
Although this book is primarily about IAM, not IDM or IAG, it would have been a missed opportunity not to provide a short overview of some of the free open source software tools for IDM: Evolveum MidPoint, Apache Syncope, Wren:IDM, and Gluu Casa.
MidPoint, Syncope, and Wren:IDM offer traditional enterprise IDM features like approvals, workflows, synchronization connectors, and self-service password management. Casa extends the traditional capabilities of self-service password management, enabling people to manage their strong authentication credentials (two-factor). It also supports optional plugins for non-authentication self-service features, like enabling a person to revoke prior authorizations or manage client credentials.
To implement a quality enterprise identity infrastructure, the importance of IDM cannot be ignored. The cliché “garbage in, garbage out” is particularly relevant. If the underlying data used by the IAM platform is wrong, bad things will happen. The IAM platform is just one consumer of identity data from an IDM system. Many systems require up-to-date identity data. Failure to implement quality identity management processes will result in security problems and lost productivity.
As an organization grows, it becomes critical to exert control over the flow of identity information between systems. On the path from startup to enterprise, organizations organically assemble processes to keep identity information in systems up-to-date. In the beginning, there may be one person who is responsible for adding and removing accounts in various systems. They may write some scripts to make their job easier. But eventually, home-grown processes become hard to maintain, unreliable, and too manual. They don’t offer the operational leverage needed for efficiency, accuracy, and legal compliance. Enter IDM and IAG software.
IDM and IAG are not exclusively technical challenges. Deploying software is only part of the solution—there are business challenges that need to be resolved too. It is not uncommon for IDM and IAG projects to require a significant investment of time by everyone in the organization. There is no quick fix, and all levels of management should be involved in crafting the IDM strategy. End user behavior may need to change—thus IDM is cultural too.
Implementing IDM and IAG systems can require a fair amount of configuration and customization. The tools are powerful, and the learning curve can be steep. You don’t have to implement a comprehensive solution on the first try. It may be best to keep the scope tight and roll out additional functionality as you go.
This overview of MidPoint, Syncope, Wren:IDM, and Casa is just an appetizer to whet your appetite for more information. You should visit each respective website, dive into the documentation, and try out the software to get a more thorough understanding of the capabilities and business models behind the software.
MidPoint
MidPoint is a comprehensive open source IDM and IAG platform. The project is led by Evolveum, who offers professional support subscriptions to organizations using the software. MidPoint is a Java application that leverages the Spring framework for its internal structure. The source code is released under the Apache license. Evolveum engineers are the primary developers, leading a vibrant and growing community of individual and organizational contributors.
Identity provisioning and synchronization
Role management
Organizational structure management
Approval process management
Auditing
Access certification
Policy rules
Web interface
Web services
Identity Provisioning and Synchronization
At its core, MidPoint has a powerful connector-based IDM engine. A connector is a simple piece of code that moves identity data (e.g., an account) from a source system to a target system. MidPoint connectors are based on the Connectors for Identity Management (ConnId) framework that is used by many open source and commercial IDM software products. This is handy because connectors are interoperable across any ConnId-based IDM system, including MidPoint.
Connectors are relatively simple blocks of code that implement a standard interface. There is almost no IDM logic in the connector. The synchronization business logic is located inside MidPoint, reducing bloat in the connectors themselves. The same logic is reused for all connectors.
MidPoint saves the account-to-person link information in its database and continuously keeps data synchronized. Once a data mapping is configured, it is reused for provisioning, synchronization, data import tasks, and other IDM functions. This unifies IDM policy and simplifies maintenance.
MidPoint can also map data to populate account attributes. A mapping can pass values unchanged or can transform values with a script (Groovy, JavaScript, or Python). Conditional mapping provides flexibility for propagating data based on context, such as a role or association with an organizational unit. Administrators can also define manual processes to supplement data with information provided by business people.
Synchronization can be configured to work in “both directions”. For example, MidPoint can push information about a person from a Human Resources system to an LDAP server. The LDAP server itself may be authoritative for other information, like the person’s password. MidPoint can aggregate the data and synchronize it to all required systems.
MidPoint can synchronize data about any object type that is accessible by a connector, not just user attributes. For example, MidPoint can read data from a relational database table and create an LDAP subtree or a nested group, use the location of an entry in the LDAP tree to provision data in a relational database table, or automatically create an LDAP role entry based on group.
Connectors can also be configured to send notifications to alert people that their account was provisioned. They can also perform system administration tasks, such as the creation of home directories, mailboxes, or password policies. The possibilities are almost limitless.
Role Management
Roles are used by most IDM platforms and are central to how MidPoint organizes privileges. Role Based Access Control (RBAC) is a strategy used by many organizations to authorize access to resources. However, RBAC has a dark side: if roles are used to reference each unique access requirement, the number of roles can grow exponentially. In fact, some organizations have more roles than people! This is known as “role explosion”. MidPoint uses several strategies to reduce the impact of role explosion, such as enabling dynamic expressions inside roles to make roles conditional, so one role is included in another role only if a specific condition is satisfied.
MidPoint roles may be based on specific user data, or a parameter of the role itself. For example, roles such as Sales Assistant, Engineering Assistant, and Logistics Assistant can be simplified with one generic Assistant role, where the organizational unit (sales, engineering, or logistics) is just a parameter to that role.
In MidPoint, role evaluation can be applied to the roles themselves, enabling the creation of meta-roles. For example, it is common for roles to be divided into several types, such as application roles, business roles, or technical roles. Roles may share common characteristics such as an approval process or lifecycle policy. Instead of duplicating common attributes, business roles may be assigned a meta-role to define common characteristics across all business roles.
