
C H A P T E R 6
![]()
The Core C API
This chapter covers the part of the SQLite API used to work with databases. You already saw an overview of how the API works in Chapter 5. Now let's concentrate on the specifics.
Starting with a few easily understood examples, we will take an in-depth tour through the C API and expand upon the examples, filling in various details with a variety of useful functions. As we go along, you should see the C equivalents of the model all fall into place, with some additional features you may not have seen before—features that primarily exist only in the C API. By the time we reach the end of this chapter, you should have a good feel for all of the API functions related to running commands, managing transactions, fetching records, handling errors, and performing many other tasks related to general database work.
The SQLite version 3 API consists of dozens and dozens of functions. Only about eight functions, however, are needed to actually connect, process queries, and disconnect from a database. The remaining functions can be arranged into small groups that specialize in accomplishing specific tasks.
Although it is best to read the chapter straight through, if at any point you want more detailed information on a particular function, you can consult the C API reference at www.sqlite.org/c3ref/intro.html.
You can find all the examples in this chapter in self-contained example programs in the examples zip file, available on the Apress web site at www.apress.com. For every example presented, we specifically identify the name of the corresponding source file from which the example was taken.
Wrapped Queries
You are already familiar with the way that SQLite executes queries, as well as its various wrapper functions for executing SQL commands in a single function call. We will start with the C API versions of these wrappers because they are simple, self-contained, and easy to use. They are a good starting point, which will let you have some fun and not get too bogged down with details. Along the way, I'll introduce some other handy functions that go hand in hand with query processing. By the end of this section, you will be able connect, disconnect, and query a database using the wrapped queries.
Connecting and Disconnecting
Before you can execute SQL commands, you first have to connect to a database. Connecting to a database is perhaps best described as opening a database, because SQLite databases are contained in single operating system files (one file to one database). Similarly, the preferred term for disconnecting is closing the database.
You open a database with the sqlite3_open_v2(), sqlite3_open(), or sqlite3_open16() functions, which have the following declaration(s):
int sqlite3_open_v2(
const char *filename, /* Database filename (UTF-8) */
sqlite3 **ppDb /* OUT: SQLite db handle */
int flags, /* Flags */
const char *zVfs /* Name of VFS module to use */
);
int sqlite3_open (
const void *filename, /* Database filename (UTF-8) */
sqlite3 **ppDb /* OUT: SQLite db handle */
);
int sqlite3_open16(
const void *filename, /* Database filename (UTF-16) */
sqlite3 **ppDb /* OUT: SQLite db handle */
);
Typically, you'll use sqlite3_open_v2(), because this is the latest and greatest function in SQLite for opening your database, and it accommodates more options and capabilities over the old sqlite3_open(). Regardless of the function chosen, the filename argument can be the name of an operating system file, the text string ':memory:', or an empty string or a NULL pointer. If you use ':memory:', sqlite3_open_v2() will create an in-memory database in RAM that lasts only for the duration of the session. If filename is an empty string or a NULL, sqlite3_open_v2() opens a temporary disk file that is automatically deleted when the connection closes. Otherwise, sqlite3_open_v2() attempts to open the database file by using its value. If no file by that name exists, sqlite3_open_v2() will open a new database file by that name if the SQLITE_OPEN_CREATE flag is included in the third parameter, or it will return an error if the SQLITE_OPEN_CREATE flag is omitted.
![]() Note Here we have included both the UTF-8 and UTF-16 declarations for
Note Here we have included both the UTF-8 and UTF-16 declarations for sqlite3_open(), as well as the more modern sqlite3_open_v2(). From here on out, we will refer to the UTF-8 declarations only for the sake of brevity, and where they exist, we'll deal with the latest function signatures that incorporate SQLite's latest functionality, rather than cover all the legacy functions as well. Therefore, please keep in mind that there are many functions in the API that have UTF-16 forms, as well as older UTF-8 forms for backward compatibility. The complete C API reference is available on the SQLite web site at www.sqlite.org/c3ref/intro.html.
The flags parameter is a bit vector that can include the following values: SQLITE_OPEN_READONLY, SQLITE_OPEN_READWRITE, and SQLITE_OPEN_CREATE. The names are reasonable self-explanatory, but a few subtleties are worth noting. SQLITE_OPEN_READONLY and SQLITE_OPEN_READWRITE open a SQLite database in read-only or read/write mode as their names suggest. Both options require that the database file already exist; otherwise, an error will be returned. SQLITE_OPEN_CREATE combined with SQLITE_OPEN_READWRITE exhibits the behavior we've seen in the first five chapters, which is the legacy sqlite3_open() behavior. Where a database already exists, it is opened for reading and writing. If the database specified doesn't exist, it is created (though as we've pointed out quite a few times, the act of persisting the database to disk will be pending the creation of the first object).
The flags parameter can also be combined with the SQLITE_OPEN_NOMUTEX, SQLITE_OPEN_FULLMUTEX, SQLITE_OPEN_SHAREDCACHE, or SQLITE_OPEN_PRIVATECACHE flags to further control transactional behavior for the database handle. The final parameter, zVfs, allows the caller to override the default sqlite3_vfs operating system interface.
Upon completion, sqlite3_open_v2() will initialize the sqlite3 structure passed into it by the ppDb argument. This structure should be considered as an opaque handle representing a single connection to a database. This is more of a connection handle than a database handle since it is possible to attach multiple databases to a single connection. However, this connection still represents exactly one transaction context regardless of how many databases are attached.
You close a connection by using the sqlite3_close() function, which is declared as follows:
int sqlite3_close(sqlite3*);
For sqlite3_close() to complete successfully, all prepared queries associated with the connection must be finalized. If any queries remain that have not been finalized, sqlite3_close() will return SQLITE_BUSY with the error message “Unable to close due to unfinalized statements.”
![]() Note If there is a transaction open on a connection when it is closed by
Note If there is a transaction open on a connection when it is closed by sqlite3_close(), the transaction will automatically be rolled back.
The exec Query
The sqlite3_exec() function provides a quick, easy way to execute SQL commands and is especially handy for commands that modify the database (that is, don't return any data). This is often also referred to as a convenience function, which nicely wraps up a lot of other tasks in one easy API call. This function has the following declaration:
int sqlite3_exec(
sqlite3*, /* An open database */
const char *sql, /* SQL to be executed */
sqlite_callback, /* Callback function */
void *data /* 1st argument to callback function */
char **errmsg /* Error msg written here */
);
The SQL provided in the sql argument can consist of more than one SQL command. sqlite3_exec() will parse and execute every command in the sql string until it reaches the end of the string or encounters an error. Listing 6-1 (taken from create.c) illustrates how to use sqlite3_exec().The example opens a database called test.db and creates within it a single table called episodes. After that, it inserts one record. The create table command will physically create the database file if it does not already exist.
Listing 6-1. Using sqlite3_exec() for Simple Commands
int main(int argc, char **argv)
{
sqlite3 *db;
char *zErr;
int rc;
char *sql;
rc = sqlite3_open_v2("test.db", &db);
if(rc) {
fprintf(stderr, "Can't open database: %s
", sqlite3_errmsg(db));
sqlite3_close(db);
exit(1);
}
sql = "create table episodes(id int, name text)";
rc = sqlite3_exec(db, sql, NULL, NULL, &zErr);
if(rc != SQLITE_OK) {
if (zErr != NULL) {
fprintf(stderr, "SQL error: %s
", zErr);
sqlite3_free(zErr);
}
}
sql = "insert into episodes values (10, 'The Dinner Party')";
rc = sqlite3_exec(db, sql, NULL, NULL, &zErr);
sqlite3_close(db);
return 0;
}
As mentioned in Chapter 5, it is actually possible to get records from sqlite3_exec(), although you don't see it implemented much outside of the C API. sqlite3_exec() contains a callback mechanism that provides a way to obtain results from select statements. This mechanism is implemented by the third and fourth arguments of the function. The third argument is a pointer to a callback function. If it's provided, SQLite will call the function for each record processed in each select statement executed within the sql argument. The callback function has the following declaration:
typedef int (*sqlite3_callback)(
void*, /* Data provided in the 4th argument of sqlite3_exec() */
int, /* The number of columns in row */
char**, /* An array of strings representing fields in the row */
char** /* An array of strings representing column names */
);
The fourth argument to sqlite3_exec() is a void pointer to any application-specific data you want to supply to the callback function. SQLite will pass this data as the first argument of the callback function.
