
C H A P T E R 7
![]()
The Extension C API
This chapter is about teaching SQLite new tricks. The previous chapter dealt with generic database work; this chapter is about being creative. The Extension API offers several basic ways to extend or customize SQLite, through the creation of user-defined functions, aggregates, collation sequences, and virtual tables. At a lower level, many more options present themselves, including interchangeable VFSs, start-time changeable page cache, and malloc and mutex implementation. We'll cover the first three options in this chapter: functions, aggregates, and collation sequences.
User-defined functions are SQL functions that map to some implementation that you write. They are callable from within SQL. For example, you could create a function hello_newman() that returns the string 'Hello Jerry' and, once it is registered, call it from SQL as follows:
sqlite > select hello_newman() as reply;
reply
------------------
'Hello Jerry'
This is a special version of the SQLite command-line program we've customized that includes hello_newman().
Aggregates are a special form of function and work in much the same way except that they operate on sets of records and return aggregated values or expressions computed over a particular column in the set. Or they may be computed from multiple columns. Standard aggregates that are built into SQLite include SUM(), COUNT(), and AVG(), for example.
Collations are methods of comparing and sorting text. That is, given two strings, a collation would decide which one is greater or whether the two are equal. The default collation in SQLite is BINARY—it compares strings byte by byte using memcmp(). Although this collation happens to work well for words in the English language (and other languages that use UTF-8 encoding), it doesn't necessarily work so well for other languages that use different encodings. Thus, SQLite includes the ability to build your own user-defined collations to better handle those alternative languages.
This chapter covers each of these three user-defined extension facilities and their associated API functions. As you will see, the user-defined extensions API can prove to be a powerful tool for creating nontrivial features that extend SQLite.
All of the code in this chapter is included in examples that you can obtain online from the Apress web site (www.apress.com). The examples for this particular chapter are located in the ch7 subdirectory of the examples folder. We will specifically point out all the source files corresponding to the examples as they are introduced in the text. Some of the error-checking code in the figures has been taken out for the sake of clarity.
Also, many examples in this chapter use simple convenience functions from a common library written to help simplify the examples. We will point out these functions and explain what they do as they are introduced in the text. The common code is located in the common subdirectory of the examples folder and must first be built before the examples are built. Please refer to the README file in the examples folder for details on building the common library.
Finally, to clear up any confusion, the terms storage class and data type are interchangeable. You know that SQLite stores data internally using five different data types, or storage classes. These classes are INTEGER, FLOAT, TEXT, BLOB, and NULL, as described in Chapter 4. Throughout the chapter, we'll use the term that best fits the context. You'll generally see the term data type, because it's most broadly applicable and easier for readers from different backgrounds to follow. When speaking about how SQLite handles a specific value internally, the term storage class seems to work better. In either case, you can equate either term as describing a specific form or representation of data.
The API
The basic method for implementing functions, aggregates, and collations consists of implementing a callback function and then registering it in your program. Once registered, your functions can be used from SQL. Functions and aggregates use the same registration function and similar callback functions. Collation sequences, while using a separate registration function, are almost identical and can be thought of as a particular class of user-defined function.
The lifetime of user-defined aggregates, functions, and collations is transient. They are registered on a connection-by-connection basis; they are not stored in the database. It is up to you to ensure that your application loads your custom extensions and registers them on each connection. Sometimes you may find yourself thinking of your extensions in terms of stored procedures and completely forget about the fact that they don't actually reside in the database. Extensions exist in libraries, not in databases, and are restricted to the life of your program. If you don't grasp this concept, you may do something like try to create a trigger (which is stored in the database) that references your extensions (which aren't stored in the database) and then turn around and try to call it from the SQLite shell or from an application that knows nothing of your extensions. In this case, you will find that either it triggers an error or nothing happens. Extensions require your program to register them on each and every connection; otherwise, that connection's SQL syntax will know nothing about them.
Registering Functions
You can register functions and aggregates on a connection using sqlite3_create_function(), which is declared as follows:
int sqlite3_create_function(
sqlite3 *cnx, /* connection handle */
const char *zFunctionName, /* function/aggregate name in SQL */
int nArg, /* number of arguments. -1 = unlimited. */
int eTextRep, /* encoding (UTF8, 16, etc.) */
void *pUserData, /* application data, passed to callback */
void (*xFunc)(sqlite3_context*,int,sqlite3_value**),
void (*xStep)(sqlite3_context*,int,sqlite3_value**),
void (*xFinal)(sqlite3_context*)
);
int sqlite3_create_function16(
sqlite3 *cnx,
const void *zFunctionName,
int nArg,
int eTextRep,
void *pUserData,
void (*xFunc)(sqlite3_context*, int args, sqlite3_value**),
void (*xStep)(sqlite3_context*, int args, sqlite3_value**),
void (*xFinal)(sqlite3_context*)
);
As with our examples in the previous chapter, we've included both the UTF-8 and UTF-16 versions of this function to underscore that the SQLite API has functions that support both encodings. From now on, we will only refer to the UTF-8 versions for the sake of brevity.