Organizational Structure
Traditional IDM is primarily concerned with synchronizing changed information about people, but many important changes aren’t about the person, rather their place in the organization. Organizational structure such as regions, divisions, departments, work groups, projects, sub-projects, ad hoc teams, faculties, classes, realms, tenants, and domains all affect which systems a person should be able to access. Many parallel organizational structures can be modeled in MidPoint. For example, there may be one big tree that represents a functional organizational structure, and a semi-flat structure of projects, ad hoc groups, and so on. A person may belong to any number of organizational units in any organizational structure. Mathematically speaking: if your structure can be expressed as an acyclic oriented graph, it can be modeled in MidPoint.
Membership in an organizational structure may include privileges to access certain resources. Therefore, organizational units can be used to control access in the same way as roles. However, the leaders of a business unit may have different access than ordinary members. In MidPoint, the organizational unit manager is a specific relation a user can have to the organizational unit and is decoupled from organizational unit membership itself. This enables a person to be a manager of an organizational unit of which they are not a member.
Organizational structure can be synchronized in the same way as a person’s accounts. MidPoint mappings can be used to transform organizational structure and maintain it in the form of LDAP groups, organizational units (OUs), entitlements, roles, or almost any form.
Approval Processes
MidPoint can assign roles and organizational units automatically, for example, based on job codes. This is an efficient and scalable approach, but is typically only feasible for a small subset of roles. Administrators can manually assign other roles and organizational units, but this is not scalable. Therefore, most IDM deployments use a process-based approach where the person requests required roles. The request is then routed through an approval process where individual approvers can make decisions about the request.
Frequently, the first stage of the approval process is performed by a person’s manager. Further stages may require approval from a business owner, security officer, resource owner, or project manager. In most IDM platforms, the approval process is driven by an internal workflow engine, which is customized using a workflow language such as Business Process Model and Notation (BPMN). This is a very flexible approach, however, approval workflows tend to get extremely complicated and can become difficult to maintain.
Rather than complex custom workflows, MidPoint supports “policy-based” approval processes driven by declarative approval policies. The approval process for each role request is dynamically computed based on associated policies. An approval policy can be defined globally, individually for each role, or for a group of roles (using the meta-role mechanism). A policy may specify approval stages that are mandatory, optional or conditional. Each stage may have different approvers or approver groups. MidPoint also supports approval escalation, delegation, and auditing. Policy-based approval means no programming is needed to set up an approval process, enabling very complex policies to be defined and maintained efficiently.
Even though MidPoint offers strategies to reduce role explosion, there may still be tens or hundreds of roles in the system. To simplify the process of assigning roles, MidPoint offers a role catalog and shopping-cart style request process for people to browse categories, select the appropriate roles, and request approval.
Midpoint Delegated Application Security Model
MidPoint’s internal authorization mechanism controls access to MidPoint objects such as users, roles, organizational units and resources. Fine-grain authorization policies can be specified down to the level of individual object properties. The authorization mechanism is aware of the organizational structure, enabling delegation of identity administration within an organizational unit to its respective managers, and the delegation of roles to its owner. The same mechanisms used to access target systems can be used to obtain access to MidPoint itself. Therefore, access to data in MidPoint can be requested, approved, and audited.
MidPoint also enables a person to specify a “deputy” who can temporarily obtain their authorizations and privileges. This can be useful when a person is traveling or on leave. The deputy can access the work items (approval decisions) of the delegating user. The deputy also gains access to entitlements in target systems, for example temporary assignment to the same LDAP groups. Privileges are automatically revoked when the operational time has concluded. Deputy functionality is meant to provide continuity of business processes both inside MidPoint and in target systems.
Auditing
MidPoint can maintain an audit trail for changes to data about people, roles, organizational structure, and configuration. A complete description of changes and any useful metadata is available for any MidPoint object. A feature called “time machine” enables the restoration of any past state. Audit trails are recorded in a database table and can be used to integrate MidPoint with security information and event management (SIEM) or data warehouse systems.
Access Certification
Role request and approval processes tend to result in a person accumulating many roles over time. However, because removal of roles no-longer-needed is often overlooked, it’s important for organizations to regularly perform access certification campaigns (i.e., “recertification” or “attestation”). For example, once per year, managers may need to decide if the roles assigned to subordinate employees are still needed. The MidPoint web interface enables managers to efficiently make these decisions. Once certification decisions have been submitted, any superfluous roles are automatically marked for removal and unassigned.
Removal of a non-sensitive role is not an urgent matter. However, certain situations might require faster action, for example if an employee is moved to a different organizational unit with a different manager. The new manager assumes responsibility for the employee’s roles and should execute an ad hoc recertification process for that specific user.
Policy Rules
Businesses must abide by certain rules and regulations. Executives are tasked with determining which rules are appropriate. Information technology professionals are responsible for implementing those rules in systems. An example is segregation of duties (SoD). For instance, it may be inadvisable for a person to both write and sign checks. Another example—at an investment banking firm, you can’t advise companies about mergers and acquisitions and trade securities.
Midpoint policies express rules governing organizational structures and roles, such as “a project must have at most one manager” or “a role must have at least one owner”. Policy rules can express policy-based approvals, which may also govern role lifecycles. The totality of policies determines the governance of the organization.
A single policy rule has two parts: a constraint and an action. A constraint defines a situation or event where the rule applies, such as “A is assigned to a user” or “A is assigned together with B”. If the constraint is triggered, then an action takes place. Actions may be as simple as “prohibit such an operation”. But actions can also be complex, for example, removing all conflicting assignments or driving a request through an approval process or re-certification.
Policy rules can be combined to form more complex business logic, such as “prohibit assignment of A and B at the same time”. MidPoint enables administrators to combine policy rules with meta-roles and approval processes. An example might be: “if any two roles from this set of roles are assigned to the same person, then drive the request through an approval by a security officer”. Such combinations are used to implement advanced features like ad hoc recertification and role lifecycle management.
User Interface (UI)
End user self-service management of identity data, for example allowing people to edit their user profiles, change their passwords, or request new roles.