The final argument (errmsg) is a pointer to a string to which an error message can be written should an error occur during processing. Thus, sqlite3_exec() has two sources of error information. The first is the return value. The other is the human-readable string, assigned to errmsg. If you pass in a NULL for errmsg, then SQLite will not provide any error message. Note that if you do provide a pointer for errmsg, the memory used to create the message is allocated on the heap. You should therefore check for a non-NULL value after the call and use sqlite3_free() to free the memory used to hold the errmsg string if an error occurs.
![]() Note Note that you can pass a NULL into
Note Note that you can pass a NULL into sqlite3_free(). The result is a harmless no-op. So, you can, if you want, call sqlite3_free(errmsg) without having to check to see whether errmsg is not NULL. It mainly depends on where and how you want to interrogate any actual errors and respond accordingly.
Putting it all together, sqlite3_exec() allows you to issue a batch of commands, and you can collect all the returned data by using the callback interface. For example, let's insert a record into the episodes table and then select all of its records, all in a single call to sqlite3_exec(). The complete code, shown in Listing 6-2, is taken from exec.c.
Listing 6-2. Using sqlite3_exec() for Record Processing
int callback(void* data, int ncols, char** values, char** headers);
int main(int argc, char **argv)
{
sqlite3 *db;
int rc;
char *sql;
char *zErr;
rc = sqlite3_open_v2("test.db", &db);
if(rc) {
fprintf(stderr, "Can't open database: %s
", sqlite3_errmsg(db));
sqlite3_close(db);
exit(1);
}
const char* data = "Callback function called";
sql = "insert into episodes (id, name) values (11,'Mackinaw Peaches'),"
"select * from episodes;";
rc = sqlite3_exec(db, sql, callback, data, &zErr);
if(rc != SQLITE_OK) {
if (zErr != NULL) {
fprintf(stderr, "SQL error: %s
", zErr);
sqlite3_free(zErr);
}
}
sqlite3_close(db);
return 0;
}
int callback(void* data, int ncols, char** values, char** headers)
{
int i;
fprintf(stderr, "%s: ", (const char*)data);
for(i=0; i < ncols; i++) {
fprintf(stderr, "%s=%s ", headers[i], values[i]);
}
fprintf(stderr, "
");
return 0;
}
SQLite parses the sql string; runs the first command, which inserts a record; and then runs the second command, consisting of the select statement. For the second command, SQLite calls the callback function for each record returned. Running the program produces the following output:
Callback function called: id=10 name=The Dinner Party
Callback function called: id=11 name=Mackinaw Peaches
Notice that the callback function returns 0. This return value actually exerts some control over sqlite3_exec(). If the callback function returns a nonzero value, then sqlite3_exec() will abort (in other words, it will terminate all processing of this and subsequent commands in the sql string).
So, sqlite3_exec() provides an easy way to modify the database and also provides an interface with which to process records. Why then should you bother with prepared queries? Well, as you will see in the next section, there are quite a few advantages:
- Prepared queries don't require a callback interface, which makes coding simple and more linear.
- Prepared queries have associated functions that provide better column information. You can obtain a column's storage type, declared type, schema name (if it is aliased), table name, and database name.
sqlite3_exec()'s callback interface provides just the column names. - Prepared queries provide a way to obtain field/column values in other data types besides text and in native C data types such as
intanddouble, whereassqlite3_exec()'s callback interface only provides fields as string values. - Prepared queries can be rerun, allowing you to reuse the compiled SQL.
- Prepared queries support parameterized SQL statements.
The Get Table Query
The sqlite3_get_table() function returns an entire result set of a command in a single function call. Just as sqlite3_exec() wraps the prepared query API functions, allowing you to run them all at once, sqlite3_get_table() wraps sqlite3_exec() for commands that return data with just as much convenience. Using sqlite3_get_table(), you don't have to bother with the sqlite3_exec() callback function, thus making it easier to fetch records. sqlite3_get_table() has the following declaration:
int sqlite3_get_table(
sqlite3*, /* An open database */
const char *sql, /* SQL to be executed */
char ***resultp, /* Result written to a char *[] that this points to */
int *nrow, /* Number of result rows written here */
int *ncolumn, /* Number of result columns written here */
char **errmsg /* Error msg written here */
);
This function takes all the records returned from the SQL statement in sql and stores them in the resultp argument using memory declared on the heap (using sqlite3_malloc()). The memory must be freed using sqlite3_free_table(), which takes the resultp pointer as its sole argument. The first record in resultp is actually not a record but contains the names of the columns in the result set. Examine the code fragment in Listing 6-3 (taken from get_table.c).
Listing 6-3. Using sqlite3_get_table
int main(int argc, char **argv)
{
/* Connect to database, etc. */
char *result[];
sql = "select * from episodes;";
rc = sqlite3_get_table(db, sql, &result, &nrows, &ncols, &zErr);
/* Do something with data */
/* Free memory */
sqlite3_free_table(result)
}
If, for example, the result set returned is of the following form:
name | id
-----------------------
The Junior Mint | 43
The Smelly Car | 28
The Fusilli Jerry | 21
then the format of the result array will be structured as follows:
result [0] = "name";
result [1] = "id";
result [2] = "The Junior Mint";
result [3] = "43";
result [4] = "The Smelly Car";
result [5] = "28";
result [6] = "The Fusilli Jerry";
result [7] = "21";
The first two elements contain the column headings of the result set. Therefore, you can think of the result set indexing as 1-based with respect to rows but 0-based with respect to columns. An example may help clarify this. Listing 6-4 shows the code to print out each column of each row in the result set.
Listing 6-4. Iterating Through sqlite3_get_table() Results
rc = sqlite3_get_table(db, sql, &result, &nrows, &ncols, &zErr);
for(i=0; i < nrows; i++) {
for(j=0; j < ncols; j++) {
/* the i+1 term skips over the first record,
which is the column headers */
fprintf(stdout, "%s", result[(i+1)*ncols + j]);
}
}
Prepared Queries
Our Chapter 5 overview of SQLite's API introduced the concepts of the prepare, step, and finalize functions. This section covers all aspects of this process, including stepping through result sets, fetching records, and using parameterized queries. We told you prepared statements were infinitely preferable to the convenience wrapper functions, and this is where we prove the point.
The wrapper functions simply wrap all these steps into a single function call, making it more convenient in some situations to run specific commands. Each query function provides its own way of getting at rows and columns. As a general rule, the more packaged the method is, the less control you have over execution and results. Therefore, prepared queries offer the most features, the most control, and the most information, with sqlite3_exec() offering slightly fewer features and sqlite3_get_table() offering fewer still.
Prepared queries use a special group of functions to access field and column information from a row. You get column values using sqlite3_column_xxx(), where xxx represents the data type of the value to be returned (for example, int, double, blob). You can retrieve data in whatever format you like. You can also obtain the declared types of columns (as they are defined in the create table statement) and other miscellaneous metadata such as storage format and both associated table and database names. sqlite3_exec(), by comparison, provides only a fraction of this information through its callback function. The same is true with sqlite3_get_table(), which only includes the result set's column headers with the data.
In practice, you will find that each query method has its uses. sqlite3_exec() is especially good for running commands that modify the database (create, drop, insert, update, and delete). One function call, and it's done. Prepared queries are typically better for select statements because they offer so much more information, more linear coding (no callback functions), and more control by using cursors to iterate over results.
As you'll recall from Chapter 5, prepared queries are performed in three basic steps: compilation, execution, and finalization. You compile the query with sqlite3_prepare_v2(), execute it step-by-step using sqlite3_step(), and close it using sqlite3_finalize(), or you can reuse it using sqlite3_reset(). This process and the individual steps are all explained in detail in the following sections.
Compilation
Compilation, or preparation, takes a SQL statement and compiles it into byte code readable by the virtual database engine (VDBE). It is performed by sqlite3_prepare_v2(), which is declared as follows:
int sqlite3_prepare_v2(
sqlite3 *db, /* Database handle */
const char *zSql, /* SQL text, UTF-8 encoded */
int nBytes, /* Length of zSql in bytes. */
sqlite3_stmt **ppStmt, /* OUT: Statement handle */
const char **pzTail /* OUT: Pointer to unused portion of zSql */
);
sqlite3_prepare_v2() compiles the first SQL statement in the zSQL string (which can contain multiple SQL statements). It allocates all the resources necessary to execute the statement and associates it along with the byte code into a single statement handle (also referred to as simply a statement), designated by the out parameter ppStmt, which is a sqlite3_stmt structure. From the programmer's perspective, this structure is little more than an opaque handle used to execute a SQL statement and obtain its associated records. However, this data structure contains the command's byte code, bound parameters, B-tree cursors, execution context, and any other data sqlite3_step() needs to manage the state of the query during execution.
sqlite3_prepare_v2() does not affect the connection or database in any way. It does not start a transaction or get a lock. It works directly with the compiler, which simply prepares the query for execution. Statement handles are highly dependent on the database schema with which they were compiled. If another connection alters the database schema, between the time you prepare a statement and the time you actually run it, your prepared statement will expire. However, sqlite3_prepare_v2() is built to automatically attempt to recompile (re-prepare) your statement if possible and will do this silently if a schema change has invalidated your existing statement. If the schema has changed in such a way as to make recompilation impossible, your call to sqlite3_step() with the statement will lead to a SQLITE_SCHEMA error, which is discussed later in the section “Errors and the Unexpected.” At this point, you would need to examine the error associated with SQLITE_SCHEMA by using the sqlite3_errmsg() function.
