
Chapter 2: Messaging and Data Streaming in AWS
AWS has an extensive array of services in the messaging space and is constantly adding more services and features to its repertoire. Some of these services are purpose-built and proprietary to Amazon, such as Amazon SQS, Amazon SNS, and the Amazon Kinesis umbrella of services. Several are open source projects being offered as managed services such as Amazon MQ and Amazon MSK.
In this chapter, we will take a brief look at the ecosystem of AWS services in the messaging space. After reading this chapter, you should have a good understanding of the various services, be able to differentiate between them, and understand the strengths of each service and how best to apply them to different architectures depending on the use case. The similarities and differences between each of these messaging services are also summarized in a table at the end of the chapter. The list of services covered in this chapter is as follows:
- Amazon Kinesis Data Streams (KDS)
- Amazon Kinesis Data Firehose (KDF)
- Amazon Kinesis Data Analytics for SQL (KDA SQL)
- Amazon Kinesis Video Streams (KVS)
- Amazon Simple Queue Service (SQS)
- Amazon Simple Notification Service (SNS)
- Amazon MQ for Apache Active MQ
- IoT Core
- Amazon EventBridge
- Amazon Managed Streaming for Apache Kafka (MSK)
Before we get started on the services, let's take a brief look at some AWS concepts that are common across services.
AWS services are API-driven, and all functionality is exposed via REST APIs. Amazon SDKs offered in multiple programming languages such as Java, Python, JavaScript, Node.js, and others simplify the use of the services by providing higher-level abstractions and a library consistent across languages that can handle many boilerplate tasks, such as credential management, retries, and data serialization. In addition to the API, the control plane functionality is also available through the AWS command-line interface (CLI) and the AWS console.
AWS service APIs use secure HTTP (HTTPS) to provide encryption in transit through TLS (https://en.wikipedia.org/wiki/Transport_Layer_Security). In addition, most services provide encryption at rest using a customer master key (CMK) from AWS Key Management Service (KMS) utilizing envelope encryption. Envelope encryption is a mechanism where an entity is encrypted using a plaintext data key and the data key, in turn, is encrypted using a master key.
AWS KMS
AWS KMS is a fully managed cryptographic key management service that provides highly available key storage, auditing, and management, allowing you to encrypt and decrypt your data stored across AWS services.
AWS Identity and Access Management (IAM) is used to provide authentication and authorization. Authentication for programmatic access (via AWS SDKs) is provided through a Signature Version 4 signing process using keys associated with IAM users, or by using temporary credentials by assuming roles.
Let's take a look at some of the streaming and messaging services in AWS, starting with the Kinesis umbrella of services.
Amazon Kinesis Data Streams (KDS)
Amazon KDS was launched in November 2013 and was the first service in the Amazon Kinesis umbrella of services. It is a fully managed, serverless platform for streaming data at any scale. It provides a highly durable, scalable, and elastic service for real-time data streaming that requires no provisioning of any infrastructure and enables users to get started with just a few clicks on the AWS console.
Amazon KDS falls into stage 3 of the 5 stages of enabling stream analytics described in Chapter 1, What Are Data Streams?. There are a number of core requirements of a stream storage platform. They include the following:
- Data durability: Data, once sent to and received by a stream storage system, needs to be durably stored; there should be no data loss.
- High parallelism: Provide high throughput and low latency in data retrieval or low overall propagation delay.
- Read from any point in the stream: The ability to rewind to different points in a stream for a defined retention period.
- Support one-to-many read: Support multiple consumers reading the same set of messages at the same time.
Amazon KDS embodies these core tenets of a stream storage platform.
There are thousands of organizations using Amazon KDS for myriad use cases. The scale ranges from only few kilobytes to gigabytes per second from thousands of data sources. In addition, within AWS, it is considered to be a tier-0 service since there are other services that are dependent on it. It is used as the backbone for services such as AWS metering, Amazon S3 events, and Amazon CloudWatch Logs. KDS is also used by other Amazon companies, such as Amazon.com for their online catalog and Amazon Go for video analytics.
Amazon KDS has APIs for both the control plane and the data plane. On the control plane, the APIs allow creating streams, deleting streams, describing streams, listing streams, setting up stream consumers, changing stream capacity and properties, enabling and disabling monitoring, and enabling and disabling encryption. On the data plane, the APIs allow inserting records (both one at a time and as batches) and getting records from streams. We will go through most of these capabilities in this book.
Figure 2.1 illustrates the shards in a data stream and the ecosystem of different types of producers and consumers available that work with Amazon KDS:
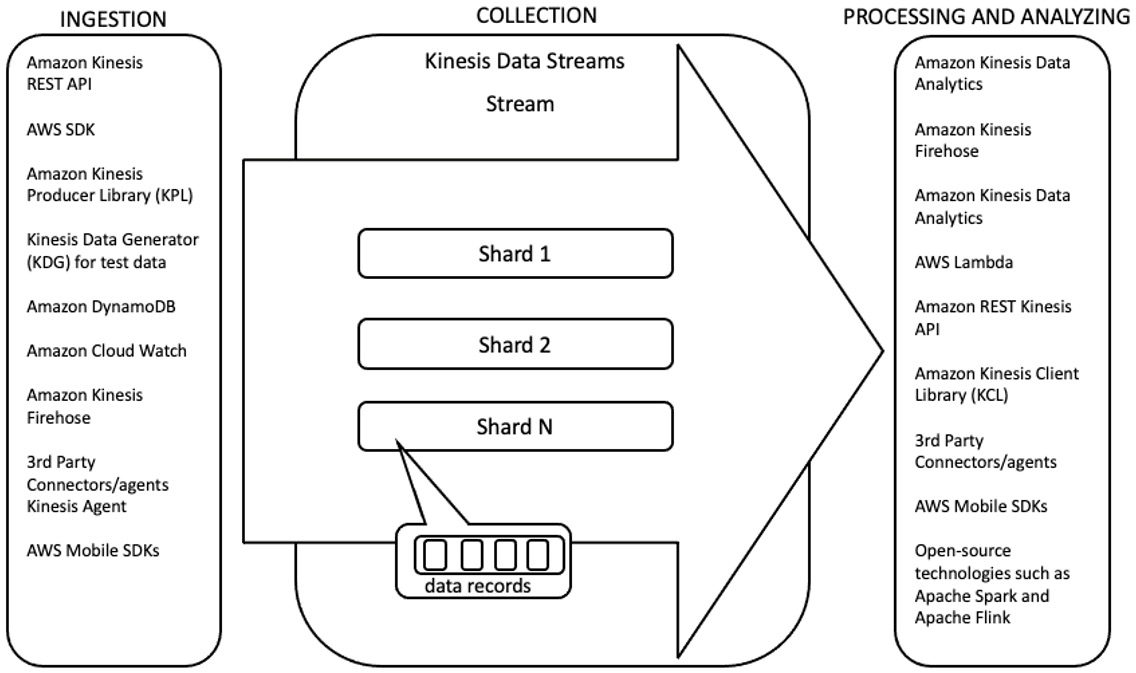
Figure 2.1 – KDS ecosystem of producers and consumers
A stream in Amazon KDS is composed of one or more shards. A shard is a unit of capacity and also a unit of parallelism. There are fixed capacity constraints for each shard and the number of shards in a stream defines the capacity and throughput for a stream both on the ingress side and the egress side. On the ingestion or ingress side, each shard can support a throughput of 1 MB per second or 1,000 records per second. On the egress side, for standard consumers (there are two supported types of consumers – standard, which utilizes the pull model, and Enhanced Fan Out (EFO), which utilizes the push model; the service pushes records to consumers), each shard supports 2 MiBs per sec (or double the ingress throughput) and five transactions per second (a transaction is a GetRecords API call to get records from a KDS stream). In addition, the maximum size of an individual record is 1 MB before base-64 encoding.
