BVIR) or “storyboard” such as that illustrated in Figure 8-5.
Daily Stand-Up
Each day, the team holds a Daily Stand-Up (DSU) to coordinate their work. The standard format is for each team member to speak and address the following questions:
• What stories did I work on yesterday to help the team meet the iteration goal?
• What stories will I be able to complete today?
• What is getting in my way of meeting the iteration goal?
The DSU is strictly timeboxed to 15 minutes. The meeting is most effective when held in front of a BVIR or kanban board (covered later in the chapter). The DSU is not a management reporting or problem-solving meeting. Rather, it’s a tool to help team members identify issues and address dependencies. It is often followed by a “meet-after” for some attendees, whereby time is dedicated to address any issues raised.
Iteration Review
Each iteration concludes with an iteration review to demo the increment and adapt the backlog as needed. During the review, the team assesses whether it has met the iteration goals, and reviews any other metrics it has agreed to analyze, including velocity. The data provides some of the context for the retrospective that follows. Another aspect of the review is to show any working stories that have not yet been demonstrated to the Product Owner and other stakeholders and to get feedback. Teams demo every story, spike, refactor, and new NFR.
The preparation for the review begins during iteration planning, where teams start thinking about how they will demo the stories they are committing to. This facilitates planning and alignment and fosters a more thorough understanding of the needed functionality for the increment.
The review starts with a quick check of the iteration goals and then proceeds with a walk-through of all the committed stories. Each is demoed in a working, tested system. Spikes are demoed through a presentation of findings. After all completed stories are demoed, the team reflects on any stories that were not completed and why. This discussion usually uncovers impediments or risks, false assumptions, changing priorities, estimating inaccuracies, or overcommitment.
Iteration Retrospective
After the iteration review, the whole team participates in a retrospective to reflect on the work just completed and to develop a plan for improvements in the next iteration. The Scrum Master facilitates and applies tools and processes for data collection and problem-solving. The team reviews the results of improvement stories identified in the prior retrospective and identifies new stories for improvement in the next iteration. One simple format is a simple analysis of what went well, what didn’t, and what to do better next time.
Building Quality In
Built-in quality is one of the four core values of SAFe. The enterprise’s ability to deliver new functionality with the fastest sustainable lead time and to be able to react to rapidly changing business environments is dependent on solution quality. But built-in quality is not unique to SAFe. Rather, it is a core principle of the Lean-Agile mindset, where it helps avoid the cost of delays associated with recall, rework, and defect fixing. The Agile Manifesto is focused on quality as well: “Continuous attention to technical excellence and good design enhances agility.”2
2. http://agilemanifesto.org/principles.html
The following sections summarize recommended practices for achieving built-in quality.
Software Practices
SAFe’s software quality practices—many of which are inspired by Extreme Programming (XP)—help Agile software teams ensure that the solutions they build are high quality and adaptable to change. The collaborative nature of these practices, along with a focus on frequent validation, creates an emergent culture in which engineering and craftsmanship are key business enablers. These include the following:
• Continuous Integration (CI). This is the practice of merging the code from each developer’s workspace into a single main branch of code, multiple times per day. This lessens the risk of deferred integration issues and their impact on system quality and program predictability. Teams perform local integration at least daily. But to confirm that the work is progressing as intended, full system-level integration should be achieved at least one or two times per iteration.
• Test-first. Consists of a set of practices that encourages teams to think deeply about intended system behavior before implementing code. In Test-Driven Development (TDD), developers write an automated unit test first, run the test to observe the failure, and then write the minimum code necessary to pass the test. In Acceptance Test-Driven Development (ATDD), story and feature acceptance criteria are expressed as automated acceptance tests, which can be run continuously to ensure continued conformance as the system evolves.
• Refactoring. Refactoring is “a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior.”3 A key enabler of emergent design, refactoring is essential to Agile. To maintain system robustness, teams continuously refactor code in a series of small steps, providing a solid foundation for future development.
3. Martin Fowler, Refactoring: Improving the Design of Existing Code (Addison-Wesley Professional, 1999).
• Pair work. Some teams follow pair programming, but that may be too extreme for many. More generally, pair work may couple developers and testers on a story. Still others prefer more spontaneous pairing, with developers collaborating for critical code segments, refactoring of legacy code, development of interface definition, and system-level integration challenges.
• Collective ownership. This practice “encourages everyone to contribute to all segments of the solution. Any developer can change any line of code to add functionality, fix bugs, improve designs, or refactor.”4 It’s particularly critical as big systems have big code bases, and it’s less likely that the original developer is still on the team or program. And even if they are, waiting for “someone else” to make a change is a handoff and a certain delay.
4. www.extremeprogramming.org/rules/collective.html
• Agile architecture. This is a set of principles and practices (see SAFe Architectural Runway and Principles of Agile Architecture guidance) that support the active evolution of the design and architecture of a system, concurrent with the implementation of new business functionality. With this approach, the architecture of a system evolves over time while simultaneously supporting the needs of current users. It avoids Big Design Up Front (BDUF) and the starting and stopping of phase-gated development.
