
CHAPTER 2
Programming View and UPC Data Types
Parallel programming languages that are available today represent a diversity of programming models. Depending on the physical structure and incorporated mechanisms of the underlying parallel computer, one or more languages may be preferable to others in both ease of programming and/or delivered performance. Similarly, the organization of the data structures and the flow control of the tasks of a given application algorithm may strongly influence the parallel programming language to be employed. UPC is one such parallel programming language that facilitates general-purpose parallel computing through a set of constructs particularly well suited to the major classes of parallel computers and a wide range of parallel applications. In this chapter we present the foundation principles of parallel programming as reflected by some of the most widely used languages and introduce UPC from the perspective of these same basic concepts to position UPC in the domain of parallel programming. Details of the UPC programming model are presented with a discussion of the memory sharing and thread execution view. The remainder of this chapter covers basic declarations, types, associated storage, and constraints in the light of the UPC memory sharing and execution model.
2.1 PROGRAMMING MODELS
A programming model is simply the abstract view of how data and instructions are stored and how processing takes place as perceived by the programmer [HWA98]. In uniprocessor systems, it is fair to say that there is one basic programming model, which is the von Neumann stored program model. Under this model, there is only one memory, and all data and instructions are stored in it. The processor fetches and decodes the program instructions and accesses and processes data accordingly. In a parallel system, the architecture is more complex, due to the multiplicity of processors and possibly, memory subsystems. Parallel programming models therefore also enable the programmer to express how the application should be decomposed (i.e., how data and work will be distributed for parallel execution).
Parallel programming models expose common architecture features to enable efficient mapping of the programs onto the architectures. However, they should be independent of precise details of specific parallel architecutures, to allow mapping of any parallel programming model onto a variety of parallel architectures.
Programming models should, however, remain simple for ease of use.
Popular parallel programming models include message passing, shared memory, data parallel, and the distributed shared memory model. UPC uses the distributed shared memory programming model. In this section we distinguish among these models and give examples of their implementations. Our intent is to position UPC in the world of parallel programming, highlighting powerful features.
In the message-passing model (Figure 2.1a), parallel processing is derived from the use of a set of concurrent sequential processes cooperating on the same task. As each process has its own private space, two-sided communication in the form of sends and receives is used. This results in substantial overhead in interprocessor communications, especially in the case of small messages. With separate spaces, ease of use becomes another concern. As large problems are decomposed for parallel processing, the overall view of the problem is lost and replaced by multiple private ones, placing a bigger burden on the program to maintain such global nature of the application, which may require adding more code. The most popular example of message passing is MPI, the message-passing interface [MPI94, SNI98].

Figure 2.1 Address Space and Execution in Parallel Programming Models
Another popular programming model is the shared memory model (Figure 2.1b). The view provided by this model is one in which multiple independent threads operate in a shared space. The most popular implementations of this model are OpenMP [OPE97] and Pthreads [BUT97]. This model is characterized by its ease of use, as programmers need not treat remote memory accesses differently from local accesses. An expression, for example, can imply a remote memory read if any of its variables is located on a remote computing element or memory bank of the physically distributed system. Similarly, an assignment statement can cause a remote memory write. Since all concurrent threads see a single shared memory space, the application view remains integrated and similar to that of the sequential case. A negative consequence of this is that due to threads being unaware of whether the data they are processing is local or remote, unnecessary remote memory accesses might be generated, resulting in performance degradation. Therefore, under the pure shared memory programming model, it is difficult to exploit the inherent data locality in applications to achieve the highest efficiency.
Another programming model, the data parallel model shown in Figure 2.1c, derives its concurrency from processing many data items simultaneously in the same manner. This model employs only one executing process, for which every operation executed processes multiple data items identically. The major problem with this model is that it does not permit independent branching within the executing process to allow processing different data in different ways. Thus, applications that are richer in functional parallelism than in data parallelism may not be expressed effectively under this model. Examples of languages that followed such a scheme are C* [ROS87] and HPF [HPF97].
