
7
Using SQL with SAS and R
7.1 What is SQL?
SQL (Structured Query Language) is a language for querying and modifying data in Relational Database Management Systems (RDBMs). However SQL is also used within Apache Hive and Python as well as PySpark. The pandasql package allows you to query pandas DataFrames using SQL syntax. The entry point into all SQL functionality in Spark is the SQLContext class. The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
7.1.1 Basic Terminology
A database is a collection of information that is organized so that it can be easily accessed, managed and updated.
A relational database is a set of tables from which data can be accessed or reassembled in many different ways without having to reorganize the database tables.
7.1.2 CAP Theorem
CAP Theorem is a concept that a distributed database system can only have 2 of the 3: Consistency, Availability, and Partition Tolerance.
- Consistency: Every read receives the most recent write or an error
- Availability: Every request receives a (non‐error) response – without the guarantee that it contains the most recent write
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties of database transactions intended to guarantee validity even in the event of errors, power failures, etc.
Eventually‐consistent services are sometimes classified as providing BASE (Basically Available, Soft state, Eventual consistency), in contrast to traditional ACID.
Database systems designed with traditional ACID guarantees in mind such as RDBMS choose consistency over availability, whereas systems designed around the BASE philosophy, common in the NoSQL databases, choose availability over consistency.
7.1.3 SQL in SAS and R
SQL can be used in R by the sqldf package and using the sqldf() function whereas in SAS we use PROC SQL for using SQL. Proc sql does not require a run statement because proc sql statements are executed immediately.
7.2 SQL Select
The select statement is used to tell the database what data we want from it.
The basic syntax of a select statement is:
We use the * wildcard to select all columns:‐
In R:
We will use the inbuilt mtcars dataset in R and I have also created a mtcars dataset in SAS as follows:
- Downloaded data from:
https://vincentarelbundock.github.io/Rdatasets/csv/datasets/mtcars.csv
- Uploaded to folder in SAS
- Created a dataset named mtcars using proc import.
In SQL * denotes all data.
Using outobs we limit the output to 10.
Using select we select the variables from a particular database satisfying a certain condition (if present). The basic syntax for using sql in SAS is:
The syntax for using sql in R is:
Note we used limit to limit the number of rows.
We can select particular columns by specifying their names separated by commas in the select statement:
To select only mpg,vs, and cyl columns:
In R:
In SAS:
7.2.1 SQL WHERE
We use the WHERE clause along with SELECT to conditionally select rows.
For example:
To select only rows which have cyl=6
In R
7.2.2 SQL Order By
“Order by” is used to display the output sorted. It can be sorted in ascending, descending, or alphabetical order.
In SAS:
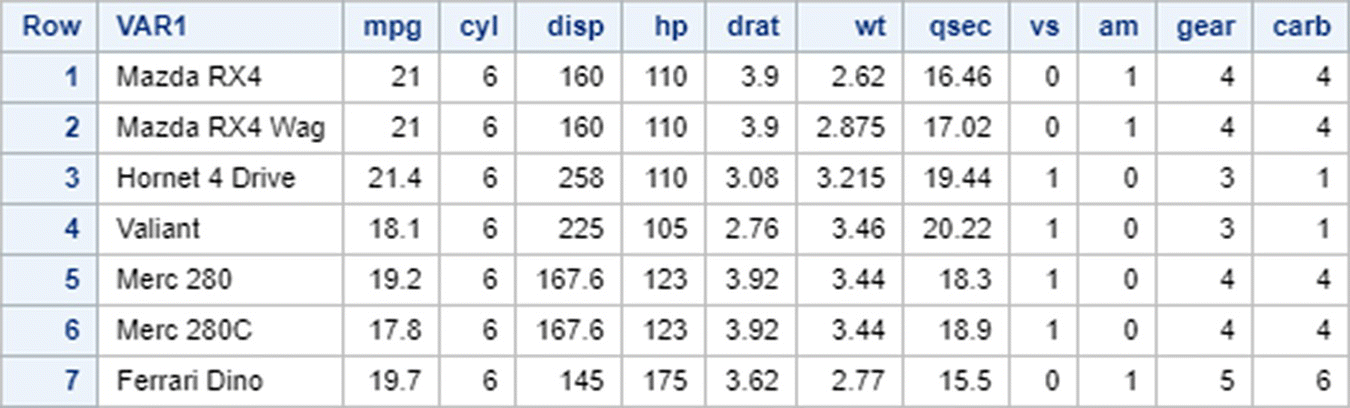
Sort/Order Data in SAS
In R
7.2.3 AND, OR, NOT in SQL
AND, OR, and NOT operators can be used along with the WHERE clause.
AND operator displays only those rows which meet all conditions in the WHERE clause.
OR operator displays those rows which meet at least one of the conditions in the WHERE clause.
NOT operator displays those rows which do not meet the condition specified in the WHERE clause.
