
Chapter 25
The Role of the IT Department in Daily Operations
25.1 INTRODUCTION
The information technology department of an investment firm has two primary responsibilities:
- Managing “business as usual” activities: These activities include:
– Ensuring that applications are stable
– Ensuring that applications can cope with normal business volumes
– Documenting deficiencies, fixing them and devising and documenting workrounds
– Ensuring appropriate data security
– Ensuring that system development keeps pace with user requirements
– Ensuring that systems integrate effectively
– Minimising manual intervention
– Dealing with data integrity issues appropriately
- Managing business change: These activities include:
– Aligning the IT strategy with business strategy
– Aligning delivered solutions with strategic business drivers
– Managing and monitoring the risks of introducing change
– Providing visibility of risk to stakeholders.
The department needs to manage these activities in such a way that it minimises operational risk. In Chapter 8 we saw the seven operational risk events that had been defined by Basel II:
- Internal fraud: Misappropriation of assets, tax evasion, intentional mismarking of positions, bribery
- External fraud: Theft of information, hacking damage, third-party theft and forgery
- Employment practices and workplace safety: Discrimination, workers’ compensation, employee health and safety
- Clients, products and business practice: Market manipulation, antitrust, improper trade, product defects, fiduciary breaches, account churning
- Damage to physical assets: Natural disasters, terrorism, vandalism
- Business disruption and systems failures: Utility disruptions, software failures, hardware failures
- Execution, delivery and process management: Data entry errors, accounting errors, failed mandatory reporting, negligent loss of client assets.
IT managers also need to be aware that major problems of the types described by the Basel Committee are often reported by the trade press, national press and television, which can lead to another type of risk – reputational risk.
25.2 USER SUPPORT AND HELPDESK MANAGEMENT
As part of its “business as usual” activity the department will normally need to set up a helpdesk to handle requests for assistance from its users. In a large organisation these requests will cover a very wide range of topics, which may be divided into the following categories:
- Planned administrative activities, such as:
– Provide a new user with a PC and/or appropriate software to run on that PC and/or usernames and passwords to run software applications
– Move one or more PCs or servers or other hardware items within the office
– Upgrade an item of hardware or software at an agreed date in the future
- Unplanned emergency activities, such as:
– An item of hardware or an application is not performing correctly and needs to be fixed to enable the user to continue normal daily operations
– An item of hardware or software has failed in the recent past and action needs to be taken to recover the problems that were created.
Such requests are often referred to as issues. The role of the helpdesk is therefore
1. To receive issues from users
2. To prioritise them
3. To pass them to the appropriate individuals for action
4. To monitor whether the issue has been actioned to the satisfaction of the requestor, and:
- If they have, to close the issues
- If they have not, to escalate them to management
5. To provide a database of “Frequently Asked Questions” that can be used by helpdesk staff in the future to deal with common queries
6. To provide statistical reports to management about the numbers of issues, and the severity of issues that are recorded:
- By different business units
- For different applications.
25.2.1 Recording and actioning issues
In many firms, issues are now recorded directly into a helpdesk management system by the users affected. Such systems have business rules that allow for the automatic logging of issues by the user concerned, and also:
- Provide a predefined series of issue types, priority codes, applications and environments for the reporting user to select from
- Based on the input into these predefined lists, automatically assign the problem to the correct individual or section
- Provide facilities for the section dealing with the issue to respond to the requestor by automated email when the issue has been actioned
- Provide facilities for the responder to provide details of the time spent dealing with a particular problem
- Provide facilities for issues of a particular type to follow a particular workflow pattern. For example, an issue that requires a software enhancement needs to be directed to:
– An analyst to decide what the software change needs to be, then
– A developer to make the change, then
– A test analyst to test the change, then
– The user who reported the issue to sign it off.
Figure 25.1 shows an example of an issue that has been entered into a helpdesk management system by a user. In this case, the item was entered into the JIRA system developed by Atlassian Software Systems Pty Ltd and is reproduced with Atlassian’s permission.
Figure 25.1 Entry of an issue in a helpdesk system.
Reproduced by permission of Atlassian Software Systems Pty Ltd.
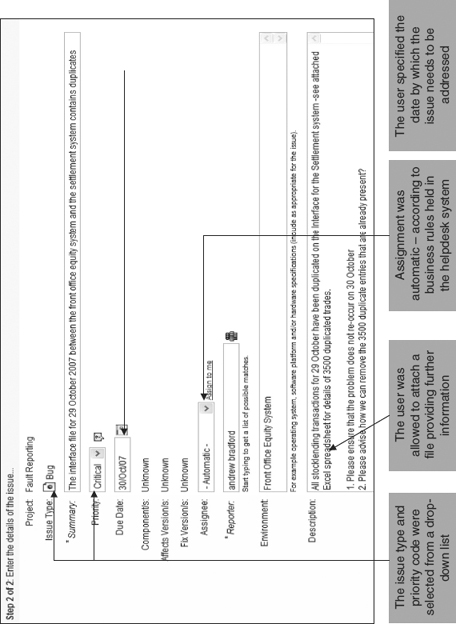
As soon as the user makes the entry in the helpdesk system the assignee will receive an email informing him of the new issue. Depending on the nature of the issue, the assignee will take one or more of the following actions:
1. Action it immediately
2. Diarise it for action at a later date
3. Respond to the user with requests for clarification
4. Delegate it to another individual
5. Provide an estimate for the effort required to handle the issue
6. Split the issue into two or more issues, or create subissues
7. Attach further documents to the issue.
The assignee records each action taken in the helpdesk system, and each time he makes an entry an email is automatically generated to the requestor informing him of the current state of the issue.
