
In this chapter, we continue our exploration in the world of simulation. Different from the previous Monte Carlo simulation where the scenario is purely static, which means there is no dynamics in the simulation, we are going to study dynamics of a system.
The Markov chain, specifically the discrete-time Markov chain, is named after Russian mathematician Andrey Andreyevich Markov. He is a pioneer in the study of stochastic processes and the first to introduce the concept of Markov chains.
Let’s introduce the Markov chain with a simple example of weather forecasting.
Weather Forecasting
Suppose we have a weather forecasting system that predicts the weather in the next hour. The weather can only take three possibilities: sunny, cloudy, or rainy. Here, we call these possibilities the states. We won’t predict the weather continuously but rather forecast the weather in the next hour. This makes our system discrete.
The continuous-time Markov chain is beyond the scope of this book. It requires more rigorous analysis. However, the fundamental ideas of the discrete-time Markov chain remain unchanged.
Weather transition probabilities
Sunny | Cloudy | Rainy | |
|---|---|---|---|
Sunny (next hour) |
|
|
|
Cloudy (next hour) |
|
|
|
Rainy (next hour) |
|
|
|
The way to interpret the table is to read it column-wise. For example, if the current weather is sunny, then the probability of the next hour’s weather being cloudy is ![]() . This is indicated by the second row in the first column (besides the row name column).
. This is indicated by the second row in the first column (besides the row name column).
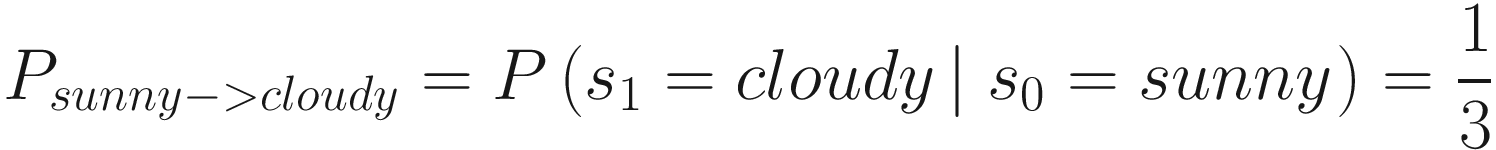
We used the notation of conditional probability in the expression P(s1 = cloudy| s0 = sunny) . It simply means that given the weather at the previous hour is sunny, which is a condition, the probability of the weather at the next hour being cloudy is ![]() .
.

An illustration of the weather forecast. 3 boxes form the vertices of a triangle labeled cloudy at the top, sunny on the left base, and rainy on the right base. Curved 180 degrees arrow on each box measures top, 1 over 3; left, 1 over 2; and right, 1 over 6. The boxes are. The boxes are connected by double headed arrows labeled with data.
A graph representing the weather forecast based upon transition probability
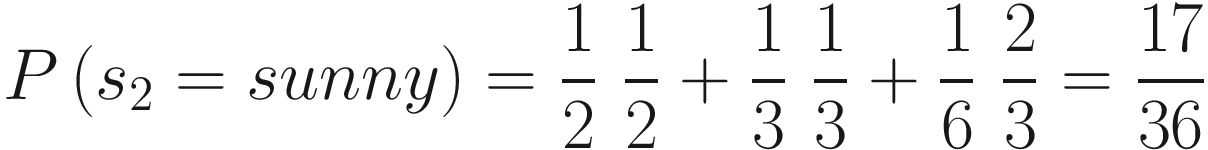
It is still possible to continue the calculation manually, but we would like to leave the labor to computers.
- 1.
The first one is called the Markovian or memoryless property. It means that the system will only remember the immediate past state but not further. For example, the weather forecast system will only remember and use the current weather to forecast the next hour’s weather but not previous hours’ weathers.
- 2.
The second one should be treated as a simplification, which can be removed if you want to match real-world scenarios. It is that our Markov transition probabilities are fixed regardless of the time index i. In real life, as seasons change, our transition probabilities should change.
In the nested for loop, we implemented the logic that one state can be achieved through multiple paths. For example, the weather after 3 hours can be essentially achieved through 33 = 27 different paths.

A line graph illustrates the weather state probabilities. Values ae estimated. Sunny, (0, 1.0), (1, 0.5), (10, 0.5). Cloudy, (0, 0.0), (1, 0.35), (10, 0.3). Rainy, (0, 0.0), (1, 0.18), (2, 0.24), (10, 0.24).
Weather state probabilities for ten iterations, starting with sunny weather