Firmware and Hardware Practices
With respect to firmware and hardware, the quality goal is the same, but the physics and economics—and therefore the practices—are somewhat different. There, errors and unproven assumptions in firmware and hardware development can introduce a much higher cost of change and rework over time, as illustrated in Figure 8-6.
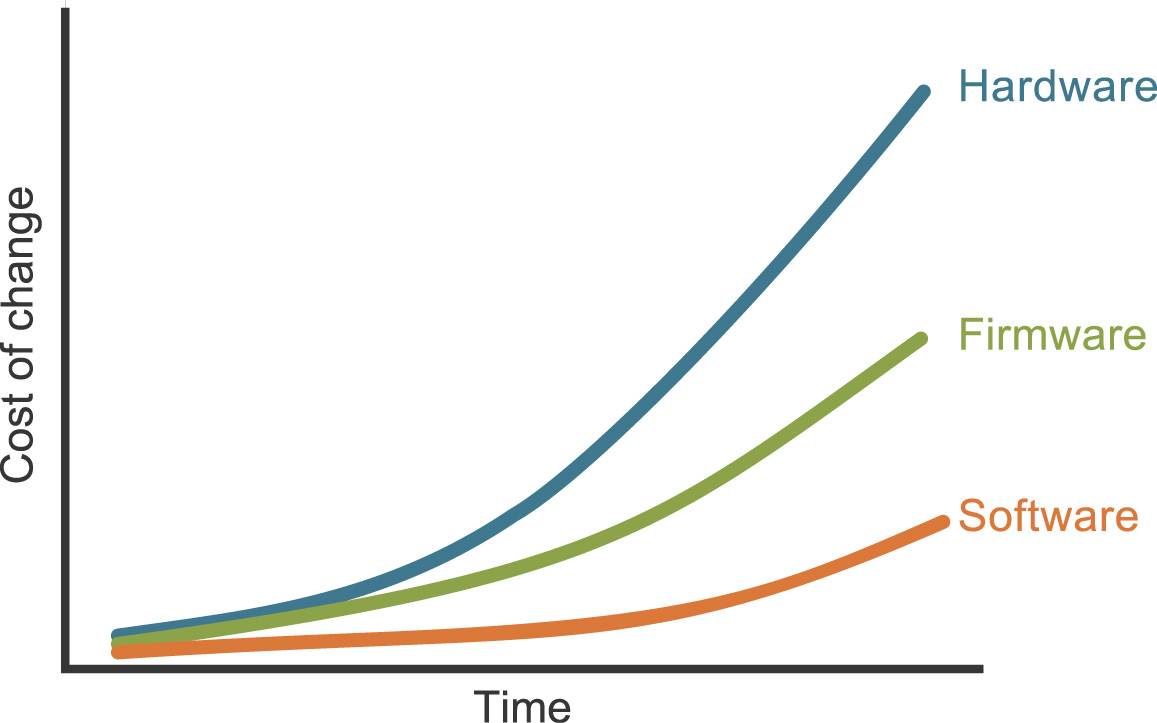
Figure 8-6. Relative cost of change over time for software, firmware, and hardware5
5. www.innolution.com/blog/agile-in-a-hardware-firmware-environment-draw-the-cost-of-change-curve
This higher cost of change drives developers of complex systems to a number of practices that assure quality during solution development.
• Model-based systems engineering. This is the application of modeling and tools to the requirements, design, analysis, and verification activities in solution development. It provides a cost-effective way to learn about system characteristics prior to and during development. It helps manage the complexity and cost of large-system documentation.
• Set-based design. This is a practice that maintains multiple requirements and design options for a longer period in the development cycle. Empirical data is used to narrow focus based on the emergent knowledge. (Set-based design was discussed further in principle #3 in chapter 5, “SAFe Principles.”)
• Frequent system integration. For many software solutions, CI is an achievable goal. However, systems with physical components—molds, printed circuit boards, mechanisms, fabricated parts, and so on—evolve more slowly and can’t be integrated and evaluated every day. However, that can’t be an excuse for late and problematic integration. That is why builders of complex and embedded systems shoot for early and frequent integration of components and subsystems.
• Design verification. Even frequent integration is not enough. First, it can occur too late in the process because of the dependencies of the availability of various system components. Second, it can’t predict and evaluate all potential usage and failure scenarios. To address this, builders of high assurance systems perform design verification to ensure that a design meets the solution intent. This may include specification and analysis of requirements between subsystems, worst-case analysis of tolerances and performance, Failure Mode Effects Analysis (FMEA), modeling and simulation, full verification and validation, and traceability.
Improving Team Flow with Kanban
Kanban is a method for visualizing and managing work. Kanban systems include Work in Process (WIP) limits, which help to identify bottlenecks and improve the flow of work.