Note that in the example, the assignee is required to take two actions:
- To stop the problem occurring again
- To deal with the knock-on effects of the problem on 29 October – there are 3500 unwanted duplicate transactions in the settlement system that need to be removed before the close of business on 30 October.
The issue is therefore reporting two problems, both of which need to be addressed urgently. For this reason, it may be a good idea to split the issue into two issues, and delegate the handling of one of them to another individual.
If this problem was caused by a software or hardware fault, then the remedy may be a code change. If so, then the code needs to be changed, then tested, and finally released before the problem can be said to be resolved. Therefore, this issue may be assigned to several individuals during its lifecycle.
The final assignee (the person responsible for release) will then reassign it to the requestor, who will be notified by email. If the requestor is satisfied with the solution, he will close the issue; if he is not satisfied then he will note the reasons on the face of the issue report, and reassign it to the original assignee.
25.2.2 Helpdesk management
An effectively managed helpdesk is a prerequisite for minimising operational risk. If the helpdesk is being established for the first time, then the following information needs to be collated. This type of information is often known as an infrastructure catalogue, and includes full details of all the:
- Users that the desk supports. Key details include:
– Name, department, telephone number, email address and physical location
– Normal working hours and working days
- Applications that the desk supports. Key details include:
– Name of application
– Details of its role in the business
– Name and full contact details of the organisation that is responsible for supporting it. Note that this may be the firm’s IT department, or an external vendor. If it is an external vendor, then full details of any service level agreements need to be available to the helpdesk.
– Technical details – is it a PC application such as Word or Excel, or is it a web-based application that does not require installation in a user PC, or is it a client–server application employing a database?
– If it is a client–server application, what database is used, and what specific servers does it run on?
– Any requirements for specific version numbers for database and operating system software
– Hours during the day and days of the week on which there is expected to be activity. If there is a great deal of night-time activity in this application, then the desk will need to hold out of hours contact details, and perhaps rotas for support staff who may need to be contacted at home.
– An assessment as to how critical the loss of this application for an extended period would be to the business
- Hardware that the desk supports. Key details include:
– Locations of all servers and routers
– Whether they are used for production, testing or disaster recovery
– Which applications are running on each server.
Once the infrastructure catalogue has been built up, IT management needs to decide:
- Which applications are “critical” to the business
- Which applications need to be supported “around the clock” on normal working days and which need to be supported for shorter periods
- Which applications need to be routinely supported at weekends and on public holidays
- If round the clock support is required, then what is the best way to achieve it? The following models are commonly used.
–”Follow the sun“: This model is widely used by firms that have operations in more than one time zone, and users accessing the same applications and servers from different countries. During normal European working hours support for all users worldwide is provided from a European location. When Europe closes, support moves to a North American support centre, and when North America closes, support is handled by an Asian support centre.
– Extended working hours: This model is widely used when a firm is doing business in a single time zone, but is using applications that are working throughout the day and night. A singe helpdesk works in shifts. One shift coincides with normal working hours for the majority of the users, and is more heavily manned than the other shift, which only deal with emergency calls.
– Partial outsourcing: If the number of out of hours calls is expected to be very few in number but may be critical, then overnight manning of the helpdesk could be outsourced to a third party specialist firm. Outsourcing is examined in more detail in Chapter 27.
25.2.3 Service level agreements
The role of the helpdesk in supporting its users may be formally expressed in a service level agreement (SLA). An SLA is that part of a service contract in which a certain level of service is agreed upon. Level of service in this context refers to both the quality of the service and the time deadlines for performing the service. It may also specify penalties to be paid by either party if the level of service provided fails to reach the minimum standards in the agreement for an extended period of time.
The SLA is a fundamental tool from the perspective of both the supplier and the recipient in provision of a service. The quality of the service level agreement is a critical matter as it defines the relationship between all concerned parties.
The SLA itself must be of sufficient detail and scope in relation to the service being offered and the scale thereof.
Typical SLA sections are as follows:
- Introduction (parties, signatures, service description)
- Scope of work (service hours, support)
- Performance
- Tracking and reporting (content, frequency)
- Problem management (change procedures, escalation)
- Penalties and compensation payable when the actual service level falls below the agreed level
- Customer duties and responsibilities
- Warranties and remedies
- Security
- Intellectual property rights and confidential information
- Legal compliance and resolution of disputes
- Termination and signatures.
An SLA is a contract between the customer and the service provider. Internal SLAs are agreements set out among two groups within the same organisation while external SLAs involve external parties. Some securities companies provide a service to an external customer where they are assessed on their compliance to the SLA while other securities companies might outsource some of their non-essential business to an external vendor who is able to provide an agreed service.
Even if there is no formal (internal) SLA between the helpdesk and its customer business units, then the work of the helpdesk may be impacted by other external SLAs between the business units and the software vendors and outsourced service providers that supply the firm.
