
IN THIS CHAPTER
When you log on to the system, you're effectively given your own copy of the shell program. This shell maintains what's known as your environment—an environment that is distinct from other users on the system. This environment is maintained from the moment you log on until the moment you log off. In this chapter you'll learn about this environment in detail, and you'll see how it relates to writing and running programs.
Type the following program called vartest into your computer:
$ cat vartest
echo :$x:
$
vartest consists of a solitary echo command that displays the value of the variable x, surrounded by colons. Now assign any value you want to the variable x from your terminal:
$ x=100
Here we chose 100. Question: What do you think will be displayed when vartest is now executed? Answer:
$ vartest
::
$
vartest doesn't know about the value of x. Therefore, its value is null. The variable x that was assigned the value 100 in the login shell is known as a local variable. The reason why it has this name will become clear shortly.
Here's another example. This program is called vartest2:
$ cat vartest2 x=50 echo :$x: $ x=100 $ vartest2 Execute it :50: $
Now the question is: What's the value of x?
$ echo $x
100
$
So you see that vartest2 didn't change the value of x that you set equal to 100 in your login shell.
The behavior exhibited by vartest and vartest2 is due to the fact that these two programs are run as subshells by your login shell. A subshell is, for all intents and purposes, an entirely new shell executed by your login shell to run the desired program. So when you ask your login shell to execute vartest, it starts up a new shell to execute the program. Whenever a new shell runs, it runs in its own environment, with its own set of local variables. A subshell has no knowledge of local variables that were assigned values by the login shell (the “parent” shell). Furthermore, a subshell cannot change the value of a variable in the parent shell, as evidenced by vartest2.
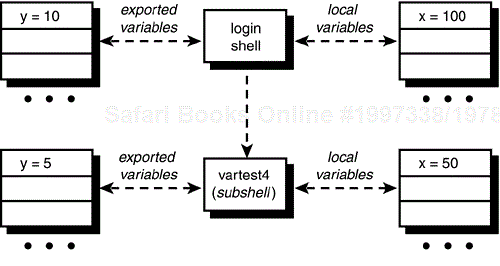
Let's review the process that goes on here. Before executing vartest2, your login shell has a variable called x that has been assigned the value 100 (assume for now that this is the only variable defined in the shell). This is depicted in Figure 11.1.
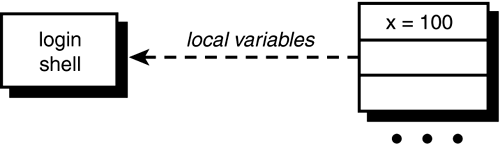
When you ask to have vartest2 executed, your login shell starts up a subshell to run it, giving it an empty list of local variables to start with (see Figure 11.2).
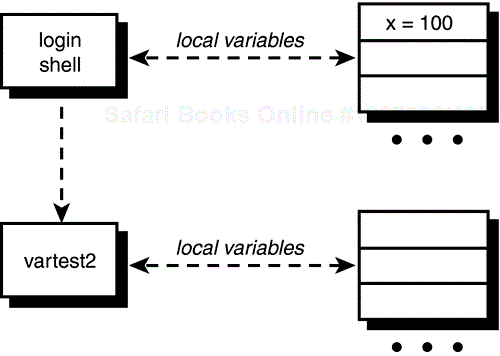
After the first command in vartest2 is executed (that assigns 50 to x), the local variable x that exists in the subshell's environment will have the value 50 (see Figure 11.3). Note that this has no relation whatsoever to the variable x that still maintains its value of 100 in the login shell.
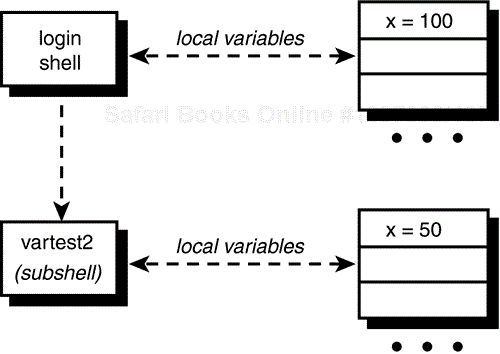
When vartest2 finishes execution, the subshell goes away, together with any variables assigned values.
There is a way to make the value of a variable known to a subshell, and that's by exporting it with the export command. The format of this command is simply
export variables
where variables is the list of variable names that you want exported. For any subshells that get executed from that point on, the value of the exported variables will be passed down to the subshell.
