
WEEK 1 Day 3
Selecting Data
Yesterday you learned what a stylesheet is and how to use it. You also learned about using templates and getting values from an Extensible Markup Language (XML) document. So far the expressions you’ve used to match templates and select data have been rudimentary. What you can do at this point therefore is limited.
Today’s lesson will focus on getting more control over the data you select. Today you will learn the following:
• How the XML document tree works
• What XPath is
• How you can select single elements
• How you can select multiple elements
• How you can select attributes
Understanding the XML Document Tree
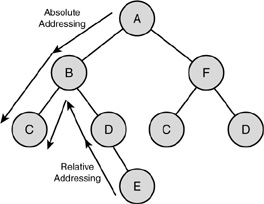
An XML document is a hierarchical structure of elements. Each element in an XML document can have zero or more child elements, which in turn have that same property. Also, each element can have zero or more attributes. No surprises so far, but it’s actually significant that an XML document is structured this way. Every element and every attribute has a uniquely identifiable place within the document tree. Because all elements and attributes are uniquely identifiable, you can address a single element or attribute and get its value. Figure 3.1 clarifies this structure.
FIGURE 3.1 Graphical representation of a tree.
NEW TERM
In Figure 3.1, each element in the tree is shown as a circle. Different children of an element can be distinguished because different letters identify them. As you can see, some elements have children with the same letters to identify them. This means that you can’t say “Give me the value of element C,” because element C can be the child element of either element B or element F. This doesn’t mean, however, that you can’t address this element at all; you just have to be more specific. To get the value of a specific element, you would have to say “Give me the value of element C, the child of element B, which is the child of the root element A.” When you address an element in this manner, you use absolute addressing, as shown in Figure 3.1. Absolute addressing means that you specify the exact location of an element within a tree. With absolute addressing, you always specify a unique location.
NEW TERM
Another way of addressing is relative to an element. Say that element E in Figure 3.1 is the element’s starting point. If you want to address the same element as before, you can say “Give me the value of element C, the sibling element of my parent element.” This type of addressing is called relative addressing, as shown in Figure 3.1. Relative addressing means that you specify the location of an element within a tree relative to the position of the current location.
With relative addressing, you don’t specify a unique location within the document tree. Which element is specified by the preceding query actually depends on the starting point of the query.
What Is a Node?
Until now, I have been talking about elements and attributes. The difference between elements and attributes is not that great, however. The most important difference is that an element can have child elements; an attribute cannot. Hence, an attribute always has a single (text) value, whereas the value of an element also includes any descendant elements (and attributes).
Because elements and attributes aren’t very different, they can be represented as the same thing in a diagram of the XML document tree. Element E in Figure 3.1, for example, could just as well be an attribute because it doesn’t have any child elements. In fact, some people think that attributes shouldn’t be used because attributes are just special cases of elements. Attributes and elements are interchangeable, as long as an element doesn’t have child elements (or attributes). Because attributes are simply names with associated values, also known as name-value pairs, an element can contain only attributes that have different names. An element value, on the other hand, can contain multiple elements with the same name. This distinction is very important when you’re designing XML documents, especially when they might have to change in the future.
NEW TERM
Within the Document Object Model (DOM), as well as Extensible Stylesheet Language Transformations (XSLT, or actually XPath), the distinction between an element and attribute is so small that they are treated more or less as being the same. Several functions in DOM Level 2 work equally well on elements and attributes. The functions nodeName and nodeValue make no distinction between elements and attributes, although the result may differ based on the type of node the function is used on. Because an element and an attribute are very similar, they are referred to as a node, which is a single item that contains data within the document tree.
Current Node
On Day 2, I used the term current element tentatively. Although this concept is somewhat self-explanatory, some clarification is in order. Also, because of the similarities between elements and attributes, from now on I will use the term current node.
