
The whole idea behind the buffer cache is to relieve processes from having to wait for relatively slow disks to retrieve or store data. Thus, it would be counterproductive to write a lot of data at once; instead, data should be written piecemeal at regular intervals so that I/O operations have a minimal impact on the speed of the user processes and on response time experienced by human users.
The kernel maintains a lot of information about each buffer to help it pace the writes, including a “dirty” bit to indicate the buffer has been changed in memory and needs to be written, and a timestamp to indicate how long the buffer should be kept in memory before being flushed to disk. Information on buffers is kept in buffer heads (introduced in the previous chapter), so these data structures require maintenance along with the buffers of user data themselves.
The size of the buffer cache may vary. Page frames are allocated on demand when a new buffer is required and one is not available. When free memory becomes scarce, as we shall see in Chapter 16, buffers are released and the corresponding page frames are recycled.
The buffer cache consists of two kinds of data structures:
A set of buffer heads describing the buffers in the cache
A hash table to help the kernel quickly derive the buffer head that describes the buffer associated with a given pair of device and block numbers
As mentioned in Section 13.4.4, each buffer head is stored in a data
structure of type buffer_head. These data
structures have their own slab allocator cache called
bh_cachep, which should not be confused with the
buffer cache itself. The slab allocator cache is a memory cache (see
Section 3.2.2) for the buffer head
objects, meaning that it has no interaction with disks and is simply
a way of managing memory efficiently. In contrast, the buffer cache
is a disk cache for the data in the buffers.
Each buffer used by a block device driver must have a corresponding buffer head that describes the buffer’s current status. The converse is not true: a buffer head may be unused, which means it is not bound to any buffer. The kernel keeps a certain number of unused buffer heads to avoid the overhead of constantly allocating and deallocating memory.
In general, a buffer head may be in any one of the following states:
- Unused buffer head
The object is available; the values of its fields are meaningless, except for the
b_devfield that stores the valueB_FREE(0xffff).- Buffer head for a cached buffer
Its
b_datafield points to a buffer stored in the buffer cache. Theb_devfield identifies a block device, and theBH_Mappedflag is set. Moreover, the buffer could be one of the following:- Not up-to-date (
BH_Uptodateflag is clear) The data in the buffer is not valid (for instance, the data has yet to be read from disk).
- Dirty (
BH_Dirtyflag set) The data in the buffer has been modified, and the corresponding block on disk needs to be updated.
- Locked (
BH_Lockflag set) An I/O data transfer on the buffer contents is in progress.
- Not up-to-date (
- Asynchronous buffer head
Its
b_datafield points to a buffer inside a page that is involved in a page I/O operation (see Section 13.4.8.2); in this case, theBH_Asyncflag is set. As soon as the page I/O operation terminates, theBH_Asyncflag is cleared, but the buffer head is not freed; rather, it remains allocated and inserted into a simply linked circular list of the page (see the later section Section 14.2.2). Thus, it can be reused without the overhead of always allocating new ones. Asynchronous buffer heads are released whenever the kernel tries to reclaim some memory (see Chapter 16).
Strictly speaking, the buffer cache data structures include only pointers to buffer heads for a cached buffer. For the sake of completeness, we shall examine the data structures and the methods used by the kernel to handle all kinds of buffer heads, not just those in the buffer cache.
All unused buffer heads are collected in a simply linked list, whose
first element is addressed by the unused_list
variable. Each buffer head stores the address of the next list
element in the b_next_free field. The current
number of elements in the list is stored in the
nr_unused_buffer_heads variable. The
unused_list_lock spin lock protects the list
against concurrent accesses in multiprocessor systems.
The list of unused buffer heads acts as a primary memory cache for
the buffer head objects, while the bh_cachep slab
allocator cache is a secondary memory cache. When a buffer head is no
longer needed, it is inserted into the list of unused buffer heads.
Buffer heads are released to the slab allocator (a preliminary step
to letting the kernel free the memory associated with them
altogether) only when the number of list elements exceeds
MAX_UNUSED_BUFFERS (usually 100 elements). In
other words, a buffer head in this list is considered an allocated
object by the slab allocator and an unused data structure by the
buffer cache.