Agile teams, including Scrum teams, can apply kanban to better understand their process, how work flows through their system, and how to make the development process more effective. The primary aspects of a kanban system include the following:
• Work moves through the system in a series of defined steps.
• All work is visualized, and the progress of individual items is tracked.
• Teams agree on specific WIP limits for each step and change them to improve flow.
• Teams adopt specific policies covering how work is managed (for example, entry/exit criteria for a step, classes of services).
• Work items are tracked from the time they enter the system to the time they leave, providing continuous indicators of flow, WIP, and measures of lead time.
The Kanban Board
To get started, teams typically create a graphic representation of their current process and define some initial WIP limits. Figure 8-7 shows an example of one team’s initial kanban board.

In this case, the team has included two “ready” buffers to better manage variability of flow. One comes before the “review” step; perhaps it helps smooth the flow of review by external subject-matter experts whose availability may be uneven. The other buffer comes before “integrate and test,” which, in this case, requires the use of shared test fixtures and resources. Since people on the same infrastructure also perform integration and testing, these two steps are treated as a single state.
A team’s kanban board evolves over time. After defining the initial process steps and WIP limits—and executing for a while—the team’s bottlenecks, resource constraints, and overspecialization will begin to surface. The team can then improve its process accordingly. As assumptions are validated, teams adjust WIP limits, and steps may be merged, split, or redefined.
Measuring Flow
To understand and improve their flow and process, kanban teams use objective measures, including average lead time, WIP, and throughput. One common method is to use a Cumulative Flow Diagram (CFD), illustrated in Figure 8-8.
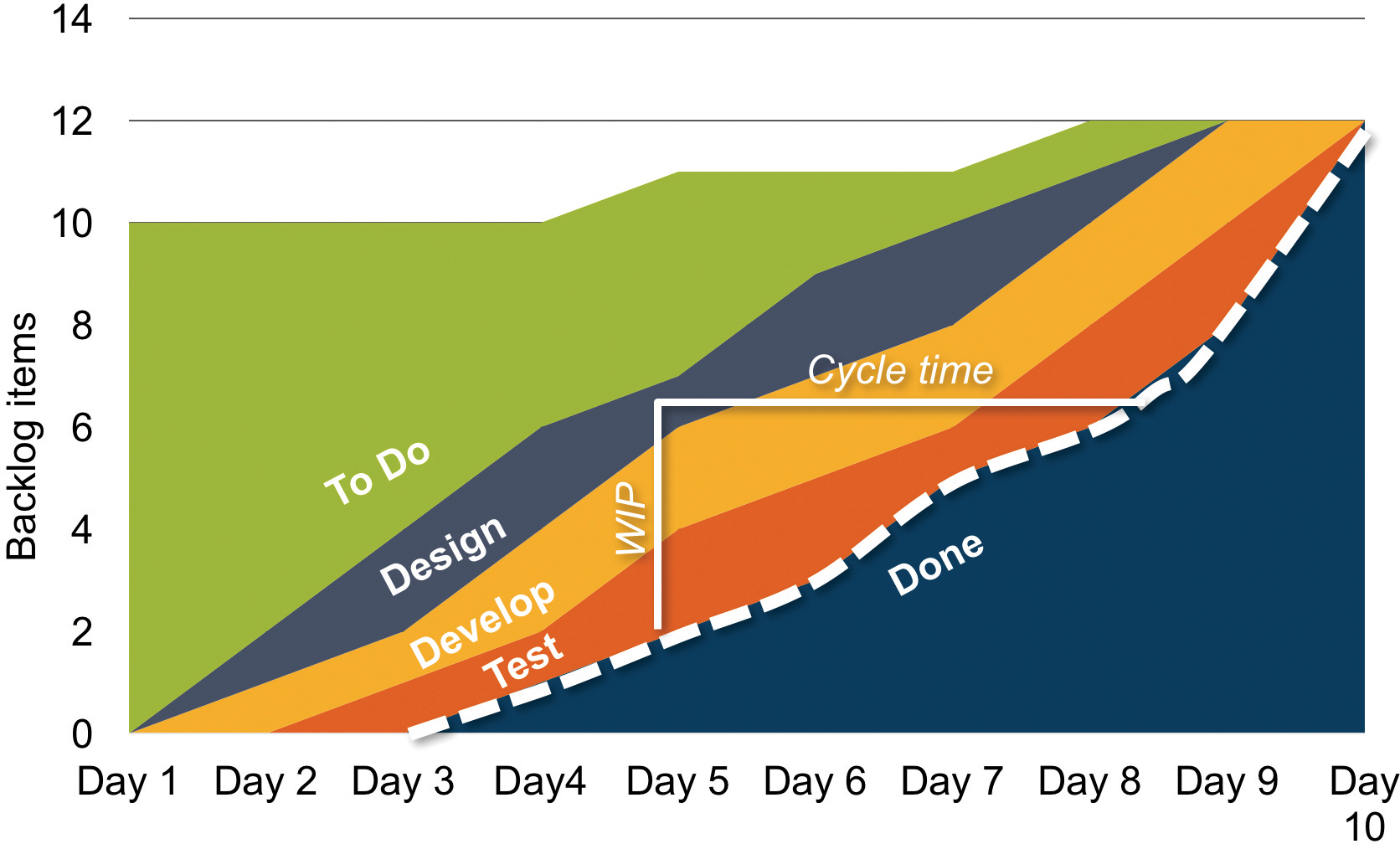
The CFD also provides data for calculating current iteration throughput (average number of stories per day). It also provides visualization of trends and significant variations, which may be a result of internal impediments the team is unaware of or external forces that impede the flow.
