
All containers define their own iterator types, so you don't need a special header file for using iterators of containers. However, there are several definitions for special iterators, such as reverse iterators. These are introduced by the <iterator> header file,[1] although you don't need to include this file in your program often. It is needed by containers to define their reverse iterator types and thus it is included by them.
Iterators are objects that can iterate over elements of a sequence. They do this via a common interface that is adapted from ordinary pointers (see the introduction in Section 5.3, page 83). Iterators follow the concept of pure abstraction: Anything that behaves like an iterator is an iterator. However, iterators have different abilities. These abilities are important because some algorithms require special iterator abilities. For example, sorting algorithms require iterators that can perform random access because otherwise the runtime would be poor. For this reason, iterators have different categories (Figure 7.1). The abilities of these categories are listed in Table 7.1, and discussed in the following subsections.
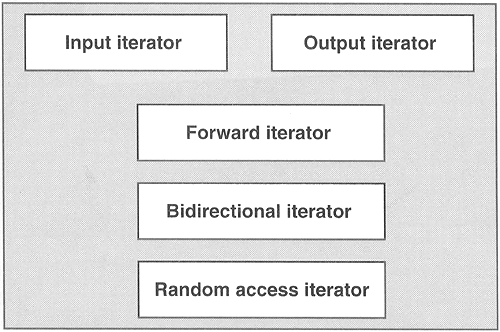
Table 7.1. Abilities of Iterator Categories
| Iterator Category | Ability | Providers |
|---|---|---|
| Input iterator | Reads forward | istream |
| Output iterator | Writes forward | ostream, inserter |
| Forward iterator | Reads and writes forward | |
| Bidirectional iterator | Reads and writes forward and backward | list, set, multiset, map, multimap |
| Random access iterator | Reads and writes with random access | vector, deque string, array |
Input iterators can only step forward element-by-element with read access. Thus, they return values elementwise. Table 7.2 lists the operations of input iterators.
Note that input iterators can read elements only once. Thus, if you copy an input iterator and let the original and the copy read forward, they might iterate over different values.
Almost all iterators have the abilities of input iterators. However, usually they can have more. A typical example of a pure input iterator is an iterator that reads from the standard input (typically the keyboard). The same value can't be read twice. After a word is read from an input stream (out of the input buffer), the next read access returns another word.
Two input iterators are equal if they occupy the same position. However, as stated previously, this does not mean that they return the same value on element access.
Table 7.2. Operations of Input Iterators
| Expression | Effect |
|---|---|
| *iter | Provides read access to the actual element |
| iter ->member | Provides read access to a member (if any) of the actual element |
| ++iter | Steps forward (returns new position) |
| iter++ | Steps forward (returns old position) |
| iter1 == iter2 | Returns whether two iterators are equal |
| iter1 != iter2 | Returns whether two iterators are not equal |
| TYPE(iter) | Copies iterator (copy constructor) |
You should always prefer the preincrement operator over the postincrement operator because it might perform better. This is because the preincrement operator does not have to return an old value that must be stored in a temporary object. So, for any iterator pos (and any abstract data type), you should prefer
++pos //OK and fastrather than
pos++ //OK, but not so fastThe same applies to decrement operators, as long as they are defined (they aren't for input iterators).
Output iterators are the counterparts of input iterators. They can only step forward with write access. Thus, you can assign new values only element-by-element. You can't use an output iterator to iterate twice over the same range. The goal is to write a value into a "black hole" (whatever that means). So, if you write something for the second time at the same position into the same black hole, it is not guaranteed that you will overwrite a previous value. Table 7.3 lists the valid operations for output iterators. The only valid use of operator * is on the left side of an assignment statement.
Table 7.3. Operations of Output Iterators
| Expression | Effect |
|---|---|
| *iter = value | Writes value to where the iterator refers |
| ++iter | Steps forward (returns new position) |
| iter++ | Steps forward (returns old position) |
| TYPE (iter) | Copies iterator (copy constructor) |
Note that no comparison operations are required for output iterators. You can't check whether an output iterator is valid or whether a "writing" was successful. The only thing you can do is to write, and write, and write values.
Usually iterators can read and write values. So, as for input iterators, almost all iterators also have the abilities of output iterators. A typical example of a pure output iterator is an iterator that writes to the standard output (for example, to the screen or a printer). If you use two output iterators to write to the screen, the second word follows the first rather than overwriting it. Another typical example of output iterators are inserters. Inserters are iterators that insert values into containers. If you assign a value, you insert it. If you then write a second value, you don't overwrite the first value; you just also insert it. Inserters are discussed in Section 7.4.2.
Forward iterators are combinations of input and output iterators. They have all the abilities of input iterators and most of those of output iterators. Table 7.4 summarizes the operations of forward iterators.
Table 7.4. Operations of Forward Iterators
| Expression | Effect |
|---|---|
| *iter | Provides access to the actual element |
| iter-> member | Provides access to a member of the actual element |
| ++iter | Steps forward (returns new position) |
| iter++ | Steps forward (returns old position) |
| iter1 == iter2 | Returns whether two iterators are equal |
| iter1 != iter2 | Returns whether two iterators are not equal |
| TYPE() | Creates iterator (default constructor) |
| TYPE(iter) | Copies iterator (copy constructor) |
| iter1 = iter2 | Assigns an iterator |
Unlike input iterators and output iterators, forward iterators can refer to the same element in the same collection and process the same element more than once.
You might wonder why a forward iterator does not have all of the abilities of an output iterator. One restriction applies that prohibits valid code for output iterators from being valid for forward iterators:
For output iterators, writing data without checking for the end of a sequence is correct. In fact, you can't compare an output iterator with an end iterator because output iterators do not have to provide a comparison operation. Thus, the following loop is correct for output iterator
pos://OK for output iterators //ERROR for forward iterators while (true) { *pos = foo(); ++pos; }
For forward iterators, you must ensure that it is correct to dereference (access the data) before you do this. Thus, the previous loop is not correct for forward iterators. This is because it would result in dereferencing the
end()of a collection, which results in undefined behavior. For forward iterators, the loop must be changed in the following manner://OK for forward iterators //IMPOSSIBLE for output iterators while (pos != coll.end()) { *pos = foo(); ++pos; }
This loop does not compile for output iterators because operator ! = is not defined for them.