To calculate how many shards are needed for a stream, workload information around ingress and egress throughputs and the number of consumers is needed. There are calculators available from AWS and other third parties that make this task easier. Armed with information on the number of shards required for the workload, a new KDS stream can be created in seconds. Once created, applications can start sending and receiving records from the KDS stream immediately. There is no administration needed at all apart from monitoring the capacity usage of the shards and adding and removing shards as needed.
It is very easy to scale up the capacity of the stream by adding additional shards, as well as to scale down by removing shards, thus cost-effectively managing capacity by tracking the capacity requirements of the workload. Scale-up happens by splitting shards and scale-down by merging shards, and they can be performed online while the stream is actively receiving records and consumers are consuming records, with no downtime. Mechanisms exist to orchestrate the scaling automatically by tracking stream or shard metrics using a Lambda function.
For durability, once a record is received by Amazon KDS, it is durably stored across multiple Availability Zones, before sending a response back to the producer. The service provides a default retention period of 24 hours once a message is successfully received but it can be increased up to 8,760 hours, or 365, days at an additional cost. The service provides an SLA (https://aws.amazon.com/kinesis/sla/) of 99.9%.
Encryption, authentication, and authorization
Both the control plane and the data plane are integrated with AWS IAM and support authentication via AWS Signature Version 4 and identity-based IAM policies for authorization. At this time, resource-based IAM policies are not supported.
The service also offers encryption at rest by encrypting messages as soon as they're received, before writing to the storage layer and decrypted after reading from the storage layer and before returning it to the consumer. It uses a CMK from KMS, which can be either user-managed or service-managed.
Producing and consuming records
Amazon KDS provides a simple API for producing and consuming records that is wrapped in AWS SDKs offered in multiple programming languages, but there still exists considerable work in actually writing high-performance, scalable, highly available producers and consumers that provide an array of consumer and producer metrics for monitoring performance. In order to ease those tasks, Amazon KDS provides a producer library called the Kinesis Producer Library (KPL) and a consumer library called Kinesis Client Library (KCL), which are offered under the Apache 2.0 license and are open source. The KPL and KCL are both written in Java. The KPL has a C++ core with a Java wrapper. The KCL does provide support for other languages through a multi-lang daemon. These libraries can be used to accelerate creating high-quality producers and consumers and are used by many other third-party products to integrate with Amazon KDS, such as the Logstash kinesis plugin and the Fluent plugin for Amazon Kinesis. In addition, connectors exist for popular data processing frameworks such as Apache Spark and Apache Flink.
Data delivery guarantees
Amazon KDS supports at-least-once delivery. The consumers need to be either idempotent, which means processing the same message multiple times does not change the outcome, or capable of deduping the message.
Integration with other AWS services
Amazon KDS is tightly integrated with a number of AWS services and is able to directly ingest records from them. One important integration is with AWS Lambda, wherein a Lambda function can be invoked with a payload of records retrieved from Amazon KDS either periodically (with standard consumers) or whenever records are available (with EFO consumers).
Monitoring
For monitoring, Amazon KDS is integrated with Amazon CloudWatch, and metrics at both the stream level (enabled by default) and the shard level (referred to as enhanced shard-level metrics; this needs to be enabled and costs extra) are available.
Next, we take a look at a closely related service that simplifies the ingestion and delivery of streaming data to a number of destinations.
Amazon Kinesis Data Firehose (KDF)
Amazon KDF was launched in October 2015. It is a fully managed, serverless service for ingesting streaming data and delivering to destinations in AWS, third-party services such as Splunk, or even generic HTTP endpoints. In terms of the five core stages of enabling real-time analytics, Amazon KDF straddles stream storage and real-time stream processing. Some of the core capabilities of Amazon KDF are as follows:
- Ingesting data at high volumes
- Ingesting high-throughput streaming data from myriad data sources
- Buffering and aggregating data
- Transforming and processing data inline
- Sending data to one of a number of destinations
- Handling errors and retries while sending
- Storing ingested data in the service for 24 hours, to enable retries and handle situations when destinations are unavailable
When Amazon KDS first launched, the majority of organizations used the service to ingest streaming data and store it in Amazon S3 or load it in Amazon Redshift. Amazon Redshift is a fully managed, highly parallel data warehousing service for analytical processing and analytical querying. With KDS, customers were spending a lot of time and energy on writing custom applications to store the data in S3 and Redshift. AWS recognized this need across a large segment of customers and built Amazon KDF to support the most popular destinations, thereby reducing customer effort and providing an easier experience for landing persistent data in near real time. If there appears to be some overlap between the Amazon KDS and Amazon KDF services, it is because Amazon KDF was designed to ease the burden of doing some common stream storage and processing tasks.
In general, since Amazon KDF buffers data; in any scenarios where latency is important, Amazon KDS should be considered instead. Similarly, even though Amazon KDF provides the ability to perform some degree of inline Extract, Transform, and Load (ETL), if the requirement is to do heavy transformations, custom stream processing, or stateful (processing events depend on previous events) processing, Amazon KDS is a better fit. However, if the use case requires stateless, low-touch ingestion and delivery of streaming data with some inline transformations, encryption, batching, and compression to supported destinations, Amazon KDF is the best choice.
Just like Amazon KDS, Amazon KDF is an API-driven service and has APIs for both the control plane and the data plane. In the control plane, it has APIs for creating and deleting delivery streams, listing and describing delivery streams, starting and stopping encryption at rest, and updating the destination for the delivery stream (changing the target destination to deliver records to). On the data plane, it has APIs to send records to the service both one at a time and in batches.
Figure 2.2 illustrates producers sending data to Amazon KDF and the delivery destinations it supports:

Figure 2.2 – Producers and delivery destinations for Amazon KDF
A delivery stream is the core construct of Amazon KDF and defines the entity streaming records are sent to. Unlike Amazon KDS, however, there is no need to define the capacity of the delivery stream. The service supports two ways of sending data:
- Direct PUT
- Using Amazon KDS stream as a source
For Direct PUT, the service provides the PutRecord and PutRecordBatch APIs to send records one by one and in batches, respectively. In this case, the default delivery stream capacity is based on the choice of AWS region. For US East (N. Virginia), US West (Oregon), and Europe (Ireland), it is 5,000 records/second, 2,000 requests/second, and 5 MiB/second. For many other regions, it is 1,000 records/second, 1,000 requests/second, and 1 MiB/second. The important thing to note here is that these are soft limits and if the throughput for a particular use case is higher than the specified limits, a limit increase support ticket needs to be submitted and the service raises the limit for the delivery stream. In addition, the service is able to auto-scale up to the delivery stream capacity limit. If an Amazon KDS stream is used as a source, the delivery stream capacity is the capacity of the source Amazon KDS stream and the service can auto-scale up to that limit.
For durability, Amazon KDF redundantly stores data across multiple Availability Zones and provides an SLA (https://aws.amazon.com/kinesis/sla/) of 99.9%. It stores records in the service for 24 hours in case it is unable to send records to the destination.
Encryption, authentication, and authorization
For authentication and authorization, both the control plane and the data plane are integrated with AWS IAM and support Signature V4 for authentication and identity-based IAM policies for authorization. At this time, resource-based IAM policies are not supported.
The service also provides encryption at rest using AWS KMS CMK, which could be either user-managed or service-managed. However, how encryption at rest is provided differs based on whether the source is Amazon KDS or Direct PUT. If an Amazon KDS stream is the source, Amazon KDF does not store the data; instead, it depends on the records being encrypted at rest in the Amazon KDS stream. When it reads records from the stream, Amazon KDS decrypts the data before Amazon KDF receives it and then Amazon KDF buffers the records in memory for the timeframe specified in the configuration and delivers the records to the destination without storing them at rest in the service. If Direct PUT is used, Amazon KDF provides APIs to start and stop encryption or configuration parameters when creating a delivery stream with an AWS KMS CMK to encrypt the data at rest.
