
The amount of data that we consume each day is overwhelming. According to Jeff Desjardins, founder and editor of Visual Capitalist, the world has an estimate of 44 zettabytes of data.1 A zettabyte is 1,000 to the power of 7 or 1 with 21 zeros. Fortunately, most architects do not need to manage data that large, but the size of the data we manage is still staggering.
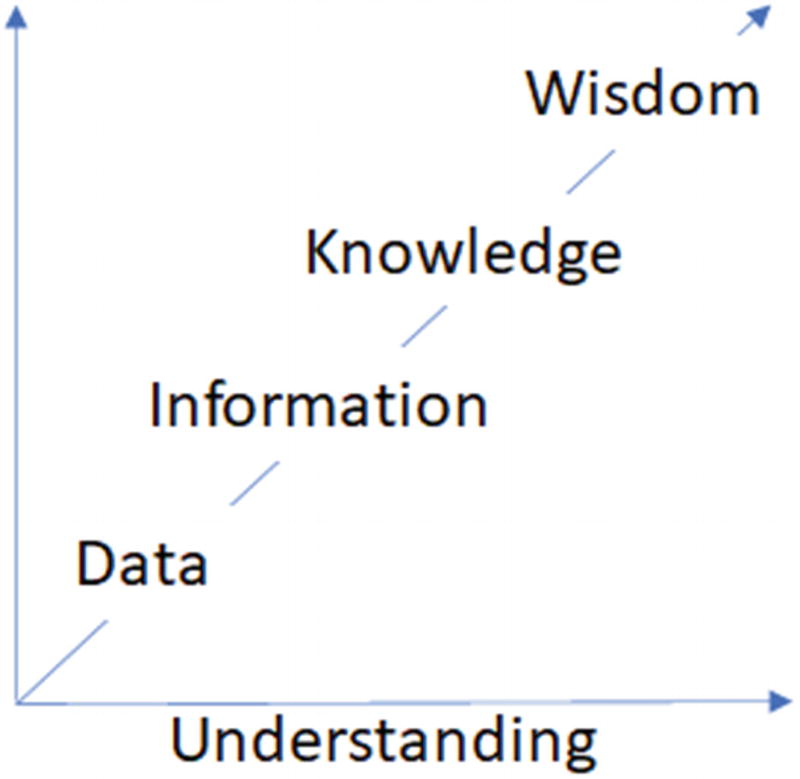
Ackoff Knowledge Continuum
So how does all of this theoretical discussion fit into the topic of Salesforce data architecture? Our job, as Salesforce architects, is to structure the data with an understanding of its use, its various categories, and its ultimate value to the organization. Understanding different data considerations, constructs, implications, and patterns is the heart of data architecture. In this chapter, we focus on three main areas of data architecture: data modeling, large data volumes (LDVs), and data migration.
The importance of data architecture as it relates to the overall instance design
The high-level data modeling concepts needed to select the right design as it relates to business processes, data movement, and optimization
The best practices, considerations, and tools used to manage a large data volume (LDV) environment
Determining the right data lifecycle management in the Salesforce approach to improve performance and maintain compliance
Evaluating data migration strategy, considerations, and appropriate tools
Why Is Data Architecture Important?
Intake data from the user or another system through a user interface or system interface.
Store data within its storage component or another system’s storage component.
Process data based on clearly predefined business logic.
Return results from processing the data to the user or another system through a user or system interface.
A simple example of data management is when you use a calculator. To use a calculator, you enter the numbers by using the user interface. The calculator intakes the numbers that you want to calculate. The calculator also requires you to choose the business logic that you want to apply to the numbers entered, such as add, subtract, multiply, or divide. During this intake process, the calculator stores all the data entered by you in its memory and starts processing the data based on the predefined business logic chosen by you (i.e., add, subtract, multiply or divide). Finally, it returns the results of the processed data by displaying the final result on its user interface.
Salesforce uses a strongly typed object-oriented programming language called Apex . Every functionality in Salesforce, even if it is configured out of the box using clicks, is built using Apex as the codebase.
In an object-oriented programming language, data is collected, processed, and stored in a logical grouping called an object. For example, all data related to a customer account, such as account name, address, phone number, website details, and account status, are managed and stored in an account object. Just like a file folder, objects logically separate a specific type of data within the system from another type of data.
Customer Company Name: ABCD Inc.
Customer Contact Name: Joe Smith
Customer Company Phone Number: (555) 555-5555
Customer Contact Email Address: [email protected]
Customer Is Interested in: 2000 blue V-neck T-shirts, 3000 polo T-shirts with collar
Contact’s Role at the Company: Decision maker
- Customer’s Previous Purchases: 3 purchases
Purchase-1: 2000 denim jeans
Purchase-2: 500 winter jackets
Purchase-3: 100 hats
- Customer’s Service Requests: 1 new request and 1 pending request and 1 completed request
New Request: “Need product catalog for the summer season.”
Pending Request: “Need to return previously ordered 100 hats, along with the full refund.”
Completed Request: “Processed a refund for 100 denim jeans for $2000, returned from the total delivered in Purchase-1.”
From an initial look of the preceding sales data, it may seem more straightforward to store all of the sales details in a single document and manage all changes related to this customer by accessing and updating that single file. However, things could get complicated very quickly when hundreds of new opportunities are created for multiple customers and often by multiple sales team users selling and servicing a typical customer daily.