25.3 DATA SECURITY, DATA RETENTION, DATA PROTECTION AND INTELLECTUAL PROPERTY
25.3.1 Data security
The IT department is responsible for the safe storage of the firm’s data. Failure to do so may result in operational risk events such as internal fraud, external fraud and market manipulation. Market manipulation includes the offences of insider dealing and market abuse that were examined in Chapter 8.
ISO 17799 the international standard for information security
ISO 17799 is the de facto standard for the information security code of practice. It includes a number of sections, covering a wide range of security issues. In terms of legislation, the standard covers:
- Data protection and privacy of personal information
- Protection of organisational records
- Intellectual property rights.
In terms of defining common practice, the standard covers:
- Use of an information security policy document
- Allocation of information security responsibilities
- Information security awareness, training and education
- Correct processing in applications
- Technical vulnerability management
- Business continuity management
- Management of information security incidents and improvements.
The standard suggests that security requirements should be established through:
- Risk assessment
- Legal and regulatory contractual obligations
- Internal principles (objectives and requirements).
The standard also advises that a simple management model should be used consisting of “plan-do-check-act” (PDCA):
PLAN: Establish the objectives and processes necessary to deliver results in accordance with the specifications
DO: Implement the processes
CHECK: Monitor and evaluate the processes and results against objectives and specifications and report the outcome
ACT: Apply actions to the outcome for necessary improvement. This means reviewing all steps (Plan, Do, Check, Act) and modifying the process to improve it before its next implementation.
Chinese walls, insider dealing and market abuse
In Chapter 7 we learned that an investment bank will normally have a corporate finance department that is working with clients that may be issuing securities, attempting to acquire other companies or performing some corporate activity that may be price sensitive, and in Chapter 8 we examined the specific offences of insider dealing and market abuse. The corporate finance department that is advising the issuer cannot help but acquire inside information as part of its normal daily operations. If this information were to be made known to the dealing desks that buy and sell securities before it were made known to the general public, then it could very well result in insider dealing and/or market abuse. Both of these are offences in the United Kingdom, and similar legislation is enacted in many other jurisdictions.
Most securities firms will therefore need to implement Chinese walls between the relevant departments. Chinese walls are information barriers implemented within firms to separate and isolate people who make investment decisions from people who are privy to undisclosed material information which may influence those decisions.
In general, all firms are required to develop, implement and enforce reasonable policies and procedures to safeguard insider information, and to ensure no improper trading occurs. Although specific procedures are not mandated, adopted practices must be formalised in writing and must be appropriate and sufficient. Procedures should address the following areas: education of employees, containment of insider information, restriction of transactions and trading surveillance.
Depending on the policies that the firm has adopted, the role of the IT department in developing and implementing these policies is likely to include:
- Identifying the particular business applications where unauthorised or unrestricted access by individuals or other business applications would be likely to breach the wall
- Ensuring that all these applications utilise appropriate user access controls (usernames, passwords, etc.)
- Ensuring that user access to these systems is correctly monitored, and that the privileges that are granted to particular groups of users (for example, which accounts they can view from a particular enquiry) do not breach the principles of the Chinese wall.
25.3.2 Data retention
The firm will find itself subject to many different legal requirements concerning the preservation and retention of data. Most (but by no means all) legal requirements demand that records be retained for five years from the date of the event that created them. There are, however, exceptions to this. For example, some correspondence with private individuals about their pension arrangements has to be kept indefinitely and information about client categorisation under the MiFID regulations has to be kept for five years “after the firm ceases to carry on business with or for that client”.
The firm’s senior management is responsible for implementing data retention policies. Data in this context includes written materials, recordings of telephone conversations, microfiches, and electronic records of orders received and executed. Such electronic records include SWIFT messages, FIX protocol messages, files transferred by FTP and similar techniques and emails. It is the responsibility of the IT department to organise the safe storage of such records.
Records must be retained for the statutory period in a form that enables them to be accessed at any time before the end of that period. Because the statutory retention periods are very long, IT departments need to consider the problems that can be created by the introduction of new technologies. For example:
- Certain records may have, at some time in the past, been moved to offline storage in a form that is no longer widely used. For example, at the time when the record was first created, tape cartridges may have been a popular offline storage device, but most modern equipment does not read most of the tape cartridges that were in use in the early 1990s.
- Certain records are being held online, in a business application that is to be replaced. It is not practical to migrate every historic record from the old system to the new one because of the sheer number of records the old system holds. Once the new system is implemented there will no longer be any user access to the old system. If that is the case, then data may have to be extracted from the old system and stored, say, in a specially created SQL database in order that the firm’s data retention policies and legal requirements may be complied with.
There are now many companies that offer outsourced services connected with paper and electronic records management and consultancy services to help firms develop “compliant records management” policies. Many of the practical issues around records management are linked to the issues involved in developing a business continuity plan. Business continuity planning is covered in section 25.5.
25.3.3 Data protection
All countries in the EEA have data protection legislation. In the United Kingdom, the relevant Act is the Data Protection Act 1998. This act details how personal data should be managed by any kind of organisation (government, corporate, charity, etc.) to protect its integrity and to protect the rights of the persons concerned.
Any firm holding and processing personal data must appoint a data controller who takes responsibility for compliance with the Data Protection Act; the data controller must be registered with the Information Commissioner.