Monitoring
For monitoring, Amazon KDF is integrated with both CloudWatch metrics and CloudWatch Logs. There are metrics collected and made available for data ingestion, data delivery, individual APIs, data transformation, data format conversion, server-side encryption at rest, and Amazon KDF usage. Also, if enabled, when inline data transformation is used within Amazon KDF using a Lambda function, Amazon KDF logs errors when Lambda invocation fails. In addition, if there are errors delivering to the specified destination, Amazon KDF logs the errors to CloudWatch Logs as well.
Producers
As mentioned, in addition to having an Amazon KDS stream as a data source, Amazon KDF provides APIs to send data to a delivery stream that are wrapped in AWS SDKs offered in multiple programming languages as well as in the AWS CLI. Producer applications can be written using the SDKs to send data to a delivery stream. In addition, there are a number of other methods and integrations that allow the easy ingestion of data into a delivery stream. These include Kinesis Agent (Linux-based), Kinesis Agent for windows and integrations with other AWS services including Amazon CloudWatch Logs, Amazon CloudWatch Events, AWS IoT, AWS Web Application Firewall (WAF), and Amazon MSK.
Delivery destinations
Once ingested, Amazon KDF offers the ability to buffer and aggregate records before delivery to a configured destination. Only one destination is supported per delivery stream and the buffering options provided vary by destination. At this time, the supported destinations include Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, generic HTTP endpoints, and service providers such as Datadog, New Relic, Splunk, and MongoDB. The service handles delivery failures and retries and message backups to Amazon S3 on failures for subsequent processing, but the semantics vary by destination. Amazon KDF supports at-least-once data delivery semantics.
Transformations
Amazon KDF provides the ability to do multiple transformations inline after data ingestion and before delivery. This includes the ability to do data transformations by invoking a Lambda function (called a Lambda transform), and multiple Lambda function blueprints are provided to do common transformations such as Apache Log to JSON and CSV, Syslog to JSON, and CSV and General Firehose Processing.
Figure 2.3 illustrates data transformation in KDF using a Lambda transform:

Figure 2.3 – Data transformation in KDF using a Lambda transform
In addition, the service also provides the ability to do data format conversion in which the format of the incoming records can be converted from JSON to Apache Parquet or Apache ORC, before sending the data to Amazon S3 (Amazon S3 is the only destination supported). Data transformation using Lambda functions and data format conversions can be combined in a pipeline inside the Amazon KDF service for various use cases, such as converting the data format of records in comma-separated values (CSV) format to Apache Parquet. In this case, a Lambda transform can be used to first convert the CSV format to JSON before using data format conversion to convert the record to Apache Parquet and store it in Amazon S3. For the Amazon S3 destination, an additional facility using expressions is provided to customize the Amazon S3 object keys for objects delivered to Amazon S3. This feature can be used to store data in partitions using Apache Hive naming conventions, which requires partition names to be defined in key=value format, for example, year=2021.
Now let's look at a service that provides fully managed, serverless, real-time data processing.
Amazon Kinesis Data Analytics (KDA)
Amazon KDA was launched in August 2016. KDA is a fully managed, serverless service for continuously processing real-time streaming data. When it launched in August 2016, it supported the SQL engine, allowing users to query continuously streaming data and get insights from the data in real time without learning a new API or a new programming language. KDA supports ANSI SQL standard with extensions. Later, in November 2018, Amazon KDA launched the second supported underlying real-time processing engine in Apache Flink. It is now called Amazon Kinesis Data Analytics for Apache Flink. As the name suggests, it offers the popular, open source, highly parallel, and low-latency distributed processing framework for stateful computations Apache Flink as a fully managed serverless service. In terms of the five core stages of enabling real-time analytics, Amazon KDA falls in the real-time stream processing stage.
Amazon KDA for SQL
Before getting into how the SQL engine in Amazon KDA works, let's first take a look at how SQL works with streaming data. In general, drawing a parallel with batch data, where SQL is used to query a table with data, the query is bounded by data present in the table at the time the query is executed. Any aggregations or calculations performed by the SQL query uses that bounded dataset, which is finite, and the query results are deterministic. However, with streaming data, it is akin to having an in-memory table with the data just flowing through the table with no bounds. So, if a SQL query is to be executed against the table, what dataset is it going to work against? How are aggregations going to be computed and calculations performed? So, in order to run a deterministic SQL query against the table, the data needs to be bounded. These bounds are created by windowing. Windows are bound based on time or number of messages or some other metric. The most common forms of windows use time. Later chapters will go into the details of windowing.
In Amazon KDA for SQL, the in-memory tables are called in-application streams. If a table receives data directly from the source, it is called an in-application input stream.
Figure 2.4 illustrates the processing pipeline using Amazon KDA for SQL:

Figure 2.4 – Processing pipeline using Amazon KDA for SQL
The core component of Amazon KDA for SQL is an application that encapsulates all functionality and has a configuration associated with it. There are control plane APIs available to create and manage applications, and these APIs are wrapped in SDKs offered in multiple programming languages and available through the AWS console and AWS CLI. The application consists of the following:
- Input, shown as 1 in Figure 2.8, which is the source of streaming data and can either be an Amazon KDS stream or an Amazon KDF delivery stream (there are no APIs to directly send data to an Amazon KDA for SQL application).
- Application code, shown as 3 in Figure 2.8, which is written in SQL and can be either a single SQL statement or a string of SQL statements feeding results to intermediate in-application streams that are read by subsequent SQL statements and fed to an output destination.
- Output, shown as 4 in Figure 2.8, which comprises in-application output streams that send data to configured destinations that can either be an Amazon KDS stream, an Amazon KDF delivery stream, or an AWS Lambda function. The application configuration specifies each of these and the AWS console provides the interface to create and update the application code and displays sample data as it flows and gets transformed by the application.
- Reference data, shown as 2 in Figure 2.8, which is data that provides additional information about the incoming event, such as address information for an event that contains location information. It is stored in an S3 object and loaded by KDA to an in-memory table to facilitate streaming joins.
The SQL language supports ANSI 11 with some data streaming extensions. The SQL application code can utilize a variety of functions to analyze the data, including aggregate, analytic, boolean, conversion, data/time, numeric, log parsing, sorting, statistical, streaming SQL, string, search, and machine learning functions. These functions can be used in-line with the SQL statements and make it very easy to do complex analysis by encapsulating the complexity in the functions. In addition, user-defined functions can be created in SQL to encapsulate logic not available as a standard function. It is recommended that several small SQL statements with results flowing into intermediate in-application streams be used instead of large, complex SQL statements, as that approach makes it easier to troubleshoot application code. In addition to the input source, the application code supports a reference (or lookup) data source (one only), with the source being an object in S3 that is loaded into an in-application stream in the application and allows joins with other in-application streams.
Amazon KDA uses a Kinesis Processing Unit (KPU) as a unit of capacity to provision capacity and resources needed for an application. A KPU roughly translates to 1 vCPU and 4 GB of memory. The service is able to elastically scale the application in response to the throughput of data coming in from the source and the complexity of the application code.
Encryption, authentication, and authorization
Amazon KDA SQL provides encryption in transit between supported data sources and the application as well as between the internal components of Amazon KDA and Amazon KDA and Amazon KDF. In addition, the service encrypts the application code and the reference data at rest using an internal key.
The control plane APIs of the service are integrated with AWS IAM and support authentication using Signature V4 and authorization with identity-based IAM policies.