The arguments for sqlite3_create_function() are defined as follows:
cnx: The database connection handle. Functions and aggregates are connection specific. They must be registered on the connection as it is opened in order to be used.zFunctionName: The function name as it will be called in SQL. Up to 255 bytes in length.nArg: The number of arguments expected by your function. SQLite will enforce this as the exact number of arguments that must be provided to the function. If you specify -1, SQLite will allow a variable number of arguments.- eTextRep: The preferred text encoding. Allowable values are
SQLITE_UTF8,SQLITE_UTF16,SQLITE_UTF16BE,SQLITE_UTF16LE, andSQLITE_ANY. This field is a hint to SQLite used only to help it choose between multiple implementations of the same function.SQLITE_ANYmeans “no preference.” In other words, the implementation works equally as well with any text encoding. When in doubt, useSQLITE_ANYhere. pUserData: Application-specific data. This data is made available through the callback functions specified inxFunc,xStep, andxFinalbelow. Unlike other functions, which receive the data as a void pointer in the argument list, these functions must use a special API function to obtain this data.xFunc: The function callback. This is the actual implementation of the SQL function. Functions only provide this callback and leave thexStepandxFinalfunction pointersNULL. These latter two callbacks are exclusively for aggregate implementations.xStep: The aggregate step function. Each time SQLite processes a row in an aggregated result set, it callsxStepto allow the aggregate to process the relevant field value(s) of that row and include the result in its aggregate computation.xFinal: The aggregate finalize function. When all rows have been processed, SQLite calls this function to allow the aggregate to conclude its processing, which usually consists of computing the final value and optionally cleaning up.
You can register multiple versions of the same function differing only in the encoding (eTextRep argument) and/or the number of arguments (nArg argument), and SQLite will automatically select the best version of the function for the case in hand.
The Step Function
The function (callback) and aggregate step functions are identical and are declared as follows:
void fn(sqlite3_context* ctx, int nargs, sqlite3_value** values)
The ctx argument is the function/aggregate context. It holds state for a particular function call instance and is the means through which you obtain the application data (pUserData) argument provided in sqlite3_create_function(). The user data is obtained from the context using sqlite3_user_data(), which is declared as follows:
void *sqlite3_user_data(sqlite3_context*);
For functions, this data is shared among all calls to like functions, so it is not really unique to a particular instance of function call. That is, the same pUserData is passed or shared among all instances of a given function. Aggregates, however, can allocate their own state for each particular instance using sqlite3_aggregate_context(), declared as follows:
void *sqlite3_aggregate_context(sqlite3_context*, int nBytes);
The first time this routine is called for a particular aggregate, a chunk of memory of size nBytes is allocated, zeroed, and associated with that context. On subsequent calls with the same context (for the same aggregate instance), this allocated memory is returned. Using this, aggregates have a way to store state in between calls in order to accumulate data (which, when you think about it, is the general purpose for aggregating something). When the aggregate completes the final() callback, the memory is automatically freed by SQLite.
![]() Note One of the things you will see throughout the API is the use of user data in void pointers. Since many parts of the API involve callback functions, these simply serve as a convenient way to maintain state when implementing said callback functions.
Note One of the things you will see throughout the API is the use of user data in void pointers. Since many parts of the API involve callback functions, these simply serve as a convenient way to maintain state when implementing said callback functions.
The nargs argument of the callback function contains the number of arguments passed to the function.
Return Values
The values argument is an array of SQLite value structures that are handles to the actual argument values. The actual data for these values is obtained using the family of sqlite3_value_xxx() functions, which have the following form:
where xxx is the C data type to be returned from the value argument. If you read Chapter 6, you may be thinking that these functions have a striking resemblance to the sqlite3_column_xxx() family of functions—and you'd be right. They work in the same way, even down to the difference between the way scalar and array values are obtained. The functions for obtaining scalar values are as follows:
int sqlite3_value_int(sqlite3_value*);
sqlite3_int64 sqlite3_value_int64(sqlite3_value*);
double sqlite3_value_double(sqlite3_value*);
The functions used to obtain array values are as follows:
int sqlite3_value_bytes(sqlite3_value*);
const void *sqlite3_value_blob(sqlite3_value*);
const unsigned char *sqlite3_value_text(sqlite3_value*);
The sqlite3_value_bytes() function returns the amount of data in the value buffer for a BLOB. The sqlite3_value_blob() function returns a pointer to that data. Using the size and the pointer, you can then copy out the data. For example, if the first argument in your function was a BLOB and you wanted to make a copy, you would do something like this:
int len;
void* data;
len = sqlite3_value_bytes(values[0]);
data = sqlite3_malloc(len);
memcpy(data, sqlite3_value_blob(values[0]), len);
Just as the sqlite3_column_xxx() functions have sqlite_column_type() to provide the column types, the sqlite3_value_xxx() functions likewise have sqlite3_value_type(), which works in the same way. It is declared as follows:
int sqlite3_value_type(sqlite3_value*);
This function returns one of the following values, which correspond to SQLite's internal, storage classes (data types), defined as follows:
#define SQLITE_INTEGER 1
#define SQLITE_FLOAT 2
#define SQLITE_TEXT 3
#define SQLITE_BLOB 4
#define SQLITE_NULL 5
This covers the basic workings of the function/aggregate interface. We can now dive into some examples and practical applications. The Collation interface is so similar that it will be immediately understandable to you now that you've reviewed the interface for functions and aggregates.
