
3. The Birth of C++
No ties bind so strongly as the links of inheritance.
– Stephen Jay Gould
From C with Classes to C++ — Cfront, the initial implementation of C++ — virtual functions and object-oriented programming — operator overloading and references — constants — memory management — type checking — C++’s relationship to C — dynamic initialization — declaration syntax — description and evaluation of C++.
3.1 From C with Classes to C++
During 1982 it became clear to me that C with Classes was a “medium success” and would remain so until it died. I defined a medium success as something so useful that it easily paid for itself and its developer, but not so attractive and useful that it would pay for a support and development organization. Thus, continuing with C with Classes and its C preprocessor implementation would condemn me to support C with Classes indefinitely. I saw only two ways out of this dilemma:
[1] Stop supporting C with Classes so that the users would have to go elsewhere (freeing me to do something else).
[2] Develop a new and better language based on my experience with C with Classes that would serve a large enough set of users to pay for a support and development organization (thus freeing me to do something else). At the time I estimated that 5,000 industrial users was the necessary minimum.
The third alternative, increasing the user population through marketing (hype), never occurred to me. What actually happened was that the explosive growth of C++, as the new language was eventually named, kept me so busy that to this day I haven’t managed to get sufficiently detached to do something else of significance.
The success of C with Classes was, I think, a simple consequence of meeting its design aim: C with Classes did help organize a large class of programs significantly better than C without the loss of run-time efficiency and without requiring enough cultural changes to make its use infeasible in organizations that were unwilling to undergo major changes. The factors limiting its success were partly the limited set of new facilities offered over C and partly the preprocessor technology used to implement C with Classes. There simply wasn’t enough support in C with Classes for people who were willing to invest significant efforts to reap matching benefits: C with Classes was an important step in the right direction, but it was only one small step. As a result of this analysis, I began designing a cleaned-up and extended successor to C with Classes and implementing it using traditional compiler technology.
The resulting language was at first still called C with Classes, but after a polite request from management it was given the name C84. The reason for the naming was that people had taken to calling C with Classes “new C,” and then C. This abbreviation led to C being called “plain C,” “straight C,” and “old C.” The last name, in particular, was considered insulting, so common courtesy and a desire to avoid confusion led me to look for a new name.
The name C84 was used only for a few months, partly because it was ugly and institutional, partly because there would still be confusion if people dropped the “84.” Also, Larry Rosier, the editor of the X3J11 ANSI committee for the standardization of C, asked me to find another name. He explained, “standardized languages are often referred to by their name followed by the year of the standard and it would be embarrassing and confusing to have a superset (C84, a.k.a. C with Classes, and later C++) with a lower number than its subset (C, possibly C85, and later ANSI C).” That seemed eminently reasonable – although Larry turned out to have been somewhat optimistic about the date of the C standard – and I started asking for ideas for a new name among the C with Classes user community.
I picked C++ because it was short, had nice interpretations, and wasn’t of the form “adjective C.” In C, ++ can, depending on context, be read as “next,” “successor,” or “increment,” though it is always pronounced “plus plus.” The name C++ and its runner up ++C are fertile sources for jokes and puns – almost all of which were known and appreciated before the name was chosen. The name C++ was suggested by Rick Mascitti. It was first used in December of 1983 when it was edited into the final copies of [Stroustrup,1984] and [Stroustrup, 1984c].
The “C” in C++ has a long history. Naturally, it is the name of the language Dennis Ritchie designed. C’s immediate ancestor was an interpreted descendant of BCPL class B designed by Ken Thompson. BCPL was designed and implemented by Martin Richards from Cambridge University while visiting MIT in the other Cambridge. BCPL in turn was Basic CPL, where CPL is the name of a rather large (for its time) and elegant programming language developed jointly by the universities of Cambridge and London. Before the London people joined the project “C” stood for Cambridge. Later, “C” officially stood for Combined. Unofficially, “C” stood for Christopher because Christopher Strachey was the main power behind CPL.
3.2 Aims
During the 1982 to 1984 period, the aims for C++ gradually became more ambitious and more definite. I had come to see C++ as a language separate from C, and libraries and tools had emerged as areas of work. Because of that, because tool developers within Bell Labs were beginning to show interest in C++, and because I had embarked on a completely new implementation that would become the C++ compiler front-end, Cfront, I had to answer several key questions:
[1] Who will the users be?
[2] What kind of systems will they use?
[3] How will I get out of the business of providing tools?
[4] How should the answers to [1], [2], and [3] affect the language definition?
My answer to [1], “Who will the users be?,” was that first my friends within Bell Labs and I would use it, then more widespread use within AT&T would provide more experience, then some universities would pick up the ideas and the tools, and finally AT&T and others would be able to make some money by selling the set of tools that had evolved. At some point, the initial and somewhat experimental implementation done by me would be faded out in favor of more industrial-strength implementations by AT&T and others.
This made practical and economic sense; the initial (Cfront) implementation would be tool-poor, portable, and cheap because that was what I, my colleagues, and many university users needed and could afford. Later, there would be ample scope for better tools and more specialized environments. Such better tools aimed primarily at industrial users needn’t be cheap either, and would thus be able to pay for the support organizations necessary for large-scale use of the language. That was my answer to [3], “How will I get out of the business of providing tools?” Basically, the strategy worked. However, just about every detail actually happened in an unforeseen way.
To get an answer to [2], “What kind of systems will they use?” I simply looked around to see what kind of systems the C with Classes users actually did use. They used everything from systems that were so small they couldn’t run a compiler to mainframes and supercomputers. They used more operating systems than I had heard of. Consequently, I concluded that extreme portability and the ability to do cross compilation were necessities and that I could make no assumption about the size and speed of the machines running generated code. To build a compiler, however, I would have to make assumptions about the kind of system people would develop their programs on. I assumed that one MIPS plus one Mbyte would be available. That assumption, I considered a bit risky because most of my prospective users at the time had a shared PDP11 or some other relatively low-powered and/or timeshared system.
I did not predict the PC revolution, but by over-shooting my performance target for Cfront I happened to build a compiler that (barely) could run on an IBM PC/AT, thus providing an existence proof that C++ could be an effective language on a PC and thereby spurring commercial software developers to beat it.
As the answer to [4], “How does all this affect the language definition?” I concluded that no feature must require really sophisticated compiler or run-time support, that available linkers must be used, and that the code generated would have to be efficient (comparable to C) even initially.
3.3 Cfront
The Cfront compiler front-end for the C84 language was designed and implemented by me between the spring of 1982 and the summer of 1983. The first user outside the computer science research center, Jim Coplien, received his copy in July of 1983. Jim was in a group that had been doing experimental switching work using C with Classes in Bell Labs in Naperville, Illinois for some time.
In that same time period, I designed C84, drafted the reference manual published January 1, 1984 [Stroustrup,1984], designed the complex number library and implemented it together with Leonie Rose [Rose, 1984], designed and implemented the first string class together with Jonathan Shopiro, maintained and ported the C with Classes implementation, supported the C with Classes users, and helped them become C84 users. That was a busy year and a half.
Cfront was (and is) a traditional compiler front-end that performs a complete check of the syntax and semantics of the language, builds an internal representation of its input, analyzes and rearranges that representation, and finally produces output suitable for some code generator. The internal representation is a graph with one symbol table per scope. The general strategy is to read a source file one global declaration at a time and produce output only when a complete global declaration has been completely analyzed.
In practice, this means that the compiler needs enough memory to hold the representation of all global names and types plus the complete graph of one function. A few years later, I measured Cfront and found that its memory usage leveled out at about 600 Kbytes on a DEC VAX just about independently of which real program I fed it. This fact was what made my initial port of Cfront to a PC/AT in 1986 feasible. At the time of Release 1.0 in 1985 Cfront was about 12,000 lines of C++.
The organization of Cfront is fairly traditional except maybe for the use of many symbol tables instead of just one. Cfront was originally written in C with Classes (what else?) and soon transcribed into C84 so that the very first working C++ compiler was done in C++. Even the first version of Cfront used classes and derived classes heavily. It did not use virtual functions, though, because they were not available at the start of the project.
Cfront is a compiler front-end (only) and can never be used for real programming by itself. It needs a driver to run a source file through the C preprocessor, Cpp, then run the output of Cpp through Cfront and the output from Cfront through a C compiler:
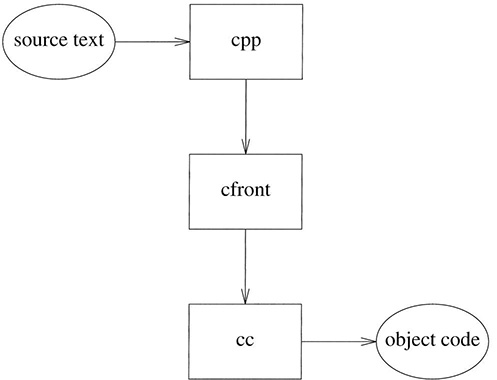
In addition, the driver must ensure that dynamic (run-time) initialization is done. In Cfront 3.0, the driver becomes yet more elaborate as automatic template instantiation (§15.2) is implemented [McCluskey,1992].
3.3.1 Generating C
The most unusual – for its time – aspect of Cfront was that it generated C code. This has caused no end of confusion. Cfront generated C because I needed extreme portability for an initial implementation and I considered C the most portable assembler around. I could easily have generated some internal back-end format or assembler from Cfront, but that was not what my users needed. No assembler or compiler back-end served more than maybe a quarter of my user community and there was no way that I could produce the, say, six backends needed to serve just 90% of that community. In response to this need, I concluded that using C as a common input format to a large number of code generators was the only reasonable choice. The strategy of building a compiler as a C generator later became popular. Languages such as Ada, Eiffel, Modula-3, Lisp, and Smalltalk have been implemented that way. I got a high degree of portability at a modest cost in compile-time overhead. The sources of overhead were
[1] The time needed for Cfront to write the intermediate C.
[2] The time needed for a C compiler to read the intermediate C.
[3] The time “wasted” by the C compiler analyzing the intermediate C.
[4] The time needed to control this process.
The size of this overhead depends critically on the time needed to read and write the intermediate C representation and that primarily depends on the disc read/write strategy of a system. Over the years I have measured this overhead on various systems and found it to be between 25% and 100% of the “necessary” parts of a compilation. I have also seen C++ compilers that didn’t use intermediate C yet were slower than Cfront plus a C compiler.
Please note that the C compiler is used as a code generator only. Any error message from the C compiler reflects an error in the C compiler or in Cfront, but not in the C++ source text. Every syntactic and semantic error is in principle caught by Cfront, the C++ compiler front-end. In this, C++ and its Cfront implementation differed from preprocessor-based languages such as Ratfor [Kernighan,1976] and Objective C [Cox, 1986].