Managing Work with Class of Service
Figure 8-7 shows “classes of service” to help teams optimize the execution of backlog items. Each class has a specific “swim lane” on the board and an execution policy for managing that type of work. Here are some examples:
• Standard. Normal prioritization and sequencing practices apply.
• Fixed date. Some items are required to meet milestones and dependencies with a predetermined date. These items are pulled into development when necessary so as to be finished on time.
• Expedite. These are high-priority items that must be done as soon as possible. They can be pulled into implementation even in violation of current WIP constraints. Typically, teams set a policy that there can be only one expedite item in the system at a time. Teams may swarm on that item to make sure it moves through the system quickly.
Kanban Teams Are on the Train
Some teams—often the System Team and maintenance teams—choose to apply kanban as their primary development method.
In these contexts, the uneven arrival of the work, fast-changing priorities, and the lower value of planning “what exactly will be done in the next iteration” all lead them to this choice. However, these teams are “on the train,” and certain rules apply.
• Cadence and synchronization still apply. Kanban teams participate in ART activities and events. This includes PI planning, the all-important system demo, and Inspect and Adapt (I&A).
• Estimating work. Kanban teams generally do not invest as much time in estimating as most Scrum teams do. However, they must be able to estimate the demand against their capacity for PI planning and also participate in the economic estimation of larger backlog items.
• Calculating velocity. To plan and forecast, the teams must understand their velocity. Kanban teams use their CFDs to estimate their actual throughput in stories per iteration or simply count and average them. Teams can then calculate their derived velocity by multiplying the throughput by an average story size. In this way, both Scrum and kanban teams participate equally in the larger planning, road-mapping, and economic framework.
Managing ART Flow
ARTs are designed to be long-lived and support a continuous flow of value to the customer. Trains continuously run; they don’t stop and restart. That means they must continuously pull in new work, elaborate it, analyze it, implement it, and release it. In this section, we’ll describe some of the aspects of ART value flow.
Program Backlog and Kanban
Each ART delivers valuable features every PI. To do that, they must always have a small backlog of new features that are visible to everyone, have been socialized, and are ready to implement. To achieve this, ARTs use a kanban system to analyze features and get them ready for implementation. Features that are approved for implementation are maintained in the program backlog, as shown in Figure 8-9.
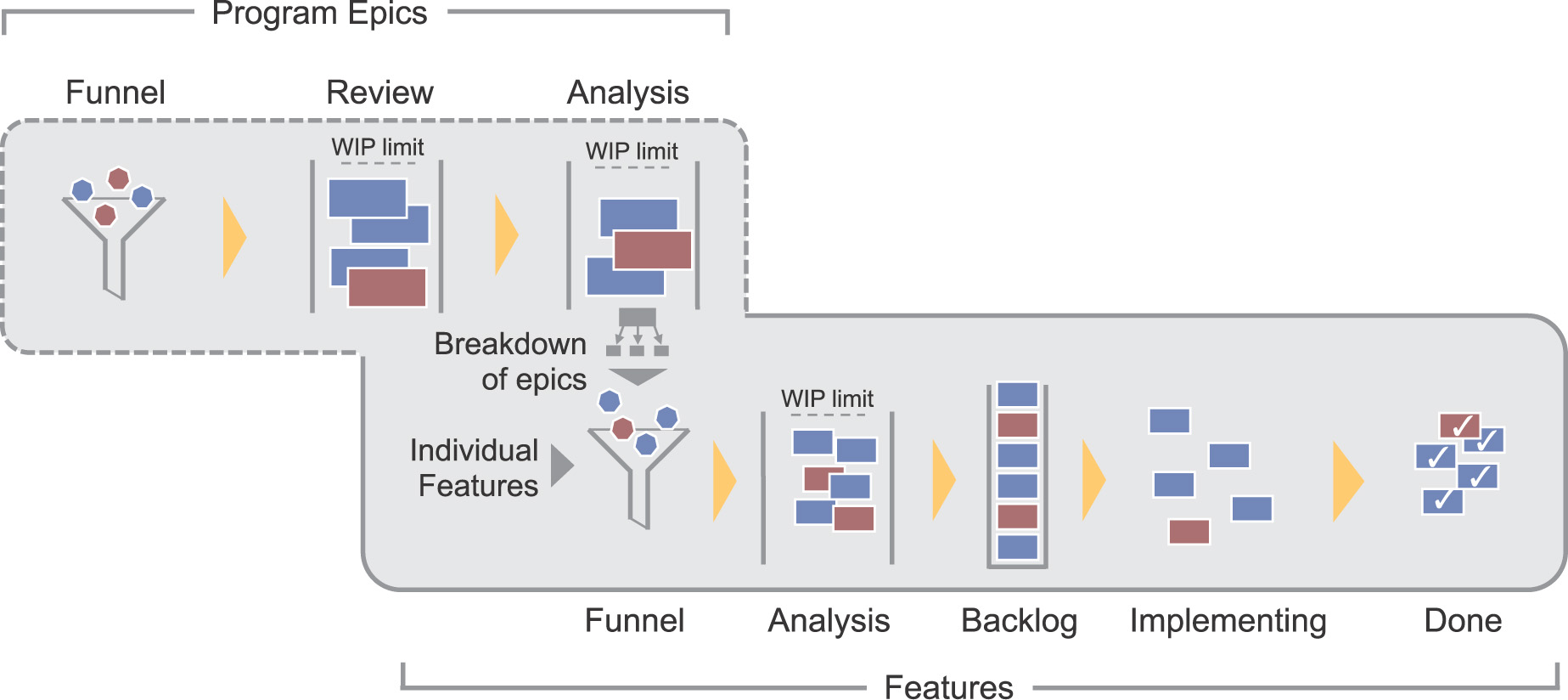
