
Let me get started by saying: Never offer or implement any design unless you are well aware that it addresses all the customer's needs.
That rule is not specific to marketing or sales folk. It's general advice for anyone who deals with technology. If not, we will hear the feedback: I'm having a nightmare; all the problems started happening after that design change. Can you please get rid of that? We have designed or seen various types of vSphere networks. Every network topology will have a loophole. Nothing is perfect in this world and all we can do is ensure that we are better prepared for failures, this seems more like an advantage than a failure? I want all of you to pause for a minute and have a look at the preceding topology; make a note of all failure scenarios that might interrupt data traffic. Adding to that, if we have carefully observed the topology, we will see that universal control VMs and Edges are running on two different sites. So how will the UDLR control VM ensure that whatever routes it is learning from that specific NSX Edge are the only routes learnt by the underlying ESXi host that are specific to that site? I know that is a slightly confusing statement. Never mind, all we need is that routes learned by Site-A appliances (Edges/Control VM) are sent to the Site-A ESXi host and vice versa for Site-B. Okay! Let's get started then and keep reading the following useful points to ensure that our design satisfies our customer requirement without inviting any further problems:
- Both the data centers have two NSX appliances running and we need to ensure they are running in HA mode with vSphere HA also configured. That way, single appliance/host failure will have less impact:
- NSX Edge
- UDLR Control VM
- Ensure that we are using LOCALE-ID (by default, this value is set to the NSX Managers-UUID). With the Locale-ID configuration, NSX Controllers will send routes to ESXi hosts matching Locale-ID. Going via our topology, each site ESXi host will maintain a site-specific local routing table. We can set Locale-ID per cluster, host level and UDLR level. This would perfectly fit in a multi-tenant network/cloud environment wherein each tenant wants to maintain routes which are specific to that tenant.
- All South-North traffic is handled by Site A NSX Edge and SITE B NSX Edge in their respective sites. Starting from NSX 6.1, Equal Cost Multi Path (ECMP) is supported. Hence, we can deploy multiple NSX Edges and the ECMP algorithm will HASH the traffic based on source and destination IP. ECMP can be enabled on Edges and DLR. That way, if there is a failure, it will recalculate the HASH and will route the traffic to the active edge/DLR. In addition to that, there will be designs that might demand back-to-back ECMP configuration, Distributed Logical Router to NSX Edge and NSX Edge to physical routers.