Execution
Once you prepare the query, the next step is to execute it using sqlite3_step(), declared as follows:
int sqlite3_step(sqlite3_stmt *pStmt);
sqlite3_step() takes the statement handle and talks directly to the VDBE, which steps through its byte-code instructions one by one to carry out the SQL statement. On the first call to sqlite3_step(), the VDBE obtains the requisite database lock needed to perform the command. If it can't get the lock, sqlite3_step() will return SQLITE_BUSY, if there is no busy handler installed. If one is installed, it will call that handler instead.
For SQL statements that don't return data, the first call to sqlite3_step() executes the command in its entirety, returning a result code indicating the outcome. For SQL statements that do return data, such as select, the first call to sqlite3_step() positions the statement's B-tree cursor on the first record. Subsequent calls to sqlite3_step() position the cursor on subsequent records in the result set. sqlite3_step() returns SQLITE_ROW for each record in the set until it reaches the end, whereupon it returns SQLITE_DONE, indicating that the cursor has reached the end of the set.
![]() Note For those of you familiar with older versions of SQLite, these result codes are part of the more advanced—and some would say more correct—set of result codes that replace the legacy simple return values like
Note For those of you familiar with older versions of SQLite, these result codes are part of the more advanced—and some would say more correct—set of result codes that replace the legacy simple return values like SQLITE_ERROR. A full list of result codes and extended result codes is available at www.sqlite.org/c3ref/c_abort.html
All other API functions related to data access use the statement's cursor to obtain information about the current record. For example, the sqlite3_column_xxx() functions all use the statement handle, specifically its cursor, to fetch the current record's fields.
Finalization and Reset
Once the statement has reached the end of execution, it must be finalized. You can either finalize or reset the statement using one of the following functions:
int sqlite3_finalize(sqlite3_stmt *pStmt);
int sqlite3_reset(sqlite3_stmt *pStmt);
sqlite3_finalize() will close out the statement. It frees resources and commits or rolls back any implicit transactions (if the connection is in autocommit mode), clearing the journal file and freeing the associated lock.
If you want to reuse the statement, you can do so using sqlite3_reset(). It will keep the compiled SQL statement (and any bound parameters) but commits any changes related to the current statement to the database. It also releases its lock and clears the journal file if autocommit is enabled. The primary difference between sqlite3_finalize() and sqlite3_reset() is that the latter preserves the resources associated with the statement so that it can be executed again, avoiding the need to call sqlite3_
prepare() to compile the SQL command.
Let's go through an example. Listing 6-5 shows a simple, complete program using a prepared query. It is taken from select.c in the examples.
Listing 6-5. Using Prepared Queries
int main(int argc, char **argv)
{
int rc, i, ncols;
sqlite3 *db;
sqlite3_stmt *stmt;
char *sql;
const char *tail;
rc = sqlite3_open_v2("foods.db", &db);
if(rc) {
fprintf(stderr, "Can't open database: %s
", sqlite3_errmsg(db));
sqlite3_close(db);
exit(1);
}
sql = "select * from episodes;";
rc = sqlite3_prepare_v2(db, sql, -1, &stmt, &tail);
if(rc != SQLITE_OK) {
fprintf(stderr, "SQL error: %s
", sqlite3_errmsg(db));
}
rc = sqlite3_step(stmt);
ncols = sqlite3_column_count(stmt);
while(rc == SQLITE_ROW) {
for(i=0; i < ncols; i++) {
fprintf(stderr, "'%s' ", sqlite3_column_text(stmt, i));
}
fprintf(stderr, "
");
rc = sqlite3_step(stmt);
}
sqlite3_finalize(stmt);
sqlite3_close(db);
return 0;
}
This example connects to the foods.db database, queries the episodes table, and prints out all columns of all records within it. Keep in mind this is a simplified example—there are a few other things we need to check for when calling sqlite3_step(), such as errors and busy conditions, but we will address them later.
Like sqlite3_exec(), sqlite3_prepare_v2() can accept a string containing multiple SQL statements. However, unlike sqlite3_exec(), it will process only the first statement in the string. But it does make it easy for you to process subsequent SQL statements in the string by providing the pzTail out parameter. After you call sqlite3_prepare(), it will point this parameter (if provided) to the starting position of the next statement in the zSQL string. Using pzTail, processing a batch of SQL commands in a given string can be executed in a loop as follows:
while(sqlite3_complete(sql) ){
rc = sqlite3_prepare(db, sql, -1, &stmt, &tail);
/* Process query results */
/* Skip to next command in string. */
sql = tail;
}
This example uses another API function not yet covered—sqlite3_complete(), which does as its name suggests. It takes a string and returns true if there is at least one complete (but not necessarily valid) SQL statement in it, and it returns false otherwise. In reality, sqlite_complete() looks for a semicolon terminator for the string (and accounting for literals in the SQL). So, although its name suggests some kind of infallible observer checking your statements, it's really just a handy tool for things such as showing you the continuation prompt in the sqlite command line when writing multiline statements and doing other similar useful tasks.
Fetching Records
So far, you have seen how to obtain records and columns from sqlite3_exec() and sqlite3_get_table(). Prepared queries, by comparison, offer many more options when it comes to getting information from records in the database.
For a statement that returns records, the number of columns in the result set can be obtained using sqlite3_column_count() and sqlite3_data_count(), which are declared as follows:
int sqlite3_column_count(sqlite3_stmt *pStmt);
int sqlite3_data_count(sqlite3_stmt *pStmt);
sqlite3_column_count() returns the number of columns associated with a statement handle. You can call it on a statement handle before it is actually executed. If the query in question is not a select statement, sqlite3_column_count() will return 0. Similarly, sqlite3_data_count() returns the number of columns for the current record, after sqlite3_step() returns SQLITE_ROW. This function will work only if the statement handle has an active cursor.
Getting Column Information
You can obtain the name of each column in the current record using sqlite3_column_name(), which is declared as follows:
const char *sqlite3_column_name( sqlite3_stmt*, /* statement handle */
int iCol /* column ordinal */);
Similarly, you can get the associated storage class for each column using sqlite3_column_type(), which is declared as follows:
int sqlite3_column_type( sqlite3_stmt*, /* statement handle */
int iCol /* column ordinal */);
This function returns an integer value that corresponds to one of five storage class codes, defined as follows:
#define SQLITE_INTEGER 1
#define SQLITE_FLOAT 2
#define SQLITE_TEXT 3
#define SQLITE_BLOB 4
#define SQLITE_NULL 5<A NAME="50520099_sqlite3_column_name16">
These are SQLite's native data types, or storage classes, as described in Chapter 4. All data stored within a SQLite database is stored in one of these five forms, depending on its initial representation and the affinity of the column. For our purposes, the terms storage class and data type are synonymous. For more information on storage classes, see the sections “Storage Classes” and “Type Affinity” in Chapter 4.
You can obtain the declared data type of a column as it is defined in the table's schema using the sqlite3_column_decltype() function, which is declared as follows:
const char *sqlite3_column_decltype( sqlite3_stmt*, /* statement handle */
int /* column ordinal */);
If a column in a result set does not correspond to an actual table column (say, for example, the column is the result of a literal value, expression, function, or aggregate), this function will return NULL as the declared type of that column. For example, suppose you have a table in your database defined as follows:
Then you execute the following query:
SELECT c1 + 1, 0 FROM t1;
In this case, sqlite3_column_decltype() will return INTEGER for the first column and NULL for the second.
In addition to the declared type, you can obtain other information on a column using the following functions:
const char *sqlite3_column_database_name(sqlite3_stmt *pStmt, int iCol);
const char *sqlite3_column_table_name(sqlite3_stmt *pStmt, int iCol);
const char *sqlite3_column_origin_name(sqlite3_stmt *pStmt, int iCol);
The first function will return the database associated with a column, the second will return its table, and the last function will return the column's actual name as defined in the schema. That is, if you assigned the column an alias in the SQL statement, sqlite3_column_origin_name() will return its actual name as defined in the schema. Note that these functions are available only if you compile SQLite with the SQLITE_ENABLE_COLUMN_METADATA preprocessor directive.
