
2.3 Audio coding
Generally speaking, audio coding is a process for changing the representation of an audio signal to make it more suitable for transmission or storage. Although high-capacity channels, networks, and storage systems have become more easily accessible, audio coding has retained its importance. Motivations for reducing the bitrate necessary for representing audio signals are the need to minimize transmission costs or to provide cost-efficient storage, the demand to transmit over channels with limited capacity such as mobile radio channels, and to support variable-rate coding in packet oriented networks. In this section, representations and coding techniques which are of relevance to spatial audio are reviewed.
2.3.1 Audio signal representation
Audio signals are usually available as discrete time sampled signals. For example, a compact disc (CD) stores stereo audio signals as two separate audio channels each sampled with a sampling frequency of 44.1 kHz. Each sample is represented as a 16-bit signed integer value, resulting in a bitrate of 2 × 44.1 × 16 = 1411 kb/s. For multi-channel audio signals or signals sampled at a higher sampling frequency the bitrate scales accordingly with the number of channels, bit depth, and sampling frequency.
2.3.2 Lossless audio coding
Ideally, an audio coder reduces the bitrate without degrading the quality of the audio signals. So-called lossless audio coders [51, 55, 95, 213, 223] can achieve this by reducing the bitrate while being able to perfectly reconstruct the original audio signal. Bitrate reduction in this case is possible by exploring redundancy present in audio signals, e.g. by applying prediction over time or a time–frequency transform, and controlling the coding process such that during decoding the values are rounded to the same integer sample values as the original samples. For typical CD audio signals, lossless audio coders reduce the bitrate by about a factor of 2. For higher sampling rates the higher degree of redundancy in the corresponding samples result in higher compression ratios.
Figure 2.6 illustrates a lossless audio coder based on prediction. It operates as follows:
Encoder: a linear predictor is used to predict the sample x(n) as a function of the past samples x(n − 1), x(n − 2),..., x(n − M),
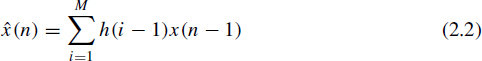
where M is the predictor order. Note that for the prediction quantized prediction parameters are used in order that the same prediction can be carried out also in the decoder. The prediction error, e(n) = x(n) − ![]() (n), is computed and lossless encoded together with the prediction parameters.
(n), is computed and lossless encoded together with the prediction parameters.
Decoder: the prediction error e(n) and the prediction parameters h(n) are decoded. The same predictor as in the encoder is used to compute ![]() (n) given the previous samples (2.2), The estimated sample,
(n) given the previous samples (2.2), The estimated sample, ![]() (n), is corrected with the prediction error, resulting in the decoder output x(n).
(n), is corrected with the prediction error, resulting in the decoder output x(n).
Alternatively, lossless audio coders can be implemented using an integer time/frequency transform. Figure 2.7 illustrates a lossless audio encoder and decoder based on an integer filterbank, e.g. integer modified discrete cosine transform (intMDCT) [92]. An integer filterbank takes a time discrete signal with integer amplitude and transforms it to the frequency domain which is also represented as integer numbers. The encoder applies an entropy coder, e.g. a Huffman coder, to the subband signals and transmits the coded subband signals as bitstream to the decoder. The decoder decodes the bitstream to recover the integer subband signals and applies the inverse filterbank to recover the original audio signal.
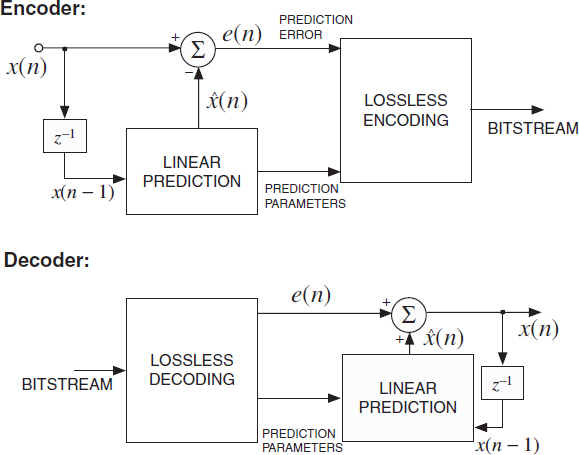
Figure 2.6 Generic prediction-based lossless audio encoder and decoder. Encoder: a linear predictor is used to predict the input integer samples. The prediction error is computed and coded together with the prediction parameters. Decoder: the prediction error and prediction parameters are decoded. The current prediction is corrected with the prediction error.