Monitoring
For monitoring, Amazon KDA for SQL is integrated with Amazon CloudWatch and provides a number of metrics in the AWS/KinesisAnalytics namespace.
Data delivery guarantees
Amazon KDA for SQL supports at-least-once data delivery semantics. Now let's look at the more recent engine offered as part of the Amazon KDA service.
Amazon Kinesis Data Analytics for Apache Flink (KDA Flink)
In addition to using SQL, a developer can create Apache Flink applications and deploy them as KDA applications. This feature was added to KDA during re:Invent 2018. The key advantage of using KDA to run your Flink applications is that you don't need to worry about infrastructure. KDA will provision the underlying resources needed to run your application and provides the ability to automatically scale those resources on your behalf. It's a turnkey solution for your Apache Flink applications. The high-level steps for deploying your KDA application include creating and building it locally, packaging it (in a JAR file), and uploading the code. To start your Flink application, once you have created the JAR file, you have two options to upload it to KDA. You can use the Amazon KDA kinesisanalytics:CreateApplication API or go through the the Amazon KDA console. KDA manages the underlying infrastructure, from scaling through security.
While removing the overhead of handling the infrastructure, you do retain a lot of Flink capabilities; however, you lose some of the flexibility. KDA will control the state backend and manage it on your behalf. KDA uses RocksDB and S3 is used as a distributed state backend; Flink savepoints (called snapshots in KDA Flink) get persisted on S3. You can use externalized parameters called runtime properties to modify or change the behavior of your application. KDA will also manage the application life cycle on your behalf. If an update of your Flink application fails, KDA will retry the application update. When updating your job, KDA will create a snapshot unless it is turned off in the configuration. The application is then stopped and updated by KDA. KDA is capable of maintaining up to a thousand snapshots that you can then restore from. KDA maintains your application metadata in a DynamoDB database internally.
Amazon KDA is a serverless service and abstracts the underlying instances from you and you don't get to choose the instance type that your KDA application runs on. Your application will run on underlying instances controlled and managed by KDA. KDA will allocate appropriate instance size from its fleet based on parallelism that you configure for your application. In addition to selecting instances for your Flink application, KDA will determine whether your application will be run on memory-optimized or CPU-optimized instances. KDA determines this based on metrics your application produces, so if your application consumes lots of CPU, KDA will move it to an appropriate compute-optimized instance such as the C instance family.
KDA allocates capacity to your application in terms of Kinesis Processing Units (KPUs). 1 KPU is roughly equivalent to 1 vCPU and 4 GB of memory and includes 50 GB of disk. When it comes to scaling your application, KDA automatically scales up and scales down the underlying infrastructure on your behalf. You can turn this behavior off if you wish to do so. If you don't want automatic scaling, you can specify parallelism, as well as parallelism per KPU. Parallelism is a setting that determines how many Flink computation processes should operate on data in parallel. As KDA detects an increase in CPU, it will scale up your application. A drop in CPU usage triggers a scale down. When you turn on autoscaling, KDA will not, however, reduce your application's CurrentParellelism value to below the setting for your application's Parallelism value. You can still set a maximum Parallelism value and KDA autoscaling will honor it. If you want full control, you can turn off autoscaling and set your application's parallelism. If you have steady load and you know what resources your application sources and sinks need, you can set parallelism yourself. KDA will then scale your application according to the parallelism boundaries that you have set.
Access and interaction with the KDA deployed Flink app is done through the KDA native AWS API. The downside of this is that you lose some of the flexibility of using the Flink REST API to manage jobs. However, the advantage is that you get out-of-the-box integration with AWS IAM. In addition, KDA encrypts all the data at rest and transit using an internal key. To ensure that your application is running in the case of failures in AWS Availability Zones, KDA seamlessly fails your application over to another Availability Zone. This removes the need for you to worry about disaster recovery within the AWS Region. KDA monitors your Flink application as well as the underlying infrastructure for any failures or issues such as bad drive, out of memory (OOM), and so on. KDA restarts your application and publishes events into CloudWatch Logs or metrics to notify you. You can use these to perform any processing that you may need to do when the job is restarted.
The Apache Flink framework contains connectors for accessing data from a variety of sources. For information about connectors available in the Apache Flink framework, see https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/.
Amazon Kinesis Video Streams (KVS)
Amazon KVS was released on November 29th, 2017. KVS is a fully managed, serverless service for ingesting video and other time-encoded data such as audio, Light Detection and Ranging (LIDAR), and Radio Detection and Ranging (RADAR) signals. KVS abstracts away many of the core challenges of building video systems, enabling developers to focus on the application instead of the complex video infrastructure required to handle low-latency video at scale.
Video cameras can stream live video into KVS with only a few seconds' buffer delay. The video can then be consumed with both real-time and batch-oriented processes. KVS also supports Web Real-Time Communication (Web-RTC) to enable peer-to-peer two-way video/audio communication. This is a low-latency peering technique designed for real-time human-to-human interaction features such as video chat.
With KVS, a video is a series of images, and each one of these images is called a frame. Frames are grouped together when compressing video. Frames usually have very little visual difference, so only the incremental changes need to be stored in subsequent frames. In KVS, the fundamental data structure is the fragment. It is a sequence of frames that have no dependencies on frames in any other fragment. Each fragment is assigned a unique fragment number (an increasing number), a producer-side timestamp (absolute or relative to the start time of the recording), and a server-side timestamp. KVS data is consumed in streams of chunks, where a chunk contains the fragment, media metadata, and KVS-specific metadata.
The KVS producer and stream parser libraries are based on the Matroska Multimedia Container (MKV) video format. This format can package an unlimited amount of video, audio, and other data. The name Matroska is derived from the Russian word matryoshka, which is the name of the wooden Russian nesting dolls. The KVS producer libraries can support any time-serialized format, but the H.264 codec is required to be viewed in the AWS Management Console.
There are three main use cases that KVS supports: live video streaming and recorded stream playback, real-time two-way streaming, and computer vision-based applications. Live video streaming is built on HTTP Live Streaming (HLS). HLS is an industry standard that supports both on-demand and live streaming. HLS provides an HTTP endpoint that multiple open source players can connect and display video on a mobile device or browser-based web page. Lower latency is required to support bi-directional interactive communication instead of broadcast streaming. KVS achieves lower latency through support for WebRTC. It provides libraries that enable clients to directly connect to each other in a peer-to-peer manner. However, due to firewall rules or certain Network Address Translation (NAT) configurations, it is not always possible to connect directly in this manner. In this case, the KVS libraries then provide a fallback to a Kinesis Traversal Using Relays around NAT (TURN) server. The TURN server is a simple relay that receives the data from one client and sends it to the other.
One of the most compelling use cases for KVS is building computer vision/machine learning applications that analyze video data. The video can be either processed in real time or in batches by a wide variety of machine learning services. These AWS services range from high-level services such as Amazon Recognition and Amazon Transcribe to custom models built using TensorFlow, MxNet, or PyTorch. Through these services, developers can identify and label potentially unsafe or inappropriate content for moderation, perform facial recognition, and identify key objects in the video.
Kinesis video streams enable the development of video-based applications that can scale and remove many of the challenges involved in video consumption and processing.
Amazon Simple Queue Service (SQS)
Amazon SQS was launched in July 2006 and was one of the earliest services to launch on Amazon Web Services. With more than 14 years in service, Amazon SQS has delivered messaging services to some of the busiest e-commerce companies in the world. Amazon SQS is a fully managed, serverless service that is highly scalable and easy to get started with and use. It is one of the primary AWS native services providing message queue functionality in AWS and has been used by numerous companies for myriad use cases.