In SAS:
To select only those rows from mtcars which have cyl=6 as well as gear=3
To select only those rows which have either carb = 1 or carb = 4
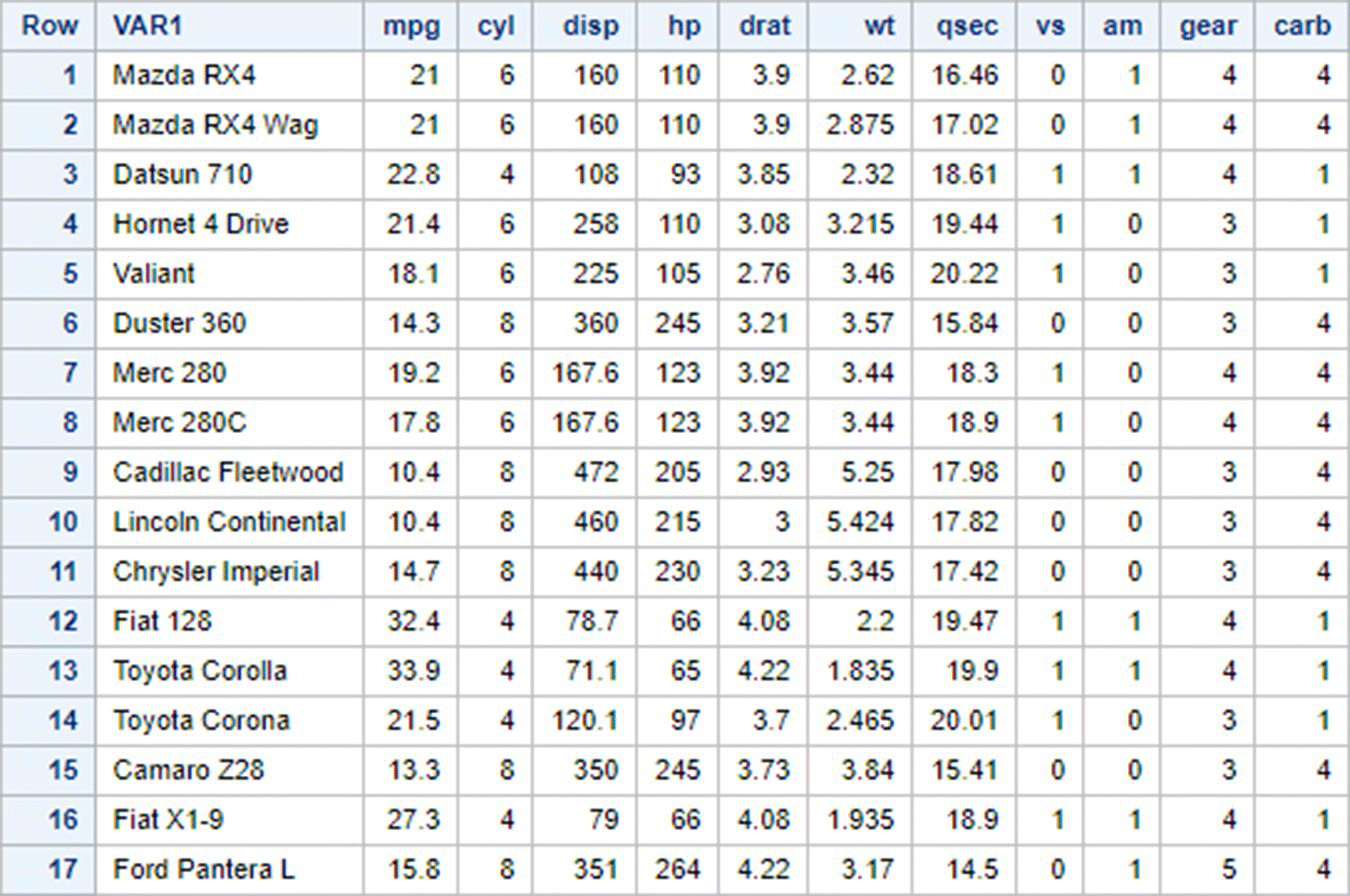
To select only and all those rows which do not have am=0:
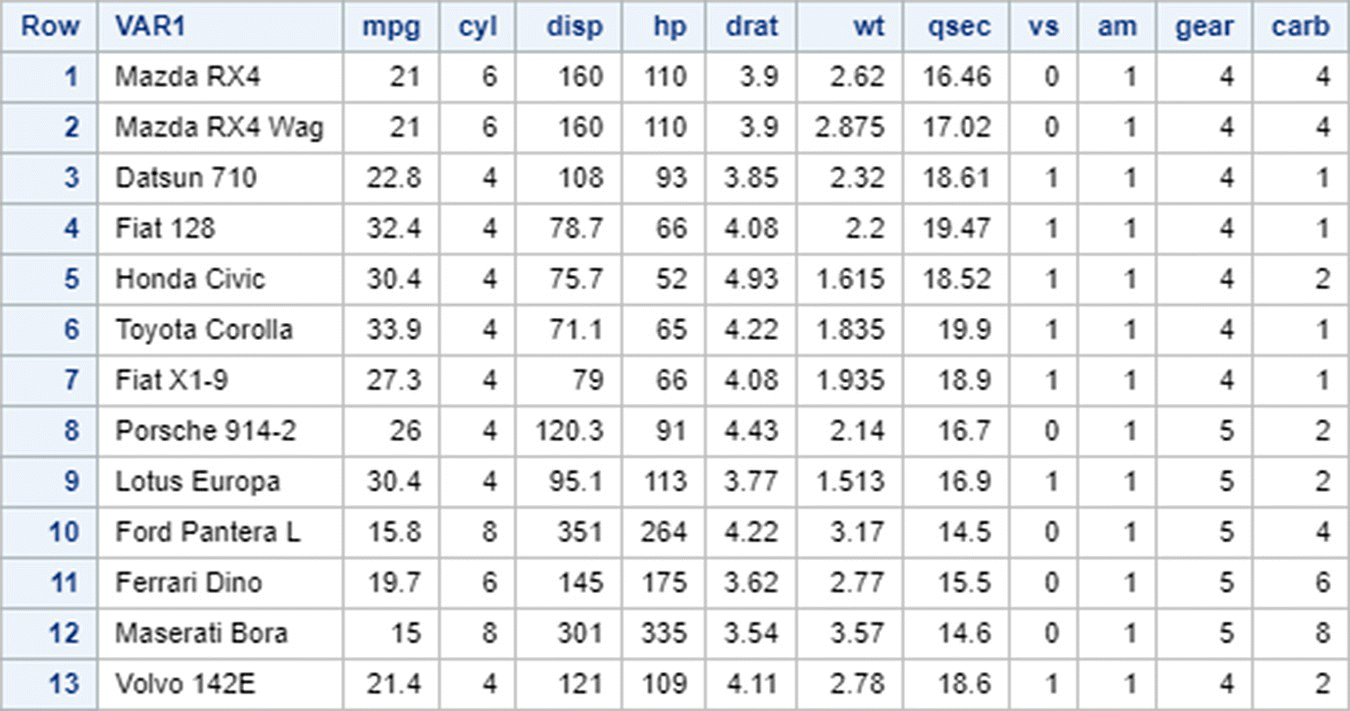
In R:
To select only those rows from mtcars which have cyl=6 as well as gear=3
To select only those rows which have either carb=1 or carb=4
To select only and all those rows which do not have am=0
7.2.4 SQL Select Distinct
We can select only the unique values of a column using the SELECT DISTINCT statement:
For example:
To know what the distinct values are that the variable gear takes in mtcars:‐
In SAS:
In R
7.2.5 SQL INSERT INTO
INSERT INTO statement is used to add rows to a data table.
- While using statements like INSERT INTO, ALTER TABLE, UPDATE which make changes to a data table in R, it is important to remember that sqldf() makes a copy of the data table provided to it, makes the required changes and returns the copy with the required changes.
- To make changes on the original data table, we need to assign the copy of the table returned by sqldf() to the object that stored the original copy.
- To use multiple SQL statements in sqldf(), we use the c() function.
- Proc Sql on the other hand makes the changes on the original copy itself.
To Insert a Row in SAS:
Note Var1 has taken the value of row.names from input R dataset.
To insert a row in mtcars in R:
Note the use of c() function and that we have assigned the result of sqldf ()to mtcars. Also note the output has 33 rows instead of the initial 32 with the new row having the input values.
7.2.6 SQL Delete
The DELETE statement is used along with WHERE to conditionally delete rows.