Functions
Let's start our custom function development with a trivial example, one that is very easy to follow. Let's implement hello_newman(), but with a slight twist. We want to include using function arguments in the example, so hello_newman() will take one argument: the name of the person addressing him. It will work as follows:
sqlite > select hello_newman('Jerry') as reply;
reply
------------------
Hello Jerry
sqlite > select hello_newman('Kramer') as reply;
reply
------------------
Hello Kramer
sqlite > select hello_newman('George') as reply;
reply
------------------
Hello George
Listing 7-1 shows the basic program (taken from hello_newman.c). Some of the error-checking code has been removed for clarity.
Listing 7-1. The hello_newman() Test Program
int main(int argc, char **argv)
{
int rc; sqlite3 *db;
sqlite3_open_v2("test.db", &db);
sqlite3_create_function( db, "hello_newman", 1, SQLITE_UTF8, NULL,
hello_newman, NULL, NULL);
/* Log SQL as it is executed. */
log_sql(db,1);
/* Call function with one text argument. */
fprintf(stdout, "Calling with one argument.
");
print_sql_result(db, "select hello_newman('Jerry')");
/* Call function with two arguments.
** It will fail as we registered the function as taking only one argument.*/
fprintf(stdout, "
Calling with two arguments.
");
print_sql_result(db, "select hello_newman ('Jerry', 'Elaine')");
/* Call function with no arguments. This will fail too */
fprintf(stdout, "
Calling with no arguments.
");
print_sql_result(db, "select hello_newman()");
/* Done */
sqlite3_close(db);
return 0;
}
This program connects to the database, registers the function, and then calls it three times. The callback function is implemented as follows:
void hello_newman(sqlite3_context* ctx, int nargs, sqlite3_value** values)
{
const char *msg;
/* Generate Newman's reply */
msg = sqlite3_mprintf("Hello %s", sqlite3_value_text(values[0]));
/* Set the return value. Have sqlite clean up msg w/ sqlite_free(). */
sqlite3_result_text(ctx, msg, strlen(msg), sqlite3_free);
}
Running the program yields the following output:
Calling with one argument.
TRACE: select hello_newman('Jerry')
hello_newman('Jerry')
---------------------
Hello Jerry
Calling with two arguments.
execute() Error: wrong number of arguments to function hello_newman()
Calling with no arguments.
execute() Error: wrong number of arguments to function hello_newman()
The first call consists of just one argument. Since the example registered the function as taking exactly one argument, it succeeds. The second call attempts to use two arguments, which fails. The third call uses no arguments and also fails.
And there you have it: a SQLite extension function. This does bring up a few new functions that we have not addressed yet. We've created several helper functions for use with the book and to aid you in your SQLite work. You'll find these included for download on the Apress web site. Many of these functions' definitions can be found in the source file util.c. The function log_sql() simply calls sqlite3_trace(), passing in a tracing function that prefixes the traced SQL with the word TRACE. We use this so you can see what is happening in the example as the SQL is executed. The second function is print_sql_result(), which has the following declaration:
int print_sql_result(sqlite3 *db, const char* sql, ...)
This is a simple wrapper around sqlite3_prepare_v2() and friends that executes a SQL statement and prints the results.
Return Values
Our hello_newman() example introduces a new SQLite function: sqlite3_result_text().This function is just one of a family of sqlite_result_xxx() functions used to set return values for user-defined functions and aggregates. The scalar functions are as follows:
void sqlite3_result_double(sqlite3_context*, double);
void sqlite3_result_int(sqlite3_context*, int);
void sqlite3_result_int64(sqlite3_context*, long long int);
void sqlite3_result_null(sqlite3_context*);
These functions simply take a (second) argument of the type specified in the function name and set it as the return value of the function. The array functions are as follows:
void sqlite3_result_text(sqlite3_context*, const char*, int n, void(*)(void*));
void sqlite3_result_blob(sqlite3_context*, const void*, int n, void(*)(void*));
These functions take array data and set that data as the return value for the function. They have the following general form:
void sqlite3_result_xxx(
sqlite3_context *ctx, /* function context */
const xxx* value, /* array value */
int len, /* array length */
void(*free)(void*)); /* array cleanup function */
Here xxx is the particular array type—void for BLOBs or char for TEXT. Again, if you read Chapter 6, you may find these functions suspiciously similar to the sqlite3_bind_xxx() functions, which they are. Setting a return value for a function is, for all intents and purposes, identical to binding a value to a parameterized SQL statement. You could even perhaps refer to it as “binding a return value.”