I stress this because there has been a long history of confusion about what Cfront is. It has been called a preprocessor because it generates C, and for people in the C community (and elsewhere) that has been taken as proof that Cfront was a rather simple program – something like a macro preprocessor. People have thus “deduced” (wrongly) that a line-for-line translation from C++ to C is possible, that symbolic debugging at the C++ level is impossible when Cfront is used, that code generated by Cfront must be inferior to code generated by “real compilers,” that C++ wasn’t a “real language,” etc. Naturally, I have found such unfounded claims most annoying – especially when they were leveled as criticisms of the C++ language. Several C++ compilers now use Cfront together with local code generators without going through a C front end. To the user, the only obvious difference is faster compile times.
The irony is that I dislike most forms of preprocessors and macros. One of C++’s aims is to make C’s preprocessor redundant (§4.4, §18) because I consider its actions inherently error prone. Cfront’s primary aim was to allow C++ to have rational semantics that could not be implemented with the kind of compilers that were used for C at the time: Such compilers simply don’t know enough about types and scopes to do the kind of resolution C++ requires. C++ was designed to rely heavily on traditional compiler technology, rather than on run-time support or detailed programmer resolution of expressions (as you need in languages without overloading). Consequently, C++ cannot be compiled with any traditional preprocessor technology. I considered and rejected such alternatives for language semantics and translator technology at the time. Cfront’s immediate predecessor, Cpre, was a fairly traditional preprocessor that didn’t understand every syntax, scope, and type rule of C. This had been a source of many problems both in the language definition and in actual use. I was determined not to see these problems repeated for my revised language and new implementation. C++ and Cfront were designed together and language definition and compiler technology definitely affected each other, but not in the simple-minded manner people sometimes assume.
3.3.2 Parsing C++
In 1982 when I first planned Cfront, I wanted to use a recursive descent parser because I had experience writing and maintaining such a beast, because I liked such parsers’ ability to produce good error messages, and because I liked the idea of having the full power of a general-purpose programming language available when decisions had to be made in the parser. However, being a conscientious young computer scientist I asked the experts. A1 Aho and Steve Johnson were in the Computer Science Research Center and they, primarily Steve, convinced me that writing a parser by hand was most old-fashioned, would be an inefficient use of my time, would almost certainly result in a hard-to-understand and hard-to-maintain parser, and would be prone to unsystematic and therefore unreliable error recovery. The right way was to use an LALR(l) parser generator, so I used A1 and Steve’s YACC [Aho,1986].
For most projects, it would have been the right choice. For almost every project writing an experimental language from scratch, it would have been the right choice. For most people, it would have been the right choice. In retrospect, for me and C++ it was a bad mistake. C++ was not a new experimental language, it was an almost compatible superset of C – and at the time nobody had been able to write an LALR(l) grammar for C. The LALR(l) grammar used by ANSI C was constructed by Tom Pennello about a year and a half later – far too late to benefit me and C++. Even Steve Johnson’s PCC, which was the preeminent C compiler at the time, cheated at details that were to prove troublesome to C++ parser writers. For example, PCC didn’t handle redundant parentheses correctly so that int (x); wasn’t accepted as a declaration of x. Worse, it seems that some people have a natural affinity to some parser strategies and others work much better with other strategies. My bias towards top-down parsing has shown itself many times over the years in the form of constructs that are hard to fit into a YACC grammar. To this day, Cfront has a YACC parser supplemented by much lexical trickery relying on recursive descent techniques. On the other hand, it is possible to write an efficient and reasonably nice recursive descent parser for C++. Several modern C++ compilers use recursive descent.
3.3.3 Linkage Problems
As mentioned, I decided to live within the constraints of traditional linkers. However, there was one constraint I found insufferable, yet so silly that I had a chance of fighting it if I had sufficient patience: Most traditional linkers had a very low limit on the number of characters that can be used in external names. A limit of eight characters was common, and six characters and one case only are guaranteed to work as external names in K&R C; ANSI/ISO C also accepts that limit. Given that the name of a member function includes the name of its class and that the type of an overloaded function has to be reflected in the linkage process somehow or other (see §11.3.1), I had little choice.
Consider:
void task::schedule() { /* ... */ } // 4+8 characters
void hashed::print() { /* ... */ } // 6+5 characters
complex sqrt(complex); // 4 character plus 'complex'
double sqrt(double); // 4 character plus 'double'
Representing these names with only six upper case characters would require some form of compression that would complicate tool building. It would probably also involve some form of hashing so that a rudimentary “program database” would be needed to resolve hash overflows. The former is a nuisance, and the latter could be a serious problem because there is no concept of a “program database” in the traditional C/Fortran linkage model.
Consequently, I started (in 1982) lobbying for longer names in linkers. I don’t know if my efforts actually had any effect, but these days most linkers do give me the much larger number of characters I need. Cfront uses encodings to implement type-safe linkage in a way that makes a limit of 32 characters too low for comfort, and even 256 is a bit tight at times (see § 11.3.2). In the interim, systems of hash coding of long identifiers have been used with archaic linkers, but that was never completely satisfactory.
3.3.4 Cfront Releases
The first C with Classes and C++ implementations to make their way out of Bell Labs were early versions that people in various university departments had requested directly from me. In that way, people in dozens of educational institutions got to use C with Classes. Examples are Stanford University (December 1981, first Cpre shipment), University of California at Berkeley, University of Wisconsin in Madison, Caltech, University of North Carolina at Chapel Hill, MIT, University of Sydney, Carnegie-Mellon University, University of Illinois at Urbana-Champaign, University of Copenhagen, Rutherford Labs (Oxford), IRCAM, INRIA. The shipments of implementations to individual educational institutions continued after the design and implementation of C++. Examples are University of California at Berkeley (August 1984, first Cfront shipment), Washington University (St. Louis), University of Texas in Austin, University of Copenhagen, and University of New South Wales. In addition, students showed their usual creativity in avoiding paperwork. Even then, handling individual releases soon became a burden for me and a source of annoyance for university people wanting C++. Consequently, my department head, Brian Kernighan, AT&T’s C++ product manager, Dave Kallman, and I came up with the idea of having a more general release of Cfront. The idea was to avoid commercial problems such as determining prices, writing contracts, handling support, advertising, getting documentation to conform to corporate standards, etc., by basically giving Cfront and a few libraries to university people at the cost of the tapes used for shipping. This was called Release E, “E” for “Educational.” The first tapes were shipped in January 1985 to organizations such as Rutherford Labs (Oxford).
Release E was an eye opener for me. In fact, Release E was a flop. I had expected interest in C++ in universities to surge. Instead, the growth of C++ users continued along its usual curve (§7.1) and what we saw instead of a flood of new users was a flood of complaints from professors because C++ wasn’t commercially available. Again and again I was contacted and told “Yes, I want to use C++, and I know that I can get Cfront for free, but unfortunately I can’t use it because I need something I can use in my consulting and something my students can use in industry.” So much for the pure academic pursuit of learning. Steve Johnson, then the department head in charge of C and C++ development, Dave Kallman, and I went back to the drawing board and came back with the plan for a commercial Release 1.0. However, the policy of “almost free” C++ implementations (with source and libraries) to educational institutions that originated with Release E remains in place to this day.
Versions of C++ are often named by Cfront release numbers. Release 1.0 was the language as defined in The C+ + Programming Language [Stroustrup,1986]. Releases 1.1 (June 1986) and 1.2 (February 1987) were primarily bug-fix releases, but also added pointers to members and protected members (§13.9).
Release 2.0 was a major cleanup that also introduced multiple inheritance (§12.1) in June 1989. It was widely perceived as a significant improvement both in functionality and quality. Release 2.1 (April 1990) was primarily a bug-fix release that brought Cfront (almost) into line with the definition in The Annotated C+ + Reference Manual [ARM] (§5.3).
Release 3.0 (September 1991) added templates (§15) as specified in the ARM. A variant of 3.0 supporting exception handling (§16) as specified in the ARM was produced by Hewlett-Packard [Cameron, 1992] and shipped starting late 1992.
I wrote the first versions of Cfront (1.0, 1.1, 1.2) and maintained them; Steve Dewhurst worked on it with me for a few months before Release 1.0 in 1985. Laura Eaves did much of the work on the Cfront parser for Release 1.0, 1.1, 2.1, and 3.0. I also did the lion’s share of the programming for Release 1.2 and 2.0, but starting with Release 1.2, Stan Lippman also spent most of his time on Cfront. Laura Eaves, Stan Lippman, George Logothetis, Judy Ward, and Nancy Wilkinson did most of the work for Release 2.1 and 3.0. The work on 1.2, 2.0, 2.1, and 3.0 was managed by Barbara Moo. Andrew Koenig organized Cfront testing for 2.0. Sam Haradhvala from Object Design Inc. did an initial implementation of templates in 1989 that Stan Lippman extended and completed for Release 3.0 in 1991. The initial implementation of exception handling in Cfront was done by Hewlett-Packard in 1992. In addition to these people who have produced code that has found its way into the main version of Cfront, many people have built local C++ compilers from it. Over the years a wide variety of companies including Apple, Centerline (formerly Saber), Comeau Computing, Glockenspiel, ParcPlace, Sun, Hewlett-Packard, and others have shipped products that contain locally modified versions of Cfront.
3.4 Language Features
The major additions to C with Classes introduced to produce C++ were:
[1] Virtual functions (§3.5)
[2] Function name and operator overloading (§3.6)
[3] References (§3.7)
[4] Constants (§3.8)
[5] User-controlled free-store memory control (§3.9)
[6] Improved type checking (§3.10)
In addition, the notion of call and return functions (§2.11) was dropped due to lack of use and many minor details were changed to produce a cleaner language.