The kanban system consists of two main elements.
• Program epic section. This section analyzes and approves program epics and splits them into features to be further explored and implemented “downstream.” The workflow follows the equivalent set of example steps in the portfolio kanban. (See chapter 13, “Portfolio Level Overview.”)
• Feature section. This section is used to analyze, approve, and ready features (and enablers) for implementation. Many features originate locally from the ART; others are initiated by splitting portfolio or program epics. Product Management and System Architects/Engineers have content authority for features and enablers, respectively.
The following is a typical list of kanban steps for the program level:
• Funnel. Captures new feature ideas. These include requests for new functionality, as well as enablers needed to implement NFRs, build architectural runway, or enhance infrastructure.
• Analysis. Features that best align with the vision and strategic themes move to analysis for further exploration. Key attributes such as business benefit, acceptance criteria, and size are refined. Some features may require prototyping or other exploration. This step is WIP limited to assure that the right level of analysis is done and to balance the flow of new features to implementation capacity.
• Backlog. The highest-priority features, sufficiently elaborated and approved by Product Management, move to the program backlog, where they are prioritized with WSJF and await implementation.
• Implementing. At every PI boundary, the ART pulls the top WSJF features from the program backlog and moves them into implementing. WIP is limited by default, as the teams put in only what they can accomplish in a PI.
• Done. When implemented and accepted, they progress to done.
Sync Meetings
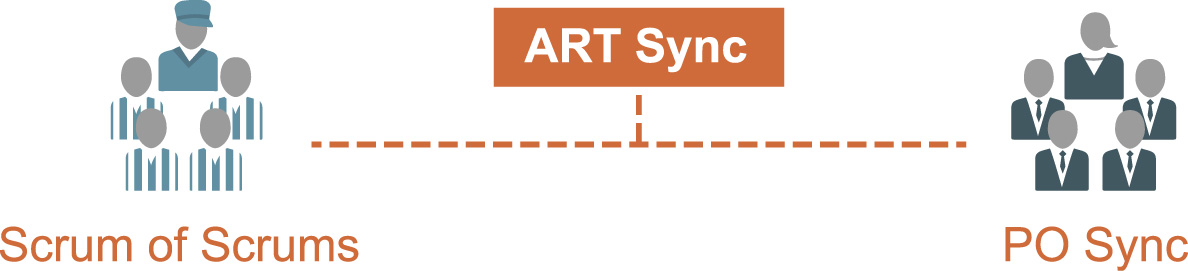
Keeping work moving requires frequent collaboration. To assess and manage progress and dependencies, ARTs coordinate through various “sync” meetings. These typically include the following:
• Scrum of Scrums (SoS). The Release Train Engineer (RTE) typically facilitates the SoS that meets to coordinate ART dependencies and to provide visibility into progress and impediments. Scrum Masters and others update their progress toward milestones and PI objectives and manage inter-team dependencies. This meeting is typically held weekly (or more frequently, as needed).
• Product Owner (PO) Sync. The purpose of the PO sync is to gain visibility into how well the ART is progressing toward achieving PI objectives, to discuss problems or opportunities with feature development, and to assess any scope adjustments. In addition, this meeting is often used for program backlog refinement. This meeting is also held weekly (or more frequently, as needed).
Sometimes, it makes sense to combine the SoS and PO sync meetings. This is called an “ART Sync” meeting, as illustrated in Figure 8-10.
