
A time series is a sequence of time-dependent data points. For example, the demand (or sales) for a product in an e-commerce website can be measured temporally in a time series, where the demand (or sales) is ordered according to the time. This data can then be analyzed to find critical temporal insights and forecast future values, which helps businesses plan and increase revenue.
Time series data is used in every domain where real-time analytics is essential. Analyzing this data and forecasting its future value has become essential to these domains.
Time series analysis/forecasting was previously considered a purely statistical problem. It is now used in many machine learning and deep learning–based solutions, which perform equally well or even outperform most other solutions. This book uses various methods and approaches to analyze and forecast time series.
This chapter uses recipes to read/write time series data and perform simple preprocessing and Exploratory Data Analysis (EDA).
The following lists the recipes explored in this chapter.
Recipe 1-1. Reading Time Series Objects
Recipe 1-2. Saving Time Series Objects
Recipe 1-3. Exploring Types of Time Series Data
Recipe 1-4. Time Series Components
Recipe 1-5. Time Series Decomposition
Recipe 1-6. Visualization of Seasonality
Recipe 1-1A. Reading Time Series Objects (Air Passengers)
Problem
You want to read and load time series data into a dataframe.
Solution
Pandas load the data into a dataframe structure.
How It Works
The following steps read the data.
Step 1A-1. Import the required libraries.
Step 1A-2. Write a parsing function for the datetime column.
Step 1A-3. Read the data.

parse_dates mentions the datetime column in the dataset that needs to be parsed.
index_col mentions the column that is a unique identifier for the pandas dataframe. In most time series use cases, it’s the datetime column.
date_parser is a function to parse the dates (i.e., converts an input string to datetime format/type). pandas reads the data in YYYY-MM-DD HH:MM:SS format. Convert to this format when using the parser function.
Recipe 1-1B. Reading Time Series Objects (India GDP Data)
Problem
You want to save the loaded time series dataframe in a file.
Solution
Save the dataframe as a comma-separated (CSV) file.
How It Works
The following steps read the data.
Step 1B-1. Import the required libraries.
Step 1B-2. Read India’s GDP time series data.
Step 1B-3. Plot the time series.

Step 1B-4. Store and retrieve as a pickle.

Recipe 1-2. Saving Time Series Objects
Problem
You want to save a loaded time series dataframe into a file.
Solution
Save the dataframes as a CSV file.
How It Works
The following steps store the data.
Step 2-1. Save the previously loaded time series object.
Recipe 1-3A. Exploring Types of Time Series Data: Univariate
Problem
You want to load and explore univariate time series data.
Solution
A univariate time series is data with a single time-dependent variable.
Let’s look at a sample dataset of the monthly minimum temperatures in the Southern Hemisphere from 1981 to 1990. The temperature is the time-dependent target variable.
How It Works
The following steps read and plot the univariate data.
Step 3A-1. Import the required libraries.
Step 3A-2. Read the time series data.
Step 3A-3. Plot the time series.

Time series plot
This is called univariate time series analysis since only one variable, temp (the temperature over the past 19 years), was used.
Recipe 1-3B. Exploring Types of Time Series Data: Multivariate
Problem
You want to load and explore multivariate time series data.
Solution
A multivariate time series is a type of time series data with more features that the target depends on, which are also time-dependent; that is, the target is not only dependent on its past values. This relationship is used to forecast the target values.
Let’s load and explore a Beijing pollution dataset, which is multivariate.
How It Works
The following steps read and plot the multivariate data.
Step 3B-1. Import the required libraries.
Step 3B-2. Write the parsing function.
Step 3B-3. Load the dataset.
Step 3B-4. Do basic preprocessing.
This information is from a dataset on the pollution and weather conditions in Beijing. The time aggregation of the recordings was hourly and measured for five years. The data includes the datetime column, the pollution metric known as PM2.5 concentration, and some critical weather information, including temperature, pressure, and wind speed.
Step 3B-5. Plot each series.

A plot of all variables across time
Recipe 1-4A. Time Series Components: Trends
Problem
You want to find the components of the time series, starting with trends.
Solution
A trend is the overall movement of data in a particular direction—that is, the values going upward (increasing) or downward (decreasing) over a period of time.
Let’s use a shampoo sales dataset, which has a monthly sales count for three years.
How It Works
The following steps read and plot the data.
Step 4A-1. Import the required libraries.
Step 4A-2. Write the parsing function.
Step 4A-3. Load the dataset.
Step 4A-4. Plot the time series.

Output
This data has a rising trend, as seen in Figure 1-6. The output time series plot shows that, on average, the values increase with time.
Recipe 1-4B. Time Series Components: Seasonality
Problem
You want to find the components of time series data based on seasonality.
Solution
Seasonality is the recurrence of a particular pattern or change in time series data.
Let’s use a Melbourne, Australia, minimum daily temperature dataset from 1981–1990. The focus is on seasonality.
How It Works
The following steps read and plot the data.
Step 4B-1. Import the required libraries.
Step 4B-2. Read the data.
Step 4B-3. Plot the time series.

Output
Figure 1-7 shows that this data has a strong seasonality component (i.e., a repeating pattern in the data over time).
Step 4B-4. Plot a box plot by month.

