
Chapter 4
The SA Forum Information Model: The Heart of Control and Monitoring
4.1 Introduction
This chapter introduces the Service Availability (SA) Forum information model, which was created to answer management needs and in particular that of the Availability Management Framework (AMF) to be discussed in Chapter 6. Subsequently the concepts of the AMF information model were applied to the management information of other Application Interface Specification (AIS) services; thus, the SA Forum information model was born.
The first question is why AMF needs an information model and what type of model it requires.
From Part I of the book one may see that SA management is all about coordination of the available resources so that at any moment in time there is at least one resource available in the system which is able to provide any given service that is required to be highly available. To pull off this attraction the availability manager needs to know or have a view of:
- the resources with their availability status and the services they are able provide;
- the services that the system needs to provide; and
- the relationship between these two sides.
What does all this mean when applied to some ‘random’ software application we want to be managed? To begin with someone needs to tell to our availability manager at least part of this information, that is, what the resources are and what services they should provide. They need to be given in a way that suits this ‘random’ software as well as the availability manager. In other words a system administrator needs to configure for the availability manager the application so it can interpret this information. Thus, we need an information model that includes at least this configuration information.
The information needs to be provided in an abstract and uniform way applicable to the wide variety of applications that one may want to be managed by the availability manager.
The information model needs to provide enough information for the management functionality to fulfill its task. In our case for the availability management the information needs to be enough so that it can map the software resources executing in the system at runtime and their services into this model representation and use this model representation to control those software resources with their services.
Yet the information needs to be simple enough so that an administrator will actually be capable of providing it, that is, it will be able to compose as well as to interpret the information and find its way within the model.
Besides the configuration information the availability manager needs to maintain the availability status and the current relationship between the resources capable of providing the services and the to-be-provided services. This is a piece of information that the administrator may also be interested in. For him or her knowing this information may provide an explanation why some required services are not provided by the system at a particular moment in time or that the risk is high for such an outage.
The status information is typically runtime information that is collected from the system and provided to the administrator to facilitate the monitoring and to support the administrative control. The exposure of this information is not necessary for the management functionality (e.g., availability management) itself, but there could be parties interested in the information even beyond the system administration.
In any case we can say that in a typical system a management facility managing some physical resources—whether they be software or hardware resources—abstracts these managed resources into some logical entities that characterize the resources from the perspective of that management functionality.
In turn some or all of these logical entities can be reflected in an information model as managed objects that may expose the status of the represented resources from the perspective of the management functionality and/or allow the system administrator to configure and control the management functionality and its resources. The collection of these managed objects composes an information model, which serves as an interface between the system and the system administration.
Considering different management functionalities in a system where each of them exposes its own information model, it is possible that the combined system information model exposes the same physical resource through multiple managed objects, each representing a particular management aspect of that resource. For example, even within the availability management we have already distinguished the service provider aspect of a resource from the services it provides.
In this chapter we take a look at the main concepts used in SA Forum systems when it comes to management information. This allows newcomers to have an easier way to understand the application of these concepts to the different SA Forum services when they try to interpret their information models. In turn this information also provides guidelines for application designers wanting or needing to extend the SA Forum system information model for their applications.
4.2 Background
4.2.1 Management Models Out There
Many systems have faced in the past, and will face in the future, this problem of how to provide an adequate management view of the system; and there are numerous solutions addressing it. Some of these solutions are more suitable for the management functionality itself or a particular class of them; in other cases they favor the administration functions. It is almost always a trade-off between providing a comprehensive view and set of controls of the various system functions and resources on the one hand and a simple and secure view for the system administrator on the other. The solution is further flavored by the particular area of technology for which it was developed.
Among the best known existing solutions we need to mention the Internet Engineering Task Force (IETF) regulated Management Information Base (MIB), which is a ‘virtual information store’—essentially a database of management information for a particular type of system. Initially the target system was the Internet, but it could be and was applied to other systems as well including the SA Forum system. To provide a management interface the SA Forum started out with defining MIBs for its services.
The initial version of MIB-I [51] quickly evolved into MIB-II [52], which has become ubiquitous on the Internet and it is used in conjunction with the Simple Network Management Protocol (SNMP) [53]. The managed objects of the MIB are defined using a subset of the Abstract Syntax Notation One (ASN.1) [54]. IETF specifies the used subset in the Structure of Management Information Version 2 (SMIv2) [55]. Multiple related objects are organized into tables, which together with the scalar objects (i.e., defining a single object) are organized into a tree hierarchy. From the management perspective, an object is a data structure that characterizes some resource (e.g., device, interface) in the system that an administrator would like to control. To this end it uses an SNMP ‘agent,’ which is capable of receiving the instructions of the administrator in reference to such an object, interpreting the data structure, and applying it to the resource represented by the object.
The SA Forum applied the MIB approach to the hardware platform interface for which it was well suited but it turned out to be less suited to the needs of the AMF [48]—the flagship specification of the SA Forum. In particular it was cumbersome to accommodate the dynamic nature of the relationships of the AMF model with the numerical enumeration of the naming hierarchy of the MIB. Similar conclusions lead IETF to develop the Network Configuration Protocol (NETCONF) [56] and its associated data modeling language YANG [57]. NETCONF provides mechanisms to install, manipulate, and delete the configuration of network devices, for which the configuration and state data are modeled in YANG. The primary target area of NETCONF and YANG—not surprisingly—remained the Internet as it was for the MIB and SNMP. YANG would have been more suitable for the SA Forum needs, but it came late. By the time it has been approved by IETF the SA Forum had its model defined using the Unified Modeling Language (UML) [59].
A competing and similarly recent standard defining management information is the Common Information Model (CIM) [58] standardized by the Distributed Management Task Force (DMTF) for the IT environments in general. It is an object-oriented approach to represent the management information in a vendor independent way for a wide variety of managed elements such as computer systems, operating systems, networks, middleware, devices, and so on. In the Core Model DMTF defines the concepts common for all targeted areas. Although extendable, this part is expected to stay stable over time. In addition for each of the target areas DMTF defines a still technology independent Common Model. The Core and Common Models provide a starting point to analyze and describe any managed system. The Common Models are extendable in Extension Schemas to capture the different technology specifics.
DMTF publishes the models as schemas. These are supplemented by specifications that define the infrastructure, interchange format, and compliance requirements. CIM is a UML-based [59] technology.
The initial attempts to derive the information models for the various SA Forum AIS services (and AMF in particular) from the CIM led to overly complex object hierarchies without providing an intuitive mapping onto SA Forum defined entities and relationships.
4.2.2 The SA Forum Needs
At the same time as the IETF and DMTF put efforts to define YANG and CIM respectively, the SA Forum has also been working on an appropriate representation of the management data of SA Forum compliant systems. The result falls somewhere between these two solutions. Let us examine why.