Bidirectional iterators are forward iterators that provide the additional ability to iterate backward over the elements. Thus, they provide the decrement operator to step backward (Table 7.5).
Random access iterators are bidirectional iterators that can perform random access. Thus, they provide operators for "iterator arithmetic" (in accordance with the "pointer arithmetic" of ordinary pointers). That is, they can add and subtract offsets, process differences, and compare iterators with relational operators such as < and >.
Table 7.6 lists the additional operations of random access iterators.
Random access iterators are provided by the following objects and types:
Containers with random access (
vector, deque)Strings (
string, wstring)Ordinary arrays (pointers)
Table 7.6. Additional Operations of Random Access Iterators
| Expression | Effect |
|---|---|
| iter[n] | Provides access to the element that has index n |
| iter+=n | Steps n elements forward (or backward, if n is negative) |
| iter−=n | Steps n elements backward (or forward, if n is negative) |
| iter+n | Returns the iterator of the nth next element |
| n+iter | Returns the iterator of the nth next element |
| iter-n | Returns the iterator of the nth previous element |
| iter1-iter2 | Returns the distance between iter1 and iter2 |
| iter1<iter2 | Returns whether iter1 is before iter2 |
| iter1>iter2 | Returns whether iter1 is after iter2 |
| iter1<=iter2 | Returns whether iter1 is not after iter2 |
| iter1>=iter2 | Returns whether iter1 is not before iter2 |
The following program demonstrates the special abilities of random access iterators:
// iter/itercat.cpp #include <vector> #include <iostream> using namespace std; int main() { vector<int> coll; //insert elements from -3 to 9 for (int i=-3; i<=9; ++i) { coll.push_back (i); } /* print number of elements by processing the distance between beginning and end * - NOTE: uses operator -for iterators */ cout << "number/distance: " << coll.end()-coll.begin() << endl; /* print all elements * - NOTE: uses operator < instead of operator ! = */ vector<int>::iterator pos; for (pos=coll.begin(); pos<coll.end(); ++pos) { cout << *pos << ' '; } cout << endl; /* print all elements * - NOTE: uses operator [ ] instead of operator * */ for (int i=0; i<coll.size(); ++i) { cout << coll.begin() [i] << ' '; } cout << endl; /* print every second element * - NOTE: uses operator += */ for (pos = coll.begin(); pos < coll.end()-1; pos += 2) { cout << *pos << ' '; } cout << endl; }
The output of the program is as follows:
number/distance: 13 −3 −2 −1 0 1 2 3 4 5 6 7 8 9 −3 −2 −1 0 1 2 3 4 5 6 7 8 9 −3 −1 1 3 5 7
This example won't work with lists, sets, and maps because all operations that are marked with NOTE: are provided only for random access iterators. In particular, keep in mind that you can use operator < as an end criterion in loops for random access iterators only.
Note that in the last loop the expression
pos < coll.end()−1
requires that coll contains at least one element. If the collection was empty, coll.end()
−1 would be the position before coll.begin(). The comparison might still work; but, strictly speaking, moving an iterator to before the beginning results in undefined behavior. Similarly, the expression pos += 2 might result in undefined behavior if it moves the iterator beyond the end() of the collection. Therefore, changing the final loop to the following is very dangerous because it results in undefined behavior if the collection contains an even number of elements (Figure 7.2):
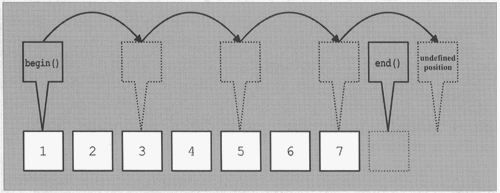
for (pos = coll.begin(); pos < coll.end(); pos += 2) {
cout << *pos << ' ';
}The use of the increment and decrement operators of iterators includes a strange problem. In general, you can increment and decrement temporary iterators. However, for vectors and strings, you typically can't. Consider the following vector example:
std::vector<int> coll; ... //sort, starting with the second element // - NONPORTABLE version if (coll.size() > 1) { sort (++coll.begin(), coll.end()); }
Typically, the compilation of sort() fails. However, if you use, for example, a deque rather than a vector, it will compile. It might compile even with vectors, depending on the implementation of class vector.
The reason for this strange problem lies in the fact that vector iterators are typically implemented as ordinary pointers. And for all fundamental data types, such as pointers, you are not allowed to modify temporary values. For structures and classes, however, it is allowed. Thus, if the iterator is implemented as an ordinary pointer, the compilation fails; if implemented as a class, it succeeds. It always works with deques, lists, sets, and maps because you can't implement iterators as ordinary pointers for them. But for vectors, whether it works depends on the implementation. Usually, ordinary pointers are used. But if, for example, you use a "safe version" of the STL, the iterators are implemented as classes. To make your code portable you should not code as the previous example, using vectors. Instead, you should use an auxiliary object:
std::vector<int> coll; ... //sort, starting with the second element // - PORTABLE version if (coll.size() > 1) { std::vector<int>::iterator beg = coll.begin(); sort (++beg, coll.end()); }
The problem is not as bad as it sounds. You can't get unexpected behavior because it is detected at compile time. But it is tricky enough to spend time solving it. This problem also applies to strings. String iterators are usually also implemented as ordinary character pointers, although this is not required.
The C++ standard library provides three auxiliary functions for iterators: advance(), distance(), and iter_swap(). The first two give all iterators some abilities usually only provided for random access iterators: to step more than one element forward (or backward) and to process the difference between iterators. The third auxiliary function allows you to swap the values of two iterators.
The function advance() increments the position of an iterator passed as the argument. Thus, it lets the iterator step forward (or backward) more than one element:
#include <iterator> void advance (InputIterator& pos, Dist n)
Lets the input iterator pos step n elements forward (or backward).
