
Chapter 5
Task #3: Map Your Source Systems to the Data Vault Design
We’ve looked at a case study involving Fire Trucks assigned to Fires. That nice little example may be helpful as an introduction to Data Vault, but it has two huge, gaping holes:
- It looks at sourcing data for the Data Vault from a single operational system. Arguably one of the most important duties for a Data Vault is to facilitate integration of data from multiple sources. This chapter presents the mechanics of loading data into a Data Vault, and then describes “Task #3” by presenting guidelines for mapping raw source data into the Data Vault.
- It talks of getting data into a Data Vault, but ignores an essential aspect behind the existence of a Data Vault – getting data assembled for easy consumption by business people, which is where the Data Vault needs to focus if it’s going to be applauded for delivery of tangible value to the business. The mechanisms for using “business rules” to transform data are addressed as part of the next chapter, “Task #4”.
Understanding Data Vault by understanding data loading
Perhaps it’s a bit like peeling an onion – we can learn about how Data Vault works one layer at a time. We’ve looked at the raw building blocks of Data Vault. We now will reinforce that earlier learning, but importantly we will go further and look at the interaction of multiple sources of potentially conflicting data, considering how data from multiple sources gets stored in the raw Data Vault, and how the sometimes inconsistent values are resolved by applying business rules to generate new instances in the Data Vault.
This section is a bit labored. It aims to offer a view into the internal workings of the Data Vault engine, and to do so takes a scenario and simulates the resultant database contents. If that’s the way you like to learn, by lifting the lid and seeing what’s happing under the bonnet, please read on. For others, this might be something you are happy to skip. I simply want to give you a choice for a deeper dive if it will assist.
The case study expanded
This time, we’ve got two operational source systems that provide source data feeds to the Data Vault, and we’re going to walk through some explicit source data samples, simulating the act of loading them to the Hubs, Links, and Satellites.
The first source is the Fleet Management system. It records the vehicles owned or leased by the emergency response organization. These vehicles include fire trucks, of course, but also included are vehicles such as the company cars driven by senior management.
The second source system is the Shared Resource Pool system. In my home state, we have government funded emergency response organizations. We also have a volunteer fire brigade, resourced by magnificent men and women who not only freely give their time to protect the community, but they also put their lives at risk, for us. When it comes to responding to a wildfire, it’s all hands to the pumps (literally sometimes). For accountability and decision-making purposes, there are clear lines as to which organization is in charge of the emergency response, but for the sake of this example, resources such as fire trucks can be seen as belonging to a shared pool of resources, available for deployment to the most needy emergency.
Then there are other companies who have their own localized fire response resources. For example, out in our west we have massive plantations of pine forests. These forestry companies may choose to make their limited resources available for the common good. It is better for the community to have a fire stopped 20 kilometers from the plantation, and believe me, it’s better for the plantation company to stop the fire well before it gets to the edge of their land.
And finally, there are private individuals who sign up to have their equipment made available if required. Yes, that may include fire trucks from individual farmers, but it goes much further than just fire trucks. I had a fire escape route cut through trees on my own place. Phil, the bulldozer driver, has often made his dozer available for emergency response support, but it can get pretty scary. One time winds changed suddenly, and he had to quickly clear away flammable vegetation on a tiny patch of land, then hide behind the dozer’s massive blade to protect himself from being killed. He survived, but this is just one of many stories I could share of the brave people behind the simple concept of a Shared Resource Pool system.
The Fleet Management system includes more than just Fire Trucks, as does the Shared Resource Pool, but we will limit the scenario below just to Fire Trucks for simplicity.
Figure 80: Overlapping data – Fire Trucks

Figure 80 above highlights how separate source system data feeds can share data subject areas, but not necessarily with a 100% overlap; if we’ve got two systems holding information about fire trucks, not all fire trucks known in one system will necessarily be known in the other. The Fleet Management system might include fire trucks that, at a point in time, aren’t also in the Shared Resource Pool system because they’re not yet ready for deployment at a fire. Maybe they still need to be fitted with special purpose radios, and have their roof numbers painted. Or maybe they are actually ready for deployment, and the Fleet Management system fire trucks should have also been loaded into the Shared Resource Pool system, but the process to synchronize the systems has failed and certain fire trucks are only known in the Fleet Management system.
Conversely, the Shared Resource Pool system will have fire trucks that have been loaded but that are not known in the Fleet Management system, if for no other reason than these shared resource fire trucks are owned by another organization and will never be entered into the prime organization’s Fleet Management system.
That’s set the scene. Now let’s carefully go through some hypothetical data that will expose the next layer of understanding behind a Data Vault solution, by simulating the code for loading the data, and looking at the tables’ contents after the load.
Populating Hubs
We go back to where we started, with a Hub for Fire Trucks.

