
This chapter deals with SQLite administration topics. We will look at how the database parameters can be adjusted with the PRAGMA command and discuss ways to back up and restore your database. We will also examine some of the database internals that will help you to gain a better understanding of the SQLite engine.
The PRAGMA command provides an interface to modify the operation of the SQLite library and perform low-level operations to retrieve information about the connected database.
This section describes the set of PRAGMA directives that allows you to find information about the currently attached databases.
PRAGMA database_list;
One row is returned for each open database containing the path to the database file and the name that the database was attached with. The first two rows returned will be the main database and the location in which temporary tables are stored.
A PRAGMA command can be executed from the sqlite program as well as through any of the language APIs—after all, the sqlite program is just a simple front end that passes typed commands to the C/C++ interface and uses a choice of callback function, selected using .mode, to output the rows to screen.
The following example shows the result of executing PRAGMA database_list through the sqlite program after a second database has been attached to the session:
sqlite> ATTACH DATABASE db2 AS db2; sqlite> PRAGMA database_list; seq name file 0 main /home/chris/sqlite/admin/db1 1 temp /var/tmp/sqlite_6x5rZ2drAEtVpzj 2 db2 /home/chris/sqlite/admin/db2
If executed from a language interface, the pseudo-table returned by this pragma contains columns named seq, name, and file.
To find information about a database table, use the table_info pragma with the following syntax:
PRAGMA table_info(table-name);
The table-name argument is required and can refer only to a table in the main database, not one attached using ATTACH DATABASE. One row is returned for each column in that table, containing the columns shown in Table 10.1.
Table 10.1. Columns in the Pseudo-Table Returned by PRAGMA table_info
| An integer column ID, beginning at zero, that shows the order in which columns appear in the table. |
| The name of the column. The capitalization used in the |
| The data type of the column, taken verbatim from the |
| If the column was declared as |
| Contains the |
| Will be 1 for the column(s) making up the |
To find information about the indexes on a table, use the index_list and index_info pragmas as follows:
PRAGMA index_list(table-name); PRAGMA index_info(index-name);
PRAGMA index_list causes one row to be returned for each index on the given table-name with the columns shown in Table 10.2.
Table 10.2. Columns in the Pseudo-Table Returned by PRAGMA index_list
| An integer beginning at zero that indicates the order in which the indexes were added to the table. |
| The name of the index. This is the identifier given in a |
| Will be 1 if the index was declared as |
When you know the name of an index, PRAGMA index_info can be used to find out which column or columns make up that index. A single column index will return a single row, whereas a clustered index will return one row for each indexed column, in the relevant order. The columns returned are shown in Table 10.3.
Table 10.3. Columns in the Pseudo-Table Returned by PRAGMA index_info
| An integer beginning at zero that indicates the sequence of the columns in the index |
| The |
| The name of the indexed column |
When an index is created implicitly by the use of a UNIQUE or PRIMARY KEY constraint in the CREATE TABLE statement, the index will take an automatically assigned name of the form (table-name autoindex num). The following example shows these pragmas being run for a table with both explicit and implicit index names:
sqlite> CREATE TABLE mytable ( ...> col1 INTEGER NOT NULL, ...> col2 CHAR NOT NULL, ...> col3 INTEGER UNIQUE, ...> col4 CHAR, ...> PRIMARY KEY (col1, col2) ...> ); sqlite> CREATE INDEX col4_idx ON mytable(col4); sqlite> PRAGMA index_list(mytable); seq name unique ---- ------------------------------ ------ 0 col4_idx 0 1 (mytable autoindex 2) 1 2 (mytable autoindex 1) 1 sqlite> PRAGMA index_info('(mytable autoindex 2)'), seqno cid name ----- ---- ---------- 0 0 col1 1 1 col2
This section describes the set of PRAGMA directives that enables you to adjust certain database parameters for the purposes of performance tuning at the overall database level. The first parameter that can be adjusted is cache_size.
PRAGMA cache_size;
This instruction will return the maximum number of database disk pages that will be held in memory at once. The default value of 2000 pages equates to around 3000KB of memory—each page taking up approximately 1.5KB.
The same PRAGMA can be used to set a new cache size by assigning a value as follows:
PRAGMA cache_size = num-pages;
Increasing the cache size can improve performance if the SQL operations you are executing would use a larger amount of memory than the size of the cache. For instance, an UPDATE operation on a large number of rows would benefit from a larger cache size. Keeping a limit on the cache size ensures that SQLite's memory usage remains under your control.
