
Chapter 5. Models
Models are related data and algorithms that respectively represent the properties and behaviors of domain objects used within an application. Models are used in nearly every decently complex object-oriented application because they organize application data in object form. Within the scope of a typical Merb application, examples of modeled objects may include users, posts, entries, or comments. These objects are most often persisted in a database through the use of an Object Relational Mapper, or ORM. As agnosticism has been central to Merb’s design, application developers are free to integrate whatever Ruby ORM they may need. Nonetheless, the default ORM included as part of the standard Merb stack is DataMapper, an ActiveRecord-like ORM that aims to push the boundaries of object-data interaction even more significantly toward the object side.
Given its acceptance as part of the standard Merb stack, we will cover the use of only DataMapper in this chapter. However, don’t let that stop you from using ActiveRecord, Sequel, or any of the other options, since each of these ORMs is capable of creating, retrieving, updating, and deleting persisted data and is fully supported by the Merb core.
5.1 Configuration
Prior to being able to use the DataMapper ORM within your Merb application, you will have to make sure that you have done three things:
• Included the DataMapper dependencies within config/dependencies.rb
• Selected DataMapper as the ORM in init.rb
• Configured your database connection in config/database.yml
However, if you used merb-gen to generate a standard application and have SQLite3 installed, then you’ll find that all of these are already covered for you. If your application was generated in some other manner, you may want to see Chapter 1 to figure out how your configuration files should be laid out.
DataMapper works with several different database back ends. Support for MySQL, PostgreSQL, and SQLite3 are all included via the DataMapper core. If you’re using another database application, you may be able to find an appropriate adapter in the dm-more or dm-adapters gems. Alternatively, if your computer has the memory for it, there’s a DataMapper adapter that will store your model records completely in memory.
Repository configuration is done in a YAML file named config/database.yml. The standardly generated config/database.yml file is broken into four environments—development, test, production, and rake—corresponding to the environments that are standardly used by a Merb application. If you have another environment—for instance, a staging environment—it, too, can be listed in this file. Typically there is overlap in the configuration of environments, so YAML node anchors and aliases are used to reduce redundancy.
What’s a YAML node?
YAML nodes are named blocks of content in a YAML file. You can set up an anchor to the content of a node by using an ampersand and word after the naming of the node. Below we connect the content of development with the anchor &default.
![]()
We can reference this anchor by using the alias *default later on. If we use this alias as the value on a merge key, <<, it will include the previously defined content. Here we merge in the defaults from before and then override the value for the database:
![]()
5.2 Model classes
Model classes exist in the directory app/models. These classes typically have singular names and exist one class per file. Examples that may appear in a Merb blog application are Post in the file app/models/post.rb and FavoriteLink in app/models/favorite_link.rb. Organizing model classes in this way isn’t strictly necessary, though, since Merb by default includes everything inside app/models by recursive glob. In other words, so long as you make sure that your model class is somewhere in app/models, it will be available at boot. Nonetheless, our recommendation is that you do arrange your model classes in a reasonable way, so that both you and others can easily find them.
While various DataMapper modules can incorporate different functionality within your model class, the fundamental module that must be included in order for your class to work with DataMapper is DataMapper::Resource. Below we include this module and effectively set up our User class as a DataMapper model.
![]()
Let’s take a look at the source behind the Resource module to get a feel for how it affects the class in which it is included:

Focusing on the last method listed above, we can see that the Resource module extends the class in which it is included (above called model). In the process, it principally extends it with the Model module, which contains the logic for property persistence and object retrieval. As we come to these methods later on, we’ll open up the Model class source as well. For now, however, take note of Resource’s ability to include extra modules through the class method append_inclusions. This method is used extensively by DataMapper plugins that need to extend the functionality of all DataMapper models. For instance, below is some of the source for dm-timestamps, which automatically sets timestamps on properties of particular names.

The first line appends the module to all DataMapper models. Later on, using its own self.included, the module includes its own logic into the model. This cascading of modules is thus particularly effective for code as modular as DataMapper.
5.3 Properties
Each DataMapper model is able to persist its data. The kind of data it is able to store is defined through its properties. If you’re using a typical database, these properties correlate with the columns of the model’s corresponding table. Below is an example of a DataMapper model with three properties.

