
Crack the Data Product Management Code
Aspects of Data Product Management
We have all heard about growing data volume in recent years. Let us quantify the “how big” and “why now” questions around data growth. By 2025, the volume of worldwide data is expected to explode to 180 zettabytes.46 How much is zettabytes anyway? It is 180 followed by 21 zeros. Seems to be a large number but to make it relatable let us use an example. Seagate became the first company to ship 3 ZB, which is enough storage to hold 30 billion 4K movies (that would take 5.4 million years to watch)!47 Global data and organizational data are growing at rapid speeds due to changes in how we operate. Some of the contributing factors for this continued data growth are an increase in horizontal business structures, a pandemic-related uptick in vertical integration across industries, the increased availability of public data, and continuous technological innovation and advancements.48 These have created new facets of the data revolution with ability to collect and store data being one major facet, along with the capability to derive meaning from it being another critical facet.
There is a good balance of a juggler needed to create a good data product that strike an equilibrium between business needs, strategy, value, governance, and technology.
There are also three key areas that are constantly changing and improving for the better. A good data product should create harmony between Technology, Data, and Creativity.
• Technology: There is a burst in both the number of tools and the functionality they offer.
• Data: Our society collects a large volume of data, and the devices that can transmit data keeps proliferating. Years ago, it was unheard of for a washing machine or a garage door to capture or transmit data. With the IoT, the connectivity of objects is constantly evolving and leading to more data variety and volume.
• Creativity: The growth and diversity of data has sparked new creative potential. Analysis that would have been impossible a decade ago is now possible—at close to real time.
Building a portfolio of data products is not an easy task, and without the right methodologies, it’s even more challenging. To build an efficient product road map, start by answering the following questions:
• What does my business need and high-level requirements? Equally important is knowing which stakeholders you need most, to avoid “swoop and poop” events. Have you ever worked on a data project with a certain group of stakeholders only to realize toward the end that there are other stake-holders whose buy-in is even more critical? Building a good data product means knowing whom to partner with. It also requires understanding the business problem (brainstorm and offer various ways of solving it) and select the best approach in terms of time, ease of use, cost, and feasibility of solution.
• Which metrics would be best to evaluate the product and prioritize the product backlog? (See Chapter 5.)
• Do I have the necessary data and skilled data team? Do I need external data from outside my organization to build my products?
• What will be the adoption rate of this product, and who can influence it? I have seen many data products get built only to be poorly adopted because no one knows it exists, no one knows to use it, the product does not help them, or multiple similar solutions already exist.
• How will I collect and incorporate feedback? Have a plan about the frequency at which you will roll out the product for user feedback.
There are various software development and project management frameworks to help develop and organize work to more quickly create business value. But the goal of all these frameworks is the same: to improve productivity while reducing waste and inefficiencies. Scrum is one such framework widely used and extremely popular for software development. Scrum employs an iterative, incremental approach to optimize predictability and to control risk.49 What methodology to use for data projects? It is unclear if a scrum framework would work as effectively for data product development. Will a different framework or methodology work better for data needs? What are the advantages and disadvantages of various frameworks and methodologies? Let us compare various frameworks to determine what can be applied to data products.
Myths Around Agile Minimum Viable Product Delivery of Data Products
Agile is an overarching methodology with a set of principles for software development with several popular frameworks like Scrum and Kanban.50 A minimum viable product (MVP) is a version of a product with just enough features to be usable by early customers who can then provide feedback for future product development.51
Let’s take our favorite kitchen example from Chapter 3. We are in a kitchen, trying to make a donut. This is what an MVP for a donut might look like:

Creating MVP
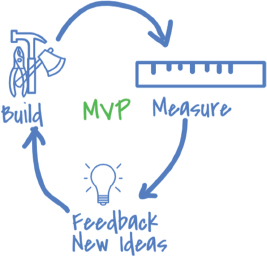
MVP Life Cycle
The idea of agile MVP is to build the minimum functional product, evaluate it, and improve it iteratively until a final product is complete.
A common myth is that all data products can be built using agile MVP principles. But although MVP concepts are beneficial for some data products, for others it only increases the cost of development. In addition, the effectiveness of agile MVP concepts depends on the data maturity of the organization and the team’s understanding of the required data.
MVP is a simple concept with two key steps: (1) build something usable fast (with the minimum needed features), and (2) get feedback to improve it. MVP is about building a prefinal version of a product with foundational features, and additional features will be added iteratively based on feedback.
• The struggle with applying an agile MVP framework to data products lies in figuring out the minimum data needed and identifying key features. Also, data product development involves significant experimentation with data, EDA, and exploration of new tools, exercises that are sometimes overlooked. If a data team is not familiar with the underlying data, the MVP might contain some basic functionality that is useless for its intended audience.