Identity administration, such as managing user data, roles, organizational structure, approvals, and access certifications.
Configuration of the MidPoint system.
The MidPoint UI is designed to automatically adapt to custom inputs. For example, an LDAP server may have a custom LDAP attribute called “foo”. When MidPoint connects to that LDAP server for the first time, it retrieves its schema, including the custom “foo” attribute. The resource schema is stored in MidPoint and automatically used for all data processing. It is also immediately reflected in the web user interface, automatically rendering an input field for that attribute. No programming or customization is needed to use this functionality. The web interface also automatically adapts to authorizations. Only those pages to which the user has access are displayed, and all inaccessible forms and input fields are hidden or displayed as read-only.
Of course, some customization may be required. MidPoint offers configuration options to specify how certain parts of the web interface behave, for example, to hide widgets or unused features.
Services and Integration
RESTful interface, which is an HTTP-based interface that exposes MidPoint functionality by following applicable RESTful principles. Data is presented in XML, JSON, or YAML data formats.
SOAP interface specified using WSDL and XSD standards.
Java interface, which is a natural choice for Java extension code, e.g., when using overlay projects and extensions based on source code modifications.
All three interfaces offer roughly equivalent functionality. The Java libraries are used by the MidPoint UI, therefore, those interfaces can be used to build a custom UI or to integrate MidPoint with other systems for management, advanced tooling, or various other purposes.
Other MidPoint Features
MidPoint offers additional features not included in this overview, including flexible reporting capabilities, self-registration and self-service password reset procedures, self-healing capabilities, and virtual identities (or “personas”). In addition, the IDM system is an ideal place to track and protect identity data, and development is ongoing to add features to enable better protection of data—a key requirement for compliance with the European Union General Data Protection Regulation (GDPR ).
Get Started with MidPoint
Visit the Evolveum MidPoint wiki to learn how to get started: https://wiki.evolveum.com/display/midPoint/Introduction .
Apache Syncope
- Provisioning:
Synchronization of users, groups, or other objects (e.g., printers, services, or sensors). Definition of realms—primarily meant for containing users, groups, or other objects. Identity lifecycle management.
Full reconciliation and live synchronization from external resources. Workflow based approval.
- Identity Governance and Administration, including:
Reports
Auditing
Administrative web application for full system management, delegated administration, self-service registration, and profile management.
Command Line Interface (CLI) for easy integration with system tools.
JAX-RS 2.0-compliant, full-fledged RESTful interface to access all services.
Syncope Architecture
The latest JDK 8 available
A Java EE Container, such as Tomcat, Payara Server, or Wildfly
A relational DBMS, such as PostgreSQL, MySQL, MariaDB, Oracle DB, or MS SQL Server
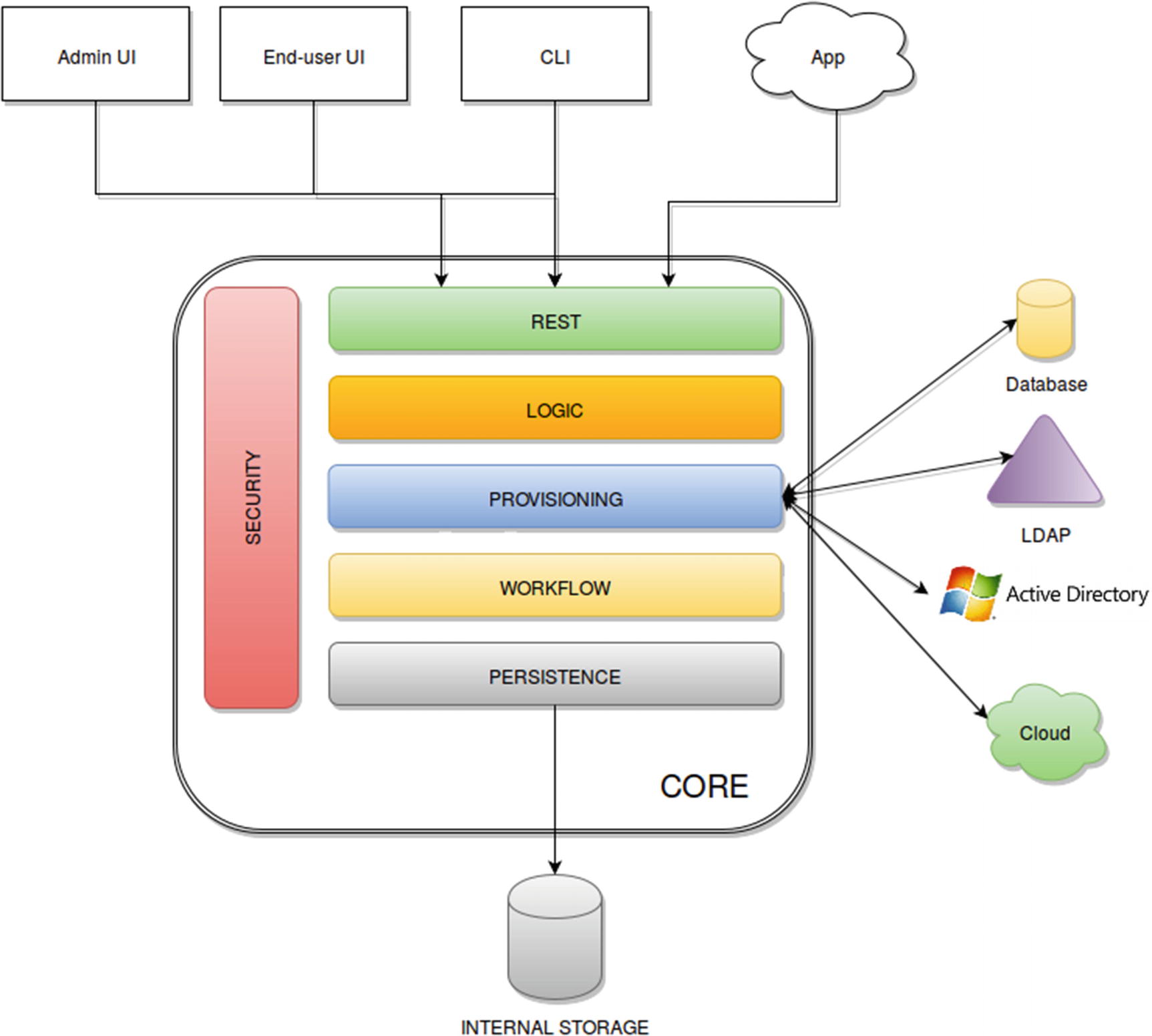
Admin UI is the web-based console for configuring and administering active deployments, with full support for delegated administration.