Amazon SQS offers a publisher/subscriber pattern with consumers pulling the messages from a queue. It offers queues without the need to set up message brokers. Authentication and authorization to SQS queues are managed with Amazon Identity and Access Management (IAM) and fine-grained IAM policies. These policies can be used to control who has access to an Amazon SQS queue. This allows you to manage who has the ability to send and receive messages from Amazon SQS.
Amazon SQS is a highly reliable and available service. The service leverages redundant server infrastructure spread across multiple Availability Zones in an AWS Region. This diversification protects against server and network failure, providing an uptime SLA (https://aws.amazon.com/messaging/sla/) of 99.9%.
Availability Zone
An AWS Availability Zone (AZ) is a logical group of one or more data centers in an AWS Region. A Region is a geographical area where AWS data centers are clustered together. The AZs are isolated from each other with redundant networking and power to provide high availability and fault tolerance. They are connected with low-cost, high-bandwidth, high-throughput, and low-latency networking, allowing the operation of applications and databases with high availability, fault tolerance, and scalability.
Figure 2.5 illustrates the integration between an Amazon SQS queue and AWS Lambda. Here a Lambda trigger can be created that automatically polls the SQS queue for messages and invokes the provided Lambda function to process the messages:

Figure 2.5 – Integration between an Amazon SQS queue and AWS Lambda
Amazon SQS offers two types of queues – Standard and First-In-First-Out (FIFO).
Standard queues offer nearly unlimited throughput, including the number of API calls per second per API action for SendMessage, ReceiveMessage, or DeleteMessage. Amazon SQS provides at-least-once message delivery, which means that a message will be delivered once but can be delivered more than once. This is due to the distributed architecture of Amazon SQS and Amazon SQS storing a copy of the message on multiple servers. It could happen, albeit rarely, that during the process of receiving and deleting a message, one of the servers that a copy resides on is unavailable, which can cause the same message to be delivered more than once. Consumers are, therefore, required to be designed to be idempotent (processing the same message multiple times does not change the outcome) or capable of deduping the message. Finally, it offers ordering as a best effort, which means that even though an effort is made to deliver messages to consumers in the order it was received by Amazon SQS, occasionally, they can arrive out of order.
FIFO queues offer exactly-once processing, which guarantees that the message is delivered once and only once. FIFO delivery guarantees that messages are delivered strictly in the order they were received in. FIFO queues have reduced throughput quotas over standard queues. Amazon SQS FIFO queues offer 300 API calls per second per API action, which when combined with batching (the maximum batching level is 10 messages per API call) supports a maximum throughput of 3,000 messages per second. In December 2020, Amazon SQS launched a preview of high-throughput FIFO queues that offers 3,000 messages per second per API call.
Both queue types support message payloads up to 256 KB in size, and with the Amazon SQS Extended Client Library for Java (https://github.com/awslabs/amazon-sqs-java-extended-client-lib), larger messages can be sent by first storing the messages in Amazon S3 and then sending a reference to the message payload in Amazon S3 to Amazon SQS. Furthermore, both queues support batching up to 10 messages, long polling, message retention up to 14 days, visibility timeouts for message locking, dead letter queues (DLQs), and server-side encryption (SSE) with keys using Amazon Key Management Service.
Now that we have had an overview of Amazon SQS and understand that it uses the pull model, let's look at another extensively used AWS messaging service that uses the push model: Amazon Simple Notification Service.
Amazon Simple Notification Service (SNS)
Amazon SNS was launched in 2010 and it is a fully managed serverless service offering the publisher/subscriber pattern with a push mechanism for sending messages to subscribers. Similar to Amazon SQS, Amazon SNS provides a highly scalable, available, and elastic service that can be used for decoupled architectures.
Amazon SNS uses the concept of topics. Topics are logical entities used to denote a specific category, subject, or type of event. The topic forms an "access point" of the service. Subscribers can subscribe to one or more topics of interest and get messages, and publishers send messages to their topics of interest. Amazon SNS identifies the list of subscribers for a particular topic and then delivers the messages sent to those topics to the corresponding list of subscribers. Unlike SQS message queues, where messages are received by one consumer, SNS messages are delivered to all subscribers in a process called fan-out. The topic owner can also specify which notification protocols are supported. Supported protocols include http, https, email, email-json, sms, sqs, application, and Lambda. Subscribers either subscribe to a topic and then go through a subscription confirmation process or are subscribed by the topic owner. Subscribers, when subscribing, need to provide the protocol and the corresponding endpoint to receive notifications.
The topic owner can define permissions in two ways: through Amazon SNS by using resource-based permissions (attached to topics that define the identities and the actions those identities are authorized to perform on the topic) and identity-based permissions (attached to identities that define the resources and the actions that are authorized on those resources). In either case, permissions are specified using IAM policies.
Figure 2.6 illustrates Amazon SNS and the subscription endpoints that it supports:

Figure 2.6 – Amazon SNS subscription endpoints
One important distinction between Amazon SNS and Amazon SQS is that Amazon SNS does not provide message retention. When a publisher sends a message to a topic, Amazon SNS immediately tries to deliver the message to all subscribers of the topic. If message delivery fails or the subscriber is not available, Amazon SNS goes through a four-phase delivery retry policy that is pre-defined for each protocol. Only the HTTP(S) retry policy can be modified. Once the delivery retry policy is exhausted, Amazon SNS discards the message. In order to prevent message loss, it is recommended that a DLQ is attached to the subscription (DLQs are attached to the subscription and not to the topic). Storing undelivered messages in a DLQ enables you to re-process the messages at a later time if they are still relevant.
Amazon SNS supports optional message attributes when the message structure is a string, but they're not supported with JSON messages. Though separate from the message payload, these message attributes, when defined, are sent along with the messages. These attributes can help the subscriber process the message and implement simple logic without having to process the message payload; for instance, the subscriber could ignore messages with a certain attribute or forward them to another service. Amazon SNS validates the attribute values for adherence to the data types specified for the message attributes and can filter the messages based on attribute values.
Amazon SNS provides a very useful feature called message filtering. Filtering makes it very efficient for consumers to receive only the messages they're interested in instead of all messages sent to the subscribed topic. This is achieved by the subscriber assigning a filter policy to the topic subscription. The filter policy is a simple JSON policy where the subscriber specifies the message attributes and the values that the subscriber is interested in. Amazon SNS performs the task of comparing the incoming topic message attributes to the filter policy attributes and sends the message to the subscriber if any attribute matches or skips the subscriber if there are no matches. Since the service performs this function, filtering and routing functions are offloaded from both publishers and subscribers. This also has the beneficial effect of allowing topic consolidation.
Amazon SNS by default supports message sizes up to 256 KB. For message sizes above that, up to 2 GB, the Amazon SNS Extended Client Library for Java (https://github.com/awslabs/amazon-sns-java-extended-client-lib/) can be used, which uses Amazon S3 to store the message payloads and sends a reference to the message payload to the Amazon SNS topic. Corresponding de-referencing libraries are available when the subscriber is either an Amazon SQS queue (with the Amazon SQS Extended Client Library for Java: https://github.com/awslabs/amazon-sqs-java-extended-client-lib) or AWS Lambda (with the Payload Offloading Java Common Library for AWS: https://github.com/awslabs/payload-offloading-java-common-lib-for-aws), which provide the ability to use the reference in the message to retrieve the payload from Amazon S3.
The messaging patterns enabled by Amazon SNS can be broadly categorized into two categories:
- Application-to-application messaging
- Application-to-person messaging
Let's take a look at each of them in detail.
Application-to-application messaging
With application-to-application messaging, the asynchronous communication is between two applications. One application is the publisher to a topic and other applications are subscribers to that topic. Amazon SNS supports HTTP(S) endpoints, Amazon SQS queues, AWS Lambda functions, and AWS Event Fork Pipelines as subscribers. When there is more than one subscriber to the same topic, the messaging pattern is referred to as fan-out.