Principles of the Act
The Data Protection Act lays down eight principles of good data protection practice. It states that personal data shall:
- be processed fairly and lawfully;
- be obtained for one or more specified and lawful purposes, and shall not be further processed in any manner that is incompatible with those purposes;
- be adequate, relevant and not excessive in relation to the purpose or purposes for which it is processed;
- be accurate and, where necessary, kept up-to-date;
- not be kept for longer than is necessary for its purpose or purposes;
- be processed in accordance with the rights of the subject under the Act;
- be safeguarded by the use of appropriate technical and organisational measures to prevent unauthorised or unlawful processing of personal data, and against accidental loss or destruction of, or damage to, the personal data;
- not be transferred to a country or territory outside the European Economic Area (EEA), unless that country or territory ensures an adequate level of protection in relation to the processing of personal data.
Penalties for non-compliance with the Data Protection
Act The Act states that:
(1) An individual who suffers damage by reason of any contravention by a data controller of any of the requirements of this Act is entitled to compensation from the data controller for that damage.
(2) An individual who suffers distress by reason of any contravention by a data controller of any of the requirements of this Act is entitled to compensation from the data controller for that distress if–
(a) The individual also suffers damage by reason of the contravention, or
(b) The contravention relates to the processing of personal data for the special purposes.
(3) In proceedings brought against a person by virtue of this section it is a defence to prove that he had taken such care as in all the circumstances was reasonably required to comply with the requirement concerned.
But in addition to the compensation that a data owner may claim under the provisions of the Act itself, companies that are regulated by the FSA may face additional sanctions, as demonstrated by the following case study.
On 14 February 2007 the Financial Services Authority (FSA) fined Nationwide Building Society (Nationwide) £980 000 for failing to have effective systems and controls to manage its information security risks. The failings came to light following the theft of a laptop from a Nationwide employee’s home in 2006.
During its investigation, the FSA found that the building society did not have adequate information security procedures and controls in place, potentially exposing its customers to an increased risk of financial crime.
The FSA also discovered that Nationwide was not aware that the laptop contained confidential customer information and did not start an investigation until three weeks after the theft.
In a press release, the FSA said “Nationwide is the UK’s largest building society and holds confidential information for over 11 million customers. Nationwide’s customers were entitled to rely upon it to take reasonable steps to make sure their personal information was secure.”
“Firms’ internal controls are fundamental in ensuring customers’ details remain as secure as they can be and, as technology evolves, firms must keep their systems and controls up-to-date to prevent lapses in security. The FSA took swift enforcement action in this case to send a clear, strong message to all firms about the importance of information security.”
By agreeing to settle at an early stage of the FSA’s investigation Nationwide qualified for a 30% discount under the FSA’s executive settlement procedures – without the discount the fine would have been £1.4 million.
25.3.4 An IT perspective on the legal aspects of data management
It is useful within firms for information to be classified internally so that it is clear how the information needs to be protected, managed and destroyed. Typical classifications are generally accessible, internal use only, confidential and secret. Generally, the accessibility of information by users and systems should be safeguarded so that data is only disclosed on a need to know basis.
The retention of data is an issue that the securities industry is currently trying to tackle. While the Data Protection Act states that customer information should not be retained for longer than necessary, money laundering or anti-terrorism regulation might require that this information is stored for a significant length of time. In the maintenance of systems, the decision not to retain data or to delete it might lead to prosecutions, fines or reputation risk. The risk that data retention may be unmanageable because of technology changes is a real one.
Unfortunately, the potential data that can be requested for recall by authorities or regulators is also increasing in scope and can include emails, chat conversations, voice message and phone call records and recordings.
25.3.5 Intellectual property rights management
Intellectual property rights (IPR) are rights to intangible property that is the product of the human intellect. Intellectual property may be protected by copyright, trademark or patent.
Computer software is normally, but not exclusively, protected by copyright. The holder of intellectual property rights is usually the person or persons who developed the product or the organisation that funded it.
Any investment firm that is using any kind of packaged software will usually find that the vendor retains the IPR to the software. In the contract, there is usually an obligation on the firm (as the customer) to ensure that the vendor’s rights are maintained, and that confidentiality clauses are not breached.
This can become an issue if the firm wishes to outsource or offshore an activity that is dependent on the vendor’s package. The firm may need to ask the express permission of the vendor, or to sign a further agreement that protects the vendor’s interest.
The IPR for software that the firm developed itself, or commissioned an external vendor to produce explicitly for them, will normally belong to the firm itself. The application that has been created is the firm’s IPR, and this IPR may provide the firm with a competitive advantage.
In order to protect the IPR of both the firm itself and its package, vendors include a confidentiality clause in their employment contracts and contracts with external IT consultants. These contracts oblige the employee or consultant to keep IPR confidential. The clause that deals with these matters usually requests that such information be kept confidential indefinitely – not just for the period of the employment or consultancy assignment.
25.4 CHANGE MANAGEMENT
Change management or change control procedures are processes designed to prevent software or hardware objects from being amended without auditability and review of the impact by all interested parties. There are two aspects to change management; the use of version control systems to control access to items that need to be changed and the development of procedures that ensure that only authorised changes are made to software or hardware items.
