
Chapter 3. A Hunting Process
In this chapter, I will discuss the process of hunting. This is an iterative process, similar to engineering or scientific research but bounded by the needs of security and business operations. These constraints mean that the threat hunter needs to keep in mind that their time is limited and that their output should focus on what they, as a hunter, are best at—finding out why something weird is happening. At the conclusion of this chapter, you should have a clear understanding of how to prepare for a hunt, execute it, end it, and transfer the results. To that end, I structure the chapter around six phases: long-term preparation for hunts, triggers for a hunt, starting the hunt, the hunt itself, ending the hunt, and export after the hunt. The hunting model in this chapter is not set in stone; expect to modify it based on your personnel and organizational needs.
Long-Term Preparation
Hunting requires that the hunters have situational awareness about their network, including assets, traffic, and data, achieved through a quality inventory. Before the hunt, and to build up for the hunt, long-term preparation is necessary. Some basic guidance:
-
Asset inventory is a basic requirement; you should be aware of how many assets are connected to your network, the churn of the assets (that is, how much the total count of visible assets changes over time and how individual assets change), as well as events that cause a large change in the asset profile. If you have a CMDB (configuration management database), get a hold of it—it’s both business and security sensible. Be ready as well for assets such as IoT devices, which may require more complex discovery and management because they’re effectively unpatchable.
-
Raw network traffic data is mandatory—by raw, I mean the traffic as seen by routers and switches, not filtered through IDS or firewall logs. A three-tier system that combines a high-level netflow overview of the whole network, selected packet capture, and signature-based detection will provide a solid foundation.
-
Complement network-based instrumentation with host and protocol detection. Collect logfiles in a common location, such as Splunk or an ELK stack, and install some type of endpoint detection tool, at least AV.
-
Continuously audit your data collection systems to ensure they are both working and collecting the right data. Hunters should not be tracking faulty sensors.1
-
Ensure a consistent representation of the data, in particular dates and times. Audit your log output to make sure it’s consistently formatted to reduce correlation overhead.
-
Implement some simple coarse anomaly detectors to provide situational awareness. A top-40 list of port/protocol combinations, a top-100 list of your busiest hosts, and a daily check to see how the lists have changed is a good starting point.
-
A good idea for threat hunting is to have some indication of how much traffic that crosses your network and how many assets you have are unknown, trusted, and handled. Trusted traffic is what you have a strong reason to believe is as advertised; this would include most commercial web traffic, traffic from reputable CDNs, and the like. Handled refers to anything hostile that you have already detected and blocked, routed, or don’t care about—for example, scanning is usually handled by being ignored. Unknown is what’s left.
Long-term preparation is about creating valuable triggers, ensuring that accidents of collection don’t create false triggers, and prepping the data to make the hunt as efficient as possible. Your initial hunts are likely going to tell you more about how poor your network instrumentation is than anything else, and taking the results from the hunt as guidance for better data collection should be a given. More discussion on this is in Chapter 4.
Triggers
There is some overlap between threat hunting and incident response; the difference is in how well-defined the data and the responses are. Threat hunters will be involved when the data needed comes from sources rather than the SIM feed, and when the potential output is not going to be a standard incident report. To understand the difference, let’s look at some common triggers:
-
Threat intelligence identifies a new class of vulnerability. Incident response may respond if there’s a well-defined signature or an existing scanning tool. Threat hunters will focus on less well-defined signatures, such as reading the documentation for the vulnerability and creating new indicators of compromise (IOCs), or creating tools that identify the vulnerable hosts behaviorally. If the vulnerability is long lived, the hunter may eventually transfer the tools over to analysts, while if it’s a short-lived vulnerability, they may train up hunters until the incident is over.
-
Looking through traffic feeds, a junior analyst sees a sudden spike in traffic to a previously unknown protocol or port combination. He escalates this up to a senior analyst, who can’t identify what the traffic is. At this point, the hunters take over the task.
-
A new class of attack is popping up in news articles and threat intelligence feeds. The threat hunting team needs to assess the risk that this attack represents, and tactics for defending against the attack. They identify examples of the attack in their own network, use those to identify behaviors, convert those into signatures, and turn it into a junior analyst process.