A line graph illustrates the weather state probabilities. Values are estimated. Rainy, (0, 1.0), (1, 0.18), (3, 0.25), (10, 0.25). Sunny, (0, 0.0), (1, 0.68), (2, 0.5), (10, 0.5). Cloudy, (0, 0.0), (2, 0.3), (10, 0.3)
Weather state probabilities for ten iterations, starting with rainy weather
Indeed, it looks like not only we reach a stable distribution, the distribution is also independent of our initial weather.
Eigenstates of Markov Chains
Is there anything special about the stable probability distribution ![$$ overrightarrow{x}approx left[0.486,0.297,0.216
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484281857/9781484281857__9781484281857__files__images__518439_1_En_2_Chapter__518439_1_En_2_Chapter_TeX_IEq14.png) ? It turns out that it is an eigenvector of the transition matrix with an eigenvalue of 1. In other words, it represents the eigenstate of the Markov chain. One can actually decompose any square matrix to find out its eigenvalues and eigenvectors. You can use numpy.linalg.eig(tm)[0] to obtain the eigenvalues of the matrix tm and use numpy.linalg.eig(tm)[1] to obtain the corresponding eigenvectors.
? It turns out that it is an eigenvector of the transition matrix with an eigenvalue of 1. In other words, it represents the eigenstate of the Markov chain. One can actually decompose any square matrix to find out its eigenvalues and eigenvectors. You can use numpy.linalg.eig(tm)[0] to obtain the eigenvalues of the matrix tm and use numpy.linalg.eig(tm)[1] to obtain the corresponding eigenvectors.
Note that eigenstate has a special meaning in quantum mechanics. Here, I just borrow the word as it makes sense in this context. It also has other names like stationary distribution, equilibrium distribution, limit distribution, etc.
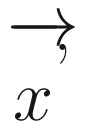 and
and 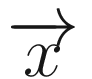 to denote the new (next hour) and old (current hour) states, respectively. The transition matrix is denoted by T:
to denote the new (next hour) and old (current hour) states, respectively. The transition matrix is denoted by T:
Note that the calculation ignores some negligible precision-caused numerical errors.

As you can see, no matter our initial state s0 is, as long as the elements sum up to 1, the output, sn is the eigenstate. This is a remarkable fact.

Exercise
- 1.
Find out the eigenstates of the transition matrix with a slower convergence rate.
- 2.
All of our previous simulation is based on analytical probability calculation. Can you do a simulation that just picks a random weather and evolves it according to the transition probabilities? Let’s say you do it for 10,000 steps, which is roughly 400 days, and count how many of these 10,000 data points are sunny, cloudy, and rainy. What’s your expectation? Does your discovery agree with your expectation?
Markov Chain Applications
In this section, let’s look at two interesting applications of the Markov chain. First, let’s look at how the Markov chain can be used to answer a nontrivial probability question. Then, we will use the Markov chain as a generative model to generate some natural languages.
A Random Walk That Has an End

An illustration of fruits inside a tube. Eight boxes are connected by double-headed arrows. The boxes are labeled from left to right as follows. Banana, 1, 2, tortoise, 4, 5, 6, apple.
A graph that represents the states the tortoise can be in
The question is, what are the probabilities that the tortoise eventually reaches the banana and apple?
- 1.
Given enough time, intuitively the tortoise will reach one of the fruits. Our tube is just 7 inches long, and the tortoise just keeps moving.
- 2.
The tortoise should have a higher, probably not much, probability of reaching the banana than the apple. The setting is not symmetric.

A line graph illustrates the probabilities of reaching bananas and apples. Values are estimated. Bananas, (0, 1.0), (0, 0.45), (900, 0.6), (10000, 0.6). Apples, (0, 0.0), (0, 0.68), (900, 0.4), (10000, 04). The horizontal axis is labeled number of runs.
Probabilities that the tortoise reaches bananas or apples for 10,000 runs
It does agree with our intuition that the tortoise is slightly more likely to reach the banana. If you check the end of the bananas/(bananas+apples) array, you will find that the probability of reaching the banana is about 0.575.

A bar graph illustrates the number of steps before the tortoise stops moving. The trend of the graph is a decreasing pattern. The first bar is the tallest reaching a height of 1750 on the vertical axis followed by a bar of the height of approximately 1000. The bars appear to be in descending order of height.
Number of steps before the tortoise stops moving

A matrix of probabilities. Values are arranged in 8 columns and 8 rows enclosed within brackets. The digit 0 occupies maximum positions except for the following. Row 1: column 1, 1; The positions of 1 over 2 are as follows. Column 2, rows 1 and 3. Column 3, rows 2 and 4. Columns 4, rows 3 and 5. Columns 5, rows 4 and 6. Columns 6, rows 5 and 7.
This Markov chain is different from the weather one mainly because it has two so-called absorbing states. The absorbing states are the left and right ends of the tube. Once the tortoise reaches one of the ends, it stops moving. The first and the last element in the transition matrix diagonal are 1 which indicate the absorbing states.