In SAS:
| Obs | VAR1 | mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb |
| 1 | Mazda RX4 | 21 | 6 | 160 | 110 | 3.9 | 2.62 | 16.46 | 0 | 1 | 4 | 4 |
| 2 | Mazda RX4 Wag | 21 | 6 | 160 | 110 | 3.9 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| 10 | Merc 280 | 19.2 | 6 | 167.6 | 123 | 3.92 | 3.44 | 18.3 | 1 | 0 | 4 | 4 |
| 11 | Merc 280C | 17.8 | 6 | 167.6 | 123 | 3.92 | 3.44 | 18.9 | 1 | 0 | 4 | 4 |
| 29 | Ford Pantera L | 15.8 | 8 | 351 | 264 | 4.22 | 3.17 | 14.5 | 0 | 1 | 5 | 4 |
| 30 | Ferrari Dino | 19.7 | 6 | 145 | 175 | 3.62 | 2.77 | 15.5 | 0 | 1 | 5 | 6 |
| 31 | Maserati Bora | 15 | 8 | 301 | 335 | 3.54 | 3.57 | 14.6 | 0 | 1 | 5 | 8 |
In R:
7.2.7 SQL Aggregate Functions
Aggregate functions perform a calculation on a set of values and return a single value. Some aggregate functions are min(),max(),avg.(),sum(),count() are:
Aggregate functions ignore missing values except count().
- min() gives the minimum value of the column.
- max() gives the maximum value of the column.
- avg.() gives the average value of the values in the column.
- sum() gives the sum of all values in the column.
- count() gives the number of non missing values in a column.
In SAS:
| Obs | _TEMG001 | _TEMG002 | _TEMG003 |
| 1 | 10.4 | 33.9 | 20.0906 |
Here, create table creates a new table mtcars2
In R:
7.2.8 SQL ALIASES
Aliases are used to give a temporary name. The AS clause is used with SELECT to do so.
In SAS:
In R:
7.2.9 SQL ALTER TABLE
ALTER TABLE is used to add, delete or modify column names in SAS.
ADD,DELETE,MODIFY are clauses that can be used with ALTER TABLE.
The new column added contains null values by default.
To make a new column in mtcars with the label ‘name’ and of type char.