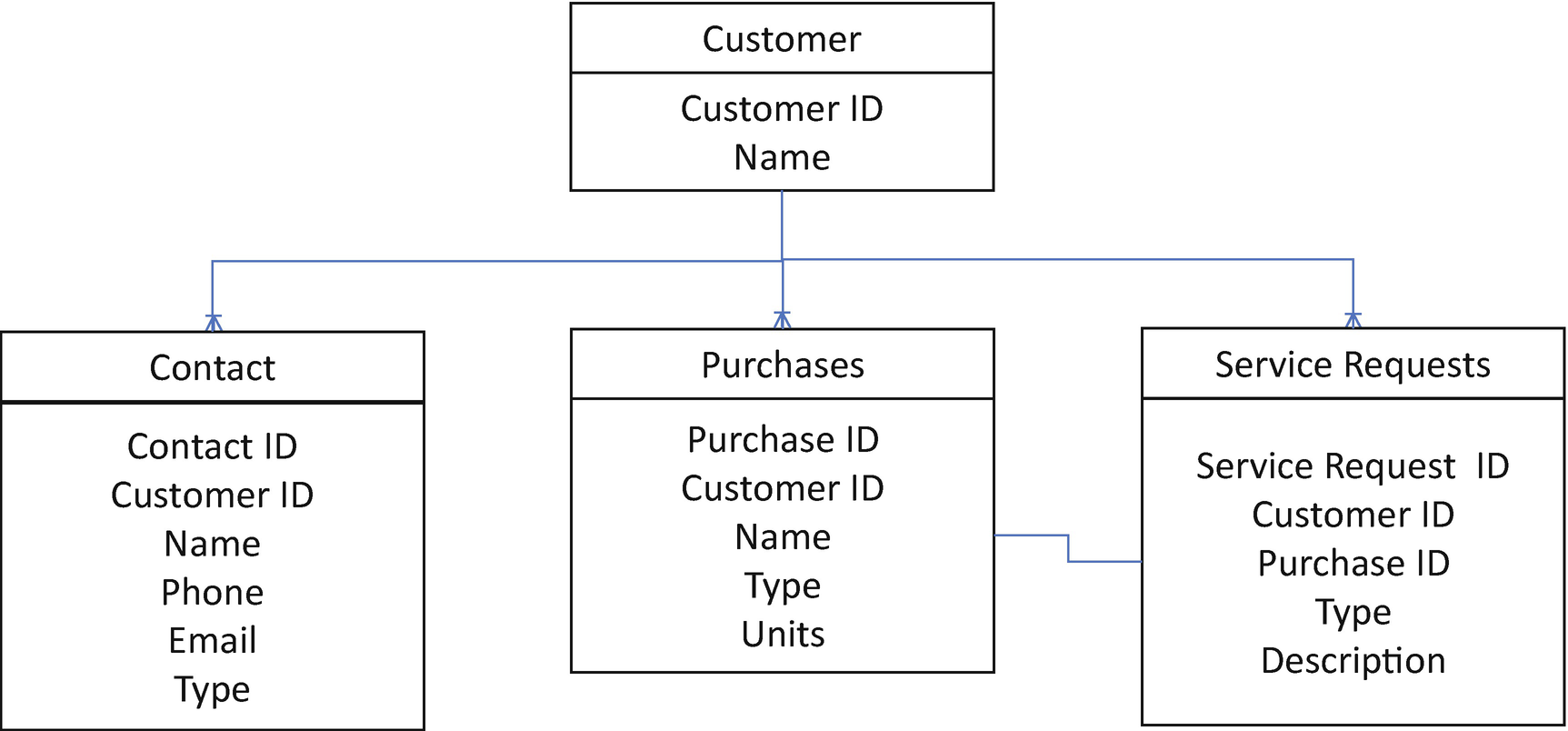
Salesforce Data Object Model to Store the Sales Data
Data Modeling in Salesforce
- 1.
Objects needed to store and manage data in Salesforce
- 2.
Object types (i.e., whether they are standard, custom, or external objects)
- 3.
Record types within each object
- 4.
Object relationship to other objects
- 5.
The organization-wide default settings for object visibility
- 6.
Owners of the records within each object
- 7.
Estimated number of records per object that can exist at any given period
Data Model Techniques and Considerations
What is the overall goal(s) of the Salesforce environment? Often, Salesforce supports multiple business functions with different applications, all using the core Salesforce “standard” objects and a defined set of custom objects. Understanding each business use case is critical before the presentation of the final design.
How will the business use the data in Salesforce to report business trends, outcomes, and KPI predictions? Starting with the final reporting requirements often changes the overall data model design to support the requirements.
Does the user need to see data on the detail page or in a related list? Traditional and academic database normalization does not work well in Salesforce. You need to understand how the application is used and consider the user experience (UX) and the page layout and presentation (UI).
Will your data model support declarative business logic? The design of the data model can also impact your ability to create an application declaratively or programmatically. Many businesses are expecting no/low code solutions.
Let’s dive a little deeper into some of the data model considerations.
Top-Down Consideration with Bottom-Up Requirements
Vision/Process/Challenges/Pain Points: Before you start the data model design, work with the executive team to understand the overall vision for Salesforce. Identify the business pain points each of the stakeholders has in the current environment and capture the business processes they use. Identify the challenges they have and the potential impact of those challenges in Salesforce.
Reporting and KPI: Often, Salesforce supports business processes and collects data to report and measure success. It is essential to understand the expected reporting requirements. Often, reporting is left to the end of a project, only to find out that the data model needs to be changed to support the reports. Starting with reporting and dashboards can provide valuable business insight, but it can also reduce the technical debt incurred by not knowing the reporting requirements early.
Security : Understanding the overall security landscape of the business and the detailed requirements reduces efforts on both the data model design and the visibility and sharing of data within the Salesforce instance.
Performance : There are three high-level ways to measure the speed of the design: intake, processing, and reporting. The first measurement, intake, is the speed in collecting data. It is crucial to understand how the system collects data used by the business process. User frustration increases if they are required to jump from object to object to collect data, causing data quality issues. The processing of data is also a consideration. Business processes that require complex, custom-built methods run slower and are challenging to maintain and update. The last performance measurement is reporting and how the initial and processed data can be extracted and reported.
Business Process: The data model design often dictates which process tools can support the business. Costly changes occur if the data model does not consider the processes used in the design. The most basic example is the use of roll-up fields. If a lookup relationship field is used instead of a master-detail relationship, then the roll-up summary solution requires a programmatic approach to support the business requirement. This example also demonstrates the need to understand the security required, as the use of the master-detail relationship field opens the access of the data.
Choices and Compromises
Choice and Compromise – Consideration of Choices
Let’s look at two user stories to see how different decisions can impact the outcome(s) of the design choice.
User Story: Same-Day Shipping
AS A shipping manager, I WANT to track the percentage of orders placed today shipped for all the warehouses SO THAT I can generate a critical KPI report showing same-day shipping per quarter.