NEW TERM
On Day 2, you saw that when a stylesheet processes an XML document, elements of the source XML are matched against templates in the stylesheet. What you haven’t learned yet is that you can also create match expressions that match an attribute. So, actually, nodes of the source XML are matched against the templates. Each time a match occurs and a template is invoked, the node that fired the template becomes the current node, which basically is a pointer to a node within the XML tree. This pointer keeps track of which node is being processed.
If you’re working with an XSLT debugger that enables you to perform the transformation process step by step, you can see which node is the current node. The debugger keeps track of the current node and the template that is being fired and shows that information to you.
NEW TERM
Because the current node is just a pointer to the node being processed, a template is not limited to accessing the value of that node alone. Within a template, you can use absolute addressing or relative addressing to get the value of any node in the XML document. As I said earlier, this value isn’t necessarily a single value. If an element has attributes and descendant elements, they are also part of that value. Such a value is called a tree fragment, which is a part of an XML document tree, starting at a specific node. A tree fragment is itself a well-formed XML structure or document.
You already saw tree fragments in action on Day 2, when you learned about the text () function that extracts only the text value of an element. If you just specify the value of an element, the text of the element and all its descendants is written to the output. That is, in fact, the text value of the tree fragment. To get a better idea what a tree fragment is, look at Figure 3.2.
FIGURE 3.2 Tree fragment of node T.
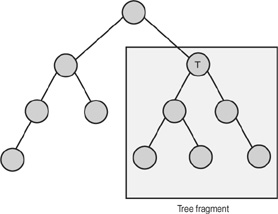
Figure 3.2 is a graphical representation of a tree fragment. In this case, the tree fragment belongs to node T. This is actually the same as the value of node T.
What Is a Node-Set?
Now that you know what a node is, you probably think that a node-set isn’t hard to explain. It’s a set of nodes, right? Well, yes, but that’s not all of it.
When you make a selection based on an expression, the expression doesn’t necessarily match one node. It may match several nodes. These nodes together are called a node-set. The most common node-set is a series of an element’s child nodes. Some people think this is the only kind of node-set, but it isn’t. You can easily create an expression that yields a node-set with nodes in different sections of an XML document. Figure 3.3 shows an example.
FIGURE 3.3 Node-set containing nodes scattered throughout an XML document.
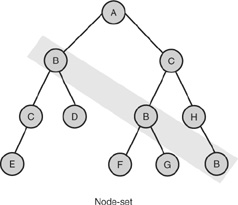
Figure 3.3 represents the node-set you would get if you were to say “Give me all nodes named B.” As you can see, the node’s location in the XML document tree is not relevant. Any node matching your query is part of the node-set. The node-set in Figure 3.3 is composed of several nodes. From those nodes, you have access to the tree fragment composed of that node and its descendants. If the expression targeted only attributes, the node-set would consist of only single value nodes.
Node-sets are essential in XSLT. They enable you to create a table of contents, indexes, and all sorts of other documents in which you use data that is scattered throughout an XML document. This capability enables you to create different outputs for different purposes from the same XML source document.
Understanding XPath
So far, this lesson has been all theory. You need this theory as a foundation for practical application, which is what the rest of this lesson is all about.
XSLT wouldn’t work if it didn’t have some kind of mechanism to match and select nodes and act on them. You need to be able to express which node or nodes should match. This is what XPath expressions are for. XPath is the language you use to specify which node or nodes you want to work with. Expressions in XPath can be very simple, pointing to a specific location within a document tree using absolute addressing. You can, however, make selections based on very complex rules. As you work your way through this book, you will learn to create more and more complex expressions. But, of course, you need to start simple.
Selecting Elements
If you’re familiar with addresses on the World Wide Web, the most basic XPath expressions are easy to understand. A Web site is a hierarchy of files, just like an XML document is a hierarchy of elements. If you visit a Web site, you specify its root with the name of the Web site. For example, http://www.somesite.com points to the root or home page of the Web site. This is the same as http://www.somesite.com/, which is actually more accurate. What comes after this part of the address specifies where in the hierarchy of the site you want to be. So, http://www.somesite.com/menu/entrees points to the index file in the entrees directory, which is a child of the menu directory, which is a child of the root directory. The /menu/entrees path is especially interesting. It uniquely identifies a location within the Web site hierarchy, as shown in Figure 3.4.