First of all there is a necessity of system configuration. For example, the availability management function needs to know all services it needs to maintain and all the resources it can use for this purpose. In a complex system—and SA Forum compliant systems are complex—this means a detailed representation showing each component with its services and state. While such a detailed representation is necessary for the availability management functions it is overwhelming for an administrator. Therefore there is a need for an organization that simplifies this view such as higher level aggregation and abstraction even when there is no physical manifestation of such compound entities in the system or if the entities are quite different from the function manager's perspective, but they are similar for the administrator.
High-availability systems are relatively autonomous in the sense that once they have been configured and deployed they operate 24/7 without continuous administrative control as the systems themselves implement mechanisms to cope with emergency situations within the defined limits. (We will see this in details in the discussion of the AMF [48] in Chapter 6.) This also means that these systems are able to handle many other workload related (e.g., increase of traffic) issues and changes dynamically.
In particular the SA Forum utility services allow the creation and deletion of their service entities dynamically through application programming interface (API) calls. The originator of these operations may or may not be part the system.
For example, new checkpoints may be created in response to increased traffic, increased number of open sessions toward the system or due to a new application that has been added to the system configuration. In either case the checkpoint service (CKPT) creates these checkpoints at runtime in response to the requests it receives from its user processes via the service API and not through configuration.
The information model needs to accommodate this feature. More specifically, the creation and deletion of these utility service resources at runtime via the service API is very similar to the creation and removal of configuration resources by an administrator from the perspective of handling; that is, the life-cycle of such an entity is controlled by the user and its representation should remain in the model until the API user requests the removal of the entity and therefore its representation. On the one hand, they have a similar ‘prescriptive power’ as the configuration has. On the other hand, they need to be distinguished from the configuration information as they are created by the service management functionality on behalf of the user and they should not be configured by the administrator.
Finally the information model also needs to be able to satisfy the needs of system monitoring and system discovery. System administrators need to be able to find out the system state, easily find their way around in the model and interpret the information even when they know very little about the functionality a particular application. In other words, in spite of the wide range of application functionality deployed on such systems and the variety of configurations, the model needs to express clearly the system's organization and state.
This requirement is related again to organizational aspects of the model, but also the differentiation of the information depending on its source.
There could be different solutions for these requirements depending on the preferences or the target behavior. The primary goal was to provide a management interface to external management systems to manage and configure a system based on the SA Forum specifications and a number of suitable open standard solutions could have been used. It was the need to provide runtime management access to the service implementations themselves that drove the decision to specify the interfaces to the UML model based on an adapted Lightweight Directory Access Protocol (LDAP) [60] model. However the administrative interface exposed by the resulting Information Model Management service (IMM) [38] is well adapted to be exploited by external management systems using agents based on the existing open management standards. We describe the SA Forum definition of the different object class categories catering to these two requirements further in this chapter.
Satisfying the above requirements were the primary drivers in the definition of the SA Forum information model while also drawing on the concepts and techniques and therefore aligning it with existing standards and developmental solutions such the MIB [52] and LDAP [60] from IETF, CIM [58] from DMTF and UML [59] from Object Management Group (OMG).
4.3 The SA Forum Information Model
4.3.1 Overview of the SA Forum Solution
4.3.1.1 The Managed Object Concept
The SA Forum system consists of many different resources—software and hardware alike [61] (Figure 4.1). These include the hardware nodes composing the system platform that run different operating system instances within or without virtual machines providing execution environments for different processes in the system. The processes may implement some SA Forum defined system functionality or some application functionality the availability or other aspects of which are still managed by the SA Forum services.
Figure 4.1 The SA Forum managed object concept. (Based on [61].)
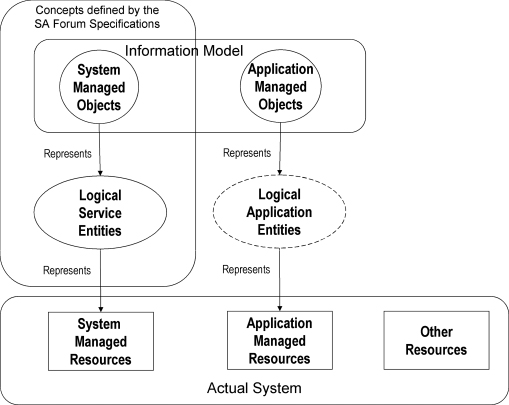
For the purpose of the management of these different resources an SA Forum service defines some logical concepts that abstract the aspect of the resources, which is managed by the given service. We refer to these logical concepts as SA Forum entities. The service semantics and functionality are defined for these logical entities. For example, the Platform Management service (PLM) abstracts most of the details of any hardware resource and represents all of them as hardware elements. Similarly, operating systems, virtual machines, and virtual machine monitors are all summarized as execution environments. Then the PLM specification describes the operation, the managed states, and other semantics of the PLM in terms of these two logical entities, that is, the hardware element and the execution environment.
In addition, a service may also define logical entities that cannot be mapped directly to any single resource present in the system, but which reflects some organizational aspect of those entities that do have a physical manifestation. Typical examples would be the AMF's service unit and service group concepts. An AMF component may manifest in the system as a process managed by AMF. The service unit, however, is only a grouping of such components and known only to AMF. If we look at the reasons why it was defined in AMF we see that one of the reasons behind the service unit is the fact that tightly collaborating components tend to fail together; it is the reflection of this coupling.
There was however a second reason behind the definition of the service unit. It simplifies the management view for administrators by adding a level of hierarchy and as a result the administrator does not need to deal with individual components, but can control them simultaneously as a service unit. Yet the option of observing each individual component still remains possible whenever it is needed.
This brings us to our subject, the SA Forum information model: these different logical entities defined in the different SA Forum services are presented to the system administration in the form of managed objects of the SA Forum information model (Figure 4.1). For each of the SA Forum services that exposes any of its logical entities to the system administration the classes of the managed objects are defined in the service specification using UML class diagrams. These diagrams define:
- the class name and category;
- the different attributes with their types, categories, multiplicities, and if applicable IMM [38] representation; and finally
- the administrative operations applicable to objects of the class.
Objects of these classes represent instances of the respective logical entities that expose the status of these logical entities in the system as appropriate and also allow the administrator to control these entities and through them the behavior of the represented logical entities and their physical resources as appropriate. Thus, the information model provides a management view of the SA Forum system.
The SA Forum IMM [38] was specified with the purpose of maintaining and managing the SA Forum information model. As part of this it provides the management interface to the SA Forum system as well as an interface for the services and applications that handle the logical (service) entities and the resources they represent. We will take a closer look at the details of IMM in Chapter 8.
4.3.1.2 Object and Object Attribute Categories
In Section 4.2.2 we pointed out that in an SA Forum system a service entity may manifest as a result of an administrator configuring it or a service user requesting the service through the API to create it.
Configuration Objects
The administrator may configure the service to instantiate the entity regardless of whether it has an actual physical manifestation or only the logical service entity exists defining some service aspects for the service implementation itself. In this case, the administrator configures the managed object in the information model via the management interface exposed by IMM. In turn IMM informs the service implementation responsible for the particular portion of the SA Forum information model so that it can deploy the configuration changes intended by the administrator. Because of this configuration aspect these objects and their classes belong to the configuration object class category.