In SAS:
| Variables in Creation Order | |||||
| # | Variable | Type | Len | Format | Informat |
| 1 | VAR1 | Char | 21 | $21. | $21. |
| 2 | mpg | Num | 8 | BEST12. | BEST32. |
| 3 | cyl | Num | 8 | BEST12. | BEST32. |
| 4 | disp | Num | 8 | BEST12. | BEST32. |
| 5 | hp | Num | 8 | BEST12. | BEST32. |
| 6 | drat | Num | 8 | BEST12. | BEST32. |
| 7 | wt | Num | 8 | BEST12. | BEST32. |
| 8 | qsec | Num | 8 | BEST12. | BEST32. |
| 9 | vs | Num | 8 | BEST12. | BEST32. |
| 10 | am | Num | 8 | BEST12. | BEST32. |
| 11 | gear | Num | 8 | BEST12. | BEST32. |
| 12 | carb | Num | 8 | BEST12. | BEST32. |
| 13 | name | Char | 8 | ||
In R:
7.2.10 SQL UPDATE
UPDATE is used to make changes to the rows of a table and is used with the SET and WHERE clause.
In SAS:
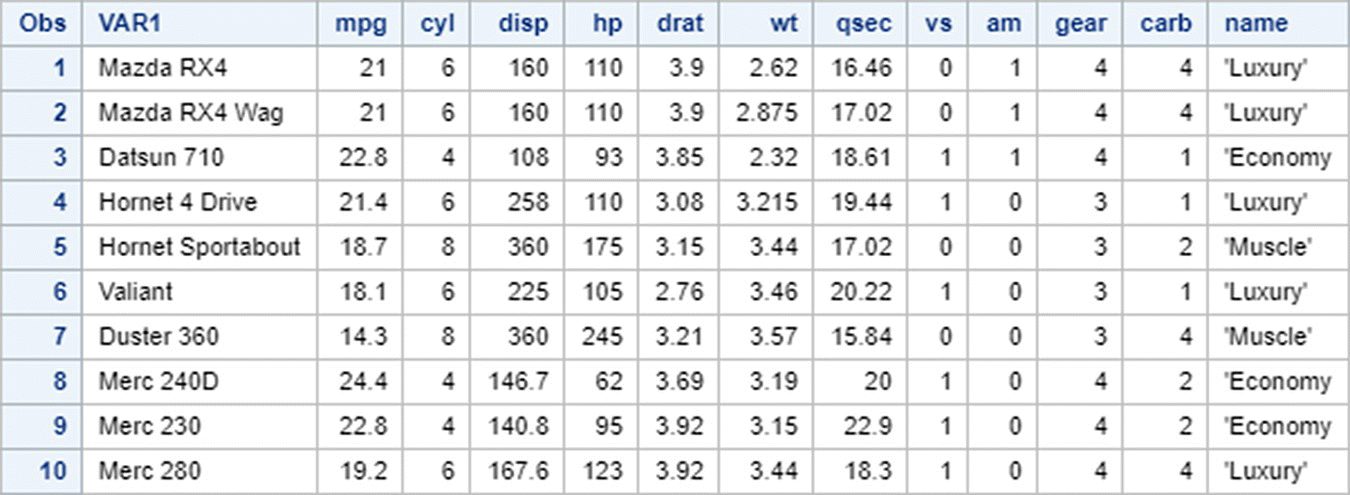
In R:
7.2.11 SQL IS NULL
Missing values in SQL are checked by IS NULL or IS NOT NULL. We take the airquality dataset from https://vincentarelbundock.github.io/Rdatasets/csv/datasets/airquality.csv
Example:
To select all rows with missing values in the Ozone column:of airquality:
In SAS (first we replace NA missing value of R with missing value in SAS using compress. We use outobs in Proc SQL to limit output to five rows.
In R:
7.2.12 SQL LIKE and BETWEEN
The LIKE option is used along with WHERE and wildcards like % and _ to select rows that have values with a specified pattern in a column:
- % is used to denote a string of characters
- _ is used to denote a single character.