The last model that we discuss here is the distributed shared memory (DSM) programming model (Figure 2.1d), also called the partitioned global address space (PGAS) model, which has been adopted by UPC. This model can achieve the desired balance between ease of use and exploiting data locality while avoiding the problem of independent branching in the data parallel model. Under this model, independent threads are operating in a shared space, just as in the shared memory model. However, this shared space is logically partitioned among the threads. This enables mapping to the same physical node of each thread and the data space that is associated with it locally. Programmers can thus declare the data to be processed by a given thread in the space partition that has affinity to that thread. Exploiting locality of access in this manner eliminates or minimizes unnecessary remote accesses from the beginning. Further, the multiple threads of the DSM programming model can all be executing the same program in single program, multiple data stream (SPMD) fashion that relaxes the rigid flow control of the data parallel programming model and thus avoides the independent branching problem. Thus, the DSM model provides a good balance between program abstraction for ease of use and portability, on the one hand, and direct control of resource management for good performance, on the other hand, to achieve efficient execution with contemporary computer architectures.
2.2 UPC PROGRAMMING MODEL
Having defined the space of programming models, UPC can be positioned in this conceptual domain by defining the UPC execution and data sharing environment, which comprises the principal semantic elements of the UPC programming model. Figure 2.2 illustrates the memory and execution model as viewed by UPC codes and programmers. Under UPC, a number of threads work independently, with no implicit synchronization, except that all threads start and finish together. This implies barrier synchronization at the beginning and end of a program. The total number of threads is given by the integer THREADS, and each thread can identify itself using MYTHREAD. Thus, MYTHREAD and THREADS can be thought of as a private constant at each thread and a global constant visible to all threads, respectively. The total number of threads, THREADS, can be specified at either compile time or run time, using the compile or the run command line, respectively.
UPC works in SPMD style, where each thread executes the same main() function. This does not limit the flexibility of the execution model, because conditional flow control within the thread can direct different thread instances to perform different parts of the total thread code based on the MYTHREAD identifier and intermediate result data values.
UPC represents a variant instance of the DSM paradigm with additional private address spaces for local computations. Under UPC, memory is composed of a logically partitioned shared memory space and additional private memory spaces, as shown in Figure 2.2. All distributed threads can reference any address location (shared variables) in the shared data space, but only its own private data space. The shared space, however, is logically divided into portions, each with a special association (affinity) to a given thread. In this way, UPC enables the programmer, with proper declarations, to keep the shared data that will be dominantly processed by a given thread (and occasionally, accessed by others) associated with that thread.
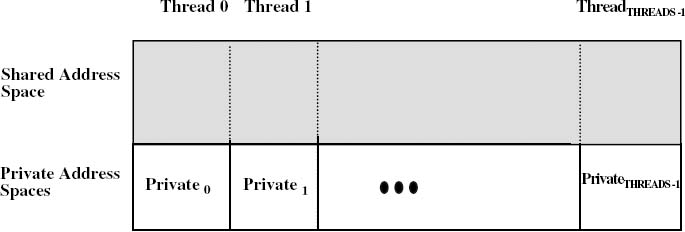
Figure 2.2 UPC Memory and Execution Model
Thus, a thread and the data that has affinity to it can be mapped by the system into the same physical node. This provides programmers with the necessary language constructs to exploit inherent data locality in their applications. Although an implementation may map each UPC thread to a different CPU, the UPC specification does not prohibit mapping more than one thread to the same CPU, permitting the exploitation of multithreading hardware support (such as in Tera MTA [ALV90]) when available.
UPC allows dynamic memory allocation in the shared space. Dynamic allocations in the private space are inherited from ISO C, as UPC is only an extension of ISO C. In addition, UPC has pointers that can access the shared address space. Pointers into the private spaces are also supported by UPC, as it is an ISO C extension. In conjunction with the programming model, UPC provides explicit extensions to the syntax and semantics of ISO C to facilitate expressing parallel applications. Therefore, UPC can be classified as an explicit parallel extension to ISO C that follows the distributed shared memory programming model.
2.3 SHARED AND PRIVATE VARIABLES
As discussed earlier, UPC is an extension of ISO C. Its execution follows an SPMD model in which each thread executes main(). A given thread in UPC appears as a sequential ISO C program. In UPC, an object can be declared as shared or private. A private object would have a separate instance for each thread, equivalent in structure and local identifiers but different in value among the distinct threads. One particular thread, thread 0, is distinguished among all others. It is allocated all scalar shared objects such that their affinity is assigned to thread 0. The following two examples show scalar private and shared declarations.