25.4.1 Symptoms of inadequate change control management
Poor change control creates operational risk. In particular, they can create the following operational risk events as defined by Basel II:
Product defects, software failures, hardware failures, accounting errors, failed mandatory reporting, negligent loss of client assets.
The symptoms of poor change control include:
- The latest version of source code cannot be found.
- A difficult defect that was fixed at great expense suddenly reappears.
- A developed and tested feature is mysteriously missing.
- A fully tested program suddenly does not work.
- The wrong version of the code was deployed.
- The wrong version of the code was tested.
- There is no traceability between the software requirements, documentation and code.
- Programmers are working on the wrong version of the code.
- The wrong versions of the configuration items are being baselined.
- No one knows which modules comprise the software system delivered to the customer.
25.4.2 Version control systems
Version control systems (VCS) are software applications that manage multiple revisions of the same unit of information. In particular, they:
1. Prevent more than one developer working on a change to a program or other software object at the same time
2. Ensure that when a program or other object is selected for modification, there is an audit trail of who is modifying it
3. Ensure that the modifications are being made to the right version of the program
4. In the event that the wrong version of an object is released, these applications provide the ability to “roll back” to a prior version.
There are at least 50 different packaged systems that perform version control. Some of them are open source software that may be downloaded for no cash payment, and some are proprietary packages. Some are suitable for a wide variety of operating systems, while others are deigned for specific operating systems such as MS Windows or UNIX.
It is not only source code that may be protected by a version control system. Version control may be applied to user and technical documentation, key static data files and virtually any object within an application that needs to be protected.
A simplified view of how version control software applications work is shown by Figures 25.2 and 25.3.
Figure 25.2 Version control software – stage 1
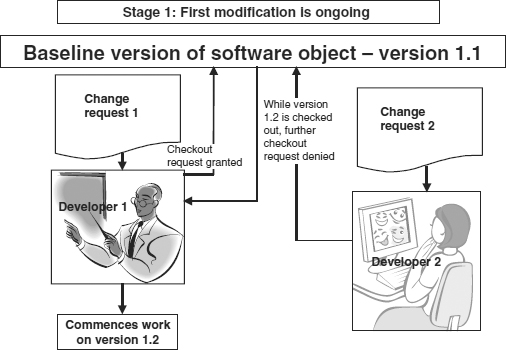
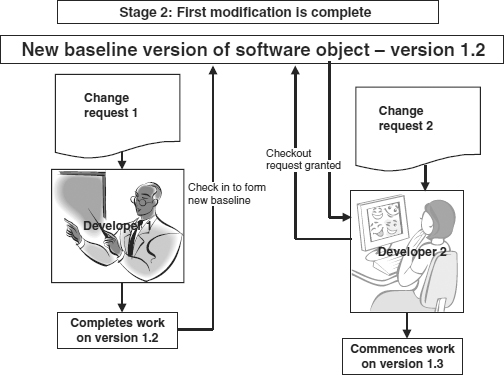
Figure 25.3 Version control software – stage 2
1. The VCS stores the current, latest version of the program (version 1.1 in this example) as the baseline version. All changes will be applied to this version so long as it remains the baseline version.
2. Developer 1 receives a change control request that requires amendment to this program. He requests the VCS to allow him to check it out, and starts work.
3. The VCS records the fact that Developer 1 is working on this object.
4. Developer 2 then receives a change request that applies to the same unit. She attempts to check the unit out, but permission is denied as Developer 1 has the record locked. She is left with two choices:
- To wait until Developer 1 has completed his work before she can commence her work; or
- To make a branching request to the VCS. A set of files under version control may be branched or forked at a point in time so that, from that time forward, two copies of those files may be developed at different speeds or in different ways independently of the other. Branching requests are usually only made when emergency fixes are needed, as versions that are branched will later on have to be merged. This may not be an easy process to control.
Assuming that there was no branching request, the next steps are illustrated in Figure 25.3.
5. Developer 1 completes his work, and checks in the new version (version 1.2) which becomes the new baseline version.
6. Developer 2 is now free to checkout the baseline version and commence work on it. The version she is working on will become version 1.3. When she checks this version in it will become the new baseline.
VCS applications include facilities to regress to previous versions of the baseline in an emergency. Should the changes made by Developer 1 create issues when version 1.2 is released, then version 1.1 can be recreated and re-released if necessary.
25.4.3 Change control procedures
Change control procedures are business practices that are designed to:
- Allow changes to accepted work products to be proposed and evaluated, schedule and quality impact assessed, and approved or rejected for release into production systems in a controlled manner
- Provide a mechanism for management to accept and sign off changes that improve the product overall while rejecting those that degrade it
- Notify all parties materially affected by a proposed revision of the need to accept the new version
- Notify interested parties on the periphery of development regarding change proposals, their assessed impact and whether the changes were approved or rejected
- Facilitate efficient deployment of changes to environments where they are required.
Many firms hold periodic (often weekly in the case of large organisations with complex configurations) change control meetings to ensure that these aims are achieved. The participants will include representatives of all the business areas affected. Change control meetings may be guided by a change management policy. An example of such a policy might be as follows:
ABC Investment Bank plc – change control policy for client–server applications
1. Changes are normally deployed after the close of business on Tuesday evenings unless the nature of the change demands a different time.
2. As the bank’s financial year end is 31 December, only emergency fixes will be released after the first Tuesday in December. This is to avoid destabilising the preparation of the bank’s annual accounts.