FIGURE 3.4 Web site hierarchy.
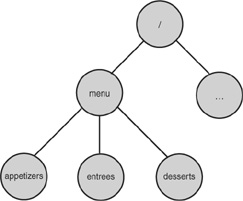
Figure 3.4 shows part of the hierarchy for the Web site. Notice that /menu/entrees uniquely identifies the entrees node in the tree. If you want to select the desserts node, you change to /menu/desserts. Now look at Listing 3.1.
LISTING 3.1 Menu in XML Corresponding to Figure 3.4
Note
You can download the sample listings in this lesson from the publisher’s Web site.
ANALYSIS
The XML in Listing 3.1 has the same tree structure as that of the Web site depicted in Figure 3.4. So, just like in the Web site, /menu/entrees points to the entrees element in the XML document. Pointing to a certain node in an XML document with XPath is, as you can see, very simple. It is based on principles that you have probably used before, so they’ll be familiar to you, even though you’ve never worked with XPath before. To see how this approach really works, look at Listing 3.2.
LISTING 3.2 Stylesheet Selecting the entrees Node from Listing 3.1
ANALYSIS
The template on line 5 matches the root element of the source document. The value retrieved on line 6 is selected using the expression /menu/entrees, which matched the entrees element that is the child element of the root element menu. The result from applying Listing 3.2 to Listing 3.1 is shown in Listing 3.3.
LISTING 3.3 Result from Applying Listing 3.2 to Listing 3.1
Note
Be aware that the preceding sample was run with the Saxon processor. If you use another processor, the result might be slightly different. MSXSL generates UTF-16 output by default, so the result when using MSXSL will have spaces between each letter.
ANALYSIS
Listing 3.3 shows the value of all the child nodes of the entrees node. If you remember yesterday’s lesson, that is exactly right, as line 6 of Listing 3.2 asks for the value of the entrees node. That node’s value contains all its descendant nodes. Getting its value yields the text value of the descendant elements. This scenario is a bit confusing because it looks like Listing 3.2 actually selects a node-set consisting of all the child elements of the entrees node. If the entrees node also contains a text value, you would see that this isn’t true. You can, however, create an additional template to handle the dish elements, as shown in Listing 3.4.
LISTING 3.4 Stylesheet with More Control over dish Elements
ANALYSIS
In Listing 3.4, note that lines 9 and 16 effectively ignore the appetizers and desserts nodes in Listing 3.1 to keep the result small and to the point. The result of applying Listing 3.4 to Listing 3.1 is shown in Listing 3.5.
OUTPUT
LISTING 3.5 Result from Applying Listing 3.4 to Listing 3.1
ANALYSIS
In Listing 3.5, each dish node is now handled separately. The hyphen (-) in front of each dish shows that this is really the case. The whitespace appears, as I said before, because of the processor’s default whitespace rules.
Getting the Value of a Single Element
The problem with the code shown so far is that it acts on an element or a set of elements. Within the set of elements (such as the dish elements), no one node is singled out. If you also address a dish node instead of matching it with a template, a reasonable assumption would be that you will get the value of a single dish node. Listing 3.6 tests this assumption.
LISTING 3.6 Stylesheet Getting the Value of a dish Element
ANALYSIS
In Listing 3.6, the template on line 11 matching the entrees element selects only the value of a dish node on line 12. Note that, compared to Listing 3.4, there is no template matching the dish element. The result for Listing 3.6 is shown in Listing 3.7.