Now we’ve also got some sample data we want to load to the Fire Truck Hub. We begin with sample data from the Fleet Management system. It is a simple extract of all of the rows in the source system’s table. On January 1st, there are only two fire trucks in the entire Fleet Management system. The extract looks like this:
Table 2: Fleet Management source data January 1st

The logic, or pseudo code, for loading any Hub goes something like this for each consecutive row read from the source:
- If the Business Key (in this case, the Registration Number of the Fire Truck) does not already exist in the target Hub, create an instance in the Hub with the sourced Business Key
- Else (if the Business Key already exists in the target Hub), do nothing with this row
Note that for loading the Fire Truck Hub, only the Registration Number is considered; the other data attributes will come into play when we consider Satellites, but for now we can ignore them.
Pretty simple?
Additional data is provided during the load, such as:
- A computed Hash Key, using the Business Key as input to the hashing algorithm (for the sake of simplicity in this case study, the source text string is shown instead of the long and complex hash result).
- Load Date / Time (again for the sake of simplicity, the values only capture hours and minutes, but not seconds, let alone decimal parts of seconds).
- A code to represent the Record Source (again simplified in this example to the code FM/FT to represent the Fleet Management system’s Fire Truck extract).
In this case study hypothetical, the Data Vault (and hence the Fire Truck Hub table) was empty before the load process was run, therefore every Registration Number in the source system must cause the creation of a new instance in the Hub table. The resultant contents in the Fire Truck Hub might now look as follows:
Table 3: Fire Truck Hub January 1st

Easy so far? Now we come to the second day. The full extract from the source data feed looks like the following (with some of the more interesting entries highlighted):
Table 4: Fleet Management source data January 2nd

Note:
- Fire Truck AAA-111 has had no changes; the pseudo code will say that the Business Key already exists in the Hub, so there is no action required.
- Fire Truck BBB-222 has had its Fuel Tank Capacity changed from 55 to 60. This can be expected to result in some action in a related Satellite, but the pseudo code for the Hub only looks at the Business Key, BBB-222, which already exists in the Hub, so again there is no action required.
- Fire Truck CCC-333 is new. The pseudo code notes that the Business Key does not exist, so will add it.
The resultant contents in the Fire Truck Hub might now look as follows, with the entry for Fire Truck CCC-333 showing it was loaded to the Data Vault on January 2nd at 1:00am:
Table 5: Fire Truck Hub January 2nd at 1:00am

Note that the Load Date / Time for Fire Truck AAA-111 records the “first seen” timestamp of January 1st; it is not updated to record the fact it was later seen again on January 2nd.
OK, so we’ve performed a few Hub loads from one source system. How do things change when we introduce a second source? Let’s look at a data feed from the Shared Resource Pool system we spoke about earlier. A full extract on January 2nd holds the following information:
Table 6: Shared Resource Pool source data January 2nd
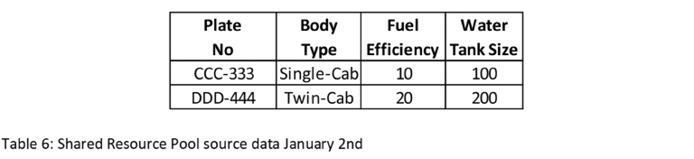
Let’s note that, as described in the case study introduction, there are partial overlaps in the Fire Trucks represented by the two systems.
- Fire Trucks AAA-111 and BBB-222 are in the Fleet Management system, but have not (yet) been made available for deployment via the Shared Resource Pool system.
- Fire Truck CCC-333 is in the Fleet Management system and in the Shared Resource Pool system.
- Fire Truck DDD-444 may be a privately owned farmer’s fire truck. It is available in the Shared Resource Pool system, but because it is not owned or leased by the corporation, it will never appear in the Fleet Management system.
Let’s think back to the pseudo code for loading a Hub. Even though Fire Truck CCC-333 is presented to the Data Vault by a different system, the Business Key already exists and no action is required. Fire Truck DDD-444 has not yet been seen by the Data Vault, and it is loaded. If the load time on January 2nd was 1:00am for the Fleet Management system, and 2:00am for the Shared Resource Pool system, the Fire Truck Hub might now look like:
Table 7: Fire Truck Hub January 2nd at 2:00am