The cache_size can be altered dynamically, so if one query in your application in particular can benefit from a larger number of pages being cached, you can increase the size for that query and drop it back down afterwards.
The temp_store pragma allows the location used for the temporary database to be queried or changed.
PRAGMA temp_store;
PRAGMA temp_store = value;
The value of temp_store can be one of the constants DEFAULT, MEMORY, or FILE, which have the values 0, 1, and 2 respectively. The values indicate whether SQLite should store temporary database objects in memory or to disk. The DEFAULT value is set at compile time and unless you have changed it, it will be FILE.
Using in-memory databases for temporary tables can produce significant performance savings if your application can afford the additional memory usage.
The synchronous pragma allows the synchronous flag for the current database session to be queried or changed.
PRAGMA synchronous;
PRAGMA synchronous = value;
The value can be OFF, NORMAL, or FULL, which have the values 0, 1, and 2 respectively.
In synchronous mode FULL or NORMAL, SQLite will pause periodically to make sure data has been written to the disk before carrying on with the next operation. FULL mode is very safe and ensures that after a system crash for any reason, even unrelated to SQLite, the database will not be corrupt.
Because FULL synchronous is very slow, NORMAL mode is used more often. SQLite still pauses to check at critical moments, but there is a small chance that an operating-system crash or power failure at the wrong time could cause corruption of the database file.
When synchronous is OFF, SQLite does not pause to check that data has been written to disk. This mode is very fast—some operations have been clocked at 50 times faster than NORMAL mode—however, the chance of data loss is greater because it relies on the operating system to ensure that data has been written. Setting synchronous=OFF can give some major performance benefits, but you should give careful consideration to the potential consequences.
A good time to turn synchronous OFF is when populating a large database for the first time. In this situation, the risk of corruption is not critical because the population process could be restarted from a known point in the event of a failure.
Note
NORMAL mode is used by default, even though there is a small chance of data loss, for performance reasons. In reality, the kind of system crash that would cause your database to become corrupt is likely to carry with it other, more serious problems such as hardware failure, so NORMAL mode is considered acceptable for everyday use.
Changes made in the way shown in the preceding section will persist only until the current database session is closed. To change a database parameter permanently, the same PRAGMA directives can be called with a default_ prefix to query and set the value that is stored in the database file.
To query the current default cache size of the attached database, use the following instruction:
PRAGMA default_cache_size;
To increase the cache size for that database to 4000 pages permanently, the command would be
PRAGMA default_cache_size = 4000;
The same prefix can be applied to give default_temp_store and default_synchronous pragmas to query or set the permanent values of temp_store and synchronous respectively.
Though it can now be done using the sqlite_changes() function call, the traditional method of counting changes made to the database as a result of an INSERT, UPDATE, or DELETE operation was to use the count_changes PRAGMA. This PRAGMA is likely to be removed from future versions of SQLite in favor of sqlite_changes(), so it is included here only for historical value.
PRAGMA count_changes = ON; PRAGMA count_changes = OFF;
When count_changes is set to ON, a single row is returned whenever an operation is performed that modifies the database containing the number of affected rows. The following example shows this in action using the sqlite program:
sqlite> PRAGMA count_changes = ON; sqlite> UPDATE contacts SET first_name = upper(first_name); 4 sqlite> DELETE FROM contacts WHERE first_name = 'CHRIS'; 1
Unless you are working with legacy code that uses count_changes, there is a small performance gain to be had by leaving this pragma turned off.
Note
The examples in this chapter use ON or OFF as the Boolean argument where one is required. ON, TRUE, and YES are equivalent to a value of 1, whereas OFF, FALSE, and NO are equivalent to zero.
The column names passed to the callback function in the C/C++ interface as columnNames—also used in other language APIs to identify the name of the column returned—are usually just the names of the columns, with a table prefix used only where a join has taken place. Use the full_column_names pragma to force SQLite to report a column name as table.column, even when only one table has been queried.
PRAGMA full_column_names = ON;
The following output shows an example of this in the sqlite monitor program—the column headings now include the table name:
sqlite> PRAGMA full_column_names = ON; sqlite> SELECT first_name, last_name FROM contacts; contacts.first_name contacts.last_name ------------------- ------------------ CHRIS NEWMAN PADDY O'BRIEN TOM THOMAS BILL WILLIAMS JO JONES
The columnNames parameter to the callback function will always contain the names of the columns selected in elements numbered from zero to argc–1, but this array can be extended to also include the data types specified in the CREATE TABLE statement.