Arrays and Cleanup Handlers
Just as in binding array values to SQL statements, these functions work in the same way as sqlite3_bind_xxx(). They require a pointer to the array, the length (or size) of the array, and a function pointer to a cleanup function. This cleanup function pointer can be assigned the same predefined meanings as in sqlite3_bind_xxx():
#define SQLITE_STATIC ((void(*)(void *))0)
#define SQLITE_TRANSIENT ((void(*)(void *))-1)
SQLITE_STATIC means that the array memory resides in unmanaged space, and therefore SQLite does not need to make a copy of the data for use, nor should it attempt to clean it up. SQLITE_TRANSIENT tells SQLite that the array data is subject to change, and therefore SQLite needs to make its own copy using sqlite3_malloc(). The allocated memory will be freed when the function returns. The third option is to pass in an actual function pointer to a cleanup function of the following form:
void cleanup(void*);
In this case, SQLite will call the cleanup function after the user-defined function completes. This is the method used in the previous example. We used sqlite3_mprintf() to generate Newman's reply, which allocated a string on the heap. We then passed in sqlite3_free() as the cleanup function to sqlite3_result_text(), which could free the string memory when the extension function completed.
Error Conditions
Sometimes functions encounter errors, in which case the return value should be set appropriately. This is what sqlite3_result_error() is for. It is declared as follows:
void sqlite3_result_error(
sqlite3_context *ctx, /* the function context */
const char *msg, /* the error message */
int len); /* length of the error message */
This tells SQLite that there was an error, the details of which are contained in msg. SQLite will abort the command that called the function and set the error message to the value contained in msg.
Returning Input Values
Sometimes, you may want to pass back an argument as the return value in the same form. Rather than you having to determine the argument's type, extract its value with the corresponding sqlite3_
column_xxx() function, and then turn right around and set the return value with the appropriate sqlite3_result_xxx() function, the API offers sqlite3_result_value() so you can do all of this in one fell swoop. It is declared as follows:
void sqlite3_result_value(
sqlite3_context *ctx, /* the function context */
sqlite3_value* value); /* the argument value */
For example, say you wanted to create a function echo() that spits back its first argument. The implementation is as follows:
void echo(sqlite3_context* ctx, int nargs, sqlite3_value** values)
{
sqlite3_result_value(ctx, values[0]);
}
It would work from SQL as follows:
sqlite > select echo('Hello Jerry') as reply;
reply
------------------
Hello Jerry
Even better, echo() works equally well with arguments of any storage class and returns them accordingly:
sqlite> select echo(3.14) as reply, typeof(echo(3.14)) as type;
reply type
---------- ----------
3.14 real
sqlite> select echo(X'0128') as reply, typeof(echo(X'0128')) as type;
reply type
---------- ----------
(? blob
sqlite> select echo(NULL) as reply, typeof(echo(NULL)) as type;
reply type
---------- ----------
null
Aggregates
Aggregates are only slightly more involved than functions. Whereas you had to implement only one callback function to do the work in user-defined functions, you have to implement both a step function to compute the ongoing value as well as a finalizing function to finish everything off and clean up. Figure 7-1 shows the general process. It still isn't hard, though. Like functions, one good example will be all you need to get the gist of it.
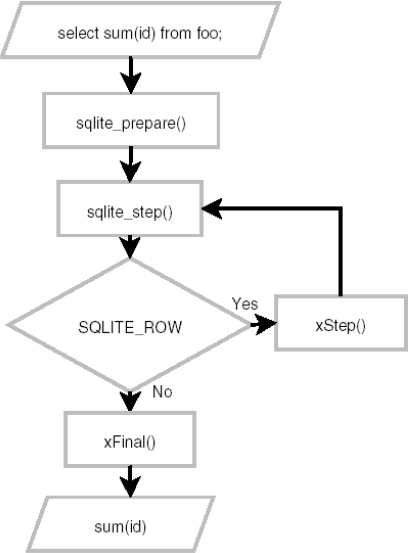
Figure 7-1. Query processing with aggregates
Registration Function
As mentioned before, aggregates and functions use the same registration function, sqlite3_create_function(), which is listed here again for convenience:
int sqlite3_create_function(
sqlite3 cnx*, /* connection handle */
const char *zFunctionName, /* function/aggregate name in SQL */
int nArg, /* number of arguments. -1 = unlimited. */
int eTextRep, /* encoding (UTF8, 16, etc.) */
void *pUserData, /* application data, passed to callback */
void (*xFunc)(sqlite3_context*,int,sqlite3_value**),
void (*xStep)(sqlite3_context*,int,sqlite3_value**),
void (*xFinal)(sqlite3_context*)
);
You do exactly the same thing here as you do with functions, but rather than proving a callback for xFunc, you leave it NULL and provide functions for xStep and xFinal.