In SAS:
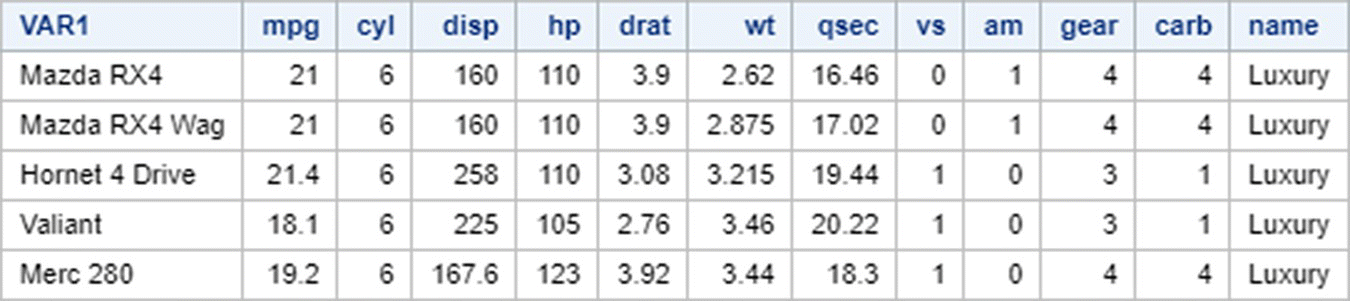
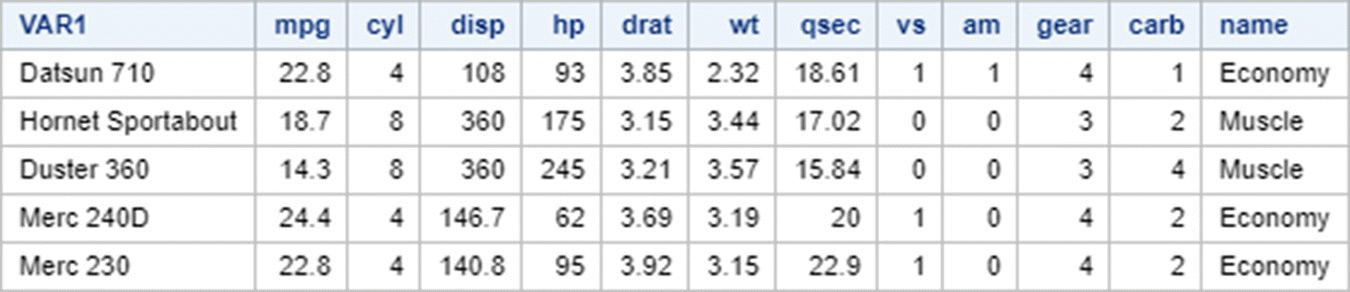
In R:
BETWEEN operator can also be used with WHERE as follows:
7.2.13 SQL GROUP BY
The GROUP BY statement is used with aggregate functions to calculate the corresponding values separately for all groups of a column. It is similar to the CLASS operator in PROC MEANS and group by operator in Hmisc in R and in data table. For multiple variables in R, we use llist in Hmisc::summarize and .(var1,var2) in data.table.
To calculate the average of mpg for each of the distinct values that cyl can take:
In SAS:
In R:
7.2.14 SQL HAVING
SQL HAVING
HAVING is used after GROUP BY to select only certain groups from the grouped aggregate values.
To display only those values of avg(mpg) grouped by cyl which have avg(mpg) >19 and sorted in ascending order of avg(mpg).
In SAS:
In R:
7.2.15 SQL CREATE TABLE and SQL CONSTRAINTS
CREATE TABLE clause can be used to create a table in SQL. NOT NULL and UNIQUE are CONSTRAINTS in SQL. They are used in front of the variable to specify that values in the user_id column cannot be missing and cannot be repeated respectively.
In SAS:
| Obs | user_id | Name | Age |
| 1 | 1 | John | 19 |
| 2 | 2 | Sarah | 20 |
| 3 | 3 | Jack | 21 |
Note: The string values have been truncated in proc sql.
In R:

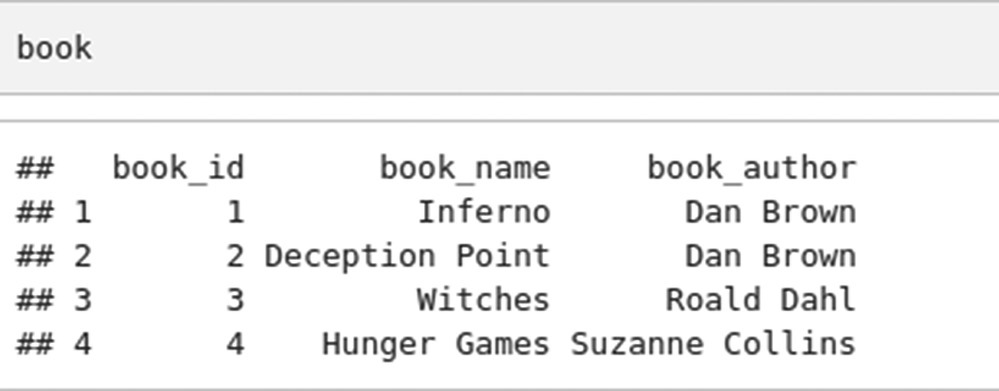
There is only one INSERT INTO statement is used in R and data values for multiple rows are separated by commas whereas the number of INSERT INTO statements needed in SAS equals the number of rows to be inserted.
PRIMARY KEY is another constraint in SQL which is used to uniquely identify a row in a table.
Columns with only the UNIQUE constraint can have null values whereas PRIMARY KEY columns cannot have null values. There can be several columns with UNIQUE constraint in a data table whereas there can be only one PRIMARY KEY column in a data table.
