
8.5 Application to MPEG Surround
8.5.1 Binaural decoding mode
The MPEG Surround parameters aim at faithful perceptual multi-channel reproduction of the original sound stage at the encoder side. In other words, the normal operation mode of MPEG Surround is intended for multi-channel loudspeaker playback. However, the parameters that are transmitted represent identical statistical properties between audio channels to those required for the binaural analysis and synthesis approach described in Sections 8.3 and 8.4. It is therefore possible to integrate the binaural analysis and synthesis approach in a dedicated MPEG Surround binaural decoding mode for headphone playback. The architecture of this mode is visualized in Figure 8.2. Instead of directly applying the transmitted spatial parameters to the output signals to generate multi-channel output, the parameters are used in a binaural parameter analysis stage to compute binaural parameters that would result from the combined spatial decoding and binaural rendering process. Thus, the binaural parameter analysis stage estimates the binaural parameters pyl, pyr, IPD and IC for each parameter band and each newly transmitted parameter set. The binaural output signals are subsequently synthesized by the binaural parameter synthesis stage.
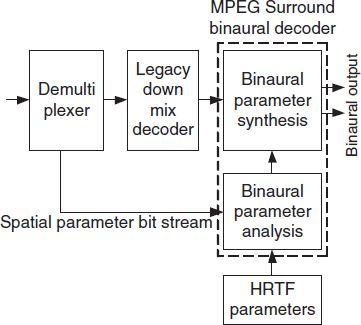
Figure 8.2 Overview of a binaural decoding mode for MPEG Surround.

Figure 8.3 Overview of a binaural synthesis stage based on a mono down-mix.
8.5.2 Binaural parameter synthesis
The binaural synthesis process, of which the essence is described in Section 8.4, is performed in a filterbank domain to enable independent processing of various time–frequency tiles. To facilitate integration of the binaural analysis and synthesis method in the MPEG Surround system, the same hybrid quadrature mirror filter (QMF) bank and decorrelators are applied that are currently being used in MPEG Surround. The synthesis stage is outlined in Figure 8.3. A hybrid QMF filterbank provides 71 down-sampled, nonlinearly spaced sub-bands that can be grouped in 28 parameter bands that approximate the bandwidth of critical bands. In case of a mono down-mix, the hybrid-QMF-domain signal is processed by a decorrelator that consists of a lattice all-pass filters to generate a signal that is statistically independent from its input [79, 235]. In case of a stereo down-mix, the two down-mix signals serve as input to the spatial synthesis stage (without decorrelator). Subsequently, a 2 × 2 matrix Wb is applied for each parameter band to generate two signals. The final binaural output is obtained by two hybrid QMF synthesis filterbanks.
The 2 × 2 binaural synthesis matrix Wb is computed for each received spatial parameter set. These spatial parameter sets are defined for specific temporal positions that are signaled in the MPEG Surround bitstream. For audio samples of positions in between such parameter positions, the synthesis matrix is interpolated linearly.
Thus, apart from the summation of statistical properties across virtual sound sources i given in Equations (8.20–8.22), the rendering method is independent of the number of sound sources. In other words, the parameter analysis stage is the only process of which the complexity depends on the number of virtual sound sources.
8.5.3 Binaural encoding mode
One of the interesting advantages of the parametric approach as described above is that the synthesis process comprises a 2 × 2 (sub-band) matrix which is, under certain constraints, invertible. In other words, the inverse of the 2 × 2 processing matrix that converts a conventional stereo down-mix to a binaural stereo signal can be employed to recover a conventional stereo down-mix from a binaural stereo signal:
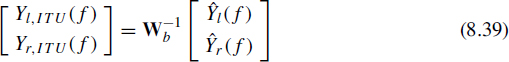
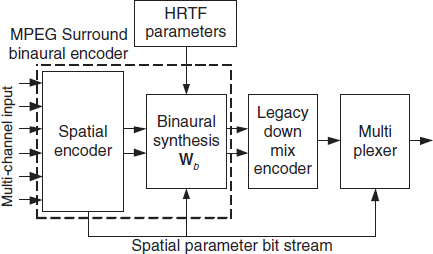
Figure 8.4 MPEG Surround encoder extended with a binaural synthesis stage (‘binaural encoder’).
This property provides means to move the binaural synthesis process to the MPEG Surround encoder as outlined in Figure 8.4. The spatial encoder within the MPEG Surround encoder generates a conventional stereo down-mix from the multi-channel input, accompanied by spatial parameters. The stereo down-mix is subsequently processed using the binaural synthesis matrix Wb. This synthesis matrix is controlled by spatial parameters and HRTF parameters, as described previously. The resulting stereo binaural signal is encoded using the legacy down-mix encoder. With this approach, binaurally rendered audio is provided to legacy decoders.