In many ways, you can think of properties as persistent accessors. In fact, taking a look into the source of the property method (found in the Model resource we spoke about earlier), we find that a dynamic getter and setter are created using class_eval:

The most important thing to learn from the source shown above is that properties dynamically create getter and setter methods. Additionally, these methods can end up protected or private through visibility attributes. Finally, the getters and setters produced are not exactly equivalent to attr_reader and attr_writer because of their internal use of the methods attribute_get and attribute_set.
Going back to the Resource source, we can find these two methods manipulating the values of model properties, once again located in Model. You’ll have to excuse this volleying back and forth, but the point of the Resource and Model modules is to separate individual resource methods from those related to the model as a whole.

You may have noticed the @api semipublic comment above the getter and setter methods. This is because application developers should not ordinarily need to use these methods. Plugin developers, on the other hand, may need to use them as the easiest way to get and set properties while making sure they are persisted.
For application developers, however, this does bring up one important point: Do not use instance variables to set property values. The reason is that while this will set the object’s value, it will unfortunately short-circuit the model code that is used to track whether a property is dirty. In other words, the property value may not persist later upon save. Instead, you should use the actual property method. Below you’ll find an example with comments that should get the point across.

Before we describe the extended use of properties, let’s take a look at the database side to understand how persistence works.
5.3.1 Database storage
In order to persist the data of model objects, we need to set up our database for that data to be stored. The default-generated configuration files use a SQLite3 database file called sample_development.db. This setup is perfect for most development scenarios given its quickness to get up and running. With that in mind, we’d say stick with it whenever possible, leaving the alteration of config/database.yml for production or staging environments.
5.3.1.1 Automigrating the DB schema
Databases typically need to be prepped for the data they will store during application development. The process by which DataMapper does this is called automigration, because DataMapper uses the properties listed in your models to automatically create your database schema for you. Using the provided Merb DataMapper rake task, we can automigrate the model that we created earlier and then take a peek inside the database to see what was done:

As you can see, a table with a pluralized and snake-cased name was created for our model, TastyAnimal. Remembering the various properties of the model class, we can also spot corresponding columns inside the schema’s CREATE statement. Note that while Ruby classes were used on the property lines, standard SQL types appear in the database.
The code behind automigration is definitely worth studying, so let’s take a look at the module AutoMigrations, which includes itself within the Model module:

As you can see, there are two API public class methods you can use with models, auto_migrate! and auto_upgrade!. These effectively call the three adapter methods destroy_model_storage, create_model_storage, and upgrade_model_storage. Let’s go deep into the source and see how these three methods do the heavy lifting:


The simplest of these, destroy_model_storage, executes a drop table statement. The create_model_storage method, on the other hand, first checks to see if the model storage already exists, returning false if it does or true if it does not, and consequently has the chance to create it. Finally, upgrade_model_storage is the most complicated of the three. It first attempts to create the storage (effectively testing whether it exists or not) and then attempts to add new columns for new properties. This leaves existing data in place and is perfect if you have simply added properties to a column. Lest this appear to be no more than hand waving, let’s dig even deeper into the methods that the AbstractAdapter uses to create the SQL for these statements:



The first thing you may notice is that the methods are included within a module called SQL and that the module is included immediately after it is closed. The reason for this is that within DataMapper adapters, code is often organized by use, and thus the encapsulation of private methods into a module easily allows for alternating regions of public and then private methods.
Now, turning to the actual methods, we can see that some of them—for instance, drop_table_statement—are just a line of simple SQL. Likewise, alter_table_column_statement is just a single line that outputs add column statements. The create_table_statement, however, is far more complex, relying on various other methods to get its work done. One of these, properties_with_subclasses, pulls up all model properties, including those that are simply keys used with relationships. We’ll go further into properties_with_subclasses later on when we examine model relationships, but for now let’s take a look at the method property_schema_statement, which quotes the property as a column name and then appends its type. It also adds the appropriate SQL for decimals, non-nullables, and default values.
We hope this has brought you deep enough into the inner workings of automigration to both appreciate its design and get a feel for how adapter code handles the production of SQL more generally. But it would also be nice to be able to use some of it practically, and thankfully you can do so. For instance, if you’re in mid-development, you may fire up interactive Merb and use auto_upgrade! on a model to which you’ve added properties:
> Fruit.auto_upgrade!
Likewise, you may want to refresh the data of a model using auto_migrate! in the middle of a test file. Here’s an example we’ve spotted in the wild:
![]()
5.3.2 Defining properties
Let’s now take a more rigorous look at properties as well as the options we have while defining them. As we’ve seen, each property is defined on its own line by using the method property. This class method is mixed in via the inclusion of DataMapper::Resource. It takes a minimum of two arguments, the first being a symbol that effectively names the property and the second being a class that defines what type of data is to be stored. As we will see soon, an optional hash of arguments may also be passed in.
5.3.2.1 Property types
While abstracting away the differences across database column types, DataMapper has chosen to stay true as much as possible to using Ruby to describe properties types. Below is a list of the various classes supported by the DataMapper core. Note that the inclusion of DataMapper::Resource will include DM in your model class, and that when defining properties, you will not have to use the module prefix DM:: before those that use it.
• Class—stores a Ruby Class name as a string. Intended for use with inheritance, primarily through the property type DM::Discriminator.
• String—stores a Ruby String. Default maximum length is 50 characters. Length can be defined by the optional hash key :length.
• Integer—stores a Ruby Integer. Length can be defined by the optional hash key :length.
• BigDecimal—stores a Ruby BigDecimal, intended for numbers where decimal exactitude is necessary. Can use the option hash keys :precision and :scale.
• Float—stores a Ruby Float. Primarily intended for numbers where decimal exactitude is not critical. Can use the two options hash keys :precision and :scale.
• Date—stores a Ruby Date.
• DateTime—stores a Ruby DateTime.
• Time—stores a Ruby Time.
• Object—allows for the marshaling of a full object into a record. It is serialized into text upon storage and when retrieved is available as the original object.
• TrueClass—a Boolean that works with any of the values in the array [0, 1, 't', 'f', true, false]. In MySQL it translates down to a tinyint, in PostgreSQL a bool, and in SQLite a boolean.
• DM::Boolean—an alias of TrueClass. This is around for legacy DataMapper support, simply to provide a more commonly recognized name for the type.
• Discriminator—stores the model class name as a string. Used for single-table inheritance.
• DM::Serial—used on the serial ID of a model. Serial IDs are auto-incremented integers that uniquely apply to single records. Alternatively, a property can use the Integer class and set :serial to true. You will nearly always see this type applied to the id property.
• DM::Text—stores larger textual data and is notably lazy-loaded by default.
You may be interested in knowing how the casting in and out of property values works. For the primitive types, values coming out of the database are cast using the method Property#typecast. Below we see how this methods prunes results, modifying them into what we want in Ruby.

Custom types, however, are handled by subclasses of an abstract type class called DataMapper::Type. These load and dump data in whatever way they are programmed to do. We’ll see custom types later on when we examine some DataMapper-type plugins, but for now let’s take a look at one of the custom types from the DataMapper core, Serial:

Note its use of the methods primitive and serial, which are defined in the class DataMapper::Type:

From this we can first see that the primitive method sets the type to which the property value should be dumped. The serial method, on the other hand, is an example of the property option, which we’re about to address.
5.3.2.2 Option hash
The third argument that the property method can take is an option hash, which affects various behavioral aspects of the property. For instance, below we’ve specified that a property should default to some value.