A subset of NR_RESERVED (usually 80) elements in
the list is reserved for page I/O operations. This is done to prevent
nasty deadlocks caused by the lack of free buffer heads. As we shall
see in Chapter 16, if free memory is scarce, the
kernel can try to free a page frame by swapping out some page to
disk. To do this, it requires at least one additional buffer head to
perform the page I/O file operation. If the swapping algorithm fails
to get a buffer head, it simply keeps waiting and lets writes to
files proceed to free up buffers, since at least
NR_RESERVED buffer heads are going to be released
as soon as the ongoing file operations terminate.
The get_unused_buffer_head( ) function is invoked
to get a new buffer head. It essentially performs the following
operations:
Acquires the
unused_list_lockspin lock.If the list of unused buffer heads has more than
NR_RESERVEDelements, removes one of them from the list, releases the spin lock, and returns the address of the buffer head.Otherwise, releases the spin lock and invokes
kmem_cache_alloc( )to allocate a new buffer head from thebh_cachepslab allocator cache with priorityGFP_NOFS(see Section 7.1.5); if the operation succeeds, returns its address.No free memory is available. If the buffer head has been requested for a block I/O operation, returns
NULL(failure).If this point is reached, the buffer head has been requested for a page I/O operation. If the list of unused buffer heads is not empty, acquires the
unused_list_lockspin lock, removes one element from the list, releases the spin lock, and returns the address of the buffer head.Otherwise (if the list is empty), returns
NULL(failure).
The put_unused_buffer_head( ) function performs
the reverse operation, releasing a buffer head. It inserts the object
in the list of unused buffer heads if that list has fewer than
MAX_UNUSED_BUFFERS elements; otherwise, it
releases the object to the slab allocator by invoking
kmem_cache_free( ) on the buffer head.
When a buffer belongs to the buffer cache, the flags of the
corresponding buffer head describe its current status (see
Section 13.4.4). For instance, when a block not
present in the cache must be read from disk, a new buffer is
allocated and the BH_Uptodate flag of the buffer
head is cleared because the buffer’s contents are
meaningless. While filling the buffer by reading from disk, the
BH_Lock flag is set to protect the buffer from
being reclaimed. If the read operation terminates successfully, the
BH_Uptodate flag is set and the
BH_Lock flag is cleared. If the block must be
written to disk, the buffer content is modified and the
BH_Dirty flag is set; the flag is cleared only
after the buffer is successfully written to disk.
Any buffer head associated with a used buffer is contained in a
doubly linked list, implemented by means of the
b_next_free and b_prev_free
fields. There are three different lists, identified by an index
defined as a macro (BUF_CLEAN,
BUF_LOCKED, and BUF_DIRTY).
We’ll define these lists in a moment.
The three lists are introduced to speed up the functions that flush dirty buffers to disk (see Section 14.2.4 later in this chapter). For reasons of efficiency, a buffer head is not moved right away from one list to another when it changes status; this makes the following description a bit murky.
-
BUF_CLEAN This list collects buffer heads of nondirty buffers (
BH_Dirtyflag is off). Notice that buffers in this list are not necessarily up to date — that is, they don’t necessarily contain valid data. If the buffer is not up to date, it could even be locked (BH_Lockis on) and selected to be read from the physical device while being on this list. The buffer heads in this list are guaranteed only to be not dirty; in other words, the corresponding buffers are ignored by the functions that flush dirty buffers to disk.-
BUF_DIRTY This list mainly collects buffer heads of dirty buffers that have not been selected to be written into the physical device — that is, dirty buffers that have not yet been included in a block request for a block device driver (
BH_Dirtyis on andBH_Lockis off). However, this list could also include nondirty buffers, since in a few cases, theBH_Dirtyflag of a dirty buffer is cleared without flushing it to disk and without removing the buffer head from the list (for instance, whenever a floppy disk is removed from its drive without unmounting—an event that most likely leads to data loss, of course).-
BUF_LOCKED This list mainly collects buffer heads of buffers that have been selected to be read from or written to the block device (
BH_Lockis on;BH_Dirtyis clear because theadd_request( )function resets it before including the buffer head in a block request). However, when a block I/O operation for a locked buffer is completed, the low-level block device handler clears theBH_Lockflag without removing the buffer head from the list (see Section 13.4.7). The buffer heads in this list are guaranteed only to be not dirty, or dirty but selected to be written.