Release Management
Release Management provides governance for any upcoming releases and also offers regular communication to management. This function has the authority to approve any scope, timing, or resource adjustments necessary to help ensure a quality release. Sometimes this can be handled by the teams and the trains themselves as part of their DevOps capability but, often, additional stakeholders, and some additional governance, is required. In such cases, Release Management meetings may be held with representatives that typically include:
• RTEs and Value Stream Engineers (VSEs)
• Business Owners and Product and Solution Managers
• Sales and marketing
• Internal IT, production, and deployment personnel
• Development managers, system and solution-level QA
• CTOs and/or System and Solution Architects/Engineering
Release Management may meet weekly, or as often as needed, to assess status and address current impediments. The meeting also provides senior management with regular visibility into upcoming releases and other milestones.
Enabling Flow with Architectural Runway
The concept of architectural runway provides one of the means by which Agile architecture is implemented. An architectural runway exists when the system has sufficient existing technological infrastructure to support the implementation of the highest-priority features in a near-term PI, without excessive redesign and delay. This runway provides the necessary technical basis for quickly implementing new features. It is a key enabler of development flow.
But as Figure 8-11 illustrates, the architectural runway is constantly consumed by new functionality. ARTs must continually invest in extending the runway by implementing enablers to support new functionality. Some of these enablers fix existing problems with the solution—for example, the need to enhance performance—while others might implement foundational technical capabilities and services that will be used by future system behaviors.
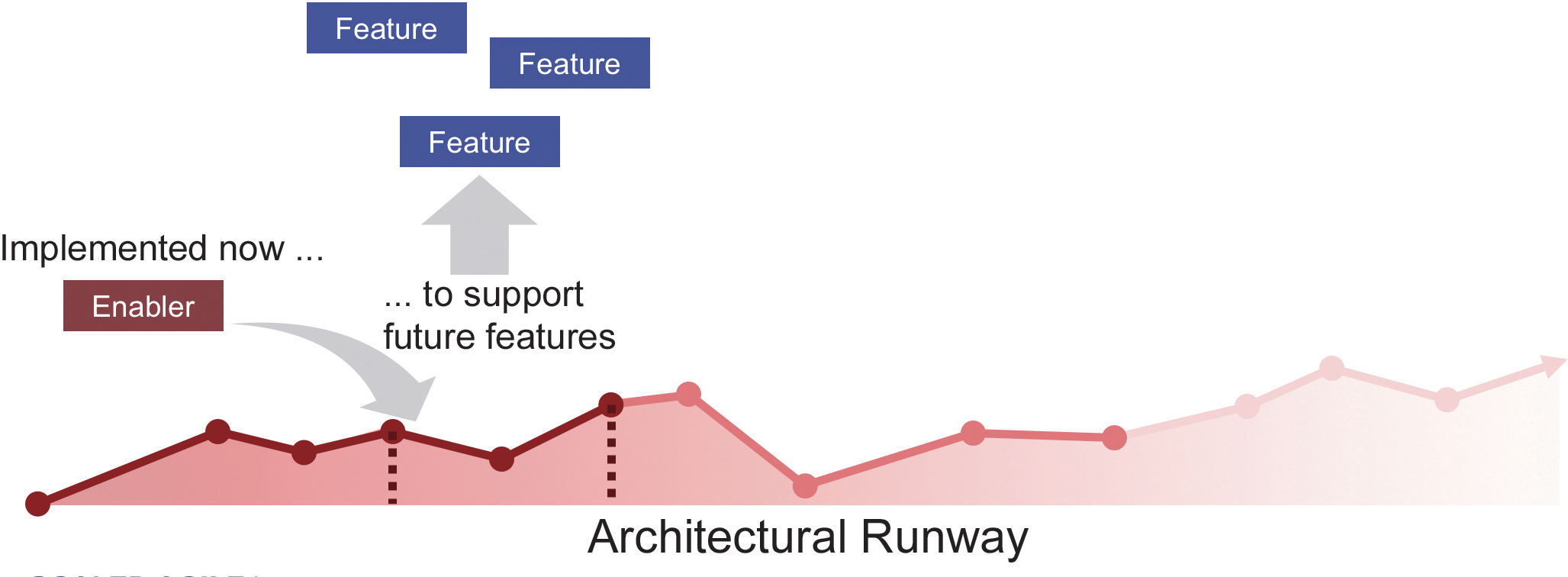
For this reason, teams need some intentional architecture—a set of planned architectural initiatives that enhance solution design, performance, and usability, and that provide guidance for cross-team design and implementation synchronization.
Together, intentional architecture and emergent design enable ARTs to create and maintain large-scale solutions. Emergent design enables fast, local control so that teams react appropriately to changing requirements without excessive attempts to future-proof the system. Intentional architecture provides the guidance needed to ensure that the system as a whole has conceptual integrity and efficacy. Achieving the right balance of emergent design and intentional architecture drives the effective evolution of large-scale systems.