3.5 Virtual Functions
The most obvious new feature in C++ – and certainly the one that had the greatest impact on the style of programming one could use for the language – was virtual functions. The idea was borrowed from Simula and presented in a form that was intended to make a simple and efficient implementation easy. The rationale for virtual functions was presented in [Stroustrup, 1986] and [Stroustrup, 1986b]. To emphasize the central role of virtual functions in C++ programming, I will quote it in detail here [Stroustrup, 1986]:
“An abstract data type defines a sort of black box. Once it has been defined, it does not really interact with the rest of the program. There is no way of adapting it to new uses except by modifying its definition. This can lead to severe inflexibility. Consider defining a type shape for use in a graphics system. Assume for the moment that the system has to support circles, triangles, and squares. Assume also that you have some classes:
class point{ /* ... */ };
class color{ /* ... * / };
You might define a shape like this:
enum kind { circle, triangle, square };
class shape {
point center;
color col;
kind k;
// representation of shape
public:
point where() { return center; }
void move(point to) { center = to; draw(); }
void draw();
void rotate(int);
// more operations
}
The “type field” k is necessary to allow operations such as draw() and rotate() to determine what kind of shape they are dealing with (in a Pascallike language, one might use a variant record with tag k). The function draw() might be defined like this:
void shape::draw()
{
switch (k) {
case circle:
// draw a circle
break;
case triangle:
// draw a triangle
break;
case square:
// draw a square
break;
}
}
This is a mess. Functions such as draw() must “know about” all the kinds of shapes there are. Therefore the code for any such function grows each time a new shape is added to the system. If you define a new shape, every operation on a shape must be examined and (possibly) modified. You are not able to add a new shape to a system unless you have access to the source code for every operation. Since adding a new shape involves “touching” the code of every important operation on shapes, it requires great skill and potentially introduces bugs into the code handling other (older) shapes. The choice of representation of particular shapes can get severely cramped by the requirement that (at least some of) their representation must fit into the typically fixed sized framework presented by the definition of the general type shape.
The problem is that there is no distinction between the general properties of any shape (a shape has a color, it can be drawn, etc.) and the properties of a specific shape (a circle is a shape that has a radius, is drawn by a circle-drawing function, etc.). Expressing this distinction and taking advantage of it defines object-oriented programming. A language with constructs that allows this distinction to be expressed and used supports object-oriented programming. Other languages don’t.
The Simula inheritance mechanism provides a solution that I adopted for C++. First, specify a class that defines the general properties of all shapes:
class shape {
point center;
color col;
// ...
public:
point where() { return center; }
void move(point to) { center = to; draw(); }
virtual void draw();
virtual void rotate(int);
// ...
};
The functions for which the calling interface can be defined, but where the implementation cannot be defined except for a specific shape, have been marked virtual (the Simula and C++ term for “may be redefined later in a class derived from this one”). Given this definition, we can write general functions manipulating shapes:
void rotate_all(shape** v, int size, int angle)
// rotate all members of vector "v"
// of size "size" "angle" degrees
{
for (int i = 0; i < size; i++) v[i]->rotate(angle);
}
To define a particular shape, we must say that it is a shape and specify its particular properties (including the virtual functions).
class circle : public shape {
int radius;
public:
void draw() { /* ... */ };
void rotate(int) {} // yes, the null function
};
In C++, class circle is said to be derived from class shape, and class shape is said to be a base of class circle. An alternative terminology calls circle and shape subclass and superclass, respectively.”
For further discussion of virtual functions and object-oriented programming see §13.2, §12.3.1, §13.7, §13.8, and §14.2.3.
I don’t remember much interest in virtual functions at the time. I probably didn’t explain the concepts involved well, but the main reaction I received from people in my immediate vicinity was one of indifference and skepticism. A common opinion was that virtual functions were simply a kind of crippled pointer to function and thus redundant. Worse, it was sometimes argued that a well-designed program wouldn’t need the extensibility and openness provided by virtual functions so that proper analysis would show which non-virtual functions could be called directly. Therefore, the argument went, virtual functions were simply a form of inefficiency. Clearly, I disagreed and added virtual functions anyway.
I deliberately did not provide a mechanism for explicit inquiry about the type of an object in C++:
“The Simula67 INSPECT statement was deliberately not introduced into C++. The reason for that is to encourage modularity through the use of virtual functions [Stroustrup,1986].”
The Simula INSPECT statement is a switch on a system-provided type field. I had seen enough misuses to be determined to rely on static type checking and virtual functions in C++ as long as possible. A mechanism for run-time type inquiry was eventually added to C++ (§14.2). I hope its form will make it less seductive than the Simula INSPECT was and is.
3.5.1 The Object Layout Model
The key implementation idea was that the set of virtual functions in a class defines an array of pointers to functions so that a call of a virtual function is simply an indirect function call through that array. There is one such array, usually called a virtual function table or vtbl, per class with virtual functions. Each object of such a class contains a hidden pointer, often called the vptr, to its class’s virtual function table.
Given:
class A {
int a;
public:
virtual void f();
virtual void g(int);
virtual void h(double);
};
class B : public A {
public:
int b;
void g(int); // overrides A::g()
virtual void m(B*);
};
class C : public B {
public:
int c;
void h(double); // overrides A::h()
virtual void n(C*);
};
a class C object looked something like this:

A call to a virtual function is transformed by the compiler into an indirect call. For example,
void f(C* p)
{
p->g(2);
}
becomes something like
(*(p->vptr[1]))(p,2); /* generated code */
This implementation is not the only one possible. Its virtues are simplicity and runtime efficiency; its problem is that recompilation of user code is necessary if you change the set of virtual functions for a class.
At this point, the object model becomes real in the sense that an object is more than the simple aggregation of the data members of a class. An object of a C++ class with a virtual function is a fundamentally different beast from a simple C struct. Then why did I not at this point choose to make structs and classes different notions?
My intent was to have a single concept: a single set of layout rules, a single set of lookup rules, a single set of resolution rules, etc. Maybe we could have lived with two set of rules, but a single concept provides a smoother integration of features and simpler implementations. I was convinced that if struct came to mean “C and compatibility” to users and class to mean “C++ and advanced features,” the community would fall into two distinct camps that would soon stop communicating. Being able to use as many or as few language features as needed when designing a class was an important idea to me. Only a single concept would support my ideas of a smooth and gradual transition from “traditional C-style programming,” through data abstraction, to object-oriented programming. Only a single concept would support the notion of “you only pay for what you use” ideal.
In retrospect, I think these notions have been very important for C++’s success as a practical tool. Over the years, just about everybody has had some kind of expensive idea that could be implemented “for classes only,” leaving low overhead and low features to structs. I think the idea of keeping struct and class the same concept saved us from classes supporting an expensive, diverse, and rather different set of features than we have now. In other words, the “a struct is a class” notion is what has stopped C++ from drifting into becoming a much higher-level language with a disconnected low-level subset. Some would have preferred that to happen.
3.5.2 Overriding and Virtual Function Matching
A virtual function could only be overridden by a function in a derived class with the same name and exactly the same argument and return type. This avoided any form of run-time type checking of arguments and any need to keep more extensive type information around at run time. For example:
class Base {
public:
virtual void f();
virtual void g(int);
};
class Derived : public Base {
public :
void f(); // overrides Base::f()
void g(char); // doesn't override Base::g()
};
This opens an obvious trap for the unwary: The non-virtual Derived::g() is actually unrelated to the virtual Base::g() and hides it. This is a problem if you work with a compiler that doesn’t warn you about the problem. However, the problem is trivial for a compiler to detect and is a non-problem given an implementation that does warn. Cfront 1.0 didn’t warn, thus causing some grief, but Cfront 2.0 and higher do.
The rule requiring an exact type match for an overriding function was later relaxed for the return type; see §13.7.
3.5.3 Base Member Hiding
A name in a derived class hides any object or function of the same name in a base class. Whether this is a good design decision has been the subject of some debate over the years. The rule was first introduced in C with Classes. I saw it as a simple consequence of the usual scope rules. When arguing the point, I hold that the opposite rule – names from derived and base classes are merged into a single scope – gives at least as many problems. In particular, state-changing functions would occasionally be called for sub-objects by mistake:
class X {
int x;
public:
virtual void copy(X* p) { x = p->x; }
};
class XX: public X {
int xx;
public:
virtual void copy(XX* p) { xx = p->xx; X::copy(p); }
};
void f(X a, XX b)
{
a.copy(&b); // ok: copy X part of b
b.copy(&a); // error: copy(X*) is hidden by copy(XX*)
}
Allowing the second copy operation, as would happen if base and derived scopes were merged, would cause b’s state to be partially updated. In most real cases, this would lead to very strange behavior of operations on XX objects. I have seen examples of people getting caught in exactly this way when using the GNU C++ compiler (§7.1.4), which allowed the overloading.
In the case where copy() is virtual, one might consider having XX::copy() override X::copy(), but then one would need run-time type checking to catch the problem with b.copy(&a) and programmers would have to code defensively to catch such errors at run time (§13.7.1). This was understood at the time, and I feared that there were further problems that I didn’t understand, so I chose the current rules as the strictest, simplest, and most efficient.
In retrospect, I suspect that the overloading rules introduced in 2.0 (§11.2.2) might have been able to handle this case. Consider the call b.copy (&a). The variable b is an exact type match for the implicit argument of XX::copy, but requires a standard conversion to match X::copy. The variable a on the other hand, is an exact match for the explicit argument of X::copy, but requires a standard conversion to match XX::copy. Thus, had the overloading been allowed, the call would have been an error because it was ambiguous.
See §17.5.2 for a way to explicitly request overloading of base and derived class functions.
3.6 Overloading
Several people had asked for the ability to overload operators. Operator overloading “looked neat” and I knew from experience with Algol68 how the idea could be made to work. However, I was reluctant to introduce the notion of overloading into C++ because:
[1] Overloading was reputed to be hard to implement and caused compilers to grow to monstrous size.
[2] Overloading was reputed to be hard to teach and hard to define precisely. Consequently, manuals and tutorials would grow to monstrous size.
[3] Code written using operator overloading was reputed to be inherently inefficient.
[4] Overloading was reputed to make code incomprehensible.
If [3] or [4] were true, C++ would be better off without overloading. If [1] or [2] were true, I didn’t have the resources to provide overloading.
However, if all of these conjectures were false, overloading would solve some real problems for C++ users. There were people who would like to have complex numbers, matrices, and APL-like vectors in C++. There were people who would like range-checked arrays, multidimensional arrays, and strings. There were at least two separate applications for which people wanted to overload logical operators such as | (or), & (and), and ~ (exclusive or). The way I saw it, the list was long and would grow with the size and the diversity of the C++ user population. My answer to [4], “overloading makes code obscure,” was that several of my friends, whose opinion I valued and whose experience was measured in decades, claimed that their code would become cleaner if they had overloading. So what if one can write obscure code with overloading? It is possible to write obscure code in any language. It matters more how a feature can be used well than how it can be misused.
Next, I convinced myself that overloading wasn’t inherently inefficient [Stroustrup, 1984b] [ARM,§ 12.1c]. The details of the overloading mechanism were mostly worked out on my blackboard and those of Stu Feldman, Doug McIlroy, and Jonathan Shopiro.