End User UI is the web-based application for self-registration, self-service, and password reset.
CLI is the command-line application for interacting with Apache Syncope from scripts, particularly useful for system administrators.
Core is the central component, providing all services offered by Apache Syncope.
Logic—Implements the overall business logic that can be triggered via REST services and controls some additional features (notifications, reports, and auditing).
Provisioning—Manages the internal (via workflow) and external (via specific connectors) representation of users, groups, and any objects.
Workflow—Chooses the preferred engine from a provided list, including one based on Activiti BPM and another based on Flowable, the reference open source BPMN 2.0 implementations. Alternatively, you can define new and custom workflows as needed.
Persistence—Manages all data (users, groups, attributes, resources, etc.) at a high level using a standard JPA 2.0 approach. The data is persisted to an underlying database (internal storage).
Security—Defines a fine-grained set of entitlements that can be granted to administrators, thus enabling the implementation of delegated administration scenarios.
The REST interface can be accessed either via the Java client library or using plain HTTPS calls.
Syncope Provisioning
Like MidPoint, the Provisioning layer for Syncope relies on ConnId. ConnId is the continuation of The Identity Connectors Framework (Sun ICF) project, which used to be part of the Sun Microsystem IDM product and has since been released as an open source project. This makes the connectors layer particularly reliable because most connectors have already been implemented in the framework and widely tested.

Syncope interactivities
Syncope Extensions
Swagger UI—Enables Swagger UI as a web interface to work with Syncope RESTful services.
SSO Support—Provides both OpenID Connect and SAML 2.0 access to the administrative or end user web interfaces.
Apache Camel Provisioning Manager—Delegates the provisioning process execution to a set of Apache Camel routes, which can be dynamically changed at runtime via the REST interfaces or the administrative console. Modifications are immediately available for processing.
Elasticsearch—Provides an alternate internal search engine for users, groups, and objects, requiring an external Elasticsearch cluster.
SCIM—Provides new REST endpoints implementing the communication according to the SCIM 2.0 standard, in order to provision User, Enterprise User, and Group SCIM entities to Apache Syncope.
Maven artifacts published by third parties.
Syncope Installation
Standalone distribution—The simplest way to start exploring Syncope, the standalone distribution contains a fully working, in-memory Tomcat-based environment that can be easily deployed on a laptop, workstation, or server.
Debian packages—Available for use with Debian GNU/Linux, Ubuntu, and their derivatives.
Installer—A GUI application for configuring and deploying on supported DBMSes and Java EE containers.
Maven project—The preferred method for working with Apache Syncope, the Maven Project provides access to the full set of customization and extension capabilities.
Visit the Apache Syncope documentation to learn how to get a local instance up and running: http://syncope.apache.org/docs/getting-started.html .
Wren:IDM
Wren:IDM is a community-developed identity management system with a flexible data model, multiple extension points, and scripting support, including JavaScript and Groovy. It can connect to and manage a wide range of systems through the Identity Connector Framework (Wren:ICF).
Wren:IDM is one of the projects in the Wren Security Suite, a community initiative that adopted open source projects formerly developed by ForgeRock, which has its own roots in Sun Microsystems’ products.
The project is also an example of open source philosophy benefits in practice. In 2017, when it became apparent that ForgeRock reduced their open source commitment, the “it’s time for a fork” initiative arose. It collected developers and engineers willing to sustain and evolve the latest open source code available before it was closed. ForgeRock no longer releases any of the most recent versions of their software under an open source license and the current ForgeRock’s Community Editions are several major versions behind what was previously offered under the CDDL license. But luckily, once code is open sourced, its copies can’t be “un-open sourced”. The community, which broke away from the closed-source model, was later named Wren Security: https://wrensecurity.org/ .
Access management in Wren:AM (formerly OpenAM)
Directory server in Wren:DS (formerly OpenDJ)
Identity management in Wren:IDM (formerly OpenIDM)
Identity Connector Framework Wren:ICF (formerly OpenICF and ICF), a special part of the IDM solution, which also provides a set of production-ready connectors—LDAP, Office 365, SPML, SSH, SQL, PowerShell, REST, and many more
Wren:IDM itself is focused on identity management processes and also provides a powerful framework for implementing IAG and a portion of IAM processes. Although the project is based on OpenIDM code, it is not affiliated with ForgeRock in any way. It is based on the very latest code available under a CDDL license (not-yet-released OpenIDM 5.x).
A complete platform—Used for building IDM and IG solutions using the concepts described next, including roles, mappings, synchronizations, workflows, policies, etc.
ICF connector servers—Services that allow connectors to be run outside of the IDM itself. Useful when a connector needs a specific client environment to talk to the integrated system. Also facilitates security. .NET and Java Connector Servers are available.
Administration GUI—An interface for making changes to data models and configuration using a point-and-click interface rather than Wren:IDM’s REST interface.
Self-service GUI—An interface for end users to update their profile information, passwords, and preferences.
Both the Administration GUI and Self-Service GUI are web-based, single-page applications that can be turned off in deployments that do not desire to use them.
Wren:IDM Quick Start
- 1.