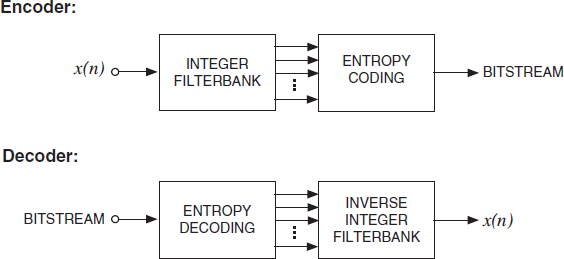
Figure 2.7 Generic lossless subband audio encoder and decoder. Encoder: the input signal is decomposed into a number of sub-bands by means of a perfect reconstruction integer filterbank. The integer sub-band signals are entropy coded and transmitted as bitstream to the decoder. Decoder: the coded sub-band signals are decoded and the inverse integer filterbank is applied to recover the audio signal.
2.3.3 Perceptual audio coding
Most audio coders are ‘lossy’ coders not aiming at reconstructing an audio signal perfectly. The primary motivation for using lossy audio coders is to achieve a higher compression ratio. A perceptual audio coder is an audio coder which incorporates a receiver model, i.e. it considers the properties of the human auditory system. Specifically, the concept of auditory masking is employed. Masking refers to the fact that one signal that is clearly audible in isolation (the ‘maskee’) can become inaudible when presented simultaneously with another (often louder) signal (the ‘masker’). The amount of masking depends strongly on the temporal and spectral content of both masker and maskee; in principle both signals should be both temporally and spectrally close for effective masking. In audio coders, the audio signal itself is the masker, while the quantization noise that is introduced due to data reduction is the maskee that should be kept inaudible. Hence audio coders employ a model to compute the masked threshold [293]. The masked threshold specifies as a function of time and frequency a signal level below which a maskee is not perceptible, i.e. the maximum level the quantization noise can have such that it is masked by the audio signal to be coded. By controlling the quantization noise as a function of time and frequency such that it is below the masked threshold, the bitrate can be reduced without degrading the perceived quality of the audio signal.
A generic perceptual audio coder, operating in a subband (or transform) domain, is shown in Figure 2.8. The encoding and decoding process are as follows.
Encoder: the input signal is decomposed into a number of sub-bands. Most audio coders use a modified discrete cosine transform (MDCT) [188] as time–frequency representation. A perceptual model computes the masked threshold as a function of time and frequency. Each sub-band signal is quantized and coded. The quantization error of each sub-band signal is controlled such that it is below the computed masked threshold. The bitstream not only contains the entropy coded quantizer indices of the sub-band signals, but also the quantizer step sizes as determined by the masked threshold (denoted ‘scale factors’).
Decoder: the entropy coded sub-band quantizer indices and quantization step sizes (‘scale factors’) are decoded. The inverse quantizer is applied prior to the inverse filterbank for recovering the audio signal.
This coding principle was introduced for speech coding by Zelinski and Noll [287]. Brandenburg et al. [41] applied this technique to wideband audio signals. Recent perceptual audio coders can be divided into two categories: so-called transform coders and sub-band coders. The first category employs a transform (such as an MDCT) on subsequent (often overlapping) segments to achieve control over separate frequency components. The second category is based on (critically sampled) filterbanks.
When more than one audio channel needs to be encoded, redundancy between the audio channels may be exploited for reducing the bitrate. Mid/side (M/S) coding [156] reduces the redundancy between a correlated channel pair by transforming it to a sum/difference channel pair prior to quantization and coding. The masked threshold depends on the interaural signal properties of the signal (masker) and quantization noise (maskee). When coding stereo or multi-channel audio signals, the perceptual model needs to consider this interaural dependence of the masked threshold. This dependence is often described by means of the binaural masking level difference (BMLD) [26].
