
Hit Counters
On Web pages, you commonly see something called a hit counter or a visitor number indicator. Supposedly, it indicates how many times a Web page has been visited. An example of one is shown in Figure 23.3.
Visitor counters have lots of problems. First and foremost, what does that number mean? A high number of "hits" supposedly indicates that the page is popular. If it's popular, does that mean it's a good Web page? Not necessarily. If you're visiting a Web page, it either has the information you want, or it doesn't. The quality of the page is in its value to you, not to others.
Essentially, a hit counter is a kind of beauty contest—with blind judges. The number represented is not necessarily the number of people who've visited your page. At best, it's a wildly inaccurate estimate. Why are these counters so inaccurate? I can think of several reasons.
First, no rule says that a hit counter has to start at 0. When you were issued your last checkbook, was the first check #1? More likely, when you ordered the checks, you were allowed to pick the starting sequence number. If you're smart, you'll pick a high number so that it appears as if you have a long-standing account with the bank. A low number will make store clerks look twice at your ID and maybe consider not taking your check at all. Web site operators frequently set the hit counter initially high to make their sites look more "popular" than they really are.
Figure 23.3. Sample of a hit counter.
The second problem with hit counters is Web robots—also called spiders, crawlers, and so on. These automatic processes search the Web for data, sometimes simply to look for a specific piece of data and sometimes to build indexes of interesting Web sites. Have you ever wondered how AltaVista, Google, or HotBot build their indexes? They search the Web, fetch pages, and ultimately make hit counters go higher than they really should be.
The next problem is the Refresh button on Web browsers. Every time your page is "refreshed," the hit counter goes up a notch. You're not really measuring the number of "visitors" to your site if someone hits the reload button, are you?
Last—and most important—is the caching problem. In Hour 17, "Introduction to CGI," you saw a diagram of how the browser communicates with the Web server. It left out an important detail, which is shown in Figure 23.4.
If the Web browser is located within the domain of a large ISP such as aol.com or home.com with many millions of subscribers, that ISP uses something called a cache proxy. A cache proxy is a stand-in between your Web browser and the Web server. When you fetch a page, the request is sent to the proxy, which actually fetches the page for you over the Internet and sends it back to your browser—after it stores a copy of the page for itself (see Figure 23.5). If someone else in the same domain fetches the page, the proxy doesn't bother refetching the page over the Internet; it uses its saved copy.
Figure 23.4. Proxy server fetching the page for the browser.
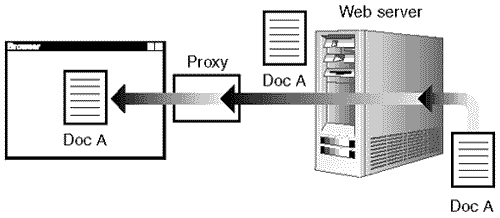
Figure 23.5. Proxy server retrieving a page from its cache.
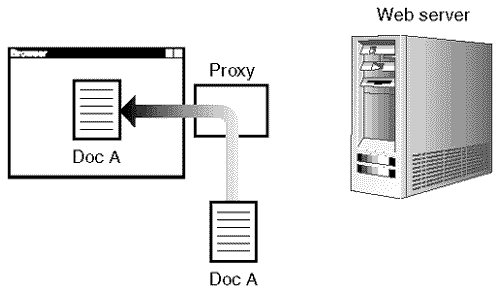
The proxy storing a copy of the page artificially deflates the number of hits that a hit counter shows. Strangely enough, it also causes the remote_host value to be repeated frequently, even though the page is fetched by many different people.
Note
Web surfers at large corporations and universities are often behind firewalls that act as caching proxies. Every page fetch that happens from one of these sites has the potential for missing the hit counter because it's being intercepted by a cache proxy.
And Now, A Hit Counter
After having read the preceding section, if you're still reading, you must be interested in writing a hit counter for your Web page. The two basic types of hit counters for Web pages are a simple text display and a graphical counter. The first example here is a text counter, and the next is a graphical one—and some ideas on making rather pretty hit counters.
To use the hit counter, include it as part of a server-side include, which you learned about in Hour 20. If you call the hit counter CGI program hits.cgi, you can include it in any page using SSI like this:
<!--#exec cgi="/cgi-bin/hits.cgi"-->
The source for the hit counter program is shown in Listing 23.3.
Listing 23.3 Hit Counter Program
Line 18: A lock is necessary because the hit-counter file will be read and written, possibly by many processes at the same time.
Lines 20–23: The contents of the file in $counterfile are read. This is the number of hits so far.
Lines 28–30: The hit counter is written back out to the file in $counterfile.
Line 32: Finally, the lock is released.
Most of the code in Listing 23.3 should not strike you as unusual. However, notice that file locking is used, and the example follows the file-locking formulas demonstrated in Hour 15, "Finding Permanence."
File locking is necessary in the case in which two people load the Web page at nearly the same time. If the reading and writing of the Web counter file is slightly out of sync, then the counter might increase too quickly or too slowly, or it might produce a corrupt file. These results would further diminish the accuracy of the counter.
Graphical Hit Counter
To spice up the hit counter, you could take three approaches. First, you could make up a graphic that represents each possible value of the hit counter and display it as necessary. That approach would be time consuming if you received more than a few visitors to the Web site.
Another approach is to have a Perl CGI program actually generate the necessary graphics to display the hit counter itself. The GD module, available from CPAN, is designed for creating graphics with Perl programs, so you could use it for this purpose. Unfortunately, covering the ins and outs of the GD module is well beyond the scope of this book.
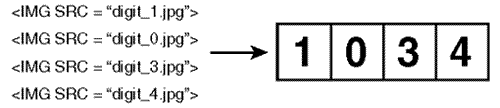
By far the easiest approach is to create 10 images, representing the digits 0 to 9. Then, as the hit counter increases, your program can simply emit HTML with <IMG> tags that put the digits in the right place (see Figure 23.6). You do, of course, have to create the images to represent the digits. The Perl CGI program in Listing 23.4 expects the images to be named digit_0.jpg, digit_1.jpg, and so on, up to digit_9.jpg.
Figure 23.6. Graphical hit counter output.
To use the hit counter, you can include it as part of a server-side include, as described in Hour 20. If you call the hit counter CGI program graphical_hits.cgi, you can include it in any page like this:
<!--#exec cgi="/cgi-bin/graphical_hits.cgi"-->
The source for this graphical hit counter is shown in Listing 23.4.
Listing 23.4 Graphical Hit Counter
Listing 23.4 is essentially the same as Listing 23.3, with some small changes.
Line 9: This line now contains in $image_url the base URL for the images that make up the digits. Remember, it must be the URL that the browser will see to load the images, not the path to the images on the local disk.
Lines 34–35: The number in the hit counter—$hits—is split up on every character and assigned to $digit one digit at a time. The <IMG> tags are then printed for each digit.