Approach Options: Normalized or Denormalized
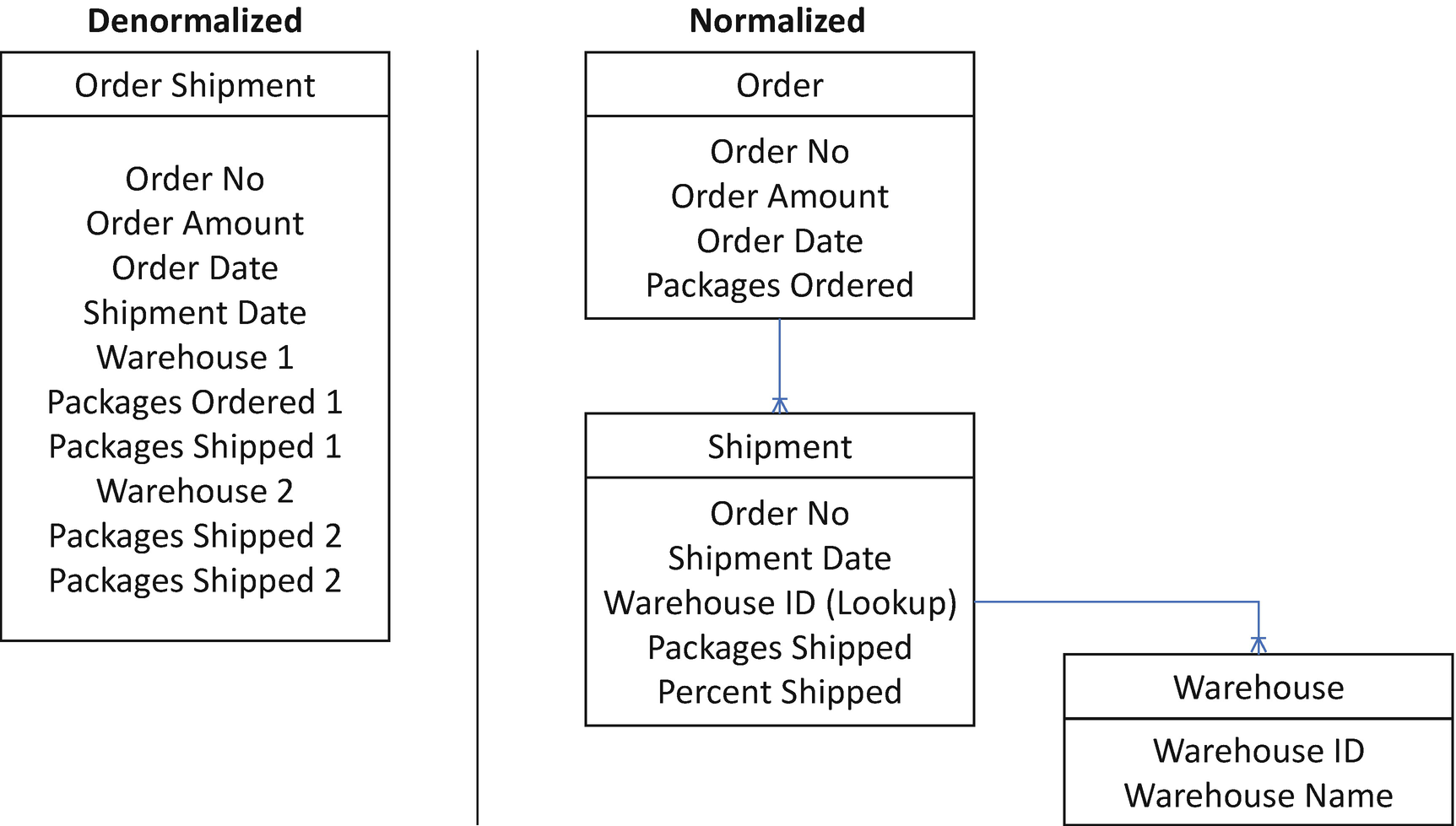
Denormalized Data Model vs. Flat Data Model - Order Shipment
Analytics Requirements: A real-time report showing the percentage of same-day shipments per quarter
User Experience (UX) Requirements: Ability to capture the shipment dates
Architecture Choice: Normalized
The focus of this user story was the analytics or reporting requirements. Therefore, it makes sense to store the warehouse data in its object. Additionally, the consideration of both the data capture and UX allows the warehouse object to collect the data as it happens.
Let’s look at a second user story.
User Story: Lead Contact Information
AS A marketing manager, I WANT to quickly enter contact information from a lead SO THAT I can quickly find the contact number for a given lead when I look at the lead detail page, reports, lists views, and highlight elements.
Approach Options: Normalized or Denormalized
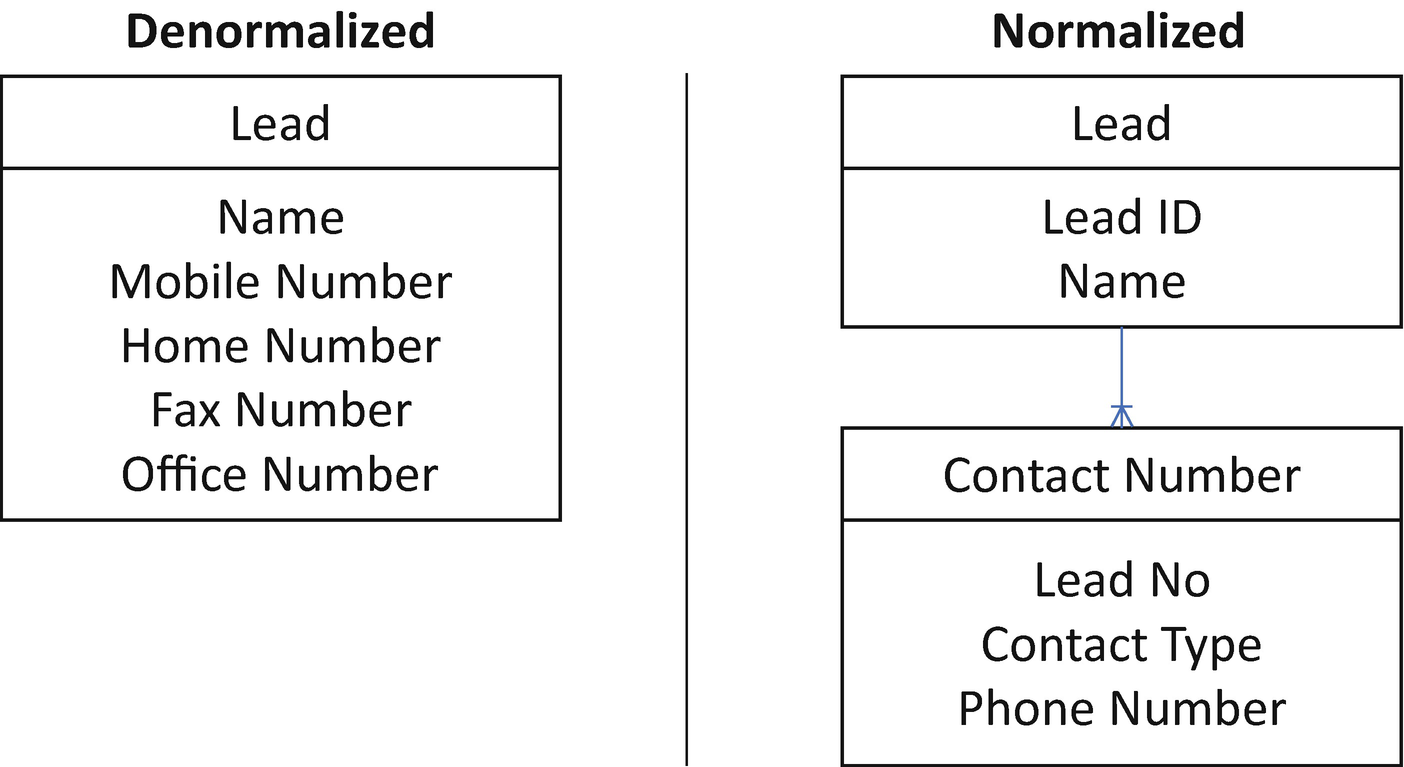
Denormalized Data Model vs. Flat Data Model - Lead Phone Numbers
Analytics Requirements: For this story, the analytic need is not a consideration.
User Experience (UX) Requirements: Ability to capture information and to display data on the detail page, report, list view, and highlight element.
Architecture Choice: Denormalized
The focus of this user story was the information capture and UX requirements. Therefore, it makes sense to store the lead data and the phone data in the same object. This approach supports both the data capture and UX requirements.
Cardinality: Salesforce Options
Salesforce offers only a few data relationship options, which are one-to-one, one-to-many, and one derived option for many-to-many relationships. These primary data cardinals are the foundation of all data designs. It is critical to understand the impact each approach has on the data model design decisions.