Getting Column Values
You can obtain the values for each column in the current record using the sqlite3_column_xxx() functions, which are of the following general form:
xxx sqlite3_column_xxx( sqlite3_stmt*, /* statement handle */
int iCol /* column ordinal */);
Here xxx is the data type you want the data represented in (for example, int, blob, double, and so on). These are the most commonly used of the sqlite3_column_xxx() functions:
int sqlite3_column_int(sqlite3_stmt*, int iCol);
double sqlite3_column_double(sqlite3_stmt*, int iCol);
long long int sqlite3_column_int64(sqlite3_stmt*, int iCol);
const void *sqlite3_column_blob(sqlite3_stmt*, int iCol);
const unsigned char *sqlite3_column_text(sqlite3_stmt*, int iCol);
const void *sqlite3_column_text16(sqlite3_stmt*, int iCol);
For each function, SQLite converts the internal representation (storage class in the column) to the type specified in the function name. There are a number of rules SQLite uses to convert the internal data type representation to that of the requested type. Table 6-1 lists these rules.
Table 6-1. Column Type Conversion Rules
| Internal Type | Requested Type | Conversion |
NULL INTEGER |
Result is 0. | |
NULL FLOAT |
Result is 0.0. | |
NULL TEXT |
Result is a NULL pointer. |
|
NULL BLOB |
Result is a NULL pointer. |
|
INTEGER FLOAT |
Convert from integer to float. | |
INTEGER TEXT |
Result is the ASCII rendering of the integer. | |
INTEGER BLOB |
Result is the ASCII rendering of the integer. | |
FLOAT INTEGER |
Convert from float to integer. | |
FLOAT TEXT |
Result is the ASCII rendering of the float. | |
FLOAT BLOB |
Result is the ASCII rendering of the float. | |
TEXT INTEGER |
Use atoi(). |
|
TEXT FLOAT |
Use atof(). |
|
TEXT BLOB |
No change. | |
BLOB INTEGER |
Convert to TEXT and then use atoi(). |
|
BLOB FLOAT |
Convert to TEXT and then use atof(). |
|
BLOB TEXT |
Add a �00 terminator if needed. |
Like the sqlite3_bind_xxx() functions described later, BLOBs require a little more work in that you must specify their length in order to copy them. For BLOB columns, you can get the actual length of the data using sqlite3_column_bytes(), which is declared as follows:
int sqlite3_column_bytes( sqlite3_stmt*, /* statement handle */
int /* column ordinal */);
Once you get the length, you can copy the binary data using sqlite3_column_blob(). For example, say the first column in the result set contains binary data. One way to get a copy of that data would be as follows:
int len = sqlite3_column_bytes(stmt,0);
void* data = malloc(len);
memcpy(data, len, sqlite3_column_blob(stmt,0));
A Practical Example
To help solidify all these column functions, Listing 6-6 (taken from columns.c) illustrates using the functions we've described to retrieve column information and values for a simple select statement.
Listing 6-6. Obtaining Column Information
int main(int argc, char **argv)
{
int rc, i, ncols, id, cid;
char *name, *sql;
sqlite3 *db;
sqlite3_stmt *stmt;
sql = "select id, name from episodes";
sqlite3_open_v2("test.db", &db);
sqlite3_prepare_v2(db, sql, strlen(sql), &stmt, NULL);
ncols = sqlite3_column_count(stmt);
rc = sqlite3_step(stmt);
/* Print column information */
for(i=0; i < ncols; i++) {
fprintf(stdout, "Column: name=%s, storage class=%i, declared=%s
",
sqlite3_column_name(stmt, i),
sqlite3_column_type(stmt, i),
sqlite3_column_decltype(stmt, i));
}
fprintf(stdout, "
");
while(rc == SQLITE_ROW) {
id = sqlite3_column_int(stmt, 0);
cid = sqlite3_column_int(stmt, 1);
name = sqlite3_column_text(stmt, 2);
if(name != NULL){
fprintf(stderr, "Row: id=%i, cid=%i, name='%s'
", id,cid,name);
} else {
/* Field is NULL */
fprintf(stderr, "Row: id=%i, cid=%i, name=NULL
", id,cid);
}
rc = sqlite3_step(stmt);
}
sqlite3_finalize(stmt);
sqlite3_close(db);
return 0;
}
This example connects to the database, selects records from the episodes table, and prints the column information and the fields for each row (using their internal storage class). Running the program produces the following output:
Column: name=id, storage class=1, declared=integer
Column: name=name, storage class=3, declared=text
Row: id=1, name='The Dinner Party'
Row: id=2, name='The Soup Nazi'
Row: id=3, name='The Fusilli Jerry'
Parameterized Queries
The API includes support for designating parameters in a SQL statement, allowing you to provide (or “bind”) values for them at a later time. Bound parameters are used in conjunction with sqlite3_prepare(). For example, you could create a SQL statement like the following:
insert into foo values (?,?,?);
Then you can, for example, bind the integer value 2 to the first parameter (designated by the first ? character), the string value 'pi' to the second parameter, and the double value 3.14 for the third parameter, as illustrated in the following code (taken from parameters.c):
const char* sql = "insert into foo values(?,?,?)";
sqlite3_prepare(db, sql, strlen(sql), &stmt, &tail);
sqlite3_bind_int(stmt, 1, 2);
sqlite3_bind_text(stmt, 2, "pi");
sqlite3_bind_double(stmt, 3, 3.14);
sqlite3_step(stmt);
sqlite3_finalize(stmt);
This generates and executes the following statement:
insert into foo values (2, 'pi', 3.14)
This particular method of binding uses positional parameters (as described in Chapter 5) where each parameter is designated by a question mark (?) character and later identified by its index or relative position in the SQL statement.
Before delving into the other parameter methods, it is helpful to first understand the process by which parameters are defined, bound, and evaluated. When you write a parameterized statement such as the following, the parameters within it are identified when sqlite3_prepare() compiles the query:
insert into episodes (id,name) values (?,?)
sqlite3_prepare() recognizes that there are parameters in a SQL statement. Internally, it assigns each parameter a number to uniquely identify it. In the case of positional parameters, it starts with 1 for the first parameter found and uses sequential integer values for subsequent parameters. It stores this information in the resulting statement handle (sqlite3_stmt structure), which will then expect a specific number of values to be bound to the given parameters before execution. If you do not bind a value to a parameter, sqlite3_step() will use NULL for its value by default when the statement is executed.
After you prepare the statement, you then bind values to it. You do this using the sqlite3_bind_xxx() functions, which have the following general form:
sqlite3_bind_xxx( sqlite3_stmt*, /* statement handle */
int i, /* parameter number */
xxx value /* value to be bound */
);
The xxx in the function name represents the data type of the value to bind. For example, to bind a double value to a parameter, you would use sqlite3_bind_double(), which is declared as follows:
sqlite3_bind_double(sqlite3_stmt* stmt, int i, double value);
The common bind functions are as follows:
int sqlite3_bind_int(sqlite3_stmt*, int, int);
int sqlite3_bind_double(sqlite3_stmt*, int, double);
int sqlite3_bind_int64(sqlite3_stmt*, int, long long int);
int sqlite3_bind_null(sqlite3_stmt*, int);
int sqlite3_bind_blob(sqlite3_stmt*, int, const void*, int n, void(*)(void*));
int sqlite3_bind_zeroblob(sqlite3_stmt*, int, int n);
int sqlite3_bind_text(sqlite3_stmt*, int, const char*, int n, void(*)(void*));
int sqlite3_bind_text16(sqlite3_stmt*, int, const void*, int n, void(*)(void*));
In general, the bind functions can be divided into two classes, one for scalar values (int, double, int64, and NULL) and the other for arrays (blob, text, and text16). They differ only in that the array bind functions require a length argument and a pointer to a cleanup function. Also, sqlite3_bind_text() automatically escapes quote characters like sqlite3_mprintf(). Using the BLOB variant, the array bind function has the following declaration:
int sqlite3_bind_blob( sqlite3_stmt*, /* statement handle */
int, /* ordinal */
const void*, /* pointer to blob data */
int n, /* length (bytes) of data */
void(*)(void*)); /* cleanup hander */
There are two predefined values for the cleanup handler provided by the API that have special meanings, defined as follows:
#define SQLITE_STATIC ((void(*)(void *))0)
#define SQLITE_TRANSIENT ((void(*)(void *))-1)
Each value designates a specific cleanup action. SQLITE_STATIC tells the array bind function that the array memory resides in unmanaged space, so SQLite does not attempt to clean it up. SQLITE_TRANSIENT tells the bind function that the array memory is subject to change, so SQLite makes its own private copy of the data, which it automatically cleans up when the statement is finalized. The third option is to provide a pointer to your own cleanup function, which must be of the following form:
void cleanup_fn(void*)
If provided, SQLite will call your cleanup function, passing in the array memory when the statement is finalized.