Here's a program called vartest3 to help illustrate the difference between local and exported variables:
$ cat vartest3
echo x = $x
echo y = $y
$
Assign values to the variables x and y in the login shell, and then run vartest3:
$ x=100 $ y=10 $ vartest3 x = y = $
x and y are both local variables, so their values aren't passed down to the subshell that runs vartest3. Now let's export the variable y and try it again:
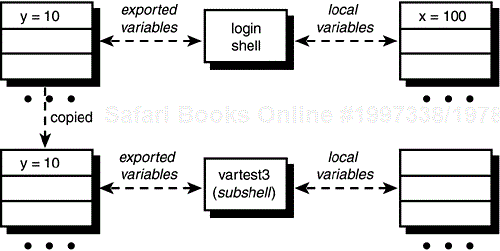
$ export y Make y known to subshells $ vartest3 x = y = 10 $
This time, vartest3 knew about y because it is an exported variable. Conceptually, whenever a subshell is executed, the list of exported variables gets “copied down” to the subshell, whereas the list of local variables does not (see Figure 11.4).
Now it's time for another question: What do you think happens if a subshell changes the value of an exported variable? Will the parent shell know about it after the subshell has finished? To answer this question, here's a program called vartest4:
$ cat vartest4
x=50
y=5
$
We'll assume that you haven't changed the values of x and y, and that y is still exported.
$ vartest4
$ echo $x $y
100 10
$
So the subshell couldn't even change the value of the exported variable y; it merely changed the copy of y that was passed to its environment when it was executed (see Figure 11.5). Just as with local variables, when a subshell goes away, so do the values of the exported variables. There is no way to change the value of a variable in a parent shell from within a subshell.
In the case of a subshell executing another subshell (for example, the rolo program executing the lu program), the process is repeated: The exported variables from the subshell are copied to the new subshell. These exported variables may have been exported from above, or newly exported from within the subshell.
After a variable is exported, it remains exported to all subshells subsequently executed.
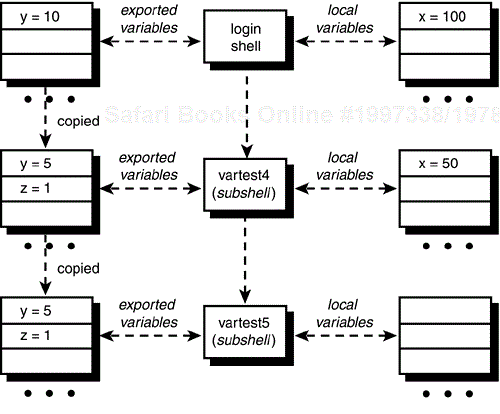
Consider a modified version of vartest4:
$ cat vartest4
x=50
y=5
z=1
export z
vartest5
$
$ cat vartest5
echo x = $x
echo y = $y
echo z = $z
$
When vartest4 gets executed, the exported variable y will be copied into the subshell's environment. vartest4 sets the value of x to 50, changes the value of y to 5, and sets the value of z to 1. Then it exports z. This makes the value of z accessible to any subshell subsequently run by vartest4. vartest5 is such a subshell, and when it is executed, the shell copies into its environment the exported variables from vartest4: y and z. This should explain the following output:
$ vartest4
x =
y = 5
z = 1
$
This entire operation is depicted in Figure 11.6.
To summarize the way local and exported variables work:
Any variable that is not exported is a local variable whose existence will not be known to subshells.
Exported variables and their values are copied into a subshell's environment, where they may be accessed and changed. However, such changes have no effect on the variables in the parent shell.
Exported variables retain this characteristic not only for directly spawned subshells, but also for subshells spawned by those subshells (and so on down the line).
A variable can be exported any time before or after it is assigned a value.
If you simply type export -p, you'll get a list of the variables and their values exported by your shell:
$ export –p
export LOGNAME=steve
export PATH=/bin:/usr/bin:.
export TIMEOUT=600
export TZ=EST5EDT
export y=10
$
As you can see, there are actually more exported variables here than you were initially led to believe. Note that y shows up on the list, together with other variables that were exported when you logged on.
Note that the variables listed include those that have been inherited from a parent shell.
The characters that the shell displays as your command prompt are stored in the variable PS1. You can change this variable to be anything you want. As soon as you change it, it'll be used by the shell from that point on.