Visit https://wrenscurity.org to get the Wren:IDM package, either by downloading a binary package or building from the latest sources.
- 2.
Make sure you have Java 8+ installed. Both OpenJDK and Oracle JDK work well. Extract the package to a folder and navigate there using your terminal.
- 3.
Run the startup script startup.sh (UNIX/Linux) or startup.bat (MS Windows).
- 4.
Open http://localhost:8080/admin in your web browser, log in with the default credentials openidm-admin:openidm-admin, and explore the administration interface (see Figure 9-3).

Wren:IDM basic administration dashboard
System Overview
Managed objects—Maintained in IDM’s repository
System objects—Represent external resources such as accounts
Configuration objects—Represent various aspects of IDM configuration
Workflow objects—Represent approval process or other business processes

Wren:IDM component overview
Wren:IDM Implementation Basics
JSON-based object model applies to the configuration as well. This is why you’ll see so much JSON while examining Wren:IDM. IDM can be managed using an admin GUI, but the admin actions still result in REST API calls. And the configuration ends up in human-readable, structured files.
This way the IDM unites the worlds of GUI-based management, API-based programmatic administration, and config-file-based administration. Organizations may find it useful to abandon the GUI-based (i.e., IDM repository-based) configuration in favor of using file-based configuration management. While the former provides IDM-level auditing, the latter allows leveraging standard SCM tools like git, which may better fit into modern devops environments. You can also combine these approaches.
Audit—Component for auditing of all triggered events and states
Repository—Persistence layer for storing all managed objects
Script engine—Component for scripts execution (JavaScript or Groovy)
Scheduler—Component for executing scheduled jobs
Policy—Component for executing validations during object modifications
Workflow—Embedded workflow engine based on Activiti
Crypto—Component for data encryption
Security—Component for handling REST API security
Managed objects—IDM managed objects like users, roles, or any objects the organization uses
System objects—Integrated system objects
Provisioner—Abstract layer for integrating external systems
Custom endpoints—REST API endpoints defined by the implementers to provide their own business logic
Wren:IDM takes a path of extension over modification. Every aspect of the system—from the data model to the framework configuration—is configurable. Implementers can use the Wren:IDM framework and its components in whichever way best meets their needs. The domain data model and its database representation are also solely in implementers’ hands. Your custom entities don’t have to end up in tables like custom_object, custom_attribute, and custom_attr_value, known from common customizable systems. The DB structure can follow your conventions, allowing the data to be better examined by administrators and even transferred to another system in the event of migration.
Wren:IDM Sample Update to a Custom Object
Wren:IDM Sample Audit Record
Wren:IDM Pre-Defined Types
There are a number of pre-defined types in Wren:IDM.
Managed User
This is a pre-defined managed object type representing a user identity and its attributes.
Managed Group
This is a pre-defined managed object type representing a low-level access right in a target system, e.g., an LDAP group. It is optional—organizations that do not use groups may use roles instead.
Roles
These can be either authorization roles, which grant rights within the IDM itself, or provisioning roles, which define how objects are provisioned in target systems. Roles are managed objects, which means they can be extended to contain additional information or invoke scripts, just like any other IDM object.
Role Grants
These relate users and roles . They can be either manual or conditional. For example, they can be triggered automatically based on a matching query. As with any managed object, role grants can carry any number of additional properties—such as temporal constraints (e.g., “users have this role for 90 days”).
Effective Roles
These indicate which roles a user ends up with after applying additional logic. By default, the effective role of a user matches his role grants. In more complex deployments, effective roles can also be calculated using a custom script that may alter the result: filtering out some role grants, or adding additional role grants. Such a script might even calculate the resultant roles on-the-fly, without considering any role grants at all.
Role Assignments (aka Assignments)
These set rules for how roles are provisioned in a particular system. For example, they might indicate that a user with the role of “Broker” gets an account created in the CRM system. There can be several assignments defined for a role.
Effective Assignments
These indicate which assignments a user ends up with after applying additional logic, similar in concept to effective roles. By default, a user’s effective assignments are the same as the assignments attached to the user’s roles. As with effective roles, a script may calculate effective assignments, enabling you to more finely control role assignment.