A Practical Example
The best way to illustrate implementing aggregates is by example. Here we will implement the aggregate str_agg(). The idea of str_agg() is to act much like the strcat() C function, where two strings are concatenated together (the eagle-eyed will spot that newer versions of SQLite include a function with a similar purpose, group_concat()). But for our purposes, we want to aggregate any number of strings involved in grouping and aggregations at the behest of your SQL in SQLite. You might well wonder whether you really need such a string contatenation aggregation feature in SQLite, given you could write your own in C. One advantage of the str_agg() approach is to enable semantically clear and easily understood SQL to be written, rather than having to shuffle back and forth between SQL and C to achieve the string aggregation. The other benefit of this example is, of course, to show you how to aggregate. Listing 7-2 shows our example str_agg() function (taken from str_agg.c).
Listing 7-2. The str_agg() Test Program
int main(int argc, char **argv)
{
int rc; sqlite3 *db; char *sql;
sqlite3_open_v2("foods.db", &db);
/* Register aggregate. */
fprintf(stdout, "Registering aggregate str_agg()
");
/* Turn SQL tracing on. */
log_sql(db, 1);
/* Register aggregate. */
sqlite3_create_function( db, "str_agg", 1, SQLITE_UTF8, db,
NULL, str_agg_step, str_agg_finalize);
/* Test. */
fprintf(stdout, "
Running query:
");
sql = "select season, str_agg(name, ', ') from episodes group by season";
print_sql_result(db, sql);
sqlite3_close(db);
return 0;
}
Note that our step function is called str_agg_step(), and our finalizing function is called str_agg_finalize(). Also, this aggregate is registered as taking only one argument.
The Step Function
Listing 7-3 shows the str_agg_step() function.
Listing 7-3. The str_agg() Step Function
void str_agg_step(sqlite3_context* ctx, int ncols, sqlite3_value** values)
{
SAggCtx *p = (SAggCtx *) sqlite3_aggregate_context(ctx, sizeof(*p));
static const char delim [] = ", ";
char *txt = sqlite3_value_text(values[0]);
int len = strlen(txt);
if (!p->result) {
p->result = sqlite_malloc(len + 1);
memcpy(p->result, txt, len + 1);
p->chrCnt = len;
}
else
{
const int delimLen = sizeof(delim);
p->result = sqlite_realloc(p->result, p->chrCnt + len + delimLen + 1);
memcpy(p->result + p->chrCnt, delim, delimLen);
p->chrCnt += delimLen;
memcpy(p->result + p->chrCnt, txt, len + 1);
p->chrCnt += len;
}
}
The value SAggCtx is a struct that is specific to this example and is defined as follows:
typedef struct SAggCtx SAggCtx;
struct SAggCtx {
int chrCnt;
char *result;
};
Our structure serves as our state between aggregate iterations (calls to the step function), maintaining the growing concatenation of text, and the character count.
The Aggregate Context
The first order of business is to retrieve the structure for the given aggregate instance. This is done using sqlite3_aggregate_context(). As mentioned earlier, the first call to this function allocates the data for the given context and subsequent calls retrieve it. The structure memory is automatically freed when the aggregate completes (after str_agg_finalize() is called). Note that sqlite3_aggregate_context() might return NULL if the system is low on memory. Such error checking is omitted in this example, for brevity, but a real implementation should always check the result of sqlite3_aggregate_context() and invoke sqlite3_result_error_nomem() if the result is NULL. In the str_agg_step() function, the text value to be aggregated is retrieved from the first argument using sqlite3_value_text(). This value is then added to the result member of the SAggCtx struct, which stores the intermediate concatenation. Note again that sqlite3_value_text() might return a NULL pointer if the argument to the SQL function is NULL or if the system is low on memory. A real implementation should check for this case in order to avoid a segfault.
The Finalize Function
Each record in the materialized result set triggers a call to str_agg_step(). After the last record is processed, SQLite calls str_agg_finalize(), which is implemented as shown in Listing 7-4.
Listing 7-4. The sum_agg() Finalize Function
void str_agg_finalize(sqlite3_context* ctx)
{
SAggCtx *p = (SAggCtx *) sqlite3_aggregate_context(ctx, sizeof(*p));
if( p && p->result ) sqlite3_result_text(ctx, p->result, p->chrCnt, sqlite_free);
}
The str_agg_finalize() function basically works just like a user-defined function callback. It retrieves the SAggCtx struct and, if it is not NULL, sets the aggregate's return value to the value stored in the struct's result member using sqlite3_result_text(). The sqlite3_aggregate_context() routine might return NULL if the system is low on memory, or the p->zResult field might be NULL if the step function was never called. In the former case, SQLite is going to return the SQLITE_NOMEM error so it does not really matter whether sqlite3_result_text() is ever called. In the latter case, since no sqlite3_result_xxx() function is ever invoked for the aggregate, the result of the aggregate will be the SQL NULL.