A matrix of probabilities. Values are arranged in 8 columns and 8 rows enclosed within brackets. The positions of values are as follows. Row 1: 1.00, 0.86, 0.71, 0.57, 0.43, 0.28, 0.14, and 0.00. Row 8: 0.00, 0.14, 0.28, 0.43, 0.57, 0.71, 0.86, 1.00. Rows 2 to 7 contain 0.00 in all the columns.
The symmetry is pretty clear. The closer the tortoise is to the left end, the more likely it will be to reach the banana. The highest probability is 0.86. This agrees with our intuition as the tortoise does have a chance to reach for the apple although the banana is just 1 inch away. We multiply the transition matrix with the initial state numpy.array([0,0,0,1,0,0,0,0]) to get the probability of reaching the banana eventually. Note that it does agree with our simulation performed earlier.
Alright. This is the end of our first section. You have seen how to use the Markov chain to predict the weather and simulate a hungry tortoise movement. Next, let’s try to use the Markov chain as a generative model to write some poems.
Sonnet Written by Drunk Shakespeare
A Markov chain can be used to model human language as a simplistic first approach. Human language has intrinsic patterns such that the probabilities that a certain word follows another word are very different. A Markov chain fits in this scenario perfectly.
Let’s try to grab some sonnets from Shakespeare and turn his text into a Markov chain with corresponding probabilities.
First, we need to process the raw text by removing the punctuation, etc. We are going to use a third-party library called “nltk” to do the lemmatization. However, we will build the Markov chain on our own. If you are interested in comparing your result with output from mature libraries, check this repository. The text file that contains the sonnets is the sonnet.txt file, which is provided in the associated GitHub repo. You can also find the sonnets on the Project Gutenberg website.
Lemmatization is a process of converting a word or phrase into its base form. For example, the word “dogs” is converted to “dog,” and the word “went” is converted to “go.” This is helpful because our sonnet dataset is not that large that reducing words with different forms, but similar meaning, to the same one can centralize our transition probabilities somehow. You are free to explore the nonlemmatized version and compare the differences.
From fairest creatures we desire increase,
That thereby beauty’s rose might never die,
But as the riper should by time decease,
His tender heir might bear his memory:
But thou contracted to thine own bright eyes,
Feed’st thy light’s flame with self-substantial fuel,
Making a famine where abundance lies,
Thy self thy foe, to thy sweet self too cruel:
Thou that art now the world’s fresh ornament,
And only herald to the gaudy spring,
Within thine own bud buriest thy content,
And, tender churl, mak’st waste in niggarding:
Pity the world, or else this glutton be,
To eat the world’s due, by the grave and thee.
Note that you may need to uncomment the wordnet download line to download additional data. The sonnets variable is a list of sentences. We are simplifying the problem by only handling lowercases and ignoring the punctuation like beauty’s, which becomes beauty.

An illustration of connections between words. It resembles radiating spots connected by a line. Arrows pointing to the word, my are labeled all, verse, with, for, in, to, and of. The other words connected by arrows are beauty, world, thy, sweet, me, love, self, be, and make. Circles labeled thine, eye, mine, and own are arranged vertically.
The transitional relationship between words
You can try to manipulate the value of the edge threshold. You will be able to see more fine structures at the cost of more overlapping edges.
i praise that keep thee lie onward and lovely argument too much a foe commend.
doom and the rest forgot upon my mistress over wrack
always write of their rank before the dead wood whose worth in it in them
wear this book of forebemoaned moan the rose have given thee i my heart right
hindmost hold his memory death eternal slave to register and wrinkle graven there reign love
authorizing thy part wa false painting set a far remote where your soundless deep a
audit canst thou not be it not for my lameness and by that million of
brain inhearse
epitaph to whom thou take them say thy picture sight would have any be brought
leapt with the gentle thou hast thou dost advance
tonguetied muse brings forth your broad main doth nightly make the blazon of that heaven
added feather to lay upon thy beauty wear this purpose laid by this shall burn
tempest and no matter then did i may be taken
shower are mine eye corrupt by thy lusty day they themselves a the world common
wrong than hawk and beauty thou be scorned like her wish i see what merit
Not bad, isn’t it? Just look at this sentence: tempest and no matter then did i may be taken. It reads like something Shakespeare would write when he was drunk.
Alrighty. This concludes this chapter. Before moving on to our next chapter, here are some exercises.
Exercise
- 1.
Can you adjust the transition probability matrix of the tortoise’s movement to make it more realistic? For example, the tortoise can perhaps smell the fruit’s scent when it’s near and move toward it. How will the change impact the result?
- 2.
For the tortoise problem, if you try to find the eigenvalues of the transition matrix, you should see two identical eigenvalues and some others. What are the repeated eigenvalues? What is the implication of the repeated eigenvalues?
- 3.
Can you try trigram instead of bigram in the text generation?
- 4.
Try to use a large corpus to improve the accuracy of your text generation model. For example, nltk has a large corpus of English texts. You can download the corpus from here.
Summary
We continue our journey of simulating using randomness. We studied the Markov chain model and learned the mathematics behind it. We applied the Markovian model to weather prediction, absorbing state cases, and the sonnet writing.