Relationships
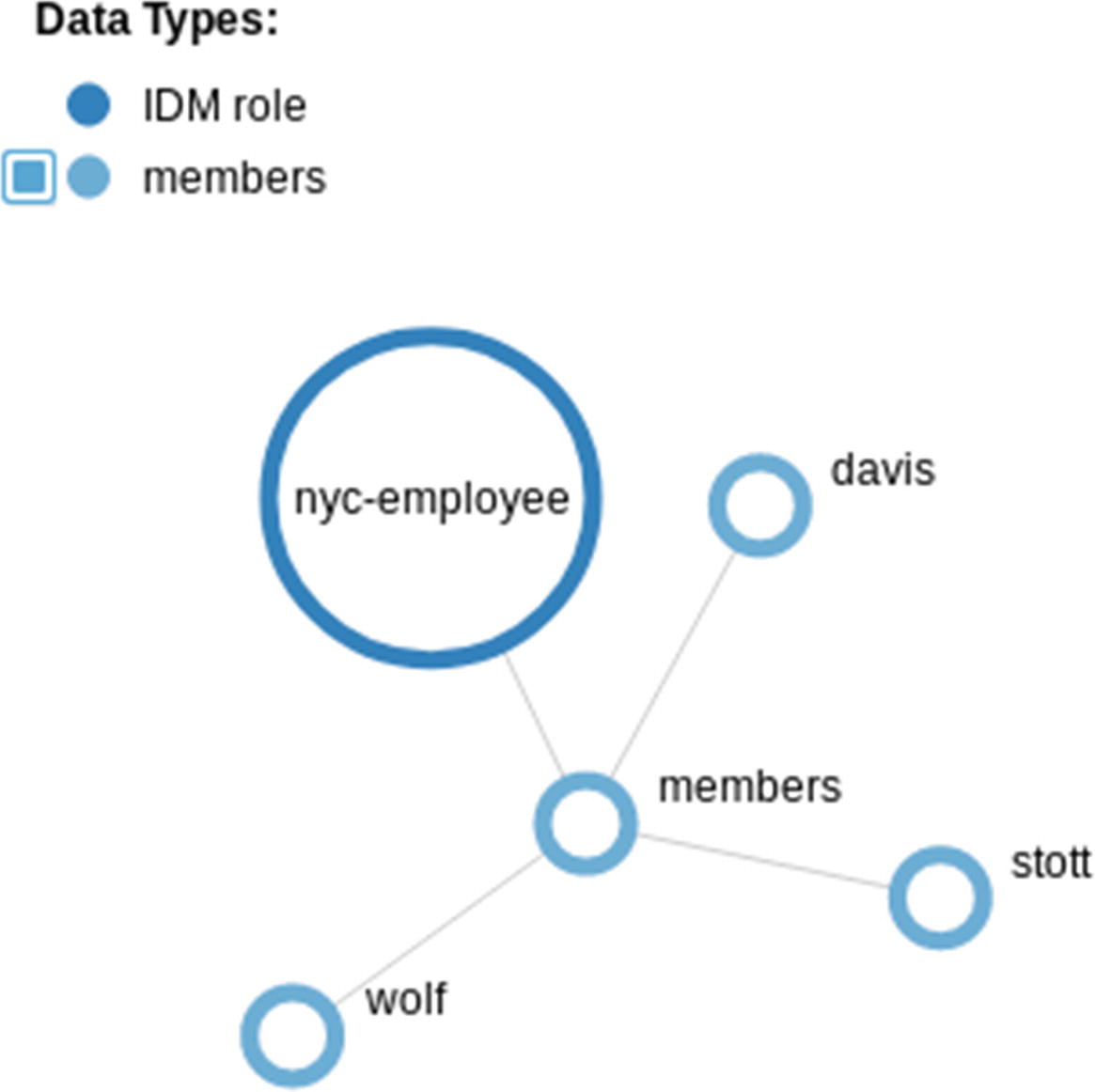
Relationship visualization
Triggers
These are extension points that allow invoking some logic on a managed object before an operation happens. For example, effective roles are calculated by invoking an onRetrieve script defined on the effectiveRoles attribute of user records. Such logic can be written in either JavaScript or Groovy—depending on whichever best suits the needs of the implementer for the use case.
There is nothing inherently special about the pre-defined types mentioned in this section. In a new installation, these types have some behavior that controls how provisioning is done, but this behavior is defined in the same way that you define behavior for any custom type. Provisioning is simply modeled through managed object definitions, relationships, and triggers. All of this logic is configurable and modifiable by the implementer, giving full control over the logic the system ends up using to manage identities.
Wren:IDM Processes
Beyond the data and entitlements that Wren:IDM manages, there are also several processes Wren:IDM uses to maintain the data. These concepts include the following.
Policies
These processes enforce validation rules for managed objects. They can be enforced automatically and/or used directly as a validation service.
Reconciliation and Synchronization
Mappings—Define the transformations between source and target systems. Mappings are also referenced from role assignments.
Correlations—Define how to match objects between source and target if they are not linked. Especially useful when rolling out the IDM. Can be also defined programmatically using correlation scripts.
Synchronization situations—Represent an evaluated result of source and target comparison, such as FOUND, MISSING, CONFIRMED, etc.
Synchronization actions—Represent the configured reaction to a synchronization situation, such as UPDATE, UNLINK, IGNORE, ASYNC, etc.
- There are subtle but important differences between reconciliation and synchronization:
With reconciliation—A full synchronization of objects in source and target systems takes place.
With synchronization (aka “LiveSync”)—Just a particular delta is synchronized, allowing it to be run frequently and changes to be quickly reflected .
Scheduling
This process controls when synchronization happens. Without a schedule, systems are only reconciled manually, on-demand.
Password Synchronization
This feature allows users to have the same password among multiple target systems, even when such systems might use different ways to hash or encrypt passwords. Wren:IDM supports plugins that can be installed in target systems to intercept password changes that occur outside of IDM, so that these changes can be propagated to all of the systems that the user needs access to.
Workflows
This process is the key to integrating identity management into business activities, including approvals, escalations, recertifications, and many others. Wren:IDM uses the Activiti BPMN 2 Engine for modeling and executing workflows. Workflows are exposed through the standard IDM resource API. Implementers can use standard Activiti tools—including the Activiti Designer—to define and edit workflows.
Example: Make Your Own Self-Service GUI
You can use the Wren:IDM default user-facing self-service website. However, there might be situations when a custom solution is preferable, either for self-service or for administrative tasks performed by, for example, the help desk staff. The simplicity of implementing such a solution is one of the strengths of the platform. The following steps provide an overview of how to create a custom self-service website.
Creating an Endpoint Configuration in Wren:IDM Sample
Sample Endpoint Implementation
Wren:IDM Sample Endpoint Security
Customizing the Wren:IDM User Interface
Example: Consent Governance
Role and assignment resolution mechanisms also provide a way for various IAG rules to be enforced in real time.
For example, let’s imagine a company “H.Q. Pennyworth & Co,” which has brokers who work with clients. Imagine that the firm has a business rule that requires brokers to make contact information readily available to those clients. To enforce this rule while complying with local regulations, a Pennyworth broker must consent to sharing his personal contact information. If a broker has not yet consented, you want to restrict either his roles or resource grants. In such a case, having the broker role is a necessary—but not sufficient—requirement for having broker access.
Restriction at the role resolution level—An employee without consent won’t effectively get the broker role even if it is assigned to them.
Restriction at the assignment resolution level—An employee without consent can effectively get the broker role, but they still won’t be eligible to get the assigned resources.