By default, any ISO C style declaration under UPC results in private objects. For example, the declaration
int x; // x is private, one x in the private space of each thread
creates one private variable x for each thread. Each thread can only reference and manipulate its own instance of x. This is consistent with the fact that UPC is simply an extension of ISO C in which parallel execution follows the SPMD model, with each thread executing main(). This demonstrates how UPC flows logically from ISO C augmented with a number of basic parallel programming constructs. These explicit extensions to the syntax and semantics of C provide the user with the means to specify and control parallel execution from within the parallel application program.
Declaring an object to be shared, however, requires explicit use of the shared qualifier. For example:
shared int y; // y is shared, only one y at thread 0 in the shared
space
creates one instance of the variable y, which can be referenced and manipulated by all threads. The variable y is therefore created in the shared space and has affinity to thread 0, as it is a scalar variable. Scalar shared objects in UPC will always have affinity to thread 0. This is logically consistent with the fact that the first element of a shared array always has affinity to thread 0, as explained in the next section.
Shared variables cannot have automatic storage duration: as, for example, in
void foo(void)
{
shared int x; // not allowed
static shared int y; // allowed
shared int *p; // allowed
int *shared q; // not allowed
…
}
In the previous foo() function, the first declaration,
shared int x;
is not allowed since it has an automatic storage duration, as it appears inside the function. However, static shared variables are allowed, with the example of y.
Although pointers are treated thoroughly in Chapter 3, the third and last declarations involve pointer declarations that bring up useful points to the discussion. In the third declaration,
shared int * p;
is a private pointer to shared, which gives each thread an independent pointer, stored in its private space but pointing into the shared space. Thus, shared in this context qualifies the pointed to variable, and it creates only private pointers to it. This declaration is therefore allowed since the pointers themselves are not shared.
In the last declaration,
int *shared q;
is a shared pointer to private. Thus, shared in this context qualifies the pointer that is to be created in the shared space and therefore is not allowed. It should be noted, however, that although the previous declaration helps explain an important concept, use of shared pointers to private variables is strongly discouraged. In general, shared should not appear in a declerator that has automatic storage duration, except when it results in creating storage in the private space.
One remedy is to move the first and last declarations outside the function foo() body, as follows:
Similarly, no data can be declared as shared inside a private structure except for private pointers to shared. Shared structures, on the other hand, can only contain data that are shared. For example:
struct rectangle {
shared int width;
shared int length;
} myrect;
is illegal, as both width and length are shared-qualified, whereas the structure is not. However,
shared struct rectangle {
int width;
int length;
} myrect;
is allowed since the structure is shared-qualified, as is
struct foo {
shared int *p; // allowed
int *shared q; // not allowed
};
Type conversion among shared and private is possible. It can be accomplished through cast and assignments. In general, private objects cannot be cast to shared objects, and assignment of private to shared objects has undefined results. These type conversions can be quite useful in the case of private and shared pointers and will be addressed further in that context. Shared-qualified objects may also have a reference qualifier to define their behavior from a memory consistency point of view. This is treated in Chapter 6.
2.4 SHARED AND PRIVATE ARRAYS
Shared arrays are created in the shared space. By default, elements of a shared array will be distributed across the threads in round-robin fashion. In other words, the first element is created in the shared space that has affinity to thread 0, the second element in the shared space that has affinity to thread 1, and so on. For simplicity, however, we say that the first element goes to thread 0, the second to thread 1, and so on. The following example declarations demonstrate how a shared vector declaration behaves compared to shared scalar and private scalar declarations.

The declarations
shared int x; /* x is a shared scalar and
will have affinity to thread 0 */
shared int y [THREADS]; /*shared array*/
int z; /*private scalar*/
in the case of four threads will result in the default layout shown in Figure 2.3, where x and y were created in the shared space, and instances of z were created in the private spaces of each thread. Thus, if the declaration
shared int y [THREADS];
was replaced with
int y [THREADS];
each thread would have had its own full four-element private version of the array y.