PRAGMA show_datatypes = ON;
Where no data type was specified in the CREATE TABLE statement, it is reported as NUMERIC. Expressions evaluated in a query are reported as either NUMERIC or TEXT depending on the expression itself.
The example in Listing 10.1 shows how the show_datatypes pragma can be used to view the data types of both database columns and evaluated expressions.
Example 10.1. Using PRAGMA show_datatypes to Find the Data Types of Columns and Expressions
#include <stdio.h>
#include <sqlite.h>
int callback(void *pArg, int argc, char **argv, char **columnNames)
{
int i;
for (i=0; i<argc; i++) {
printf("%-20s %-8s %s
",
columnNames[i], columnNames[i+argc], argv[i]);
}
return(0);
}
int main()
{
char *errmsg;
int ret;
sqlite *db = sqlite_open("db1", 0777, &errmsg);
if (db == 0)
{
fprintf(stderr, "Could not open database: %s
", errmsg);
sqlite_freemem(errmsg);
return(1);
}
ret = sqlite_exec(db,
"SELECT id, first_name, id+2, upper(first_name) "
"FROM contacts LIMIT 1", callback, NULL, &errmsg);
if (ret != SQLITE_OK)
{
fprintf(stderr, "SQL error: %s
", errmsg);
}
sqlite_close(db);
return(0);
}
The resulting output shows that the column types of the database columns are as they were declared in the CREATE TABLE statement, but the expressions revert to one of the internal data types, NUMERIC or TEXT.
$ ./listing10.1
id INTEGER 1
first_name CHAR Chris
id+2 NUMERIC 3
upper(first_name) TEXT CHRIS
An integrity check can be performed on the entire database with the integrity_check pragma. It is simply issued as follows:
PRAGMA integrity_check;
The check searches for corrupt indexes, malformed records, and other such problems. Any issues are returned as a single string or if there are no problems, a single string ok is returned. The response you would hope to see is
sqlite> PRAGMA integrity_check;
ok
The parser_trace pragma turns ON or OFF internal tracing of the SQLite parser stack and, when ON, returns one row for each step of the parser trace. To use this feature, SQLite must have been compiled without the NDEBUG compile time option.
The following example shows the first few lines of output from the parser trace for a simple SELECT statement. As you can see, it is not desirable to have this output turned on unless you are looking for a particular problem with the parser code—there were 108 lines of output in total, just for this simple query!
sqlite> PRAGMA parser_trace=ON; sqlite> SELECT first_name, last_name FROM contacts; parser: Input SELECT parser: Reduce [explain ::=]. parser: Shift 3 parser: Stack: explain parser: Shift 73 parser: Stack: explain SELECT parser: Input ID parser: Reduce [distinct ::=]. parser: Shift 74 parser: Stack: explain SELECT distinct parser: Reduce [sclp ::=]. parser: Shift 289 parser: Stack: explain SELECT distinct sclp parser: Shift 64 parser: Stack: explain SELECT distinct sclp ID parser: Input COMMA parser: Reduce [expr ::= ID]. parser: Shift 290 [...]
Similarly, tracing can be enabled at the Virtual Database Engine level using the vdbe_trace pragma. One row is returned for each VDBE opcode in the trace, which gives a result very similar to that obtained by the EXPLAIN command.
sqlite> PRAGMA vdbe_trace=ON; sqlite> DELETE FROM contacts; 0 Transaction 0 0 1 VerifyCookie 0 3 2 Transaction 1 0 3 Clear 3 0 4 SetCounts 0 0 5 Commit 0 0 6 Halt 0 0
We will examine the VDBE opcodes in more detail later in this chapter.
It is, of course, essential to back up your data regularly. SQLite stores databases to the filesystem, so backing up your databases can be as easy as taking a copy of the database files themselves and putting them somewhere safe.
However, if you are copying the database file, can you be sure that it is not being written to at the time you issue the copy command? If there's even a small chance that a SQLite write operation could happen during the copy, you should not use this method to back up your database to ensure that data corruption cannot occur.
SQLite implements locking at the database level using a lock on the database file itself, which works to the extent that other processes using the SQLite library know when the database is being written to. Many processes can read from a database at the same time; however, a single writer process locks the entire database, preventing any other read or write operation taking place.
On Windows platforms, if SQLite has locked the file the operating system will acknowledge the lock and will not allow you to copy the file until SQLite is done with it. Likewise the copy operation will lock the database file so that SQLite cannot access it. However, on Unix systems, file locks are advisory—in other words they tell you that the file is locked if you care to check, but do not otherwise prevent access. Therefore it is entirely possible to initiate a cp command while SQLite has a database file locked for writing.