$ echo :$PS1: :$ : $ PS1="==> " ==> pwd /users/steve ==> PS1="I await your next command, master: " I await your next command, master: date Wed Sep 18 14:46:28 EDT 2002 I await your next command, master: PS1="$ " $ Back to normal
Your secondary command prompt, normally >, is kept in the variable PS2, where you can change it to your heart's content:
$ echo :$PS2: :> : $ PS2="=======> " $ for x in 1 2 3 =======> do =======> echo $x =======> done 1 2 3 $
Like any other shell variables, after you log off the system, the values of those variables go with it. So if you change PS1, the shell will use the new value for the remainder of your login session. Next time you log in, however, you'll get the old value again. You can make the change yourself every time you log in, or you can have the change made automatically by adding it to your .profile file (discussed later in this chapter).
Your home directory is where you're placed whenever you log on to the system. A special shell variable called HOME is also automatically set to this directory when you log on:
$ echo $HOME
/users/steve
$
This variable can be used by your programs to identify your home directory. It's also used by the cd command whenever you type just cd with no arguments:
$ pwd Where am I? /usr/src/lib/libc/port/stdio $ cd $ pwd /users/steve There's no place like home $
You can change your HOME variable to anything you want, but be warned that doing so may affect the operation of any programs that rely on it:
Return for a moment to the rolo program from Chapter 10, “Reading and Printing Data”:
$ rolo Liz
Liz Stachiw 212-555-2298
$
Let's see what directory this program was created in:
$ pwd
/users/steve/bin
$
Okay, now change directory to anywhere you want:
$ cd Go home $
And now try to look up Liz in the phone book:
$ rolo Liz
sh: rolo: not found
$
Unless you already know where this discussion is leading, you are likely to get the preceding results.
Whenever you type in the name of a program to be executed, the shell searches a list of directories until it finds the requested program.[1] When found, it initiates its execution. This list of directories is contained in a special shell variable called PATH. This variable is automatically set for you when you log on to the system. See what it's set to now:
Chances are that your PATH has a slightly different value. As noted, the PATH specifies the directories that the shell searches to execute a command. These directories are separated from one another by colons (:). In the preceding example, three directories are listed: /bin, /usr/bin, and . (which, you'll recall, stands for the current directory). So whenever you type in the name of a program, say for example rolo, the shell searches the directories listed in PATH from left to right until it finds an executable file called rolo. First it looks in /bin, then in /usr/bin, and finally in the current directory for an executable file called rolo. As soon as it finds rolo, the shell executes it; if the shell doesn't find rolo, the shell issues a “not found” message.
The path
/bin:.:/usr/bin
specifies to search /bin, followed by the current directory, followed by /usr/bin. To have the current directory searched first, you put the period at the start of the path:
.:/bin:/usr/bin
For security reasons, it's generally not a good idea to have your current directory searched before the system ones.[2]
The period for specifying the current directory is optional; for example, the path
:/bin:/usr/bin
is equivalent to the previous one; however, throughout this text we'll specify the current directory with a period for clarity.
You can always override the PATH variable by specifying a path to the file to be executed. For example, if you type
/bin/date
the shell goes directly to /bin to execute date. The PATH in this case is ignored, as it is if you type in
../bin/lu
or
./rolo
This last case says to execute the program rolo in the current directory.
So now you understand why you couldn't execute rolo from your HOME directory: /users/steve/bin wasn't included in your PATH, and so the shell couldn't find rolo. This is a simple matter to rectify. You can simply add this directory to your PATH:
$ PATH=/bin:/usr/bin:.:/users/steve/bin
$
Now any program in /users/steve/bin can be executed by you from anywhere:
$ pwd Where am I? /users/steve $ rolo Liz grep: can't open phonebook $
This time the shell finds rolo and executes it, but grep can't find the phonebook file. Look back at the rolo program, and you'll see that the grep error message must be coming from lu. Take another look at lu:
$ cat /users/steve/bin/lu
#
# Look someone up in the phone book -- version 3
#
if [ "$#" -ne 1 ]
then
echo "Incorrect number of arguments"
echo "Usage: lu name"
exit 1
fi
grep "$name" phonebook
$
grep is trying to open the phonebook file in the current directory, which is /users/steve (that's where the program is being executed from—the current directory has no relation to the directory in which the program itself resides).