Configuration objects are prescriptive in nature, that is, they express the intention of the system administration about the organization and the behavior of the system. The physical resources associated with such objects are controlled and manipulated by the service implementation to which the objects belong so that their status and behavior matches that of the intention of the administrator.
For example, the information model of the already mentioned AMF is primarily composed of configuration objects. Since AMF manages the life-cycle of the application components it controls, it requires first the configuration of the application: The components it is built from, their organization and the different policies applicable to them that guide among others the recoveries should an error occur. An AMF implementation cannot figure out all this information by itself; it cannot know the intention of the administrator.
Runtime Objects
Alternatively, service entities may be created by the SA Forum service itself as a result of user requests received via the service API. For example, the application configured for AMF may use checkpoints defined in the SA Forum CKPT to synchronize the execution state between the component actively providing a service and the one standing by to protect the service against any failure. In this case it is the application, the processes represented by the AMF components that instruct the CKPT to create, read, write, and remove the checkpoint as necessary. The CKPT handles in the system the physical representations, the replicas of such a checkpoint according to the requests received through its API. It also exposes the checkpoint and its status in the information model. Again the service functionality is defined in terms of logical service entities, which then can be implemented in different ways, for example, some database records, or files depending on the given service implementation.
The important part is that the user processes refer to the logical service entity (e.g., checkpoint) and the operations the service needs to perform to fulfill their needs via the API. The system administration is not involved, yet, these entities need to be present as long as the user process requires it. So they also have some prescriptive nature toward the service implementing them. Nevertheless from the perspective of the information flow its direction is opposite to that of the configuration objects. It is the service implementation which inserts the managed object into the information model in response to the API request creating the logical entity. The system administrator is primarily an observer of the life-cycle of these objects that as a result reflect the runtime status of the system and of the particular service implementing these objects. Accordingly these classes of objects are called runtime objects.
Object Life-Cycle
Considering the life-cycle of objects of these categories, configuration objects are created and deleted by an administrator. In case of runtime objects, they are created as a consequence of a service user request. Depending on the service their removal may be explicitly the result of an API request, but more often since they may be accessed by several service user processes simultaneously they are removed as the consequence of inactivity. The definition of inactivity varies from service to service, it may be declared after the expiration of some period without any process accessing the associated service entity; immediately after the last user process indicates that it stopped using the entity; or when such situations imply, for example, due to a process failure.
Since we are dealing with fault tolerant systems we need to consider different error situations: The service user process may fail, the service implementation process may fail and/or the IMM implementation process may fail.
The assumption is that if the service implementation process (including IMM) fails then there is a standby process, which will take over in providing the service, that is, the service as a whole does not fail. This means that even though a user session with the initial service process may terminate the entities created as a result of that session remain in the system and so do the runtime objects representing them.
If the user process fails then any session it has opened toward a given service is implicitly terminated. The SA Forum services should detect the termination of the application processes even if it was abrupt. The service entities created through this session, however, remain in the system as long as they are active; that is, there are still users that may access them or their timer has not expired.
Considering a checkpoint, it will remain in the system in all these cases and its representation will remain in the information model as well.
The story changes when we consider termination or restart operations.
For example, if the application is restarted whether the service entities created by the application and the runtime objects representing them remain in the system depends on different factors: If the restart is due to a failure the application components are terminated abruptly, so the same applies as in case of the process failure. If it is a graceful termination then depending on the service the application processes may clean up their logical entities, which results in the cleanup of the information model. For example, the application processes have the possibility to close the checkpoints they use and that means that all the associated resources will be freed by the CKPT. It will also remove the associated checkpoint objects from the information model.
If the IMM is terminated or restarted, it has no obligation to preserve and restore runtime objects in the information model. It is required, however, to persist and restore configuration objects. Once IMM becomes available again it is the responsibility of the various SA Forum services to restore their runtime objects in the information model. Picking up our example of the checkpoints, IMM will not restore the runtime objects representing the checkpoints in the information model, but the CKPT will keep and maintain the checkpoint replicas themselves regardless IMM. It will recreate the runtime objects in the model when the IMM becomes available again.
On the other hand, if the service implementation is terminated or restarted this implies that the operation also terminates all its logical service entities. That is, the checkpoint replicas go away together with the CKPT since it cannot maintain them any more. But the IMM—since it is up and running—continues to maintain all the runtime objects representing them (e.g., the checkpoint objects) unless they are explicitly removed by the quitting service implementation, which it may only do if it was terminated gracefully.
If the entire cluster is terminated or restarted all the logical service entities and their model representations are removed. But again the IMM is required to preserve and restore configuration objects. That is, all checkpoint replicas in the system and the objects representing them in the information model go away, but the objects representing the AMF components configured by the administrator will be kept by IMM and restored in the model as soon as IMM is running. Using this information AMF can start the appropriate application processes in the system, which in turn will need to open their checkpoints again triggering the recreation of the associated runtime objects.
In-between: Persistent Runtime Objects
This difference in the handling of runtime and configuration objects may not be appropriate in all the cases since as we pointed out runtime objects do have a prescriptive nature even if it is less emphasized than for configuration objects. To close the gap and also enable the preservation of runtime objects the category of persistent runtime objects was introduced in the SA Forum information model. That is, the IMM is required to persist and restore this object category in a similar manner to what it does for configuration objects even though they are runtime objects. From our discussion it also follows that for the service entities represented by this object category the service needs to define an API for explicit life-cycle handling. Note that none of the defined SA Forum services currently uses this object category, but it could be used by an application that wishes to extend the SA Forum information model with its own classes. We could assume an application, which enhances the Checkpoint by declaring its checkpoint object class as persistent runtime. In this case the objects representing the checkpoint will remain in the information model whether IMM or the entire cluster is restarted so that this application may use this information to restore the checkpoint replicas in the system accordingly.
One may ask the question why not just use configuration objects instead? This would require that the application process accesses the information model the same way management processes and the administration do, which may not be desirable. First of all it complicates the application process as now it needs to use an additional service and not a simple one for that matter: configuration changes are heavy operations because they may have wide impact; they also need to be validated at runtime as they may have been initiated by a human operator, who may not be aware of all the consequences.
The alternative of the service (e.g., CKPT) inserting the configuration object is not viable due to the information flow, as the same service initiating the change is the receiver of this model change which creates a potential deadlock.
Attribute Categories
Specific individual object attributes of a configuration object may in fact be assigned to the runtime category. This was done to avoid having to model a single logical entity with separate configuration and runtime classes. Accordingly IMM preserves the values of configuration and persistent runtime attributes, while it takes no such responsibility for runtime attributes.
Configuration objects may have attributes of any of these categories. In their case the runtime attributes may serve as a feedback mechanism through which the service or application implementing the logical and physical entity represented by the object can inform the administrator to what extent it was able to align the service entity with the requirements of the configuration attributes. That is, these runtime attributes reflect entity states.