Thus, having worked out an answer to [3], “code written using overloading is inefficient,” I needed to concern myself with [1] and [2], the issue of compiler and language complexity. I first observed that use of classes with overloaded operators, such as complex and string, was quite easy and didn’t put a major burden on the programmer. Next, I wrote the manual sections to prove that the added complexity wasn’t a serious issue; the manual needed less than a page and a half extra (out of a 42-page manual). Finally, I did the first implementation in two hours using only 18 lines of extra code in Cfront, and I felt I had demonstrated that the fears about definition and implementation complexity were somewhat exaggerated. Nevertheless, §11 will show that overloading problems did appear.
Naturally, all these issues were not really tackled in this strict sequential order, but the emphasis of the work did slowly shift from utility issues to implementation issues. The overloading mechanisms were described in detail in [Stroustrup, 1984b], and examples of classes using the mechanisms were written up [Rose, 1984] [Sho-piro,1985].
In retrospect, I think that operator overloading has been a major asset to C++. In addition to the obvious use of overloaded arithmetic operators (+, *, +=, *=, etc.) for numerical applications, [] subscripting, () application, and = assignment are often overloaded to control access, and << and >> have become the standard I/O operators (§8.3.1).
3.6.1 Basic Overloading
Here is an example that illustrates the basic techniques:
class complex {
double re, im;
public:
complex(double);
complex(double,double);
friend complex operator+(complex,complex);
friend complex operator*(complex,complex);
// ...
};
This allows simple complex expressions to be resolved into function calls:
void f(complex z1, complex z2)
{
complex z3 = z1+z2; // operator+(z1,z2)
}
Assignment and initialization needn’t be explicitly defined. They are by default defined as memberwise copy; see §11.4.1.
In my design of the overloading mechanism, I relied on conversions to decrease the number of overloading functions needed. For example:
void g(complex z1, complex z2, double d)
{
complex z3 = z1+z2; // operator+(z1,z2)
complex z4 = z1+d; // operator+(z1,complex(d))
complex z5 = d+z2; // operator+(complex(d),z2)
}
That is, I rely on the implicit conversion of double to complex to allow me to support “mixed-mode arithmetic” with a single complex add function. Additional functions can be introduced to improve efficiency or numerical accuracy.
In principle, we could do without implicit conversions altogether by either requiring explicit conversion or by providing the full set of complex add functions:
class complex {
public:
friend complex operator+(complex,complex);
friend complex operator+(complex,double);
friend complex operator*(double,complex);
// ...
};
Would we have been better off without implicit conversions? The language would have been simpler without them, implicit conversions can certainly be overused, and a call involving a conversion function is typically less efficient than a call of an exactly matching function.
Consider the four basic arithmetic operations. Defining the full set of mixed-mode operations for complex and double requires 12 arithmetic functions compared to 3 plus a conversion function when implicit conversion is used. Where the number of operations and the number of types involved are higher, the difference between the linear increase in the number of functions that we get from using conversions and the quadratic explosion we get from requiring all combinations becomes significant. I have seen examples in which the complete set of operators was provided because conversion operators couldn’t be safely defined. The result was more than 100 functions defining operators. I consider that acceptable in special cases, but not as a standard practice.
Naturally, I realized that not all constructors defined meaningful and unsurprising implicit conversions. For example, a vector type usually has a constructor taking an integer argument indicating the number of elements. It was an unfortunate sideefect to have v=7 construct a vector of seven elements and assign it to v. I didn’t consider this problem urgent, though. Several members of the C++ standards committee (§6.2), notably Nathan Myers, suggested that a solution was necessary. In 1995, the problem was solved by allowing the prefix explicit to be added to the declaration of a constructor. A constructor declared explicit is used for explicit construction only and not for implicit conversions. For example, declaring vector's constructor "explicit vector (int);" makes v=7 an error while the more explicit v=vector (7) as ever constructs and assigns a vector.
3.6.2 Members and Friends
Note how a global operator+, a friend function, was used in preference to a member function to ensure that the operands of + are handled symmetrically. Had member functions been used, we would have needed a resolution like this:
void f(complex z1, complex z2, double d)
{
complex z3 = z1+z2; // z1.operator+(z2);
complex z4 = z1+d; // z1.operator+(complex(d))
complex z5 = d+z2; // d.operator+(z2)
}
This would have required us to define how to add a complex to the built-in type double. This would not only require more functions, but also require modification of code in separate places (that is, the definition of class complex and the definition of the built-in type double). This was deemed undesirable. I considered allowing the definition of additional operations on built-in types. However, I rejected the idea because I did not want to change the rule that no type – built-in or user-defined – can have operations added after its definition is complete. Other reasons were that the definition of conversions between C’s built-in types is too messy to allow additions, and that the member-function solution to provide mixed-mode arithmetic is intrinsically more messy than the global-function-plus-conversion-function solution adopted.
The use of a global function allows us to define operators so that their arguments are logically equivalent. Conversely, defining an operator as a member ensures that no conversions are invoked for the first (leftmost) operand. This allows us to mirror the rules for operands that require an lvalue as their leftmost operand, such as the assignment operators:
class String {
// ...
public:
String(const char*);
String& operator^(const Strings);
String& operator+=(const String&); // add to end
// ...
};
void f(String& s1, String& s2)
{
s1 = s2;
s1 = "asdf"; // fine: s1.operator=(String ("asdf"));
"asdf" = s2; // error: String assigned to char*
}
Later, Andrew Koenig observed that the assignment operators such as += are more fundamental and more efficient than their ordinary arithmetic cousins such as +. It is often best to define only assignment operator functions, such as += and *=, as members and define ordinary operator functions, such as + and *, as global functions later:
String& String::operator+=(const String& s)
{
// add s onto the end of *this
return *this;
}
String operator+(const Strings s1, const String& s2)
{
String sum = s1;
sum+=s2;
return sum;
}
Note that no friendship is required, and that the definition of the binary operator is trivial and stylized. No temporary variables are needed to implement the call of +=, and the local variable sum is all the temporary variable management that the user has to consider. The rest can be handled simply and efficiently by the compiler (see §3.6.4).
My original idea was to allow every operator to be either a member or a global function. In particular, I had found it convenient to provide simple access operations as member functions and then let users implement their own operators as global functions. For operators such as + and – my reasoning was sound, but for operator = itself we ran into problems. Consequently, Release 2.0 required operator = to be a member. This was an incompatible change that broke a few programs, so the decision wasn’t taken lightly. The problem was that unless operator = is a member, a program can have two different interpretations of = dependent on the location in the source code. For example:
class X {
// no operator=
};
void f(X a, X b)
{
a = b; // predefined meaning of =
}
void operator=(X&,X); // disallowed by 2.0
void g(X a, X b)
{
a = b; // user-defined meaning of =
}
This could be most confusing, especially where the two assignments appeared in separately compiled source files. Since there is no built-in meaning for += for a class that problem cannot occur for +=.
However, even in the original design of C++, I restricted operators [], (), and –> to be members. It seemed a harmless restriction that eliminated the possibility of some obscure errors because these operators invariably depend on and typically modify the state of their left-hand operand. However, it is probably a case of unnecessary nannyism.
3.6.3 Operator Functions
Having decided to support implicit conversions and the model of mixed mode operations supported by them, I needed a way of specifying such conversions. Constructors of a single argument provide one such mechanism. Given
class complex {
// ...
complex(double); // converts a double to a complex
// ...
};
we can explicitly or implicitly convert a double to a complex. However, this allows the designer of a class to define conversions to that class only. It was not uncommon to want to write a new class that had to fit into an existing framework. For example, the C library has dozens of functions taking string arguments, that is, arguments of type char*. When Jonathan Shopiro first wrote a full-blown String class, he found that he would either have to replicate every C library function taking a string argument:
int strlen(const char*); // original C function
int strlen(const String&); // new C++ function
or provide a String to const char* conversion operator.
Consequently, I added the notion of conversion operator functions to C++:
class String {
// ...
operator const char*();
// ...
};
int strlen(const char*); // original C function
void f(String& s)
{
// ...
strlen(s); // strlen(s.operator const char*())
// ...
}
In real use, implicit conversion has sometimes proven tricky to use. However, providing the full set of mixed-mode operations isn’t pretty either. I would like a better solution, but of the solutions I know, implicit conversions is the least bad.
3.6.4 Efficiency and Overloading
Contrary to (frequently expressed) naive superstition there is no fundamental difference between operations expressed as function calls and operations expressed as operators. The efficiency issues for overloading were (and are) inlining and the avoidance of spurious temporaries.
To convince myself of that, I first noted that code generated from something like a+b or v[i] was identical to what one would get from function calls add (a, b) and v.elem (i).
Next, I observed that by using inlining, a programmer could ensure that simple operations would not carry function-call overhead (in time or space). Finally, I observed that call-by-reference would be necessary to support this style of programming effectively for larger objects (more about that in §3.7). This left the problems of how to avoid spurious copying in examples such as a=b+c. Generating
assign(add(b,c),t); assign(t,a);
would not compare well to the
add_and_assign(b, c, a);
that a compiler can generate for a built-in type and a programmer can write explicitly. In the end, I demonstrated [Stroustrup, 1984b] how to generate
add_and_initialize(b,c,t); assign(t,a);
That left one “spurious” copy operation that can be removed only where it can be proved that the + and = operations don’t actually depend on the value assigned to (aliasing). For a more accessible reference for this optimization, see [ARM]. This optimization did not become available in Cfront until Release 3.0. I believe the first available C++ implementation using that technique was Zortech’s compiler. Walter Bright easily implemented the optimization after I explained it to him over an ice cream sundae at the top of the Space Needle in Seattle after an ANSI C++ standards meeting in 1990.
The reason I considered this slightly sub-optimal scheme acceptable was that more explicit operators such as += are available for hand-optimization of the most common operations, and also that the absence of aliasing can be assumed in initializations. Borrowing the Algol68 notion that a declaration can be introduced wherever it is needed (and not just at the top of some block), I could enable an “initialize-only” or “single-assignment” style of programming that would be inherently efficient – and also less error-prone than traditional styles where variables are assigned again and again. For example, one can write
complex compute(complex z, int i)
{
if (/* ... */) {
// ...
}
complex t = f(z,i);
// ...
z += t;
// ...
return t;
}
rather than the more verbose and less efficient:
complex compute(complex z, int i)
{
complex t;
if (/* ... */) {
// ...
}
t = f(z,i);
// ...
z = z + t;
// ...
return t;
}
For yet another idea for increasing run-time efficiency by eliminating temporaries, see §11.6.3.