The PATH only specifies the directories to be searched for programs to be executed, and not for any other types of files. So phonebook must be precisely located for lu. There are several ways to fix this problem—a problem which, by the way, exists with the rem and add programs as well. One approach is to have the lu program change directory to /users/steve/bin before it does the grep. That way, grep finds phonebook because it exists in the current directory:
... cd /users/steve/bin grep "$1" phonebook
This approach is a good one to take when you're doing a lot of work with different files in a particular directory: simply cd to the directory first and then you can directly reference all the files you need.
A second approach is to simply list a full path to phonebook in the grep command:
... grep "$1" /users/steve/bin/phonebook
But suppose that you want to let others use your rolo program (and associated lu, add, and rem programs). You can give them each their own copy, and then you'll have several copies of the identical program on the system—programs that you'll probably have to maintain. And what happens if you make a small change to rolo? Are you going to update all their copies as well? A better solution might be to keep just one copy of rolo but to give other users access to it.[3]
If you change all the references of phonebook to explicitly reference your phone book, everyone else who uses your rolo program will be using your phone book, and not his own. One way to solve the problem is to require that everyone have a phonebook file in his home directory; this way, if the program references the file as $HOME/phonebookw, it will be relative to the home directory of the person running the program.
Let's try this approach: Define a variable inside rolo called PHONEBOOK and set it to $HOME/phonebook. If you then export this variable, lu, rem, and add (which are executed as subshells by rolo) can use the value of PHONEBOOK to reference the file. One advantage of this is if in the future you change the location of the phonebook file, all you'll have to do is change this one variable in rolo; the other three programs can remain untouched.
Here is the new rolo program, followed by modified lu, add, and rem programs.
$ cd /users/steve/bin $ cat rolo # # rolo - rolodex program to look up, add, and # remove people from the phone book # # # Set PHONEBOOK to point to the phone book file # and export it so other progs know about it # PHONEBOOK=$HOME/phonebook export PHONEBOOK if [ ! -f "$PHONEBOOK" ] then echo "No phone book file in $HOME!" exit 1 fi # # If arguments are supplied, then do a lookup # if [ "$#" -ne 0 ] then lu "$@" exit fi validchoice="" # set it null # # Loop until a valid selection is made # until [ -n "$validchoice" ] do # # Display menu # echo ' Would you like to: 1. Look someone up 2. Add someone to the phone book 3. Remove someone from the phone book Please select one of the above (1-3): c' # # Read and process selection # read choice echo case "$choice" in 1) echo "Enter name to look up: c" read name lu "$name" validchoice=TRUE;; 2) echo "Enter name to be added: c" read name echo "Enter number: c" read number add "$name" "$number" validchoice=TRUE;; 3) echo "Enter name to be removed: c" read name rem "$name" validchoice=TRUE;; *) echo "Bad choice";; esac done $ cat add # # Program to add someone to the phone book file # if [ "$#" -ne 2 ] then echo "Incorrect number of arguments" echo "Usage: add name number" exit 1 fi echo "$1 $2" >> $PHONEBOOK sort -o $PHONEBOOK $PHONEBOOK $ cat lu # # Look someone up in the phone book # if [ "$#" -ne 1 ] then echo "Incorrect number of arguments" echo "Usage: lu name" exit 1 fi name=$1 grep "$name" $PHONEBOOK if [ $? -ne 0 ] then echo "I couldn't find $name in the phone book" fi $ cat rem # # Remove someone from the phone book # if [ "$#" -ne 1 ] then echo "Incorrect number of arguments" echo "Usage: rem name" exit 1 fi name=$1 # # Find number of matching entries # matches=$(grep "$name" $PHONEBOOK | wc –l) # # If more than one match, issue message, else remove it # if [ "$matches" -gt 1 ] then echo "More than one match; please qualify further" elif [ "$matches" -eq 1 ] then grep -v "$name" $PHONEBOOK > /tmp/phonebook$$ mv /tmp/phonebook$$ $PHONEBOOK else echo "I couldn't find $name in the phone book" fi $
(In an effort to be more user-friendly, a test was added to the end of lu to see whether the grep succeeds; if it doesn't, a message is displayed to the user.)