Runtime object classes, on the other hand, may only have runtime attributes. If any of the runtime attributes is declared as persistent that makes the object class itself persistent as well. To be able to preserve the object with its persistent runtime attribute the name attribute of the object also needs to be declared persistent.
This leads us to the next topic we need to discuss about the SA Forum information model: its organization and naming conventions.
4.3.1.3 LDAP DNs and RDNs versus UML
The SA Forum adopted the basic naming conventions from the LDAP [60].
LDAP organizes the directory objects into a tree structure and the objects' name reflects this structure. Namely, an object which is the child of another object in the tree will have a name which distinguishes it from any other child object of this same parent object—it will have a Relative Distinguished Name or (RDN). Since this is true for the parent object and its ancestors as well, we can generate a unique name for any object within the tree just by concatenating the RDNs of the objects we need to go through to reach the root of the tree. Such a name is called the Distinguished Name, or the (DN) of the object.
The root of the tree has no name. The specificity of LDAP and therefore the SA Forum DNs is that the DN of a child object is constructed from the child object's RDN followed by the parent object's DN. So the RDN works exactly as the first name: it distinguishes the kids in the family indicated by the last name. Unfortunately people's full name is not generated through the ancestry any more, so it does not provide the uniqueness at this point in time; however, we are pretty sure the idea was the same—at least for a given locality. In comparison addresses still work in this manner in many countries, that is, the addressee's name is followed by the house number, then the street, the municipality and if applicable by the province or state, and finally the country. The same logic applies to the generation of the DN of an object in the LDAP tree: it leads from the object to the root in case of left-to-right reading. To find the object from the root, the DN needs to be read right-to-left. In this direction it can be interpreted as a containment hierarchy and this is often the implied interpretation used in the SA Forum model.
The SA Forum also adopted the method of typing of relative names, but it did so with a slight twist. LDAP defines an RDN as an attribute_type=value pair, where the attribute_type is a standard naming attribute and the value is the relative name of the part. SA Forum managed objects are named in a similar manner. The difference is that the naming attribute does not have a fixed naming type but the type can be determined by the object class. In this way structurally important attributes can be used as the link in the naming (containment) hierarchy without imposing a type on them.
The different SA Forum specifications when they define an object class the name of the first attribute of this class defines the attribute_type portion of the RDN for the objects of the class and it is identified as the RDN attribute. The value of this attribute for each given object will provide the value portion of the object's RDN.
For example, the AMF specification defines the configuration classes SaAmfApplication, SaAmfSG, and SaAmfSI to represent respectively applications, service groups, and service instances in the information model for which we only show the RDN attributes in Figure 4.2. They have their RDN attributes named respectively: safApp, safSg, and safSi. Note that these naming attributes all start with the ‘saf’ prefix as opposed to all other attributes of the SA Forum defined classes that start with ‘sa’.
Figure 4.2 Example of the RDN attribute definitions in AMF configuration object classes.
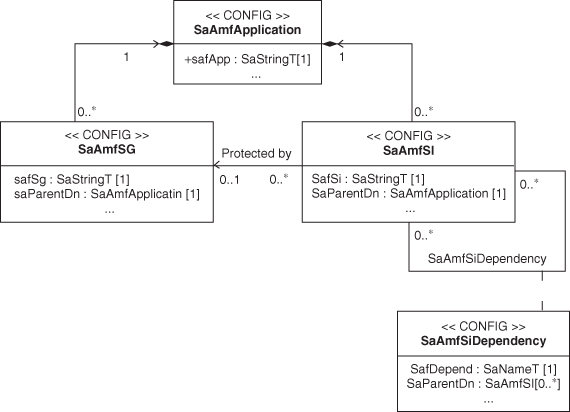
The <CONFIG> stereotype in the diagram is used to indicate that the object class belongs to the configuration object class category. Using these classes we can define an object model of an application myApp providing two service instances myService1 and myService2, each of which is protected by a respective service group which could also be named myService1 and myService2 even though they are also children of this same myApp application object as the actual providers of those service instance. The reason is visible from our Figure 4.3, which shows the RDN attribute with its value for each of these objects as well as in the saParentDn attribute the DN of the object which is the parent of the given object in the SA Forum information model.
Figure 4.3 Objects of some AMF configuration object classes with all their links.
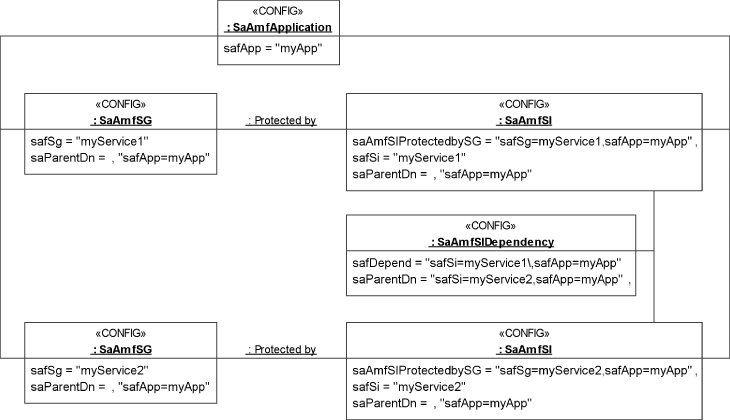
Accordingly the objects mentioned so far have the following DNs:
- ‘safApp=myApp’—the object representing the application;
- ‘safSi=myService1,safApp=myApp’—the object representing one of the service instances;
- ‘safSi=myService2,safApp=myApp’—the object representing the other service instance;
- ‘safSg=myService1,safApp=myApp’—the object representing the service group providing the first service instances;
- ‘safSg=myService2,safApp=myApp’—the object representing the service group providing the second service instances.
We can see that the RDN attribute name used as the RDN tag distinguishes the service groups from the service units and therefore make their DNs unique.
As we mentioned earlier the SA Forum specifications define the object classes using UML diagrams. The complete model is also published as an XMI file [62].
Both figures are UML diagrams: Figure 4.2 is a class diagram as it is used in some specifications, while Figure 4.3 is an object or instance diagram one would use to represent the information model instance describing the SA Forum system.
On these UML diagrams we also specify relations between classes and respectively their object instances such as the already mentioned parent child relation reflected by the DNs. In some cases the relationship between some object classes is expressed through a UML association class. This is the case for the SaAmfSIDependency class in Figure 4.2, which implies appropriate objects in the object diagram and also in the SA Forum information model. Unfortunately these relations do not readily convert into a tree organization required by the LDAP naming conventions presented so far. The solution used in the SA Forum specifications is the following:
One of the object classes in such an association is selected as the parent object class for the association class objects in the information tree. Since usually such associations have a direction it is the source object class, which is selected for the parent role. Among the two objects that participate in such a relationship the object of this class will provide the parent DN for the DN of the association class object. To link the association class object with the second, the target object of the association relation, the DN of this second object is used as RDN value of the association class object.