Who takes over the role is a function of the quality of the data available, and the expected output. As a rule, SOC analysts work with specific data in and specific outputs; they are highly constrained. Hunters take over when the task requires using data in unorthodox ways, or collecting poorly defined data that will require active investigation. If experimentation, prototyping, or vagueness is involved, it’s the threat hunters’ bailiwick.
Broadly speaking, hunts begin with external or internal triggers. External triggers are going to be threat intelligence in various forms of doneness. Examples include alerts from a threat feed, such as an IOC or an IDS signature, but can just as easily be a blog post. When discussing these triggers, keep track of how done the information is, that is, how well defined it is, and how valuable the payoff was. The more well defined the IOCs, the less it’s a threat hunting problem and the more it’s an incident response problem.
Internal triggers build on situational awareness within the network; the most common internal trigger is simple escalation—a junior analyst gets an alert, doesn’t know what it means, pops it to a senior analyst, the senior analyst doesn’t know, pops it to tier 3, and lets the hunters worry about it. Other approaches include:
- Taking the temperature
-
Hunters and other senior analysts can regularly ask the SOC about unusual or poorly understood phenomena. If someone is seeing something weird, they may not have reported it but may from direct prompting.
- Internal anomaly detection
-
Coarse features such as the top-n lists mentioned in “Long-Term Preparation” are intended to provide threat hunters with triggers. Good hunters may also set up honeypots or other detection tools to provide additional triggers.
- Pure exploration
-
Giving your hunters time to explore and analyze the network will help them develop intuitions about how the network operates and provide guidance for future hunts based on phenomena they uncover in the process.
This list is not exhaustive. Good threat hunters are going to be very self-directed people, and will cull ideas from research papers, conferences, or newspaper articles. Hunts also breed hunts; as part of the after-action for a hunt, the team should track unanswered questions raised by the hunt to look at later.
Starting the Hunt
At the beginning of the hunting process, the hunter should define and bound the hunt. This involves forming a hypothesis, defining the logistics of the hunt, and describing success criteria for the hunt.
To aid in this process, a form like the one in Figure 3-1 can help guide development. This form is intended to be filled out by the hunter, reviewed by the rest of the hunting team, and then used to approve and structure the hunt itself. Forms like this should be kept simple: less than a page and ideally electronic.