$ cd Return home $ rolo Liz Quick lookup No phonebook file in /users/steve! Forgot to move it $ mv /users/steve/bin/phonebook . $ rolo Liz Try again Liz Stachiw 212-555-2298 $ rolo Try menu selection Would you like to: 1. Look someone up 2. Add someone to the phone book 3. Remove someone from the phone book Please select one of the above (1-3): 2 Enter name to be added: Teri Zak Enter number: 201-555-6000 $ rolo Teri Teri Zak 201-555-6000 $
rolo, lu, and add seem to be working fine. rem should also be tested to make sure that it's okay as well.
If you still want to run lu, rem, or add standalone, you can do it provided that you first define PHONEBOOK and export it:
$ PHONEBOOK=$HOME/phonebook $ export PHONEBOOK $ lu Harmon I couldn't find Harmon in the phone book $
If you do intend to run these programs standalone, you'd better put checks in the individual programs to ensure that PHONEBOOK is set to some value.
Your current directory is also part of your environment. Take a look at this small shell program called cdtest:
$ cat cdtest
cd /users/steve/bin
pwd
$
The program does a cd to /users/steve/bin and then executes a pwd to verify that the change was made. Let's run it:
$ pwd Get my bearings /users/steve $ cdtest /users/steve/bin $
Now for the $64,000 question: If you execute a pwd command now, will you be in /users/steve or /users/steve/bin?
$ pwd
/users/steve
$
The cd executed in cdtest had no effect on your current directory. Because the current directory is part of the environment, when a cd is executed from a subshell, the current directory of that subshell is altered. There is no way to change the current directory of a parent shell from a subshell.
When cd is invoked, it sets the PWD shell variable to the full pathname of the new current directory, so the command
echo $PWD
produces the same output as the pwd command:
$ pwd /users/steve $ echo $PWD /users/steve $ cd bin $ echo $PWD /users/steve/bin $
cd also sets OLDPWD to the full pathname of the previous current directory.
Incidentally, cd is a shell built-in command.
The CDPATH variable works like the PATH variable: It specifies a list of directories to be searched by the shell whenever you execute a cd command. This search is done only if the specified directory is not given by a full pathname and if CDPATH is not null (obviously). So if you type in
cd /users/steve
the shell changes your directory directly to /users/steve; but if you type
cd memos
the shell looks at your CDPATH variable to find the memos directory. And if your CDPATH looks like this:
$ echo $CDPATH
.:/users/steve:/users/steve/docs
$
the shell first looks in your current directory for a memos directory, and if not found then looks in /users/steve for a memos directory, and if not found there tries /users/steve/docs in a last ditch effort to find the directory. If the directory that it finds is not relative to your current one, the cd command prints the full path to the directory to let you know where it's taking you:
$ cd /users/steve $ cd memos /users/steve/docs/memos $ cd bin /users/steve/bin $
Like the PATH variable, use of the period for specifying the current directory is optional, so
:/users/steve:/users/steve/docs
is equivalent to
.:/users/steve:/users/steve/docs
Judicious use of the CDPATH variable can save you a lot of typing, especially if your directory hierarchy is fairly deep and you find yourself frequently moving around in it (or if you're frequently moving around into other directory hierarchies as well).
Unlike the PATH, you'll probably want to put your current directory first in the CDPATH list. This gives you the most natural use of CDPATH (because you're used to doing a cd x to switch to the subdirectory x). If the current directory isn't listed first, you may end up in an unexpected directory.
It's important for you to understand the way subshells work and how they interact with your environment. You know now that a subshell can't change the value of a variable in a parent shell, nor can it change its current directory. Suppose that you want to write a program to set values for some variables that you like to use whenever you log on. For example, assume that you have the following file called vars:
$ cat vars BOOK=/users/steve/book UUPUB=/usr/spool/uucppublic DOCS=/users/steve/docs/memos DB=/usr2/data $
You know that if you execute vars, the values assigned to these variables will not be accessible by you after this program has finished executing because vars will be run in a subshell:
Luckily, there is a shell built-in command called . (pronounced “dot”) whose general format is
. file
and whose purpose is to execute the contents of file in the current shell. That is, commands from file are executed by the current shell just as if they were typed at that point. A subshell is not spawned to execute the program. The shell uses your PATH variable to find file, just like it does when executing other programs.
$ . vars Execute vars in the current shell $ echo $BOOK /users/steve/book Hoorah! $
Because a subshell isn't spawned to execute the program, any variable that gets assigned a value stays even after execution of the program is completed. It follows then that if you have a program called db that has the following commands in it:
$ cat db
DATA=/usr2/data
RPTS=$DATA/rpts
BIN=$DATA/bin
cd $DATA
$
executing db with the “dot” command
$ . db $
defines the three variables DATA, RPTS, and BIN in the current shell and then changes you to the $DATA directory.