In our example of Figure 4.3, we may have a dependency between the two service instances indicating that the second service instance ‘safSi=myService2,safApp=myApp’ cannot be provided unless ‘safSi=myService1,safApp=myApp’ is provided. This we could show in UML as a simple directed association. However, since there could be a short period while ‘safSi=myService2,safApp=myApp’ can tolerate the outage of ‘safSi=myService1,safApp=myApp’ we need to define this period in an association class object of the SaAmfSIDependency object class of Figure 4.2. This object in Figure 4.3 will then have the DN: ‘safDepend=safSi=myService1,safApp=myApp,safSi=myService2,safApp=myApp’. Note that the ‘safSi=myService1,safApp=myApp’ is an RDN value and in this situation we need to use an escape character (‘’) so that the following comma is not processed as an RDN delimiter. As this DN implies and the saParentDn attribute shows in the SA Forum information model, this association class object is the child of the ‘safSi=myService2,safApp=myApp’ object representing the second, the dependent service instance, which references through the RDN attribute value the first service instance on which it depends and which is represented by the object ‘safSi=myService1,safApp=myApp’.
Figure 4.4 shows again the same AMF objects organized based on their DNs into a tree as it is used in the SA Forum information model. Note that the saParentDn attribute in the UML model is private and not shown in the UML classes of the specifications as it reflects exactly the same information that the object DN implies. In the UML classes, however, the DN of the objects are not represented. They can be constructed from the RDN attributes and this private attribute (which in UML terms is the association end of the association representing the parent–child relation).
Figure 4.4 The tree organization of the sample AMF information model objects.
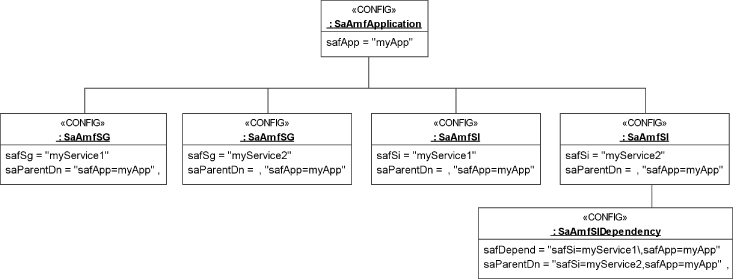
Other relations are expressed explicitly through attributes (or association ends in UML terms). For example, the saAmfSIProtectedbySG attribute, which indicates the name of the service group protecting the service instance.
But—and there is a big but here—the early versions of the model would choose a descriptive name for these attributes and reference simply the SaNameT as the type of the attribute. This approach did not reflect the class at the other end of this association. Essentially the SaNameT type works like a generic pointer that can point to any class it can hold, the DN of any object. Since it is important to see what classes are associated through which relation therefore the newer model will indicate the class of the object at the other end for these associations whenever it is known. The SaNameT type is used when the class is not known and the associated object may not even be present in the information model.
One of the consequences of this change is that now the saParentDn attribute (by having the appropriate object class as the attribute type) also reflects the way the information model tree can be built, which was only implied before. Previously the DN formats guiding these relations were only defined in the specification as a table.
The DN of an object cannot be changed without destroying the object. In other words both the RDN and the saParentDn attributes are read only.
4.3.1.4 Consideration for Designing an Information Model
Now that we understood the tree structure of the information model, we may want to define information models for our applications. As mentioned earlier the different services define the object classes they use for their portion of the information model. In addition to the classes the specifications also define the DN format. For some classes this definition is very restrictive, for others it allows for different organizations.
For the AMF classes we used in our example the specification defines that objects representing applications should be at the root of the SA Forum information model, that is, their DN has the format of ‘safApp=...’. Service groups have the definition of ‘safSg=...,safApp=...’ and service instances the ‘safSi=...,safApp=...’ indicating that they need to be children of an application object, and so on. In these cases the information model also has the appropriate class indication for saParentDN attribute.
As opposed to this the CKPT [42] allows the placement of a checkpoint object anywhere in the SA Forum information model based on the DN format: ‘safCkpt=...,*’. It is also a runtime object class, which means that it is created by the CKPT upon the request of a user. In fact the user provides the DN of the checkpoint object when it creates the checkpoint and the CKPT uses this information to fit the object into the model. This assumes that the software developer has a very good idea of the organization of the related portion of the information model at the development time.
To this end, it is important to consider the object's and its ancestors' life-cycle and their category. According to the specification defining the C programming model [63] and the IMM specification [38] no object should parent an object of stronger persistency. However the precedence of object categories with respect to persistency is not defined nor is it completely relevant to the life-cycle of the objects.
The idea is that objects should not be removed from the information model while they still have children. If only configuration objects are involved, this becomes only a matter of ordering as one can remove the object starting from the leaf-objects proceeding toward the root.
The story is different with runtime objects as they are ideally controlled only by the service or application that created them. For successful creation of such an object it is necessary that all its expected ancestry already exists: There is a path in the information model matching the object's DN given by the service user.
Appending an object to an existing tree, however, locks in that branch of the tree, as in this case it is not allowed to delete an ancestor before all its children have been deleted. These two aspects imply an ordering at the creation as well as at the deletion of these objects. This ordering is implied by the information model, its organization and not by the services owning the relevant portions of the information model. As we have mentioned the service entities may explicitly be deleted by an API user or cease to exist due to inactivity making the control of this ordering at the time of deletion virtually impossible in many cases.
The restart of IMM or the cluster—which are both extremely drastic measures in this context—will purge all the ‘simple’ runtime objects from the information model, but preserve the persistent runtime objects.
Considering persistent runtime objects the IMM is obliged to maintain them even across cluster restarts. One cannot expect IMM to figure out when such objects become obsolete in the information model. They can only be removed by the service user explicitly. We emphasize this as none of the SA Forum services defines persistent runtime objects and this category is expected to be used by applications mainly.
After restart IMM may restore an object only if all ancestor objects are also persistent (belong to a persistent runtime or a configuration object class). That is, if a class is runtime class at least its RDN attribute needs to be defined as persistent.
For all the classes in the ancestry of a persistent runtime object, the user also needs to be able to indicate the removal of the entities these object classes represent, at which time the application needs to remove the object.
This also means that, since there is no other way to remove these objects but wait for their owner to do so, an IMM implementation needs to be able to resolve the case if the owner application of such a preserved persistent runtime object never comes back after it crashed for example. There is a need for some type of garbage collection.
We assume that if the application is removed from the system it cleans up its part of the information model, but the more open the system for third party applications the less assumptions one may make. Or, conversely, the system needs to protect itself from faulty implementations, which may behave in an unexpected way and the integrity of the information model is essential in this respect.
In any case, we see that the organization of the information model requires careful consideration in cases where the specification provides different levels of freedom.