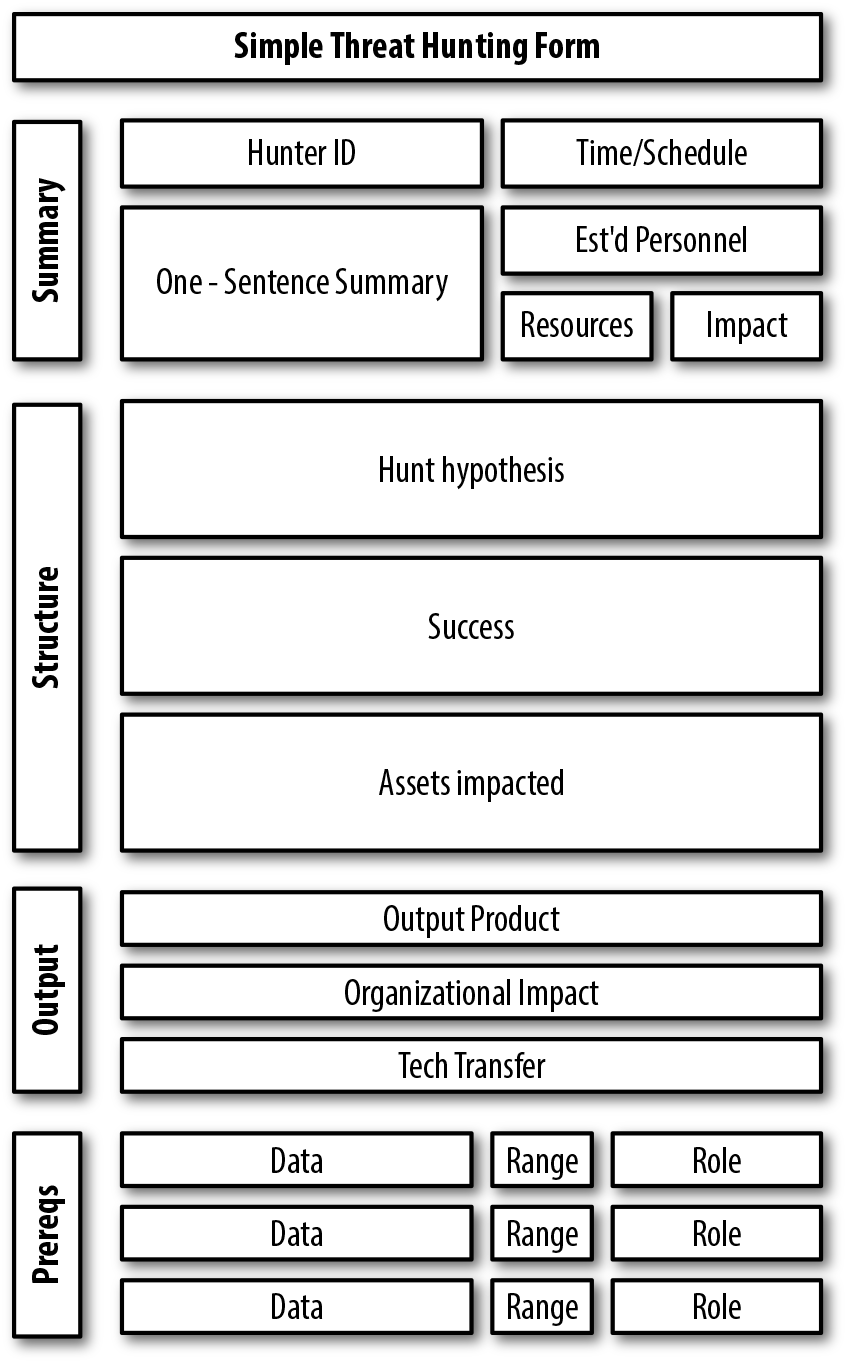
Figure 3-1. A simple form to start a hunt
The form in Figure 3-1 is broken into four sections. The summary, in the top section, should be taken mostly from the rest of the form—it’s intended as a short description of the hunting effort. This description includes the hunter and their short description of the goals (e.g., “Michael Collins, Testing to see whether this spike in UDP/443 traffic is a security risk”). The next boxes begin with some estimates on timing—how long the hunt will take, and if that time is dedicated analyst time or spread out,2 as well as how many personnel are involved (how many hunters, if there’s a need for developers). The last two boxes indicate, briefly, how many resources are needed and the impact. I suggest these be qualitative: low (single hunter, immediate start, existing resources, no data pulls), medium (single hunter, pull data, isolation from operational resources), high (multiple hunters, long data pulls, installing or setting up software).
The next section, structure, is going to be up for review and evaluation by the hunting team. The hunter should state a clear and falsifiable hypothesis about their hunt (e.g., “Port 443 traffic is caused by this previously unseen Google protocol; if this is the case, then I expect to see the majority of the traffic is associated with Google. Examples of association may include Google addresses or Chrome browsers”), then criteria for success (“If I am correct, then I should be able to account for the majority of UDP/443 traffic by looking for Google indicators”) and what assets are impacted (“I will need NetFlow records, proxy logs, and a list of browsers from a selection of HTTP clients whose IPs will be identified during the hunt”).
The third section, output, focuses on what the organization gets from the hunt. This should include the expected product, such as a presentation, network reconfiguration, or a new tool. The analyst should include an argument for why the organization cares about this hunt—its impact on operational security or the organization as a whole. Finally, the analyst should include an estimate for tech transfer; this is a hedged bet, not a prediction, and the analyst should indicate whether they think they’ll need a developer to transfer the technology or if this is going to be something that can be handled with existing tools. The analyst should specify the tech transfer with specific tools in mind—for example, if Splunk is your preferred SIEM, how the tool would output Splunk-friendly data.
The final section is a list of any data and the ranges of that data the hunter needs for the hunt. This forms the basis of the big pull, a pull of all the potentially relevant data the hunter believes they’ll need, which is duplicated from and isolated from operational data so that the hunter doesn’t interfere with normal operations.