Selecting the Best Type of Relationship
Differences Between Lookup and Master-Detail Relationships in Salesforce
Consideration | Lookup | Master-Detail |
|---|---|---|
Object dependents | Loosely coupled. | Tightly coupled. |
Number of relationships per object | 40 in total including count of master-detail (can increase to 50 on request). | Only 2. |
Parent required | No. Records can be orphaned or reparented. | Yes. No orphans. Deletion of reparenting only. |
Sharing | Independent. | Inherited from parent. |
Cascade deletes | No – Standard object.Selectable – Custom objects (delete is not allowed for >100,000 records). | Yes. |
Many-to-many | Not recommended as lookup since it does not mandate a relationship record on both sides by default. | Yes, sharing requires including both related objects. However, ownership is controlled by the first M-D field or primary master object. |
Self-relationships | Yes. | Only one M-D. No M:M allowed. |
External object | Yes. | No. |
Indirect lookup (external child object to standard or custom SF object) | Yes. | No. |
Hierarchical | On user object only. | No. |
Roll-up summary | With code or AppExchange app. | Yes. |
Revisiting Cardinality in Salesforce
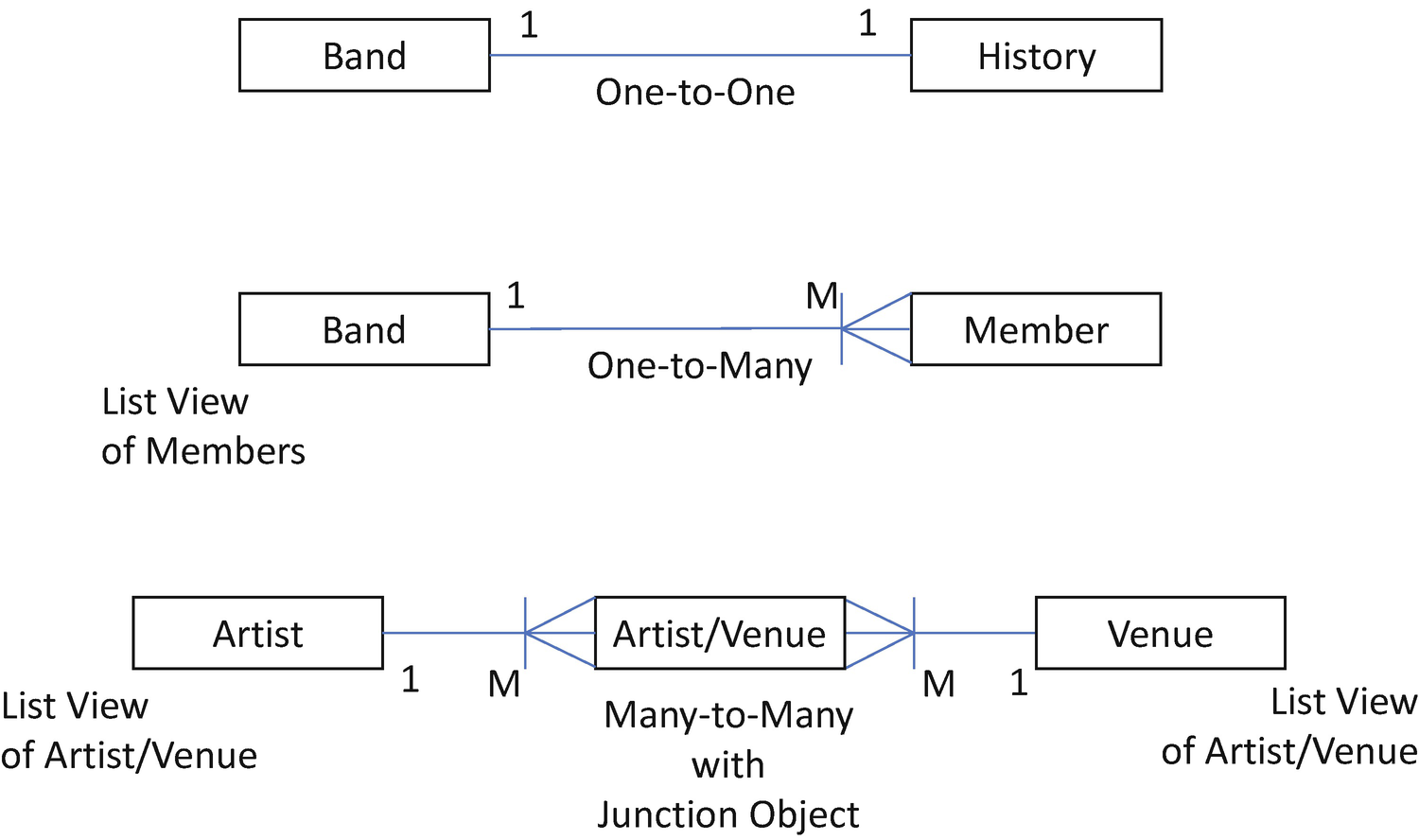
Cardinality in Salesforce
Other Data Modeling Considerations
Salesforce offers several standard data models depending on the “cloud” solution you recommend to your client. Each “cloud” is composed of the objects used in the software as a service (SaaS) offering. At the time of this writing, Salesforce listed 871 different standard objects supported for all of its “cloud” products. At the core of the most popular “cloud” licenses (Sales and Service), Salesforce provides standard objects that are the heart of the overall design. These objects are often called the “Hero” or core objects. These objects include the account, contact, opportunity, lead, and case objects.