Note that the Record Source for the Fire Truck DDD-444 is “POOL” (a code for the Shared Resource Pool system).
Now here’s a trick question. What difference, if any, might be observed if the load sequence on January 2nd was reversed, with the Shared Resource Pool loading first at 1:00am and the Fleet Management system loading afterwards at 2:00am? The answer is below:
Table 8: Fire Truck Hub (reversed load sequence)

When the Shared Resource Pool load was executed at 1:00am, Fire Truck CCC-333 did not exist, so would have been created. In this variation, the “First Seen” information for Fire Truck CCC-333 would note that the “First Seen” Record Source was “POOL” rather than “FM/FT”.
Populating a Hub’s Satellites
Hubs are at the very heart of business-centric integration. If multiple sources hold data about the same “thing”, all of their data values are held in Satellites that hang off the one central, shared Hub.
The “good practice” default design is to have (at least) one separate Satellite for each source data feed. I say “at least one” because sometimes a Satellite is split further, for example to move attributes with frequently changing values into their own Satellite. But for the sake of simplicity, we will look a bit deeper into how population of Satellites works with one Satellite per source.
We’ve already seen some sample data, but it’s repeated here for convenience, starting with the data that was used to commence the population of the Fire Truck Hub.
Table 9: Fleet Management source data January 1st

When we used this data to create rows in the Fire Truck Hub, we were only interested in the business key values from the Registration Number column. Now the focus shifts to the current values for the Fire Truck’s other attributes. We need a Satellite to hold them.
The logic, or pseudo code, for loading any Satellite against a Hub goes something like this for each consecutive row read from the source:
- If attribute values in the source load are different from what’s already on file for the Business Key (either because the values have changed since the last load, or because it’s the first load and there’s nothing there yet!), create a row in the Satellite.
- Else (if the same data values as are found in the source load already exist in the Satellite for the current Business Key), do nothing with this row
Figure 82: Fire Truck Satellite for Fleet data

Again, the logic is pretty simple, and as for Hubs, we record the Load Date / Time and the Record Source to aid in auditing. Note that the Load Date / Time is part of the Satellite’s Primary Key, so we end up with snapshots of the data values each time any of the values presented to the Data Vault change.
Though not shown here, one of the optional extras for a Satellite table is a Hash Difference attribute. The pre-processing in the Staging Area can calculate a hash value across the entire combination of values (in this case, the Vehicle Type plus the Fuel Tank Capacity plus the Water Tank Capacity as a single text string). If this is stored in the Satellite, next time a new source row comes in (also with its hash value), instead of comparing every attribute to see if anything has changed, comparing the hash value as a single attribute achieves the same result.
The Fire Truck Satellite for data sourced from the Fleet Management system was empty before the first day’s processing began, but will now look like this:
Table 10: Fire Truck Satellite for Fleet Management, after load on January 1st

That was not too challenging – no data existed prior to the load, so the “first seen” values are simply created. Now things get a little bit more interesting as we load the second day’s data. Again for convenience, the second day’s data from the Fleet Management system is repeated here:
Table 11: Fleet Management source data January 2nd