The .dump command in sqlite provides a simple way to create a backup file in the form of a list of SQL statements that can be used to re-create the database from scratch. The CREATE TABLE statements are preserved and one INSERT command is written for each row of data in the table.
Note
Because the .dump command is part of an application that uses the SQLite library, there are no issues with file locking to worry about. If the database is locked at the moment you attempt to fetch the rows from the database, the busy handler will be invoked, which, in sqlite, is to wait for the specified timeout before returning an error message.
A backup operation can therefore be performed as follows:
$ sqlite dbname .dump > backup.sql
Future restoration from the generated backup.sql is simple:
$ sqlite dbname < backup.sql
You can optionally pass a table name to .dump to extract only the schema and records for that table. The following example shows the dump file produced for the contacts table:
$ echo '.dump contacts'| sqlite db1 BEGIN TRANSACTION; CREATE TABLE contacts ( id INTEGER PRIMARY KEY, first_name CHAR, last_name CHAR, email CHAR); INSERT INTO contacts VALUES(1,'Chris','Newman','[email protected]'), INSERT INTO contacts VALUES(2,'Paddy','O''Brien','[email protected]'), INSERT INTO contacts VALUES(3,'Tom','Thomas','[email protected]'), INSERT INTO contacts VALUES(4,'Bill','Williams','[email protected]'), INSERT INTO contacts VALUES(5,'Jo','Jones','[email protected]'), COMMIT;
Note that the INSERT statements generated do not contain a column list before the VALUES keyword. If you are using the .dump output to restore a table exactly as it used to be, this is no problem; however, you cannot alter the table schema in the CREATE TABLE statement without also modifying every INSERT in the extract file.
The .dump command can act as a handy workaround for the lack of ALTER TABLE command in SQLite if you are able to adjust the INSERT commands accordingly. The following example uses sed to change the SQL commands to full inserts so that you can go ahead and add columns to the CREATE TABLE statement to re-create the database from this file with the new schema.
$ echo .dump | sqlite dbname | sed –e 's/VALUES/(id,first_name,last_name,email) VALUES/g' > backup.sql
Whether you decide to use .dump for regular backups or to simply copy the database file itself will depend on several factors. The output from .dump is often smaller than the SQLite database file and will certainly compress much smaller using gzip or some similar utility.
However, restoring from an SQL file can take some time, particularly if there are a lot of indexes to be rebuilt after the data has been loaded. As a backup should be as quick and easy to restore as possible, copying the SQLite database file may be the correct choice.
Using .dump is a better choice for a long-term archive of old data. Although there is, in theory, no reason that the same version of SQLite will not be available several years from now, you might actually want to load your archived data into a newer version of SQLite or even some other database system. The SQL output file produced by .dump will be fairly portable.
In this section we'll take a look under the hood of SQLite to see how the command process works and to examine the internals of the Virtual Database Engine (VDBE). Though it is not essential to know what goes on behind the scenes, a little insight into how the SQLite engine processes your queries can help you understand SQLite better, and if you want to gain a deeper knowledge of how SQLite is implemented, you will learn the roles of the different source code files.
Let's begin by looking at the steps SQLite goes through in order to process a query. Figure 10.1 shows a diagram of the flow of information between submitting a query for processing and the output being returned.
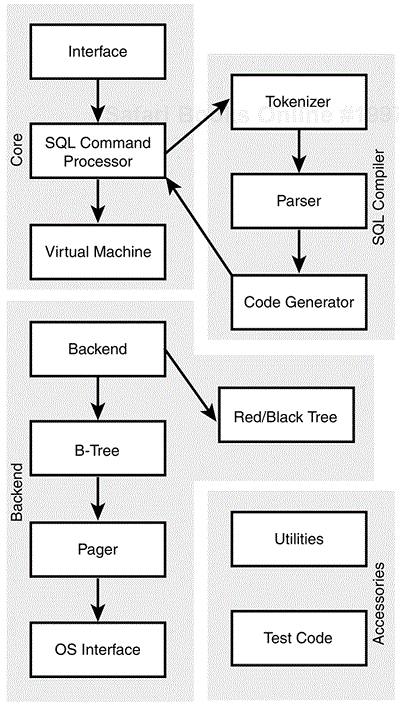
The interface is the C library through which all SQLite processing is programmed. Even if you are using a different language API, at a lower level it is implemented using the C library. The core interface is defined in the main.c file of the SQLite source distribution. A few other files contain ancillary functions; for instance, printf.c contains sqlite_mprintf() and its derivatives.