For bidirectional and random access iterators n may be negative to step backward.
Distis a template type. Normally, it must be an integral type because operations such as<, ++, −−,and comparisons with0are called.Note that
advance()does not check whether it crosses theend()of a sequence (it can't check because iterators in general do not know the containers on which they operate). Thus, calling this function might result in undefined behavior because calling operator++for the end of a sequence is not defined.
Due to the use of iterator traits (introduced in Section 7.5), the function always uses the best implementation, depending on the iterator category. For random access iterators, it simply calls pos+=n. Thus, for such iterators advance() has constant complexity. For all other iterators, it calls ++pos n times (or −−pos, if n is negative). Thus, for all other iterator categories advance() has linear complexity.
To be able to change container and iterator types, you should use advance() rather than operator +=. However, in doing so be aware that you risk unintended worse performance. This is because you don't recognize that the performance is worsening when you use other containers that don't provide random access iterators (bad runtime is the reason why operator += is provided only for random access iterators). Note also that advance() does not return anything. Operator += returns the new position, so it might be part of a larger expression. Here is an example of the use of advance():
// iter/advance1.cpp #include <iostream> #include <list> #include <algorithm> using namespace std; int main() { list<int> coll; //insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } list<int>::iterator pos = coll.begin(); //print actual element cout << *pos << endl; //step three elements forward advance (pos, 3); //print actual element cout << *pos << endl; //step three elements backward advance (pos, -1); //print actual element cout << *pos << endl; }
In this program, advance() lets the iterator pos step three elements forward and one element backward. Thus, the output is as follows:
1 4 3
Another way to use advance() is to ignore some input for iterators that read from an input stream. See the example on page 282.
The distance() function is provided to process the difference between two iterators:
#include <iterator> Dist distance (InputIterator pos1, InputIterator pos2)
Returns the distance between the input iterators pos1 and pos2.
Both iterators have to refer to elements of the same container.
If the iterators are not random access iterators, pos2 must be reachable from pos1; that is, it must have the same position or a later position.
The return type, Dist, is the difference type according to the iterator type:
iterator_traits<InputIterator>::difference_type
See Section 7.5, page 283, for details.
By using iterator tags, this function uses the best implementation according to the iterator category. For random access iterators, it simply returns pos2−pos1. Thus, for such iterators distance() has constant complexity. For all other iterator categories, pos1 is incremented until it reaches pos2 and the number of incrementations is returned. Thus, for all other iterator categories distance() has linear complexity. Therefore, distance() has bad performance for other than random access iterators. You should consider avoiding it.
The implementation of distance() is described in Section 7.5.1. The following example demonstrates its use:
// iter/distance.cpp #include <iostream> #include <list> #include <algorithm> using namespace std; int main() { list<int> coll; // insert elements from -3 to 9 for (int i=-3; i<=9; ++i) { coll.push_back(i); } // search element with value 5 list<int>::iterator pos; pos = find (coll.begin(), coll.end(), // range 5); // value if (pos != coll.end()) { // process and print difference from the beginning cout << "difference between beginning and 5: " << distance(coll.begin(),pos) << endl; } else { cout << "5 not found" << endl; } }
find() assigns the position of the element with value 5 to pos. distance() uses this position to process the difference between this position and the beginning. The output of the program is as follows:
difference between beginning and 5: 8
To be able to change iterator and container types, you should use distance() instead of operator-. However, if you use distance() you don't recognize that the performance is getting worse when you switch from random access iterators to other iterators.
To process the difference between two iterators that are not random access iterators, you must be careful. The first iterator must refer to an element that is not after the element of the second iterator. Otherwise, the behavior is undefined. If you don't know which iterator position comes first, you have to process the distance between both iterators to the beginning of the container and process the difference of these distances. However, you must then know to which container the iterators refer. If you don't, you have no chance of processing the difference of the two iterators without running into undefined behavior. See the remarks about subranges on page 99 for additional aspects of this problem.
In older versions of the STL, the signature of distance() was different. Instead of the difference being returned, it was added to a third argument. This version was very inconvenient because you could not use the difference directly in an expression. If you are using an old version, you should define this simple workaround:
// iter/distance.hpp
template <class Iterator>
inline long distance (Iterator pos1, Iterator pos2)
{
long d = 0;
distance (pos1, pos2, d);
return d;
}Here, the return type does not depend on the iterator; it is hard coded as long. Type long normally should be big enough to fit all possible values, however this is not guaranteed.
The following simple auxiliary function is provided to swap the values to which two iterators refer:
#include <algorithm> void iter_swap (ForwardIterator1 pos1, ForwardIterator2 pos2)
Swaps the values to which iterators pos1 and pos2 refer.
The iterators don't need to have the same type. However, the values must be assignable.
Here is a simple example (function PRINT_ELEMENTS() is introduced in Section 5.7):
// iter/swap1.cpp #include <iostream> #include <list> #include <algorithm> #include "print.hpp" using namespace std; int main() { list<int> coll; // insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } PRINT_ELEMENTS(coll); //swap first and second value iter_swap (coll.begin(), ++coll.begin()); PRINT_ELEMENTS(coll); //swap first and last value iter_swap (coll.begin(), --coll.end()); PRINT_ELEMENTS(coll); }
The output of the program is as follows:
1 2 3 4 5 6 7 8 9 2 1 3 4 5 6 7 8 9 9 1 3 4 5 6 7 8 2
Note that this program normally does not work if you use a vector as a container. This is because ++coll.begin() and −−coll.end() yield temporary pointers (see Section 7.2.6, for details regarding this problem).
This section covers iterator adapters. These special iterators allow algorithms to operate in reverse, in insert mode, and with streams.