Results
The program produces the following output (abbreviated here to conserve paper):
Registering aggregate str_agg()
Running query:
TRACE: select season, str_agg(name, ', ') from episodes group by season
. . .
season str_agg(name, ', ')
------ ------------------------------------------------------------------
0 Good News Bad News
1 Male Unbonding, The Stake Out, The Robbery, The Stock Tip
2 The Ex-Girlfriend, The Pony Remark, The Busboy, The Baby Shower, . . .
3 The Note, The Truth, The Dog, The Library, The Pen, The Parking Garage . . .
. . .
As you can see, the select statement pulls back the data from the episode table, and the str_agg() aggregate concatenates the episode names per season. You can think of this as something similar to cross-tabs or pivots in spreadsheets and other tools.
And that is the concept of aggregates in a nutshell. They are so similar to functions that there isn't much to talk about once you are familiar with functions.
Collations
As stated before, the purpose of collations is to sort strings. But before starting down that path, it is important to recall that SQLite's manifest typing scheme allows varying data types to coexist in the same column. For example, consider the following SQL (located in collate1.sql):
.headers on
.m column
create table foo(x);
insert into foo values (1);
insert into foo values (2.71828);
insert into foo values ('three'),
insert into foo values (X'0004'),
insert into foo values (null);
select quote(x), typeof(x) from foo;
Feeding it to the SQLite CLP will produce the following:
C: empexamplesch7> sqlite3 < collate.sql
quote(x) typeof(x)
---------- ----------
1 integer
2.71828 real
'three' text
X'0004' blob
NULL null
You have every one of SQLite's native storage classes sitting in column x. Naturally, the question arises as to what happens when you try to sort this column. That is, before we can talk about how to sort strings, we need to review how different data types are sorted first.
When SQLite sorts a column in a result set (when it uses a comparison operator such as < or >= on the values within that column), the first thing it does is arrange the column's values according to storage class. Then within each storage class, it sorts the values according to methods specific to that class. Storage classes are sorted in the following order, from first to last:
NULLvaluesINTEGERandREALvaluesTEXTvaluesBLOBvalues
Now let's modify the SELECT statement in the preceding example to include an ORDER BY clause such that the SQL is as follows:
select quote(x), typeof(x) from foo order by x;
Rerunning the query (located in collate2.sql) confirms this ordering:
C: empexamplesch7> sqlite3 < collate.sql
quote(x) typeof(x)
---------- ----------
NULL null
1 integer
2.71828 real
'three' text
X'0004' blob
NULLs are first, INTEGER and REAL are next (in numerical order), TEXT is next, and then BLOBs are last.
SQLite employs specific sorting methods for each storage class. NULLs are obvious—there is no sort order. Numeric values are sorted numerically; integers and floats alike are compared based on their respective quantitative values. BLOBs are sorted by binary value. Text, finally, is where collations come in.
Collation Defined
Collation is the method by which strings are compared. A popular1 glossary of terms defines a collation as follows:
Text comparison using language-sensitive rules as opposed to bitwise comparison of numeric character codes.
In general, collation has to do with the ordering, comparison, and arrangement of strings and characters. Collation methods usually employ collation sequences. A collation sequence is just an ordered list of characters, usually numbered to make the order easier to remember and use. The list in turn is used to dictate how characters are ordered, compared and sorted. Given any two characters, the collation (list) can resolve which would come first or whether they are the same.
How Collation Works
Normally, a collation method compares two strings by breaking them down and comparing their respective characters using a collation. They do this by lining the strings up and comparing characters from left to right (Figure 7-2). For example, the strings 'jerry' and 'jello' would be compared by first comparing the first letter in each string (both j in this case). If one letter's numerical value according to the collation sequence is larger than the other, the comparison is over: the string with the larger letter is deemed greater, and no further comparison is required. If, on the other hand, the letters have the same value, then the process continues to the second letter in each string, and to the third, and so on, until some difference is found (or no difference is found, in which case the strings are considered equal). If one string runs out of letters before the other, then it is up to the collation method to determine what this means.