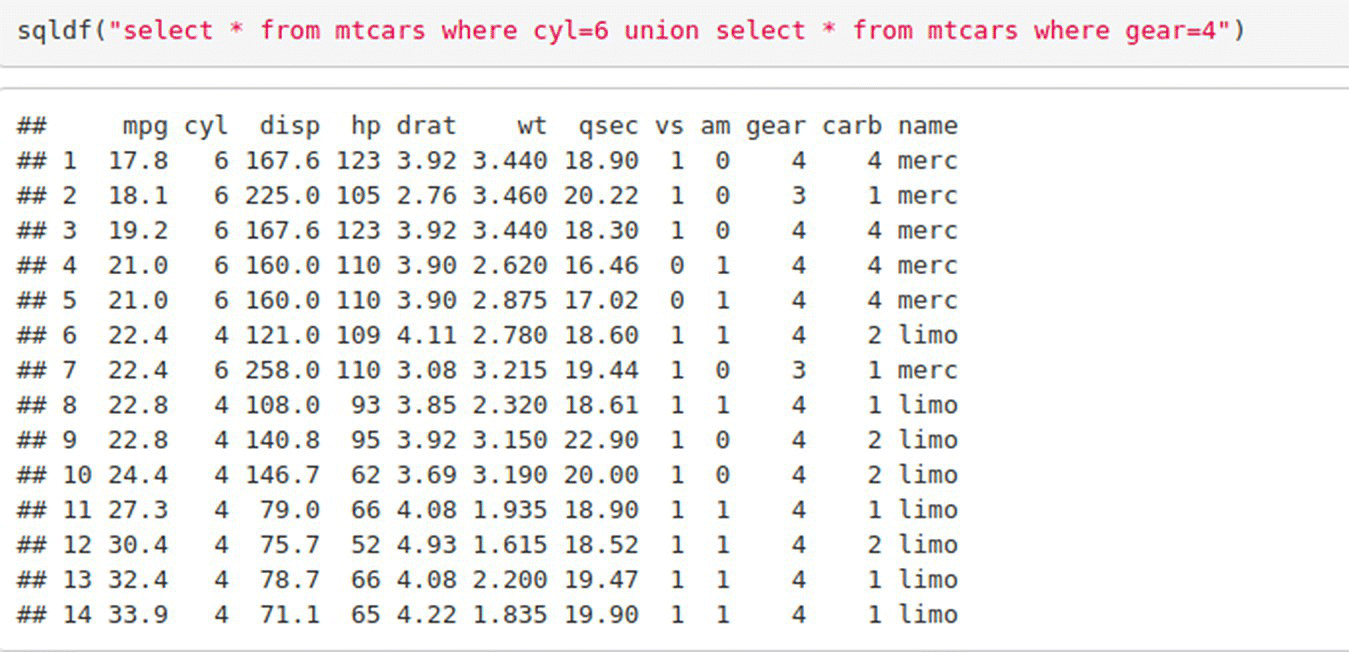
7.2.16 SQL UNION
UNION clause with select is used to select all observations which lie in at least one of the result sets. UNION ALL can be used to select the observations that lie in both the result sets twice along with the observations that lie in only one of them.
To select all observations which have either cyl=6 or gear=4 or both
In SAS:
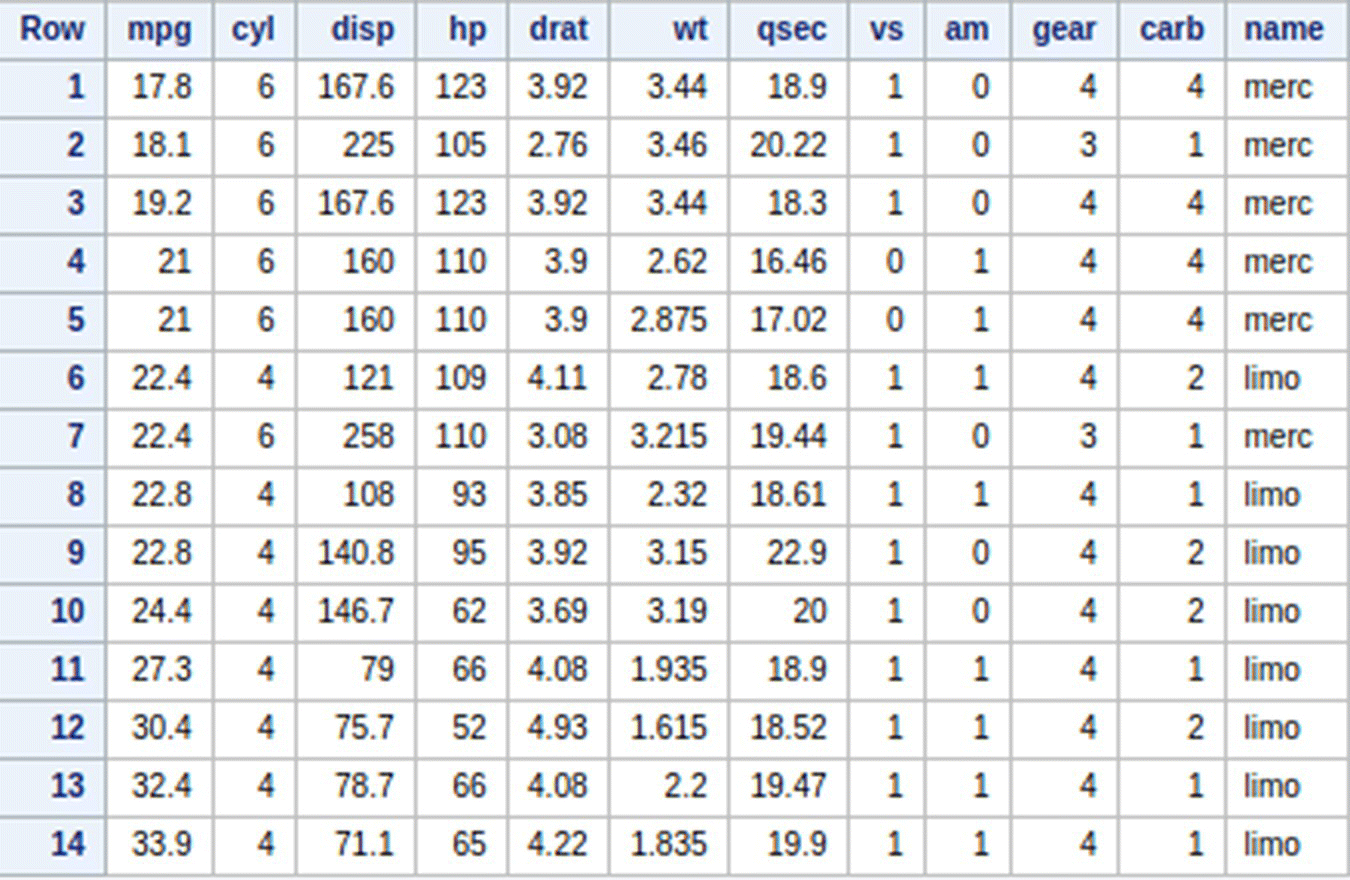
In R:
7.2.17 SQL JOINS
SQL JOINS can be used to merge data from more than one table into a single table.