Let’s think through the logic of the pseudo code for each row.
- Fire Truck AAA-111 has had no changes. The pseudo code will conclude that all of the data attribute values for Business Key AAA-111 already exist in the Satellite, so no action is required.
- Fire Truck BBB-222 has had its Fuel Tank Capacity changed from 55 to 60. The pseudo code will note that at least one value has changed, so will write a new row to the Satellite table.
- Fire Truck CCC-333 is new. The pseudo code notes that the data attribute values have changed (because none existed before!), so will create a new Satellite row.
The resultant contents in the Fire Truck Satellite for data sourced from the Fleet Management system might now look as follows. Note that there are two rows for Fire Truck BBB-222, one being the initial snapshot on January 1st, the other being the more recent snapshot on January 2nd, with one data value (Fuel Tank Capacity) changed from 55 to 60.
Table 12: Fire Truck Satellite for Fleet Management, after load on January 2nd

When we looked at loading Hubs, we deliberately introduced a data feed from a second source. A repeated copy of the sample data follows:
Table 13: Shared Resource Pool source data January 2nd

When we load Hubs, the data instances can overlap. For example, Fire Truck CCC-333 is known in both systems. However, when we load Satellites, if we follow the guidelines and we define a separate Satellite for each source data feed, life is simpler. Our data model might look like the model in Figure 83.
Loading the data sourced from the Shared Resource Pool system to its Fire Truck Satellite would result in the following:
Table 14: Fire Truck Satellite for Shared Resource Pool, after load on January 2nd

Figure 83: Fire Truck Satellite for Fleet and Pool data

It is worth noting that the types of attributes held about fire trucks are different between the two systems, and even where they appear to be the same, they can have different names for the attributes. Many practitioners suggest that the attributes in a Satellite loaded from a raw source data feed should align with data structures in the source systems rather than use the more business-friendly names we would hope to see in business-centric Data Vault Satellite structures. Two arguments I have encountered for this approach that I think have real merit are:
- Easier traceability of data back to the source systems (though this should also be achievable by other data mapping mechanisms).
- Support for data consumers who already have familiarity with source system data structures.
Populating Links
You might remember the skeleton Data Vault model we presented earlier for the introductory case study? When the Satellites are removed, it looked like:
Figure 84: “Fire” data model - Data Vault Hubs and Links

We’ve been loading Hubs and their Satellites for Fire Trucks. Let’s assume we have likewise been loading Hubs and their Satellites for Fires. To bring the two Hubs together, we now need to load the Fire-Truck-Assigned-To-Fire Link.
In the hypothetical case study, there are two ways an assignment of a Fire Truck to a Fire can occur.
The first method is driven by a logistics officer at the Fire itself. He or she sees a need, and submits a request to acquire a Fire Truck from the shared resource pool. They try to “pull” a resource from the pool so that they can put the fire truck under their direct control. Their data entry screen might look something like:
Figure 85: Resource Acquisition screen

In this case, the logistic officer has requested the assignment of Fire Truck CCC-333 to the Fire WF123, starting from February 2nd, with the assignment to be indefinite.
(For my northern hemisphere friends, please remember that February is in our Australian summertime. The most recent fire that put my own house at risk was one February when it reached 46 degrees Celsius, or 115 degrees Fahrenheit. And that was in the shade!)
You may remember that the source data for populating the Fire Truck’s Hub had lots of data in addition to the Registration Number business key, but for a Hub, we were only interested in the business key, because the attribute values were managed by the Hub’s Satellites. We’ve got a similar scenario here. The assignment transaction provides two business keys (Fire Truck CCC-333 and Fire WF123), and also two contextual data attributes (a “From” date and a “To” date), but for populating the Link, we only need the participating business keys; the attribute values are managed by the Link’s Satellites.
To spotlight some of the flexibility of a Data Vault, while we had nightly batch loads populating the Fire Truck Hub, let’s assume the resource assignment function needs to be much more dynamic. The sample screen above could be a web-based screen, with the service running on top of an enterprise service bus, in real time. If the operation represented by Figure 85 were to execute at 12:33 on February 2nd, with an almost immediate load into the Data Vault, the resultant Fire-Truck-Assigned-To-Fire Link could look like:
Table 15: Fire-Truck-Assigned-To-Fire Link February 2nd