Application-to-person messaging
In application-to-person messaging, the asynchronous communication is between an application and a user. The user can be a mobile application, mobile phone number, SMS, or email address. The primary purpose of this type of messaging is user notification, but the notification can also be used in a mobile application to take automated action on the client side.
Amazon SNS integrations with other AWS services
Amazon SNS is tightly integrated with a number of AWS services. One important integration is with Amazon CloudWatch, a service for monitoring applications and infrastructure. Amazon CloudWatch provides the ability to create alarms based on configurable thresholds and then natively utilize a configured Amazon SNS topic to send notifications. Amazon SNS sends notifications to configured email subscribers, AWS Lambda functions, or Amazon SQS queues to direct actions that should be performed when the alarm is triggered. For instance, a high CPU usage alarm can send an email to the system administrators notifying them of the issue, while at the same time triggering a Lambda function to automatically provision more capacity. These notifications can also fan out through Amazon SNS, so other AWS services and third-party services can receive the message. A commonly used pattern for application and operation automation is to have SNS send messages to an SQS queue that is then drained by other applications, including Lambda functions, to take the appropriate action. This pattern allows the messages to be processed at the rate of the downstream systems.
Encryption at rest
In Amazon SNS, messages are encrypted as they are received using a CMK from AWS Key Management Service (KMS). The encrypted messages are then stored across multiple AZs and decrypted right before they're delivered to subscribers.
Amazon SNS is a fundamental service that is essential for notification and message exchange in most AWS cloud-based architectures.
Next, let's take a look at Amazon MQ and how it helps with lift-and-shift approaches for moving messaging workloads easily into the cloud.
Amazon MQ for Apache ActiveMQ
Amazon MQ is a managed message broker service for Apache ActiveMQ and RabbitMQ that launched in 2017. Apache ActiveMQ is a popular Java-based open source message broker that supports multiple protocols providing a choice of a wide range of programming languages and protocol options for clients. The supported APIs and protocols include JMS, NMS, AMQP, STOMP, MQTT, and WebSocket. RabbitMQ is an open source, very popular lightweight message broker that supports many protocols, including AMQP 0-9-1 and extensions, AMQP 1.0, STOMP, MQTT, AMQP 1.0, WebSocket, and JMS via a plugin. Amazon MQ is a managed service that provides high availability, infrastructure management, broker setup, software updates, and operations and management of the brokers. Amazon MQ provides access to the industry-standard APIs, the ActiveMQ console, and the RabbitMQ web console. One of the main advantages of Amazon MQ is the ability to easily move to a managed service when using any message broker utilizing one of the aforementioned protocols. When migrating to Amazon MQ, there is no need to change the clients or applications interfacing with the message brokers. The primary purpose of this service is to support such migrations.
Amazon MQ for Apache Active MQ offers two types of broker configurations from a storage standpoint:
- High durability
- High throughput and low latency
In the high-durability configuration (the default), the service uses Amazon Elastic File System (EFS) for broker storage. Amazon EFS is a cloud-based network file system (NFS) that is elastic, scalable, fully managed, and highly durable as it is spread across multiple AZs. It is possible to mount it on multiple broker nodes, so the broker nodes can read and modify the same files on shared storage, allowing active/standby broker configurations for high availability and failover.
In the high-throughput and low-latency configuration, the service uses Amazon Elastic Block Store (EBS) for broker storage. While Amazon EBS maintains multiple copies of the storage volume in the same AZ, the storage is not spread across multiple Availability Zones. Correspondingly, it cannot be used for active/standby broker configurations.
Amazon MQ for Apache Active MQ provides the ability to set up brokers in multiple configurations. Let's take a look at them.
Single-instance brokers
Single-instance brokers, as the name suggests, have a single broker in a single Availability Zone using either Amazon EFS or Amazon EBS for storage. This configuration does not provide any high availability or failover.
Active/standby brokers
Active/standby brokers utilize two separate brokers in two different Availability Zones using Amazon EFS for storage. Clients can connect to either of the brokers but typically only one broker is active at a time. Amazon MQ provides a separate ActiveMQ web console URL for each broker but only one is active at a time. Correspondingly, the service provides separate endpoint URLs for each wire protocol for each broker with only one being active at a time. ActiveMQ Failover Transport can be used by clients to connect to the wire protocol endpoints of either broker and transparently handle connection failures and broker failovers.
Network of brokers
A network of brokers consists of multiple active brokers, single-instance or active/standby, configured in a variety of topologies such as hub and spoke, concentrator, mesh, and tree. It provides both high availability and scalability and the ability to fail over almost instantly in the case of broker failure. The service provides integration with AWS IAM for control plane API authentication and authorization, via identity-based policies (resource-based policies are currently not supported). In addition, encryption at rest is supported with AWS KMS and a CMK, both user-managed and service-managed (when a user-managed CMK is not provided).
All communication between brokers is encrypted using TLS V 1.2 and clients can access the brokers over TLS using protocols AMQP, MQTT, MQTT over WebSocket, OpenWire, STOMP, and STOMP over WebSocket. For message authentication and authorization both native ActiveMQ authentication and LDAP authentication and authorization are supported.
Next, let's take a quick look at the deployment options for Amazon MQ for Rabbit MQ.
Single-instance standalone
This deployment mode is primarily intended for development or low-latency workloads that want to avoid replication There is a single broker, in a single Availability Zone that can be either publicly accessible over the internet or deployed in a VPC with access only within the VPC.
Cluster deployment
This deployment mode is intended for production workloads and utilizes three brokers spread across three Availability Zones fronted by a network load balancer (NLB) to provide a single access point for APIs and the RabbitMQ web console. To ensure high availability, classic mirroring is employed. In addition, both private brokers as well as publicly accessible brokers are supported.
Next, we look at a service that is at the heart of the IoT services offered by AWS.
IoT Core
AWS IoT Core is a family of managed services that allows IoT-connected devices to interact with each other as well as with other cloud applications and services. You can use a variety of protocols with AWS IoT Core. MQTT is the primary protocol used as it is optimized for publish/subscribe messaging between various remote devices with scarce resources and when network bandwidth is nominal.
This book will not cover IoT in depth; however, the purpose and key functionality apply to streaming data solutions with IoT use cases.
Device software
FreeRTOS is an open source operating system for microcontrollers. FreeRTOS is similar to the Raspberry Pi Raspian operating system. FreeRTOS is intended for embedded software (software that controls devices and hardware) development for microcontrollers. FreeRTOS provides you with building blocks to create software for microcontrollers and implement multitasking. Whereas Raspian is an operating system intended for end users just to install and run, FreeRTOS is a baseline operating system for developers to build on top of. You can think of Raspian as a meal at the restaurant and FreeRTOS as being a set of ingredients that you put together and cook to create a meal.
AWS Greengrass brings IoT capabilities to the edge. As IoT devices generate large amounts of data, Greengrass provides the ability to filter that data. Rather than filtering data once it arrives in the cloud, Greengrass lets you filter it on the device and only send the data that you want. The AWS Greengrass functionality is similar to that performed by "check-in" agents at the airport. Instead of letting everybody go to the gate, check-in agents filter passengers in the pre-gate area inside the terminal.
Control services
AWS IoT Device Management enables the management of large device fleets from a single management console. If you think of your car's dashboard, that's similar to IoT Device Management: you can monitor your devices just like you monitor how much fuel you have in your car or the temperature of the engine. It also allows you to access the remote devices in a secure manner and perform maintenance tasks such as upgrades and setting changes.