3. No significant changes will be applied to critical systems in the last week of any accounting month. This is to avoid destabilising the preparation of the bank’s monthly accounts.
4. No changes will be applied to critical systems in weeks when the key individuals concerned with the change are unavailable due to sickness, holiday or other absence.
5. No change will be released if there are any Grade A issues outstanding, and/or more than five Grade B errors outstanding.1
25.5 BUSINESS CONTINUITY PLANNING
25.5.1 Introduction
Business continuity plans are concerned with ensuring that the firm is able to recover from an emergency such as utility disruptions, software failures and hardware failures – some of the key operational risk events defined in Basel II.
Disaster recovery is the process of regaining access to the data, hardware and software necessary to resume critical business operations after a natural or human-induced disaster. A disaster recovery plan (DRP) should also include plans for coping with the unexpected or sudden loss of key personnel. DRP is part of a larger process known as business continuity planning (BCP).
A “disaster” could be any one or more of the following kinds of events, ranked by increasing severity:
1. One or more of the applications that the firm uses to process its business is lost as a result of either a software or hardware failure. The failure is in one of the firm’s own systems, and it is the only firm affected.
2. An external application on which this firm is dependent (such as one provided by an exchange or clearing house system or an information provider’s system) is lost as a result of either a software or hardware failure. Other user firms with which the firm trades are also dependent on this application.
3. The firm is the victim of an event such as fire, flood, criminal or terrorist related activity, and has lost access to one of its key buildings. Other neighbouring businesses may also be affected. In locations such as the City of London or Downtown Manhattan, where there is a large concentration of investment firms, there is the likelihood that many of the firm’s trading parties and critical suppliers may also be affected.
Since 9/11 much attention has been paid to the most severe event. But let us first look at the less dramatic events that are confined to the loss of an individual firm’s applications.
25.5.2 Critical and non-critical systems and standby servers
In section 25.2.2 we examined the benefits of compiling an infrastructure catalogue. As part of this process, it is necessary to make an assessment as to how critical the loss of this application for an extended period would be to the business. Another part of the infrastructure catalogue identifies which servers and other hardware items are concerned with the operation of each application.
Assuming that the applications concerned are client–server applications, then any application that is defined as critical to the running of the business needs to have a standby or DR server allocated to it as well as a production server. In the event that the production server or a software product running on that server ceases to function, then the running of the application will switch from the production server to the standby server (also known as the DR server).
The standby server needs to be located at a separate physical location to the production server, so that in the event of a major disaster that restricts access to the building that houses the production server the firm can still gain access to the location of the standby server. Sufficient bandwidth needs to be provided between the two locations so that data may be accessed and entered on the standby server.
Next, the firm needs to determine what level of access it needs to the standby server. The terminology is cold standby, warm standby and hot standby, and these options offer increasing resilience in the case of failure, but of course as resilience increases so does the cost of the service.
Cold standby
A cold standby server is a spare server that is configured similarly to the primary server and is running the same version of the operating system, database and application software, with all the same service packs applied. If the primary server suffers a failure, then the SQL database is restored to the secondary server from the primary’s backup files. The backup files may not be totally up to date, for example they may have been made the previous evening, so there may be a large amount of data that needs to be re-entered.
This methodology provides a reliable means to recover the database with minimal loss although there will still be a significant number of manual processes that must be followed in order to get back up and running again, giving a typical downtime of between two hours and one day (a lot depends upon what the client applications are written in, how the client applications connect to the database, how easy it is to switch them to another database name, how many clients are involved, etc.).
Warm standby
To set up recovery using a warm standby server it is necessary to implement a range of automated procedures to maintain same data on the two servers. Typically this involves some form of automatic synchronisation between the databases such as is provided by log shipping. Automated log shipping is included in the Enterprise edition of SQL Server.
Log shipping essentially consists of automating and integrating the process of backing up, copying and restoring the database from the primary server to the secondary server. This maintains the secondary server’s database as an identical copy of the primary server’s database apart from a small time latency of between five and 15 minutes.
While log shipping keeps the databases in synchronisation other procedures are needed for data (such as messages, logins, permissions, DTS packages, SQLServer Agent™ jobs, server configurations, etc.) that are held outside of the database. With a warm standby server and log shipping the aim is to be able to get up and running again with a probable downtime of between 10 minutes and one hour depending upon how easy it is to change the client applications over to another server and how many clients there are.
Hot standby
Hot standby is an approach to maintaining system availability whereby all transactions are routinely written to the production server and the standby server simultaneously. The standby server is therefore ready to take over the processing load instantaneously, should there be any failure in the production system.
When the production server that was lost is up and running again it will need to be updated with the transactions that have only been processed by the standby server. This is usually automated by software programs designed to perform database replication.
25.5.3 The business continuity plan
The business continuity plan (BCP) is a plan developed to mitigate different disaster or worst case scenarios. The BCP will contain agreed workarounds and task lists for those supporting the application during a disaster. The goal of BCP processes is to ensure that IT services can be recovered within required, agreed and business sensitive timescales.
It is a comprehensive statement of consistent actions to be taken before, during and after a disaster. The plan should be documented and tested to ensure the continuity of operations and the availability of critical resources in the event of a disaster.