Once the hunter has filled out the form, they should include the hunt’s triggers and the form should be reviewed by members of the hunting team and ideally at least one data person, who would be responsible for fetching the data. The team’s job is to challenge the hunter—identify logical fallacies, and verify that the right data is being pulled and is available, and that the data chosen is complete. This meeting is a critique, so the team should be politely confrontational—the goal is to identify the mistakes before someone has to explain to the CEO why the entire network went down for three days. For a mature hunting team, a hunt that’s proposed at a shift’s beginning should be collecting data by shift’s end.
The Hunt Itself
Now we hunt. Figure 1-2 (in Chapter 1) and Figure 3-2 describe the basic process of the hunt. Figure 1-2 describes the entire hunt from beginning to end, and we have largely covered it in the rest of the chapter. At this point, we want to focus on the iterative hunt shown in Figure 3-2.

Figure 3-2. A basic hunting loop
The most common point of conflict when threat hunting involves pulling the relevant data. Hunters are normally pulling large, complex sets of data, often using the same resources that the SOC is. If your hunters are not careful, they will delay SOC operations with their own pulls—query contention is a real problem on large operational floors. There are two ways to solve this problem: you can spectacularly overprovision your collection system (something which, while easier to do with modern storage architectures, is still expensive), or you can isolate your hunters. I refer to the second strategy as “big pull, little pull.”
During the hunting proposal process (see “Starting the Hunt”), the hunter draws up a list of needed data. This data set should be chosen to be larger than expected, with the intent that the hunter will refine it on his or her own after pulling it. This big pull can then be conducted during off hours. The goal is, if at all possible, to isolate all the data that might be used for the hunt and move it over to a separate database, instance, or environment so that the hunter can work without interfering with operations.
The hunter then conducts little pulls off of the big pull. Little pulls are selections of data to test specific hypotheses. For example, a big pull might consist of all the traffic from a specific subnet over the course of a month, while the little pulls are daily traffic from specific IP/port combinations in that big set.
The loop in Figure 3-2 takes place within the context of a little pull, and represents the iterative steps that will take place during the majority of the hunt. The core process of the hunt is iterative refinement and expansion—refinement is the progressive filtering of data to remove corner cases, false positives, and noise, while expansion is the extension of the dataset based on further observations.
The loop generally operates as follows:
-
The hunter selects some data from the pull based on their initial intuitions, indicators of compromise, or other information.
-
The hunter converts the pulled data into some type of manipulable form or statistic, then examines the output to find specific cases.
-
The hunter investigates those specific cases—and from those investigations, creates new rules to refine the data.
In the majority of the cases observed, the hunter is going to find noise, transience, innocence, or other indicators that the case is not directly relevant to the investigation. The hunter will then refine the search to remove those elements from the hunt. At the same time, the hunter sorts through the information to find additional evidence of related phenomena. This expansion grows the dataset; as the hunter progresses, this loop of refinement and expansion increasingly covers the phenomena of interest.
There are innumerable variations on this process:
-
The hunter may find that the data they need is not in the set and requires another big pull. This is particularly common with forensic investigations; from the little pull, the analyst may isolate a particular IP address as a problem and then need that address’s complete history.
-
The hunter may set up sensors or collection systems to lie in wait. Instead of pulling data retrospectively, they set up sensors and wait until an event occurs.
-
The hunter may use a lab to collect specific samples or examples of phenomena. This is particularly important when discovering new services or classes of network traffic.
Ultimately, the data pulled is not the only data the hunter uses; the intent is that data from the pull is the most expensive data to query. A hunter may examine WHOIS data, lookups, even experimental data—the pull system is intended to reduce the impact of operational analyses, not chain the hunt.
Ending the Hunt
Threat hunting is not academic research—in an academic environment, the process of hunting and refinement is focused on constantly poking at the data until all options have been exhausted. Hunters are in a business environment; they have a schedule and multiple priorities. The criteria for ending the hunt should be laid out at the beginning of the hunting process as discussed in “Starting the Hunt”.
While hunts are not as constrained as normal incident response, they use your most expensive resource, senior analyst time. Hunter time may also be more split up—in particular, if the hunt is going to use expensive or longer pulls of data, those pulls may be best done during off hours. It is possible for a hunt to consist of a very long period of data collection followed by a short, quick period of data analysis. For this reason, data collection defines the minimal period of the hunt; your data team should be able to estimate how long it takes to pull the data and to conduct a query.