• Another struggle is getting user feedback and incorporating it. It is relatively simple to show users a website MVP where they can try out the core features and provide additional feedback. With data products, there is an expected interpretation expertise needed like this data insight can help me to take this action, which is not my primary problem. Maybe I have better problems I want to address first, which current MVP data does not include and user does not know if such data exists. The user is expected to connect the dots while also providing feedback for the data product, which is challenging.
• A better approach for data products is to use a proof of concept (PoC) to test a new tool—or to determine if its functionalities are even useful—before jumping ahead with an MVP just for the sake of using the agile framework.
• It is not useful to waste time and money building a bunch of unnecessary or “not needed” data MVPs. Many times, the attitude toward early data product development is to build an MVP fast as we do not know what is needed yet instead of really building a valuable blueprint first. Data products can benefit when teams know when to use PoC instead of MVP, and when they supplement these methods with user brainstorming sessions.
Which Methodology to Use
Scrum Versus Kanban
Most likely your organization uses Scrum, Kanban, or both across various software development teams. Both these frameworks are extremely popular framework and many IT teams either already use or in process of using Scrum or Kanban but do they work for data product development?
Let’s start with some differences between Scrum and Kanban.
The Dedicated Role Challenge of Scrum
In the scrum framework, work is divided into small tasks to be completed in fixed periods of time called sprints. Most sprints typically last two to three weeks. Scrum uses defined roles like product owner, scrum master, and development team. Scrum is a structured agile framework, whereas Kanban is a lightweight framework. Kanban has a long history that predates its application to software development. In early years, it was used by the Toyota automobile company to improve efficiencies via just-intime manufacturing—producing only what is needed based on customer needs. Kanban is a Japanese word that means Kan = Sign, Ban = board.52 As the name suggests, Kanban is a visual representation of work that aims to minimize work-in-progress items and constantly improve the overall flow of work. Unlike Scrum, Kanban has no required roles like product owner or scrum master.
Most Kanban teams prefer to use a wall with sticky notes to demonstrate work in progress, unlike scrum teams that use cloud management tools like Jira. Scrum is immutable, which means participants should commit to it in absolute and not pick and choose only certain elements of it. Although scrum teams can use a wall to demonstrate their work, most teams I have worked with do not. This is a contrast to Kanban’s emphasis on keeping things visual. During COVID, sharing a physical wall has been challenging for team members working remotely. But seeing a wall that shows work in progress is both interactive and attractive—any executive or cross-functional team member passing by will get curious about what is being developed.
The Time Box Challenge of Scrum
Another major difference between Scrum and Kanban is that Kanban does not employ fixed time iterations or even time boxes. Kanban’s objective is to move tasks from “doing” to “done” quickly and then to pick the next task. Scrum, with its fixed-length iterations, is less flexible, and employs a structured plan of how many story points the team will deliver each sprint.
Being Structured and Rigid Scrum or the Adaptation Challenge
Scrum is well suited to projects for which goals are clearly defined and work can be broken down to the story level. Kanban works better for production support teams with lot of incoming requests and teams that do not always know what needs to be delivered within the next two weeks. Scrum does not work well for more innovative products where lot is unknown and those that are not building upon or comparable to previous versions to follow along. Many data product tasks evolve over time, and teams often spend the initial weeks simply identifying the various tasks required to develop the product. Most data teams do not have a product owner, and rightly so: data products involve multiple stakeholders, and it is impossible for one product owner to possess the breadth of knowledge or task-level expertise to plan a scrum sprint. Kanban works better for data products because it is adaptable.
The Meetings Saga Overhead of Scrum
Scrum also entails a variety of scrum ceremonies, like sprint planning to sprint retrospectives. Although the intention of the retrospective is to create a list of lessons learned and thus improve future sprints, sprint retrospectives can drag along. Team members often perform them more to satisfy the requirement of hosting a retrospective than because they plan to incorporate the feedback. And scrum retrospective meetings are facilitated by a scrum master—a role that most data teams neither have nor need.
Data products often benefit more when teams document feedback from stakeholders or internal lessons learned—“the learning curve for this tool was steeper than anticipated,” “missing metadata made it hard to understand the data elements”—on an ongoing basis, rather than waiting for a dedicated retrospective meeting.
The Everyone-Needs-to-Do-Scrum Challenge
I have been involved in teams that tried to fit every data project into Scrum because that was the only framework used for development work in the organization. These teams were not aware of the new technologies required, and so they faced a learning curve. Even when they were familiar with the required development tools, they were unwilling to explore alternate methods to implement in the feature. This resulted in adding few “Design Spike” stories in each sprint. Design spike is a user story type to reserve time to explore viable options and acceptance criteria for such story is detailed documentation of findings. In theory, it appeared the time was delivering 15 story points in a sprint, but more than half was design spike or rework from previous sprints adding no value. The team was only Band-Aiding the previous sprint’s work in the “We do Scrum for data projects.”