![]() Note Bound parameters remain bound throughout the lifetime of the statement handle. They remain bound even after a call to
Note Bound parameters remain bound throughout the lifetime of the statement handle. They remain bound even after a call to sqlite3_reset() and are freed only when the statement is finalized (by calling sqlite3_finalize()).
Once you have bound all the parameters you want, you can then execute the statement. You do this using the next function in the sequence: sqlite3_step(). sqlite3_step() will take the bound values, substitute them for the parameters in the SQL statement, and then begin executing the command.
Now that you understand the binding process, the four parameter-binding methods differ only by the following:
- The way in which parameters are represented in the SQL statement (using a positional parameter, explicitly defined parameter number, or alphanumeric parameter name)
- The way in which parameters are assigned numbers
For positional parameters, sqlite3_prepare() assigns numbers using sequential integer values starting with 1 for the first parameter. In the previous example, the first ? parameter is assigned 1, and the second ? parameter is assigned 2. With positional parameters, it is your job to keep track of which number corresponds to which parameter (or question mark) in the SQL statement and correctly specify that number in the bind functions.
Numbered Parameters
Numbered parameters, on the other hand, allow you to specify your own numbers for parameters, rather than use an internal sequence. The syntax for numbered parameters uses a question mark followed by the parameter number. Take, for example, the following piece of code (taken from parameters.c):
name = "Mackinaw Peaches";
sql = "insert into episodes (id, cid, name) "
"values (?100,?100,?101)";
rc = sqlite3_prepare(db, sql, strlen(sql), &stmt, &tail);
if(rc != SQLITE_OK) {
fprintf(stderr, "sqlite3_prepare() : Error: %s
", tail);
return rc;
}
sqlite3_bind_int(stmt, 100, 10);
sqlite3_bind_text(stmt, 101, name, strlen(name), SQLITE_TRANSIENT);
sqlite3_step(stmt);
sqlite3_finalize(stmt);
This example uses 100 and 101 for its parameter numbers. Parameter number 100 has the integer value 10 bound to it. Parameter 101 has the string value 'Mackinaw Peaches' bound to it. Note how numbered parameters come in handy when you need to bind a single value in more than one place in a SQL statement. Consider the values part of the previous SQL statement:
insert into episodes (id, cid, name) values (?100,?100,?101)";
Parameter 100 is being used twice—once for id and again for cid. Thus, numbered parameters save time when you need to use a bound value in more than one place.
![]() Note When using numbered parameters in a SQL statement, keep in mind that the allowable range consists of the integer values 1–999, and for optimal performance and memory utilization, you should choose smaller numbers.
Note When using numbered parameters in a SQL statement, keep in mind that the allowable range consists of the integer values 1–999, and for optimal performance and memory utilization, you should choose smaller numbers.
Named Parameters
The third parameter binding method is using named parameters. Whereas you can assign your own numbers using numbered parameters, you can assign alphanumeric names with named parameters. Likewise, because numbered parameters are prefixed with a question mark (?), you identify named parameters by prefixing a colon (:) or at-sign (@) to the parameter name. Consider the following code snippet (taken from parameters.c):
name = "Mackinaw Peaches";
sql = "insert into episodes (id, cid, name) values (:cosmo,:cosmo,@newman)";
rc = sqlite3_prepare(db, sql, strlen(sql), &stmt, &tail);
sqlite3_bind_int( stmt,
sqlite3_bind_parameter_index(stmt, ":cosmo"), 10);
sqlite3_bind_text( stmt,
sqlite3_bind_parameter_index(stmt, "@newman"),
name,
strlen(name), SQLITE_TRANSIENT );
sqlite3_step(stmt);
sqlite3_finalize(stmt);
This example is identical to the previous example using numbered parameters, except it uses two named parameters called :cosmo and @newman instead. Like positional parameters, named parameters are automatically assigned numbers by sqlite3_prepare(). Although the numbers assigned to each parameter are unknown, you can resolve them using sqlite3_bind_parameter_index(), which takes
a parameter name and returns the corresponding parameter number. This is the number you use to bind the value to its parameter. All in all, named parameters mainly help with legibility more than anything else.
![]() Note While the function
Note While the function sqlite3_bind_parameter_index() seems to refer to a parameter number as an index, for all intents and purposes the two terms (number and index) are synonymous.
Tcl Parameters
The final parameter scheme is called Tcl parameters and is specific more to the Tcl extension than it is to the C API. Basically, it works identically to named parameters except that rather than using alphanumeric values for parameter names, it uses Tcl variable names. In the Tcl extension, when the Tcl equivalent of sqlite3_prepare() is called, the Tcl extension automatically searches for Tcl variables with the given parameter names in the active Tcl program environment and binds them to their respective parameters. Despite its current application in the Tcl interface, nothing prohibits this same mechanism from being applied to other language interfaces, which can in turn implement the same feature. In this respect, referring to this parameter method solely as Tcl parameters may be a bit of a misnomer. The Tcl extension just happened to be the first application that utilized this method. Basically, the Tcl parameter syntax does little more than provide an alternate syntax to named parameters—rather than prefixing the parameters with a colon (:) or an at-sign (@), it uses a dollar sign ($).
Errors and the Unexpected
Up to now, we have looked at the API from a rather optimistic viewpoint, as if nothing could ever go wrong. But things do go wrong, and there is part of the API devoted to that. The three things you always have to guard against in your code are errors, busy conditions, and, my personal favorite, schema changes.
Handling Errors
Many of the API functions return integer result codes. That means they can potentially return error codes of some sort. The most common functions to watch are typically the most frequently used, such as sqlite3_open_v2(), sqlite3_prepare_v2(), and friends, as well as sqlite3_exec(). You should always program defensively and review every API function before you use it to ensure that you deal with error conditions that can arise. Of all the error results defined in SQLite, only a fraction of them will really matter to your application in practice. All of the SQLite result codes are listed in Table 6-2. API functions that can return them include the following:
sqlite3_bind_xxx()
sqlite3_close()
sqlite3_create_collation()
sqlite3_collation_needed()
sqlite3_create_function()
sqlite3_prepare_v2()
sqlite3_exec()
sqlite3_finalize()
sqlite3_get_table()
sqlite3_open_v2()
sqlite3_reset()
sqlite3_step()
You can get extended information on a given error using sqlite3_errmsg(), which is declared as follows:
const char *sqlite3_errmsg(sqlite3*);
It takes a connection handle as its only argument and returns the most recent error resulting from an API call on that connection. If no error has been encountered, it returns the string “not an error.”
Table 6-2. SQLite Result Codes
Although it is very uncommon outside of embedded systems, one of the most critical errors you can encounter is SQLITE_NOMEM, which means that no memory can be allocated on the heap (for example, malloc() failed). SQLite is quite robust in this regard, recovering gracefully from out-of-memory error conditions. It will continue to work assuming the underlying operating system completes memory allocation system calls like malloc().
Handling Busy Conditions
Two important functions related to processing queries are sqlite3_busy_handler() and sqlite3_busy_timeout(). If your program uses a database on which there are other active connections, odds are it will eventually have to wait for a lock and therefore will have to deal with SQLITE_BUSY. Whenever you call an API function that causes SQLite to seek a lock and SQLite is unable to get it, the function will return SQLITE_BUSY. There are three ways to deal with this:
- Handle
SQLITE_BUSYyourself, either by rerunning the statement or by taking some other action - Have SQLite call a busy handler
- Ask SQLite to wait (block or sleep) for some period of time for the lock to clear
The last option involves using sqlite3_busy_timeout(). This function tells SQLite how long to wait for a lock to clear before returning SQLITE_BUSY. Although it can ultimately result in you still having to handle SQLITE_BUSY, in practice setting this value to a sufficient period of time (say 30 seconds) usually provides enough time for even the most intensive transaction to complete. Nevertheless, you should still have some contingency plan in place to handle SQLITE_BUSY.
User-Defined Busy Handlers
The second option entails using sqlite3_busy_handler(). This function provides a way to call a user-defined function rather than blocking or returning SQLITE_BUSY right away. It's declared as follows:
int sqlite3_busy_handler(sqlite3*, int(*)(void*,int), void*);
The second argument is a pointer to a function to be called as the busy handler, and the third argument is a pointer to application-specific data to be passed as the first argument to the handler. The second argument to the busy handler is the number of prior calls made to the handler for the same lock.