Reverse iterators are adapters that redefine increment and decrement operators so that they behave in reverse. Thus, if you use these iterators instead of ordinary iterators, algorithms process elements in reverse order. All standard container classes provide the ability to use reverse iterators to iterate over their elements. Consider the following example:
// iter/reviter1.cpp #include <iostream> #include <list> #include <algorithm> using namespace std; void print (int elem) { cout << elem << ' '; } int main() { list<int> coll; //insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } //print all elements in normal order for_each (coll.begin(), coll.end(), //range print); //operation cout << endl; //print all elements in reverse order for_each (coll.rbegin(), coll.rend(), //range print); //operations cout << endl; }
The rbegin() and rend() member functions return a reverse iterator. According to begin() and end(), these iterators define the elements to process as a half-open range. However, they operate in a reverse direction:
rbegin()returns the position of the first element of a reverse iteration. Thus, it returns the position of the last element.rend()returns the position after the last element of a reverse iteration. Thus, it returns the position before the first element.
You can convert normal iterators to reverse iterators. Naturally, the iterators must be bidirectional iterators, but note that the logical position of an iterator is moved during the conversion. Consider the following program:
// iter/reviter2.cpp #include <iostream> #include <vector> #include <algorithm> using namespace std; int main() { vector<int> coll; //insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } //find position of element with value 5 vector<int>::iterator pos; pos = find (coll.begin(), coll.end(), 5); //print value to which iterator pos refers cout << "pos: " << *pos << endl; //convert iterator to reverse iterator rpos vector<int>::reverse_iterator rpos(pos); //print value to which reverse iterator rpos refers cout << "rpos: " << *rpos <<endl; }
This program has the following output:
pos: 5 rpos: 4
Thus, if you print the value of an iterator and convert the iterator into a reverse iterator, the value has changed. This is not a bug; it's a feature! This behavior is a consequence of the fact that ranges are half-open. To specify all elements of a container, you must use the position after the last argument. However, for a reverse iterator this is the position before the first element. Unfortunately, such a position may not exist. Containers are not required to guarantee that the position before their first element is valid. Consider that ordinary strings and arrays might also be containers, and the language does not guarantee that arrays don't start at address zero.
As a result, the designers of reverse iterators use a trick: They "physically" reverse the "half-open principle." Physically, in a range defined by reverse iterators, the beginning is not included, whereas the end is. However, logically, they behave as usual. Thus, there is a distinction between the physical position that defines to which element the iterator refers and the logical position that defines to which value the iterator refers (Figure 7.3). The question is, what happens on a conversion from an iterator to a reverse iterator? Does the iterator keep its logical position (the value) or its physical position (the element)? As the previous example shows, the latter is the case. Thus the value is moved to the previous element (Figure 7.4).
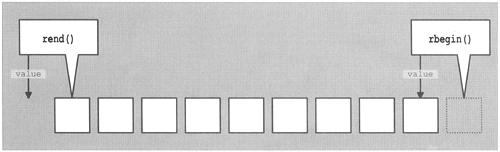
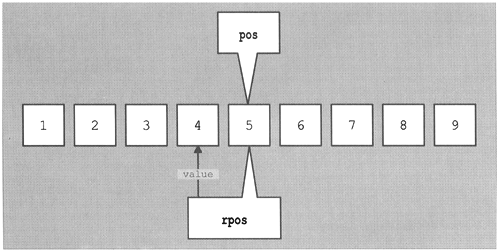
You can't understand this decision? Well, it has its advantages: You have nothing to do when you convert a range that is specified by two iterators rather than a single iterator. All elements stay valid. Consider the following example:
// iter/reviter3.cpp #include <iostream> #include <deque> #include <algorithm> using namespace std; void print (int elem) { cout << elem << ' '; } int main() { deque<int> coll; //insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } //find position of element with value 2 deque<int>::iterator pos1; pos1 = find (coll.begin(), coll.end(), //range 2); //value //find position of element with value 7 deque<int>::iterator pos2; pos2 = find (coll.begin(), coll.end(), //range 7); //value //print all elements in range [pos1,pos2) for_each (pos1, pos2, //range print); //operation cout << endl; //convert iterators to reverse iterators deque<int>::reverse_iterator rpos1(pos1); deque<int>::reverse_iterator rpos2(pos2); //print all elements in range [pos1,pos2) in reverse order for_each (rpos2, rpos1, //range print); //operation cout << endl; }
The iterators pos1 and pos2 specify the half-open range, including the element with value 2 but excluding the element with value 7. When the iterators describing that range are converted to reverse iterators, the range stays valid and can be processed in reverse order. Thus, the output of the program is as follows:
2 3 4 5 6 6 5 4 3 2
Thus, rbegin() is simply:
container::reverse_iterator(end())and rend() is simply:
container::reverse_iterator(begin())Of course, constant iterators are converted into type const_reverse_iterator.
You can convert reverse iterators back to normal iterators. To do this, reverse iterators provide the base() member function:
namespace std {
template <class Iterator>
class reverse_iterator ... {
...
Iterator base() const;
...
};
}Here is an example of the use of base():
// iter/reviter4.cpp #include <iostream> #include <list> #include <algorithm> using namespace std; int main() { list<int> coll; //insert elements from 1 to 9 for (int i=1; i<=9; ++i) { coll.push_back(i); } //find position of element with value 5 list<int>::iterator pos; pos = find (coll.begin(), coll.end(), //range 5); //value //print value of the element cout << "pos: " << *pos << endl; //convert iterator to reverse iterator list<int>::reverse_iterator rpos(pos); //print value of the element to which the reverse iterator refers cout << "rpos: " << *rpos << endl; //convert reverse iterator back to normal iterator list<int>::iterator rrpos; rrpos = rpos.base(); //print value of the element to which the normal iterator refers cout << "rrpos: " << *rrpos << endl; }
The program has the following output:
pos: 5 rpos: 4 rrpos: 5
Thus, the conversion with base()
*rpos.base()
is equivalent to the conversion in a reverse iterator. That is, the physical position (the element of the iterator) is retained, but the logical position (the value of the element) is moved. You can find another example of the use of base() on page 353.
Insert iterators, also called inserters, are iterator adapters that transform an assignment of a new value into an insertion of that new value. By using insert iterators, algorithms can insert rather than overwrite. All insert iterators are in the output iterator category. Thus, they provide only the ability to assign new values (see Section 7.2.2).