AWS IoT Device Defender is to devices what AWS Config is to the cloud. Device Defender examines device configurations against expected security parameters. If it detects deviations or tampering with device settings that aren't within the boundaries of your expected baseline, it sends an alert.
AWS IoT 1-Click is for extending the functionality of simple devices, such as switches or buttons. Actual devices such as IoT Button (https://aws.amazon.com/iotbutton/) would send signals to AWS IoT 1-Click, which in turn executes an AWS Lambda function to perform your desired functionality.
Analytics services
AWS IoT Analytics is a service that provides insights from the IoT data that the devices in an IoT fleet produce. AWS IoT Analytics is a fully managed service that allows the devices' data to be queried and analyzed using machine learning.
IoT Events provides a convenient way to take actions based on events produced by device fleets. IoT Events can act across multiple data points such as weight, temperature, or speed and invoke actions. The service is simple to use as it follows the if-else-then notion. Once you determine that an event has occurred, for example, a temperature is above 32F, it can trigger actions from a predefined set. Some of the actions include saving to DynamoDB, sending messages to Kinesis, or invoking AWS Lambda.
AWS IoT SiteWise is intended for industrial large-scale monitoring of facilities such as manufacturing plants or warehouses storing goods. For example, SiteWise can be set up in a car manufacturing plant to capture equipment data and allow you to assess how your equipment is performing and troubleshoot problems without needing to have physical access to the devices.
AWS IoT Things Graph is kind of like a glue to connect various vendor devices or different device types. It is a simplified orchestration engine to allow vendor devices to communicate with each other by building common models of communication, leveraging a no-code visualization tool. A useful analogy to understand the function of Things Graph is the "translation" services provided during United Nations meetings and summits. There are multiple countries and languages that participate in UN meetings and they all need to coordinate with each other. Since not all of them speak the same language (they all use different protocols, in IoT terms), the translation service ensures that everyone understands each other. IoT Things Graph does exactly the same by allowing you to visually connect different devices into cohesive applications.
Now, let's look at Amazon Managed Streaming for Apache Kafka.
Amazon Managed Streaming for Apache Kafka (MSK)
Amazon MSK is a fully managed service for Apache Kafka. Launched in May 2019, Amazon MSK removed the difficult setup and management tasks for Apache Kafka. Apache Kafka is a popular open source, distributed, high-throughput, and low-latency streaming platform that is used by thousands of companies and is extremely popular. It is available under the Apache 2.0 license.
Amazon MSK allows you to focus on building applications and simply use Apache Kafka for stream storage.
Let's dive deeper into Apache Kafka and Amazon MSK in the following sections.
Apache Kafka
Apache Kafka is a distributed system that is typically installed as a cluster on multiple machines, EC2 instances (in AWS), or containers. The core component of a cluster is the broker. Multiple brokers form a cluster working together to provide high availability and durability. The brokers depend on Apache ZooKeeper for cluster management and coordination, although the Apache Kafka community is progressively moving toward removing this dependency.
The brokers host topics, which are logical entities representing a category to which events with similar event types are sent. Producers send messages to topics of interest and consumers subscribe to topics of interest. Underlying each topic is a commit log, which is at the heart of Apache Kafka. It is an append-only, ordered sequence of records with each incoming record appended to the end of the log. Each message in the log gets a unique offset. When consumers read from a topic, they are read from the commit log and can start from any point (offset) in the commit log. Consumers can read the earliest (the start of the log) or the latest (end of the log). The commit log for a topic is distributed across multiple brokers based on the number of partitions defined for the topic. Partitions provide scalability and parallelism in Apache Kafka. As partitions for a topic are added, the overall throughput for the topic increases. Correspondingly, consumers can read from multiple partitions in parallel to drain the queue faster. Each partition gets its own commit log, which is a physical file on disk, and the offsets in each partition log file start from 0 and can be the same across multiple partitions.
Figure 2.7 shows a high-level architecture of an Apache Kafka cluster with three broker nodes, a three-node ZooKeeper ensemble, a producer sending records to all three brokers of the cluster, and a consumer group with three consumers load balancing incoming records from the three brokers:

Figure 2.7 – High-level architecture of an Apache Kafka cluster
In order to achieve durability and high availability, Apache Kafka provides the ability to replicate messages to multiple brokers by setting the replication factor at the cluster level or the topic level. When set to more than one, Kafka creates the specified number of copies of the partition log for the topic(s). Each copy is called a replica. If the replication factor for a topic is set to three, there will be a total of three replicas for every partition for that topic distributed across the available brokers. One of the replicas is the partition leader and the others are followers. The leader serves write and read requests while the followers fetch records from the leader and keep their partition logs in sync (as of Apache Kafka 2.4.0, KIP-392 (https://cwiki.apache.org/confluence/display/KAFKA/KIP-392%3A+Allow+consumers+to+fetch+from+closest+replica) allows consumers to fetch from the closest replica, whereby followers serve read requests). The partition logs for all follower replicas look identical to the leader, except for the possibility of some unreplicated messages. This provides the ability to fail over to a surviving replica if the partition leader becomes unavailable. This happens through a process called leader election and is automatic.
Producers send messages to topics. The messages are key/value pairs with headers. Messages may or may not have keys. If keys are not present, then the producer API uses a default partitioner that round robins the message to all available partitions. If the key is present, then the default behavior is to create a hash of the key to determine the partition and send it to that partition. It is also possible to specify a custom partitioner in the producer to implement a custom partitioning strategy.
On the consumer side, Kafka supports both the publish-subscribe model as well as the queuing model. On the publish-subscribe side, Kafka can have many independent consumers consuming from the same topic, all getting the same set of messages and having the ability to read from different offsets in the commit log. On the queuing side, consumers are usually deployed in a consumer group consisting of multiple consumers started with the same group.id consumer property. They work together in concert and read from all partitions of a topic in parallel, but there is always a 1:1 mapping between a topic partition and a consumer instance in the consumer group.
A consumer instance can read from multiple partitions depending on the number of partitions and the number of consumer instances, but one partition can be read by one and only one consumer instance at a time, thus maintaining queuing semantics where only one consumer gets a message. The consumer group model utilizes the Kafka group protocol to coordinate among consumer instances and can identify failed consumer instances, whereupon the consumer group goes through a "rebalance" and the consumer instances get a new set of partitions to read from.
In order to do that, consumer instances need to know where the failed consumer instances left off. By default, Kafka consumers commit the offsets they have read and processed to an internal topic called __consumer_offsets, which is read by the consumer instances after rebalancing to start reading their assigned partitions from the committed offsets.
One of the great advantages of Kafka, and one that provides a great deal of performance, is the binary protocol used by Kafka over TCP. The binary data format for producers, on-disk storage at brokers, and consumers is the same and requires no conversion. This allows Kafka to use zero-copy, in which the data is not copied from the kernel space to application space.
Amazon MSK
Many Kafka users find it challenging to set up a distributed, fault-tolerant Kafka cluster and manage, scale, and operate it in production. It requires a lot of expertise on the DevOps and support side and a lot of time and effort spent on infrastructure, to provision and replace servers as needed, patch and upgrade servers, perform disk maintenance, and set up monitoring and alerting. In addition, Apache Kafka has a dependency on Apache ZooKeeper, which most people do not want to be in the business of maintaining.