In case of stereo or multi-channel loudspeaker playback at the receiver side, the corresponding MPEG Surround decoder needs to be extended with a binaural inversion stage that applies matrix W−1b on the binaural down mix that reconstructs the conventional stereo down mix. This extension is visualized in Figure 8.5. This scheme works under the constraints that: (1) the legacy stereo audio coder is (to a large extend) waveform preserving; (2) the same HRTF parameters are available at the encoder and the decoder; and (3) special care is taken to ensure nonsingular encoding matrices.
This scheme has the advantage that legacy stereo decoders (for example on mobile devices) will render a virtual multi-channel experience, while MPEG Surround decoders are still capable of decoding high-quality multi-channel signals for loudspeaker playback despite the fact that the transmitted stereo down-mix is heavily altered by the binaural synthesis process. The drawbacks of the encoder-side binaural synthesis scenario are the need to align encoder and decoder-side HRTF data (for example by including the HRTF parameters in the MPEG Surround bit stream), and the difficulty to use personalized HRTFs. The latter can be accounted for however by cascading the inversion matrix of Fig 8.5 based on the same (generic) HRTFs as applied in the encoder, with an additional synthesis stage based on different, personalized HRTFs. This scheme is depicted in Figure 8.6. Hence, if personalized HRTFs are available at the decoder, the structure of Figure 8.6 is capable of synthesizing a binaural signal using these personalized HRTFs, even if the received down-mix signal was generated using nonpersonalized (generic) HRTFs.
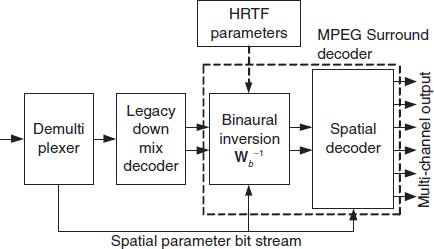
Figure 8.5 MPEG Surround decoder extended with a binaural inversion stage.
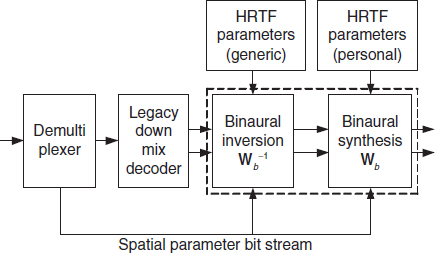
Figure 8.6 Conversion of a binaural signal using nonindividualized (generic) HRTFs to a binaural signal using individual HRTFs.
8.5.4 Evaluation
Procedure
A listening test was pursued to evaluate the subjective quality of the proposed binaural synthesis method. In this test, the quality of the MPEG Surround binaural decoding mode (MPS binaural) is compared with a reference condition. This reference condition comprised convolution of an original multi-channel audio excerpt with HRIRs. As a control condition, the combination of MPEG Surround multi-channel decoding followed by conventional HRIR convolution was employed (denoted MPS+ HRIR). For all configurations, anechoic KEMAR HRIRs [91] were used with a length of 128 samples at a sampling frequency of 44.1 kHz.
For both the binaural decoding mode as well as the control condition, the same MPEG Surround bitstream was employed. This bitstream was generated using a state-of-theart MPEG Surround decoder using a mono down-mix configuration. This mono downmix was subsequently encoded using a high-efficiency AAC encoder at 44 kbps. The spatial parameters generated by the MPEG Surround decoder occupied approximately 4 kbps. This rather low bitrate of 48 kbps total was selected because it is foreseen that the binaural decoding mode is especially suitable for mobile applications that are under severe transmission bandwidth and complexity constraints.
Twelve listeners participated in this experiment. All listeners had significant experience in evaluating audio codecs and were specifically instructed to evaluate the overall quality, consisting of the spatial audio quality as well as any other noticeable artifacts. In a double-blind MUSHRA test [148], the listeners had to rate the perceived quality of several processed excerpts against the original (i.e. unprocessed) excerpts on a 100-point scale with 5 anchors, labeled ‘bad’, ‘poor’, ‘fair’, ‘good’ and ‘excellent’. A hidden reference and the low-pass filtered anchor (reference with a bandwidth limitation of 3.5 kHz) were also included in the test. The subjects could listen to each excerpt as often as they liked and could switch in real time between all versions of each excerpt. The experiment was controlled from a PC with an RME Digi 96/24 sound card using ADAT digital out. Digital-to-analog conversion was provided by an RME ADI-8 DS eight-channel D-to-A converter. Beyerdynamic DT990 headphones were used throughout the test. Subjects were seated in a sound-insulated listening room.
A total of 11 critical excerpts were used as listed in Table 8.1. The excerpts are the same as used in the MPEG Call for Proposals (CfP) on Spatial Audio Coding [142], and range from pathological signals (designed to be critical for the technology at hand) to movie sound and multi-channel music productions. All input and output excerpts were sampled at 44.1 kHz.