After a command is received through the interface, it is passed into the SQL Command Processor, which consists of three separate steps.
The tokenizer handles the process of breaking up a character string containing SQL statements into tokens that can be understood by the parser. Each individual component of the SQL language is a token—each combination of characters that forms a keyword or identifier and each symbol or sequence of symbols that forms an operator.
SQLite uses the Lemon LALR(1) parser generator, which is probably not already on your system, so the SQLite source code is distributed with the entire Lemon source code in a single file as tool/lemon.c. Though it does much the same job as BISON or YACC, Lemon was chosen for its ability to generate a parser that is thread-safe and less prone to memory leaks.
The source file parse.y contains the grammar definition for SQLite's implementation of SQL. Lemon reads this file and generates a corresponding C-language file for the actual parser.
There is a document giving an introduction to the Lemon parser at http://www.hwaci.com/sw/lemon/lemon.html.
The parser assembles the tokenized SQL components into statements, checking that its syntax is valid before calling the Code Generator to produce virtual machine code that will do the actual work of executing the SQL statement. We'll look at the way the virtual machine works shortly.
Many SQL statements have their own source code file to handle the conversion to virtual machine code. For instance, select.c, insert.c, update.c, and delete.c deal with SELECT, INSERT, UPDATE, and DELETE statements respectively. The WHERE clause is processed by where.c, and code to evaluate expressions is generated by expr.c.
The virtual machine implements an abstract computing engine for the specific purpose of manipulating database files. The virtual machine itself can be found in the source code files vdbe.c, and various utilities used to compile SQL statements to VDBE opcodes are contained in vdbeaux.c.
SQLite uses an abstraction layer between the virtual machine and the low-level storage and retrieval routines, implemented as a B-tree, page cache, and OS interface.
The database is stored to disk using a B-tree layer—a balanced tree structure that provides fast data access by minimizing the number of disk reads required to access a particular piece of information. The implementation and interface to SQLite's B-tree subsystem can be found in btree.c and btree.h.
Each table and index in the database is written using a separate B-tree though, as we have already seen, all the B-trees are stored in a single file on disk.
The B-tree storage mechanism requests data from the disk in 1KB chunks. The pager layer implements a page caching system that handles the reading, writing, and caching of these chunks, including the rollback and commit operations needed to implement atomic transactions.
The pager implementation and its interface can be found in pager.c and pager.h respectively.
For portability between different platforms, SQLite has implemented an abstraction layer that interfaces with the underlying operating system.
The file os.c contains routines that deal with low-level filesystem access on Windows and Unix. The definitions are contained in preprocessor ifdef instructions to ensure that the relevant interface is built into SQLite at compile time.
The VDBE's machine language contains more than 100 opcodes, defined in vdbe.c, that are used to handle every possible database operation. We will look at how a few common operations are translated into opcodes and use the vdbe_trace pragma to walk through the command execution process.
Each instruction in the virtual machine is made up of an opcode and between zero and three operands. The first operand, named P1, must be an integer. P2 is also an integer but must be non-negative. P2 will always contain the jump destination for an operation that may cause a jump. P3 can be either a NULL-terminated string, or simply NULL.
To see SQL commands converted to VDBE opcodes as they are executed from the sqlite program, begin by turning on the vdbe_trace pragma. To use this feature, SQLite must have been compiled without the NDEBUG compile time option.
sqlite> PRAGMA vdbe_trace=ON;
0 Halt 0 0
Immediately we see some VDBE trace output, although not a lot has happened for it to trace just yet. The zero at the start of the line is the instruction number—as we'll see shortly, lines from the trace are numbered to indicate the sequence of operation—followed by the Halt opcode with operands P1 and P2 both zero.
The Halt opcode instructs the VDBE to exit immediately, tidying up any incomplete operations. We will always see the Halt instruction at the end of every command trace.
P1 will contain the return code, which is usually SQLITE_OK, which is defined with a value of zero. The full list of return codes can be found in Appendix E, “C/C++ Interface Reference.”
When P1 is non-zero, the return code indicates an error has occurred and the value of P2 tells the virtual machine whether to roll back the current transaction. The values OE_Fail, OE_Rollback, and OE_Abort—defined in sqliteInt.h—will cause the transaction to be saved, rolled back, or aborted.
A different set of operands to Halt would be seen if we violate a database constraint, for instance. The following operation was the final trace step of a command that attempted to insert a duplicate value into a PRIMARY KEY column:
14 Halt 19 2 column id is not unique
Here P1 has a value of 19, which represents a return code of SQLITE_CONSTRAINT and P2 has a value of OE_Abort (2). Additionally, P3 contains a textual error message indicating the SQL error that caused this constraint to be violated.