In the case of higher-dimensional arrays, the elements of a shared array are still distributed in round-robin fashion. Consider, for example, the declaration
shared int A [4][THREADS];
This declaration results in the layout shown in Figure 2.4. Such default distribution can be very useful, as the vector addition program in the next example shows.

Example 2.1: vectadd1.upc
#include <upc_relaxed.h>//upc_relaxed explained in Chapter 6
#define N 10 * THREADS
shared int v1[N], v2[N], v1plusv2[N];
int main ()
{
int i;
upc_forall (i = 0; i < N; i ++; i)
v1plusv2 [i] = v1 [i] + v2 [i];
return 0;
}
In this example, two vectors v1 and v2 are added to produce the vector v1plusv2. By default, v1, v2, and v1plusv2 are distributed across the threads in round-robin fashion. The last field in the upc_forall statement is the affinity field and says that iteration i should be executed on thread i%THREADS. Thus, iterations are also distributed in round-robin fashion across the threads, which will ensure that each thread manipulates only the shared data that are available locally.
2.5 BLOCKED SHARED ARRAYS
In many cases, the default shared array distribution is not appropriate for optimal execution, and an alternative explicit data layout may improve data locality exploitation and execution efficiency. Consider the following matrix-vector multiplication example.
Example 2.2: matvect1.upc
#include <upc_relaxed.h> shared int a [THREADS][THREADS]; shared int b [THREADS], c [THREADS]; int main (void) { int i, j; upc_forall(i = 0; i < THREADS; i++; i) { c [i] = 0; for (j= 0; j <THREADS; j++) c [i] += a [i][j]*b [j]; } return 0; }
The default layout in the shared space in the case of running with three threads is shown in Figure 2.5. A first glance at the layout will show that for computing each c[] element, there will be more remote memory accesses than local accesses. For example, in case of c[0], only a [0][0] and b[0] are local input operands; the remaining four are not. Luckily, this default distribution can be altered to better fit the need of an application and improve locality exploitation in the underlying computations.
The default shared array distribution can be altered by specifying a given block size, also called a blocking factor, in the declaration using a layout qualifier as follows:
shared [block-size]array [number-of-elements]
shared [4] int a [16];
In the previous case, array a [] will have 16 elements distributed across the threads in four-element by four-element blocks in a round-robin fashion. Thus, the block size and total number of threads, THREADS, determine the affinity of each data element to threads as follows: Element i of a blocked array has an affinity to thread:
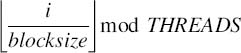
Thus, the declaration
shared [3] int x [12];
has a layout qualifier of 3, which means that array entries will be blocked and distributed across the threads in blocks of three in round-robin fashion. The resulting layout for THREADS = 3 is shown in Figure 2.6. Thus, if the previous declaration were changed to
shared [12] int x [12];
all array elements would have affinity to thread 0. This can also be established using the indefinite block size. Omitting the block size or making it zero in the layout qualifier brackets would result in making all array elements have affinity to thread 0. Using such indefinite block size, the effect of the previous declaration can be established through the declaration
shared [] int x [12];
or
shared [0] int x [12];


In many cases it is desirable to distribute an array of data in contiguous blocks such that, when possible each thread gets one of those chunks. One convenient way to do this is by using the * layout qualifier. For example,
shared [*] int y [8];
would produce the layout shown in Figure 2.7 for the case of three threads.
Layout qualifiers work in the same way with two- and higher-dimensional arrays as in the case of one-dimensional arrays. Consider, for example, the declaration
shared [3] int A [4][4];
In this case, array elements are also blocked by a factor of 3. Therefore, blocks of three elements each are distributed across the threads in round-robin fashion until all the array elements are allocated. The resulting layout in the case of four threads is shown in Figure 2.8.
By employing the foregoing techniques, the matrix-vector multiplication example can now be revisited.

Example 2.3: matvect2.upc
#include <upc_relaxed.h> shared [THREADS] int a[THREADS][THREADS]; shared int b [THREADS], c [THREADS]; int main (void) { int i, j; upc_forall(i = 0; i < THREADS; i++; i) { c [i] = 0; for (j= 0; j (THREADS; j++) c [i] += a [i][j]*b [j]; } return 0; }
The only difference between this version and the version that was shown in Example 2.2 is in the declaration of a[], where a[] is now blocked by a factor equal to the number of THREADS. The resulting layout for the case of three threads is shown in Figure 2.9. In this case, computing c[0] requires only two remote accesses for reading b[1] and b[2] instead of the four remote accesses needed in the case of default distribution.