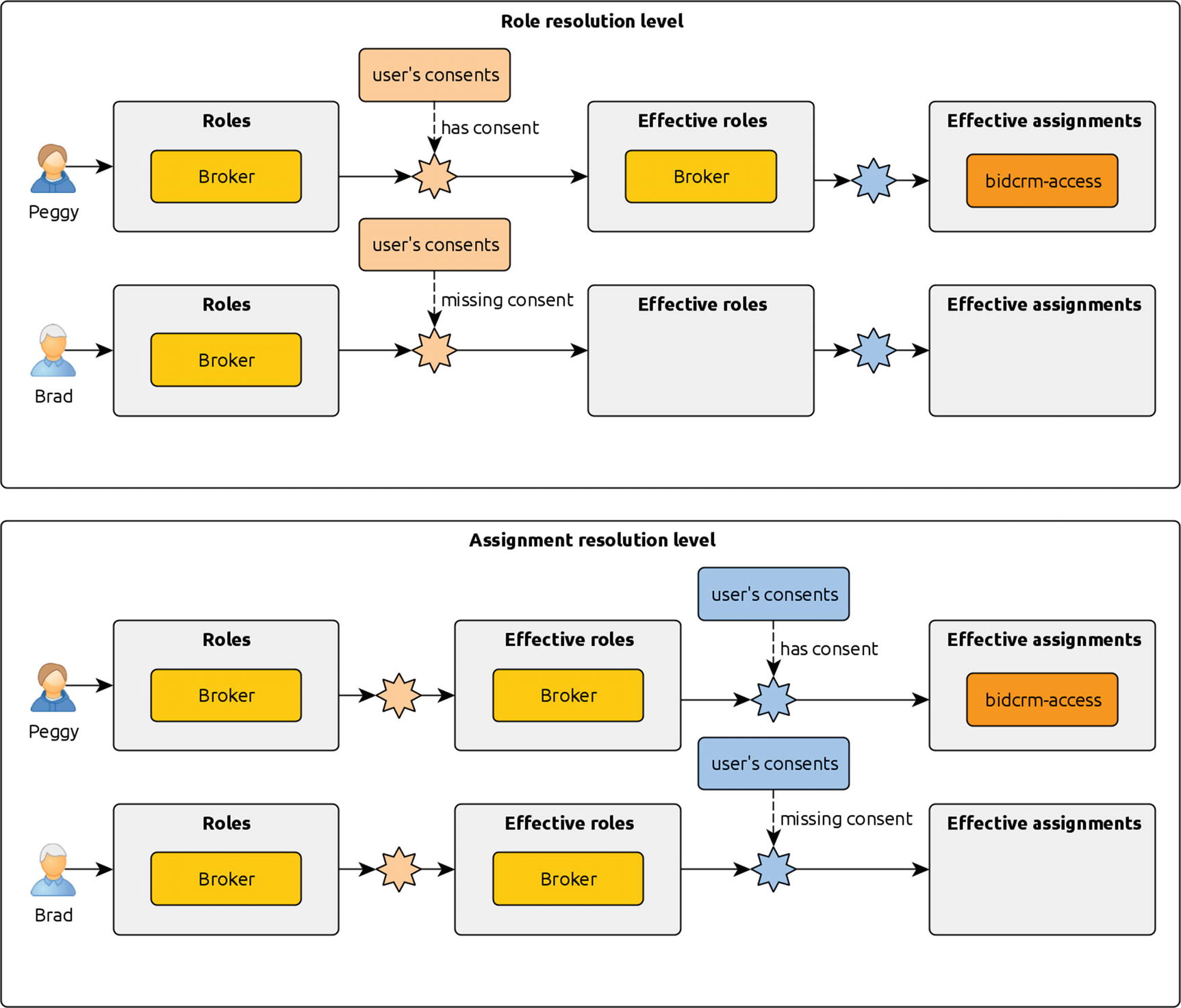
Enforcing the consent condition in H.Q. Pennyworth & Co: effective roles or effective assignments
Example: Connector Configuration with Object Mapping Transformations

Sample connector and mapping scenario
Wren:IDM Sample Connector Configuration Sample
Wren:IDM mapping Configuration Sample
When Is Wren:IDM Suitable?
In small to medium organizations that have only a single location —or multiple locations where identity information is owned by a single location—other IDM products that make a lot of assumptions about corporate structure may be faster to implement.
In medium to large organizations, where there are branch offices and/or organizational units that need to have autonomous control over their identity information, Wren:IDM is an excellent fit.
Effectively, Wren:IDM is so flexible that you could end up spending a lot of time on integration when something out-of-the-box fits your model. But if your organization isn’t cookie-cutter, and you have some requirements that take you a little outside of the other solutions, then Wren:IDM is a better solution, even if it might take a bit more time to integrate, because it’s built to handle the customization. The time spent integrating pays off in flexibility and maintainability of the implementation.
Rolling Out Wren:IDM to Production
Wren:IDM can run with any JDBC-connected database, but has been tested with PostgreSQL, MySQL, Oracle, and Microsoft SQL. In addition, for local development and testing purposes, it also ships with an embedded copy of OrientDB. In general, Wren:IDM shares dependencies common to any lightweight JEE application. It runs both on Oracle JDK and OpenJDK.
A single, commodity-hardware machine with 4GB of RAM would be sufficient to run the whole solution, including a PostgreSQL database server on a Linux operating system. The requirements grow with the number and frequency of scheduled tasks and complexity of the particular actions. The system can be also operated in a cluster. While high availability is usually not a requirement for IDMs, cluster-based deployment can help by distribute reconciliation tasks across several nodes. In addition, if direct access to target systems from the IDM is not possible or desirable (e.g., the target system is local, but IDM is running on Amazon EC2), connector servers can be used to provide an interface from the IDM to the target system.