Let's look at a very simple SELECT statement that evaluates an expression without using any database table. The following trace output shows the VDBE opcodes along with the values on the stack as the operation takes place:
sqlite> SELECT 2+3 AS result;
0 ColumnName 0 1 result
1 ColumnName 1 0 NUMERIC
2 Integer 2 0 2
Stack: si:2
3 Integer 3 0 3
Stack: si:3 si:2
4 Add 0 0
Stack: i:5
5 Callback 1 0
5
6 Halt 0 0
The first two opcodes on lines 0 and 1 are both ColumnName and contain the name and data type of the result column respectively. P1 is the number of the column, beginning at zero, for which the name in P3 is being assigned. P2 has a value of 1 to indicate the last column in the result. Remember that, with the show_datatypes pragma on, the data types are passed to the callback as later column index numbers in the result set.
The Integer opcode causes the integer value of P1 to be pushed onto the stack. P3 contains a string representation of the same integer. After line 2 the stack trace shows si:2, where si indicates that the value was placed onto the stack as both a string and an integer.
After line 3 the stack contains the values from both sides of the addition operator, and then the Add operation is performed. Add does not take any operands; it pops the top two elements from the stack, adds them together, and pushes the result back onto the stack. After this operation we can see that indeed the stack contains the value 5; however, this time it is shown as i:5 as the Add opcode has created only an integer result.
With the hard work done, the Callback opcode is called. Callback pops P1 values off the stack and invokes the callback function with an array of those values passed as the argv parameter.
The remainder of the trace shows the output of the callback function and a normal Halt operation.
Adding two integers isn't a complex operation, but it still has to be converted to VDBE opcodes in order to be evaluated by SQLite.
Let's look at an example of a database operation next. Listing 10.2 contains the virtual machine program code generated by the EXPLAIN command for a SELECT query that fetches two columns from the contacts table using an equality condition in the WHERE clause.
Example 10.2. Virtual Machine Program Generated by EXPLAIN
sqlite> .explain sqlite> EXPLAIN ...> SELECT first_name, last_name ...> FROM contacts ...> WHERE first_name = 'Chris'; addr opcode p1 p2 p3 ---- ------------ ---------- ---------- ----------------------------------- 0 ColumnName 0 0 first_name 1 ColumnName 1 1 last_name 2 ColumnName 2 0 CHAR 3 ColumnName 3 0 CHAR 4 Integer 0 0 5 OpenRead 0 4 contacts 6 VerifyCookie 0 3603 7 Rewind 0 15 8 Column 0 1 9 String 0 0 Chris 10 StrNe 1 14 11 Column 0 1 12 Column 0 2 13 Callback 2 0 14 Next 0 8 15 Close 0 0 16 Halt 0 0
Although EXPLAIN shows the complete program code that would be executed for a given SQL statement, the statement is not executed. However, the vdbe_trace pragma produces its response while the query is being executed. The trace shows the commands as they are executed, and any jumps that alter the flow of the program result in corresponding jumps in the trace output.
Listing 10.2 shows the VDBE trace for the same query featured in Listing 10.1. The operation numbers are the same in both listings so that you can compare the lines in the trace to the complete virtual machine code.
sqlite> PRAGMA vdbe_trace=on; sqlite> SELECT first_name, last_name ...> FROM contacts ...> WHERE first_name = 'Chris'; 0 ColumnName 0 0 first_name 1 ColumnName 1 1 last_name 2 ColumnName 2 0 CHAR 3 ColumnName 3 0 CHAR 4 Integer 0 0 Stack: i:0 5 OpenRead 0 4 contacts 6 VerifyCookie 0 3455 7 Rewind 0 15 8 Column 0 1 Stack: s[Chris] 9 String 0 0 Chris Stack: t[Chris] s[Chris] 10 StrNe 1 14 11 Column 0 1 Stack: s[Chris] 12 Column 0 2 Stack: s[Newman] s[Chris] 13 Callback 2 0 Chris|Newman 14 Next 0 8 8 Column 0 1 Stack: s[Paddy] 9 String 0 0 Chris Stack: t[Chris] s[Paddy] 10 StrNe 1 14 14 Next 0 8 8 Column 0 1 Stack: s[Tom] 9 String 0 0 Chris Stack: t[Chris] s[Tom] 10 StrNe 1 14 14 Next 0 8 8 Column 0 1 Stack: s[Bill] 9 String 0 0 Chris Stack: t[Chris] s[Bill] 10 StrNe 1 14 14 Next 0 8 8 Column 0 1 Stack: s[Jo] 9 String 0 0 Chris Stack: t[Chris] s[Jo] 10 StrNe 1 14 14 Next 0 8 15 Close 0 0 16 Halt 0 0
In operation 5, the OpenRead opcode opens a read-only cursor for a database table with the root page at the value of P2 in the database identified by P1. In this example the contacts table is opened from root page 4 of the main database. The temporary database has value 1 and any attached databases are given subsequent sequential numbers.
