
Before we can get into the specifics on the internals of Web services, it is important to understand the communication fundamentals upon which they operate. In this hour, we’ll examine the communications mechanisms upon which Web services operate. We’ll examine the following topics:
Message queues for Web services
SMTP as a Web service transfer protocol
Jabber for Web services
Although it’s possible to get extremely low level in the discussion of these areas, it’s not really necessary for the level of this book to do so. Instead, we’ll focus more on how these protocols work from the standpoint of Web services.
One key feature of Web services is that they leave the definition of how to transmit the data over the network open ended. Although only HTTP was initially used to perform this transmission of data, newer standards have allowed for a wider range of communication protocols to be used—each with its own strengths and weaknesses in relation to the original HTTP mechanisms.
Because our focus in this hour is on the communications protocols rather than the content and structure of the messages, we’ll refer to data transferred (such as the SOAP XML messages) as the payload. You’ll see more about the specific payloads in later hours. For now, just consider the payload as some data that has to be transferred from one place to another in some way. This hour is about the “how it gets there” and not the “what is sent.” Regardless of which transport mechanism is used, the payload is the same.
Before we can talk about the various transport protocols that can be used for Web services communications, we must first establish a foundation of knowledge on how the Internet itself works. Before the Internet, computers were standalone entities. In most cases, the only way to connect and communicate from one machine to another was if both machines were identical in terms of hardware architecture and operating system. Even then, this was often a difficult endeavor.
Then in the late 1960s the U.S. military’s Advanced Defense Research Agency (ARPA) was tasked to create a computer networking system that would allow for computer-to-computer communications that would be somewhat reliable even if entire nodes of the network were destroyed in a nuclear war. At the same time, there was the goal of being able to link dissimilar computer networks together. Their solution was the TCP/IP stack. TCP/IP stands for Transmission Control Protocol/Internet Protocol.
TCP/IP is the foundation of all communications on the Internet today. It controls how computers interconnect and how information is routed around the network, as well as the processes that take place at each node to handle the connections. In reality, TCP/IP is actually two separate protocols. TCP is considered a transport protocol (not what we mean by transport protocol in the Web services sense though), whereas IP is the network protocol. The distinction is that IP handles the actual routing of information, whereas TCP (and UDP) handles the flow of data, how the packets are arranged and sent, and so on. Each of the protocols that we will discuss in this hour run on top of TCP and make use of the services that it provides.
In reality, there are two transport layer protocols to the TCP/IP stack: TCP and UDP. TCP can be thought of as a virtual circuit, which means a connection is established from the source to the destination through various nodes. As long as the connection is maintained, all packets of data will be sent along the same path and are guaranteed to be delivered in the same sequence that they were sent out. As a result, TCP is the method of choice for streaming communications. This involves a bit of overhead, but provides for reliable transmission. UDP (User Datagram Protocol), on the other hand, has much less overhead but does not guarantee delivery or packet arrival order. It instead sends small self-contained bundles of data that match the size of the underlying IP packets. It cannot be used for large datasets or streaming applications. For this reason, TCP is the protocol used by all the Web service transports we will discuss.
How does all this fit in together? Communications on the Internet are done in a layered approach. Figure 8.1 shows this layered system of communications. This layered approach is known as the OSI model.

As you can see, the protocols we will discuss later in this hour sit just below the actual Web service and provide an interface down to the TCP and IP layers, respectively.
Now that you have at least a basic understanding of TCP/IP, you’re ready to examine the different mechanisms for doing Web services communications.
The most popular protocol on the Internet, and the one that most people think of when you say the word Internet, is HTTP. HTTP (Hypertext Transfer Protocol) was originally created in the early 1990s to help scientists find and share information by enabling the easy linking of information from one document to another. It quickly has grown into much more though. However, just because Web sites use HTTP as their communication mechanism, does not mean that HTTP is restricted to the World Wide Web. In fact, the Web is just an application that uses HTTP to carry its informational payload between servers and clients.
Initial versions of the Web services specifications only provided for HTTP as the means of transport and communications between clients and services. As a result, many services at this time use HTTP, and it is the most common of all the transport protocols. All the examples you will find in this book use the HTTP transport mechanism. Newer versions of the specifications have opened up the possibilities though, and as you’ll see, those other transports have some advantages that HTTP doesn’t.