Here’s a list of the various property options and their uses:
• :accessor—takes the value :private, :protected, or :public. Sets the access privileges of the property as both a reader and a writer. Defaults to :public.
• :reader—takes the value :private, :protected, or :public. Sets the access privileges of the property as a reader. Defaults to :public.
• :writer—takes the value :private, :protected, or :public. Sets the access privileges of the property as a writer. Defaults to :public.
• :lazy—determines whether the property should be lazy-loaded or not. Lazy-loaded properties are not read from the repository unless they are used. Defaults to false on most properties, but is notably true on DM::Text.
• :default—sets the default value of the property. Can take any value appropriate for the type.
• :nullable—if set to true it will disallow a null value for the property. When dm-validations is used this invalidates a model.
• :key—defines a property as the table key. This allows for natural keys in place of a serial ID. This key can be used as the index on the model class in order to access the record.
• :serial—sets the property to be auto-incremented as well as to serve as the table key.
• :field—manually overrides the field name. Best used for legacy repositories.
• :size—sets the size of the property type.
• :length—alias of :size.
• :format—used with the String property type. When used with a dmvalidations format can set a regular expression against which strings must validate.
• :index—sets the property to be indexed for faster retrieval. If set to a symbol instead of to true, it can be used to create multicolumn indexes.
• :unique_index—defines a unique index for the property. When used with dmvalidations, new records with nonunique property values are marked invalid. If set to a symbol instead of true, it can be used to create multicolumn indexes.
• :auto_validation—when used with dm-validations, can be used to turn off autovalidations by using the value true.
• :track—determines when a property should be tracked for dirtiness. Takes the values :get, :set, :load, and :hash.
• :precision—sets the number of decimal places allowed for BigDecimal and Float type properties.
• :scale—sets the number of decimal places after the decimal point for BigDecimal and Float type properties.
5.4 Associations
DataMapper also supports the defining of associations between models. If you’ve used ActiveRecord before, these are nearly the same. Otherwise, know that associations allow you to define the relationships between models (one-to-one, one-to-many, etc.), automatically creating database keys where necessary while also making it possible to conveniently pull up related model objects from associates. Let’s survey the various relationships possible with DataMapper.
5.4.1 Belongs to
In general, you should know that a belongs-to association is meant to help you quickly retrieve an associated resource by defining a one-to-something association between two models (specifically, a child and its parent), where the child class should store its parent’s key as a property. So, for instance, the following associates a comment with a user:

Note that upon automigration the belongs-to association automatically creates the column user_id within the comments table. This means that any model object now has two new methods accessible, user_id and user. The first is simply the ID of the associated user, but the second actually retrieves the user resource for you. These defaults may not always fit your domain logic, however, so they can be altered.

Here we have two user objects parenting our paper object. To handle ambiguity, we use the hash keys class_name and child_key. The first is a string representation of the parent class name, and the second is an array indicating how the key should be stored within our child. At the end this produces the methods author_id, reviewer_id, author, and reviewer on papers, where the first two are essentially association properties and the second two are means of retrieving the associated objects.
Let’s take a look at how the belongs_to magic is performed:
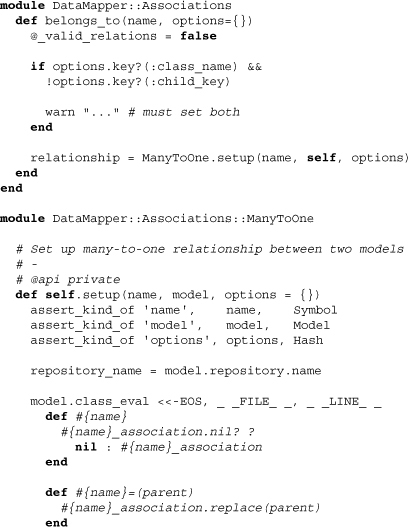

Starting with the Associations module, we can see that belongs_to fires off the creation of a many-to-one association. Moving on to ManyToOne.setup, we find extensive class evaluation where new methods for the association are defined. These allow us to get or set the association. Note that the reader method essentially proxies to the parent model (using a Proxy class later defined within ManyToOne). It also employs the Relationship class, DataMapper’s most generalized way of storing information on associations within model classes. Finally, note that the use of ManyToOne does not strictly indicate that the relationship between the two models needs to be many-to-one. It may indeed be one-to-one (as determined within the other model), but from the perspective of the child model the more generalized ManyToOne class is appropriate for handling both possibilities.
5.4.2 Has
At this point you may be wondering about the flip side of the relationship, that is, the parent. Has associations are meant to handle this. The characteristics of has associations, however, differ in that they are meant to associate varying numbers of related model resources without storing information within the model object itself.
Let’s create the counterpoint of the comment model we created in the previous section:

Note that the has method takes a minimum of two parameters. The first of these is the cardinality, which may be specified by a number, series, or n, and the second is the symbolized name of the associated class. If you’re scratching your head over n, just know that it is equivalent to 1.0/0 and that it allows an indefinite number of associates. If you’re coming from the ActiveRecord world, you can think of this as the “many” in has_many.
As we did before, we can tweak our relationship for the sake of the domain logic:

There are plenty of things to notice this time. Once again, we’ve specified the associated class name along with the child_key, but we’ve also set remote_name, which is the symbolized name of the relationship in our other model. Last, note that we set the cardinality of the first to 1, which limits users to authoring only one paper, effectively making the relationship one-to-one.
Having now seen the use of has, let’s go into the source to understand how it works:


From this we can see that has_many, like belongs_to, creates an association, but that it may be OneToOne or OneToMany based upon the max cardinality. Because we’ve already looked inside one of these associations and because the others are set up in similar ways, we’ll leave it up to you to explore further if you like.
5.4.3 Has through
You may need to work with one-to-many-through or many-to-many relationships. To handle these, DataMapper uses through. Let’s tackle one-to-many-through first and then take a look at many-to-many relationships:

These examples show us three associated models where the Tagging class acts like a join table bridging the one-to-many relationships from both sides. Sometimes, though, you don’t want to explicitly define this middle table. DataMapper lets you do this by setting through to Resource:

This automatically creates the bridging model for us dynamically. But this isn’t magic; remember the line from the def has snippet of source code that we didn’t show you? Here it is:
![]()
With that inside the previous snippet, it’s easy to see that the use of the through option with Resource changes the association setup to a ManyToMany. This special association is used to create a join table model for you. Here’s part of the setup method showing just that:

Note the particularly unique creation of a model through Model.new as opposed to a standard class definition. This is meant only for dynamically defined models like the one above.
5.5 CRUD basics
DataMapper as an ORM is intended to create, retrieve, update, and delete records from a repository through interactions with Ruby objects. This means that we don’t have to write SQL statements through the normal course of usage. In fact, DataMapper’s versatility, intelligence, and performance will probably leave you never needing to write a single SQL statement in your entire application.
Throughout this section, we will assume the existence of the following model:

5.5.1 Creating records
The creation of DataMapper records is a two-step process. The first step is the creation of a new model object. This is as simple as initializing with the new method. This method can also take an attributes hash that will set the model object’s properties. The second step of this process is the saving of the object’s data into the database as a record. This is done via the save method. Below we create a new blog entry and then save it immediately after.

At the end, this issues a SQL insert command, saving the data in our database. However, let’s take a look first at the most superficial methods inside the DataMapper that make this work:


As you can see, the default initialize has been overridden so that it can set attributes. You’ll also spot a method assert_valid_model, but it isn’t of much interest since all it does is confirm that the model class does in fact have properties defined. Moving on to the save method, you’ll find that it first checks to see if the model object should be a new record. To do this it uses the public method new_record?, which is also available to you should you need it as an application or plugin developer. Then, given that our record is new, it invokes the protected method create. This method effectively cascades through the resource’s repository object down to an adapter, where a SQL create statement is executed.
Alternatively, you can shorten this process to a single step by using the class method create defined within the Model module. Here we use it just as we did before:
![]()
Taking a peek at the source code, we find that the class method create does exactly what we did ourselves before but returns the model object for our convenience:

5.5.2 Retrieving records
The retrieval of model records is principally done through the two methods all and first. These two methods pull up a collection of records or access a single record, respectively. They can easily be chained, allowing for the refining of the data to be retrieved. Let’s take a look at some basic examples:
![]()
The first line looks up a user by login, the second retrieves all groups with the word Ruby in them, and the third refines the collection of the second to only those where the user is the admin. Let’s look at the source behind the methods first and all to get an understanding of how they work:

Both all and first use the method scoped_query to integrate new query parameters with any preexisting ones that may exist higher up on a collection on which the method may be acting:

DataMapper uses the method assert_kind_of as a way of enforcing types and throws errors when types do not match. Thus, above, we see that scoped_query accepts only queries and hashes. The hashes are really just cases of yet-to-be-initiated queries coming from the parameters of some method like all or first. If both new query parameters and an existing query exist, the two are merged. The model’s default scope (typically having no conditions and all non-lazy model fields) is used to merge in further conditions.
The method Query#merge duplicates the query and then seeks to update it. Below we see this method as it leads into Query#update.