For any buffer head associated with a used buffer, the
b_list field of the buffer head stores the index
of the list containing the buffer. The lru_list
array[99] stores the address of the first element
in each list, the nr_buffers_type array stores the
number of elements in each list, and the
size_buffers_type array stores the total capacity
of the buffers in each list (in byte). The
lru_list_lock spin lock protects these arrays from
concurrent accesses in multiprocessor systems.
The mark_buffer_dirty( ) and
mark_buffer_clean( ) functions set and clear,
respectively, the BH_Dirty flag of a buffer head.
To keep the number of dirty buffers in the system bounded,
mark_buffer_dirty( ) invokes the
balance_dirty( ) function (see the later section
Section 14.2.4). Both functions also
invoke the refile_buffer( ) function, which moves
the buffer head into the proper list according to the value of the
BH_Dirty and BH_Lock flags.
Beside the BUF_DIRTY list, the kernel manages two
doubly linked lists of dirty buffers for every inode object. They are
used whenever the kernel must flush all dirty buffers of a given file
— for instance, when servicing the fsync( )
or fdatasync( ) service calls (see
Section 14.2.4.3 later in this
chapter).
The first of the two lists includes buffers containing the
file’s control data (like the disk inode itself),
while the other list includes buffers containing the
file’s data. The heads of these lists are stored in
the i_dirty_buffers and
i_dirty_data_buffers fields of the inode object,
respectively. The b_inode_buffers field of any
buffer head stores the pointers to the next and previous elements of
these lists. Both of them are protected by the
lru_list_lock spin lock just mentioned. The
buffer_insert_inode_queue( ) and
buffer_insert_inode_data_queue( ) functions are
used, respectively, to insert a buffer head in the
i_dirty_buffers and
i_dirty_data_buffers lists. The
remove_inode_queue( ) function removes a buffer
head from the list that includes it.
The addresses of the buffer heads belonging to the buffer cache are inserted into a hash table. Given a device identifier and a block number, the kernel can use the hash table to quickly derive the address of the corresponding buffer head, if one exists. The hash table noticeably improves kernel performance because checks on buffer heads are frequent. Before starting a block I/O operation, the kernel must check whether the required block is already in the buffer cache; in this situation, the hash table lets the kernel avoid a lengthy sequential scan of the lists of cached buffers.
The hash table is stored in the hash_table array,
which is allocated during system initialization and whose size
depends on the amount of RAM installed on the system. For example,
for systems having 128 MB of RAM, hash_table is
stored in 4 page frames and includes 4,096 buffer head pointers. As
usual, entries that cause a collision are chained in doubly linked
lists implemented by means of the b_next and
b_pprev fields of each buffer head. The
hash_table_lock read/write spin lock protects the
hash table data structures from concurrent accesses in multiprocessor
systems.
The get_hash_table( ) function retrieves a buffer
head from the hash table. The buffer head to be located is identified
by three parameters: the device number, the block number, and the
size of the corresponding data block. The function hashes the values
of the device number and the block number, and looks into the hash
table to find the first element in the collision list; then it checks
the b_dev, b_blocknr, and
b_size fields of each element in the list and
returns the address of the requested buffer head. If the buffer head
is not in the cache, the function returns NULL.
The b_count field of the buffer head is a usage
counter for the corresponding buffer. The counter is incremented
right before each operation on the buffer and decremented right
after. It acts mainly as a safety lock, since the kernel never
destroys a buffer (or its contents) as long as it has a non-null
usage counter. Instead, the cached buffers are examined either
periodically or when the free memory becomes scarce, and only those
buffers that have null counters may be destroyed (see Chapter 16). In other words, a buffer with a null usage
counter may belong to the buffer cache, but it cannot be determined
how long the buffer will stay in the cache.