3.6.5 Mutation and New Operators
I considered it important to provide overloading as a mechanism for extending the language and not for mutating it; that is, it is possible to define operators to work on user-defined types (classes), but not to change the meaning of operators on built-in types. In addition, I didn’t want to allow programmers to introduce new operators. I feared cryptic notation and having to adopt complicated parsing strategies like those needed for Algol68. In this matter, I think my restraint was reasonable. See also §11.6.1 and §11.6.3.
3.7 References
References were introduced primarily to support operator overloading. Doug McIlroy recalls that once I was explaining some problems with a precursor to the current operator overloading scheme to him. He used the word reference with the startling effect that I muttered “Thank you,” and left his office to reappear the next day with the current scheme essentially complete. Doug had reminded me of Algol68.
C passes every function argument by value, and where passing an object by value would be inefficient or inappropriate the user can pass a pointer. This strategy doesn’t work where operator overloading is used. In that case, notational convenience is essential because users cannot be expected to insert address-of operators if the objects are large. For example:
a = b – c;
is acceptable (that is, conventional) notation, but
a = &b – &c;
is not. Anyway, &b-&c already has a meaning in C, and I didn’t want to change that.
It is not possible to change what a reference refers to after initialization. That is, once a C++ reference is initialized it cannot be made to refer to a different object later; it cannot be re-bound. I had in the past been bitten by Algol68 references where r1=r2 can either assign through r1 to the object referred to or assign a new reference value to r1 (re-binding r1) depending on the type of r2. I wanted to avoid such problems in C++.
If you want to do more complicated pointer manipulation in C++, you can use pointers. Because C++ has both pointers and references, it does not need operations for distinguishing operations on the reference itself from operations on the object referred to (like Simula) or the kind of deductive mechanism employed by Algol68.
I made one serious mistake, though, by allowing a non-const reference to be initialized by a non-lvalue. For example:
void incr(int& rr) { rr++; }
void g()
{
double ss = 1;
incr(ss); // note: double passed, int expected
// (fixed: error in Release 2.0)
}
Because of the difference in type the int& cannot refer to the double passed so a temporary was generated to hold an int initialized by ss’s value. Thus, incr() modified the temporary, and the result wasn’t reflected back to the calling function.
The reason to allow references to be initialized by non-lvalues was to allow the distinction between call-by-value and call-by-reference to be a detail specified by the called function and of no interest to the caller. For const references, this is possible; for non-const references it is not. For Release 2.0 the definition of C++ was changed to reflect this.
It is important that const references can be initialized by non-lvalues and lvalues of types that require conversion. In particular, this is what allows a Fortran function to be called with a constant:
extern "Fortran" float sqrt(const float&);
void f()
{
sqrt(2); // call by reference
}
In addition to the obvious uses of references, such as reference arguments, we considered the ability to use references as return types important. This allowed us to have a very simple index operator for a string class:
class String {
// ...
char& operator[](int index); // subscript operator
// return a reference
};
void f(String& s, int i)
{
char c1 = s[i]; // assign operator[]'s result
s[i] = c1; // assign to operator[]'s result
// ...
}
Returning a reference to the internal representation of a String assumes responsible behavior by the users. That assumption is reasonable in many situations.
3.7.1 Lvalue vs. Rvalue
Overloading operator []() to return a reference doesn’t allow the writer of operator []() to provide different semantics for reading and writing an element identified by subscripting. For example,
s1[i] = s2[j];
we can’t cause one action on the String written to, s1, and another on the string read, s2. Jonathan Shopiro and I considered it essential to provide separate semantics for read access and write access when we considered strings with shared representation and database accesses. In both cases, a read is a very simple and cheap operation, whereas a write is a potentially expensive and complicated operation involving replication of data structures.
We considered two alternatives:
[1] Specifying separate functions for lvalue use and rvalue use.
[2] Having the programmer use an auxiliary data structure.
The latter approach was chosen because it avoided a language extension and because we considered the technique of returning an object describing a location in a container class, such as a String, more general. The basic idea is to have a helper class that identifies a position in the container class much as a reference does, but has separate semantics for reading and writing. For example:
class char_ref { // identify a character in a String
friend class String;
int i;
String* s;
char_ref(String* ss, int ii) { s=ss; i=ii; }
public:
void operator=(char c);
operator char();
};
Assigning to a char_ref is implemented as assignment to the character referenced. Reading from a char_ref is implemented as a conversion to char returning the value of the character identified:
void char_ref::operator=(char c) { s->r[i]=c; }
char_ref::operator char() { return s->r[i]; }
Note that only a String can create a char_ref. The actual assignment is implemented by the String:
class String {
friend class char_ref;
char* r;
public:
char_ref operator[](int i)
{ return char_ref(this,i); }
// ...
};
Given these definitions,
s1[i] = s2[j];
means
s1.operator[](i) = s2.operator[](j)
where both s1.operator [] (i) and s2.operator[] (j) return temporary objects of class char_ref. That in turn means
s1.operator[](i).operator=(s2.operator[](j).operator char())
Inlining makes the performance of this technique acceptable in many cases, and the use of friendship to restrict the creation of char_refs ensures that we do not get lifetime temporary problems (§6.3.2). For example, this technique has been used in successful String classes. However, it does seem complicated and heavyweight for simple uses such as access to individual characters, so I have often considered alternatives. In particular, I have been looking for an alternative that would be both more efficient and not a special-purpose wart. Composite operators (§11.6.3) is one possibility.
3.8 Constants
In operating systems, it is common to have access to some piece of memory controlled directly or indirectly by two bits: one that indicates whether a user can write to it and one that indicates whether a user can read it. This idea seemed to me directly applicable to C++, and I considered allowing every type to be specified readonly or writeonly. An internal memo dated January 1981 [Stroustrup,1981b] describes the idea:
“Until now it has not been possible in C to specify that a data item should be read only, that is, that its value must remain unchanged. Neither has there been any way of restricting the use of arguments passed to a function. Dennis Ritchie pointed out that if readonly was a type operator, both facilities could be obtained easily, for example:
readonly char table[1024]; /* the chars in "table"
cannot be updated */
int f(readonly int * p)
{
/* "f" cannot update the data denoted by "p" */
/* ... */
}
The readonly operator is used to prevent the update of some location. It specifies that out of the usually legal ways of accessing the location, only the ones that do not change the value stored there are legal.”
The memo goes on to point out that
“The readonly operator can be used on pointers, too. *readonly is interpreted as “readonly pointer to,” for example:
readonly int * p; /* pointer to read only int */
int * readonly pp; /* read only pointer to int */
readonly int * readonly ppp; /* read only pointer
to read only int */
Here, it is legal to assign a new value to p, but not to *p. It is legal to assign to *pp, but not to pp, and it is illegal to assign to ppp, or *ppp.”
Finally, the memo introduces writeonly:
“There is the type operator writeonly, which is used like readonly, but prevents reading rather than writing. For example:
struct device_registers {
readonly int input_reg, status_reg;
writeonly int output_reg, command_reg;
};
void f(readonly char * readonly from,
writeonly char * readonly to)
/*
"f" can obtain data through "from",
deposit results through "to",
but can change neither pointer
*/
{
/ * . . *.
}
int * writeonly p;
Here, ++p is illegal because it involves reading the old value of p, but p=0 is legal.”
The proposal focused on specifying interfaces rather than on providing symbolic constants for C. Clearly, a readonly value is a symbolic constant, but the scope of the proposal is far greater. Initially, I proposed pointers to readonly but not readonly pointers. A brief discussion with Dennis Ritchie evolved the idea into the readonly/writeonly mechanism that I implemented and proposed to an internal Bell Labs C standards group chaired by Larry Rosier. There, I had my first experience with standards work. I came away from a meeting with an agreement (that is, a vote) that readonly would be introduced into C – yes C, not C with Classes or C++ – provided it was renamed const. Unfortunately, a vote isn’t executable, so nothing happened to our C compilers. Later, the ANSI C committee (X3J11) was formed and the const proposal resurfaced there and became part of ANSI/ISO C.
In the meantime, I had experimented further with const in C with Classes and found that const was a useful alternative to macros for representing constants only if global consts were implicitly local to their compilation unit. Only in that case could the compiler easily deduce that their value really didn’t change. Knowing that allows us to use simple consts in constant expressions and to avoid allocating space for such constants. C did not adopt this rule. For example, in C++ we can write:
const int max = 14;
void f(int i)
{
int a[max+l]; // const 'max7 used in constant expression
switch (i) {
case max: // const 'max' used in constant expression
// ...
}
}
whereas in C, even today we must write
#define max 14
// ...
because in C, consts may not be used in constant expressions. This makes consts far less useful in C than in C++ and leaves C dependent on the preprocessor while C++ programmers can use properly typed and scoped consts.
3.9 Memory Management
Long before the first C with Classes program was written, I knew that free store (dynamic memory) would be used more heavily in a language with classes than in most C programs. This was the reason for the introduction of the new and delete operators in C with Classes. The new operator that both allocates memory from the free store and invokes a constructor to ensure initialization was borrowed from Simula. The delete operator was a necessary complement because I did not want C with Classes to depend on a garbage collector (§2.13, §10.7). The argument for the new operator can be summarized like this. Would you rather write:
X* p = new X(2) ;
or
struct X * p = (struct X *) malloc(sizeof(struct X));
if (p == 0) error("memory exhausted");
p->init(2);
and which version are you most likely to make a mistake in? Note that the checking against memory exhaustion is done in both cases. Allocation using new involves an implicit check and may invoke a user-supplied new_handler function; see [2nd,§9.4.3]. The arguments against – which were voiced quite a lot at the time -were, “but we don’t really need it,” and, “but someone will have used new as an identifier.” Both observations are correct, of course.
Introducing operator new thus made the use of free store more convenient and less error-prone. This increased its use even further so that the C free-store allocation routine malloc() used to implement new became the most common performance bottleneck in real systems. This was no surprise either; the only problem was what to do about it. Having real programs spend 50% or more of their time in malloc() wasn’t acceptable.
I found per-class allocators and deallocators very effective. The fundamental idea is that free-store memory usage is dominated by the allocation and deallocation of lots of small objects from very few classes. Take over the allocation of those objects in a separate allocator and you can save both time and space for those objects and also reduce the amount of fragmentation of the general free store.
I don’t remember the earliest discussions about how to provide such a mechanism to the users, but I do remember presenting the “assignment to this” technique (described below) to Brian Kernighan and Doug McIlroy and summing up, “This is ugly as sin, but it works, and if you can’t think of a better way either then that’s the way I’ll do it,” or words to that effect. They couldn’t, so we had to wait until Release 2.0 for the cleaner solution now in C++ (see §10.2).