Conclusion
In short, do not force Scrum for data products, because other frameworks work better for data initiatives. Kanban, for instance, is more flexible and adaptable when you do not have a clear definition at the start of what needs to be done (or when you have a high-level definition that you want to fine-tune over time). At times like this, your team does not need to spend its energy time-boxing or attending ceremony meetings. Kanban also works efficiently when development must involve a wide range of stakeholders, which is the case for many data products. In the pursuit of a better framework for data products, some teams are starting to use hybrid of Scrum and Kanban called “Scrumban,” which combines the benefits of both approaches in a happy middle ground.
CRISP-DM
If you worked in teams being pushed to use Agile for everything, chances are you have begun to explore other available frameworks that may be better suited to data initiatives. One such framework is CRISP-DM. Although CRISP-DM has been around for a long time, many teams have not heard of it. Scrum and Kanban have become the “go to framework” and megastars for software development and any organization aiming to deliver software fast, but a go-to framework for data and analytics products does not exist. Now that industries across the board are turning their focus to data, it is common for data teams to use Scrum or Kanban without exploring any other frameworks.
CRISP-DM, which stands for CRoss-Industry Standard Process for Data Mining, was first conceived in 1996 by DaimlerChrysler, SPSS, and NCR.53 CRISP-DM consists of six parts: Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation, and Deployment. It is a flexible framework, and the sequence of these six parts can be changed as needed.
One challenge of implementing the CRISP-DM steps sequentially is that it can become a “waterfall” methodology in which no business value functionality can be showcased until all the steps are finished. CRISP-DM principles work better when implemented alongside some agile principles like iterating frequently to gain stakeholder feedback.
Imagine you are baking a multilayer cake. If you want to offer it for tasting, you will naturally make a vertical slice of the cake instead of horizontal slice that contains only a single layer by itself. The same is true with CRISP-DM: if you make a change to the entire database before starting the next step, you cannot show the product to the user and expect feedback on its functionality. The backend change is boring to the end user and cannot use the functionality by itself to provide feedback. It would be like asking your cake taster to try only one layer. As a result, CRISP-DM needs to be implemented with vertical slicing principles (shown in the following image) to engage users sooner than waiting till the end of the process.
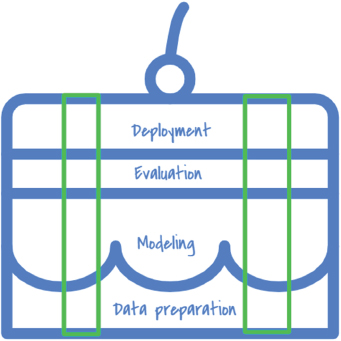
CRISP-DM
The SEMMA process was developed by the SAS Institute a few years after the introduction of CRISP-DM. SEMMA stands for Sample, Explore, Modify, Model, Assess.54 SEMMA is less used compared to CRISP-DM and is more common among SAS users than widely used for data product development.
Microsoft TDSP
The newest framework in our comparison is Microsoft’s TDSP, which stands for Team Data Science Process. It is an iterative agile methodology to deliver predictive and intelligent analytics solutions.55 It was developed mainly for data science projects. Exploratory data and analytics projects can also use it by eliminating some of the steps of this life cycle. It focuses on five major areas:
• Business understanding
• Data acquisition and understanding
• Modeling
• Deployment
• Customer acceptance
It is a modern framework focusing specifically on the data projects, and it acknowledges the differences between software and data development. Teams can implement TDSP along with CRISP-DM or scrum. The approach addresses gaps in CRISP-DM by, for example, defining six team roles. Microsoft provides detailed documentation for each stage of the life cycle. Some teams find it difficult to follow such detailed documentation, while other find TDSP’s fixed length sprints frustrating.
Despite its business-understanding step, TDSP, unlike CRISP-DM, focuses mainly on the technical aspects of defining and finding anomalies in data rather than the business value the product will deliver. Also, TDSP removes CRISP-DM’s essential step of evaluation, thereby neglecting to require teams to assess their products against business objectives. It is not enough to build a technical data product—teams must ensure that their solution solves the business problem as well.
The Struggle With the “Definition of Done”
Scrum and Kanban teams are required to follow the definition of done (DoD), which means team members must have a shared, transparent understanding of what it means for work to be completed. In other words, the DoD comprises a set of testing scenarios or acceptance criteria to verify the completed work. Teams define DoD at the product level and as work is completed as a part of a sprint—every sprint must result in a releasable increment of the product that meets the DoD.56
However, in the development of a data product, there is lot of data discovery and research activities that will never reach a shippable state. In such cases, it is impossible to define the DoD because the future is not yet determined.