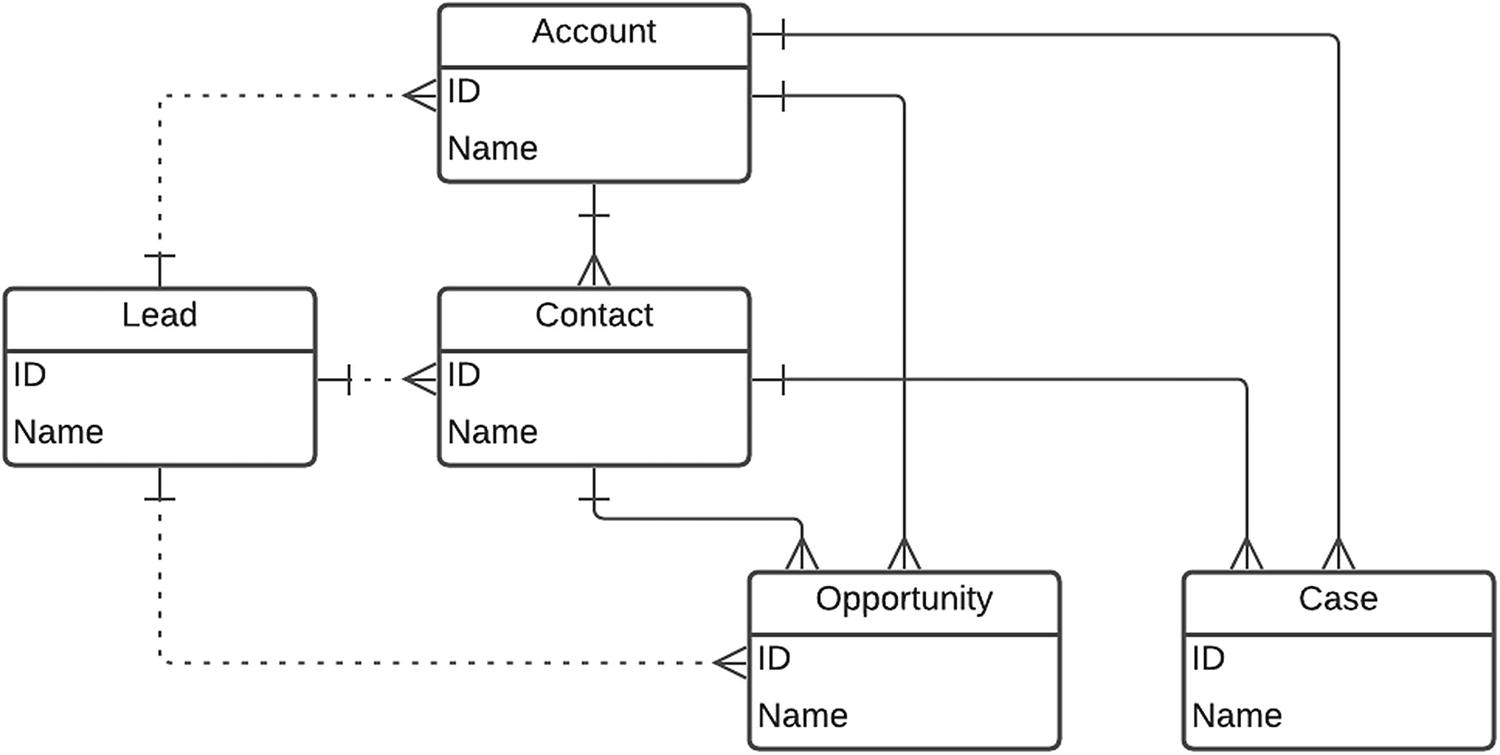
Salesforce Standard or Core Objects
Architects should know how standard objects create a scalable data model that supports all business processes with an appropriate level of customizations (click vs. code) while considering performance for large data volumes. Let’s look at the object types available in Salesforce.
Custom Objects : These objects are created by the administrator or architect to store information that is unique to the business or requirements of the design. A custom object has similar attributes and characteristics of Salesforce standard objects, including standard and custom fields, field history tracking, relationships, custom links, search layouts, page layouts, object limits, and sharing.
External Objects : These objects are similar to custom objects, except that they map to data outside of Salesforce. An external object uses an external data source definition to connect to the external system. Usually, this is the Salesforce Connect optional product. External objects are searchable and appear the same to Salesforce users. Salesforce sharing rules do not control access to the data; permission sets or profiles control access to the data. Limits come from the external host system.
Storage Considerations : Salesforce has storage limitations. Because of these limits and the availability of external objects, an architect understands these options. (See specific license information for details.)
Large Data Volume Architecture
an imprecise, elastic term. If your deployment has tens of thousands of users, tens of millions of records, or hundreds of gigabytes of total record storage, you have a large data volume. Even if you work with smaller deployments, you can still learn something from these best practices.3
This definition leads me to more questions than it answers. In fact, in practice, the actual definition of LDV is even more elusive. LDV impacts the full spectrum of interaction with Salesforce from importing and exporting data; establishing sharing and visibility; using data in the UI, reports, and list views; and performing business rules and processes. The size of the data is not a one-size-fits-all assumption. It is also nuanced in how to use data volume. An architect’s role is understanding how to identify an LDV, what causes it, and, most importantly, how to mitigate its impact on your Salesforce instance performance.
- 1.
What is the performance of the UI/UX?
- 2.
Is the efficiency of the underlying database optimized?
- 3.
Will API throughput meet or exceed requirements?
- 4.
Will you have data migration issues during the data lifecycle?
What Causes LDV Issues?
The access to and the presentation of data is a vital feature provided in Salesforce. To support this critical feature, Salesforce uses a data model that creates a pivot table to index fields, enforce unique fields, and manage foreign keys.4 Salesforce also establishes tables to manage sharing and group access; see Chapter 5. Additionally, Salesforce uses an underlying database to support its multi-tenant design called the Lightning Platform Query Optimizer. The query optimization runs automatically to create indexes, select the best table to run queries, order data, create key values and joins, and establish execution plans to minimize database transactions.5 Because of the complexity of the design, large data volumes can impact overall performance. Let’s look at the potential causes of poor database performance in Salesforce.
Object Size
>50 M account records
>20 M contact records
>100 M custom records
>10 K users
>100 GB record data storage
These volumes are not definitive. Rather, they are indicators that an LDV impact might occur. Let’s look at the “>100 M custom records” example. For this rule of thumb, the assumption is that the custom object is going to be used to capture associated data, and its associated relationship easily reduces the volume with a simple query. Remember that LDV is multifaceted. Let’s dig a little deeper.
Object Size Growth: Another consideration is the potential growth of an object volume. If our 4 million contacts are expected by 20% per month for the next 36 months, we have more than 23 million contacts in 36 months.
Examine the data growth for several years and consider current and future growth expectations. A good rule of thumb is to look at 2–3 years minimum, with a maximum of 5 years.
Present Value * (1 + Percent Growth)^n = Future Value
Why does the object volume matter? What can impact its performance? In Salesforce, every record has an owner. A specific user (internal or external) or a queue (a group of users) owns a record. Additionally, a list of data or a report is the primary user experience. As a data volume grows, so does the number of system resources required to manage and present the data. Let’s look at a few crucial perspectives.
Record Ownership
In Salesforce, every record must have an owner. The owner can be a single user, or it can be a “queue” of users. Salesforce mandates this design to support the security and visibility requirements inherent in the design. The owner of a record has full access to the record. To keep data secure and only allow appropriate users access to that record, Salesforce also provides a system object to manage the sharing rules associated with that record. A system object is not visible directly in the Salesforce UI. However, it is available to the business logic in terms of both declarative and programmatic controls used to manipulate the associated data.
Record Relationships
Every record in Salesforce is related to several other objects. At the system level, the relationships include the owner, created by, last modified by, sharing, and other business process relationships. These relationships are either a master-detail type or a lookup type.
The platform automatically cascades the deletion of child records when the deletion of the parent occurs and enforces the need for a parent reference upon the creation of a child record.
By default, the platform prevents users from moving the child records to another parent by editing the relationship field. However, you can disable this validation and permit this by selecting the reparenting option for child records.
With the use of roll-up summary fields, it also becomes possible to build calculated fields based on values of the child record fields.
You can define up to three levels of master-detail relationships.
The deletion of a parent record does not result in a cascade delete of related child records; Salesforce Support can enable this feature.
Unlike with master-detail, you can elect for the platform to enforce referential integrity during the creation of the field by utilizing the Don’t allow deletion of the lookup record that’s part of a lookup relationship option.
Currently, the roll-up summary fields are not supported when using a lookup relationship.
Lookup fields of either kind are automatically indexed by the platform, making queries, in some cases, faster.
External Lookup : External lookup is a relationship that links a child standard, custom, or external object to a parent external object. The external lookup relationship field is a standard external ID field from the parent external object matched against the values of the child ID.