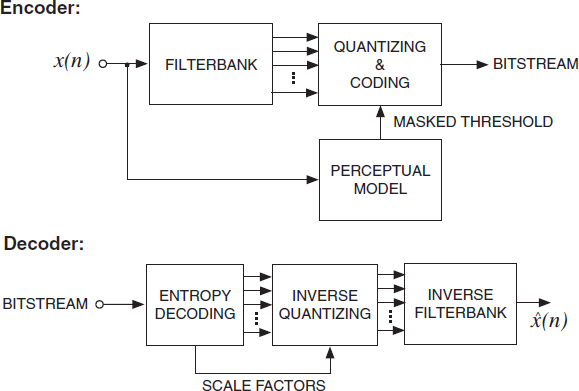
Figure 2.8 Generic perceptual audio encoder and decoder. Encoder: the input signal is decomposed into a number of sub-bands. The sub-band signals are quantized and coded. A perceptual model controls the quantization error such that it is just below the masked threshold and thus not perceptible. Decoder: the inverse entropy coder recovers subband quantization indices and quantization parameters (‘scale factors’). After inverse quantization the inverse filterbank is applied to recover the audio signal.
Today many proprietary perceptual audio coders, such as AC-3 (Dolby) [88], ATRAC (Sony) [258], PAC (Bell Laboratories, Lucent Technologies) [243] are available and in some cases (AC-3) widely used. International standards-based perceptual audio coders are widely used, such as MPEG-1 Layer 3 (MP3) [40, 136, 249] and MPEG-2 AAC (used for the Apple iTunes music store) [32, 40, 104, 136, 137, 249]. When requiring that the coded audio signal can not be distinguished from the original audio signal, these perceptual audio coders are able to reduce the bitrate of CD audio signals by a factor of about 10. When higher compression ratios are required, the audio bandwidth needs to be reduced or coding distortions will exceed the masked threshold.
2.3.4 Parametric audio coding
Perceptual audio coders (either sub-band or transform based) with coding mechanisms as described above perform only sub-optimally when high compression ratios need to be achieved. This is in most cases caused by the fact that the amount of bits required to keep the quantization noise below the masked threshold is insufficient, resulting in audible noise, so-called spectral holes, or a reduction in signal bandwidth. Parametric audio coders, on the other hand, are usually based on a source model, i.e. they make specific assumptions about the signals to be coded and can thus achieve higher compression ratios. Speech coders are a classical example for parametric coding and can achieve very high compression ratios. However, they perform sub-optimally for signals which can not be modeled effectively with the assumed source model. In the following, a number of parametric coding techniques, applicable to audio and speech coding, are described.
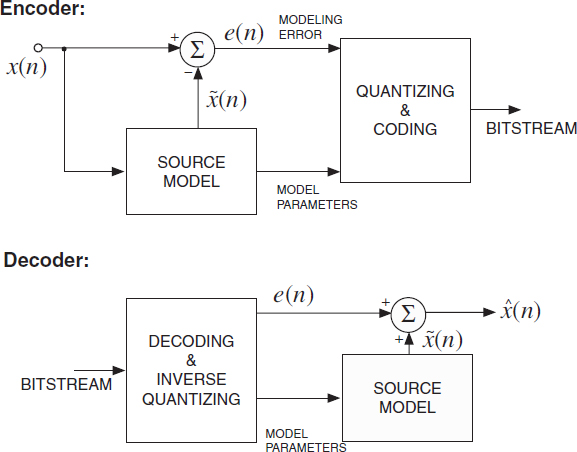
Figure 2.9 A generic parametric encoder and decoder. Encoder: parameters of a source model are estimated adaptively in time for modeling the input signal. The model parameters and often also the modeling error are transmitted to the decoder. Decoder: given the decoded modeling parameters, the source model estimates the original signal. If the error is also coded/transmitted then the source model output is ‘corrected’ given the modeling error.
A parametric encoder and decoder are illustrated in Figure 2.9. The encoder and decoder operate as follows.
Encoder: a source model predicts the input signal x(n) as a function of modeling parameters. The modeling parameters, and optionally the modeling error e(n), are quantized, coded, and transmitted to the decoder as bitstream. Nonparametric coding techniques may be applied for coding the modeling error, see e.g. [57].
Decoder: the bitstream is parsed and the modeling parameters (and, if used, the modeling error) are decoded and the inverse quantizer is applied. Given the modeling parameters the audio signal is estimated. If the modeling error was also transmitted then the model estimate is improved by adding the modeling error.