Following the floor set by the data, the actual time required is driven by the severity of the hunt’s impact and the hunter’s success criteria. The truth is that, as a creative process, the output is weighed in the context of the time investment—more time is more loops and more cases addressed, but a good hunter is going to reach a point of diminishing returns very quickly.3 For this reason, it’s best to consider periodic reviews—a short hunt may complete in a day; if a longer hunt is expected to take a week or so, then there should be a review two or three days in to make sure that the hunt is producing results.
The goal of any mid-hunt review is to determine if the hunt is actually progressing. There are a number of reasons that a hunt may not progress, including:
- The goal’s been met, and nobody realizes it
-
It’s not uncommon for a hunter to reach a conclusion, and then walk right past it because it’s too simple. If the team can identify that goal and agree that the hunt’s been addressed, then close it out.
- A new shiny object
-
Hunting often uncovers more questions than answers, and the hunter may get distracted by something else. The team should evaluate whether the shiny object merits a new hunt, and whether that hunt should start now or can be put off until the current one is completed.
- Lost in technology
-
The hunter may want to try out a particular tool or technique, and get lost in the minutia of setting it up. If a new tech takes more than a day to set up and use for the hunt, it’s a distraction and should be handed over to an infrastructure team to handle while the hunter returns to their work.
- There’s nothing there
-
This one always hurts, but sometimes a hunter’s original hypothesis is wrong and they can’t find what they’re looking for. It’s time to close out the hunt.
- The hunt isn’t happening
-
Hunters are expensive resources and usually are on call for multiple projects at any one time. This may involve reassigning personnel so that the hunter can focus.
Hunts should be quick; most hunts are going to end up being failures, and it’s best to rip off the band-aid and move on to the next of the infinite queue of potential hunts and security projects. As a rule of thumb, a short hunt is about a day and won’t have a mid-hunt review, just an end review. A medium-term hunt may take three days to a week, so have a review on the second day to ensure that it’s progressing as expected; after the midterm review presumptively schedule the end review early the following week. An absurdly long threat hunt is two weeks; the vast majority of hunts should be far shorter. Hunts will come up dry a lot: kill, document, and move on.
Output from the Hunt
After finishing the hunt, the hunter and the team should consider the actual output, what’s going to be transferred to other teams. This can come in four forms: briefings, TTPs (tools, techniques, and procedures), modifications to infrastructure, and future hunts.
Every threat hunt should result in an after-action briefing. This report should summarize what the hunter proposed, what the hunter discovered, and how he got from point A to point B. It is intended for consumption by senior analysts and the threat hunting team. For short hunts, this may be the only output.
TTPs are the output for analysts. These products usually require some post-processing before they’re SOC friendly, and may best be handled by having the hunter specify them while other developers or writers work on them. Example outputs here includes:
- Training
-
This includes slides or a manual explaining how to replicate the hunter’s results. Training assumes that there are no significant technical changes to the existing SOC.
- Software
-
The hunter may develop prototype software in the form of scripts, dashboards, and programs. This normally has to be handed over to developers to turn into something maintainable and robust with good perfomance. Software almost always requires companion training.
- Threat intelligence
-
This includes elements such as behavior indicators, attacker TTPs, and other information that may be fed into existing detectors.
Infrastructure modifications come out of discoveries about the network during a hunt. These include things like missing sensors, misconfigured sensors, network blindspots, and data that the hunting team would like to have but doesn’t yet have access to. During your initial hunts, you can expect much of the output to be infrastructurally oriented; hunters always find out what’s odd about the network.
Finally, hunts breed hunts. During the hunting process, the hunter will find other issues that merit future activity. A hunting team should record these and regularly review them—after time, they will see patterns, and will be able to identify which hunts are the best ones to consider next.
1 They will, but they shouldn’t have to.
2 For example, if the hunt requires waiting until an event occurs, it may be ongoing without a large time investment but still take a significant amount of calendar time.
3 To quote Lorne Michaels, “The show doesn’t go on because it’s ready, the show goes on because it’s 11:30.”
4 Remember when the first Gmail invite was so exciting?