- We should never design something that breaks a working topology. While we deal with ECMP, we need to be aware that NSX Edge has a stateful firewall. There is a good chance we might have asymmetric routing issues; basically, a packet that travels from source to destination uses one path and while replying, takes another path, because at any time only one Edge will be aware of the traffic flow. No worries: while we enable ECMP in NSX 6.1, we will get a message that says enabling this feature will disable Edge firewall. Don't worry, we are not compromising on firewall rules in such designs. Either we can deploy any third-party physical firewall (as shown in the figure) between NSX Edges and Upstream router or we need to leverage Distributed Firewall, which will filter the traffic at the VNIC level. However, starting from NSX 6.1.3, ECMP and logical firewall can work together and for the same reason it won't get disabled by default when we enable ECMP. However, starting from
NSX 6.1.3, ECMP and logical firewall can work together and for the same reason
it won't get disabled by default when we enable ECMP (Active/Standby NSX Edges). The following diagram depicts an ECMP-added configuration for the same topology:
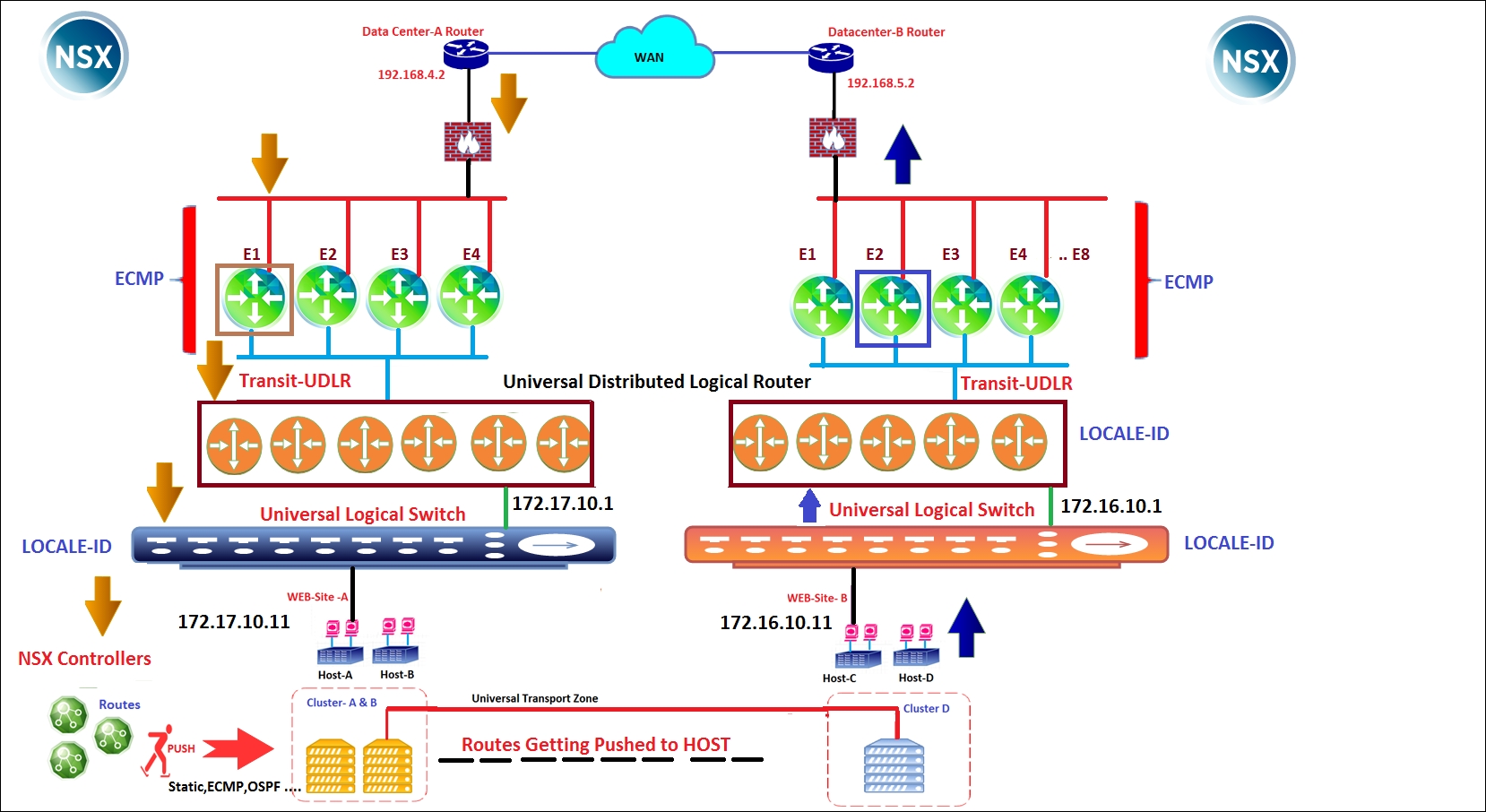
- Since we have NSX Edges running on each site, overlapping IP addresses are supported by configuring a NAT on the site-specific Edge. Again, a highly demanding use case, especially for cloud providers.
- We can have eight NSX Edges participating in ECMP configuration at a time; in our case, eight ECMP edges per site with a total of 16 Edges we can run in that way.
- How about a worst case scenario of complete Site A or Site B failure one at a time? There is certainly a solution for any problem, but in this case, the solution will be slightly tedious and based on the physical network design. Reconfiguring all NSX components in another site may not work.
- Site-B is where we have the primary NSX Manager and Site-B had a complete failure. Starting from NSX Manager role changing, we need to deploy Edges and appliances and can bring the environment back to normal only if the physical network design is equally matching for both the sites. I know this is a tedious process,so if we want to automate such tasks,we need to leverage NSX API and VRO workflow's so that that would ease lot of manual tasks. In a rare case, we may have to reconfigure the physical network so that Site-B machines can communicate with the physical network while they are residing in Site-A during the outage.
There is a lot to be discussed about types of failures, such as NSX components in network sites failing at the same time or virtual environment and physical network partial/full failure scenarios. There are also routing protocol (OSPF/BGP) specific failure scenarios that also bring up some good points for discussion. It is extremely hard to cover all such failure scenarios and carry out precautionary steps based on the type of design in just one book. Luckily, the NSX product documentation from VMware is not limited to installation, configuration, and general designs. There are a few design guides they have released specific to vendor integration, such as NSX+UCS design, NSX+CISCO ACI, and so on. It's worth reading such documents once we have mastered the basics and, hopefully, what we have learnt so far in all seven chapters is a foundation step for climbing the network virtualization ladder. It's been a remarkable discussion so far on VMware NSX topologies and, optimistically, by this time, we all are clear on how VMware NSX is reinventing data center networking.