The primary objective of disaster recovery planning is to protect the organisation in the event that all (or part) of its operations and/or computer services are rendered unusable. Preparedness is the key. The planning process should minimise the disruption of operations and ensure some level of organisational stability and an orderly recovery after a disaster.
The steps involved in producing a BCP can be found in Figure 25.4.
Figure 25.4 Stages of business continuity planning
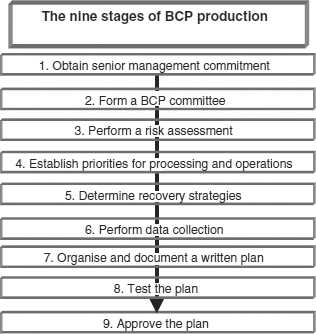
Obtain senior management commitment
Management as a whole is responsible for coordinating the disaster recovery plan and ensuring its effectiveness within the organisation. Adequate time and resources must be committed to the development of an effective plan, and the implementation of the plan may require significant financial resources.
Form a planning committee
A planning committee should be appointed to oversee the development and implementation of the plan. The planning committee should include representatives from all functional areas of the organisation. Key committee members should include the operations manager and the IT manager. The committee also should define the scope of the plan.
Perform a risk assessment and establish priorities for processing and operations
The planning committee should prepare a risk analysis and business impact analysis that include a range of possible disasters, including natural, technical and human threats. The planning committee need to consider the likelihood of a range of possible events, the impact of those events on the business and the costs of mitigating them. This risk analysis might be presented in graphical form (see Figure 25.5).
Figure 25.5 BCP risk analysis
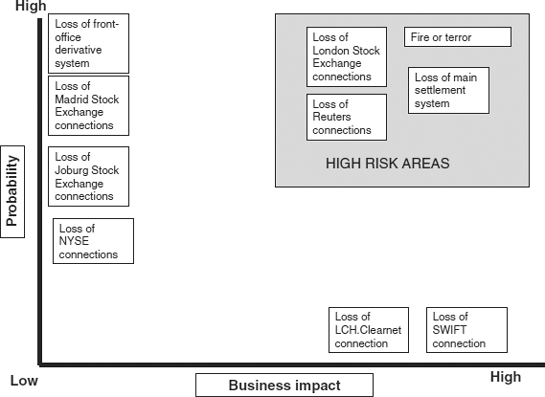
This firm has mapped a number of applications and business services into a risk analysis matrix. Its BCP will therefore concentrate on the items in the top right-hand corner, where it considers that the likelihood of an event is high, and the business impact of that event is also high. It has therefore taken the decision that in the event of a serious disaster where many applications and services are affected, it may have to temporarily suspend its business on the Madrid, Johannesburg and New York Stock Exchanges and its dealings in derivatives. It is not, however, prepared to suspend its business on the London Stock Exchange, or to tolerate the loss of its Reuters services or its main settlement system. It considers that although the loss of its SWIFT connections and its LCH.Clearnet interfaces would be very serious, the likelihood of those events is very low.
Determine recovery strategies
The most practical alternatives for processing in case of a disaster should be researched and evaluated. It is important to consider all aspects of the organisation, such as:
- Staff: In the most serious disaster event, there is the possibility that staff members suffer serious, even fatal, personal injury, and procedures need to be put into place to cover this event. Additionally, staff members may be unable to reach either their normal place of work or the backup site.
- Press relations: In the event of a serious incident, there may be a high level of interest from press and broadcasters. Resources need to be allocated to deal with this.
- Regulators may take a keen interest in the recovery process, and again resources need to be made available to liaise with them.
- Insurers may bear many of the costs of the use of the DR service, and may wish to be involved to protect their interests.
- Business operations in general, including (inter alia) hardware, software, telecommunications facilities, end-user systems, data and physical files and other processing operations, may all need to be operated from a temporary disaster recovery site or sites. These may be provided by any one or more of the following models:
– Having reciprocal agreements with other firms
– Subscribing to the services of companies that offer dedicated DR service centres
– Consortium arrangements
– Acquiring a dedicated DR site that is private to this firm
– Combinations of the above.
When selecting the location of a DR site, bear in mind the following:
- If it is too close to the main site, then it could be overcome by the same factors that affect the main site.
- If it is a site provided by a specialist provider of DR facilities, then that vendor may have a number of clients in the same area as your firm. Is there a danger that they could be overwhelmed and unable to offer the contracted services?
Written agreements with suppliers for the specific recovery alternatives selected should be prepared, including the following special considerations:
- Contract duration
- Termination conditions
- Testing
- Costs
- Special security procedures
- Notification of systems changes
- Hours of operation
- Specific hardware and other equipment required for processing
- Personnel requirements
- Circumstances constituting an emergency
- Process to negotiate extension of service
- Guarantee of compatibility
- Availability
- Non-mainframe resource requirements
- Priorities
- Other contractual issues.
Perform data collection
Recommended data gathering materials and documentation include:
- Critical telephone numbers
- Communications inventory
- Distribution register
- Documentation inventory
- Forms inventory
- Insurance policy inventory
- Computer hardware inventory
- Computer software inventory
- Staff contact details list
- Vendor list
- Notification checklist
- Office supply inventory
- Off-site storage location inventory
- Software and data files backup/retention schedules
- Telephone inventory
- Temporary location specifications
- Other materials and documentation.