Just as a refresher on the use of hash keys:
- Instead of storing the actual business key of “CCC-333” for the Fire Truck participating in this Link, we store its hash key value. This is a Foreign Key that points directly to the Fire Truck Hub that contains a row for Fire Truck CCC-333, identified via whatever is its long hashed value.
- Similarly, instead of storing “WF123” for the participating Fire, we store its Foreign Key which is also a hash value.
- Last but not least, we have the Primary Key for the Link itself. In business terms, the Link is identified by combining the business keys of all participating Hubs. We could represent the Fire Truck + Fire resultant text string as “CCC-333|WF123”. We then pretend the hashing algorithm takes this text string and spits out some meaningless hash value, which we use as the internal representation of the Primary Key for the Link.
Now to finish off commenting on the contents of this Link instance:
- The hypothetical that says that the Record Source for this Link is code ER/RA, representing the Emergency Response system’s Resource Acquisition function.
- The real-time transaction occurred at 12:33, and the Load Date Time for the arrival of this data into the Data Vault was one minute later, at 12:34. In reality, the latency can be mere seconds.
We’ve looked at one of the real-time functions. It “pulls” resources from the Shared Resource Pool into the control of those managing the fire. Our second hypothetical method for resource acquisition is driven by a resource manager responsible for the shared resource pool. He or she hears of a Fire that’s escalating, and sometimes proactively releases one of the Fire Trucks for use by the fire crew. He or she “pushes” one of their nominated resources out to the Fire. A possible representation of their screen follows:
Figure 86: Resource Release function

In this hypothetical, the resource manager has assigned Fire Truck CCC-333 to the Fire WF123, starting from February 2nd, but with a maximum assignment period, ending on April 4th. This action is performed at 13:57, a bit over an hour after the request had come from the logistics officer belonging to the fire management team.
One thing you may have picked up from the two screen snapshots in Figure 85 and Figure 86 is that they both refer to exactly the same business keys. Maybe the Fire Truck and the Fire attributes appear in a different order on the screen, and the person doing the data entry has a very different “push” versus “pull” view of their world, but at the end of the day, either way Fire Truck CCC-333 gets assigned to a Fire WF123.
You may recall that for Hubs, each Hub instance stores details of “first seen” information; it records the Record Source of the first source to present the business key to the Hub, and any other subsequent sources presenting the same business key are ignored. In this scenario, the Link instance likewise stores details of “first seen” information; it records the Record Source of the first source to present the set of business keys to the Link, and any other subsequent sources presenting the same set of business key are ignored. The pseudo code for loading Links is very similar to the pseudo code for Hubs. It goes something like this:
- If the set of Business Keys (in this case, the Registration Number of the Fire Truck plus the Fire Reference Number for the Fire), represented by a hash key computation, does not already exist in the target Link, create an instance in the Link with the sourced set of Business Keys
- Else (if the set of Business Keys already exists in the target Link), do nothing with this row.
It follows that if the operation represented by Figure 85 were to execute first (and also at the same time of 12:34), the results would be the same other than with a Record Source code of (say) POOL/RR, representing the Shared Resource Pool system’s Resource Request function.
Populating a Link’s Satellites
There are some differences of opinion within the Data Vault community on the topic of Satellites for Links, but most if not all accept at least the use of Satellites that record effective periods for the relationship, and for now we will restrict discussions on Link Satellites to this safer ground. Remembering that Satellites, whether for a Hub or a Link, are typically split by source system data feed, we want one Fire-Truck-Assigned-To-Fire Link for the relationship between Fire Trucks and Fires, plus one Satellite for the assignment details when sourced from the Shared Resource Pool’s Resource Release function, and another Satellite for the assignment details when sourced from the Emergency Response system’s Resource Acquisition function.
We’ve already looked at the first assignment transaction, depicted in Figure 85. It resulted in the creation of the Link instance as shown in Figure 87. What we now need is a snapshot of the data values at a point in time captured in the Satellite.
Figure 87: Resource assignment Satellites

The Satellite we want to populate as shown on the Data Vault model in Figure 87 above is the Satellite whose name includes “ERRA”, a short-form code indicating its data values are sourced from the Emergency Response system’s Resource Acquisition function. As part of the loading of this very first assignment transaction, we end up with the following:
Table 16: Assignment Effectivity Satellite for Emergency Response, after load on February 2nd