Without enough investment in the architectural runway, the train will experience slow value delivery, needing to redesign for the delivery of each feature. Too much runway, however, will create architecture “inventory” that might never be used and can even clog the system. A sense of balance is required.
Lean UX
In SAFe, Lean UX is the application of lean principles to user experience design, focusing on minimizing waste in the development process and gaining fast, experiential feedback.
It uses an iterative, hypothesis driven approach to product development, through constant measurement and learning loops (build – measure – learn). In SAFe, Lean UX is applied at scale, with the right combination of centralized and decentralized user experience design and implementation.
As described below, Lean UX in SAFe adheres to its principles of Lean-Agile development at scale.
• SAFe Principle #2: Apply systems thinking. As Seiden and Jeff Gothelf note,6 “Lean principles drive us to harmonize our ‘system’ of designers, developers, product managers, quality assurance engineers, marketers, and others in a transparent, cross-functional collaboration that brings non-designers into our design process.” In addition, Lean UX in SAFe is a challenge of scale and is not strictly a local concern. Instead, designers take a system view and work to harmonize design elements across the larger solution, so that users who work across the system experience common styles, designs, and interactions.
6. Jeff Gothelf and Josh Seiden, Lean UX: Designing Great Products with Agile Teams (O’Reilly Media; Kindle Edition), Kindle Locations 155–157.
• SAFe Principle #3: Assume variability; preserve options. SAFe principle #3 drives UX designers to commit to final designs only at the last responsible moment. Big up-front user experience design (just like up-front anything) is avoided. Instead, the design evolves in parallel with the solution development, with teams committed to refactoring user designs as necessary in support of new knowledge.
• SAFe Principle #4: Build incrementally with fast, integrated learning cycles. Perhaps this principle summarizes SAFe Lean UX best. The user experience is built incrementally, on the same basic cadence at which the system evolves. Short iterations, rapid functional prototypes, and fast user feedback drive the design to optimum efficacy. This occurs at the local (story, component) level, as well as the system (features and subsystems) level and value stream (systems and capabilities) levels.
• SAFe Principle #5: Base milestones on objective evaluation of working systems. And finally, how does one know when the user experience is a quality experience? Simply, local team iteration reviews and system and solution demos highlight integrated user interactions and reactions. Product Owners and Product Managers serve as proxy users to some extent throughout development. And, because end-users ultimately determine value, they are brought into the development process whenever and wherever possible to validate user experience.
Given the above, achieving Lean UX at enterprise scale often challenges traditional UX roles and responsibilities. Heroic and independent UX designers no longer create pixel perfect designs up front. Instead, constant team collaboration, experimentation, fast feedback, (and yes, some continuous UX refactoring), rule the day.
Real, tangible value occurs only when the end users are successfully operating the solution in their environment. DevOps is a combination of two words, “development” and “operations,” which represents the ability of an enterprise to develop and release small batches of functionality to the business or end user in a continuous flow process. The ability to do so is integral to the value stream, and therefore DevOps is integral to SAFe.
Many SAFe concepts—small batch size, short iterations, fast feedback, continuous integration, test automation, and more—support this ultimate business need. Indeed, ARTs are developed and designed in large part for this specific purpose. They are cross-functional, and include all the skills necessary (define-design-build-test and deploy) to accomplish this objective. Initially, this typically involves engaging deployment and operations personnel within an ART, as well as cross training development teams with the skills to deploy.
Over time, the distinction between development and deployment is reduced, and ARTs operate with a continuous delivery pipeline, a mechanism by which they can seamlessly define, implement and deliver solution elements to the user, without handoffs or much external production or operations support.
Technically, there are three main processes that must be automated to implement this continuous delivery pipeline:
1. Retrieving all necessary artifacts from version control, including code, scripts, tests, metadata, and the like
2. Building, integrating, deploying, and validating the code in a staging environment
3. Deploying the validated build from staging to production, and quickly validating the new system
For most traditional IT shops, this is a form of agility that takes significant time to develop. Toward that end, SAFe offers six specific, recommended practices for building the deployment pipeline:
• Build and maintain a production-equivalent staging environment. Implement a staging environment that has the same or similar hardware and supporting systems as production.
• Maintain development and test environments to better match production. Implement development and test environments to closely resemble production by taking an economic view.
• Deploy to staging every iteration; deploy to production frequently. Do all system demos from the staging environment, including the final system and solution demos. In that way, deployability becomes part of Definition of Done (DoD) for every user story, resulting in potentially deployable software every iteration.
• Put everything under version control. This includes the new code, all required data, all libraries and external assemblies, configuration files or databases, application or database servers—everything that may realistically be updated or modified.
• Start creating the ability to automatically build environments. In order to establish a reliable deployment process, the environment setup process itself needs to be fully automated.