__________
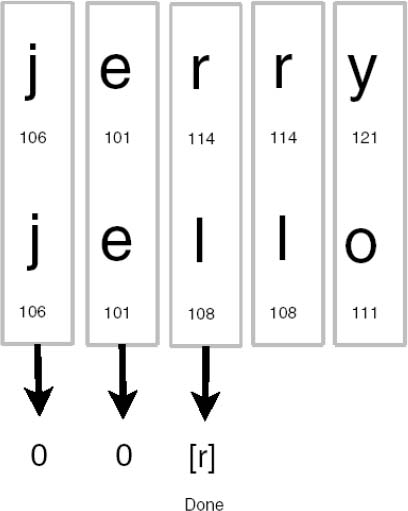
Figure 7-2. Binary collation
In this example, the collation is the ASCII character set. Each character's numeric ASCII value in the figure is displayed underneath it. Using the collation method just described, string comparison continues to the third character, whereupon 'jerry' wins out, as it has an r with the value 114, whereas 'jello' has the inferior 'l' with the value 108. Based on ASCII collation, 'jerry' > 'jello'.
Had 'jerry' been 'Jerry', then 'jello' would have won out, because big J's 74 pales to little j's 106, so the comparison would have been resolved on the first character, with the prize going to 'jello'. In short, 'jello' > 'Jerry'.
However, to continue the example, we could use a different collation wherein uppercase values are assigned the same numbers as their lowercase counterparts (a case-insensitive collation sequence). Then the comparison between 'Jerry' and 'jello' would go back to 'Jerry' because in this new collation J and j are the same, pulling the rug out from under 'jello''s lowercase j superiority.
But enough about collations. You get the picture. A sequence is a sequence. Ultimately, it's not the collation sequence that matters but the collation method. Collation methods don't have to use sequences. They can do whatever they want, however strange or mad that may seem.
Odds are that you are really confused by now and are just ready for a summary. So here it is. Think of collation methods as the way that strings are compared. Think of collation sequences as the way characters are compared. Ultimately, all that matters in SQLite is how strings are compared, and the two terms refer to just that. Therefore, the two terms collation method and collation sequence should just be thought of as string comparison. If you read collation, think string comparison. If you read collation, think string comparison. All in all, just think string comparison. That is the way the API is geared. When you create a custom collation, SQLite hands it two strings, a and b, and the collation returns whether string a is less than, equal to, or greater than string b. That's it, plain and simple.
Standard Collation Types
SQLite comes with a single built-in collation named binary, which is implemented by applying the memcmp() routine from the standard C library to the two strings to be compared. The binary collation happens to work well for English text. For other languages or locales, alternative collation may be preferred. SQLite also offers an alternate collation called nocase, which treats upper- and lowercase versions of the same letter as equivalents.
Collations are applied by associating them with columns in a table or an index definition or by specifying them in a query. For example, to create a case-insensitive column bar in foo, you would define foo as follows:
create table foo (bar text collate nocase, baz integer);
From that point on, whenever SQLite deals with a bar, it will use the nocase collation. If you prefer not to attach a collation to a database object but would rather specify it as needed on a query-by-query basis, you can specify them directly in queries, as in the following:
select * from foo order by bar collate nocase;
SQLite can also apply a collation as the result of a cast() expression where you convert nontext data (that wouldn't normally have a textual collation) to the text data type. We could cast our baz numeric value to text and apply the nocase collation like this:
select cast(baz) collate nocase as baz_as_text from foo order by baz_as_text;
Although the example is a little contrived, the capability will help you especially when dealing with data of mixed storage classes being converted to text.
A Simple Example
To jump into collations, let's begin with a simple example to get the big picture. Let's implement a collation called length_first. Length_first will take two strings and decide which one is greater depending on the length of the string. Image Jerry at the deli, demanding to only eat ingredients with short names—or Kramer insisting he has a great deal on foods with really long names. Whimsical, but very Seinfeld.
Collations are registered with SQLite through the sqlite3_create_collation_v2() function, which is declared as follows:
int sqlite3_create_collation_v2(
sqlite3* db, /* database handle */
const char *zName, /* collation name in SQL */
int pref16, /* encoding */
void* pUserData, /* application data */
int(*xCompare)(void*,int,const void*,int,const void*)
void(*xDestroy)(void*)
);
It looks pretty similar to sqlite3_create_function(). There is the standard database handle, the collation name as it will be addressed in SQL (similar to the function/aggregate name), and the encoding, which pertains to the format of the comparison strings when passed to the comparison function.
![]() Note Just as in aggregates and functions, separate collation comparison functions can be registered under the same collation name for each of the UTF-8, UTF-16LE, and UTF-16BE encodings. SQLite will automatically select the best comparison function for the given collation based on the strings to be compared.
Note Just as in aggregates and functions, separate collation comparison functions can be registered under the same collation name for each of the UTF-8, UTF-16LE, and UTF-16BE encodings. SQLite will automatically select the best comparison function for the given collation based on the strings to be compared.
The application data pointer is another API mainstay. The pointer provided there is passed on to the callback function. Basically, sqlite3_create_collation_v2() is a stripped-down version of sqlite3_create_function(), which takes exactly two arguments (both of which are text) and returns an integer value. It also has the aggregate callback function pointers stripped out.
Of the remaining two parameters, the last is xDestroy pointer. This function will be called at destruction time of the collation, which typically will happen when the database connection is destroyed. The destruction function will also be called if your collation is overridden by later calls to sqlite3_create_collation_v2().