An hour later, we also add the first row to the Satellite whose name includes “Pool RR”, a short-form code indicating it data values are sourced from the Shared Resource Pool system’s Resource Release function. It is for the same Link, but has different values in its attributes – the requestor wanted an indefinite assignment, but the Resource Pool’s manager said they could have it from today, but only until April 4th rather than indefinitely.
Table 17: Assignment Effectivity Satellite for Shared Resource Pool, after load on February 2nd

The two Satellites hold different data that reflects what may be a conflict in the real world as to when the Fire Truck’s assignment ends, but they faithfully hold the facts as presented by the source system. That’s good. The Data Vault is now positioned to expose any apparent inconsistencies, and action can be taken to resolve the disagreements if required.
We now roll the clock forward. A month later, on March 3rd there’s a new fire, WF456. In response, the manager responsible for the Shared Resource Pool makes several decisions:
- The large Fire Truck, CCC-333, with a highly experienced crew, is reassigned from Fire WF123 and handed over to the new threat, WF456. This action has two parts:
- The assignment of Fire Truck CCC-333 to WF123 was intended to be up until April 4th, but the assignment is cut short, effective immediately.
- The formal assignment of Fire Truck CCC-333 to WF456 is also made.
- To backfill at the mopping up action for the original Fire, WF123, a smaller Fire Truck, DDD-444 is assigned to that Fire.
The resultant assignment transactions are loaded to the Data Vault:
Table 18: Assignment Effectivity Satellite for Shared Resource Pool, March 3rd

Note that the first row is an historic record of the original assignment of CCC-333 to WF123, and that the second row effectively replaces it with updated information. Also note that, over time, Fire WF123 has more than one Fire Truck assigned to it, and likewise, the one Fire Truck CCC-333 is, over time, assigned to more than one Fire. This is a simple example of the many-to-many nature of Links.

Some other data load considerations
Extracts versus Change Data Capture (CDC)
Many of the above examples were based on a full extract of all of the data from the nominated source system, every time. That’s safe and simple, but it’s not necessarily efficient. Some organizations I have consulted to have had more than ten million customers. If one hundred new customers have been added today, we’re processing 10,000,100 rows just to add 100 in the Customer Hub. Data Vault is robust, and doesn’t care if we present information it already knows about; it just ignores us! But are there more efficient ways?
Without going into lots of technical details, I will briefly explain two common approaches we may consider.
One approach is to play spot-the-difference in the staging area (“delta” processing), and only pass on to the Data Vault load whatever has changed. The staging area still has to process large volumes, but at least the Data Vault load job is smaller. And we can possibly share the Staging Area workload around a few servers.
Another approach is to turn on Change Data Capture (CDC), or similar, in our source system’s database. The database engine can observe inserts, updates, and deletes of rows in nominated tables, and inform the Staging Area of just things that have really changed. That can work well if our relational database management system supports CDC, if it’s an affordable feature (some database vendors charge extra for CDC), and if the data we want to present to our Data Vault maps nicely to just one source system table. If not, we may go back to full snapshots, maybe with some pre-processing in the Staging Area.
Restarting the load
Finally, before leaving the topic of loading data into a Data Vault, there’s the topic of restarting a load job that has failed to finish successfully. If none of the data presented to the Data Vault for processing was successfully loaded, it’s like running the load job for the first time. If all of the data was actually successfully processed, but we just think the job failed, re-running the load will see no changes needing to be applied, and the attempted re-load will do no harm, even if we run it a hundred times! And if some data had been processed and some hadn’t been, the bits that were processed will be ignored the second time through, and the bits that got missed will get successfully applied. Data Vault really is robust.
Doing the source-to-Data Vault mapping
Now we’ve had a closer look at the internal mechanics of a Data Vault as it loads raw data from a source system feed, let’s look at the essence of Task #3 – mapping source data to the Data Vault.
We start by taking a snippet from the example of conveyancing (buying and selling of properties). A purchaser need to borrow some money, and the business view of the Data Vault design looks something like the following.
Figure 88: A Purchaser and their Loan

Now let’s assume we have a source data feed from the Loan Management operational system. It might look something like the following.
Figure 89: Loan Management source data

If we mentally identify the business concepts and business keys, we can mark up the source data feed with “BK” (business key) tags.
Figure 90: Loan Management data, with Business Keys identified

