
Univariate time series data analysis is the most popular type of temporal data, where a single numeric observation is recorded sequentially over equal time periods. Only the variable observed and its relation to time is considered in this analysis.
The forecasting of future values of this univariate data is done through univariate modeling. In this case, the predictions are dependent only on historical values. The forecasting can be done through various statistical methods. This chapter goes through a few important ones.
Recipe 2-1. Moving Average (MA) Forecast
Recipe 2-2. Autoregressive (AR) Model
Recipe 2-3. Autoregressive Moving Average (ARMA) Model
Recipe 2-4. Autoregressive Integrated Moving Average (ARIMA) Model
Recipe 2-5. Grid search Hyperparameter Tuning for Autoregressive Integrated Moving Average (ARIMA) Model
Recipe 2-6. Seasonal Autoregressive Integrated Moving Average (SARIMA) Model
Recipe 2-7. Simple Exponential Smoothing (SES) Model
Recipe 2-8. Holt-Winters (HW) Model
Recipe 2-1. Moving Average (MA) Forecast
Problem
You want to load time series data and forecast using a moving average.
Solution
A moving average is a method that captures the average change in a metric over time. For a particular window length, which is a short period/range in time, you calculate the mean target value, and then this window is moved across the entire period of the data, from start to end. It is usually used to smoothen the data and remove any random fluctuations.
Let’s use the pandas rolling mean function to get the moving average.
How It Works
The following steps read the data and forecast using the moving average.
Step 1-1. Import the required libraries.
Step 1-2. Read the data.
The US GDP data is a time series dataset that shows the annual gross domestic product (GDP) value (in US dollars) of the United States from 1929 to 1991.
Step 1-3. Preprocess the data.
Step 1-4. Plot the time series.

Step 1-5. Use a rolling mean to get the moving average.
Step 1-6. Plot the forecast vs. the actual.

MA forecast vs. actual
Recipe 2-2. Autoregressive (AR) Model
Problem
You want to load the time series data and forecast using an autoregressive model.
Solution
Autoregressive models use lagged values (i.e., the historical values of a point to forecast future values). The forecast is a linear combination of these lagged values.
Let’s use the AutoReg function from statsmodels.tsa for modeling.
How It Works
The following steps load data and forecast using the AR model.
Step 2-1. Import the required libraries.
Step 2-2. Load and plot the dataset.

Step 2-3. Check for stationarity of the time series data.
Step 2-4. Find the order of the AR model to be trained.

Partial autocorrelation function plot
Figure 2-4 shows the partial autocorrelation function output and the number of lags until there is a significant partial correlation in the order of the AR model. In this case, it is 8.
Step 2-5. Create training and test data.
Step 2-6. Call and fit the AR model.
Step 2-7. Output the model summary.

AR model summary
Step 2-8. Get the predictions from the model.
Step 2-9. Plot the predictions vs. actuals.

Predictions vs. actuals
Recipe 2-3. Autoregressive Moving Average (ARMA) Model
Problem
You want to load time series data and forecast using an autoregressive moving average (ARMA) model.
Solution
An ARMA model uses the concepts of autoregression and moving averages to build a much more robust model. It has two hyperparameters (p and q) that tune the autoregressive and moving average components, respectively.
Let’s use the ARIMA function from statsmodels.tsa for modeling.
How It Works
The following steps load data and forecast using the ARMA model.
Step 3-1. Import the required libraries.
Step 3-2. Load the data.
Step 3-3. Preprocess the data.
Step 3-4. Plot the time series.

Step 3-5. Do a train-test split.
Step 3-6. Plot time the series after the train-test split.