The idea was that, by default, memory for an object is allocated “by the system” without requiring any specific action from the user. To override this default behavior, a programmer simply assigns to the this pointer. By definition, this points to the object for which a member function is called. For example:
class X {
// ...
public:
X (int i);
// ...
};
X::X(int i)
{
this = my_alloc(sizeof(X));
// initialize
}
Whenever the X::X(int) constructor is used, allocation will be done using my_alloc(). This mechanism was powerful enough to serve its purpose, and several others, but far too low level. It didn’t interact well with stack allocation or with inheritance. It was error-prone and repetitive to use when – as is typical – an important class had many constructors.
Note that static and automatic (stack allocated) objects were always possible and that the most effective memory management techniques relied heavily on such objects. The string class was a typical example. String objects are typically on the stack, so they require no explicit memory management, and the free store they rely on is managed exclusively and invisibly to the user by the String member functions.
The constructor notation used here is discussed in §3.11.2 and §3.11.3.
3.10 Type Checking
The C++ type checking rules were the result of experience with C with Classes. All function calls are checked at compile time. The checking of trailing arguments can be suppressed by explicit specification in a function declaration. This is essential to allow C’s printf():
int printf(const char* ...); // accept any argument after
// the initial character string
// ...
printf("date: %s %d 19%d
",month,day,year); // maybe right
Several mechanisms were provided to alleviate the withdrawal symptoms that many C programmers feel when they first experience strict checking. Overriding type checking using the ellipsis was the most drastic and least recommended of those. Function name overloading (§3.6.1) and default arguments [Stroustrup,1986] (§2.12.2) made it possible to give the appearance of a single function taking a variety of argument lists without compromising type safety.
In addition, I designed the stream I/O system to demonstrate that weak checking wasn’t necessary even for I/O (see §8.3.1):
cout<<"date: "<<month<<' '<<day<<" 19" <<year<<' ';
is a type-safe version of the example above.
I saw, and still see, type checking as a practical tool rather than a goal in itself. It is essential to realize that eliminating every type violation in a program doesn’t imply that the resulting program is correct or even that the resulting program cannot crash because an object was used in a way that was inconsistent with its definition. For example, a stray electric pulse may cause a critical memory bit to change its value in a way that is impossible according to the language definition. Equating type insecurities with program crashes and program crashes with catastrophic failures such as airplane crashes, telephone system breakdowns, and nuclear power station meltdowns is irresponsible and misleading.
People who make statements to that effect fail to appreciate that the reliability of a system depends on all of its parts. Ascribing an error to a particular part of the total system is simply pin-pointing the error. We try to design life-critical systems so that a single error or even many errors will not lead to a “crash.” The responsibility for the integrity of the system is in the people who produce the system and not in any one part of the system. In particular, type safety is not a substitute for testing even though it can be a great help in getting a system ready for testing. Blaming programming language features for a specific system failure, even a purely software one, is confusing the issue; see also §16.2.
3.11 Minor Features
During the transition from C with Classes to C++, several minor features were added.
3.11.1 Comments
The most visible minor change was the introduction of BCPL-style comments:
int a; /* C-style explicitly terminated comment */
int b; // BCPL-style comment terminated by end-of-line
Since both styles of comments are allowed, people can use the style they like best. Personally, I like the BCPL-style for one-line comments. The immediate cause for introducing the / / comments was that I sometimes made silly mistakes forgetting to terminate C comments and found that the three extra characters I used to terminate a / * comment sometimes made my lines wrap around on my screen. I also noted that / / comments were more convenient than / * comments for commenting out small sections of code.
The addition of / / was soon discovered not to be 100% C compatible because of examples such as
x = a//* divide */b
which means x=a in C++ and x=a/b in C. At the time and also now, most C++ programmers considered such examples of little real importance.
3.11.2 Constructor Notation
The name “new-function” for constructors had been a source of confusion, so the named constructor was introduced. At the same time, the concept was extended to allow constructors to be used explicitly in expressions. For example,
complex i = complex(0,1);
complex operator+(complex a, complex b)
{
return complex(a.re+b.re,a.im+b.im);
}
The expressions of the form complex (x, y) are explicit invocations of a constructor for class complex.
To minimize the number of new keywords, I didn’t use an explicit syntax like this:
class X {
constructor();
destructor();
// ...
};
Instead, I chose a declaration syntax that mirrored the use of constructors:
class X {
X(); // constructor
~X(); // destructor (~ is the C complement operator)
// ...
};
This may have been overly clever.
The explicit invocation of constructors in expressions proved very useful, but it is also a fertile source of C++ parsing problems. In C with Classes, new() and delete() functions had been public by default. This anomaly was eliminated so that C++ constructors and destructors obey the same access control rules as other functions. For example:
class Y {
Y(); // private constructor
// ...
};
Y a; // error: cannot access Y::Y(): private member
This led to several useful techniques based on the idea of controlling operations by hiding the functions that perform them; see § 11.4.
3.11.3 Qualification
In C with Classes, a dot was used to express membership of a class as well as to express selection of a member of a particular object. This had been the cause of some minor confusion and could also be used to construct ambiguous examples. Consider:
class X {
int a;
public:
void set(X);
};
void X.set(X arg) { a = arg.a; }; //so far so good
class XX; // common C practice:
// class and object with the same name
void f()
{
// ...
X.a; // now, which X do I mean?
// the class or the object?
// ...
}
To alleviate this, :: was introduced to mean membership of class, and . was retained exclusively for membership of object. The example thus becomes:
void X::set(X arg) { a = arg.a; };
class X X;
void g()
{
// ...
X.a; // object.member X::a;
X::a; // class::member
// ...
}
3.11.4 Initialization of Global Objects
It was my aim to make user-defined types usable wherever built-in types were, and I had experienced the lack of global variables of class type as a source of performance problems in Simula. Consequently, global variables of class type were allowed in C++. This had important and somewhat unexpected ramifications. Consider:
class Double {
// ...
Double(double);
};
Double s1 = 2; // construct s1 from 2
Double s2 = sqrt(2); // construct s1 from sqrt(2)
Such initialization cannot in general be done completely at compile time or at link time. Dynamic (run-time) initialization is necessary. Dynamic initialization is done in declaration order within a translation unit. No order is defined for initialization of objects in different translation units except that all static initialization takes place before any dynamic initialization.
3.11.4.1 Problems with Dynamic Initialization
My assumption had been that global objects would be rather simple and therefore require relatively uncomplicated initialization. In particular, I had expected that global objects with initialization that depended on other global objects in other compilation units would be rare. I regarded such dependencies simply as poor design and therefore didn’t feel obliged to provide specific language support to resolve them. For simple examples, such as the one above, I was right. Such examples are useful and cause no problems. Unfortunately, I found another and more interesting use of dynamically initialized global objects.
A library often has some actions that need to be performed before its individual parts can be used. Alternatively, a library may provide objects that are supposed to be pre-initialized so that users can use them directly without first having to initialize them. For example, you don’t have to initialize C’s stdin and stdout: the C startup routine does that for you. Similarly, C’s exit() closes stdin and stdout. This is a very special treatment, and no equivalent facilities are offered for other libraries. When I designed the stream I/O library, I wanted to match the convenience of C’s I/O without introducing special-purpose warts into C++. Thus, I simply relied on dynamic initialization of cout and cin.
That worked nicely, except that I had to rely on an implementation detail to ensure that cout and cin were constructed before user code was run and destroyed after the last user code had completed. Other implementers were less considerate and/or careful. People found their programs could dump core because cout was used before constructed, or some of their output could be lost because cout had been destroyed (and flushed) too soon. In other words, we had been bitten by the order dependency that I had considered “unlikely and poor design.”
3.11.4.2 Workarounds for Order Dependencies
The problem wasn’t insurmountable, though. There are two solutions: The obvious one is to add a first-time switch to every member function. This relies on global data being initialized to 0 by default. For example:
class Z {
static int first_time;
void init();
// ...
public:
void f1();
// ...
void fn();
};
Every member function would look like this:
void Z::f1()
{
if (first_time == 0) {
init();
first_time = 1;
}
// ...
}
This is tedious and the overhead is potentially significant for simple functions such as a single character output operation.
In his redesign of stream I/O (§8.3.1), Jerry Schwarz used a clever variant of this [Schwarz, 1989]. An <iostream.h> header contains something like this:
class io_counter {
static int count;
public:
io_counter()
{
if (count++ == 0) { /* initialize cin, cout, etc. */}
}
~io_counter()
{
if (--count == 0) { /* clean up cin, cout, etc. */ }
}
};
static io_counter io_init;
Now every file that includes the iostream header also creates an io_counter object and initializes it with the effect of increasing io_counter::count. The first time this happens the library objects will be initialized. Since the library header appears before any use of the library facilities proper initialization is ensured. Since destruction is done in reverse order of construction, this technique also ensures that cleanup is done after the last use of the library.
This technique solves the order dependency problem in general at the trivial cost of having the library provider add a few lines of highly stylized code. Unfortunately, the performance implications can be serious. Where such tricks are used, most C++ object files will contain dynamic initialization code and (assuming an ordinary linker) that means that these dynamic initialization routines are scattered throughout the address space of a process. On a virtual memory system, it means that most pages of a program will be brought into primary memory during the initial startup phase and during the final cleanup. This is not well-behaved virtual memory use and can lead to seconds of delays in the startup of significant applications.
A trivial solution for an implementer is to modify the linker to coalesce dynamic startup code in a single place. Also, the problem doesn’t occur unless a system supports some form of dynamic loading of program into primary memory. However, that is cold comfort for a C++ user who suffers from the problem [Reiser, 1992]. Fundamentally, this violates the dictum that a C++ feature not only has to be useful, it also has to be affordable (§4.3). Can the problem be solved by adding a feature? On the surface, it can’t because neither a language design nor even an official standards committee can legislate efficiency. The proposals I have seen attack the ordering problem – which has already been solved by Jerry’s initialization trick – rather than the efficiency problems they imply. I suspect that the real solution is to find some means to encourage implementers to avoid “virtual memory bashing” by dynamic initialization routines. Techniques for achieving that are known, but some explicit wording in the standard may be needed as encouragement.