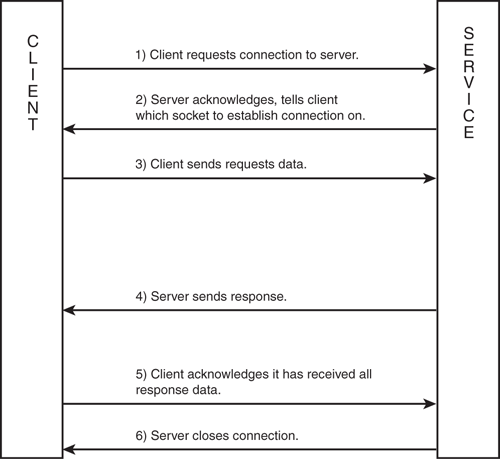
HTTP communications are established by a simple handshaking mechanism. Figure 8.2 illustrates this handshaking. In HTTP, communications are always initiated by the client machine. The client will make a connection to a server listening for HTTP requests. When the server receives the connection request, an acknowledgement is returned to the client, instructing the client which socket to communicate and send its request data through on. The client creates that new socket connection to the server and sends along some header information, as well as any parameters. This data is considered the request.
The server reads in this request and processes it in some way. After processing has been completed, it sends back any resulting data as a response. While the server is processing the request, the connection between the client and server stays open, and the client is effectively blocked, waiting for the response. After the client receives the response, it signals back to the server that it has received the data. At this point, the server terminates its connection with the client.
Now that you know how HTTP works, you’re probably wondering why it is used so much for Web services. HTTP provides Web services with some attractive features. The protocol is relatively simple to understand and code for. Web servers are built to handle large numbers of requests, and the software to write the server-side services is not very different from writing CGIs, servlets, or PHP/ASP/JSP scripts. Because HTTP traffic is considered relatively benign, most firewalls will allow HTTP traffic through without any special configuration. The protocol was designed to accept textual data in requests (or binary encoded as ASCII or as attachments), so it can easily handle XML on both the request and response side of the equation. Finally, HTTP is ubiquitous and standardized. The specification has been fairly stable for several years now, and its popularity in the WWW has forced vendors to stick with the standards or be cast out in the cold.
HTTP has issues though. There is no guaranteed delivery of data sent via HTTP. If you need that capability, you’ll have to add it to your client and service code. As we said earlier, HTTP-based clients are forced to block until they receive a response from the service. This sort of synchronous behavior can impede scalability and is often not desirable in business systems.
Message queues have been a staple part of enterprise information systems for many years. They are exactly what their name implies—a queue that can contain messages. We deal with queues in computing all the time though. What makes these types of queues important is that they are used to connect systems together in a way that provides for three important facets of intersystem communications: reliable delivery, scalability, and loose coupling.
It is important to note that message queues are unidirectional. If you need communication in both directions, two separate queues are needed—one on each side of the communication process. Figure 8.3 shows how message queues fit into the Web services arena in comparison to the HTTP transport mechanism.

Messaging queue technology is considered reliable because the messages that enter the queue can be set to stay in the queue until they are delivered. If the intended recipient of the message happens to be disconnected or unreachable when the message enters the queue, the message will remain there until the recipient reestablishes a connection. At that time, all messages destined for that recipient will be delivered. More importantly, the messages will arrive in the order in which they entered the queue (hence the reason it’s called a queue and not a pool). Unlike HTTP-based Web services, ones that use message queues as their transport protocol don’t have to tack on structures to guarantee delivery or reliability; it’s inherent to the transport itself.
Message queues can work in one of two different modes. The first mode, called point-to-point, provides a communication capability from one sender to a receiver. A pair of queues are set up for that one, and only that one, pair of connections. One queue handles requests going to the server; the other handles replies coming back to the client. Only messages for that recipient are stored in the queue.
The second mode is publish-subscribe, where multiple recipients ask (or subscribe) to listen in on the queue for messages. The producer of the messages creates (or publishes) new messages in the queue. This is analogous to subscribers of a magazine or newspaper. A single producer (the publisher of the magazine or newspaper) disseminates information to all of its subscribers.
The second mode is extremely useful in Web service situations that need to operate in an event-driven mode. Clients hook into the queue and can listen for messages that are important to them. They can then trigger activities to occur on the client whenever one of those messages is encountered in the queue. In fact, once connected to the queue, the client does not have to send any other information to the service at all. It simply waits and listens. As such, the client and service are bound asynchronously.
This is very different from the HTTP approach in which all communications are performed in a strictly request-response mode, where a client sends a request and must sit and wait for the response from the server. Such a synchronous operation can impair scalability because it ties both the client and the server together for a period of time and can block access to resources from other processes.
As such, the asynchronous nature of message queues adds to their capability to scale up. Clients now can pop a request onto the service’s incoming queue, and then decouple themselves and do other things. The service can process the message when it gets to it, and then respond back the same way by publishing to another queue. The client returns when the message is delivered, so no resources are tied up while waiting for processing to complete.