The Compare Function
The xCompare argument is the key new thing here. It points to the actual comparison function that will resolve the text values. The comparison function must have the following form:
int compare( void* data, /* application data */
int len1, /* length of string 1 */
const void* str1, /* string 1 */
int len2, /* length of string 2 */
const void* str2) /* string 2 */
The function should return negative, zero, or positive if the first string is less than, equal to, or greater than the second string, respectively.
As stated, the length_first collation is a bit wishy-washy. Listing 7-5 shows its implementation.
Listing 7-5. The Length_first Collation Function
int length_first_collation( void* data, int l1, const void* s1,
int l2, const void* s2 )
{
int result, opinion;
/* Compare lengths */
if ( l1 == l2 ) result = 0;
if ( l1 < l2 ) result = 1;
if ( l1 > l2 ) result = 2;
/* Form an opinion: is s1 really < or = to s2 ? */
switch(result) {
case 0: /* Equal length, collate alphabetically */
opinion = strcmp(s1,s2);
break;
case 1: /* String s1 is shorter */
opinion = -result;
break;
case 2: /* String s2 is shorter */
opinion = result
break;
default: /* Assume equal length just in case */
opinion = strcmp(s1,s2);
}
return opinion;
}
The Test Program
All that remains is to illustrate it in a program. Listing 7-6 shows the example program (length_first.c) implementation.
Listing 7-6. The Length_first Collation Test Program
int main(int argc, char **argv)
{
char *sql; sqlite3 *db; int rc;
sqlite3_open("foods.db", &db);
/* Register Collation. */
fprintf(stdout, "1. Register length_first Collation
");
sqlite3_create_collation_v2( db, "LENGTH_FIRST", SQLITE_UTF8, db,
length_first_collation, length_first_collation_del );
/* Turn SQL logging on. */
log_sql(db, 1);
/* Test default collation. */
fprintf(stdout, "2. Select records using default collation.
");
sql = "select name from foods order by name";
print_sql_result(db, sql);
/* Test Length First collation. */
fprintf(stdout, "
Select records using length_first collation.
");
sql = "select name from foods order by name collate LENGTH_FIRST";
print_sql_result(db, sql);
/* Done. */
sqlite3_close(db);
return 0;
}
Results
Running the program yields the following results (abbreviated here to save space):
1. Register length_first Collation
2. Select records using default collation.
TRACE: select name from foods order by name
name
-----------------
A1 Sauce
All Day Sucker
Almond Joy
Apple
Apple Cider
Apple Pie
Arabian Mocha Java (beans)
Arby's Roast Beef
Artichokes
Atomic Sub
...
Select records using length_first collation.
TRACE: select name from foods order by name collate LENGTH_FIRST
issue
-----------------
BLT
Gum
Kix
Pez
Pie
Tea
Bran
Duck
Dill
Life
...
Our program starts by registering the length_first collation sequence. We then proceed to select records using SQLite's default binary collation, which returns records in alphabetical order. Then comes our use of the length_first collation, where we select records again. As the results indicate, we are right on the mark, sorting first by length and then alphabetically.
Collation on Demand
SQLite provides a way to defer collation registration until it is actually needed. So if you are not sure your application is going to need something like the length_first collation, you can use the sqlite3_collation_needed() function to defer registration to the last possible moment (perhaps as the result of some secret last-minute food renaming). You simply provide sqlite3_collation_needed() with a callback function, which SQLite can rely on to register unknown collation sequences as needed, given their name. This acts like a callback for a callback, so to speak. It's like saying to SQLite, “Here, if you are ever asked to use a collation that you don't recognize, call this function, and it will register the unknown sequence; then you can continue your work.”
The sqlite3_collation_needed() function is declared as follows:
int sqlite3_collation_needed(
sqlite3* db, /* connection handle */
void* data, /* application data */
void(*crf)(void*,sqlite3*,int eTextRep,const char*)
);
The crf argument (the collation registration function as we call it) points to the function that will register the unknown collation. For clarity, it is defined as follows:
void crf( void* data, /* application data */
sqlite3* db, /* database handle */
int eTextRep, /* encoding */
const char*) /* collation name */
The db and data arguments of crf() are the values passed into the first and second arguments of sqlite3_collation_needed(), respectively.
Summary
By now you've discovered that user-defined functions, aggregates, and collations can be surprisingly useful. The ability to add such functions using the extensions part of the C API is a great complement to the open nature of the core SQLite library. So, you're free to dig in and modify SQLite to your heart's content. We would even go so far to say that SQLite provides a friendly, easy-to-user interface that makes it possible to implement a wide range of powerful extensions and customizations, especially when combined with other features already present in SQLite.
In the next chapter, you will see how many extension languages take advantage of this. They use the C API to make it possible to implement all manner of capabilities and extensions for a given language.