OUTPUT
LISTING 3.7 Result from Applying Listing 3.6 to Listing 3.1
ANALYSIS
In Listing 3.7, the assumption made for Listing 3.6 is correct. Getting the value of a dish node yields the value of exactly one dish node. But what happened to the other nodes? After all, the xsl:value-of element matches dish nodes, so it, in fact, matches a node-set. The fact that you get a single value is again a result of the default behavior of XSLT. If a node-set matches a xsl:value-of selection, only the value of the first element in the node-set is used. The first element is the one that comes first in the source XML, according to the selection—in this case, the Grilled Salmon.
Now a new question arises: How do you specifically select another element in the node-set? Fortunately, you can just specify the number of the element you want to select. This, however, deviates from the path notation you are familiar with from Web sites. You need to place the number of the element you want to select between square brackets, [ and ]. Hence, you select the third dish element like this:
<xsl:value-ofselect=”dish[3]” />
In many programming languages, a list of elements is numbered from 0, so element number 3 is actually the fourth element in the list. XSLT numbers a list starting with 1, so element number 3 is the third element.
NEW TERM
The value between the square brackets is called a predicate, which is a literal or expression that determines whether a certain node should be included in the selection.
Note that the preceding example uses relative addressing, which means that the selection is done based on the current location. If that is the entrees element, the third dish element in the entrees element is selected. If the current node has no child elements named dish, the value is empty.
Because predicates can be expressions, they can become quite complex, testing whether an element conforms to certain criteria. As I said at the beginning of this section, I’ll discuss more complex expressions later in this book. The object now is to make you familiar with the building blocks, so let’s proceed with an example based on what you’ve seen so far. The example in Listing 3.8 creates a menu of the day from the sample XML in Listing 3.1.
LISTING 3.8 Stylesheet Creating “Today’s Menu”
ANALYSIS
Listing 3.8 has only one template on line 5, matching the root element. This template displays the values for different elements in Listing 3.1 using absolute addressing and number predicates. Line 7 selects the second dish element in the appetizers element; line 8, the third dish element in the entrees element; and line 9, the first dish element in the desserts element. Listing 3.9 shows the result.
LISTING 3.9 Result from Applying Listing 3.8 to Listing 3.1
ANALYSIS
Listing 3.8 contains only a template matching the root of the XML source. The rest of the stylesheet’s functionality utilizes absolute addressing to get the wanted values. As you can see, this yields a list of dishes that form today’s menu.
NEW TERM
Earlier, you learned about the current node. After a template is fired, a certain node is considered the current node. A path expression doesn’t contain a current node, but it does consist of context nodes. A context node is a part of an expression that operates on a certain node.
The predicates used in Listing 3.8 operate on the context node—in this case, the dish node. At one point or another, each part of the path’s expression is the context node. It, however, is relevant only when you’re working with predicates in a path expression. You can have predicates at several stages within the path expression, in which case the context node is the node that the predicate operates on.
You must realize that if no match occurs, nothing happens. This is also the case if a predicate holds a number for which no element exists. In that case, the number is just ignored. You don’t see an error message or anything telling you that an element is missing. The clue is not that an element is missing, but rather that no element matches that particular rule, so the rule is never applied.
Selecting Attributes
So far, you’ve learned only about elements. But what about attributes? Earlier, I said that elements and attributes don’t differ very much, so you might expect that you can address them in the same way, as Listing 3.10 tries to do.
LISTING 3.10 Stylesheet Trying to Select Attributes
ANALYSIS
Line 8 in Listing 3.10 tries to get the value of the price attribute of a dish element. That this approach doesn’t work is obvious from the result in Listing 3.11.
OUTPUT
LISTING 3.11 Result from Applying Listing 3.10 to Listing 3.1
ANALYSIS
The value-of element in Listing 3.10 doesn’t yield a result. A gap appears in the result because no element matches the select expression. That is as it should be, because no price element exists. The dish element does, however, have a price attribute, which is what Listing 3.10 is supposed to select. What’s wrong?
Nothing is wrong. You just need to tell the processor that it needs to match an attribute, not an element. You can tell the processor that you’re looking for an attribute by adding the @ character in front of the name. So, if line 8 in Listing 3.10 is supposed to point to an attribute, the path expression should be /menu/desserts/dish[2]/@price, as shown
in Listing 3.12. The result in Listing 3.13 is now correct.