The VerifyCookie instruction checks that the schema version number of database P1 is equal to the value of P2. The schema version number is an arbitrary integer that changes whenever the schema is updated and is used so that SQLite knows when the schema has to be reread.
Next a Rewind takes place so that the following Column instruction will begin from the first record in the table. The P2 operand to Rewind is the jump location should the operation fail—in this case execution will jump to line 15 to perform an immediate Close and Halt.
The Column opcode in instruction 8 causes the column indicated by P2 to be pushed onto the stack. In this case P2 is 1, indicating the first_name column (with the first column, id, having index 0). We can see that the stack contains the string Chris, the first_name of the first row in the database.
Instruction 9 pushes the argument in the WHERE clause onto the stack ready to be compared. The comparison is performed with the StrNe opcode, which pops two elements from the stack and jumps to P2 if they are not equal.
In this example StrNe is used to implement an equality test by jumping past the conditional statement that returns execution to the top of the loop if the two strings are not equal. For this first record, the strings are equal, so operation continues to instruction 13 and pops the two fields in the result off the stack and passes them to the callback function.
The Next opcode at instruction 14 is where the jump from StrNe ends up if the strings are not equal. The cursor in P1 is advanced to the next data row and, as long as there are more records to fetch, execution jumps to the instruction number in P2.
Program execution continues for the remaining rows in the contacts table, with first_name values of Paddy, Tom, Bill, and Jo not being equal to the specified string, so no further Callback operations are performed.
Finally the Next instruction has no more rows to fetch and the virtual machine program calls a Close on the open table cursor and does a Halt with return code SQLITE_OK in instruction 16.
The complete list of opcodes for the SQLite VDBE is extensive and too large to cover in this chapter. A comprehensive list is maintained as part of the online documentation at http://sqlite.org/opcode.html if you find you want to analyze a particular SQL command in this level of detail.
Because SQLite uses a local filesystem to store its databases, the SQL language does not implement the GRANT and REVOKE commands that are commonly found in client/server database systems. They simply do not make any sense in this context.
Therefore the only access issues that need to be addressed are those associated with the database file itself and are done at the operating-system level.
For SQLite to be able to open a database, the user under which a process is running must have permission to access that file on the operating system.
Quite simply, to open a database for reading the process must be able to open the file in read-only mode, and to open it for writing the process must have both read and write access to the file.
On a Unix system, if the process runs as the owner of the database file, the file mode can be 0400 or 0600 for read and write access respectively. Mode 0444 would enable all users to access the database file as read-only, whereas mode 0644 would additionally grant write access to the owner of the file, and mode 0666 would allow writing by all users respectively. More information about file permissions can be found from man chmod.
Remember that although there is no limit to the number of concurrent reads allowed by SQLite, a single write process will lock the database and prevent any further read or write operations until it is complete.
It is therefore important to handle the SQLITE_BUSY return code if more than one process might access your database at a time. The more instances of SQLite there are running in your application, the greater chance that one of them will encounter a timeout when trying to access the database file.
The simplest approach is to continue attempting the query in a loop until SQLITE_OK is returned or some other exit forces you to stop trying, with a small pause on each iteration of the loop. Listing 10.3 shows how you might take care of this.
Example 10.3. Handling the SQLITE_BUSY Status
#include <stdio.h>
#include <sqlite.h>
int main()
{
char *errmsg;
int ret;
sqlite *db = sqlite_open("db1", 0777, &errmsg);
if (db == 0)
{
fprintf(stderr, "Could not open database: %s
", errmsg);
sqlite_freemem(errmsg);
return(1);
}
do {
ret = sqlite_exec(db, "INSERT INTO mytable (col1, col2) VALUES (1, 2)", NULL, NULL,
 &errmsg);
switch(ret) {
case SQLITE_OK: break;
case SQLITE_BUSY: fprintf(stderr, "Database locked, sleeping...