Linear predictive coding (LPC) is a standard technique often used in speech coders [4, 163]. In LPC, the source model is composed of an excitation and an all-pole filter. It has been shown that such an all-pole filter is a good model for the human vocal tract thus is suitable for speech coding. LPC has also been applied to wide-band audio signals, see e.g. [31, 110, 111, 242].
Another commonly used parametric coding technique is based on sinusoidal modeling, where the source model consists of a number of sinusoids. The parameters to be estimated here are amplitude, frequency, and phase of the sinusoids. Sinusoidal modeling has been applied to speech coding [118, 190] and audio coding [244].
For audio coding, a parametric coder has been proposed which decomposes an audio signal into sinusoids, harmonic components, and noise [76], denoted harmonic and individual lines plus noise (HILN) coder [140, 215]. Each of these three ‘objects’ is represented with a suitable set of parameters. A similar approach, but decomposing an audio signal into sinusoids, noise, and transients, was proposed by den Brinker et al. [67].
Parametric coders may not only incorporate a source model, but also a receiver model. Properties of the human auditory system are often considered for determining the choice or coding precision of the modeling parameters. Frequency selectivity properties of the human auditory system were explored for LPC-based audio coding by Härmä et al. [111]. A masking model is incorporated into the object-based parametric coder of Edler et al. [76] and only signal components which are not masked by the remaining parts of the signal are parameterized and coded. A later version of this coder additionally incorporates a loudness model [216] for giving precedence to signal components of highest loudness.
Most parametric audio and speech coders are only applicable to single-channel audio signals. Recently, the parametric coder proposed by den Brinker et al. [67] was extended for coding of stereo signals [233, 234] with parametric spatial audio coding techniques as described in this book.
2.3.5 Combining perceptual and parametric audio coding
Usually, parametric audio coding is applied for very low bitrates, e.g. 4–32 kb/s for mono or stereo audio signals, and nonparametric audio coding for higher bitrates up to transparent coding, e.g. 24–256 kb/s for mono or stereo audio signals. The perceptual audio coder as described above is based on the principle of ‘hiding’ quantization noise below the masked threshold. It is by design aimed at transparent coding. For medium bitrates, when the amount of quantization noise has to exceed the masked threshold for achieving the desired bitrate, this coding principle may not be optimal. A number of techniques have been proposed for extending perceptual audio coders with parametric coding techniques for improved quality at such medium bitrates.
One such parametric technique applicable for stereo or multi-channel audio coding is intensity stereo coding (ISC) [119]. ISC is a parametric technique for coding of audio channel pairs. ISC is illustrated in Figure 2.10. For lower frequencies, the spectra of a pair of audio channels are both coded. At higher frequencies, e.g. > 1–3 kHz, only a single spectrum is coded and the spectral differences are represented as intensity differences. The intensity difference parameters contain significantly less information than a spectrum and thus the bitrate is lowered by ISC.
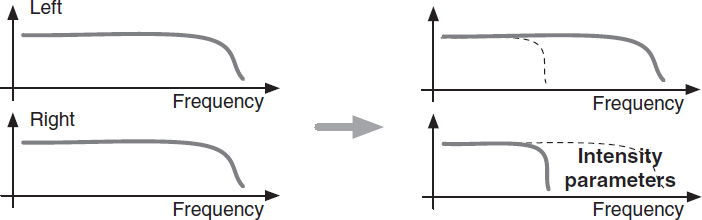
Figure 2.10 Intensity stereo coding (ISC) is applied to a pair of short-time spectra. At higher frequencies (usually above 1–3 kHz) the spectrum pair is represented as a single spectrum plus parameters representing the intensity difference between the channel pair.

Figure 2.11 Spectral bandwidth replication (SBR) represents the higher-frequency spectrum with a few parameters which allow regeneration of a meaningful spectrum at the decoder.
Another parametric technique that has been applied within the framework of perceptual audio coders is denoted spectral bandwidth replication (SBR) [68]. SBR is illustrated in Figure 2.11. It applies perceptual audio coding at frequencies below a certain frequency (e.g. <4–12 kHz) and parametric coding above that frequency. Very little information is used to parameterize the upper spectrum and the decoder uses information from the lower spectrum to generate a perceptually meaningful upper spectrum. Ideas related to SBR were already introduced by Makhoul and Berouti [186] in the context of speech coding.