3.11.4.3 Dynamic Initialization of Built-in Types
In C, a static object can only be initialized using a slightly extended form of constant expressions. For example:
double PI = 22/7; /* ok */
double sqrt2 = sqrt(2); /* error in C */
However, C++ allows completely general expressions for the initialization of class objects. For example:
Double s2 = sqrt(2); // ok
Thus, the built-in types had been made “second-class citizens” because the support for classes had progressed beyond what was provided for the built-in types. The anomaly was easily removed, but the facility was not made generally available until Release 2.0:
double sqrt2 = sqrt(2); // ok in C++ (2.0 and higher)
3.11.5 Declaration Statements
I borrowed the Algol68 notion that a declaration can be introduced wherever it is needed (and not just at the top of some block). Thus, I enabled an “initialize-only” or “single-assignment” style of programming that is less error-prone than traditional styles. This style is essential for references and constants that cannot be assigned and inherently more efficient for types where default initialization is expensive. For example:
void f(int i, const char* p)
{
if (i<=0) error("negative index");
const int len = strlen(p);
String s(p);
// ...
}
Having constructors guarantee initialization (§2.11) is another part of the effort to minimize problems caused by uninitialized variables.
3.11.5.1 Declarations in for-statements
One of the most common reasons to introduce a new variable in the middle of a block is to get a variable for a loop. For example:
int i;
for (i=0; i<MAX; i++) // ...
To avoid separating the declaration of the variable from its initialization, I allowed the declaration to be moved after the for:
for (int i=0; i<MAX; i++) // ...
Unfortunately, I didn’t take the opportunity to change the semantics to limit the scope of a variable introduced in this way to the scope of the for-statement. The reason for this omission was primarily to avoid adding a special case to the rule that says “the scope of a variable extends from its point of declaration to the end of its block.”
This rule was the subject of much discussion and was eventually revised to match the rule for declarations in conditions (§3.11.5.2). That is, a name introduced in a for-statement initializer goes out of scope at the end of the for-statement.
3.11.5.2 Declarations in Conditions
Where people conscientiously try to avoid uninitialized variables, they are left with:
[1] Variables used for input:
int i;
cin>>i;
[2] Variables used in conditions:
Tok* ct;
if (ct = gettok()){/*...*/}
During the design of the run-time type identification mechanism in 1991 (§14.2.2.1), I realized that the latter cause of uninitialized variables could be eliminated by allowing declarations to be used as conditions. For example:
if (Tok* ct = gettok()) {
// ct is in scope here
}
// ct is not in scope here
This feature is not merely a cute trick to save typing. It is a direct consequence of the ideal of locality. By joining the declaration of a variable, its initialization, and the test on the result of that initialization, we achieve a compactness of expression that helps eliminate errors arising from variables being used before they are initialized. By limiting their scope to the statement controlled by the condition, we also eliminate the problem of variables being “reused” for other purposes or accidentally used after they were supposed to have outlived their usefulness. This eliminated a further minor source of errors.
The inspiration for allowing declarations in expressions came from expression languages – in particular from Algol68. I “remembered” that Algol68 declarations yielded values and based my design on that. Later, I found my memory had failed me: declarations are one of the very few constructs in Algol68 that do not yield values! I asked Charles Lindsey about this and received the answer, “Even Algol68 has a few blemishes where it isn’t completely orthogonal.” I guess this just proves that a language doesn’t have to live up to its own ideals to provide inspiration.
If I were to design a language from scratch, I would follow the Algol68 path and make every statement and declaration an expression that yields a value. I would probably also ban uninitialized variables and abandon the idea of declaring more than one name in a declaration. However, these ideas are clearly far beyond what would be acceptable for C++.
3.12 Relationship to Classic C
With the introduction of the name C++ and the writing of a C++ reference manual [Stroustrup,1984], compatibility with C became an issue of major importance and a point of controversy.
Also, in late 1983 the branch of Bell Labs that developed and supported UNIX and produced AT&T’s 3B series of computers became interested in C++ to the point where they were willing to put resources into the development of C++ tools. Such development was necessary for the evolution of C++ from a one-man show to a language that a corporation could base critical projects on. Unfortunately, it also implied that development management needed to consider C++.
The first demand to emerge from development management was that of 100% compatibility with C. The ideal of C compatibility is quite obvious and reasonable, but the reality of programming isn’t that simple. For starters, which C should C++ be compatible with? C dialects abounded, and though ANSI C was emerging, it was still years from having a stable definition, and its definition allowed many dialects. I remember at the time calculating – partly in jest – that there were about 342 strictly-conforming ANSI C dialects. That number was based on taking the number of undefined and implementation-defined aspects and using it as the exponent for the average number of alternatives.
Naturally, the average user who wanted C compatibility wanted C++ to be compatible with the local C dialect. This was an important practical problem and a great concern to me and my friends. It seemed far less of a concern to business-oriented managers and salesmen, who either didn’t quite understand the technical details or would like to use C++ to tie users into their software and/or hardware. The Bell Labs C++ developers, on the other hand, independently of who they worked for, were “emotionally committed to portability as a concept [Johnson, 1992]” and resisted management pressure to enshrine a particular C dialect in the C++ definition.
Another side of the compatibility issue was more critical: “In which ways must C++ differ from C to meet its fundamental goals?” Also, “In which ways must C++ be compatible with C to meet its fundamental goals?” Both sides of the issue are important, and revisions were made in both directions during the transition from C with Classes to Release 1.0 of C++. Slowly and painfully, an agreement emerged that there would be no gratuitous incompatibilities between C++ and ANSI C (when it became a standard) [Stroustrup,1986] but also that there was such a thing as an incompatibility that was not gratuitous. Naturally, the concept of “gratuitous incompatibilities” was a topic of much debate and it took up a disproportionate part of my time and effort. This principle has lately been known as “C++: As close to C as possible – but no closer,” after the title of a paper by Andrew Koenig and me [Koenig, 1989]. One measure of the success of this policy is that every example in K&R2 [Kernighan,1988] is written in the C subset of C++. Cfront was the compiler used for the primary testing of the K&R2 code examples.
Some conclusions about modularity and how a program is composed out of separately compiled parts were explicitly reflected in the original C++ reference manual [Stroustrup, 1984]:
[a] Names are private unless they are explicitly declared public.
[b] Names are local to their file unless explicitly exported from it.
[c] Static type rules are checked unless the check is explicitly suppressed.
[d] A class is a scope (implying that classes nest properly).
Point [a] doesn’t affect C compatibility, but [b], [c], [d] imply incompatibilities:
[1] The name of a non-local C function or object is by default accessible from other compilation units.
[2] C functions need not be declared before use and calls are by default not type checked.
[3] C structure names don’t nest (even when they are lexically nested).
In addition,
[4] C++ has a single namespace, whereas C had a separate namespace for “structure tags” (§2.8.2).
The “compatibility wars” now seem petty and boring, but some of the underlying issues are still unresolved, and we are still struggling with them in the ANSI/ISO standards committee. I strongly suspect that the reason the compatibility wars were drawn out and curiously inconclusive was that we never quite faced the deeper issues related to the differing goals of C and C++ and saw compatibility as a set of separate issues to be resolved individually.
Typically, the least fundamental issue, [4] “namespaces,” took up the most effort, but was eventually resolved by a compromise in [ARM].
I had to compromise the notion of a class as a scope, [3], and accept the C “solution” to be allowed to ship Release 1.0. One practical problem was that I had never realized that a C struct didn’t constitute a scope so that examples like this:
struct outer {
struct inner {
int i;
};
int j;
};
struct inner a = { 1 };
are legal C. Not only that, but such code was found in the standard UNIX header files. When the issue came up towards the end of the compatibility wars, I didn’t have time to fathom the implications of the C “solution,” and it was much easier to agree than to fight the issue. Later, after many technical problems and much discontent from users, nested class scopes were reintroduced into C++ in 1989 [ARM] (§13.5).
After much hassle, C++’s stronger type checking of function calls was accepted (unmodified). An implicit violation of the static type system is the original example of a C/C++ incompatibility that is not gratuitous. The ANSI C committee adopted a slightly weaker version of C++’s rules and notation on this point and declared uses that don’t conform to the C++ rules obsolete.
I had to accept the C rule that global names are by default accessible from other compilation units. There simply wasn’t any support for the more restrictive C++ rule. This meant that C++, like C, lacked an effective mechanism for expressing modularity above the level of the class and the file. This led to a series of complaints until the ANSI/ISO committee accepted namespaces (§17) as the mechanisms to avoid name space pollution. However, Doug McIlroy and others argued that C programmers would not accept a language in which every object and function meant to be accessible from another compilation unit had to be explicitly declared as such. They were probably right at the time and saved me from making a serious mistake. I am now convinced that the original C++ solution wasn’t elegant enough anyway.
One problem with compatibility issues is that there always seem to be two camps that are so sure of their views they hardly feel the need to argue their cases. The first camp demands 100% compatibility – often without having understood the implications. For example, many who demand 100% C compatibility are surprised to learn that this would imply incompatibilities with existing C++ that would cause tens of millions of lines of C++ code to stop compiling. In many cases, the demand for 100% compatibility is based on the assumption that C++ has few users. It is also not unusual for people to hide ignorance of C++ or dislike of newer features behind a demand for 100% compatibility.
The other camp can be equally annoying by declaring C compatibility a non-issue and arguing for new features that would seriously inconvenience people who want to mix C and C++ code. Naturally, the more extreme claims of each camp make the other camp even further entrenched out of fear of losing aspects of a language they care about. Where – as almost always – cooler heads prevail and the needs of the people involved and the actual facts of C and C++ usage are taken into account, the debates usually converge on the more constructive examination of the minutiae of the compromise. At the organizational meeting of the X3J16 ANSI committee, Larry Rosier, the original ANSI C committee editor, explained to a skeptical Tom Plum, “C++ is C as we tried to make it, but couldn’t.” This is probably an overstatement, but not too far from the truth for the common subset of C and C++.
3.13 Tools for Language Design
Theory and tools more advanced than a blackboard have not been given much space in the description of the design and evolution of C++. I tried to use Y ACC (an LALR(l) parser generator [Aho,1986]) for the grammar work, and was defeated by C’s syntax (§2.8.1). I looked at denotational semantics, but was again defeated by quirks in C. Ravi Sethi had looked into that problem and found that he couldn’t express the C semantics that way [Sethi, 1980].
The main problem was the irregularity of C and the number of implementation-dependent and undefined aspects of a C implementation. Much later, the ANSI/ISO C++ committee had a stream of formal definition experts explain their techniques and tools and give their opinions of the extent to which a genuine formal approach to the definition of C++ would help us in the standards effort. I also looked at the formal specifications of ML and Modula-2 to see if a formal approach was likely to lead to a shorter and more elegant description than traditional English text would. I don’t think that such a description of C++ would be less likely to be misinterpreted by implementers and expert users. My conclusion is that a formal definition of a language that is not designed together with a formal definition method is beyond the ability of all but a handful of experts in formal definition. This confirms my conclusion at the time.