Indirect Lookup: Indirect lookup is a relationship that links a child’s external object to a parent object. The lookup is a custom, unique, external ID field on the parent object matched against the child’s indirect lookup on an external data source.
Hierarchical Lookup: Hierarchical lookup is a relationship available for only the user object to support user lookups for both direct and indirect relationships .
Data Skews
The primary factor associated with data skew is the aligning of many relationships with a single record or owner. In other words, if you load tens of thousands of leads or accounts to one user or if you associate tens of thousands of contacts with a single account in Salesforce, you are creating a data skew. Three factors impact Salesforce performance: record locking, sharing performance, and lookup skew. Let’s look at each factor.
Use a Public Read or Read/Write OWD sharing model for all nonconfidential data loading.
To avoid creating implicit shares, configure child objects to beings “Controlled by Parent.”
Configure parent-child relationships with no more than ten thousand children to one parent record.
If you have occasional locking errors, retry logic might be sufficient to resolve the problem.
Sequence operations on parent and child objects by ParentID and ensure that different threads are operating on unique sets of records.
Use compression using gzip for responses to reduce network traffic and HTTP keep-alive to improve performance.
Tune your updates for maximum throughput by working with batch sizes, timeout values, Bulk API, and other performance optimization techniques.
Salesforce introduced improved batch management in the Winter ’21 release to support LDV data loads.
Sharing performance is impacted when a change is made that causes a cascaded impact across many records. This performance impact is highly visible in a situation where a parent or child record is changed and the system has to iterate through tens of thousands of potentially affected records. The sharing recalculation happens every time a criterion is changed that could or would change the sharing requirement, such as ownership and criteria-based sharing rules. Having a large number (greater than 10,000) of child records associated with a single owner causes this performance issue.
Lookup skew is when an extensive set of records are associated with one record within a lookup object. Behind the scenes, Salesforce needs to identify and lock any associated lookup record. Process, workflow, and validation exacerbate lookup skew for a given object.
Addressing LDV Issues
Divisions
Force.com Query Plan
Skinny tables
Indexes
Database statistics
Let’s look at each approach.
Divisions: Divisions can partition an organization’s data into logical sections, making searches, reports, and list views smaller and faster. Note: Submit a case to enable this feature.
Force.com Query Plan: Salesforce offers a tool in the Developer Console to review and evaluate the performance of queries in large data volumes. The goal is to optimize queries using selective and indexed fields and to speed up performance over large volumes. Note: Enable this feature in the Developer Console.
Database Statistics : Salesforce performs a nightly process to collect statistics from the database. This process happens automatically. The outcome is improved index objects. An architect can use this knowledge to tune the query design to take advantage of these automatic calculations and indexing files. Note: The statistics is calculated by Salesforce automatically.
Skinny Tables : Salesforce can create skinny tables (denormalized, flat files) that combine frequently used fields and remove joins. Skinny tables can resolve specific long-running queries for objects with millions of records. Skinny tables resolve long-running reports, slow list views, and SOQL queries that time out. Note: Submit a case to enable this feature.
Custom Indexes : Salesforce creates custom indexes to speed up queries. They can be helpful for SOQL queries that need to use non-indexed fields. Note: Submit a case to enable this feature.
A Final Word on Account Skews, Ownership Skews, and Lookup Skews
The impact on organizational performance is the lack of adherence to account and ownership skew guidelines. Let’s restate them here:
Mitigation Option: Place the user in a separate role at the top of the hierarchy. Keep the user out of public groups.
Mitigation Option: Split the account into smaller (fewer children) accounts and use a parent account to consolidate information.
Mitigation Option: Split the parent object record into smaller (fewer children) records and use a parent account to consolidate information.
Avoid records with many child records.
Use triggers instead of workflows.
Picklists instead of lookup.
Schedule maintenance updates at non-peak times to avoid record locking.
Data Lifecycle Management in Salesforce
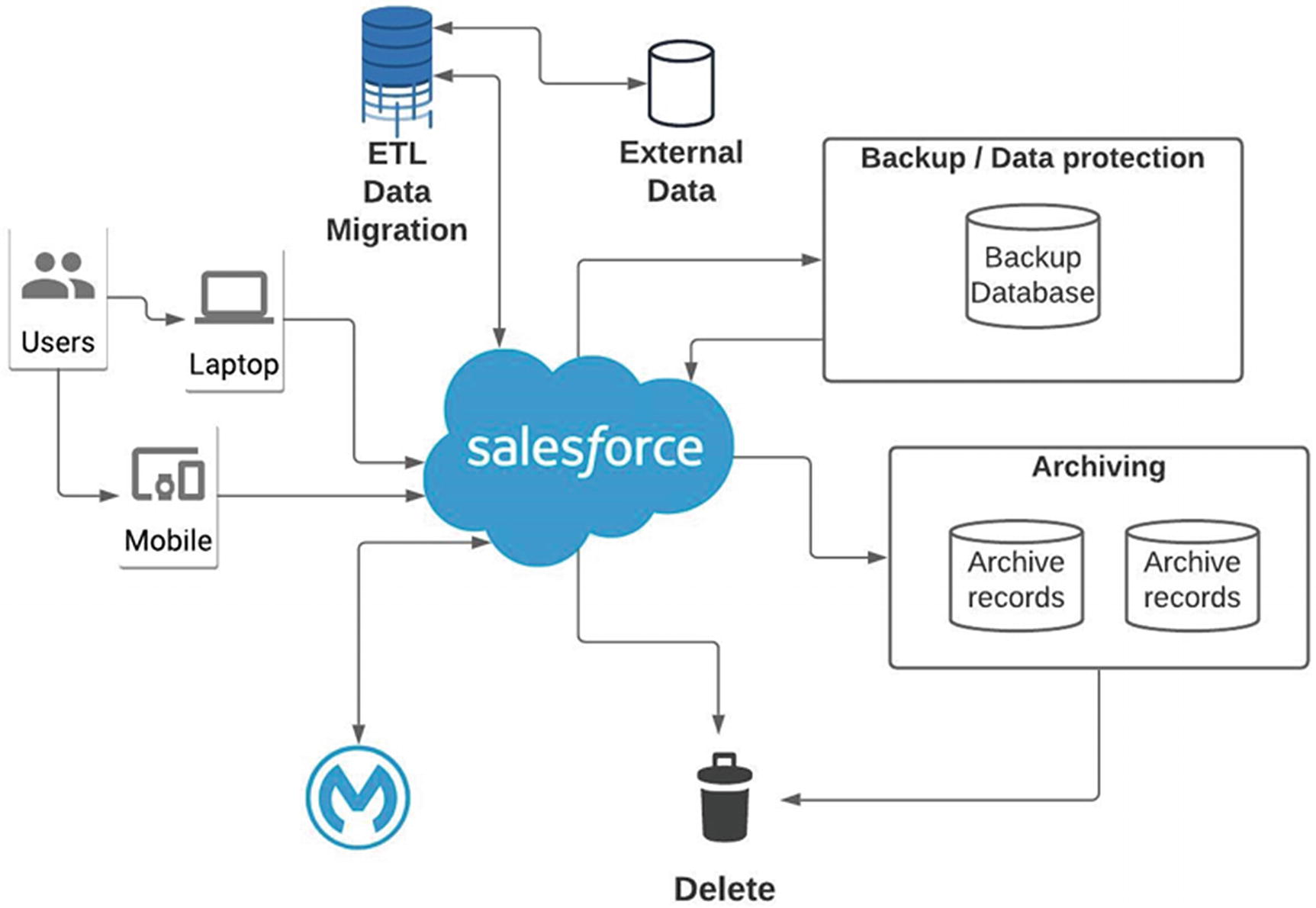
Salesforce Data Lifecycle: Backup and Archiving Approach
Data Migration
Common Data Migration Tools Comparison
Data Migration Tool | Features | When to Use |
|---|---|---|
DataLoader – included with standard license | • Standalone application. • Supports bulk data loads. • Supports auto-scripts. | This tool is suited for small to medium data migration efforts or when overnight process is needed. DOS batch routines can be used. |
DataLoader.io – basic features built-in to UI | • Web-based options. • Supports bulk data loads. • Option to purchase enhanced features. | This tool is well suited for administrator data management. It supports advanced data management features with scheduling. |
Data wizard – internal feature | • Step-by-step tool for users and administrators. • Limited to CSV files. | This toll is used by end users and admins to perform basic data managements such as loading leads and contacts. |
Types of Data Manipulation Operations Available for Data Migration
The lifecycle of data migration starts with the creation or insertion of data into a Salesforce object. The next step in the lifecycle is to update the data as required over time. Salesforce offers an operation that can insert and update in the same operation called upsert.