2.6 COMPILING ENVIRONMENTS AND SHARED ARRAYS
The number of UPC executing threads can be specified at either compile time or run time. If the number of threads is known at compile time, the UPC program is translated in the “static THREADS” environment. If the number of threads is not known at compile time, the UPC program is translated in the “dynamic THREADS” environment.
Specifying the number of threads at compile time gives compilers the opportunity to offer their best optimizations. On the other hand, it may not be very convenient when a program is to be run with different numbers of threads. Specifying the number of threads at run time allows the users to compile once and run multiple times with different numbers of threads. However, this can present technical challenges to compilers, particularly where the number of array elements allocated to each thread depends on the number of executing threads. To contain such challenges, a number of constraints are established. One clear constraint is that an array declaration is considered illegal if the UPC program is translated in the “dynamic THREADS” environment (i.e., THREADS is specified at run time, and the number of elements to allocate at each thread depends on the number of threads). For example, the declarations
shared int x [10*THREADS]; shared [] int x [10];
are legal in both the “static THREADS” and “dynamic THREADS” translation environments. In the first case, 10 elements will be allocated to each thread, and in the second declaration 10 elements will be allocated to thread 0.
On the other hand, the declarations
shared int x [10]; shared [] int x [THREADS]; shared int x [10+THREADS];
are illegal in the case of the “dynamic THREADS” translation environment. In the first declaration, it is unclear how many x[] elements will be given to each thread without knowing the total number of threads. In the second declaration, although the entire array goes to thread 0, the size of that array is unknown without knowing the total number of threads. In the third declaration, it is clear that each thread gets at least one element, but without knowing the total number of threads, the total share of each thread of the array elements will be unknown.
2.7 SUMMARY
UPC is an extension of ISO C that follows the distributed shared memory programming model. All threads can access the entire shared space. However, the shared space is logically partitioned, and each partition has affinity to one of the threads. This enables programmers to co-locate data and processing, thus exploiting data locality for improved performance. Each thread has, in addition, a private memory space, which should be accessed by that thread only. UPC operates in a SPMD model of execution, where all threads execute the main() function. No synchronization is implied except that threads must start and finish the same program at the same time. Programmers determine at declaration time where data will be located with respect to threads and private and shared space. Private variable declarations result in one instance of the variable within the private space of each thread. Shared scalar variables have affinity to thread 0. Shared array elements are distributed by default in round-robin fashion across the threads. Such default can be changed using a block size specified by the programmer, in which case the array elements are distributed by blocks of elements across the threads in round-robin fashion. Thus, the data layout can be defined in a way that reduces the overall number of remote shared memory references. Shared variables and arrays cannot have automatic storage duration.
EXERCISES
2.1 List two unique features in each of the four parallel programming models: message passing, data parallel, shared memory, and distributed shared memory.
2.2 Two popular computer architectures are the multicomputer architecture, in which each node has a local memory with a private address space, and the NUMA (nonuniform memory access architecture), in which there is one global address space but each node holds a part of that shared system memory. Discuss the performance pros and cons of implementing each of the four programming models on each of these two architectures.
2.3 In addition to the shared address space of the distributed shared memory programming model, the UPC memory model includes thread-private memories. Give two reasons why including such private memories would be a good idea.
2.4 Why does it make sense not to have dynamic shared variables? It was also stated that shared pointers to private variables were not recommended. Why?
2.5 Write a program to perform A = B * C, where A, B, and C are n × n matrices and n is a multiple of THREADS.
2.6 Repeat Exercise 2.5, but block the A matrix by rows. Derive an expression for the number of remote accesses needed for computing each C element and compare the results with those of Exercise 2.5.
UPC: Distributed Shared Memory Programming, by Tarek El-Ghazawi, William Carlson, Thomas Sterling, and Katherine Yelick
Copyright © 2005 John Wiley & Sons, Inc.