");
sleep(1);
break;
default: fprintf(stderr, "Error: %s
", errmsg);
sqlite_freemem(errmsg);
return(ret);
}
} while (ret != SQLITE_OK);
sqlite_close(db);
return(0);
}
&errmsg);
switch(ret) {
case SQLITE_OK: break;
case SQLITE_BUSY: fprintf(stderr, "Database locked, sleeping...
");
sleep(1);
break;
default: fprintf(stderr, "Error: %s
", errmsg);
sqlite_freemem(errmsg);
return(ret);
}
} while (ret != SQLITE_OK);
sqlite_close(db);
return(0);
}
The do ... while loop ensures that the query is executed at least once, and if the return code in ret is SQLITE_OK, the loop will not repeat a second time. However, if the SQLITE_BUSY error is encountered, the program outputs a message and sleeps for one second before the loop restarts and the query is attempted again.
Note
The sleep() function on Unix takes as its argument a number of seconds to wait. However, on Windows it requires a number of milliseconds. Listing 10.3 assumes a Unix platform so will only sleep for one thousandth of a second under Windows unless the value passed to sleep() is adjusted to 1000. However, it is much more useful if your program can do some other task than just hanging around while waiting to obtain a database lock.
Upon encountering any other return code, the program will halt execution displaying the contents of errmsg.
Similar functionality can be implemented using sqlite_busy_handler() to set a callback function that is invoked whenever a lock cannot be obtained.
Listing 10.4 shows a busy handler callback that will cause the program to attempt to obtain a lock five times, sleeping for one second between each try and giving up after the fifth attempt.
Example 10.4. Using a Busy Handler Callback Function
#include <stdio.h>
#include <sqlite.h>
static int myhandler(void *NotUsed, const char *dbname, int numtries) {
fprintf(stderr, "Database locked on try %d, sleeping...
", numtries);
if (numtries >= 5)
return(0);
else {
sleep(1);
return(1);
}
}
int main()
{
char *errmsg;
int ret;
sqlite *db = sqlite_open("db1", 0777, &errmsg);
if (db == 0)
{
fprintf(stderr, "Could not open database: %s
", errmsg);
sqlite_freemem(errmsg);
return(1);
}
sqlite_busy_handler(db, myhandler, NULL);
ret = sqlite_exec(db, "INSERT INTO mytable (col1, col2) VALUES (1, 2)",
NULL, NULL, &errmsg);
if (ret != SQLITE_OK) {
fprintf(stderr, "Error: %s
", errmsg);
sqlite_freemem(errmsg);
return(ret);
}
sqlite_close(db);
return(0);
}
The busy callback function is registered with the line
sqlite_busy_handler(db, myhandler, NULL);
The function pointer myhandler references the callback function declared at the top of the listing. The callback takes three arguments. The first is the pointer passed as the third argument to sqlite_busy_handler(), which allows arbitrary data to be passed to the callback. We have not used this facility in this example. Secondly, the name of the database table or index that SQLite was attempting to access is passed in. The third argument contains the number of attempts that have been made to obtain a lock, and Listing 10.4 restricts the number of attempts that may be made by looking at this value.
if (numtries >= 5)
return(0);
else {
sleep(1);
return(1);
}
If numtries exceeds 5, the sleep() instruction will not occur and a value of 1 is returned. When the busy callback returns zero, it instructs the query to continue attempting execution. A non-zero return value causes the query to be interrupted and the SQLITE_BUSY error to be raised.
The following output shows what happens when the program in Listing 10.4 is run on a locked database:
$ ./listing10.4
Database locked on try 1, sleeping...
Database locked on try 2, sleeping...
Database locked on try 3, sleeping...
Database locked on try 4, sleeping...
Database locked on try 5, sleeping...
Error: database is locked
SQLite includes support for multithreaded database connections so that you can access your database from two or more threads simultaneously.
The THREADSAFE preprocessor macro is used to determine whether SQLite is built in thread-safe mode. Enable this feature by adding –DTHREADSAFE=1 to an appropriate place in the Makefile. Precompiled binary distributions are thread-safe by default for Windows systems, but not for Unix systems.
The most important thing to remember is that each thread must make its own call to sqlite_open() to obtain an sqlite* type pointer. The same sqlite* pointer should not be accessed from more than one thread at a time as unpredictable results may be seen. The child process from the result of a fork() command should also open its own copy of the database after being spawned.
Be aware that because SQLite reads the database schema only once upon opening the database, if one thread changes the schema the other thread will not be able to see the amended schema until you close and reopen the database connection—just the same as would happen in a multi-process environment.