Monthly level box plot output
The box plot, Figure 1-8, shows the distribution of minimum temperature for each month. There appears to be a seasonal component each year, showing a swing from summer to winter. This implies a monthly seasonality.
Step 4B-5. Plot a box plot by year.

Yearly level box plot
Figure 1-9 reveals that there is not much yearly seasonality or trends in the box plot output.
Recipe 1-4C. Time Series Components: Seasonality (cont’d.)
Problem
You want to find time series components using another example of seasonality.
Solution
Let’s explore tractor sales data to understand seasonality.
How It Works
The following steps read and plot the data.
Step 4C-1. Import the required libraries.
Step 4C-2. Read tractor sales data.
Step 4C-3. Set a datetime series to use as an index.
Step 4C-4. Format the data.
Step 4C-5. Plot the time series.

Output
From the time series plot, Figure 1-10 shows that the data has a strong seasonality with an increasing trend.
Step 4C-6. Plot a box plot by month.
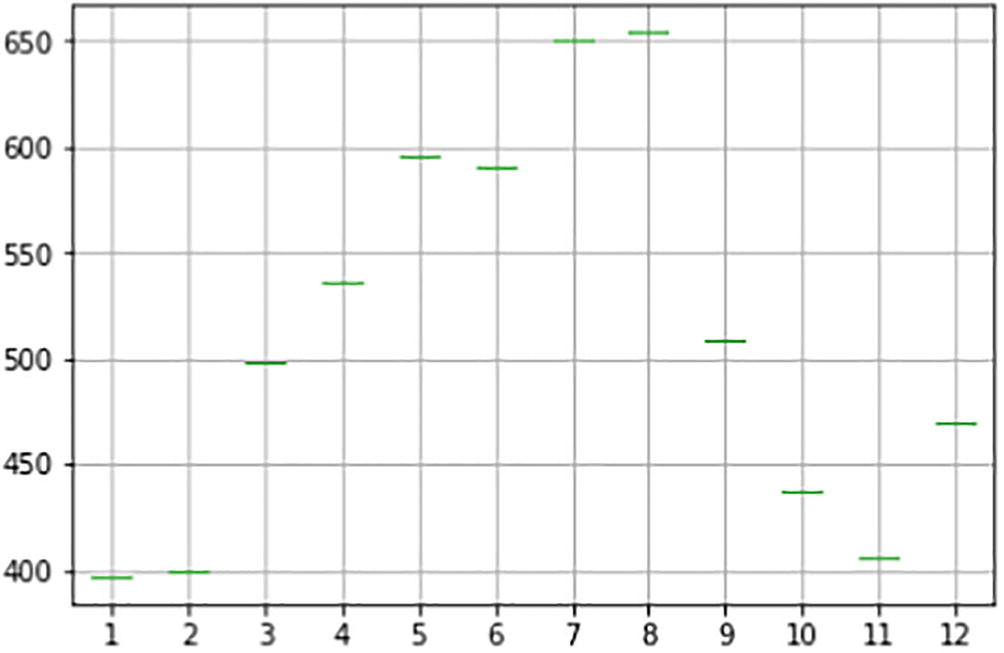
Monthly level box plot
The box plot shows a seasonal component each year, with a swing from May to August.
Recipe 1-5A. Time Series Decomposition: Additive Model
Problem
You want to learn how to decompose a time series using additive model decomposition.
Solution
The additive model suggests that the components add up.
It is linear, where changes over time are constantly made in the same amount.
The seasonality should have the same frequency and amplitude. Frequency is the width between cycles, and amplitude is the height of each cycle.
The statsmodel library has an implementation of the classical decomposition method, but the user has to specify whether the model is additive or multiplicative. The function is called seasonal_decompose.
How It Works
The following steps load and decompose the time series.
Step 5A-1. Load the required libraries.
Step 5A-2. Read and process retail turnover data.
Step 5A-3. Plot the time series.

Figure 1-12 shows that the trend is linearly increasing, and there is constant linear seasonality.
Step 5A-4. Decompose the time series.

Time series decomposition output
Step 5A-5. Separate the components.
Recipe 1-5B. Time Series Decomposition: Multiplicative Model
Problem
You want to learn how to decompose a time series using multiplicative model decomposition.
Solution
A multiplicative model suggests that the components are multiplied up.
It is non-linear, such as quadratic or exponential, which means that the changes increase or decrease with time.
The seasonality has an increasing or a decreasing frequency and/or amplitude.
How It Works
The following steps load and decompose the time series.
Step 5B-1. Load the required libraries.
Step 5B-2. Load air passenger data.
Step 5B-3. Process the data.

Step 5B-4. Decompose the time series.

Time series decomposition output
Step 5B-5. Get the seasonal component.
Recipe 1-6. Visualization of Seasonality
Problem
You want to learn how to visualize the seasonality component.
Solution
Let’s look at a few additional methods to visualize and detect seasonality. The retail turnover data shows the seasonality component per quarter.
How It Works
The following steps load and visualize the time series (i.e., the seasonality component).
Step 6-1. Import the required libraries.
Step 6-2. Load the data.
Step 6-3. Process the data.
Step 6-4. Pivot the table.

Step 6-5. Plot the line charts.

Quarterly turnover line chart
Step 6-6. Plot the box plots.

Quarterly level box plot
Looking at both the box plot and the line plot, you can conclude that the yearly turnover is significantly high in the first quarter and is quite low in the second quarter.