Usually an algorithm assigns values to a destination iterator. For example, consider the copy() algorithm (described on page 363):
namespace std {
template <class InputIterator, class OutputIterator>
OutputIterator copy (InputIterator from_pos, //beginning of source
InputIterator from_end, //end of source
OutputIterator to_pos) //beginning of dest.
{
while (from_pos != from_end) {
*to_pos = *from_pos; //copy values
++from_pos; //increment iterators
++to_pos;
}
return to_pos;
}
}The loop runs until the actual position of the source iterator has reached the end. Inside the loop, the source iterator, from_pos, is assigned to the destination iterator, to_pos, and both iterators get incremented. The interesting part is the assignment of the new value:
*to_pos = valueAn insert iterator transforms such an assignment into an insertion. However, there actually are two operations involved: First, operator * returns the current element of the iterator, and second, operator = assigns the new value. Implementations of insert iterators usually use the following two-step trick:
Operator
*is implemented as a no-op that simply returns*this.Thus, for insert iterators,*posis equivalent topos.The assignment operator is implemented so that it gets transferred into an insertion. In fact, the insert iterator calls the
push_back(), push_front(),orinsert()member function of the container.
Thus, for insert iterators, you could write pos=value instead of *pos=value to insert a new value. However, I'm talking about implementation details of input iterators. The correct expression to assign a new value is *pos=value.
Similarly, the increment operator is implemented as a no-op that simply returns *this. Thus,
you can't modify the position of an insert iterator. Table 7.7 lists all operations of insert iterators.
The C++ standard library provides three kinds of insert iterators: back inserters, front inserters, and general inserters. They differ in their handling of the position at which to insert a value. In fact, each uses a different member function, which it calls for the container to which it belongs. Thus, an insert iterator must be always initialized with its container.
Each kind of insert iterator has a convenience function for its creation and initialization. Table 7.8 lists the different kinds of insert iterators and their abilities.
Table 7.8. Kinds of Insert Iterators
| Name | Class | Called Function | Creation |
|---|---|---|---|
| Back inserter | back_insert_iterator
| push_back
(value)
| back_inserter
(cont)
|
| Front inserter | front_insert_iterator
| push_front
(value)
| front_inserter
(cont)
|
| General inserter | insert_iterator
| insert (pos, value)
| inserter (cont, pos)
|
Of course, the container must provide the member function that the insert iterator calls; otherwise, that kind of insert iterator can't be used. For this reason, back inserters are available only for vectors, deques, lists, and strings; front inserters are available only for deques and lists. The following subsections describe the insert iterators in detail.
A back inserter (or back insert iterator) appends a value at the end of a container by calling the push_back() member function (see page 241 for details about push_back()). push_back() is available only for vectors, deques, lists, and strings, so these are the only containers in the C++ standard library for which back inserters are usable.
A back inserter must be initialized with its container at creation time. The back_inserter() function provides a convenient way of doing this. The following example demonstrates the use of back inserters:
// iter/backins.cpp #include <iostream> #include <vector> #include <algorithm> #include "print.hpp" using namespace std; int main() { vector<int> coll; //create back inserter for coll // - inconvenient way back_insert_iterator<vector<int> > iter(coll); //insert elements with the usual iterator interface *iter = 1; iter++; *iter = 2; iter++; *iter = 3; PRINT_ELEMENTS(coll); //create back inserter and insert elements // - convenient way back_inserter(coll) = 44; back_inserter(coll) = 55; PRINT_ELEMENTS(coll); //use back inserter to append all elements again copy (coll .begin(), coll.end(), //source back_inserter(coll)); //destination PRINT_ELEMENTS(coll); }
The output of the program is as follows:
1 2 3 1 2 3 44 55 1 2 3 44 55 1 2 3 44 55
Note that you must not forget to reserve enough space before calling copy(). This is because the back inserter inserts elements, which might invalidate all other iterators referring to the same vector. Thus, the algorithm invalidates the passed source iterators while running, if not enough space is reserved.
Strings also provide an STL container interface, including push_back(). Therefore, you could use back inserters to append characters in a string. See page 502 for an example.
A front inserter (or front insert iterator) inserts a value at the beginning of a container by calling the push_front() member function (see page 241 for details about push_front()). push_front() is available only for deques and lists, so these are the only containers in the C++ standard library for which front inserters are usable.
A front inserter must be initialized with its container at creation time. The front_inserter() function provides a convenient way of doing this. The following example demonstrates the use of front inserters:
// iter/frontins.cpp #include <iostream> #include <list> #include <algorithm> #include "print.hpp" using namespace std; int main() { list<int> coll; //create front inserter for coll // - inconvenient way front_insert_iterator<list<int> > iter(coll); //insert elements with the usual iterator interface *iter = 1; iter++; *iter = 2; iter++; *iter = 3; PRINT_ELEMENTS(coll); //create front inserter and insert elements // - convenient way front_inserter(coll) = 44; front_inserter(coll) = 55; PRINT_ELEMENTS(coll); //use front inserter to insert all elements again copy (coll.begin(), coll.end(), //source front_inserter(coll)); //destination PRINT_ELEMENTS(coll); }
The output of the program is as follows:
3 2 1 55 44 3 2 1 1 2 3 44 55 55 44 3 2 1
Note that the front inserter inserts multiple elements in reverse order. This happens because it always inserts the next element in front of the previous one.
A general inserter (or general insert iterator)[2] is initialized with two values: the container and the position that is used for the insertions. Using both, it calls the insert() member function with the specified position as argument. The inserter() function provides a convenient way of creating and initializing a general inserter.
A general inserter is available for all standard containers because all containers provide the needed insert() member function. However, for associative containers (set and maps) the position is used only as a hint because the value of the element defines the correct position. See the description of insert() on page 240 for details.
After an insertion, the general inserter gets the position of the new inserted element. In particular, the following statements are called:
pos = container .insert (pos, value); ++pos;
The assignment of the return value of insert() ensures that the iterator's position is always valid. Without the assignment of the new position for deques, vectors, and strings, the general inserter would invalidate itself. This is because each insertion does, or at least might, invalidate all iterators that refer to the container.