When a kernel control path wishes to access a buffer, it should
increment the usage counter first. This task is performed by the
getblk( ) function, which is usually invoked to
locate the buffer, so that the increment need not be done explicitly
by higher-level functions. When a kernel control path stops accessing
a buffer, it may invoke either brelse( ) or
bforget( ) to decrement the corresponding usage
counter.The difference between these two functions is that
bforget( ) also marks the buffer as clean, thus
forcing the kernel to forget any change in the buffer that has yet to
be written on disk.
Although the page cache and the buffer cache are different disk caches, in Version 2.4 of Linux, they are somewhat intertwined.
In fact, for reasons of efficiency, buffers are not allocated as single memory objects; instead, buffers are stored in dedicated pages called buffer pages. All the buffers within a single buffer page must have the same size; hence, on the 80 × 86 architecture, a buffer page can include from one to eight buffers, depending on the block size.
A stronger constraint, however, is that all the buffers in a buffer page must refer to adjacent blocks of the underlying block device. For instance, suppose that the kernel wants to read a 1,024-byte inode block of a regular file. Instead of allocating a single 1,024-byte buffer for the inode, the kernel must reserve a whole page storing four buffers; these buffers will contain the data of a group of four adjacent blocks on the block device, including the requested inode block.
It is easy to understand that a buffer page can be regarded in two different ways. On one hand, it is the “container” for some buffers, which can be individually addressed by means of the buffer cache. On the other hand, each buffer page contains a 4,096-byte portion of a block device file, hence, it can be included in the page cache. In other words, the portion of RAM cached by the buffer cache is always a subset of the portion of RAM cached by the page cache. The benefit of this mechanism consists of dramatically reducing the synchronization problems between the buffer cache and the page cache.
In the 2.2 version of the kernel, the two disk caches were not intertwined. A given physical block could have two images in RAM: one in the page cache and the other in the buffer cache. To avoid data loss, whenever one of the two block’s memory images is modified, the 2.2 kernel must also find and update the other memory image. As you might imagine, this is a costly operation.
By way of contrast, in Linux 2.4, modifying a buffer implies
modifying the page that contains it, and vice versa. The kernel must
only pay attention to the “dirty”
flags of both the buffer heads and the page descriptors. For
instance, whenever a buffer head is marked as
“dirty,” the kernel must also set
the PG_dirty flag of the page that contains the
corresponding buffer.
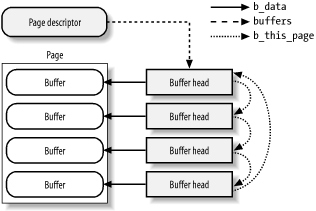
Buffer heads and page descriptors include a few fields that define
the link between a buffer page and the corresponding buffers. If a
page acts as a buffer page, the buffers field of
its page descriptor points to the buffer head of the first buffer
included in the page; otherwise the buffers field
is NULL. In turn, the
b_this_page field of each buffer head implements a
simply linked circular list that includes all buffer heads of the
buffers stored in the buffer page. Moreover, the
b_page field of each buffer head points to the
page descriptor of the corresponding buffer page. Figure 14-1 shows a buffer page containing four buffers
and the corresponding buffer heads.
There is a special case: if a page has been involved in a page I/O
operation (see Section 13.4.8.2), the kernel
might have allocated some asynchronous buffer heads and linked them
to the page by means of the buffers and
b_this_page fields. Thus, a page could act as a
buffer page under some circumstances, even though the corresponding
buffer heads are not in the buffer cache.