Train-test split output
Step 3-7. Define the actuals from training.
Step 3-8. Initialize and fit the ARMA model.
Step 3-9. Get the test predictions.
Step 3-10. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 3-11. Calculate the RMSE score for the model.
The RMSE (root-mean-square error) is very high, as the dataset is not stationary. You need to make it stationary or use the autoregressive integrated moving average (ARIMA) model to get a better performance.
Recipe 2-4. Autoregressive Integrated Moving Average (ARIMA) Model
Problem
You want to load time series data and forecast using an autoregressive integrated moving average (ARIMA) model.
Solution
An ARIMA model improves upon the ARMA model because it also includes a third parameter, d, which is responsible for differencing the data to get in stationarity for better forecasts.
Let’s use the ARIMA function from statsmodels.tsa for modeling.
How It Works
The following steps load data and forecast using the ARIMA model.
Steps 3-1 to 3-7 from Recipe 2-3 are also used for this recipe.
Step 4-1. Make the data stationary by differencing.
Step 4-2. Check the ADF (Augmented Dickey-Fuller) test for stationarity.
Step 4-3. Get the Auto Correlation Function and Partial Auto Correlation Function values.
Step 4-4. Plot the ACF and PACF to get p- and q-values.
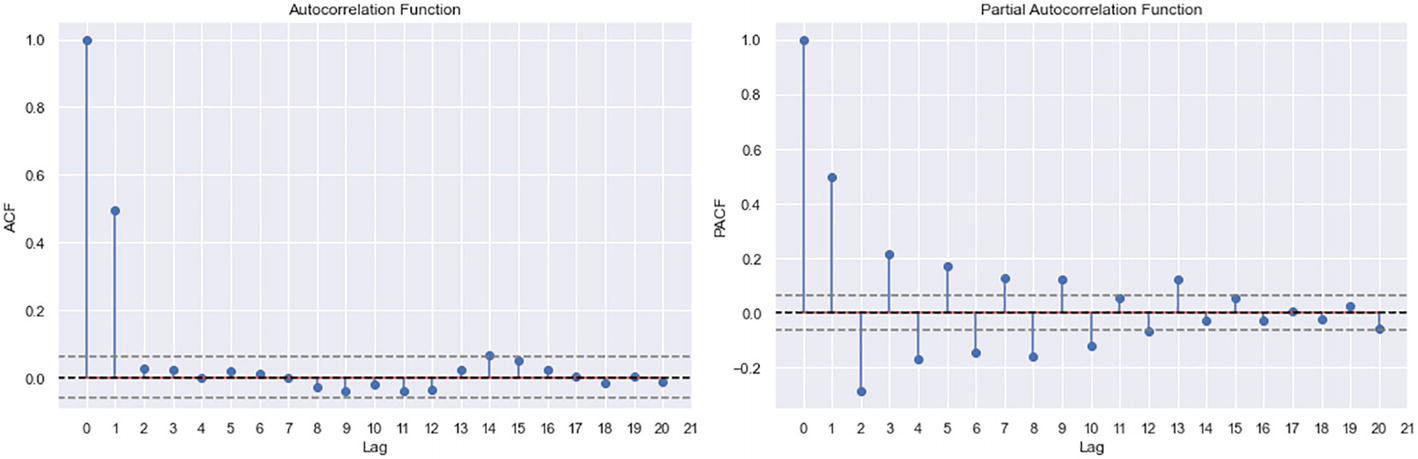
ACF and PACF plots
According to the ACF plot, the cutoff is 1, so the q-value is 1. According to the PACF plot, the cutoff is 10, so the p-value is 10.
Step 4-5. Initialize and fit the ARIMA model.
Step 4-6. Get the test predictions.
Step 4-7. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 4-8. Calculate the RMSE score for the model.
This model has performed better than an ARMA model due to the differencing part and finding the proper p-, d-, and q-values. But still, it has a high RMSE as the model is not perfectly tuned.
Recipe 2-5. Grid Search Hyperparameter Tuning for ARIMA Model
Problem
You want to forecast using an ARIMA model with the best hyperparameters.
Solution
Let’s use a grid search method to tune the model’s hyperparameters. The ARIMA model has three parameters (p, d, and q) that can be tuned using the classical grid search method. Loop through various combinations and evaluate each model to find the best configuration.
How It Works
The following steps load data and tune hyperparameters before forecasting using the ARIMA model.
Steps 3-1 to 3-7 from Recipe 2-3 are also used for this recipe.
Step 5-1. Write a function to evaluate the ARIMA model.
Step 5-2. Write a function to evaluate multiple models through grid search hyperparameter tuning.
Step 5-3. Perform the grid search hyperparameter tuning by calling the defined functions.
Step 5-4. Initialize and fit the ARIMA model with the best configuration.
Step 5-5. Get the test predictions.
Step 5-6. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 5-7. Calculate the RMSE score for the model.
This is the best RMSE so far because the model is tuned and fits well.
Recipe 2-6. Seasonal Autoregressive Integrated Moving Average (SARIMA) Model
Problem
You want to load time series data and forecast using a seasonal autoregressive integrated moving average (SARIMA) model.
Solution
The SARIMA model is an extension of the ARIMA model. It can model the seasonal component of data as well. It uses seasonal p, d, and q components as hyperparameter inputs.
Let’s use the SARIMAX function from statsmodels.tsa for modeling.
How It Works
The following steps load data and forecast using the SARIMA model.
Steps 3-1 to 3-7 from Recipe 2-3 are also used for this recipe.
Step 6-1. Initialize and fit the SARIMA model.
Step 6-2. Get the test predictions.
Step 6-3. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 6-4. Calculate the RMSE score for the model.
You can further tune the seasonal component to get a better RMSE score. Tuning can be done using the same grid search method.
Recipe 2-7. Simple Exponential Smoothing (SES) Model
Problem
You want to load the time series data and forecast using a simple exponential smoothing (SES) model.
Solution
Simple exponential smoothing is a smoothening method (like moving average) that uses an exponential window function.
Let’s use the SimpleExpSmoothing function from statsmodels.tsa for modeling.
How It Works
The following steps load data and forecast using the SES model.
Steps 3-1 to 3-7 from Recipe 2-3 are also used for this recipe.
Step 7-1. Initialize and fit the SES model.
Step 7-2. Get the test predictions.
Step 7-3. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 7-4. Calculate the RMSE score for the model.
As expected, the RMSE is very high because it’s a simple smoothing function that performs best when there is no trend in the data.
Recipe 2-8. Holt-Winters (HW) Model
Problem
You want to load time series data and forecast using the Holt-Winters (HW) model.
Solution
Holt-Winters is also a smoothing function. It uses the exponential weighted moving average. It encodes previous historical values to predict present and future values.
For modeling, let’s use the ExponentialSmoothing function from statsmodels.tsa.holtwinters.
How It Works
The following steps load data and forecast using the HW model.
Steps 3-1 to 3-7 from Recipe 2-3 are also used for this recipe.
Step 8-1. Initialize and fit the HW model.
Step 8-2. Get the test predictions.
Step 8-3. Plot the train, test, and predictions as a line plot.

Predictions vs. actuals output
Step 8-4. Calculate the RMSE score for the model.
The RMSE is a bit high, but for this dataset, the additive model performs better than the multiplicative model. For the multiplicative model, change the trend term to 'mul' in the ExponentialSmoothing function.