If message queues are so wonderful, why aren’t they used by all Web services? First, setting up and managing the message queue has traditionally been much more complicated than HTTP-based packages. Second, there is an interoperability problem in that most vendor’s messaging queues don’t work well together. For example, a client written using Microsoft Message Queue can’t communicate with a service using IBM’s WebsphereMQ. As a result, this solution really only works if you control both sides of the equation: the clients and the service. However, although there is no standard wire protocol for the various message queue implementations, some abstraction API layers out there (such as Java Message service) allow the developer to write to a common API while using different underlying message queue products. Third, most message queue software requires special port numbers. One of the design goals of Web services was to enable easy communications through firewalls, and opening of ports is often not easy because of security concerns.
Even with the limitations, the use of message queues for Web services is on the rise. It is entirely reasonable to expect that the services that are the most robust (in terms of fault tolerance), most reliable, and most scalable will be written using message queues for their transport mechanism.
Unless you’ve lived on another planet for the past 30 years, you’ve at least heard of email even if you haven’t used it daily. We all know what it does, but far fewer know how it actually works. What happens after you click that Send button? How can we use email for Web services?
In reality, we’re not using email for Web services per se. Instead, we’re really using the underlying system responsible for the management and delivery of email. That mechanism is called Simple Mail Transport Protocol, or SMTP for short. Let’s briefly look at how SMTP works.
Conceptually, SMTP is the electronic equivalent to the U.S. postal system. When you create an email message and click the Send button, several things happen. First, the message is encoded into a special textual format. Attachments are transformed from binary to a textual representation and labeled with an encoding type flag, referred to as a MIME-type (Multipurpose Internet Mail Extensions). All the data for the message is then sent into a spooler on the server.
Once it’s on the server, the message header is examined to see if the Send To address corresponds to anyone on the local mail system. If so, the message is placed into a queue for that user to read the next time he checks his email. If the intended recipient isn’t local, the server then passes the message along to some other server upstream. This passing along of the message happens over and over—with each server along the way receiving the message, storing a copy of the message, checking to see whether the message can directly be delivered, and then forwarding it along to the next server until the message eventually finds it’s way to a server that the recipient’s account is on. This type of mechanism is referred to as store and forward. Each server along the path of delivery stores (either temporarily or permanently) a complete copy of the message. For this reason, email is not considered a safe way to send unencrypted data because every machine along the delivery path has the opportunity to intercept the message.
You’ll also notice that nothing in the email designates the routing path that the message must take to get to the recipient. When you type in a delivery address of [email protected], you’re not telling your server how to contact test.net, only that the message needs to get to that server at some point. If your server has routing information for how to directly find test.net, it will send the message directly from your server to the destination server. In most cases, however, your mail server has no knowledge of the destination server. In these cases, your server will pass the message upstream to some other server. In fact, it’s entirely possible that two messages being sent from the same person to the same recipient might take completely different paths, go through a different number of servers, and arrive in an order different than how they were sent. Figure 8.4 illustrates the SMTP store-and-forward and routing system.

Email (again, much like the U.S. postal system) is also considered an unreliable delivery mechanism. There is no guarantee that your message will ever reach its destination. This isn’t as much of a problem as it used to be in the early days of the Internet when messages would sometimes be “lost in the ether.” However, it does still happen on occasion. Email has a max hop count limit embedded in its header information. If the number of servers that the message has traveled through exceeds this limit, the server that has the message at that time will no longer attempt to send the message on. Instead, it will attempt to send a message back to the originator of the message to indicate that the message could not be delivered. Even this message is not guaranteed to be delivered though!
After looking at how the SMTP system works for email, you’re probably wondering why you would ever want to use it for Web services. Unreliable, out of order delivery with simple eavesdropping and so on doesn’t sound like a very robust system at first. However, for all its faults, SMTP has several good points in its favor.
First, similar to HTTP, SMTP traffic is usually allowed through firewalls. This means that it is often simple to get a system deployed in a corporate environment without the security folk raising a minor temper tantrum.
Second, even more so than message queues, SMTP-based systems are extremely asynchronous. It might take days before a request arrives at the destination and several more days before a response is sent back. SMTP systems also can take advantage of concepts such as mailing lists to mimic the publish-subscribe model that makes message queues so attractive.
Third, because of the nature of SMTP, with the messages being stored on server machines until they can be delivered, it is possible to send a message to a recipient that might not be available 100% of the time. With SMTP as the transport, the mail server at the service end will hold onto all the received Web service requests (spool them). Then when the service becomes active, it can process those requests and mail back out the responses. The client’s mail server will then receive and likewise spool the response messages until the client checks his mail again. This is just like email. For the right system, this capability to be used for a partially connected system can be a powerful feature.
In situations in which timely, in-order response is not a necessity, you can’t go wrong with SMTP. It is technology that has been around for more than 25 years and is well understood. The servers supporting SMTP are robust, scalable, and built in to or available for nearly every server operating system produced.