Note that the method update picks out special query parameters before updating the conditions and finally returning itself.
5.5.2.1 Special query parameters
The parameters passed into all and first are mostly understood simply as conditions upon parameters. However, certain keys are understood as special query parameters that shape the query in other ways. The following list should make the use of each of these clear:
• add_reversed—reverses the order in which objects are added to the collection. Defaults to false.
• conditions—allows SQL conditions to be set directly using an array of strings. Conditions are appended to conditions specified elsewhere.
• fields—sets the fields to fetch as an array of symbols or properties. Defaults to all of a model’s non-lazy properties.
• includes—includes other model data specified as a list of DataMapper property paths.
• limit—limits the number of records returned. Defaults to 1 in the case of first and is otherwise not set.
• links—links in related model data specified by an array of symbols, strings, or associations.
• offset—the offset of the query, essential for paging. Defaults to 0.
• order—the query order specified as an array or properties (or symbols) modified by the two direction methods desc and asc.
• reload—causes the reloading of the entire data set. Defaults to false.
• unique—groups by the fields specified, resulting in a unique collection. Defaults to false.
5.5.2.2 Lazy loading of collections
DataMapper does not load collections or issue database queries until the data is absolutely needed. The major benefit here is that application developers can worry less about the database side of things once again, knowing that unless they actually use the data of a resource, no database query will be executed. With Merb, we’ve also found that this means simpler controller code, since we can use chained relationships or pagination inside the view. With any other ORM, this may be extremely bad form, given that it implies littering the view with lines of supporting code as well as incurring performance penalties based on the retrieval of possibly unused data. Below we present the practical application of collection lazy loading.
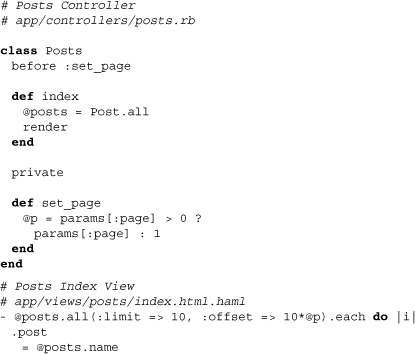
Note that this executes only one database query, specifically at the each. To see how and why this works, we need to take a look at some of the code in the parent class of Collection, LazyArray:

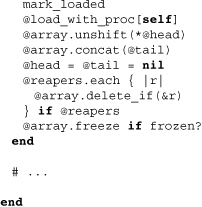
Starting at the top, we can see that all but the quintessence methods are undefined. This is because LazyArray is meant to emulate the primitive Array class, and starting off with a slate that is as blank as possible helps us get there. The next few lines define various instance methods from both Array and Enumerable, essentially making LazyArray a proxy to a real array but prefacing the call of any array method with lazy_load. The lazy_load method itself either simply returns true if already loaded, or uses a Proc defined through the load_with method to populate the array. All in all, the lazy loading of LazyArray has a profound impact on the DataMapper API, arguably serving as the foundation for the elegance and straightforwardness of the query algebra.
5.5.2.3 Lazy loading of properties
Some property data is not automatically retrieved when a model object is loaded. For instance, by default, text properties are not loaded unless you specifically request them. This form of lazy loading is facilitated by code with the Resource module and PropertySet class. Let’s see it in action before taking an in-depth look at how it has been put together:

Note that if we had multiple text properties, they would all have been loaded by the second line of interaction. To prevent this from happening, you can define lazy contexts on properties, thus segmenting the retrieval of lazy property data:

It’s time to see how this is done. We’ll have to open up Resource and PropertySet, with the insight that a property when either get or set calls the method Resource#lazy_load:


The methods of PropertySet aren’t anything special, but seeing how they work certainly clears up any ambiguity that may have existed within the concept of lazy load contexts.
5.5.2.4 Strategic eager loading
If you’ve used ActiveRecord before, you’ve probably trained yourself to avoid N + 1 queries. These come up frequently in ActiveRecord since iteration over the associates of a model object usually forces you to make a query for each associate. Add in the original query for the model itself, and you have N + 1 queries in total. However, DataMapper prevents this from happening and instead issues only two queries. Let’s take a look at an example in a view to make this more concrete:

With the code above, all posts and the names of their authors are outputted using only two queries: the first to get the posts and the second to get their authors. This kind of elimination of N + 1 queries is called strategic eager loading and is possible thanks to a combination of many different DataMapper implementation decisions. To get an idea of how strategic eager loading works, let’s take a look at some code inside the Relationship class that would have been used in the previous example:


From this we learn that in the process of getting a parent resource, DataMapper pulls up the identity map of the parent model and child model to see if the resource has already been loaded. If it has, DataMapper short-circuits any retrieval and simply returns the appropriate parent. Most important, if the resource is not already loaded, DataMapper uses the parent keys from all the relevant children within a collection query. The results are then loaded immediately, and after all children are connected with their parents, the parent requested is returned.
5.5.3 Updating records
Resources can be updated by using the save method similarly to how it was used with record creation. However, for saving to have any effect, it is necessary that at least one property value be recently set. This causes DataMapper to mark certain properties as dirty and use them during the creation of an update statement. Below we display the two ways of setting a property value and causing it to be marked as dirty.