Before we go any further, we can map the source feed to the Data Vault Hubs. Assuming we’ve got some tools to take our mapping and generate code, we’ve already got enough to drive the population of Hub instances.
Figure 91: Mapping raw data to (business-centric) Hubs

Next we note that the two Hubs identified by the business also have a Link identified by the business as a fundamental “business relationship”. We are in luck. The raw source has the same level of “grain” – the business-centric Link relates to two Hubs, and the raw source data feed also relates to the same two Hubs. It is not always so, but in this hand-picked example, we can map the raw source feed directly to a business-centric Link.
Figure 92: Mapping raw data to a (business-centric) Link

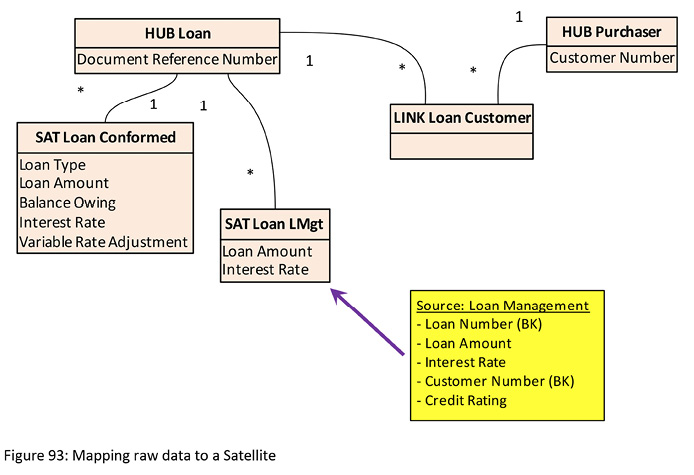
Now we’ve got some data in the raw source that needs to go in a Satellite somewhere. We’ve already designed a “business-centric” Satellite for the Loan Hub, called the Loan Conformed Satellite. If we could guarantee that the Loan Hub was only ever going to be fed from one source, maybe we could treat the Conformed Satellite as if it were the Satellite from a single source. However, we expect that the Loan Hub will have data coming in from multiple sources, with each source being given its own source-specific Satellite, so we design a new Satellite just for the “LMgt” (Loan Management) source, as shown in “Figure 93: Mapping raw data to a Satellite”. Though not shown in Figure 93, we would do likewise for a Satellite holding the Credit Rating attribute, hanging off the Purchase Hub.
It’s nice when life is simple, but it’s not always that way. If you’ve ever bought or sold a house, there’s the exciting day when “settlement” occurs (see Figure 94). And it can be pretty complicated. Behind the scenes, you’ve got the buyer (“Purchaser”) and the seller (“Vendor”). At the table, you might have the legal representatives for each of these two parties, and maybe their two banks. The vendor might reference a mortgage to be discharged, and the purchaser might reference a new mortgage to be registered. Then at the center is the land title being transferred. And maybe the purchaser’s mum and dad as guarantors for the loan, and on and on.
Figure 93: Mapping raw data to a Satellite
It’s no wonder that there are times settlements “fall over” on the day because some small but vital part doesn’t line up. A subset of this complexity is presented below, where a source system data feed has been marked up with Business Key (BK) tags.
Figure 94: Complex source data feed

In this feed alone, there are nine business keys identified. If we try to find a Link to match, you may hear people refer to a Link with a “grain” of nine. Realistically, the chances of finding a business-centric Link that perfectly matches are low. The solution? One approach we can adopt is to create a source-centric Link (with a Satellite) that matches the event / transaction being presented to us for mapping.
Figure 95: Complex source feed requiring a source-centric Link

The diagram is detailed, ugly, and hard to read. But the message is simple. If the business had already identified the Settlement transaction as a business concept with its own business key, it may have modelled Settlement as a Hub. But in this scenario, we have no such luck. Settlement is merely a transaction with no business key, and so it’s a Link, tied to a multitude of Hubs.
We’ve captured the data, and that’s good. But we may want to map some of the data to objects that are more business centric. For example, maybe the Loan Amount should be in a Satellite hanging off the Loan Hub, and maybe we want to record the business relationship between the Loan and the Purchaser in the business-centric Loan Customer Link. How do we do this? By using business rules to do some transformation of data. Please read on.