Insert: The insert operation creates a new record in an object and commits it to the database. This operation is the fastest and should be used for new data.
Update: The update operation identifies the related record using a primary or foreign key to change one or more fields in the record. This operation is slower because it must look for existing records to update.
- 1.
If the key does not match, then a new record is created.
- 2.
If the key matches once, then an existing record is updated.
- 3.
If the key matches multiple times, then an error is generated, and the operation fails.
A record is inserted or updated based on how it is related to existing records if a relationship has already been defined between the two objects, using either a lookup or master-detail relationship, which is considered a foreign key ID. Note: Updates cannot make changes to the related object using the same operation.
A data migration plan can also require the removal or deletion of existing data. Salesforce offers three delete operations to support this requirement. Before we look at the available delete operation, we need to understand the impact a delete can have on the direct and related records. If a record is a master record in a master-detail relationship, the process deletes the related record if allowed. (For more information on what can stop a deletion, please refer to the Salesforce referential integrity rule). Salesforce also provides an operation to restore soft deletes and related records. The process relies on the availability of items remaining in the trash bin. The delete operations are as follows:
Delete: The delete operation is a soft delete of records. Recovery of data is possible.
Hard Delete: The “hard delete” operation is a permanent deletion that removes the record and any related records concerning referential integrity.
Mass Delete: The “mass delete” operation is only available for custom objects. If the entire custom object requires removal, use truncation instead .
Data Migration Process
- 1.
Identify the data you want to migrate. Determine the state of the data and how you want to use it in the new org.
- 2.
Create templates for the data. Build the loading template to gather all of the required fields and relationships. Don’t forget historical data elements like created date and created by users. Also, look at special requirements such as record types and picklist values.
- 3.
Prepare your data. Look for duplicates and wrong or missing data. If required, clean the data to provide the best data in the new organization. Be careful with leading zeros and case-sensitive record ID.
- 4.
Populate your data into the templates. To catch issues before you migrate the data, organize the data, and load the template.
- 5.
Prepare the destination org for use and testing. Consider adding information from the legacy system that can improve your data. Adding an external ID can help troubleshoot issues and make future updates easier.
- 6.
Migrate the data using appropriate operations; if possible, turn off business processes, workflows, triggers, and sharing recalculation before you start. Also, consider loading a test in a sandbox environment first to make sure the template works as expected.
- 7.
Validate the data. After the data is loaded, run tests to make sure you had a successful migration. Make sure the number loader equals the number of new or updated records. Spot-check for added validation.
Data migration is often much more complicated than a single object update. In these cases, the structured and unstructured data includes many legacy objects with complex or normalized data. When this happens, the process is much more complicated, but the necessary steps still hold. The interaction is more of a consideration. As an example, the data may require a series of data loads to support the ultimate solution. Here we need to add a step to understand the order of operations and both the upstream and downstream implications. As an example, you may need to load the users into the system first to obtain the unique Salesforce ID to associate the user to the created by ID. In Salesforce, you can only add the “createdBy” ID as a system input during the creation of an initial record. If you tried to update the record later, your update would fail.
Complex Data Migration
Having the right tools is essential for a complex project. Data migration is not different. The architect must review the requirement and suggest the right tools for the job. It could be a simple tool like DataLoader, or it could be a sophisticated ETL (Extract-Transform-Load) solution such as Informatica.
(CS-DEV) “See as a developer”:
C: Cleanse data.
S: Standardize data.
D: Dedupe data.
E: Enhance data via ETL.
V: Validate data.
ETL (Extract-Transform-Load)
- 1.
Data extraction
- 2.
Data cleansing
- 3.
Data transformation
- 4.
Data loading
Step 2, data cleansing, is added into the process, as it is required to prepare data for the transformation.
Data Extraction and Data Cleaning
The main objective of the extraction and cleaning process is to retrieve all the required data from the source data systems. Make sure to consider the impact the act of extraction has on the performance, response time, and locking within the source systems. Data cleansing and scrubbing is the detection and removal of inconsistent, insufficient, or duplicate data. The goal of cleansing is to improve the quality and usability of data extracted from the host system before loaded into a target system.
Review and identification of significant data issues, such as duplicates and troublesome or missing data.
Evaluation of data formatting. The originating system may use a different date format. As an example, Excel uses a base numbering system to create and manipulate dates.
Enrich your data during the cleansing process. This process improves the transformation and usefulness of the data in the new environment.
Clean the data with the destination system in mind. Focus on the fields and objects used in both the transformation and destination systems.
Review how the workflow might change the data as it migrates into the system and include all of the required fields.
Data issues come in many forms, such as misspelled, incorrectly capitalized, duplicated, and missing or null. It can also include reference errors with contradictory values, referential integrity errors, or summarization errors. Use the cleansing stage to resolve these errors.
Data Transformation and Verification
The transformation step is the point in the ETL process where the data is being shaped, aligned, and “transformed” to be ready to load into the new system. It is also the point where there is a detailed knowledge of the new data model and how incoming data transforms during the load. It is also the time to define the order of operations for the data to be loaded. The transformation happens in steps, and the new relationships are created.
Equally important is the verification process. This part of the ETL process includes the testing and evaluation of the outcomes. In its simplest form, the verification includes a “checksum” count or summarization for a given transformation that can be used as a test if the expected number of users, opportunities, and accounts is loaded. This checksum helps to confirm that all records have been processed and included in the transformation.