Such a handler might call sleep() for a period to wait out the lock, or it may send some kind of notification. It may do whatever you like, because it is yours to implement. Be warned, though, that registering a busy handler does not guarantee that it will always be called. As mentioned in Chapter 5, SQLite will forego calling a busy handler for a connection if it perceives a deadlock might result. Specifically, if your connection in SHARED is interfering with another connection in RESERVED, SQLite will not invoke your busy handler, hoping you will take the hint. In this case, you are trying to write to the database from SHARED (starting the transaction with BEGIN) when you really should be starting from RESERVED (starting the transaction with BEGIN IMMEDIATE).
The only restriction on busy handlers is that they may not close the database. Closing the database from within a busy handler can delete critical data structures out from under the executing query and result in crashing your program.
Advice
All things considered, the best route may be to set the timeout to a reasonable value and then take some precautions if and when you receive a SQLITE_BUSY value. In general, if you are going to write to the database, start in RESERVED. If you don't do this, then the next best thing is to install a busy handler, set the timeout to a known value, and if SQLite returns SQLITE_BUSY, check the response time. If the time is less than the busy handler's delay, then SQLite is telling you that your query (and connection) is preventing a writer from proceeding. If you want to write to the database at this point, you should finalize or reset and then reexecute the statement, this time starting with BEGIN IMMEDIATE.
Handling Schema Changes
Whenever a connection changes the database schema, all other prepared statements that were compiled before the change are invalidated. The result is that the first call to sqlite3_step() for such statements will attempt to recompile the relevant SQL and proceed normally from there if possible. If recompilation is impossible (for example, if an object has been dropped entirely), the sqlite3_step() returns SQLITE_SCHEMA. From a locking standpoint, the schema change occurs between the time a reader calls sqlite3_prepare() to compile a statement and calling sqlite3_step() to execute it.
When this happens, the only course of action for you is to handle the change in circumstances and start over. Several events can cause SQLITE_SCHEMA errors:
- Detaching databases
- Modifying or installing user-defined functions or aggregates
- Modifying or installing user-defined collations
- Modifying or installing authorization functions
- Vacuuming the database
The reason the SQLITE_SCHEMA condition exists ultimately relates to the VDBE. When a connection changes the schema, other compiled queries may have VDBE code that points to database objects that no longer exist or are in a different location in the database. Rather than running the risk of a bizarre runtime error later, SQLite invalidates all statements that have been compiled but not executed. They must be recompiled.
Operational Control
The API provides several functions you can use to monitor and/or manage SQL commands at compile time and runtime. These functions allow you to install callback functions with which to monitor and control various database events as they happen.
Commit Hooks
The sqlite3_commit_hook() function allows you to monitor when transactions commit on a given connection. It is declared as follows:
void *sqlite3_commit_hook( sqlite3 *cnx, /* database handle */
int(*xCallback)(void *data), /* callback function */
void *data); /* application data */
This function registers the callback function xCallback, which will be invoked whenever a transaction commits on the connection given by cnx. The third argument (data) is a pointer to application-specific data, which SQLite passes to the callback function. If the callback function returns a nonzero value, then the commit is converted into a rollback.
Passing a NULL value in for the callback function effectively disables the currently registered callback (if any). Also, only one callback can be registered at a time for a given connection. The return value for sqlite3_commit_hook() is NULL unless another callback function was previously registered, in which case the previous data value is returned.
Rollback Hooks
Rollback hooks are similar to commit hooks except that they watch for rollbacks for a given connection. Rollback hooks are registered with the following function:
void *sqlite3_rollback_hook(sqlite3 *cnx, void(*xCallback)(void *data), void *data);
This function registers the callback function xCallback, which will be invoked in the event of a rollback on cnx, whether by an explicit ROLLBACK command or by an implicit error or constraint violation. The callback is not invoked if a transaction is automatically rolled back because of the database connection being closed. The third argument (data) is a pointer to application-specific data, which SQLite passes to the callback function.
As in sqlite3_commit_hook(), each time you call sqlite3_rollback_hook(), the new callback function you provide will replace any currently registered callback function. If a callback function was previously registered, sqlite3_rollback_hook() returns the previous data argument.
Update Hooks
The sqlite3_update_hook() is used to monitor all update, insert, and delete operations on rows for a given database connection. It has the following form:
void *sqlite3_update_hook(
sqlite3 *cnx,
void(*)(void *, int, char const*, char const*, sqlite_int64),
void *data);
The first argument of the callback function is a pointer to application-specific data, which you provide in the third argument. The callback function has the following form:
void callback ( void * data,
int operation_code,
char const *db_name,
char const *table_name,
sqlite_int64 rowid),
The operation_code argument corresponds to SQLITE_INSERT, SQLITE_UPDATE, and SQLITE_DELETE for insert, update, and delete operations, respectively. The third and fourth arguments correspond to the database name and table name the operation took place on. The final argument is the rowid of the affected row. The callback is not invoked for operations on system tables (for example, sqlite_master and sqlite_sequence). The return value is a pointer to the previously registered callback function's data argument, if it exists.
Authorizer Functions
Perhaps the most powerful event filter is sqlite3_set_authorizer(). It allows you to monitor and control queries as they are compiled. This function is declared as follows:
int sqlite3_set_authorizer(
sqlite3*,
int (*xAuth)( void*,int,
const char*, const char*,
const char*,const char*),
void *pUserData
);
This routine registers a callback function that serves as an authorization function. SQLite will invoke the callback function at statement compile time (not at execution time) for various database events. The intent of the function is to allow applications to safely execute user-supplied SQL. It provides a way to restrict such SQL from certain operations (for example, anything that changes the database) or to deny access to specific tables or columns within the database.
For clarity, the form of the authorization callback function is as follows:
int auth( void*, /* user data */
int, /* event code */
const char*, /* event specific */
const char*, /* event specific */
const char*, /* database name */
const char* /* trigger or view name */ );
The first argument is a pointer to application-specific data, which is passed in on the fourth argument of sqlite3_set_authorizer(). The second argument to the authorization function will be one of the defined constants listed in Table 6-3. These values signify what kind of operation is to be authorized. The third and fourth arguments to the authorization function are specific to the event code. These arguments are listed with their respective event codes shown earlier in Table 6-2.
The fifth argument is the name of the database (main, temp, and so on) if applicable. The sixth argument is the name of the innermost trigger or view that is responsible for the access attempt or NULL if this access attempt is directly from top-level SQL.
The return value of the authorization function should be one of the constants SQLITE_OK, SQLITE_DENY, or SQLITE_IGNORE. The meaning of the first two values is consistent for all events—permit or deny the SQL statement. SQLITE_DENY will abort the entire SQL statement and generate an error.
The meaning of SQLITE_IGNORE is specific to the event in question. Statements that read or modify records generate SQLITE_READ or SQLITE_UPDATE events for each column the statement attempts to operate on. In this case, if the callback returns SQLITE_IGNORE, the column in question will be excluded from the operation. Specifically, attempts to read data from this column yield only NULL values, and attempts to update it will silently fail.
Table 6-3. SQLite Authorization Events
To illustrate this, the following example (the complete source of which is in authorizer.c) will create a table foo, defined as follows:
create table foo(x int, y int, z int)
It registers an authorizer function, which will do the following:
- Block reads of column
z - Block updates to column
x - Monitor
ATTACHandDETACHdatabase events - Log database events as they happen
This is a rather long example, which uses the authorizer function to filter many different database events, so for clarity I am going to break the code into pieces. The authorizer function has the general form shown in Listing 6-7.