However, abandoning hope of a formal specification left us at the mercy of imprecise and insufficient terminology. Given that, what could I do to compensate? I tried to reason about new features both on my own and with others to check my logic. However, I soon developed a healthy disrespect for arguments (definitely including my own) because I found that it is possible to construct a plausible logical argument for just about any feature. On the other hand, you simply don’t get a useful language by accepting every feature that makes life better for someone. There are far too many reasonable features and no language could provide them all and stay coherent. Consequently, wherever possible, I tried to experiment.
Unfortunately, you usually cannot conduct proper experiments either. It is not possible to provide full-scale systems with implementation, tools, and education and have some people use the one and some people use the other and measure the differences. People are too different, projects are too different, and suggested features mutate during the effort to define, implement, and explain them. So I used the effort to define, implement, and explain features as a design aid. Once a feature was implemented, I and a few others used it and I tried as best I could to be highly suspicious of any positive claims made. As far as possible, I relied on the opinions of experienced programmers considering real applications only. Thus, I tried to compensate for the fundamental limitations of my “experiments.” These experiments were usually only comparisons of implementations, examinations of quality of source code for small examples, together with run-time and space measurements on those examples. At least I had feedback in the design process so I could rely on experience rather than on pure thought alone. I firmly believe that language design isn’t an exercise in pure thought, but a very practical exercise in balancing needs, ideals, techniques, and constraints. A good language is not merely designed, it is grown. The exercise has more to do with engineering, sociology, and philosophy than with mathematics.
In retrospect, I wish I had known a way of formalizing the rules for type conversion and argument matching. This topic has proven very hard to get right and to document unambiguously. Unfortunately, I suspect that no rational and general formalism would be able to deal with the very irregular C rules governing the built-in types and operators in a convenient manner.
There is a great temptation for a language designer to provide features and services where the alternative is for users to use a workaround. The screams when an addition is rejected are usually far louder than the complaints that “yet another useless feature has been added.” This is also a serious problem for standards committees (§6.4). The worst variant of this argument is the cult of orthogonality. Many people feel that if the language would be more orthogonal if it provided a feature, then that is a conclusive argument for accepting that feature. I agree that orthogonality is a good thing in principle, but note that it also carries costs. Usually, despite all good intentions about orthogonality, the definition of a combination of features does require extra work on the manual and the tutorial material. Most often, implementation of combinations prescribed by the ideal of orthogonality is harder than people realize. In the case of C++, I always considered the run-time and space cost of orthogonality for people who did not use a combination. If that cost couldn’t at least in principle be made zero, I was most reluctant to admit the feature – however orthogonal. Thus orthogonality is a secondary principle – after the primary but subjective concerns of utility and efficiency.
My impression was and is that many programming languages and tools represent solutions looking for problems, and I was determined that my work should not fall into that category. Thus, I follow the literature on programming languages and the debates about programming languages primarily looking for ideas for solutions to problems my colleagues and I have encountered in real applications. Other programming languages constitute a mountain of ideas and inspiration – but it has to be mined carefully to avoid featurism and inconsistencies. The main sources for ideas for C++ were Simula, Algol68, and later Clu, Ada, and ML. The key to good design is insight into problems, not the provision of the most advanced features.
3.14 The C++ Programming Language (1st edition)
In the autumn of 1984, my next-door neighbor at work, A1 Aho, suggested that I write a book on C++ structured along the lines of Brian Kernighan and Dennis Ritchie’s The C Programming Language [Kernighan, 1978] based on my published papers, internal memoranda, and the C++ reference manual. Completing the book took nine months. I completed the book mid-August 1985 and the first copies appeared mid-October. Thanks to a curiosity in the US publishing industry the book has a 1986 copyright.
The preface mentions the people who had by then contributed the most to C++: Tom Cargill, Jim Coplien, Stu Feldman, Sandy Fraser, Steve Johnson, Brian Kernighan, Bart Locanthi, Doug McIlroy, Dennis Ritchie, Larry Rosier, Jerry Schwarz, and Jonathan Shopiro. My criterion for adding a person to that list was that I was able to identify a specific C++ feature that the person has caused to be added.
The book’s opening line, “C++ is a general-purpose programming language designed to make programming more enjoyable for the serious programmer,” was deleted twice by reviewers who refused to believe that the purpose of programming-language design could be anything but some serious mutterings about productivity, management, and software engineering. However,
“C++ was designed primarily so that the author and his friends would not have to program in assembler, C, or various modern high-level languages. Its main purpose is to make writing good programs easier and more pleasant for the individual programmer.”
This was the case whether those reviewers were willing to believe it or not. The focus of my work is the person, the individual (whether part of a group or not), the programmer. This line of reasoning has been strengthened over the years and is even more prominent in second edition [2nd] where design and software development issues are discussed in greater depth.
The C++ Programming Language was the definition of C++ and the introduction to C++ for an unknown number of programmers, and its presentation techniques and organization (borrowed with acknowledgments if not always sufficient skill from The C Programming Language) have become the basis for an almost embarrassing number of articles and books. It was written with a fierce determination not to preach any particular programming technique. In the same way I feared to build limitations into the language out of ignorance and misguided paternalism, I didn’t want the book to turn into a manifesto for my personal preferences.
3.15 The Whatis? Paper
Having shipped Release 1.0 and sent the camera-ready copy of the book to the printers, I finally found time to reconsider larger issues and to document overall design issues. Just then, Karel Babcisky (the chairman of the Association of Simula Users) phoned from Oslo with an invitation to give a talk on C++ at the 1986 ASU conference in Stockholm. Naturally, I wanted to go, but I was worried that presenting C++ at a Simula conference would be seen as a vulgar example of self-advertisement and an attempt to steal users away from Simula. After all, I said, “C++ is not Simula so why would Simula-users want to hear about it.” Karel replied, “Ah, we are not hung up on syntax.” This provided me with an opportunity to write not only about what C++ was but also what it was supposed to be and where it didn’t measure up to those ideals. The result was the paper What is “Object-Oriented Programming?” [Stroustrup, 1986b]. An extended version was presented to the first ECOOP conference in June 1987 in Paris.
The significance of this paper is that it is the first exposition of the set of techniques that C++ was aiming to provide support for. All previous presentations, to avoid dishonesty and hype, had been restricted to describe what features were already implemented and in use. The “whatis paper” defined the set of problems I thought a language supporting data abstraction and object-oriented programming ought to solve and gave examples of language features needed.
The result was a reaffirmation of the importance of the “multi-paradigm” nature of C++:
“Object-oriented programming is programming using inheritance. Data abstraction is programming using user-defined types. With few exceptions, object-oriented programming can and ought to be a superset of data abstraction. These techniques need proper support to be effective. Data abstraction primarily needs support in the form of language features, and object-oriented programming needs further support from a programming environment. To be general purpose, a language supporting data abstraction or object-oriented programming must enable effective use of traditional hardware.”
The importance of static type checking was also strongly emphasized. In other words, C++ follows the Simula rather than the Smalltalk model of inheritance and type checking:
“A Simula or C++ class specifies a fixed interface to a set of objects (of any derived class), whereas a Smalltalk class specifies an initial set of operations for objects (of any subclass). In other words, a Smalltalk class is a minimal specification and the user is free to try operations not specified, whereas a C++ class is an exact specification and the user is guaranteed that only operations specified in the class declaration will be accepted by the compiler.”
This has deep implications for the way one designs systems and for what language facilities are needed. A dynamically typed language such as Smalltalk simplifies the design and implementation of libraries by postponing type checking to run time. For example (using C++ syntax):
void f() // dynamic checking only, not C++
{
stack cs;
cs.push(new Saab900);
cs.pop()->takeoff(); // Oops! Run-time error:
// a car does not have a
// takeoff method.
}
This delayed type-error detection was considered unacceptable for C++, yet there had to be a way of matching the notational convenience and the standard libraries of a dynamically typed language. The notion of parameterized types was presented as the (future) solution for that problem in C++:
void g()
{
stack(plane*) cs;
cs.push(new Saab37b); // ok a Saab37b is a plane
cs.push(new Saab900); // error, type mismatch:
// car passed, plane* expected.
cs.pop()->takeoff(); // no run-time check needed
cs.pop()->takeoff(); // no run-time check needed
}
The key reason for considering compile-time detection of such problems essential was the observation that C++ is often used for programs executing where no programmer is present. Fundamentally, the notion of static type checking was seen as the best way of providing as strong guarantees as possible for a program rather than merely a way of gaining run-time efficiency.
This is partly a special case of the general notion that what can be guaranteed by machine and from general rules shouldn’t be done by people and by debugging. Naturally, it also helps debugging. However, the most fundamental reason for relying on statically checked interfaces was that I was – as I still am – firmly convinced that a program composed out of statically type-checked parts is more likely to faithfully express a well-thought-out design than a program relying on weakly-typed interfaces or dynamically-checked interfaces. Please remember though, that not every interface can be exclusively statically checked and that static checking doesn’t imply the absence of errors.
The “whatis” paper lists three aspects in which C++ was deficient:
[1] “Ada, Clu, and ML support parameterized types. C++ does not; the syntax used here is simply devised as an illustration. Where needed, parameterized classes are “faked” using macros. Parameterized classes would clearly be extremely useful in C++. They could easily be handled by the compiler, but the current C++ programming environment is not sophisticated enough to support them without significant overhead and/or inconvenience. There need not be any run-time overheads compared with a type specified directly.”
[2] “As programs grow, and especially when libraries are used extensively, standards for handling errors (or more generally: “exceptional circumstances”) become important. Ada, Algol68, and Clu each support a standard way of handling exceptions. Unfortunately, C++ does not. Where needed, exceptions are “faked” using pointers to functions, “exception objects,” “error states,” and the C library signal and longjmp facilities. This is not satisfactory in general and fails even to provide a standard framework for error handling.”
[3] “Given this explanation, it seems obvious that it might be useful to have a class B inherit from two base classes Al and A2. This is called multiple inheritance.”
All three facilities were linked to the need to provide better (that is, more general and more flexible) libraries. All are now available in C++ (templates, §15; exceptions, §16; multiple inheritance, §12). Note that adding multiple inheritance and templates was considered plausible directions for further evolution as early as [Stroustrup, 1982b]. That paper also mentions exception handling as a possibility, but I was worried rather than positive about the possible need to move in that direction.
As usual, I pointed out that demands on run-time and space efficiency, and of the ability to coexist with other languages on traditional systems provided “limits to perfection” that could not be violated by a language claiming to be “general purpose.”