Results
The results of the listening test are shown in Figure 8.7. The various excerpts are given along the abscissa, while the ordinate corresponds to the average MUSHRA score across listeners. Different symbols refer to different configurations. The error bars denote the 95% confidence intervals of the means.
The hidden reference (square symbols) has the highest scores. The results for the binaural decoding mode are denoted by the diamonds; the control condition using convolution is represented by the downward triangles. Although the scores for these methods vary between 45 and 85, the binaural decoding approach has scores that are higher than the conventional method for all excerpts. Finally, the low-pass anchor has the lowest scores of around 20.
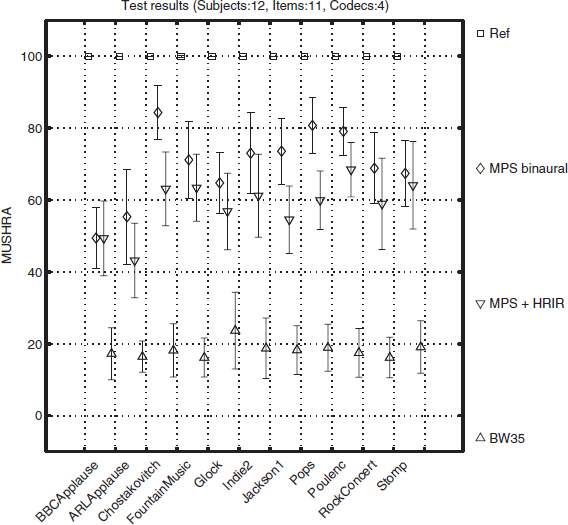
Figure 8.7 Subjective test results averaged across subjects for each excerpt. Error bars denote the 95% confidence intervals of the means.
The average scores for each method across subjects and excerpts are shown in Figure 8.8. The difference between the binaural decoding mode and the control condition amounts to 12 points in favor of the binaural decoder.
If the computational complexity of the binaural decoder and the conventional systems are compared, interesting differences are observed. The number of operations (expressed in multiply-accumulates per second which represent the combined, single processor operation of multiplication followed by addition) amounts to 11.1 million for the binaural decoder and 47 million for the MPEG Surround multi-channel decoder followed by convolution using fast Fourier transforms.
Discussion
The results of the perceptual evaluation indicate that both binaural rendering methods (the binaural decoding mode and the conventional HRIR convolution method) are distinguishable from the reference. This is most probably due to the low bitrate (48 kbps total) that was employed to represent the multi-channel signal in MPEG Surround format. For loudspeaker playback, the perceived quality of MPEG Surround operating at 48 kbps has been shown to amount 65 in other tests [48, 265]. In that respect, the quality for the test and control conditions are in line with earlier reports.
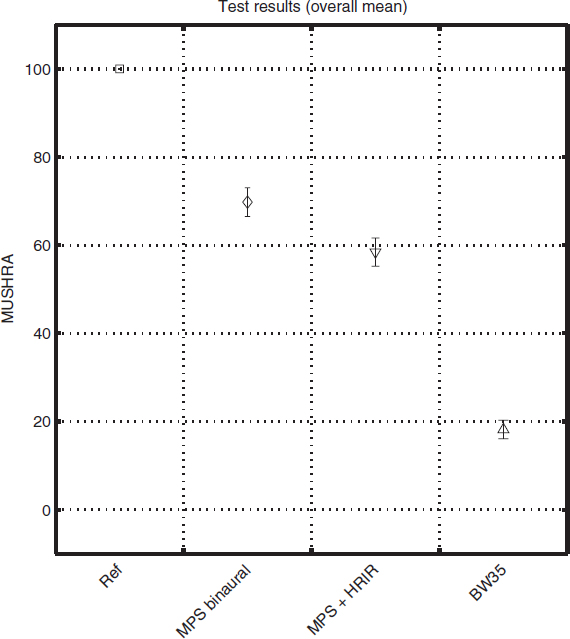
Figure 8.8 Average scores across subjects and excerpts.
The parametric representation of MPEG Surround aims at perceptual reconstruction of multi-channel audio. As such, at the bitrate that was under test, MPEG Surround does not deliver full waveform reconstruction of the multi-channel output signals. Such waveform reconstruction requires the use of ‘residual coding’ as supported by MPEG Surround. However, residual coding results in a significant increase in the bitrate which is undesirable or even unavailable in mobile applications. Given the low scores for MPEG Surround decoding followed by HRIR convolution, the multi-channel signals resulting from the parametric representation seem unsuitable for further post-processing using HRIRs. A high sensitivity for artefacts during post-processing of decoded output is a property that is often observed for lossy audio coders. The binaural decoding mode, however, which does not rely on post-processing of decoded signals, outperforms the convolution-based method, both in terms of perceived quality and computational complexity. This clearly indicates the advantages of parameter-domain processing compared with the signal-domain approach.