LISTING 3.12 Stylesheet Correctly Selecting an Attribute
OUTPUT
LISTING 3.13 Result from Applying Listing 3.12 to Listing 3.1
Listing 3.12 produces the desired result. Because attributes don’t have any child elements, you also know that no side effects will occur. The value of the attribute is always text.
Note
Attributes can have data types, but all are based on the text value. Data types will be thoroughly discussed on Day 10, “Working with Data Types.”
Because attributes don’t have side effects, they are much easier to work with. Also, because all attributes of an element need to have a different name, you have no trouble with matching multiple attributes (and getting only the value of the first). The only way you can get multiple attributes is to start working with selections based on a wildcard character.
Another point to consider is that attributes take less space in a document than elements. Elements have begin and end tags; an attribute doesn’t need these tags. Because attributes have only a text value, a parser or processor can deal with them more quickly because it doesn’t have to check for child elements. This is likely to have a positive effect on performance.
Beyond the Basics
Until now, the discussion has targeted single nodes wherever possible. In fact, the focus has been on how to avoid selections that yield more than one node. Although this information is very useful to get you started, it really limits your capabilities. Without creating complex expressions, you can already perform many tasks with some of the basic functionality XPath provides.
Using a Wildcard
Wildcard characters are common in most search-oriented functions and languages. XPath has only one wildcard character: *. You can use it only to match entire names of elements or attributes, so the expression a* does not match all elements starting with the letter a. This expression generates an error instead. Wildcards are useful when you want to drill deeper into the source XML, and the names of certain nodes (particularly parent nodes) don’t matter. Listing 3.14 shows how to use a wildcard.
LISTING 3.14 Stylesheet Using a Wildcard
ANALYSIS
Line 5 in Listing 3.14 uses a wildcard character, so it doesn’t matter whether the matched dish element is a child element of the appetizers, entrees, or desserts element. Line 6 just shows the value of the matched dish element. Listing 3.15 shows the result.
OUTPUT
LISTING 3.15 Result from Applying Listing 3.14 to Listing 3.1
ANALYSIS
In Listing 3.15, the result yields all the dish nodes, not just those that are child nodes of a particular node.
You can use this technique in all kinds of situations. Say that you’ve created a white-paper or book using an XML document. Using a wildcard, you can select all the chapter and section headers to create a table of contents. If you don’t want to get all the nodes, using just the wildcard doesn’t solve your problem. However, just as with the path expressions you saw earlier, you can use predicates to refine the expression. That way, you have more control over what the wildcard actually matches. A simple example is shown in Listing 3.16.
LISTING 3.16 Stylesheet Using Wildcards and Predicates
ANALYSIS
Listing 3.16 yields the same result as Listing 3.12; the result is shown in Listing 3.13. Instead of addressing nodes by name, line 8 in Listing 3.16 uses several wildcards aided by position predicates. The desserts element is the third child element of the menu element. The /menu/*[3] section of the path expression tells the processor to take the third child element of the menu element, with no regard to the name of that element. That expression yields the desserts element, just as if it had been named. The attribute chosen is also based on a wildcard. In this case, the expression tells the processor to take the second attribute of the dish element, which is, of course, the price attribute.
Working with the Document Tree
NEW TERM
What you’ve seen so far is quite rigid in utilizing the XML document tree. XPath can do much more, based on location paths, which are expressions that select a node or node-set relative to the context node. A location path consists of several parts. The path expressions you’ve seen so far often are specific cases of location paths, starting from the root node or current node (from a matching template). Location paths can, however, appear in other instances and as part of a predicate within a path expression. One part of a location path is actually a predicate, so you can have a location path with a predicate, containing a location path containing another predicate, and so on.