Listing 6-7. Example Authorizer Function
int auth( void* x, int type,
const char* a, const char* b,
const char* c, const char* d )
{
const char* operation = a;
printf( " %s ", event_description(type));
/* Filter for different database events
** from SQLITE_TRANSACTION to SQLITE_INSERT,
** UPDATE, DELETE, ATTACH, etc. and either allow or deny
** them.
*/
return SQLITE_OK;
}
The first thing the authorizer looks for is a change in transaction state. If it finds a change, it prints a message:
if((a != NULL) && (type == SQLITE_TRANSACTION)) {
printf(": %s Transaction", operation);
}
Next the authorizer filters events that result in a schema change:
switch(type) {
case SQLITE_CREATE_INDEX:
case SQLITE_CREATE_TABLE:
case SQLITE_CREATE_TRIGGER:
case SQLITE_CREATE_VIEW:
case SQLITE_DROP_INDEX:
case SQLITE_DROP_TABLE:
case SQLITE_DROP_TRIGGER:
case SQLITE_DROP_VIEW:
{
// Schema has been modified somehow.
printf(": Schema modified");
}
The next filter looks for read attempts (which are fired on a column-by-column basis). Here, all read attempts are allowed unless the column name is z, in which case the function returns SQLITE_IGNORE. This will cause SQLite to return NULL for any field in column z, effectively blocking access to its data.
if(type == SQLITE_READ) {
printf(": Read of %s.%s ", a, b);
/* Block attempts to read column z */
if(strcmp(b,"z")==0) {
printf("-> DENIED
");
return SQLITE_IGNORE;
}
}
Next come insert and update filters. All insert statements are allowed. However, update statements that attempt to modify column x are denied. This will not block the update statement from executing; rather, it will simply filter out any attempt to update column x.
if(type == SQLITE_INSERT) {
printf(": Insert records into %s ", a);
}
if(type == SQLITE_UPDATE) {
printf(": Update of %s.%s ", a, b);
/* Block updates of column x */
if(strcmp(b,"x")==0) {
printf("-> DENIED
");
return SQLITE_IGNORE;
}
}
Finally, the authorizer filters delete, attach, and detach statements and simply issues notifications when it encounters them:
if(type == SQLITE_DELETE) {
printf(": Delete from %s ", a);
}
if(type == SQLITE_ATTACH) {
printf(": %s", a);
}
if(type == SQLITE_DETACH) {
printf("-> %s", a);
}
printf("
");
return SQLITE_OK;
}
The (abbreviated) program is implemented as follows. As with the authorizer function, I will break it into pieces. The first part of the program connects to the database and registers the authorization function:
int main(int argc, char **argv)
{
sqlite3 *db, *db2;
char *zErr, *sql;
int rc;
/** Setup */
/* Connect to test.db */
rc = sqlite3_open_v2("test.db", &db);
/** Authorize and test
/* 1. Register the authorizer function */
sqlite3_set_authorizer(db, auth, NULL);
Step 2 illustrates the transaction filter:
/* 2. Test transactions events */
printf("program : Starting transaction
");
sqlite3_exec(db, "BEGIN", NULL, NULL, &zErr);
printf("program : Committing transaction
");
sqlite3_exec(db, "COMMIT", NULL, NULL, &zErr);
Step 3 tests schema modifications by creating the test table foo:
/* 3. Test table events */
printf("program : Creating table
");
sqlite3_exec(db, "create table foo(x int, y int, z int)", NULL, NULL, &zErr);
Step 4 tests read (select) and write (insert/update) control. It inserts a test record, selects it, updates it, and selects it again to observe the results of the update.
/* 4. Test read/write access */
printf("program : Inserting record
");
sqlite3_exec(db, "insert into foo values (1,2,3)", NULL, NULL, &zErr);
printf("program : Selecting record (value for z should be NULL)
");
print_sql_result(db, "select * from foo");
printf("program : Updating record (update of x should be denied)
");
sqlite3_exec(db, "update foo set x=4, y=5, z=6", NULL, NULL, &zErr);
printf("program : Selecting record (notice x was not updated)
");
print_sql_result (db, "select * from foo");
printf("program : Deleting record
");
sqlite3_exec(db, "delete from foo", NULL, NULL, &zErr);
printf("program : Dropping table
");
sqlite3_exec(db, "drop table foo", NULL, NULL, &zErr);
Several things are going on here. The program selects all records in the table, one of which is column z. We should see in the output that column z's value is NULL. All other fields should contain data from the table. Next, the program attempts to update all fields, the most important of which is column x. The update should succeed, but the value in column x should be unchanged, because the authorizer denies it. This is confirmed on the following select statement, which shows that all columns were updated except for column x, which is unchanged. The program then drops the foo table, which should issue a schema change notification from the previous filter.
Step 5 tests the attach and detach database commands. The thing to notice here is how the authorizer function is provided with the name of the database and that you can distinguish the operations being performed under the attached database as opposed to the main database.
/* 5. Test attach/detach */
/* Connect to test2.db */
rc = sqlite3_open_v2("test2.db", &db2);
if(rc) {
fprintf(stderr, "Can't open database: %s
", sqlite3_errmsg(db2));
sqlite3_close(db2);
exit(1);
}
sqlite3_exec(db2, "drop table foo2", NULL, NULL, &zErr);
sqlite3_exec(db2, "create table foo2(x int, y int, z int)",
NULL, NULL, &zErr);
printf("program : Attaching database test2.db
");
sqlite3_exec(db, "attach 'test2.db' as test2", NULL, NULL, &zErr);
printf("program : Selecting record from attached database test2.db
");
sqlite3_exec(db, "select * from foo2", NULL, NULL, &zErr);
printf("program : Detaching table
");
sqlite3_exec(db, "detach test2", NULL, NULL, &zErr);
Again for clarity, I will break up the program output into pieces. Upon executing it, the first thing we see is the transaction filter catching changes in transaction state:
program : Starting transaction
SQLITE_TRANSACTION : BEGIN Transaction
program : Committing transaction
SQLITE_TRANSACTION : COMMIT Transaction
program : Starting transaction
SQLITE_TRANSACTION : BEGIN Transaction
program : Aborting transaction
SQLITE_TRANSACTION : ROLLBACK Transaction
Next we see a schema change notification as the result of creating the test table foo. The interesting thing to notice here is all the other events that transpire in the sqlite_master table as a result of creating the table:
program : Creating table
SQLITE_INSERT : Insert records into sqlite_master
SQLITE_CREATE_TABLE : Schema modified
SQLITE_READ : Read of sqlite_master.name
SQLITE_READ : Read of sqlite_master.rootpage
SQLITE_READ : Read of sqlite_master.sql
SQLITE_UPDATE : Update of sqlite_master.type
SQLITE_UPDATE : Update of sqlite_master.name
SQLITE_UPDATE : Update of sqlite_master.tbl_name
SQLITE_UPDATE : Update of sqlite_master.rootpage
SQLITE_UPDATE : Update of sqlite_master.sql
SQLITE_READ : Read of sqlite_master.ROWID
SQLITE_READ : Read of sqlite_master.name
SQLITE_READ : Read of sqlite_master.rootpage
SQLITE_READ : Read of sqlite_master.sql
SQLITE_READ : Read of sqlite_master.tbl_name
Next the program inserts a record, which the authorizer detects:
program : Inserting record
SQLITE_INSERT : Insert records into foo
This is where things get more interesting. We are going to be able to see the authorizer block access to individual columns. The program selects all records from the foo table. We see the SQLITE_SELECT event take place, followed by the subsequent SQLITE_READ events generated for each attempted access of each column in the select statement. When it comes to column z, the authorizer denies access. Immediately following that, SQLite executes the statement, and print_sql_result() prints the column information and rows for the result set:
program : Selecting record (value for z should be NULL)
SQLITE_SELECT
SQLITE_READ : Read of foo.x
SQLITE_READ : Read of foo.y
SQLITE_READ : Read of foo.z -> DENIED
Column: x (1/int)
Column: y (1/int)
Column: z (5/(null))
Record: '1' '2' '(null)'
Look at what goes on with column z. Its value is NULL, which confirms that the authorizer blocked access. But also look at the column information. Although SQLite revealed the storage class of column z, it denied access to its declared type in the schema.
Next comes the update. Here we are interested in column x. The update statement will attempt to change every value in the record. But an update of column x will be denied:
program : Updating record (update of x should be denied)
SQLITE_UPDATE : Update of foo.x -> DENIED
SQLITE_UPDATE : Update of foo.y
SQLITE_UPDATE : Update of foo.z
To confirm this, the program then selects the record to show what happened. The update did execute, but column x was not changed. Even more interestingly, while z was updated (trust me, it was), the authorizer will not let us see its value:
program : Selecting record (notice x was not updated)
SQLITE_SELECT
SQLITE_READ : Read of foo.x
SQLITE_READ : Read of foo.y
SQLITE_READ : Read of foo.z -> DENIED
Column: x (1/int)
Column: y (1/int)
Column: z (5/(null))
Record: '1' '5' '(null)'
Next the program deletes the record and drops the table. The latter operation generates all sorts of events on the sqlite_master table, just like when the table was created:
program : Deleting record
SQLITE_DELETE : Delete from foo
program : Dropping table
SQLITE_DELETE : Delete from sqlite_master
SQLITE_DROP_TABLE : Schema modified
SQLITE_DELETE : Delete from foo
SQLITE_DELETE : Delete from sqlite_master
SQLITE_READ : Read of sqlite_master.tbl_name
SQLITE_READ : Read of sqlite_master.type
SQLITE_UPDATE : Update of sqlite_master.rootpage
SQLITE_READ : Read of sqlite_master.rootpage
Finally, the program creates another database on a separate connection and then attaches it on the main connection. The main connection then selects records from a table in the attached database, and we can see how the authorizer reports these operations as happening in the attached database:
program : Attaching database test2.db
SQLITE_ATTACH : test2.db
SQLITE_READ : Read of sqlite_master.name
SQLITE_READ : Read of sqlite_master.rootpage
SQLITE_READ : Read of sqlite_master.sql
program : Selecting record from attached database test2.db
SQLITE_SELECT
SQLITE_READ : Read of foo2.x
SQLITE_READ : Read of foo2.y
SQLITE_READ : Read of foo2.z -> DENIED
program : Detaching table
SQLITE_DETACH -> test2
As you can see, sqlite3_set_authorizer() and its event-filtering capabilities are quite powerful. It gives you a great deal of control over what the user can and cannot do on a given database. You can monitor events and, if you want, stop them before they happen. Or, you can allow them to proceed but impose specific restrictions on them. sqlite3_set_authorizer() can be a helpful tool for dealing with SQLITE_SCHEMA conditions. If you know you don't need any changes to your database schema in your application, you can simply install an authorizer function to deny any operations that attempt to modify the schema in certain ways.