The kernel allocates a new buffer page when it discovers that the
buffer cache does not include data for a given block. In this case,
the kernel invokes the grow_buffers( ) function,
passing to it three parameters that identify the block:
The block device number — the major and minor numbers of the device
The logical block number — the position of the block inside the block device
The block size
The function essentially performs the following actions:
Computes the offset
indexof the page of data within the block device that includes the requested block.Gets the address
bdevof the block device descriptor (see Section 13.4.1).Invokes
grow_dev_page( )to create a new buffer page, if necessary. In turn, this function performs the following substeps:Invokes
find_or_create_page( ), passing to it theaddress_spaceobject of the block device (bdev->bd_inode->i_mapping) and the page offsetindex. As described in the earlier section Section 14.1.3,find_or_create_page( )looks for the page in the page cache and, if necessary, inserts a new page in the cache.Now the page cache is known to include a descriptor for our page. The function checks its
buffersfield; if it isNULL, the page has not yet been filled with buffers and the function jumps to Step 3e.Checks whether the size of the buffers on the page is equal to the size of the requested block; if so, returns the address of the page descriptor (the page found in the page cache is a valid buffer page).
Otherwise, checks whether the buffers found in the page can be released by invoking
try_to_free_buffers( ).[100] If the function fails, presumably because some process is using the buffers,grow_dev_page( )returnsNULL(it was not able to allocate the buffer page for the requested block).Invokes the
create_buffers( )function to allocate the buffer heads for the blocks of the requested size within the page. The address of the buffer head for the first buffer in the page is stored in thebuffersfield of the page descriptor, and all buffer heads are inserted into the simply linked circular list implemented by theb_this_pagefields of the buffer heads. Moreover, theb_pagefields of the buffer heads are initialized with the address of the page descriptor.Returns the page descriptor address.
If
grow_dev_page( )returnedNULL, returns 0 (failure).Invokes the
hash_page_buffers( )function to initialize the fields of all buffer heads in the simply linked circular list of the buffer page and insert them into the buffer cache.Unlocks the page (the page was locked by
find_or_create_page( ))Decrements the page’s usage counter (again, the counter was incremented by
find_or_create_page( ))Increments the
buffermem_pagesvariable, which stores the total number of buffer pages — that is, the memory currently cached by the buffer cache in page-size units.
The getblk( )
function is the main service routine for the buffer cache. When the
kernel needs to read or write the contents of a block of a physical
device, it must check whether the buffer head for the required buffer
is already included in the buffer cache. If the buffer is not there,
the kernel must create a new entry in the cache. To do this, the
kernel invokes getblk( ), specifying as parameters
the device identifier, the block number, and the block size. This
function returns the address of the buffer head associated with the
buffer.
Remember that having a buffer head in the cache does not imply that
the data in the buffer is valid. (For instance, the buffer has yet to
be read from disk.) Any function that reads blocks must check whether
the buffer obtained from getblk( ) is up to date;
if not, it must read the block first from disk before using the
buffer.
The getblk( ) function looks deceptively simple:
struct buffer_head * getblk(kdev_t dev, int block, int size)
{
for (;;) {
struct buffer_head * bh;
bh = get_hash_table(dev, block, size);
if (bh)
return bh;
if (!grow_buffers(dev, block, size))
free_more_memory( );
}
}The function first invokes
get_hash_table( ) (see the earlier section Section 14.2.1.3) to check whether the
required buffer head is already in the cache. If so, getblk( ) returns the buffer head address.
Otherwise, if the required buffer head is not in the cache,
getblk( ) invokes grow_buffers( ) to allocate a new buffer page that contains the buffer
for the requested block. If grow_buffers( ) fails
in allocating such a page, getblk( ) tries to
reclaim some memory (see Chapter 16). These actions
are repeated until get_hash_table( ) succeeds in
finding the requested buffer in the buffer cache.
Unix systems allow the deferred writes of dirty buffers into block devices, since this noticeably improves system performance. Several write operations on a buffer could be satisfied by just one slow physical update of the corresponding disk block. Moreover, write operations are less critical than read operations, since a process is usually not suspended because of delayed writings, while it is most often suspended because of delayed reads. Thanks to deferred writes, each physical block device will service, on the average, many more read requests than write ones.
A dirty buffer might stay in main memory until the last possible moment — that is, until system shutdown. However, pushing the delayed-write strategy to its limits has two major drawbacks:
If a hardware or power supply failure occurs, the contents of RAM can no longer be retrieved, so many file updates that were made since the system was booted are lost.