4.3.1.5 More Conventions
In this section we go into further details on how to read the information model to provide some clarification on the specifications. These details are not necessary for the general understanding of the information model and may be overwhelming so if that is the case we suggest to skip to Section 4.3.2 and return to this section later as it may become necessary.
Issues with Inheritance
Probably the biggest surprise to a seasoned UML user when looking at the SA Forum information model specification is still the fact that it barely uses inheritance and when it does so it may be the reflection of the semantics rather than the class inheritance of object-oriented technology.
Nevertheless classic object-oriented inheritance is used in the definitions of relations. For example, in the PLM the abstract class PLM entity is defined which is specialized in two concrete classes for hardware elements and execution environments. The reason for the abstract class is the dependency relationship that can be defined within and among the two concrete classes. In all these cases the parent class is an abstract class and therefore the system information model will never include an object of this class.
Inheritance is indicated in other cases too, but they do not act in the classic way as in case of PLM. To clarify this statement let us consider the class defining the component base type of the AMF, which is specialized as component type class. The only attribute defined in the component base type is the name, that is, the RDN attribute. However the component type class has its own RDN attribute as required by the LDAP roots of the model. So in the way the object-oriented technology uses inheritance there is no inheritance here. On the other hand, the semantics of the component base type is that it collects the component types that have common features that are different versions of the same application software, for example. So semantically the component base type is the generalization of the component type. The relation between these classes does represent inheritance at this different angle of abstraction.
There was another relation where inheritance could be considered, and that was the relation between entities and their types, for example, the components of this component type is question.
The role of the component type is to provide the default values for the attributes of its components. It can do so because the type object semantically represents an implementation, the software; while the entity object represents an instantiation of this implementation such as a process running the software.
In the information model there will be at least two objects present: one for the type and one for the entity of the type, which will reference the type object. In these relations there is always only one type object, which provides a single point of control of the configuration for the one or more entities represented by the objects referencing this type object. That is, in this relation the type locks in not only the set of attributes, but also the values for the objects of the entity class.
Instead of inheritance the relation was defined as a realization reflecting that the type object provides the specification, the blueprint for the entity objects. We will look further in section ‘Multiplicities and Defaults’ at the use of this relation as single point of control. Before doing so we need to explain first the naming conventions.
With respect to inheritance the conclusion is that the SA Forum information model does not use inheritance for other than documentation purposes, therefore IMM does not need to deal with inheritance per se.
Naming Conventions
We have mentioned that the RDN attributes defined by the SA Forum all start with the ‘saf’ prefix. This is the only attribute in an object class that has such a prefix. All other attributes have the ‘sa’ prefix followed by an <area> tag that identifies the service specification to which the attribute belongs. If the service defines more than one class then typically the next tag identifies the service entity that the object class represents. For example, in the ‘saAmfSIProtectedbySG’ attribute seen in Figure 4.3 ‘sa’ indicates that this is an attribute defined by the SA Forum. ‘Amf’ indicates the AMF specification as the area and ‘SI’ indicates that the service entity, an aspect of which is characterized by the attribute, is the service instance. The rest of the name describes this aspect, that is, in this particular case this attribute links together the service instance (SI) with the service group (SG) that protects it.
The same approach is used in naming the object classes, except that they use the ‘Sa’ prefix. Accordingly the class defined for AMF service instances is named ‘SaAmfSI’.
Well-Known Names
In addition to these naming conventions of the classes and their attributes the programming model specification [63] also defines some well-known names for objects representing the different SA Forum services. Each SA Forum service is represented in the SA Forum information model by an AMF application object with a standard name. This facilitates the exposure of the status and the administrative control of the middleware services in a similar way as it is done for the applications running in the cluster. A middleware implementation may follow through completely this alignment or remain at the level described here. That is, it may only provide the application level well-known objects so that users can identify from the information model the middleware services deployed in the platform and their versions.
These names follow the format ‘safApp=saf<area>Service’, where the <area> is the standard three or four letter abbreviation of the particular SA Forum service, for example, the object representing the AMF implementation in the system has the DN ‘safApp=safAmfService’. Through the use of a colon symbol the DN may include the particular implementation name, that is, ‘safApp=safAmfService:OpenSAF’ for the implementation of the OpenSAF Foundation [64].
Since one may also be interested in finding out the version of the specification, the implementation is compliant to as well as the implementation version itself. For this the already mentioned type concept is used. That is, the specification [63] also defines the application base type and the application version type objects that the above mentioned application object should reference. The application base type has the same RDN value as the application object, but with a different RDN tag ‘safAppType=saf<Area>Service[:<vendImplRef>]’. The application type object indicates the specification release and optionally the implementation version. ‘safVersion=<specRel>[:<vendVersion>]’.
Accordingly the object representing the mentioned OpenSAF implementation may reference in its type attribute an application type object with the DN of ‘safVersion=B.04.01:4.0,safAppType=safAmfService:OpenSAF’. In particular the version B.04.01 indicates the specification release which defines the classes used in the information model in order to allow management applications correctly handle the content of the information model. No lower level granularity (e.g., class level) of versioning is available in the information model.
Multiplicities and Defaults
Another notoriously questioned issue is the multiplicity used in the specifications. To understand the problem we need to discuss a little bit of the background.
As discussed, one of the goals of the information model is to provide a management interface, for example, for human operators. To simplify the information model the specifications define single classes for entities that may exist in the system in a number of varieties. These classes represent the basic concepts of these logical entities important for an administrator rather than all the sophistication required for the management functionality implementing them. For example, the basic concept of the mentioned AMF service group is the protection of service instances and this is what is important for an operator at a high abstraction level he or she deals with; and who may not know about all the application details regarding different redundancy models and their implied attributes. (Just like we are ignorant at this point of all those details—we will get into them soon enough.) This allows for this higher level system view and an application (functionality) independent navigation within the information model.
This intention is opposed by the original purpose of the information model to provide the configuration information for the AMF, which does require all the low level details of the configuration as well, such as the redundancy model of the service group and all the appropriate attributes. The problem in this case is that each redundancy model has its own set of configuration attributes. This nonapplicability cannot be reflected in a single UML class, while specialization (e.g., defining different classes for each redundancy model) would have complicated the administrative view which was a definite no-no in this context.
The resolution—the trade-off—between these opposing tendencies was made by creating the object class attributes for representing the service groups as the union of those different sets of attributes required by the different redundancy models. The result is shown in Figure 4.5. In the UML object class the attributes that may be absent for some redundancy models are defined as optional attributes having the multiplicity [0..1], while those that are required for all service group objects were defined as mandatory with multiplicity [1].
Figure 4.5 The service group and the service group type configuration object classes.

The twist is that the specification defines default values for most of the attributes regardless whether they are mandatory or optional and these default values and their applicability may depend on the actual redundancy model. For example the saAmfSGNumPrefStandbySUs attribute is only needed for the N+M redundancy model while it is applicable to the 2N as well. It is not applicable for the other redundancy models even though it has a default value. This default is defined so it satisfies the redundancy models the attribute is applicable.