For Web services to work on SMTP, the payload must follow certain rules of behavior. First, the SOAP message must be processed as a MIME attachment with a content type of text/xml. The content is typically base64 encoded. Second, if the case in which a request-response type mechanism is desired, the same subject line for both the request and response should be used. The request should include a message-ID in its header information, and the response should contain the same message-ID in the In-Reply-To header field, along with a new message-ID. By using these message-IDs, a form of message ordering and pairing can be established to place some order on the apparent chaos of the SMTP delivery system for your clients and services.
Another of the tried and true staple protocols of the Internet is FTP, which stands for File Transfer Protocol. FTP is designed to facilitate moving files from one machine to another. It can handle both text and binary data without the need for translation. One of the strengths of FTP is its capability of working with large sets of data.
FTP works slightly differently than the other protocols we’ve discussed here in that it makes use of two connections to transfer information. The first connection, referred to as the command connection, is established and remains open throughout the life of the communications. This connection is where commands associated with the sending of information and the determination of status and authentication are processed.
The second set of connections, referred to as the data connection(s), are established and maintained only for the duration of a single data transfer. For instance, the command to transfer a request is sent over the command connection to inform the service that it should be waiting for data. After the server acknowledges this request, the client creates a new data connection to the service and the data is pumped through it. After the data is all received, the data connection is terminated, but the command connection remains. When the service is ready to send back the response, another data connection is established and the response message is received by the client. Figure 8.5 illustrates this sequence of events.

Because the data is transferred on its own connection and that connection is dedicated for that purpose, very little overhead is required. This helps FTP maintain extremely quick transfer speeds. However, it also must maintain the command connection throughout the lifecycle of the transaction. FTP usually is not fault tolerant (although some implementations do have this capability). If the connection is lost, so is the data. Connectivity must be maintained.
FTP also is considered a security risk because of its capability to drop files, as well as streaming data into another machine. As such, most network administrators restrict its use through firewalls. If you need to communicate through firewalls or be fault tolerant, use one of the other solutions. However, if your service and clients are all located behind the firewall, FTP is an extremely fast protocol for large-scale communications.
One of the quickest growing applications on the Internet over the past several years has been instant messaging. A number of competing systems have evolved that provide real-time, text-based communications between users. Some of the most popular are AOL’s Instant Messenger, ICQ, Yahoo! Instant Messenger, MSN Messenger, and IRC. Although all these products work in a similar manner, each has been reluctant to open its chat networks to the others. Many provide programming APIs to allow for the development of new applications, but all (except IRC) use proprietary, closed network protocols. This has been a headache for many users who end up running several clients on their machines just to chat with friends on different networks.
In an attempt to fix this, the Jabber project was started. Jabber’s goals were not only to provide a way to communicate with users of all chat engines, but also to provide an open communication architecture upon which other software could piggyback. Jabber refers to this as Extensible Instant Messaging.
The results of this effort are the Jabber system we have today. Jabber communicates using XML, provides peer-to-peer communications, and provides both API- and communication-level interfaces for developers to work with. Jabber also is capable of operating through firewalls, which gives it an advantage over transport solutions such as FTP and message queues.
Communications in Jabber typically initiate with a client making a request to send data to a recipient (in this case, the service). The request is sent to the Jabber server, where the client’s account is authenticated. The server then attempts to contact the destination service node. If the connection can be made, it relays the payload message to the service. The service can reply in a similar manner. If the Jabber server can’t find the recipient locally, it can automatically contact other Jabber servers to ask them to attempt to deliver the content. Once the communications are established, the Jabber server acts simply as a relay mechanism, and the client and service are linked logically as though they were communicating in a peer-to-peer fashion. Figure 8.6 shows this communication configuration.

When using Jabber for Web services, communication scalability, fail-over, and load balancing are easily established through the addition of more Jabber relay servers. Jabber is the newest of the protocols we’ve looked at though, and as such, fewer toolsets support it for communications. Its acceptance is growing rapidly, however, and this limitation should diminish over time.
In this hour, we’ve looked at some of the transports available for use by Web services. We discussed how TCP/IP forms the underlying foundation of all communications on the Internet. We then saw how HTTP communicates and why it has been the predominant protocol for Web services.
Next, we examined the features and capabilities of transports such as message queues, SMTP, and FTP. We also saw how Jabber can be used to facilitate Web services.
Along the way, we examined the strengths and weaknesses of each of these protocols. With this knowledge, you should be able to choose the right protocol for your needs when building Web service solutions.
This section is designed to help you anticipate possible questions, review what you’ve learned, and begin learning how to put your knowledge into practice.