The size of the buffer cache, and hence of the RAM required to contain it, would have to be huge—at least as big as the size of the accessed block devices.
Therefore, dirty buffers are flushed (written) to disk under the following conditions:
The buffer cache gets too full and more buffers are needed, or the number of dirty buffers becomes too large; when one of these conditions occurs, the bdflush kernel thread is activated.
Too much time has elapsed since a buffer has stayed dirty; the kupdate kernel thread regularly flushes old buffers.
A process requests all the buffers of block devices or of particular files to be flushed; it does this by invoking the
sync( ),fsync( ), orfdatasync( )system call.
As explained in the earlier section Section 14.2.2, a buffer page is dirty
(PG_DIRTY flag set) if some of its buffers are
dirty. As soon as the kernel flushes all dirty buffers in a buffer
page to disk, it resets the PG_DIRTY flag of the
page.
The bdflush
kernel thread (also called
kflushd ) is created during system
initialization. It executes the bdflush( )
function, which selects some dirty buffers and forces an update of
the corresponding blocks on the physical block devices.
Some system parameters control the behavior of
bdflush; they are stored in the
b_un field of the bdf_prm table
and are accessible either by means of the
/proc/sys/vm/bdflush file or by invoking the
bdflush( ) system call. Each parameter has a
default standard value, although it may vary within a minimum and a
maximum value stored in the bdflush_min and
bdflush_max tables, respectively. The parameters
are listed in Table 14-4.[101]
Table 14-4. Buffer cache tuning parameters
|
Parameter |
Default |
Min |
Max |
Description |
|---|---|---|---|---|
|
|
40 |
0 |
100 |
Threshold percentage of dirty buffers for waking up bdflush |
|
|
60 |
0 |
100 |
Threshold percentage of dirty buffers for waking up bdflush in blocking mode |
|
|
3000 |
100 |
600,000 |
Time-out in ticks of a dirty buffer for being written to disk |
|
|
500 |
0 |
1,000,000 |
Delay in ticks between kupdate activations |
The most typical cases that cause the kernel thread to be woken up are:
The
balance_dirty( )function verifies that the number of buffer pages in theBUF_DIRTYandBUF_LOCKEDlists exceeds the threshold:P × bdf_prm.b_un.nfract_sync / 100
where P represents the number of pages in the system that can be used as buffer pages (essentially, this is all the pages in the “DMA” and “Normal” memory zones; see Section 7.1.2). Actually, the computation is done by the
balance_dirty_state( )helper function, which returns -1 if the number of dirty or locked buffers is below thenfractthreshold, 0 if it is betweennfractandnfract_sync, and 1 if it is abovenfract_sync. Thebalance_dirty( )function is usually invoked whenever a buffer is marked as “dirty” and the function moves its buffer head into theBUF_DIRTYlist.When the
try_to_free_buffers( )function fails to release the buffer heads of some buffer page (see the earlier section Section 14.2.2.1).When the
grow_buffers( )function fails to allocate a new buffer page, or thecreate_buffers( )function fails to allocate a new buffer head (see the earlier section Section 14.2.2.1).When a user presses some specific combinations of keys on the console (usually
ALT+SysRq+UandALT+SysRq+S). These key combinations, which are enabled only if the Linux kernel has been compiled with the Magic SysRq Key option, allow Linux hackers to have some explicit control over kernel behavior.
To wake up bdflush, the kernel invokes the
wakeup_bdflush( ) function, which simply executes:
wake_up_interruptible(&bdflush_wait);
to wake up the process suspended in the
bdflush_wait task queue. There is just one process
in this wait queue, namely bdflush itself.
The core of the bdflush( ) function is the
following endless loop:
for (;;) {
if (emergency_sync_scheduled) /* Only if the kernel has been compiled */
do_emergency_sync( ); /* with Magic SysRq Key support */
spin_lock(&lru_list_lock);
if (!write_some_buffers(0) || balance_dirty_state( ) < 0) {
wait_for_some_buffers(0);
interruptible_sleep_on(&bdflush_wait);
}
}If the Linux kernel has been compiled with the Magic SysRq Key
option, bdflush( ) checks whether the user has
requested an emergency sync. If so, the function invokes
do_emergency_sync( ) to execute
fsync_dev( ) on all existing block devices,
flushing all dirty buffers (see the later section Section 14.2.4.3).