The limiting factor in most deployments is the I/O throughput of the target system; specifically, how quickly such a system can query records and return them. If you’re using existing connectors, take note of options that can reduce the amount of data that a connector will need to request from the remote system (e.g., limit base DNs, filter out objectclasses that are not of interest). If you’re developing custom connectors for an IDM project, it is best to optimize the connector to query the target system for as few records as possible.
- 1.
Plan out your deployment ahead of time.
- 2.
Integrate with each target system one at a time. Isolation can help to reveal bottlenecks.
- 3.
Test the system as you go rather than testing everything at the end of implementation.
There are several approaches to deploying and testing Wren:IDM. A good implementer can leverage software engineering best practices such as using SCM, test-driven development, continuous integration, and continuous delivery. Wren:IDM works best in such a process.
Gluu Casa
MidPoint, Syncope, and Wren:IDM offer enterprise IDM and IAG tools, and even some handy user-facing self-service functionality. However, data related to a person’s web authentication and authorization preferences is outside the scope of traditional IDM and IAG systems.
Enroll and manage two-factor authentication (2FA) credentials and preferences (e.g., phone numbers, U2F keys, OTP, etc.)
View and revoke consent decisions (e.g., which applications have what access to personal data)
Add and remove social login accounts (e.g., Facebook or GitHub)
Request and manage OAuth client credentials
Gluu Casa (Casa) offers a user-facing, self-service dashboard for managing these newer self-service requirements. It’s available under the free open source MIT License.
Architecture
Casa is a Java EE web application that runs inside the Gluu Server’s chroot container, although it’s distributed as a separate package. Casa interacts directly with Gluu’s underlying LDAP server and file system, and uses the oxd-java library to leverage Gluu’s OpenID Connect Provider (OP) and UMA Authorization Server (AS) functionalities. Casa is built using frameworks such as Weld, ZK, and RestEasy.
Casa’s core functionality—self-service 2FA management—is enabled via a Gluu Server custom authentication script written in Jython. The script enables a person to specify their preferences for 2FA—whether to prompt for every authentication, to remember a certain location, or to remember the browser.
2FA Credential Management
2FA can significantly increase account security. However, security is only as strong as its weakest link. If you have a strong authentication mechanism, but you can use email to recover from a lost credential, your security is degraded. Control of email is an even weaker credential than a password! If a human operator can reset a strong credential, people are extremely susceptible to social engineering. Don’t hack the crypto—hack the people! Account recovery is the Achilles heel of 2FA, as an authentication mechanism is only as strong as the weakest recovery process.
As there are no widely accepted Internet standards for account recovery and strong authentication, it can be helpful to review and mimic how industry giants like Google support these important security processes. With one billion user accounts, Google has lots of data to determine how to roll out secure and usable 2FA.
Google supports several types of authentication: SMS, OTP, FIDO tokens, and several others. With billions of accounts, strong security can’t come at the expense of usability—that’s why Google offers a self-service portal where people can enroll, delete, and manage their own strong credentials.
Gluu Casa provides an open source solution that organizations can use to offer a similar user-facing, self-service 2FA experience. In the Casa dashboard, people can enroll and manage their strong authentication credentials to secure their accounts.
Out-of-the-box, Casa supports the same credentials as Google: FIDO, OTP, SMS, and mobile push (using Super Gluu). This combination of 2FA options makes strong security available to anyone with a mobile phone. The self-service dashboard empowers people to enroll multiple strong credentials to thoroughly secure their account.
Net-net, the value of the transaction should drive security enforcement, and in the Casa administration web interface, system administrators can manage which 2FA mechanisms are enabled and supported by the system.
Consent Management
Federated identity enables people to leverage an existing account in an identity provider (IDP) to create and maintain a passwordless account in an external service provider application (SP). For example, when you “Sign in with Google” to an unaffiliated third-party website, Google may send along personal information about you that will be used to create a local profile for you (sans password). In these situations, before allowing you to proceed, the IDP will prompt you to “consent” to the release of personal information (in OAuth jargon, this is the authorization). In addition, Google may prompt you to authorize the third-party website to perform actions on your behalf, for example to access your contacts or update your calendar.
As the user’s window into the authentication system, Casa provides a UI for reviewing and revoking previously made consent decisions. For example, if you sign in to Dropbox using your Gluu IDP account, then decide you no longer want Dropbox to be able to control your calendar, you can revoke your consent decision in Casa. The third-party website could (and likely would) retain a copy of any personal data previously shared, but would no longer have authorization to perform actions on your behalf—it would need to re-prompt you for consent if you attempt to access the service again using your external IDP account.
Social Login Account Management
Creating and remembering passwords for each service is not only a terrible user experience, but people tend to re-use passwords in many systems, which can quickly lead to account security issues. Not all systems are secured equally! Spreading your password across the Internet like the seeds of an ailanthus tree certainly increases your risk of compromise.
Casa offers people the ability to enroll and remove social login accounts available to the Gluu Server as a means of authentication. For example, you could create your account by signing in with Google, then enroll a Twitter, GitHub, and Facebook account to provide multiple options for accessing your account. This way, even if you get locked out of Google, you can still access your account.
Developer Portal
In order to support federated authentication and authorization, application developers need client credentials from the IAM system (i.e., client-id and client_secret). Client credentials enable an application to identify itself to the IAM system. Depending on the scopes granted, client credentials can be used for different purposes. Casa provides an interface for people to request and manage client credentials in the IAM system, enabling a more convenient developer experience and greater transparency and accountability for system administrators.
Getting Started
Gluu Casa can be deployed via Linux packages. Visit the documentation to learn how to get a local instance up and running: http://gluu.org/docs/casa .
Conclusion
It’s critically important to your organization’s security to get IDM right. It’s a moving target—there will always be new systems and new business process to which you will need to adapt. It won’t be easy—defining and implementing IDM requires a significant investment of time and energy.