• Start automating the actual deployment process. This includes all the steps in the flow, including building the code, creating the test environments, executing the automated tests, and deploying and validating verified code and associated systems and utilities in the target environment.
In addition, to assure continuous and reliable operations, development teams should build application telemetry into the system, so that the system itself can report on its current health and status.
And finally, the impact on application architecture should not be underestimated. Long term, the continuous delivery pipeline requires systems that were designed—at least in part—for this primary purpose.
System Demo
The primary measure of ART progress is the objective evidence provided by a working solution in the system demo. Every two weeks, the full system—the integrated work of all teams on the train for that iteration—is demoed to the train’s stakeholders. (This is in addition to each team’s iteration demo.) Stakeholders provide the feedback the train needs to stay on course and take corrective action.
At the end of each PI, a final system demo is held as part of I&A. That demo is a significant and somewhat more structured affair, as it demonstrates the accumulation of all the features (from all teams on the train) that have been developed over the course of the PI.
In value streams with multiple ARTs, the results of all the development efforts from multiple trains—along with the contributions from suppliers—are demoed to the customers and other key stakeholders for objective feedback and evaluation. This solution demo is in addition to each ART’s PI system demo. For more information, please see chapter 12, “Coordinating ARTs and Suppliers.”
Innovation and Planning
IP iterations provide a regular, dedicated, and cadence-based opportunity for teams to work on activities that are difficult to fit into standard development iterations. These can include the following:
• Full solution integration, verification, and validation; release documentation; and so on (if releasing on the PI boundary)
• Innovation and exploration, hackathons, and so on
• I&A workshop, including final PI system demo
• Program and team backlog refinement
• Work on technical infrastructure, tooling, and other systemic impediments
• Fostering continuing education
• PI planning
In addition, IP iterations fulfill another critical role by providing an estimating buffer for meeting PI objectives and enhancing release predictability. However, routinely using that time for completing the work is a failure pattern. Doing so defeats the primary purpose of the IP iteration, and innovation will suffer. Teams must take care that the estimating guard does not simply become a crutch. ARTs typically report that their overall efficiency, velocity, sustainability of pace, and job satisfaction are all enhanced by regular opportunities to “recharge their batteries and sharpen their tools.” Figure 8-12 illustrates an example IP calendar.

Innovation
Innovation is one of the pillars of the Lean-Agile mindset. But finding time for it in the midst of urgent delivery deadlines can be difficult. To this end, ARTs use IP iterations to schedule time for research and design activities and hackathons. The rules for a hackathon can be simple.
• Team members work on whatever they want, with whomever they want.
• They demo their work to others at the end.
The insights from these activities routinely make their way into program backlogs, helping to drive innovation. Some innovations and fixes will make their way directly into the product. Automation and process improvements arising from the hackathons will be leveraged right away.
Inspect and Adapt
The I&A is held at the end of each PI and provides time to demonstrate the solution, get feedback, and then reflect, problem solve, and identify improvement actions. The improvement items can then be immediately incorporated into PI planning. This workshop has a timebox of three to four hours and has three parts.
• The PI system demo
• Quantitative measurement
• The problem-solving workshop
This is such an important event that it is the entire subject of chapter 9, “Inspect and Adapt.”
Summary
This chapter gave an overview of executing the PI, which starts with a planning session and is typically followed by four execution iterations. Each PI concludes with an IP iteration.
The key takeaways from this chapter are as follows:
• The iteration cycle occurs within the PI and consists of four main activities: iteration planning, execution, demo, and retrospective.
• Built-in quality is one of the four core values of SAFe. The enterprise’s ability to deliver new functionality with the fastest sustainable lead time and react to rapidly changing business environments is dependent on solution quality.
• Kanban is a method for visualizing and managing work. Agile teams, including Scrum teams, can apply kanban to better understand their process, how work flows through their system, and how to make the development process more effective.
• ARTs use a kanban system to analyze features and get them ready for implementation. Features that are approved for implementation are maintained in the program backlog.
• The architectural runway provides the necessary technical basis for quickly implementing new features. It is a key enabler of development flow.
• In IT shops, ARTs build and operate a DevOps pipeline that is used to help automate a continuous flow of small, incremental releases to end users. In some contexts, continuous delivery is an appropriate, and achievable, goal.
• ARTs apply scaled Lean UX practices based on SAFe’s Lean-Agile principles. These practices support emergent knowledge via fast, objective feedback on component, feature, system, and solution-level user experience design and implementation.
• The primary measure of ART progress is the objective evidence provided by a working solution in the system demo. At the end of each PI, a final system demo is held as part of I&A. It demonstrates all the features (from all teams on the train) that have been developed during the course of the PI.
• IP iterations provide a regular, dedicated, and cadence-based opportunity for teams to work on activities that are difficult to fit into standard development iterations (for example, hackathons, PI planning, I&A).
• The I&A is a regular event, held at the end of each PI, that provides time to demo the solution, get feedback, problem solve, and identify improvement actions.