It is extremely helpful to develop pre-formatted forms to facilitate the data gathering process.
Organise and document a written plan
An outline of the plan’s contents should be prepared to guide the development of the detailed procedures. Top management should review and approve the proposed plan. The outline can ultimately be used for the table of contents after final revision. Other benefits of this approach are that it:
- Helps to organise the detailed procedures
- Identifies all major steps before the writing begins
- Identifies redundant procedures that only need to be written once
- Provides a “road map” for developing the procedures.
A standard format should be developed to facilitate the writing of detailed procedures and the documentation of other information to be included in the plan. This will help ensure that the disaster plan follows a consistent format and allows for ongoing maintenance of the plan. Standardisation is especially important if more than one person is involved in writing the procedures.
The plan should be thoroughly developed, including all detailed procedures to be used before, during and after a disaster. It may not be practical to develop detailed procedures until backup alternatives have been defined.
The procedures should include methods for maintaining and updating the plan to reflect any significant internal, external or systems changes. The procedures should allow for a regular review of the plan by key personnel within the organisation.
The disaster recovery plan should be structured using a team approach. Specific responsibilities should be assigned to the appropriate team for each functional area of the company.
There should be teams responsible for administrative functions, facilities, logistics, user support, computer backup, restoration and other important areas in the organisation. The structure of the contingency organisation may not be the same as the existing organisation chart. The contingency organisation is usually divided into teams responsible for major functional areas such as:
- Staff liaison
- Press liaison
- Regulator liaison
- Administrative functions
- Facilities
- Logistics
- User support
- Computer backup
- Restoration
- Other important areas.
The management team is especially important because it coordinates the recovery process. The team should assess the disaster, activate the recovery plan and contact team managers. The management team also oversees documents and monitors the recovery process. Management team members should be the final decision-makers in setting priorities, policies and procedures.
Each team has specific responsibilities that must be completed to ensure successful execution of the plan. The teams should have an assigned manager and an alternate in case the team manager is not available. Other team members should also have specific assignments where possible.
Develop testing criteria and procedures
It is essential that the plan be thoroughly tested and evaluated on a regular basis (at least annually). Procedures to test the plan should be documented. The tests will provide the organisation with the assurance that all necessary steps are included in the plan. Other reasons for testing include:
- Determining the feasibility and compatibility of backup facilities and procedures
- Identifying areas in the plan that need modification
- Providing training to the team managers and team members
- Demonstrating the ability of the organisation to recover
- Providing motivation for maintaining and updating the disaster recovery plan.
Test the plan
After testing procedures have been completed, an initial test of the plan should be performed by conducting a structured walk-through test. The test will provide additional information regarding any further steps that may need to be included, changes in procedures that are not effective and other appropriate adjustments. The plan should be updated to correct any problems identified during the test. Initially, testing of the plan should be done in sections and after normal business hours to minimise disruption to the overall operations of the organisation. Types of tests include:
- Checklist tests
- Simulation tests
- Parallel tests
- Full interruption tests.
Approve the plan
Once the disaster recovery plan has been written and tested, the plan should be approved by top management. It is top management’s ultimate responsibility that the organisation has a documented and tested plan.
Management is responsible for:
- Establishing policies, procedures and responsibilities for comprehensive contingency planning
- Providing financial resources to implement the plan
- Reviewing and approving the contingency plan annually, documenting such reviews in writing
- Committing the necessary financial resources to make the plan work.
If the organisation receives information processing from service bureaux or other providers of outsourced services, management must also evaluate the adequacy of contingency plans for the supplier and ensure that the supplier’s contingency plan is compatible with the firm’s own service plan.
25.6 USE OF THE IT INFRASTRUCTURE LIBRARY IN MANAGING IT OPERATIONS
The Information Technology Infrastructure Library (ITIL) is a set of concepts and techniques that was developed by the United Kingdom government for managing IT infrastructure, development, and operations; and has now become a globally accepted standard for “best practice” in IT management. The examples of best practice that are included within ITIL may be used as a baseline for managing the activities described in Chapters 25, 26 and 27 of this book.
ITIL is published in a series of books which are available in both hard copy and electronic formats, each of which cover an IT management topic. The names ITIL™ and IT Infrastructure Library™ are registered trademarks of the United Kingdom’s Office of Government Commerce (OGC). Each volume is designed to be extendable by IT companies. For example, Microsoft is free to add detail to the Service Transition book that is specific to the Windows™ operating system or the MS SQLServer™ database.
ITIL gives a detailed description of a number of important IT practices with comprehensive checklists, tasks and procedures that can be tailored to any IT organisation.
The current version of ITIL is version 3, released in 2007. It consists of five volumes:
- Service Strategy: Concerned with defining the set of services provided by the IT department that help achieve business objectives
- Service Design: Designing the services with utility and warranty objectives in mind
- Service Transition: Moving services into the live production environment
- Service Operation: Managing services on an ongoing basis to ensure their utility and warranty objectives are achieved
- Continual Service Improvement: Evaluating services and identifying ways to improve their utility and warranty in support of business objectives.
IT practitioners are able to study for the ITIL diploma, which offers a formal qualification in the use of these methodologies.
1 Refer to Table 26.3 for an explanation of Grade A and Grade B issues.