Unfortunately this may create some confusion as optional attributes are also used with defaults (e.g., saAmfSgtDefAutoRepair with the default SA_TRUE) to indicate that the value does not need to be provided at the creation of an object of the class as in case of absence it will take the default value.
The possibility of not providing some values was perceived as simplification of the configuration process and therefore embraced.
The approach presented so far was applied in general at the definition of all object classes of the information model. That is, only one object class was defined for each service entity category. If service entities of a given category needed differently sets of attributes depending on their subcategories, then rather than defining different object classes the union of the attributes of the different the subcategories was used to form the object class that captures all the possibilities. In this class if needed additional attributes were added to reflect the subcategories.
The attributes required only in some subcategories were defined optional while those required in all subcategories were defined as mandatory.
To reduce the configuration information whenever it was possible default values were defined for configuration attributes and the attributes themselves were made optional. So whether a configuration attribute is optional or not reflects whether the attribute value needs to be provided at object creation and not its applicability. If it is not provided then the defined default may be used, but it is up to the service or application using the configuration information to decide whether this default value needs to be used.
Attributes may have also multiple values. These are typically attributes that are optional in its true meaning and therefore have no defaults.
There are different ways to define the default value of an attribute:
- as a literal (e.g., saAmfSgtDefAutoRepair the default value is SA_TRUE);
- as a variable depending on some feature of the model (e.g., saAmfSGNumPrefInserviceSUs has a default of the number of service units in the service group);
- as a variable based on another attribute in the same object (e.g., the default for the saAmfSGNumPrefAssignedSUs attribute is the value of the saAmfSGNumPrefInserviceSUs attribute of the same object);
- as a variable based on another attribute in a different object of the model (e.g., the default of the saAmfSGAutoRepair in the service group object is defined based on the saAmfSgtDefAutoRepair attribute of the related service group type object).
In cases when the default value is defined based on another attribute's value that attribute's name is given for the default value.
Whenever this referenced attribute is in another object class if it is possible the path to the attribute is given (e.g., saAmfSGType.saAmfSgtDefAutoRepair). This is usually formed as two attribute names: the first one is attribute name in the referencing object class that holds the reference to the object of the object class (e.g., saAmfSGType the attribute which is the association end that points to the service group type class); the second name is the name of the attribute in the referenced class which provides the default value (e.g., saAmfSgtDefAutoRepair).
The first attribute name can be omitted if the referenced object class is singleton as long as the attribute name is distinguishable from all the attributes in the referencing class.
The UML model indicates these referenced defaults to document where the applicable default values originate from. However, in the information model instance the default values are not set. They are fetched as needed by whoever needs it from the referenced attributes.
This is the mechanism through which an object class representing a type can be used as a single point of control for the configuration of all its entities that we mentioned in section ‘Issues with Inheritance.’
As long as the linked attribute does not have a value in the referencing object, the applicable value is fetched from the referenced attribute whenever it is needed. When such an attribute is set to a given value, for example in an object representing an entity of a given type, this value overrides the value provided by the attribute of the referenced object representing the entity's type. It is used as set without looking into the referenced attribute.
For example, as long as the saAmfSGAutoRepair attribute in the service group object is not set AMF will check the value in the saAmfSgtDefAutoRepair attribute in the service group type reference by the saAmfSGType of the service group object. If there are 100 service group objects in the model all referencing this same service group type then for all of them the service group type object will determine the applicable value and this will change as this attribute is changed in the service group type object. If in any of this 100 service group objects we set the value to directly in the saAmfSGAutoRepair attribute to SA_TRUE, this attribute of the service group object becomes decoupled from the saAmfSGType.saAmfSgtDefAutoRepair attribute and will only change if it is modified directly.
As we mentioned the expectation is that it is the service or application using the attribute that interprets this link.
Attribute Types and Constraints
The C programming model specification defines a set of types that are used by the different SA Forum specifications. These types are also defined for the SA Forum information model.
However the service specifications or applications may extend this common set of types in different ways, some of which may show up in the information model of the particular service or application. The most common cases are:
- The runtime attribute representing a state of the service entity for which the values are defined by the related service specification as an enumeration.
- Attributes reflecting associations between classes of a service or an application as these classes are defined by the given services or applications and they are not known in advance.
Of course the IMM managing the information model cannot be prepared for all these different extensions in advance, so instead in the class definitions such an attribute indicates two types:
- As the attribute type it indicates the type defined in the owner service specification or application (e.g., SaAmfSGType for the saAmfSGType attribute of the service group class shown in Figure 4.5).
- As the IMM representation type given as a constraint of the attribute it indicates the IMM type to which the attribute type is mapped to represent the attribute value in IMM (e.g., SA_IMM_ATTR_SANAMET which indicates the SaNameT C type). The definition of the mapping between these types is the responsibility of the service specification or the application.
It is important to note that when an attribute's type is a class, it is always interpreted as a reference to an object of this class, which has a proper DN. This DN is used as the reference to the object. This implies that the class of the referenced object includes an RDN attribute and there is at least an implied DN format indicating the positioning of these objects in the tree of the information model. In addition the saParentDn attribute may also reflect this information in the class definition.
Besides the IMM representation type, the attribute categories discussed in Section 4.3.1.2 and other features are also defined as constraints. We already mentioned the configuration, runtime, and the persistency categories and RDN role of an attribute, all of which are indicated as constraints.
In addition for configuration attributes the writability, for runtime attributes the caching are given as constraints.
Class Operations
Since the information model is concerned of the management view, the only operations defined in the UML object classes are the administrative operations applicable to the objects of the given class.
4.3.2 Administrative and Management Aspects
As we have noted the SA Forum Information Model is managed by the IMM, which exposes it to administrators and object manager (OM) applications through a ‘northbound’ API referred to as the IMM Object Manager or OM-API. In turn IMM delivers the administrative operations and changes applied to the information model to the AIS services owning (or responsible for) the objects being manipulated to carry out the changes in the system and return any result, which then returned to the initiator again using the OM-API. The IMM and the use of its APIs are covered in details in Section 8.4.
However, IMM provides only a general framework for managing the information model. The actual management objects, their meaning and the applicable operations are defined by the different AIS services and we present them as we go through each discussing their information model and how they map into the different service entities the services manipulate.
4.3.3 Application Information Models
Applications may also have their own information model and they may want to expose it to the system administration. It makes sense, and it is actually desirable for the system administration that the applications expose their model in the same way as the middleware, the SA Forum system, does.
As we have hinted already in our discussion (Figure 4.1), the SA Forum information model is extensible for applications as long as they follow the concepts and principles of the system model. In particular, the model needs to be organized into a tree and use the LDAP naming schema.
The object classes representing the application entities can be added to the SA Forum model using the IMM. The application implementation is expected to be the owner (or implementer) of these object classes. The classes may be of any of the categories defined for the services. This means that this owner application should not create or delete the objects or manipulate the configuration attributes of the configuration object classes. On the other hand it is responsible for maintaining the runtime attributes and objects of the runtime object classes.