INNER JOIN
Inner Join is used to select only those records that have the same value for a particular column.
LEFT JOIN
Left Join is used to select all records from the first table and those records from the second table which have common values in both tables for the specified column.
Let’s take these tables ‐issued, book and user.
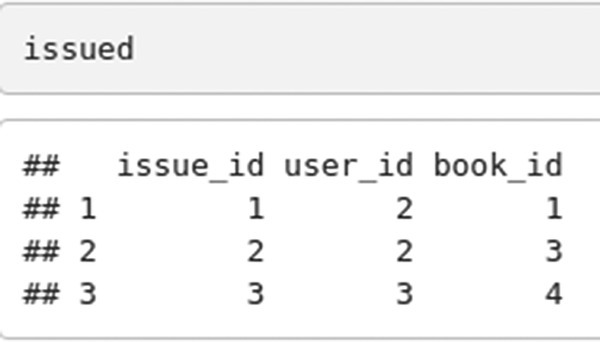
And book table.
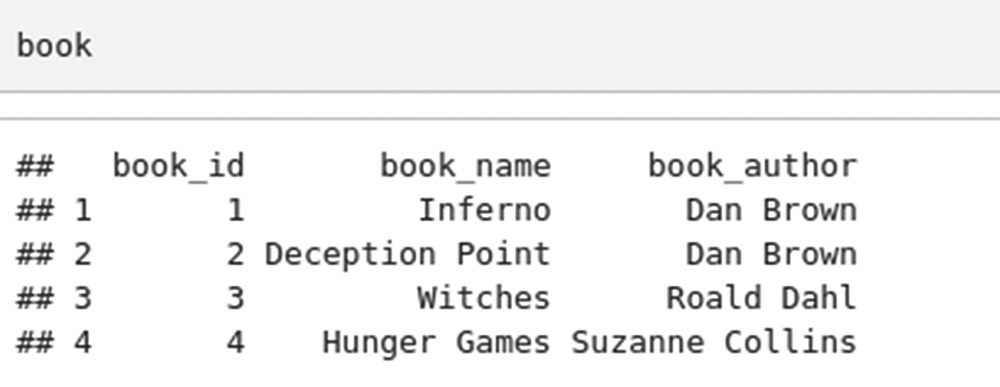
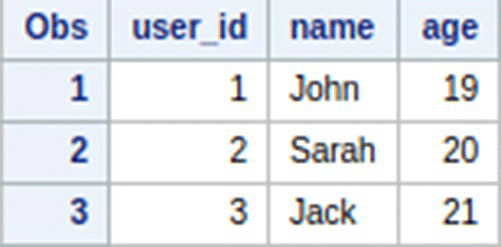
And
User
In SAS – Inner Join:
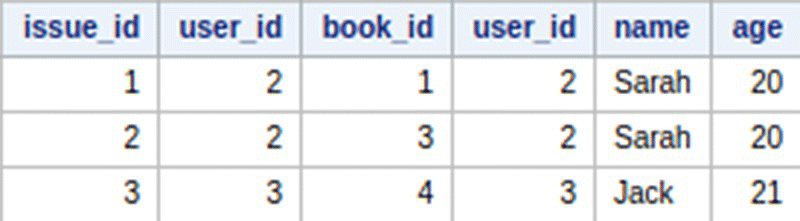
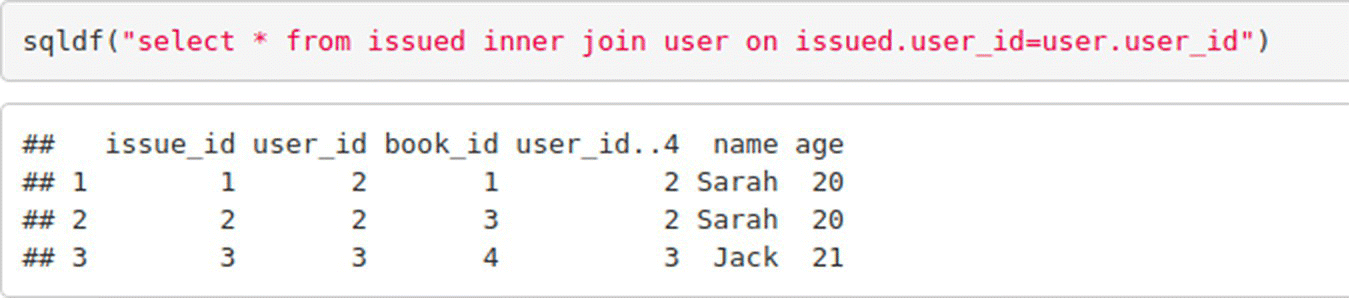
In SAS – Left Join:
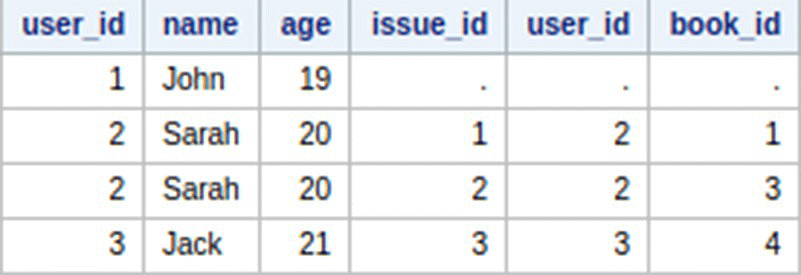
In R:
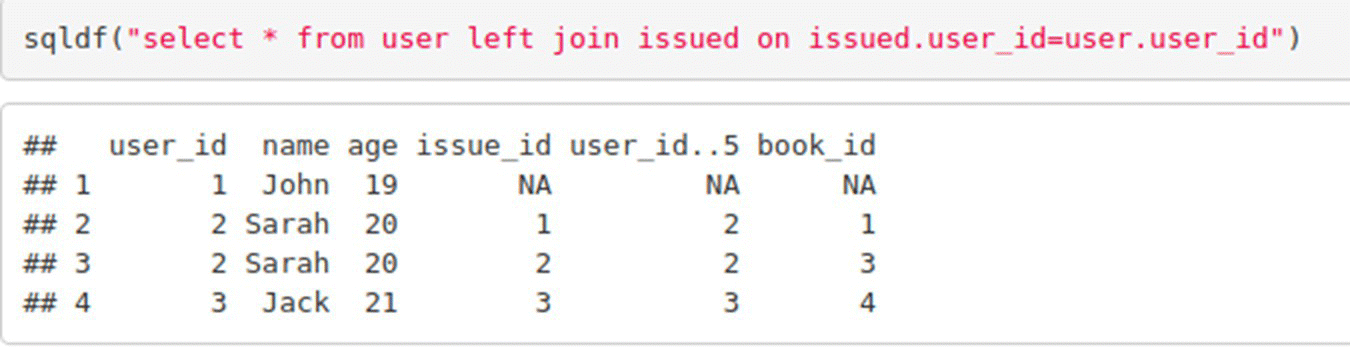
There are many types of JOINs in SQL:
- Inner Join:
- Full Outer Join:
- Left Outer Join:
- Right Outer Join:
- Self‐Join:
- Cross Join:
7.3 Merges
We use the merge function in both SAS and R and compare them with the SQL Joins. First, we make the tables in SAS and export the data to import it in R.
| Obs | book_id | book_name | book_author |
| 1 | 1 | Inferno | Dan Brow |
| 2 | 2 | Deceptio | Dan Brow |
| 3 | 3 | Witches | Roald Da |
| 4 | 4 | Hunger G | Suzanne |
| Obs | user_id | name | age |
| 1 | 1 | John | 19 |
| 2 | 2 | Sarah | 20 |
| 3 | 3 | Jack | 21 |
| Obs | issue_id | user_id | book_id |
| 1 | 1 | 2 | 1 |
| 2 | 2 | 2 | 3 |
| 3 | 3 | 3 | 4 |
We first use the libname statement to make the datasets permanent.
The all.x helps to create the create the left join here.