But data product development frameworks could benefit from an adapted version of DoD. Instead of defining DoD at only the product level, there can be DoD for different elements, such as data science models, data analytics, data visualizations, and so on. Examples of DoD include a verified solution for governance, documented data sources, models reviewed for bias, an updated data catalog with new business glossary terms, and proof that the underlying data architecture has been followed. A DoD for data products helps achieve a high-level understanding and agreement about what to expect when development is complete.
DataOps
Until now, we discussed different frameworks for managing and organizing work tasks of data products or the “How.” As the volume of data increases, managing that data spawns new challenges as well as opportunities. There is no use in collecting this volume of data if your data team insights cannot put insights into the hands of decision makers fast. If business users and decision makers must wait months for any kind of report or insight, how can data provide any competitive advantage? Time is of essence for benefitting from insights. In this section, we will be discussing the “what”: the underlying setup required to quickly extract meaning from this large volume of data. Having the wrong data or inaccurate reports is costly in terms of missed opportunities, loss of user trust in data, and compliance issues. Is there a better way to handle data to avoid these costly mistakes?
Pandemic-related decisions required enormous speeds of processing data to decide when to open schools, how much a store should stock, or even how fast banks should process loans. Back in March 2020, the CARES act established the Paycheck Protection Program to help small businesses with access to borrow money.57 Small businesses were desperate to apply for these loans, but banks were not prepared to accept and process this volume spike of loan applications with the exception of one bank.58 Bank of America became the first major bank to successfully handle this spike. My own personal experience with some banks has been painful—I struggled with one major bank, for example, that allowed customers to load loan documents online, but there was no way to view your list of loaded documents or even learn the status of the application. The only way to gain this information was to call and find if they received your document or status of processing. This scenario shows just how little banks were prepared for a digital transformation on this scale. Those few banks that could accept and process higher volumes of data, gained a competitive advantage in the form of more customers and improved customer satisfaction.
The effectiveness and speed of data journey (from data creation to consumption) within an organization is critical to act fast with data (Bank of America example). This means some aspects of this data processing needs to be automated and error rate should be minimal. This fast data journey is an emerging area called “DataOps.”
• How could some banks adapt to this volume of data and others could not?
• What exactly is DataOps and why should my team care about it?
• Anyone working with IT would have heard DevOps. Is DataOps DevOps for Data?
Although both DevOps and DataOps use agile principles and place an emphasis on making continuous improvements, one key difference is users play a bigger part in DataOps by providing feedback. DevOps is also a mature, proven approach, whereas DataOps is in its early stages. And data analytics challenges cannot be solved by exploiting DevOps practices due to data analytics’ heterogeneous nature.59
In simple terms, DataOps is about getting quality data in the hands of users and decision makers by reducing data analytics cycle time. Unlike DevOps, DataOps implementation steps are not well defined, and organizations are still testing various ways to implement it. There are a few definitions of DataOps implementation, however, from DataKitchen and iCEDQ. DataKitchen suggests there are seven steps to DataOps implementation: add automated monitoring and tests, use a version control system, branch and merge, use multiple environments, reuse and containerize, parameterize your processing, and work without fear or heroism;60 iCEDQ describes DataOps as culture plus tools plus practices.61
DataOps is an emerging approach still surrounded by ambiguity and challenges. Hopefully, ways of implementing DataOps will evolve, with experimentation by organizations and data enthusiasts, and bring sufficient uniformity to cater to the wide range of data needs across organizations. Maturing DataOps to the next level will provide organizations with the ability to realize benefits from large volumes of data. DataOps will help organizations eliminate departmental silos, and hence provide organizations the means to measure their collective strength of data assets or identify gaps. DataOps will lead to better data quality and hence improving trust of data across the organization.
Next Steps
We have discussed various frameworks for building data products, but picking the right framework depends on factors such as learning curve, organizational culture, and type of supported data products. At their core, all frameworks aim to deliver a valuable product, but the steps to get there differ. Data products comes in all shapes and forms, from EDA to visualization suites, from knowledge graphs to customer insights analytics solutions, and to everything in between. So one size does not fit all when you’re picking the ideal framework for building data products. All frameworks have their own strengths and disadvantages and hence devote your energy to selecting a framework that can be tailored to your team’s needs. As data tools and product development techniques are constantly improving, it is essential to pick a flexible framework. Depending on your organizational culture and approach to handling data products, you may even have to combine the principles of various frameworks to create a customized version instead of using any one framework in its entirety. The how and what need to go hand in hand in order to rapidly build a valuable data product.