With Amazon MSK, it is possible to set up a Kafka cluster with a few clicks on the AWS console or using the AWS CLI or AWS SDKs in the supported programming languages. The brokers and the ZooKeeper nodes are set up in a service-managed Virtual Private Cloud (VPC), which provides an isolated, dedicated virtual network in an AWS account. The service VPC is a dedicated, independent VPC for every cluster and also has a dedicated ZooKeeper ensemble for every cluster. The Kafka producers, consumers, and other tools can access the Amazon MSK Apache Kafka cluster using virtual network interfaces (Elastic Network Interfaces – ENIs) in the user account VPCs. Amazon MSK uses the open source Apache Kafka software and is therefore compatible with all Apache Kafka ecosystem tools and third-party tools that work with open source Apache Kafka, such as Kafka Connect, Kafka streams, Schema Registry, and REST Proxy. The only caveat is that tools that upload a custom jar to the Apache Kafka brokers do not work as Amazon MSK does not allow custom jar uploads. Amazon MSK identifies broker problems and failures and replaces the brokers as necessary, but it maintains the same IP addresses and broker DNS endpoints and re-attaches the same disk volumes (unless the disk volumes have issues) to maintain healthy clusters with minimal application downtime. The service offers an SLA (https://aws.amazon.com/msk/sla/) of 99.9%.
Figure 2.8 illustrates how connectivity works between the VPC and the broker and ZooKeeper nodes in the service-managed VPC:

Figure 2.8 – Connectivity between your VPC and Amazon MSK
The control plane of Amazon MSK provides the ability to create and delete clusters, create and delete configurations (configurations are mechanisms to provide supported server properties to Amazon MSK to influence broker and cluster behavior), list and describe cluster properties, add additional brokers, increase broker storage, and perform a number of other actions.
When creating an Amazon MSK cluster, the number and type of Amazon EC2 instances to be used for the Apache Kafka brokers need to be specified. The brokers are spread across multiple AZs for high availability, fault tolerance, and data durability. Two topologies are supported: two AZs and three AZs. The three-AZ setup is recommended for most production setups.
Encryption, authentication, and authorization
The control plane is integrated with AWS IAM and supports authentication via AWS Signature Version 4, which uses a keyed Hash Message Authentication Code (HMAC) for authentication and Identity-based IAM policies for authorization. At this time, resource-based IAM policies are not supported. The data plane uses the Apache Kafka APIs (the Producer API, Consumer API, and the AdminClient API) and utilizes supported authentication mechanisms for Apache Kafka.
At the time of writing, TLS certificate-based mutual authentication, using certificates from AWS Certificate Manager Private Certificate Authority, and SASL/SCRAM authentication with integration with AWS Secrets Manager are supported. TLS encryption in transit between clients and brokers and in-cluster between brokers is also supported. In addition, Apache Kafka authorization using Access Control Lists (ACLs) at all resource levels is supported with both authentication mechanisms. AWS VPC security groups and network ACLs can also be used to control access to the Amazon MSK cluster in addition to the authentication and authorization mechanisms provided by Apache Kafka. It is recommended that the ZooKeeper nodes be secured by using a separate security group from the one used for the Apache Kafka broker nodes and only exposed to a specific security group utilized by an administrative client. While there is full access provided to the ZooKeeper nodes as port 2181 is open and the ZooKeeper ensemble can be used for custom applications outside of Amazon MSK, it is recommended not to do so as it is a fully managed service.
Amazon MSK provides encryption at rest by utilizing symmetric keys from AWS KMS and supports both service-managed CMKs and customer-managed CMKs. Customer-managed CMKs should be used where possible, as they provide the advantage of controlling which principals have access to the keys, the ability to audit key usage via AWS CloudTrail, and the ability to perform key rotations. Amazon MSK uses Amazon EBS volumes for storage and utilizes EBS encryption using envelope encryption.
Logging and monitoring
For monitoring, Amazon MSK has integrations with AWS CloudWatch for both metrics and brokers logs. The broker logs can also be sent directly to Amazon S3 or to Amazon Kinesis Data. The JMX metrics for the brokers is also exported using a Prometheus JMX exporter and can be scraped using a Prometheus server or other third-party software such as Datadog.
With the popularity of Apache Kafka in the industry, Amazon MSK provides a compelling managed service for Apache Kafka.
Next, let's take a brief look at a serverless event bus offered by AWS.
Amazon EventBridge
Amazon EventBridge is an implementation of the event-driven architecture pattern that AWS launched in July 2019. EventBridge is a serverless event bus service that allows you to build event-driven architectures in your applications and integrate with partners. The key advantage that EventBridge offers is the ability to remove the need for point-to-point integrations, so you can become more flexible and agile as you connect to other applications. Since it's a fully managed service, there are no servers for you to manage, and you pay only for usage, with no minimum fees or upfront commitments. The service is metered by events published, schema discovery usage, and event replay:

Figure 2.9 – Amazon EventBridge architecture
EventBridge has event buses, events, rules, and targets. The service provides an out-of-the-box event bus called "default." The event bus is the starting point to using EventBridge; it is the central hub that receives and distributes events. You can create up to 100 event buses per AWS account. An event is an indication of a change in an application, system, server, and so on. For example, an event can represent a change in an AWS service, such as an EC2 instance state change from running to shutting down, or an event from an application indicating that a customer placed an order with an item needing to be shipped. In addition to "live" events, EventBridge also allows you to schedule events just like you would do with a cron job or an application scheduler. Rules perform the filtering and routing of the events to particular targets. Rules can send an event to multiple targets and can modify the event itself by adding data or transforming event data. An event bus has a quota of up to 300 rules, with each rule pattern having up to 2,048 characters. Targets are the receiving endpoints for an event bus. Popular targets are AWS Lambda functions, SNS and SQS, and Kinesis. There is a limit of up to five targets per rule. In Chapter 8, Kinesis Integrations, we will show you how you can use EventBridge and Kinesis to implement rule-based routing.
The EventBridge Schema Registry is useful for the creation of the code bindings based on events structure. Schema Registry uses the OpenAPI and JSON Schema Draft4 standards to discover and manage these event schemas. Schema Registry can automatically generate a schema by providing the JSON of the event or allowing EventBridge to infer schemas based on the events in the event bus. Once a schema is created, you can generate code bindings for several languages, such as Java, Python, and TypeScript.
When it comes to security, Amazon EventBridge uses IAM to control access to other AWS services and resources. For data in transit, you can use TLS 1.2 or later to communicate with the event bus. When EventBridge passes data to other services, it is encrypted using TLS. Data at rest is fully encrypted using 256-bit Advanced Encryption Standard (AES-256). You can use an AWS-owned CMK, which is provided at no additional charge. The compliance certifications for Amazon EventBridge include SOC, PCI, FedRAMP, HIPAA, and several others; a full list can be found at the AWS Services in Scope by Compliance Program (https://aws.amazon.com/compliance/services-in-scope/). You can use EventBridge to send events between your AWS accounts. You can do this with your own AWS organization or accounts belonging to other organizations by controlling whether an account can send or receive events. When using the AWS Organizations feature, you can grant access at the organization level.
Service comparison summary
Figure 2.10 shows a comparison of the services under the Kinesis umbrella across various aspects relevant to streaming and messaging:

Figure 2.10 – Service comparison summary of the Kinesis umbrella of services
Figure 2.11 shows a comparison of the messaging and streaming services other than those under the Kinesis umbrella of services in AWS, across various aspects relevant to streaming and messaging:

Figure 2.11 – Service comparison summary of other AWS messaging services
The service comparison summaries take into account the most common aspects related to streaming and messaging and are intended to be a quick lookup when making a choice between AWS services for streaming and messaging architectures.
Summary
In this chapter, we reviewed the extensive array of services offered by Amazon Web Services in the messaging and streaming space. We discussed how each of these services is purpose-built to solve specific use cases and achieve application scalability and compatibility. These services have several similarities and differences, as described through the chapter. Now that we have covered all these topics, you should have a good understanding of the different AWS offerings. It should now be easier for you to pick the right service for your needs.
In the next chapters, we will focus specifically on each of the Amazon Kinesis services, with a deep dive into a fictitious use case for SmartCity, USA.