For other joins between two data frames d1 and d2.
7.4 Summary
SQL can be used in both R and SAS. We can use the sqldf package to use SQL in R and PROC SQL to use SQL in SAS.
The basic syntax for using sql in R is:
The basic syntax for using sql in SAS is:‐
SAS needs data to be sorted before merge. We can also merge data using joins.
7.5 Quiz Questions
- What does SQL stand for?
- Name a package that can be used to use SQL in R.
- Which proc statement is used to use SQL in SAS?
- Which function is used to combine multiple SQL queries in a single call to sqldf()?
- What is * used for in the following select statement?
- Which clause is used to add new values and make changes to a row of a table?
- Name some SQL constraints.
- What is HAVING used for in SQL?
- Name some SQL aggregate functions.
- Explain the difference between INNER JOIN and LEFT JOIN in SQL.
Quiz Answers
- Structured Query Language
- sqldf
- PROC SQL
- c()
- * is used to select all columns from a data table.
- Sql UPDATE is used to make changes to the rows of a table and is used with the SET and WHERE clause.
- NOT NULL, Unique, Primary Key.
- HAVING is used after GROUP BY to select only certain groups from the grouped aggregate values.
- min(),max(),avg.(),sum(),count() are some SQL aggregate functions.
- INNER JOIN is used to select only those records which have matching values in the specified column whereas LEFT JOIN selects all records from the first table along with the records which have matching values in the specified column.