However, note that the second method attribute_set is typically reserved for use inside override writer methods. Note that save, in the case of non-new records, cascades to the calling of update. Thus we have the option of using that method directly if we want:
post.update
5.5.3.1 Using update_attributes
There is one other way to invoke the updating of attributes. This is to use the method update_attributes, which accepts an arbitrary hash and then an optional constraining property array. Consequently, it works well with form parameters a user may have passed in:

Here we have constrained the user to being able to update only name, email, and description.
5.5.3.2 Original and dirty attribute values
You may at some point want to enhance model logic through the comparison of original and dirty attribute values. Here we do so within the method update_speed:

You may notice that we use a before hook here. We’ll cover hooks in the next section.
5.5.4 Destroying records
Records can be deleted by using the destroy method. Alternatively, if you’re looking to delete a full collection of resources, you can use the method destroy!:
![]()
5.6 Hooks
DataMapper hooks differ from those used in Merb controllers. This is because controller filter chains require a decently specific form of logic. DataMapper models, on the other hand, have the benefit of using the more generic Hook class of Extlib.
From the application developer’s perspective, the two methods used to create hooks are before and after. DataMapper registers specific hooks for the methods save, create, update, and destroy. Each of these can be used with before and after.

5.7 Plugins
Modularity has been a central objective of DataMapper. Thus, many of the features that you might otherwise expect within a standard ORM are with DataMapper found as plugins. This includes timestamping, aggregation, validations, and various data structures. In this section we’ll go over the most fundamental of these plugins, understanding not only how they’re used but also how they work.
5.7.1 Extra property types
The package dm-types provides numerous additional property types. Here’s a list of those included:
• BCryptHash—encrypts a string using the bcrypt library
• Csv—parses strings as CSVs using FasterCSV
• Enum—stores an enumerated value as an integer
• EpochTime—converts Time and DateTime to EpochTime, that is, the number of seconds since the beginning of UNIX time
• FilePath—stores paths as strings using Pathname
• Flag—binary flags stored as integers
• IpAddress—IP address stored as a string
• Json—JSON stored as a string
• Regexp—regular expressions stored as strings
• Serial—an auto-incrementing integer type
• Slug—escapes a stored string, making it suitable to be used as part of a URL
• URI—stores an Addressable::URI as a string
• UUID—creates a UUID stored as a string
• Yaml—stores YAML as a string
Let’s take a look at the source to one of these for a better understanding of how to create our own types:

As you can see, new DataMapper types can be created by subclass off of DataMapper::Type. You will then have to set the primitive type, and this can be done using the class method primitive. You may additionally have to set attributes like size and laziness as was done in the case above. Finally, the two methods that do the hard work are the class methods load and dump. These need to be defined only if the custom type needs to override them from simply returning the value. With the Yaml type, strings are converted into YAML when loaded from the database and are converted to strings when they need to be dumped into the database.
5.7.2 Timestamps
The gem dm-timestamps is one of the most commonly used DataMapper plugins. It saves you from having to code timestamping into your models. Note that once the gem is included, it applies to all DataMapper models. Thus we can set the following four properties in any Merb stack model, knowing they will automatically be set when needed:

Because dm-timestamps is a decently simple plugin but also reveals the foundation of resource extension plugins, let’s take a quick look:


The first line to notice is the third one. Here the module appends itself to Resource. As we saw earlier in this chapter, this gets the Timestamp module automatically included in all classes that include DataMapper::Resource. Moving on, we see the definition of a number of lambdas to be used in setting the four basic timestamps. This is followed by the class method included, which sets up before hooks to apply the timestamps. It all extends our model classes with a timestamps class method. This is a convenience method for defining the various timestamp properties tersely.
5.7.3 Aggregates
The DataMapper core has been designed to limit its use as a reporting tool and simply act as an ORM. The plugin dm-aggregates consequently adds in some of the most common aggregating methods used by SQL databases:
• count—finds the number of records in a collection by directly using a count SQL statement and not the Ruby size method
• min—finds the minimum value of a numerical property using SQL
• max—finds the maximum value of a numerical property using SQL
• avg—finds the average value of a numerical property using SQL
• sum—totals the values of a numerical property using SQL
Chances are you will use dm-aggregates at some point. However, before we look into the source, it’s best to recognize that the plugin essentially extends DataMapper’s capability to what it was not really meant to do.