Next, the function acquires the lru_list_lock spin
lock, and invokes the write_some_buffers( )
function, which tries to activate block I/O write operations for up
to 32 unlocked dirty buffers. Once the write operations have been
activated, write_some_buffers( ) releases the
lru_list_lock spin lock and returns 0 if less than
32 unlocked dirty buffers have been found; it returns a negative
value otherwise.
If write_some_buffers( ) didn’t
find 32 buffers to flush, or the number of dirty or locked buffers
falls below the percentage threshold given by the
bdflush’s parameter
nfract, the bdflush kernel
thread goes to sleep. To do this, it first invokes the
wait_for_some_buffers( ) function so that it
sleeps until all I/O data transfers of the buffers in the
BUF_LOCKED list terminate. During this time
interval, the kernel thread is not woken up even if the kernel
executes the wakeup_bdflush( ) function. Once data
transfers terminate, the bdflush( ) function
invokes interruptible_sleep_on( ) on the
bdflush_wait wait queue to sleep until the next
wakeup_bdflush( ) invocation.
Since the bdflush kernel thread is usually activated only when there are too many dirty buffers or when more buffers are needed and available memory is scarce, some dirty buffers might stay in RAM for an arbitrarily long time before being flushed to disk. The kupdate kernel thread is thus introduced to flush the older dirty buffers.[102]
As shown in Table 14-4,
age_buffer is a time-out parameter that specifies
the time for buffers to age before kupdate
writes them to disk (usually 30 seconds), while the
interval field of the bdf_prm
table stores the delay in ticks between two activations of the
kupdate kernel thread (usually five seconds). If
this field is null, the kernel thread is normally stopped, and is
activated only when it receives a SIGCONT signal.
When the kernel modifies the contents of some buffer, it sets the
b_flushtime field of the corresponding buffer head
to the time (in jiffies) when it should later be flushed to disk. The
kupdate kernel thread selects only the dirty
buffers whose b_flushtime field is smaller than
the current value of jiffies.
The kupdate kernel thread runs the
kupdate( ) function; it keeps executing the
following endless loop:
for (;;) {
wait_for_some_buffers(0);
if (bdf_prm.b_un.interval) {
tsk->state = TASK_INTERRUPTIBLE;
schedule_timeout(bdf_prm.b_un.interval);
} else {
tsk->state = TASK_STOPPED;
schedule( ); /* wait for SIGCONT */
}
sync_old_buffers( );
}First of all, the kernel thread suspends itself until the I/O data
transfers have been completed for all buffers in the
BUF_LOCKED list. Then, if
bdf.prm.b_un.interval interval is not null, the
thread goes to sleep for the specified amount of ticks (see
Section 6.6.2); otherwise, the thread stops
itself until a SIGCONT signal is received (see
Section 10.1).
The core of the kupdate( ) function consists of
the sync_old_buffers( ) function. The operations
to be performed are very simple for standard filesystems used with
Unix; all the function has to do is write dirty buffers to disk.
However, some nonnative filesystems introduce complexities because
they store their superblock or inode information in complicated ways.
sync_old_buffers( ) executes the following steps:
Acquires the big kernel lock.
Invokes
sync_unlocked_inodes( ), which scans the superblocks of all currently mounted filesystems and, for each superblock, the list of dirty inodes to which thes_dirtyfield of the superblock object points. For each inode, the function flushes the dirty pages that belong to memory mappings of the corresponding file (see Section 15.2.5), then invokes thewrite_inodesuperblock operation if it is defined. (Thewrite_inodemethod is defined only by non-Unix filesystems that do not store all the inode data inside a single disk block — for instance, the MS-DOS filesystem).Invokes
sync_supers( ), which takes care of superblocks used by filesystems that do not store all the superblock data in a single disk block (an example is Apple Macintosh’s HFS). The function accesses the superblocks list of all currently mounted filesystems (see Section 12.4). It then invokes, for each superblock, the correspondingwrite_supersuperblock operation, if one is defined (see Section 12.2.1). Thewrite_supermethod is not defined for any Unix filesystem.Releases the big kernel lock.