The following example demonstrates the use of general inserters:
// iter/inserter.cpp #include <iostream> #include <set> #include <list> #include <algorithm> #include "print.hpp" using namespace std; int main() { set<int> coll; //create insert iterator for coll // - inconvenient way insert_iterator<set<int> > iter(coll,coll.begin()); //insert elements with the usual iterator interface *iter = 1; iter++; *iter = 2; iter++; *iter = 3; PRINT-ELEMENTS(coll,"set: "); //create inserter and insert elements // - convenient way inserter(coll,coll.end()) = 44; inserter(coll,coll.end()) = 55; PRINT_ELEMENTS(coll,"set: "); //use inserter to insert all elements into a list list<int> coll2; copy (coll.begin(), coll.end(), //source inserter(coll2,coll2.begin())); //destination PRINT_ELEMENTS(coll2,"list: "); //use inserter to reinsert all elements into the list before the second element copy (coll.begin(), coll.end(), //source inserter(coll2,++coll2.begin())); //destination PRINT_ELEMENTS(coll2,"list: "); }
The output of the program is as follows:
set: 1 2 3 set: 1 2 3 44 55 list: 1 2 3 44 55 list: 1 1 2 3 44 55 2 3 44 55
The calls of copy() demonstrate that the general inserter maintains the order of the elements. The second call of copy() uses a certain position inside the range that is passed as argument.
As mentioned previously, for associative containers the position argument of general inserters is only used as a hint. This hint might help to improve speed, however it also might cause bad performance. For example, if the inserted elements are in reverse order, the hint may slow down programs a bit. This is because the search for the correct insertion point always starts at a wrong position. Thus, a bad hint might even be worse than no hint. This is a good example of the useful supplementation of the C++ standard library. See Section 7.5.2, for such an extension.
A stream iterator is an iterator adapter that allows you to use a stream as source or destination of algorithms. In particular, an istreams iterator can be used to read elements from an input stream and an ostream iterator can be used to write values to an output stream.
A special form of a stream iterator is a stream buffer iterator, which can be used to read from or write to a stream buffer directly. Stream buffer iterators are discussed in Section 13.13.2, page 665.
Ostream iterators write assigned values to an output stream. By using ostream iterators, algorithms can write directly to streams. The implementation of an ostream iterator uses the same concept as the implementation of insert iterators (see page 271). The only difference is that they transform the assignment of a new value into an output operation by using operator <<. Thus, algorithms can write directly to streams using the usual iterator interface. Table 7.9 lists the operations of ostream iterators.
Table 7.9. Operations of ostream Iterators
| Expression | Effect |
|---|---|
ostream_iterator<T> (ostream)
| Creates an ostream iterator for ostream |
ostream_iterator<T> (ostream,delim)
| Creates an ostream iterator for ostream with the string delim as the delimiter between the values (note that delim has type const char*)
|
| *iter | No-op (returns iter) |
| iter = value | Writes value to ostream: ostream<<value (followed by delim if set) |
| ++iter | No-op (returns iter) |
| iter++ | No-op (returns iter) |
At creation time of the ostream iterator you must pass the output stream on which the values are written. An optional string can be passed, which is written as a separator between single values. Without the delimiter, the elements directly follow each other.
Ostream iterators are defined for a certain element type T:
namespace std {
template <class T,
class charT = char,
class traits = char_traits<charT> >
class ostream_iterator;
}The optional second and third template arguments specify the type of stream that is used (see Section 13.2.1, for their meaning).[3]
The following example demonstrates the use of ostream iterators:
// iter/ostriter.cpp #include <iostream> #include <vector> #include <algorithm> using namespace std; int main() { //create ostream iterator for stream cout // - values are separated by a newline character ostream_iterator<int> intWriter (cout," "); //write elements with the usual iterator interface *intWriter = 42; intWriter++; *intWriter = 77; intWriter++; *intWriter = -5; //create collection with elements from 1 to 9 vector<int> coll; for (int i=1; i<=9; ++i) { coll.push_back(i); } //write all elements without any delimiter copy (coll.begin(), coll.end(), ostream_iterator<int> (cout)); cout << endl; //write all elements with " < " as delimiter copy (coll.begin(), coll.end(), ostream_iterator<int>(cout," < ")); cout << endl; }
The output of the program is as follows:
42 77 −5 123456789 1 < 2 < 3 < 4 < 5 < 6 < 7 < 8 < 9 <
Note that the delimiter has type const char*. Thus, if you pass an object of type string you must call its member function c_str() (see Section 11.3.6, page 513) to get the correct type. For example:
string delim; ... ostream_iterator<int>(cout,delim.c_str());
Istream iterators are the counterparts of ostream iterators. An istream iterator reads elements from an input stream. By using istream iterators, algorithms can read from streams directly. However, istream iterators are a bit more complicated than ostream iterators (as usual, reading is more complicated than writing).
At creation time the istream iterator is initialized by the input stream from which it reads. Then, by using the usual interface of input iterators (see Section 7.2.1), it reads element-by-element using operator >>. However, reading might fail (due to end-of-file or an error), and source ranges of algorithms need an "end position." To handle both problems, you can use an end-of-stream iterator. An end-of-stream iterator is created with the default constructor for istream iterators. If a read fails, every istream iterator becomes an end-of-stream iterator. Thus, after any read access, you should compare an istream iterator with an end-of-stream iterator to check whether the iterator has a valid value. Table 7.10 lists all operations of istream iterators.
Note that the constructor of an istream iterator opens the stream and usually reads the first element. It has to read the first value because otherwise it could not return the first element when operator * is called after the initialization. However, implementations may defer the first read until the first call of operator *. So, you should not define an istream iterator before you really need it.