NEW TERM
Another part of a location path that you are already familiar with is called a node test, which is the part of the location path that matches a certain node or nodes. This definition is clearer with an example. Consider the following location path:
Here, menu, *, dish, and @* are node tests.
NEW TERM
The last (or actually the first) part of a location path may not be familiar to you yet. This part, called an axis, is an expression specifying the relationship within the document tree between the selected nodes and the context node.
In the previous examples, you saw quite a few location paths. Not all of them contained axes, however. Well, they did, but the axes were included implicitly. Look at the following location path:
/menu/desserts/dish
This location path selects all the dish elements, which are child nodes of desserts nodes, which in turn are child nodes of the root element menu. If you write out that location path in full, it actually reads
/child::menu/child::desserts/child::dish
The axis and the node test are always separated by a double colon. The axis in front of the node test tells the processor where to look for a node or node-set. The node test tells the processor which nodes to actually match. Using the explicit location path isn’t very useful for match templates. The location path only becomes lengthier and less readable. Also, you would not often use the child axis because it is included implicitly anyway.
Another axis you are already familiar with is the attribute axis. You are actually familiar with its shortcut, the @ character. In Listing 3.12, the following location path was used on line 8:
/menu/desserts/dish[2]/@price
You also can write the @price selection using the attribute axis, which would yield the following location path:
/menu/desserts/dish[2]/attribute::price
An axis that you haven’t yet encountered but is quite clear is the parent axis. Yes, you guessed it: It returns the parent node of the current context. Listing 3.17 shows an example using the parent axis.
LISTING 3.17 Stylesheet Using parent Axis
ANALYSIS
Line 8 in Listing 3.17 uses the parent axis to select the title attribute of the parent element. This is the parent element of the current node, which is one of the dish elements in the appetizers element. Listing 3.18 shows the result.
OUTPUT
LISTING 3.18 Result from Applying Listing 3.17 to Listing 3.1
ANALYSIS
In Listing 3.18, the title attribute is inserted with every dish. This could also have been done with absolute addressing, but if there had been a separate template for the dish element, dishes in entrees or desserts could also match and the title would need to be different. In that case, relative addressing using the parent axis would be the only way out.
There is another way to specify any parent node. If you’re familiar with the command prompt from DOS or Unix, it will look familiar. The location path
parent::*/@title
can also be written as
../@title
The latter example is much more compact and usable. If, however, the node test is not a wildcard, using this location path would not work. You would have to specify the parent axis explicitly, as well as the node that the node test needs to match.
Multilevel Axes
The axes discussed so far cover a single level in the XML document tree. They either go one level down, to child nodes, or one level up, to the parent node. Several axes operate on multiple levels. This does not mean, however, that such an axis returns a tree fragment because that wouldn’t give added functionality. If that were the case, the parent and child axes would suffice. Each multilevel axis yields a node-set containing all the elements within that axis. The order in which the elements appear in the node-set depends on the axis. So, you can actually think of a multilevel axis as part of the XML document tree “flattened” into a set.
The best way to show you how these axes work is to go through some examples. The easiest axis to start with is ancestor, which is shown in Listing 3.19.
LISTING 3.19 Stylesheet Using the Ancestor Axis
ANALYSIS
All the action occurs in Lines 6 and 7 in Listing 3.19. Both lines first select the first child node of the appetizers element named dish. At that point, this element becomes the context node. Next, the ancestor axis tells the processor it wants to act on the ancestor nodes of the context node. The ancestor nodes are appetizers and menu. On line 6, the node test consists of a wildcard and predicate—in this case, pointing to the first ancestor node in the axis, which is the parent node appetizers. On line 7, a named node test specifies that the menu element is the element needed in this particular axis. This line could also have been written as ancestor::*[2] because that is the grandparent of the context node and, as such, the second node in the axis node-set ancestor.
LISTING 3.20 Result from Applying Listing 3.19 to Listing 3.1
ANALYSIS
Listing 3.20 shows that Listing 3.19 first selects the title attribute of the appetizers element and then the title attribute of the entrees element.