Above we have included only the code covering the count method. However, it’s easy to recognize the substantial monkey patching going on, particularly in the case of the SQL methods. Otherwise, though, this is a great example of the trickling down of method calls from collections and models into the adapter where SQL statements are formed.
5.7.4 Validations
The plugin dm-validations validates the property values of model objects before saving them. This means that if a model object returns false upon save, you can most likely interpret it as having been caused by undesirable values on properties. Another way to check if a particular model is valid is to directly use the valid? method that is squeezed in before create or update. Before we go any further, here’s a list of the validation methods available within your models through dm-validations:
• validates_present—validates the presence of an attribute value.
• validates_absent—validates the absence of an attribute value.
• validates_is_accepted—validates that an attribute is true or optionally not false through :allow_nil => true. It can also work with a custom set of acceptance values using :accept => [values].
• validates_is_confirmed—validates the confirmation of an attribute with another attribute, for instance, matching password and password_confirmation. The default confirmation attribute is the original attribute ending in _confirmation, but :confirm can be used to set it to anything else.
• validates_format—validates the format of an attribute value against a regular expression or Proc associated by :with. Alternatively, it can be used with predefined formats such as Email and Url through :as. The :allow_nil key is also available.
• validates_length—validates the value of a numeric against a :min or :max value. Alternatively, a range can be used along with :within.
• validates_with_method—validates either the model as a whole or a specific property through a method. If only one parameter is given, it is the symbolic form of the method to check the entire model. If two are given, they are the attribute and the method used to check that attribute. Error messages can be passed as true by returning an array where false is the first element and a string for an error message is the second from the validating method.
• validates_with_block—like validates_with_method but uses blocks. You can validate either against the whole model or a specific attribute as well as pass in error messages.
• validates_is_number—validates that the value of an attribute is a number, appropriate for use in checking the precision and scale of floats.
• validates_is_unique—validates that the attribute value is unique, either within the scope of the attribute value of all other model objects or some other scope specified by an array of property symbols through :scope. Also accepts :allow_nil to be set.
• validates_within—validates that an attribute value is within a set of values specified by :set.
Alternatively, instead of directly using the validations methods, you can include particular hash key-and-values on property definitions. Here’s a list of what keys automatically create appropriate validations:
• :nullable—when set to false, automatically creates a presence validator
• :length or :size—automatically creates a length validator
• :format—creates a format validator
• :set—creates a within validator
Additionally, numerical properties are automatically validated using validates_is_number. To turn off autovalidation on this or any other property type, use :auto_validation => false.
5.7.4.1 Conditions
Validation methods are also capable of generally accepting conditions as Procs assigned to :if or :unless. The single block parameter for these Procs is the resource itself. Thus we can do the following:

For terseness, DataMapper validations also allow us to specify a method as a symbol instead of a full Proc. Here we require only that an experiment be complete for it to have a conclusion:
validates_present :conclusion, :if => :completed?
5.7.4.2 Contexts
Contexts allow us to do validations with similar conditions, but specified at the point of validation. For instance, assuming we have the same Experiment model from before, we may set different contexts on particular property validations specifying that they must be validated together:
![]()
The array assigned to when is an array of contexts. The default context is known as :default. We can now use these contexts by including them as a parameter with valid?:

5.7.4.3 Errors
Every time a model object is validated, it populates (or empties) a hash of errors accessible through the resource instance method errors. These errors can be used to indicate to a user that something went wrong or otherwise recognize what particular attributes are invalid:

Notice how errors.on returns nil when there are no errors. Consequently it can be used to test if an error is present on a property. Also note that error messages are given as arrays. This is because multiple validation errors may have occurred on a single attribute.
5.8 Conclusion
DataMapper is an undeniably excellent ORM. It offers application developers the chance to stay as far away from database work as possible by streamlining development migrations and placing model properties within the model. It also lets us treat ORM objects even more casually by virtue of its eager and lazy loading of data sets. Inside the Merb stack or not, the highly modular DataMapper will serve you well.