$ pwd
/usr2/data
$
This last example brings up an interesting point of discussion. If you're one of those Unix users who have to support a few different directory hierarchies, you can create programs like db to execute whenever you have to work on one of your directories. In that program, you can also include definitions for other variables; for example, you might want to change your prompt in PS1 to something like DB—to let you know that your database variables have been set up. You may also want to change your PATH to include a directory that has programs related to the database and your CDPATH variable so that directories in the database will be easily accessible with the cd command. You can even change HOME so that a cd without any arguments returns you directly to your database directory.
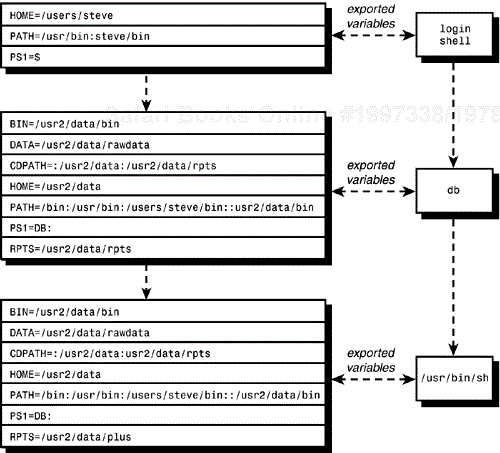
If you make these sorts of changes, you'll probably want to execute db in a subshell and not in the current shell because doing the latter leaves all the modified variables around after you've finished your work on the database. The trick to doing it right is to start up a new shell from inside the subshell, with all the modified variables exported to it. Then, when you're finished working with the database, you can “log off” the new shell by pressing Ctrl+d. Let's take a look at how this works. Here is a new version of db:
$ cat db
#
# Set up and export variables related to the data base
#
HOME=/usr2/data
BIN=$HOME/bin
RPTS=$HOME/rpts
DATA=$HOME/rawdata
PATH=$PATH$BIN
CDPATH=:$HOME:$RPTS
PS1="DB: "
export HOME BIN RPTS DATA PATH CDPATH PS1
#
# Start up a new shell
#
/usr/bin/sh
$
The HOME directory is set to /usr2/data, and then the variables BIN, RPTS, and DATA are defined relative to this HOME (a good idea in case you ever have to move the directory structure somewhere else: all you'd have to change in the program is the variable HOME).
Next, the PATH is modified to include the database bin directory, and the CDPATH variable is set to search the current directory, the HOME directory, and the RPTS directory (which presumably contains subdirectories).
After exporting these variables (which as you recall must be done to put the values of these variables into the environment of subsequently spawned subshells), the standard shell, /usr/bin/sh, is started. From that point on, this new shell processes commands typed in from the terminal. When Ctrl+d is typed to this shell, control returns to db, which in turn returns control to your login shell.
$ db Run it DB: echo $HOME /usr2/data DB: cd rpts Try out CDPATH /usr2/data/rpts It works DB: ps See what processes are running PID TTY TIME COMMAND 123 13 0:40 sh Your login shell 761 13 0:01 sh Subshell running db 765 13 0:01 sh New shell run from db 769 13 0:03 ps DB: Ctrl+d Done for now $ echo $HOME /users/steve Back to normal $
The execution of db is depicted in Figure 11.7 (where we've shown only the exported variables of interest, not necessarily all that exist in the environment).
After you started up the new shell from db, you weren't interested in doing anything further after the shell finished, as evidenced by the fact that no commands followed /usr/bin/sh in the program. Instead of having db wait around for the new shell to finish, you can use the exec command to replace the current program (db) with the new one (/usr/bin/sh). The general format of exec is
exec program
where program is the name of the program to be executed. Because the exec'ed program replaces the current one, there's one less process hanging around; also, startup time of an exec'ed program is quicker, due to the way the Unix system executes processes.
To use exec in the db program, you simply replace the last line with
exec /usr/bin/sh
As noted, after this gets executed, db will be replaced by /usr/bin/sh. This means that it's pointless to have any commands follow the exec because they'll never be executed.
exec can be used to close standard input and reopen it with any file that you want to read. To change standard input to file, you use the exec command in the form
exec < file
Any commands that subsequently read data from standard input will read from file.