![]() Caution Keep in mind that denying schema changes in an authorizer is by no means a cure-all for
Caution Keep in mind that denying schema changes in an authorizer is by no means a cure-all for SQLITE_SCHEMA events. You need to be careful about all the implications of denying various changes to the schema. Just blindly blocking all events resulting in a schema change can restrict other seemingly legitimate operations such as VACUUM.
Threads
SQLite has enjoyed threading support for many releases. Although normal defensive coding techniques in multithreaded code apply to SQLite as well, there are a few additional precautions to take.
One limitation that is somewhat thread-related pertains to the fork() system call on Unix. You should never try to pass a connection across a fork() call to a child process. It will not work correctly.
Shared Cache Mode
Starting with SQLite version 3.3.0, SQLite supports something called shared cache mode, which allows multiple connections in a single process to use a common page cache, as shown in Figure 6-1. This feature is designed for embedded servers where a single thread can efficiently manage multiple database connections on behalf of other threads. The connections in this case share a single page cache as well as a different concurrency model. Because of the shared cache, the server thread can operate with significantly lower memory usage and better concurrency than if each thread were to manage its own connection. Normally, each connection allocates enough memory to hold 2,000 pages in the page cache. Rather than each thread consuming that much memory with its own connection, it shares that memory with other threads using a single page cache.
In this model, threads rely on a server thread to manage their database connections for them. A thread sends SQL statements to the server through some communication mechanism; the server executes them using the thread's assigned connection and then sends the results back. The thread can still issue commands and control its own transactions; only its actual connection exists in, and is managed by, another thread.
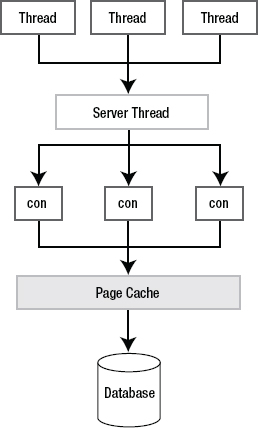
Figure 6-1. The shared cache model
Connections in shared cache mode use a different concurrency model and isolation level. Furthermore, an option exists to allow connections in a shared cache can see what their kindred connections have changed. If the pragma read_committed is set to true, this kind of change inspection is possible. That is, there can be both multiple readers and an active writer in the database at the same time. That writer can write to the database—performing complete write transactions—without having to wait for other readers to clear. Therefore, data can change in the database within a reader's transaction. Although SQLite normally runs in a serialized isolation level, meaning that readers and writers always see a consistent view of the database, in shared cache mode, readers are subject to the database changing underneath them.
There are some control measures in place to keep connections out of one another's way. By default, shared cache mode uses table locks to keep reader connections and writer connections separated. Table locks are not the same as database locks and exist only within connections of the shared cache. Whenever a connection reads a table, SQLite first tries to get a read lock on it. The same is true for writing to a table. A connection may not write to a table that another connection has a read lock on, and vice versa. Furthermore, table locks are tied to their respective connection and last for the duration of its transaction.
Read Uncommitted Isolation Level
Although table locks help keep connections in shared cache mode out of one another's way, it is possible for connections to elect not to be in the way at all. That is, a connection can choose to have a read-uncommitted isolation level by using the read_uncommitted pragma. If it is set to true, then the connection will not put read locks on the tables it reads. Therefore, another writer can actually change a table as the connection reads it. This can lead to inconsistent query results, but it also means that a connection in read-uncommitted mode can neither block nor be blocked by any other connections.
Some large changes have happened as of version 3.7 of SQLite, with the introduction of Write-Ahead Log mode. We'll cover Write-Ahead Logging in detail in Chapter 11.
Unlock Notification
If the thought of operating in the wilds of read-uncommitted isolation doesn't appeal to you, SQLite provides for an alternative where shared cache mode is in use. Recent versions of SQLite have included the sqlite3_unlock_notify() function to provide additional flexibility in locking situations. The function profile looks as follows:
int sqlite3_unlock_notify(
sqlite3 *pBlocked, /* Waiting connection */
void (*xNotify)(void **apArg, int nArg), /* Callback function to invoke */
void *pNotifyArg /* Argument to pass to xNotify */
)
If your code encounters a failure to gain a shared lock because of a contending lock, SQLITE_LOCKED will be returned. At this point, you can call sqlite3_unlock_notify() to allow registering of your callback function xNotify (the second parameter) with any desired parameters to that function (access via the pNotifyArg pointer as the third parameter) against your blocked connection (the first parameter).
The connection that holds the blocking lock will trigger the xNotify callback as part of the sqlite3_step() or sqlite3_close() call that completes its transaction. It is also possible, particularly within a multithreaded application, that in the time it takes you to invoke sqlite3_unlock_notify(), the competing transaction will have completed. In this case, your callback function will be initiated immediately from within sqlite3_unlock_notify().
There are some caveats to the use of sqlite3_unlock_notify(), including the following:
- You can register only one unlock/notify callback per blocked connection (newer calls replace any existing callback).
sqlite3_unlock_notify()is not reentrant, meaning you should not include other SQLite function calls in your callback function. You're likely to crash your application.- Special care must be taken if you plan to use with
drop tableordrop index commands. Because these can be “blocked” byselect statements, there is no real blocking transaction to include as thepBlockedparameter. Refer to the details on the SQLite web site for using the extended return codes to detect and handle this scenario atwww.sqlite.org/c3ref/unlock_notify.html.
Threads and Memory Management
Since shared cache mode is about conserving memory, SQLite has several functions associated with threads and memory management. They allow you to specify an advisory heap limit—a soft heap limit—as well as manually initiate memory cleanups. These functions are as follows:
void sqlite3_soft_heap_limit(int N);
int sqlite3_release_memory(int N);
The sqlite3_soft_heap_limit() function sets the current soft heap limit of the calling thread to N bytes. If the thread's heap usage exceeds N, then SQLite automatically calls sqlite3_release_memory(), which attempts to free at least N bytes of memory from the caches of all database connections associated with the calling thread. The return value of sqlite3_release_memory() is the number of bytes actually freed.
These routines are no-ops unless you have enabled memory management by compiling SQLite with the SQLITE_ENABLE_MEMORY_MANAGEMENT preprocessor directive.
Summary
The core C API contains everything you need to process SQL commands and then some. It contains a variety of convenient query methods that are useful in different ways. These include sqlite3_exec() and sqlite3_get_table(), which allow you to execute commands in a single function call. The API includes many utility functions as well, allowing you to determine the number of affected records in a query, get the last inserted ROWID of an INSERT statement, trace SQL commands run on a connection, and conveniently format strings for SQL statements.
The sqlite3_prepare_v2(), sqlite3_step(), and sqlite3_finalize() methods provide you with a lot of flexibility and control over statement execution through the use of statement handles. Statement handles provide more detailed row and column information, the convenience of bound parameters, and the ability to reuse prepared statements, avoiding the overhead of query compilation.
SQLite provides a variety of ways to manage runtime events through the use of event filters. Its commit, rollback, and update hooks allow you to monitor and control specific changes in database state. You can watch changes to rows and columns as they happen and use an authorizer function to monitor and restrict what queries can do as they are compiled.
And believe it or not, you've seen only half of the API! Actually, you've seen more like three-quarters, but you are likely to find that what is in the next chapter—user-defined functions, aggregates, and collations—is every bit as useful and interesting as what is in this one.