Starts a loop consisting of the following steps:
Gets the
lru_list_lockspin lock.Gets the
bhpointer to the first buffer head in theBUF_DIRTYlist.If the pointer is null or if the
b_flushtimebuffer head field has a value greater thanjiffies(young buffer), releases thelru_list_lockspin lock and terminates.Invokes
write_some_buffers( ), which tries to activate block I/O write operations for up to 32 unlocked dirty buffers in theBUF_DIRTYlist. Once the write activations have been performed,write_some_buffers( )releases thelru_list_lockspin lock and returns 0 if less than 32 unlocked dirty buffers have been found; it returns a negative value otherwise.If
write_some_buffers( )flushed to disk exactly 32 unlocked dirty buffers, jumps to Step 5a; otherwise, terminates the execution.
Three different system calls are available to user applications to flush dirty buffers to disk:
-
sync( ) Usually issued before a shutdown, since it flushes all dirty buffers to disk
-
fsync( ) Allows a process to flush all blocks that belong to a specific open file to disk
-
fdatasync( ) Very similar to
fsync( ), but doesn’t flush the inode block of the file
The core of the sync( ) system call is the
fsync_dev( ) function, which performs the
following actions:
Invokes
sync_buffers( ), which essentially executes the following code:do { spin_lock(&lru_list_lock); } while (write_some_buffers(0)); run_task_queue(&tq_disk);As you see, the function keeps invoking the
write_some_buffers( )function until it succeeds in finding 32 unlocked, dirty buffers. Then, the block device drivers are unplugged to start real I/O data transfers (see Section 13.4.6.2).Acquires the big kernel lock.
Invokes
sync_inodes( ), which is quite similar to thesync_unlocked_inodes( )function discussed in the previous section.Invokes
sync_supers( )to write the dirty superblocks to disk, if necessary, by using thewrite_supermethods (see earlier in this section).Releases the big kernel lock.
Invokes
sync_buffers( )once again. This time, it waits until all locked buffers have been transferred.
The fsync( ) system call forces the kernel to
write to disk all dirty buffers that belong to the file specified by
the fd file descriptor parameter (including the
buffer containing its inode, if necessary). The system service
routine derives the address of the file object and then invokes the
fsync method. Usually, this method simply invokes
the fsync_inode_buffers( ) function, which scans
the two lists of dirty buffers of the inode object (see the earlier
section Section 14.2.1.3), and invokes
ll_rw_block( ) on each element present in the
lists. The function then suspends the calling process until all dirty
buffers of the file have been written to disk by invoking
wait_on_buffer( ) on each locked buffer. Moreover,
the service routine of the fsync( ) system call
flushes the dirty pages that belong to the memory mapping of the
file, if any (see Section 15.2.5).
The fdatasync( ) system call is very similar to
fsync( ), but writes to disk only the buffers that
contain the file’s data, not those that contain
inode information. Since Linux 2.4 does not have a specific file
method for fdatasync( ), this system call uses the
fsync method and is thus identical to
fsync( ).
[99] The name of the array derives from the abbreviation for Least Recently Used. In earlier versions of Linux, these lists were ordered according to the time each buffer was last accessed.
[100] This can happen when the page was previously involved in a page I/O operation using a different block size, and the corresponding asynchronous buffer heads are still allocated.
[101] The
bdf_prm table also includes several other unused
fields.
[102] In an earlier version
of Linux 2.2, the same task was achieved by means of the
bdflush( ) system call, which was invoked every
five seconds by a User Mode system process launched at system startup
and which executed the /sbin/update
program. In more recent kernel versions, the
bdflush( )system call is used only to allow users
to modify the system parameters in the bdf_prm
table.