Istream iterators are defined for a certain element type T:
namespace std {
template <class T,
class charT = char,
class traits = char_traits<charT>,
class Distance = ptrdiff_t>
class istream_iterator;
}Table 7.10. Operations of istream Iterators
| Expression | Effect |
|---|---|
istream_iterator<T>()
| Creates an end-of-stream iterator |
istream_iterator<T> (istream)
| Creates an istream iterator for istream (and might read the first value) |
| *iter | Returns the value, read before (reads first value if not done by the constructor) |
| iter->member | Returns a member (if any) of the actual value, read before |
| ++iter | Reads next value and returns its position |
| iter++ | Reads next value but returns an iterator for the previous value |
| iter1==iter2 | Tests iter1 and iter2 for equality |
| iter1!= iter2 | Tests iter1 and iter2 for inequality |
The optional second and third template arguments specify the type of stream that is used (see Section 13.2.1, for their meaning). The optional fourth template argument specifies the difference type for the iterators.[4]
Two istream iterators are equal if
both are end-of-stream iterators and thus can no longer read, or
both can read and use the same stream.
The following example demonstrates the operations provided for istream iterators:
// iter/istriter.cpp #include <iostream> #include <iterator> using namespace std; int main() { //create istream iterator that reads integers from cin istream_iterator<int> intReader(cin); //create end-of-stream iterator istream_iterator<int> intReaderEOF; /* while able to read tokens with istream iterator * - write them twice */ while (intReader != intReaderEOF) { cout << "once: " << *intReader << endl; cout << "once again: " << *intReader << endl; ++intReader; } }
If you start the program with the following input:
1 2 3 f 4
the output of the program is as follows:
once: 1 once again: 1 once: 2 once again: 2 once: 3 once again: 3
As you can see, the input of character f ends the program. Due to a format error, the stream is no longer in a good state. Therefore, the istream iterator intReader is equal to the end-of-stream iterator intReaderEOF. So, the condition of the loop yields false,
Here is an example that uses both kinds of stream iterators as well as the advance() iterator function:
// iter/advance2.cpp #include <iostream> #include <string> #include <algorithm> using namespace std; int main() { istream_iterator<string> cinPos(cin); ostream_iterator<string> coutPos(cout," "); /* while input is not at the end of the file * - write every third string */ while (cinPos != istream_iterator<string>()) { //ignore the following two strings advance (cinPos, 2); //read and write the third string if (cinPos != istream_iterator<string>()) { *coutPos++ = *cinPos++; } } cout << endl; }
The advance() iterator function is provided to advance the iterator to another position (see Section 7.3.1). Used with istream iterators, it skips input tokens. For example, if you have the following input[5]:
No one objects if you are doing a good programming job for someone whom you respect.
the output is as follows:
objects are good for you
Don't forget to check whether the istream iterator is still valid after calling advance() and before accessing its value with *cinPos. Calling operator * for an end-of-stream iterator results in undefined behavior.
See pages 107, 366, and 385 for other examples that demonstrate how algorithms use stream iterators to read from and write to streams.
Iterators have different categories (see Section 7.2) that represent special iterator abilities. It might be useful or even necessary to be able to overload behavior for different iterator categories. By using iterator tags and iterator traits (both provided in <iterator>) such an overloading can be performed.
For each iterator category, the C++ standard library provides an iterator tag that can be used as a "label" for iterators:
namespace std {
struct output_iterator_tag {
};
struct input_iterator_tag {
};
struct forward_iterator_tag
: public input_iterator_tag {
};
struct bidirectional_iterator_tag
: public forward_iterator_tag {
};
struct random_access_iterator_tag
: public bidirectional_iterator_tag {
};
}Note that inheritance is used. So, for example, any forward iterator is a kind of input iterator. However, note that the tag for forward iterators is only derived from the tag for input iterators, not from the tag for output iterators. Thus, any forward iterator is not a kind of output iterator. In fact, forward iterators have requirements that keep them from being output iterators.
If you write generic code, you might not only be interested in the iterator category. For example, you may need the type of the elements to which the iterator refers. Therefore, the C++ standard library provides a special template structure to define the iterator traits. This structure contains all relevant information regarding an iterator. It is used as a common interface for all the type definitions an iterator should have (the category, the type of the elements, and so on):
namespace std {
template <class T>
struct iterator_traits {
typedef typename T::value_type value_type;
typedef typename T::difference_type difference_type;
typedef typename T::iterator_category iterator_category;
typedef typename T::pointer pointer;
typedef typename T::reference reference;
};
}In this template, T stands for the type of the iterator. Thus, you can write code that uses for any iterator its category, the type of its elements, and so on. For example, the following expression yields the value type of iterator type T:
typename std::iterator_traits<T>::value_type
This structure has two advantages:
It ensures that an iterator provides all type definitions.
It can be (partially) specialized for (sets of) special iterators. The latter is done for ordinary pointers that also can be used as iterators:
namespace std {
template <class T>
struct iterator_traits<T*> {
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef random_access_iterator_tag iterator_category;
typedef T* pointer;
typedef T& reference;
};
}Thus, for any type "pointer to T", it is defined that it has the random access iterator category. A corresponding partial specialization exists for constant pointers (const T*).
Using iterator traits, you can write generic functions that derive type definitions or use different implementation code depending on the iterator category.
A simple example of the use of iterator traits is an algorithm that needs a temporary variable for the elements. Such a temporary value is declared simply like this
typename std::iterator_traits<T>::value_type tmp;
whereby T is the type of the iterator.
Another example is an algorithm that shifts elements cyclically:
template <class ForwardIterator>
void shift_left (ForwardIterator beg, ForwardIterator end)
{
//temporary variable for first element
typedef typename
std::iterator_traits<ForwardIterator>::value_type value_type;
if (beg != end) {
//save value of first element
value_type tmp(*beg);
//shift following values
...
}
}To use different implementations for different iterator categories you must follow these two steps:
Let your template function call another function with the iterator category as an additional argument. For example:
template <class Iterator> inline void foo (Iterator beg, Iterator end) { foo (beg, end, std::iterator_traits<Iterator>::iterator_category()); }Implement that other function for any iterator category that provides a special implementation that is not derived from another iterator category. For example:
//foo() for bidirectional iterators template <class BiIterator> void foo (BiIterator beg, BiIterator end, std::bidirectional_iterator_tag) { ... } //foo() for random access iterators template <class RaIterator> void foo (RaIterator beg, RaIterator end, std::random_access_iterator_tag) { }
The version for random access iterators could, for example, use random access operations, whereas the version for bidirectional iterators would not. Due to the hierarchy of iterator tags (see page 283) you could provide one implementation for more than one iterator category.