Note that certain aspects of the SA Forum information model are not mapped into its representation maintained by the IMM. These include the different associations, the administrative operations, and the referenced default values.
4.3.4 Open Issues and Recommendations
The core portion of the SA Forum information model is the information model of the AMF, the concepts of which were extended to the other SA Forum services as well as to applications designed for SA Forum compliant systems. This increasing scope also reflects the state of maturity of the model. It has been used mostly for AMF and the SA Forum services, while for applications the use is just starting as the first mature implementation (i.e., OpenSAF [64]) of the SA Forum AIS is taking off.
When looking at the open issues we need to distinguish the issues related to the information model itself and those related to the IMM maintaining the representation of the information model within an SA Forum middleware implementation. Here we will focus only on the issues of the information model itself.
Probably the biggest issue with the information model is that even though it uses UML it does not follow completely the UML concepts. It combines UML with different more traditional solutions which occasionally result in cumbersome solutions. We have seen this in the discussions of the LDAP naming which reflects a tree structure that does not fit easily the UML association class concept used in the model simultaneously.
UML was initially used mostly for documentation purposes. As a result, it was not so much the UML semantics as the semantics of the domain and targeted use that were the guiding principles. On the one hand this may put off people with UML expertise. On the other hand the same feature may be embraced by people who use the model in day-to-day system management and who are less comfortable with the abstractions of UML. For example, configuration management does not require the use of inheritance and in the information model in many cases it is not used in an object-oriented (i.e., UML) way.
The SA Forum model is designed to be as simple as possible, so when in a class definition another class is given as an attribute type it is always interpreted as a reference to another object. In other words, the information model does not support complex types as attributes which is also an issue that some may question.
Nevertheless at this stage these issues are not open for discussion. The SA Forum made its choices and defined the information model accordingly.
The two biggest issues that still not settled are:
- the rules ensuring model consistency; and
- the IMM representation of the information model.
With respect to model consistency the issue which is not completely resolved is the ordering of the creation and the deletion operations of different objects in the model. The only defined requirement in the specifications (noted in both [38] and [63]) is that objects of weaker persistency cannot parent objects of stronger persistency. Accordingly a runtime object may not be the parent of a configuration or a persistent runtime object.
This expectation was defined from the perspective of failures and restarts of the IMM and the entire cluster due to the fact that IMM cannot restore a persistent object if its ancestor is a runtime object, which is flushed at such an event. But in a system designed to run continuously these events are rare and the information model content is preserved for a long time even in the case of runtime objects. So the question is raised: how to combine the objects' life cycle with their category as well as semantics?
For example, the configuration objects of an application that require regular reconfiguration may have a shorter life-cycle than some runtime objects representing the platform itself.
A related issue is the power of the system administrator with respect to runtime objects. The SA Forum services have been defined with the idea in mind that objects should not and cannot be removed from the information model while they still have children. This expectation opposes the tendency that an administrator should be able to perform configuration changes any time and therefore should be able to remove configuration objects even if they still parent other potentially runtime objects.
While for configuration objects the removal of the parent can be viewed as equivalent to the removal of all its children starting from the leaves, the operation becomes questionable if any of the child objects is a runtime object, which should only be removed by the owner service as appropriate for service users. One may argue that application processes may crash and considering the life-cycle of runtime objects—particularly persistent ones—they may pollute the information model by locking in potentially even a configuration object. So there is a need to get rid of such runtime objects. On the other hand experience shows that most outages are caused by operator errors and the information model is the main user interface of an SA Forum compliant system.
The specifications give few guidelines regarding the proper design of the information model tree. At the same time, as we have seen, this knowledge may be needed in some form at application development time as API calls are expected to provide the DN of the service entities they access. This may create the tendency of inserting objects at or close to the root of the information model as it is the safest place not to disturb and not to be disturbed by other operations. This flattens the model and provides little help to administrators in navigation.
The opposing tendency is driven by the containment relation, which maps well into the tree structure and usually also implies life-cycle dependency among represented service entities. We will see this in the case of the AMF information model.
The second major issue, which has no resolution, is related to IMM representation of the information model. As noted, some features of the information model defined in its UML representation are not mapped into IMM features defined as up to date. Some of these may therefore limit the extensibility of the information model for applications. The features of the model not reflected in the IMM representation include the administrative operations, some associations between object classes, and attribute relations. The main limitation they impose is that they need to be known by all parties using the model, that is, the application owning the given portion of the information model as well as the system administration and any management applications manipulating the model. The IMM cannot assist in discovering these features.
4.4 Conclusion
In this chapter we presented an overall view and the main concepts of the SA Forum information model. We will explore its different portions further as we introduce the SA Forum services, defining their own parts of the information model, all of which follow the concepts presented in this chapter.
The purpose of the information model is to provide an interface between the system management and the middleware through which the administrator can monitor the system status and configure it as required. Accordingly the model needs to suit both parties – the needs of system management as well as the configuration needs of the middleware. The third party typically not considered from this perspective is the applications running in the system which may act in a similar manner as administrators with respect to the services they use, that is, they may set up a particular environment for themselves, which is essentially a configuration that needs to be preserved in similar ways as the administrator provided configuration is preserved. Yet this environment setting needs to be distinguished from the administrator's realm as it is the application that maintains it and controls its life-cycle. One consequence is that there is no need for additional consistency checks and a lightweight API satisfies all the access needs.
We have introduced the concept of the physical resource, service entities, and managed objects as they reflect the different layers of abstractions and different perspectives. The services manipulate the physical resources, which are abstracted into logical service entities that provide the basis for the service definitions themselves. Service entities are mapped into management objects of the information model to expose these concepts toward the system management. These management objects provide the window into the service operation through which service behavior can be observed – and manipulated, if desired. Applications may extend the information model for their own needs following these principles.
To match the needs of configuration and observation the objects and their attributes are classified into two main categories: configuration and runtime.
Configuration objects and attributes are used to prescribe the expected behavior of the services and the system as a whole, while runtime objects and attributes are the reflections of the actual behavior, the status of the represented system resources.
To allow for the application side environment setup, the notion of persistent runtime objects and attributes has been introduced, which is a distinguishing feature of the SA Forum information model. It reflects the autonomy of such systems that they are able to run continuously without the need for administrative interventions, even in the presence of certain failures.
In this chapter we have presented the conventions defined for the SA Forum information model with respect to its organization, the naming of its objects as well as their classes and class attributes. We described the perspective from which multiplicities and defaults have been defined in the information model which helps their correct use, whether it is about interpreting the model defined for the SA Forum services or extending it for applications. This extensibility allows for similar management of the system as its applications, which facilitates the creation of a unified system view that should ease the task of system management.
The SA Forum information model is based on UML even though it does not adopt all its conventions and also incorporates other technologies. Nevertheless this definition is ‘formal enough’ for tools to be built to further aid, validate and automate system management functions.