Redirection of standard output is done similarly. The command
exec > report
redirects all subsequent output written to standard output to the file report. Note here that exec is not used to start up execution of a new program as previously described; here it is used to reassign standard input or standard output.
If you use exec to reassign standard input and later want to reassign it someplace else, you can simply execute another exec. To reassign standard input back to the terminal, you would write
exec < /dev/tty
The same discussion applies to reassignment of standard output.
Sometimes you may want to group a set of commands together for some reason. For example, you may want to send a sort followed by execution of your plotdata program into the background for execution. You can group a set of commands together by enclosing them in a set of parentheses or braces. The first form causes the commands to be executed by a subshell, the latter form by the current shell.
Here are some examples to illustrate how they work:
$ x=50 $ (x=100) Execute this in a subshell $ echo $x 50 Didn't change $ { x=100; } Execute this in the current shell $ echo $x 100 $ pwd Where am I? /users/steve $ (cd bin; ls) Change to bin and do an ls add greetings lu number phonebook rem rolo $ pwd /users/steve No change $ { cd bin; } This should change me $ pwd /users/steve/bin $
If the commands enclosed in the braces are all to be typed on the same line, a space must follow the left brace, and a semicolon must appear after the last command.
As the example
(cd bin; ls)
shows, the parentheses are useful for doing some commands without affecting your current environment. You can also use them for other purposes:
$ (sort 2002data -o 2002data; plotdata 2002data) &
[1] 3421
$
The parentheses group the sort and plotdata commands together so that they can both be sent to the background for execution, with their order of execution preserved.
Input and output can be piped to and from these constructs, and I/O can be redirected. In the next example, a
.ls 2
nroff command (for double-spaced output) is effectively tacked to the beginning of the file memo before being sent to nroff.
$ { echo ".ls 2"; cat memo; } | nroff -Tlp | lp
In the command sequence
$ { prog1; prog2; prog3; } 2> errors
all messages written to standard error by the three programs are collected into the file errors.
As a final example, let's return to the mon program from Chapter 9, “'Round and 'Round She Goes.” As you'll recall, this program periodically checked for a user logging on to the system. One of the comments we made back then is that it would be nice if the program could somehow automatically “send itself” to the background for execution because that's how it's really meant to be run. Now you know how to do it: You simply enclose the until loop and the commands that follow inside parentheses and send it into the background:
$ cat mon # # Wait until a specified user logs on -- version 4 # # Set up default values mailopt=FALSE interval=60 # process command options while getopts mt: option do case "$option" in m) mailopt=TRUE;; t) interval=$OPTARG;; ?) echo "Usage: mon [-m] [-t n] user" echo" -m means to be informed by mail" echo" -t means check every n secs." exit 1;; esac done # Make sure a user name was specified if [ "$OPTIND" -gt "$#" ] then echo "Missing user name!" exit 2 fi shiftcount=$(( OPTIND – 1 )) shift $shiftcount user=$1 # # Send everything that follows into the background # ( # # Check for user logging on # until who | grep "^$user " > /dev/null do sleep $interval done # # When we reach this point, the user has logged on # if [ "$mailopt" = FALSE] then echo "$user has logged on" else runner=$(who am i | cut -c1-8) echo "$user has logged on" | mail $runner fi ) &
The entire program could have been enclosed in parentheses, but we arbitrarily decided to do the argument checking and parsing first before sending the remainder to the background.
$ mon fred $ Prompt comes back so you can continue working ... fred has logged on
Note that a process id number is not printed by the shell when a command is sent to the background within a shell program.
If you want to send the value of a variable to a subshell, there's another way to do it besides setting the variable and then exporting it. On the command line, you can precede the name of the command with the assignment of as many variables as you want. For example,
DBHOME=/uxn2/data DBID=452 dbrun
places the variables DBHOME and DBID, and their indicated values, into the environment of dbrun and then dbrun gets executed. These variables will not be known to the current shell; they're created only for the execution of dbrun. In fact, execution of the preceding command behaves identically to typing
(DBHOME=/uxn2/data; DBID=452; export DBHOME DBID; dbrun)
Here's a short example:
$ cat foo1 echo :$x: foo2 $ cat foo2 echo :$x: $ foo1 :: :: x not known to foo1 or foo2 $ x=100 foo1 Try it this way :100: x is known to foo1 :100: and to its subshells $ echo :$x: :: Still not known to current shell $
So variables defined this way otherwise behave as normal exported variables to the subshell.