An example of following the steps in the previous subsection is the implementation of the auxiliary distance() iterator function. This function returns the distance between two iterator positions and their elements (see Section 7.3.2). The implementation for random access iterators only uses the operator -. For all other iterator categories, the number of increments to reach the end of the range is returned.
//general distance() template <class Iterator> typename std::iterator_traits<Iterator>::difference_type distance (Iterator pos1, Iterator pos2) { return distance (pos1, pos2, std::iterator_traits<Iterator> ::iterator_category()); } //distance() for random access iterators template <class RaIterator> typename std::iterator_traits<RaIterator>::difference_type distance (RaIterator pos1, RaIterator pos2, std::random_access_iterator_tag) { return pos2 - pos1; } //distance() for input, forward, and bidirectional iterators template <class InIterator> typename std::iterator_traits<lnIterator>::difference_type distance (Inlterator pos1, InIterator pos2, std::input_iterator_tag) { typename std::iterator_traits<lnIterator>::difference_type d; for (d=0; pos1 != pos2; ++pos1, ++d) { ; } return d; }
The difference type of the iterator is used as the return type. Note that the second version uses the tag for input iterators, so this implementation is also used by forward and bidirectional iterators because their tags are derived from input_iterator_tag.
Let's write an iterator. As mentioned in the previous section, you need iterator traits provided for the user-defined iterator. You can provide them in one of two ways:
Provide the necessary five type definitions for the general
iterator_traitsstructure (see page 284).Provide a (partial) specialization of the
iterator_traitsstructure.
For the first way, the C++ standard library provides a special base class, iterator<>, that does the type definitions. You need only to pass the types[6]:
class MyIterator
: public std::iterator <std::bidirectional_iterator_tag,
type, std::ptrdiff_t, type*, type&> {
...
};The first template parameter defines the iterator category, the second defines the element type type, the third defines the difference type, the fourth defines the pointer type, and the fifth defines the reference type. The last three arguments are optional and have the default values ptrdiff_t, type*, and type&. Often it is enough to use the following definition:
class MyIterator
: public std::iterator <std::bidirectional_iterator_tag, type> {
...
};The following example demonstrates how to write a user-defined iterator. It is an insert iterator for associative containers. Unlike insert iterators of the C++ standard library (see Section 7.4.2), no insert position is used.
Here is the implementation of the iterator class:
// iter/assoiter.hpp #include <iterator> /* template class for insert iterator for associative containers */ template <class Container> class asso_insert_iterator : public std::iterator <std::output_iterator_tag, void, void, void, void> { protected: Container& container; //container in which elements are inserted public: //constructor explicit asso_insert_iterator (Container& c) : container(c) { } //assignment operator // - inserts a value into the container asso_insert_iterator<Container>& operator= (const typename Container::value_type& value) { container.insert(value); return *this; } //dereferencing is a no-op that returns the iterator itself asso_insert_iterator<Container>& operator* () { return *this; } //increment operation is a no-op that returns the iterator itself asso_insert_iterator<Container>& operator++ () { return *this; } asso_insert_iterator<Container>& operator++ (int) { return *this; } }; /* convenience function to create the inserter */ template <class Container> inline asso_insert_iterator<Container> asso_inserter (Container& c) { return asso_insert_iterator<Container>(c); }
The asso_insert_iterator class is derived from the iterator class. The first template argument output_iterator_tag is passed to iterator to specify the iterator category. Output iterators can only be used to write something. Thus, as for all output iterators, element and difference types are void.[7]
At creation time the iterator stores its container in its container member. Any value that gets assigned is inserted into the container by insert(). Operators * and ++ are no-ops that simply return the iterator itself. Thus, the iterator maintains control. If the usual iterator interface is used
*pos = value
the *pos expression returns *this to which the new value is assigned. That assignment is transfered into a call of insert(value) for the container.
After the definition of the inserter class, the usual convenient function asso_inserter is defined as convenience function to create and initialize an inserter. The following program uses such an inserter to insert some elements into a set:
// iter/assoiter.cpp #include <iostream> #include <set> #include <algorithm> using namespace std; #include "print.hpp" #include "assoiter.hpp" int main() { set<int> coll; //create inserter for coll // - inconvenient way asso_insert_iterator<set<int> > iter(coll); //insert elements with the usual iterator interface *iter = 1; iter++; *iter = 2; iter++; *iter = 3; PRINT_ELEMENTS(coll); //create inserter for coll and insert elements // - convenient way asso_inserter(coll) = 44; asso_inserter(coll) = 55; PRINT_ELEMENTS(coll); //use inserter with an algorithm int vals[] = { 33, 67, -4, 13, 5, 2 }; copy (vals, vals+(sizeof(vals)/sizeof(vals[0])), //source asso_inserter(coll)); //destination PRINT_ELEMENTS(coll); }
The output of the program is as follows:
1 2 3 1 2 3 44 55 −4 1 2 3 5 13 33 44 55 67
[1] In the original STL, the header file for iterators was called <iterator.h>.
[2] A general inserter is often simply called insert iterator or inserter. This means that the words insert iterator and inserter have different meanings: They are a general term for all kinds of insert iterators. They are also used as names for a special insert iterator that inserts at a specified position rather than in the front or in the back. To avoid this ambiguity, I use the term general inserter in this book.
[3] In older systems, the optional template arguments for the stream type are missing.
[4] In older systems without default template parameters, the optional fourth template argument is required as the second argument, and the arguments for the stream type are missing.
[5] Thanks to Andrew Koenig for the nice input of this example.
[6] In older STL versions, the auxiliary types input_iterator, output_iterator, forward_iterator, bidirectional_iterator, and random_access_iterator were provided instead of iterator.
[7] For older STL versions, the asso_insert_iterator class must be derived from class output_iterator without any template parameter.