Several more multilevel axes are available. All axes are listed in Table 3.1.
TABLE 3.1 Available Axes
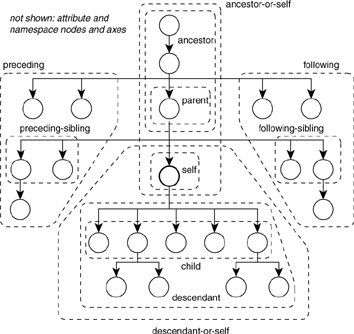
Figure 3.5 shows a graphical representation of most axes in Table 3.1 to give you a better idea of what each axis listed actually selects.
FIGURE 3.5 Graphical representation of the axes in Table 3.1.
Something that is, strictly speaking, not an axis but fits nicely in this section is the // expression. It matches any location within the document tree. So, //dish matches any dish node within the document. Listing 3.21 shows this expression in action.
LISTING 3.21 Stylesheet Using // to Get All Nodes
ANALYSIS
Listing 3.21 yields the same result as Listing 3.14 because line 5 uses // to match all nodes in the document from which the dish nodes are selected.
A common mistake is to think that //dish[6] will yield the sixth dish element within the document. Unfortunately, because of precedence rules, this expression will yield no element at all. The processor will look for a sixth element in each of the parent contexts. Unfortunately, there is none because appetizers contains only four dish elements; entrees, only five; and desserts, only three. So how do you solve this problem? You can use parentheses to override the default precedence. Therefore, (//dish)[6] would yield the sixth element (the Seafood Pasta).
Summary
Today you learned that elements and attributes alike are referred to as nodes. You also learned that a node with child nodes (elements) is called a tree fragment. Using XPath expressions, you can also match nodes in different parts of an XML document. If the match expression matches more than one node, the result is a node-set in which each node can be referred to by number within the node-set. A node-set is not a hierarchy of nodes.
You select nodes by using XPath expressions. They consist of location paths, which in turn consist of an axis, a node test, and a predicate. The axis and predicate are optional. If no axis is specified, it is implied. If no predicate is specified, all nodes that match the axis and node test will match.
Tomorrow you will learn more information about templates. You will use many of the rules you learned today about XPath expressions as you learn more about templates and controlling the flow of control.
Q&A
Q How can I tell if an expression will match a node or a node-set?
A Unless a predicate specifically targets a specific node or the expression matches an attribute, you can’t tell whether your expression will match a node or a node-set. This is by design because it actually shouldn’t matter whether you are matching a node or a node-set; each node matching the expression is supposed to be processed. You can download a tool called XPath Visualizer from http://www.topxml.com/xpathvisualizer/default.asp. This tool can help you determine whether your expression is correct.
Q How can I tell whether an expression in a value-of command will yield a text value or a tree fragment?
A You have no way of knowing whether you are getting a text value or a tree fragment unless you use the text () function.
Q I have a stylesheet that keeps outputting text that I didn’t ask for. How can I get rid of this problem?
A The default behavior of the stylesheet causes this problem. Check whether all nodes are being matched by a template. Also, check that your expression outputting values doesn’t match a tree fragment.
Workshop
This workshop tests whether you understand all the concepts you learned today. It is helpful to know and understand the answers before starting tomorrow’s lesson. You can find the answers to the quiz questions and exercises in Appendix A.
Quiz
1. True or False: The ancestor-or-self axis includes the context node.
2. True or False: A predicate can contain a location path.
3. Given Listing 3.1, what would be the output of <xsl:value-of select="/menu/entrees/dish" />?
4. Given Listing 3.1, what would be the output of <xsl:value-of select="//dish[10]/parent::*/@title" />?
5. Given Listing 3.1, what would be the output of <xsl:value-of select=" (//dish)[10]/parent::*/@title" />?
Exercise
1. Create a stylesheet that displays Listing 3.1 nicely as a menu with sections, using the title attribute as a header for each section.