In Chapter 3, “What Is the Shell?,” you learned about the login sequence. This sequence is completed when your shell displays your command prompt and waits for you to type your first command. Just before it does that, however, your login shell executes two special files on the system. The first is /etc/profile. This file is set up by the system administrator and usually does things like checking to see whether you have mail (Where do you think the “You have mail.” message comes from?), setting your default file creation mask (your umask), assigning values to some standard exported variables, and anything else that the administrator wants to have executed whenever a user logs in.
The second file that gets automatically executed is .profile in your home directory. Your system administrator may have given you a default .profile file when you got your account. See what's in it now:
$ cat $HOME/.profile
PATH="/bin:/usr/bin:/usr/lbin:.:"
export PATH
$
Here you see a small .profile file that simply sets the PATH and exports it.
You can change your .profile file to include any commands that you want executed whenever you log in. You can even put commands in your .profile file that override settings (usually environment variables) made in /etc/profile. Note that the commands in /etc/profile and .profile are executed by your login shell (as if you typed in
$ . /etc/profile $ . .profile $
as soon as you logged in), which means that changes made to your environment remain after the programs are executed.
Here's a sample .profile that sets your PATH to include your own bin, sets your CDPATH, changes your primary and secondary command prompts, changes your erase character to a backspace (Ctrl+h) with the stty command, and prints a friendly message using the greetings program from Chapter 8, “Decisions, Decisions”:
$ cat $HOME/.profile PATH=/bin:/usr/bin:/usr/lbin:$HOME/bin:.: CDPATH=.:$HOME:$HOME/misc:$HOME/documents PS1="=> " PS2="====> " export PATH CDPATH PS1 PS2 stty echoe erase CTRL+h echo greetings $
Here's what a login sequence would look like with this .profile:
If you tend to use more than one type of terminal, the .profile is a good place to put some code to prompt for the terminal type and then set the TERM variable accordingly. This variable is used by screen editors such as vi and other screen-based programs.
A sample section of code from a .profile file to prompt for the terminal type might look like this:
echo "What terminal are you using (xterm is the default)? c"
read TERM
if [ -z "$TERM" ]
then
TERM=xterm
fi
export TERM
Based on the terminal type entered, you may also want to do things such as set up the function keys or the tabs on the terminal.
Even if you always use the same terminal type, you should set the TERM variable in your .profile file.
The TZ variable is used by the date command and some Standard C library functions to determine time zone information. The simplest setting for TZ is a time zone name of three or more alphabetic characters followed by a number that specifies the number of hours that must be added to the local time to arrive at Coordinated Universal Time, also known as Greenwich Mean Time. This number can be positive (local time zone is west of 0 longitude) or negative (local time zone is east of 0 longitude). For example, Eastern Standard Time can be specified as
TZ=EST5
The date command calculates the correct time based on this information and also uses the time zone name in its output:
$ TZ=EST5 date Wed Sep 18 15:24:09 EST 2002 $ TZ=xyz3 date Wed Sep 18 17:24:28 xyz 2002 $
A second time zone name can follow the number; if this time zone is specified, daylight savings time is assumed to apply (date automatically adjusts the time in this case when daylight saving is in effect) and is assumed to be one hour earlier than standard time. If a number follows the daylight saving time zone name, this value is used to compute the daylight savings time from the Coordinated Universal Time in the same way as the number previously described.
So, the following TZ settings are quivalent:
TZ=EST5EDT TZ=EST5EDT6
The TZ variable is usually set in either the /etc/profile file or your .profile file. If not set, an implementation-specific default time zone is used, typically Coordinated Universal Time.
[1] Actually, the shell is a bit more intelligent, because it keeps track of where it finds each command you execute. When you re-execute one of these commands, the shell remembers where it was found and doesn't go searching for it again. This feature is known as hashing.
[2] This is to avoid the so-called Trojan horse problem: Someone stores her own version of a command such as su (the command that changes you to another user) in a directory she can write into and waits for another user to change to that directory and run su. If the PATH specifies that the current directory be searched first, then the horsed version of su will be executed. This version will get the password that is typed and then print out Sorry. The user will think he just typed the wrong password.
[3] This can be done by giving them execute permission on all the directories leading to rolo, as well as read and execute permissions on the programs themselves. They can always copy your programs at that point, but you won't have to maintain them.