Depending on the complexity of the transformation, an architect creates an intermediate area or staging area where the transformation takes place. Spreadsheets, SQL-based databases, or external transformation solutions, including using scripts for recurring data migration processes, can support the staging process. Let’s look at a few options:
Microsoft Excel Spreadsheets: For simple transformations, Excel is an easy tool to create tables of CSV files for capturing structured data and adding transformations such as accountID, OwnerID, and RecordTypeID. The process works well for transformations that are limited to single object lookups. Once your process requires a multistep transformation, the Excel option starts to break down quickly.
Microsoft Access, MySQL, or SQL Server DB: As the transformation complexity increases, the need to build tables and cross-reference tables to support the transformation also increases. An off-the-shelf database option provides the architect with the ability to create transformations to support a complex requirement. The downside is that it assumes the availability of the tools and the knowledge and experience with the selected DB to create the transformation application. Often, this approach requires a substantial amount of work to create a solution with the appropriate amount of testing and validation.
Informatica and Jitterbit : This type of third-party solution allows the architect to focus on the transformations without building the application to manage and run the process. They usually have predefined mapping and transformation tools that significantly reduce the time required to implement the required processes. The downside to this option is the initial cost of the tool. You should expect to pay for the tools and processes created to make your work easier.
Formatting Data: Transform data to specific data types and lengths.
Required Field Population: Adding required information to base data to support data validation requirements in the destination system.
Deduplication: Delete or merge duplicate records.
Cleaning: Normalizing the data to a standard for given values such as gender, addresses, and picklist values.
Foreign Key Association: Create key relationships across tables.
Translating Data Fields: Translate data coming from multiple sources into values that make sense to business users.
Parsing Complex Fields: Transforming complex fields into individual fields.
Merging/Combination of Data: Merging data from multiple fields as a single entity, for example, product, price, type, and description.
Calculated and Derived Values: Aggregate or calculate field values for the ultimate load.
Summarization: Convert external data in multidimensional or related tables.
Data Loading
The last step is to “load” the data into the new instance. It is imperative to remember that loading data into a system like Salesforce has two perspectives. The first is the impact that a “large data” load has on the system, and the second is the limitations with the loading of data. Let’s look closer at each point.
If possible, change affected objects and related objects to Public Read/Write security during the initial load to avoid sharing calculation overhead.
Defer computations by disabling Apex triggers, workflow rules, and validations during loads; consider using Batch Apex after the load is complete instead of during the data load.
Minimize parent record locking conflicts by grouping the child records by parent in the same batch.
- Consider the order of data loads for large initial loads; populate roles before sharing rules:
Load users into roles.
Load record data with owners to trigger sharing calculations in the role hierarchy.
Configure public groups and queues, and then let those computations propagate.
Then add sharing rules one at a time while letting computations for each rule finish before adding the next one.
- Add people and data before creating and assigning groups and queues:
Load the users and data.
Load new public groups and queues.
Then, add sharing rules one at a time, letting computations for each rule finish before adding the next one.
Data Limitations : As we all know, Salesforce has system governor limits to protect the instance. As such, these limits come into play during the load phase. If you are using the API to load data into Salesforce, you must consider both the daily API limit and the query size limits. Make sure to plan your migration using these guideposts.
Data Loading Tools: Salesforce supports several data migration tools, including data wizard, Java-based Salesforce DataLoader, MuleSoft DataLoader.io, and API-based third-party applications.
Data Backup
On July 31, 2020, Salesforce discontinued its recovery services for production instance owners. That said, the service was not tenable, as it cost $10,000 and took more than six weeks to recover your lost data. This may sound shocking, but data in the cloud is not risk-free. It is critical to have a plan and to use it regularly. A good architect will have a data architecture that includes data backup and archiving plan.
Out-of-the-box Salesforce provides the ability to create backup files of the instance data on a weekly or monthly basis, depending on your edition. The data is saved as CSV files and file blobs and consolidated into zip files. The system administrator downloads them one zip file at a time. This data is only visible for a couple of days; Salesforce does not store the data long-term. Salesforce does not have any extraction tools to recreate your data. WARNING: This is not a viable option for enterprise data management.
We recommend that you invest in a third-party backup and recovery service such as OwnBackup.com. We do not have a relationship with the company other than limited exposure to the solution and the high ratings it has on Salesforce AppExchange. Do your homework.
Data backup includes two sides of the data management coin: the backup or extraction of data from your org and the recovery or the replacement of data into your org after a disaster. Any data backup solution needs to provide services in both directions. Recovery services are the most critical part of the solution. We remember back when on-prem solutions used a magnetic tape to store copies of data as a backup. More often than not, when the company tried to recover the data, the tape was severely damaged, or the process did not work.
Recover from data corruption.
Quickly restore one, a few, or all records in an object quickly.
Support mass restore and rebuild all associated and related data.
Recover metadata.
Restore process and automation seamlessly.
Restore system, process, and data integrations.
Data Archiving
An essential aspect of data management within Salesforce is to develop a data archiving strategy to offload from the active Salesforce instance. Salesforce provides minimal setup tools to archive data from Salesforce. See the “Data Backup” section.
- 1.
Organize the archive data for understanding.
- 2.
Make the archive accessible to the business.
- 3.
Establish processes to retrieve data elements and summaries.
- 4.
Retain valuable data, not trivial.
Salesforce Big Object
The cost of data and file storage in Salesforce can be expensive when compared to external options. That said, Salesforce does offer a solution for storing vast amounts of data to provide holistic views for data, such as customers and partners, storing audit and tracking data, and near-real-time historical archives. The solution is called Big Objects. Salesforce uses standard Big Objects to manage the FieldHistoryArchive, which is part of the Field Audit Trail projects. Salesforce now allows an architect to use the same non-transactional database for custom solutions.
The archive requirement is a great use case for this data option. Using custom applications to extract data from Salesforce relational database objects, you can create archive data to support the archiving plan listed in the preceding text. The Big Object is not available to the user experience as other objects are, and a custom interface is required to update and extract the data in the Big Object. That said, several AppExchange applications are available to support these requirements .
It uses a horizontally scalable distributed database.
It is a non-transactional database.
It can process hundreds of millions or even billions of records efficiently.
Data deleted programmatically, not declaratively.
You cannot use standard Salesforce sharing rules.
You must use custom Lightning and Visualforce components rather than standard UI elements, home pages, detail pages, and list views.
You cannot have duplicate records in Big Objects.
You cannot encrypt Big Object data .
Chapter Summary
That data moves through a continuum from data to knowledge, as understanding improves.
That data management includes intake, storage, processing, and presentation throughout its lifecycle.
The importance of the data architecture as it relates to the overall instance design and that data modeling is more than the creation of an Entity Relationship Design (ERD).
That high-level data modeling concepts are needed to select the right design as it relates to business processes, data movement, and optimization. Your data model selection requires choices and compromises to optimize it from your organization.
That large data volume (LDV) management involves using the tools provided and the knowledge to apply them appropriately. Understanding what causes LDV issues makes solving them more manageable.
That data lifecycle management involves more than operational data. It starts with the initial migration and continues through backup and restore and data archival.
That using available Salesforce resources, such as Big Objects, can solve difficult data lifecycle issues.