
Chapter 13. Databases and Authorization
The AdminTask scripting object has several groups of methods that directly or indirectly support data access. In this chapter, we explore the methods from the JDBCProviderManagement and VariableConfiguration groups.
We use a subset of the commands in these groups to present an example that is not well-documented elsewhere. Afterward, we list the other commands in these groups, along with a brief explanation of each.
Database Basics
Any serious enterprise application requires interaction with a database. Given that WebSphere Application Server is really a network of centrally managed servers, this presents a few interesting issues:
• How do you connect to the database in the first place?
• How do you pool connections to the database for efficiency and performance?
• How do you effectively manage what could be a complex configuration?
The database vendor, or some third-party vendor, supplies a jar file that contains a database driver, and that database driver allows database connections to the defined. Application modules deployed to the containers of an application server use that connection to query the database, get result sets from those queries, and update tables in the database. We, as systems administrators, create pools of database connections that applications ultimately use. We decide how big those pools are and how big they will get, and we configure security credentials that allow applications to access the database.
Terminology
DataSource—Creates a pool of database connections and shares that pool among applications on the same server.
J2C Authentication Alias—A flexible data structure that holds a user ID, password, and possibly other data as well. All of this is accessible using an alias. The purpose of this data structure is to enable access to Enterprise Information Systems of all kinds.
JDBC™ Provider—Supplies the actual code that establishes communications between an application and a database.
A Simple Example
An example script file, named database.py, is available from the book website and contains the functions shown in this chapter that can be used to create some basic but useful plumbing to support database connections. If you want to use this script, there are some things you will have to change:
• You will have to change the example node name to a node name that exists in your cell.
• You will have to change the example server name to the name of a server that exists within that node in your cell.
• If your cell already has any of the JNDI names that we use in the sample script, you will have to edit these names so that they do not conflict with your existing JNDI names.
• You may have to make some other changes depending on the specifics of the database you want to use.
You will need some variables for this simple example and will use them throughout it. If your database requires any kind of security credentials, you will need to create a JAAS Authentication Alias.1
1 We cover JAAS Authentication Alias extensively in Chapter 12, “Scripting and Security.”

Notice that the name of the alias is prefixed with the name of one of the nodes, specifically the Deployment Manager’s node’s name. The reason for this has to do with the way the AdminTask SecurityConfiguration command group creates and deletes JAAS Authentication Aliases.2
2 See the discussion about creating a JAAS alias in Chapter 12.
secMgrID = AdminConfig.list( 'Security' )
This line of script is used to obtain the configuration ID of WebSphere Application Server’s security manager. You see sample code like this on many official IBM websites. This code assumes that there is exactly one Security object in your cell.3 There is more than one way to create a JAAS Authentication Alias. This is simply one way. Other choices are discussed in Chapter 12, “Scripting and Security.”4
3 That assumption might not always be true. For a discussion of more advanced security configurations, see the “Multiple Security Domains” section in Chapter 12.
4 See the discussion about creating a JAAS alias in Chapter 12.

The first piece of real database-related work is creating a JDBCProvider. The JDBCProvider supplies the database driver class that actually talks to the database. The two things you absolutely must provide to create a JDBCProvider are the name of a JDBCProvider and the name of the driver class. Although that satisfies the bare bones minimum application server configuration syntax, it is not enough information to do useful work with a database.
The AdminTask scripting object has a method called createJDBCProvider that provides a useful configuration environment for a supported database driver. This method requires more information than the bare bones minimum for a JDBCProvider,5 but it produces a configuration that does useful work. In the next example, we supply some optional arguments in addition to the required arguments:
5 For a complete list of the attributes of JDBCProvider, type print AdminConfig.attributes ('JDBCProvider').

This JDBCProvider is created at the node scope.6 Once the database type, the provider type, and the implementation type are specified, if you also specify one of the supported databases, AdminTask.createJDBCProvider() uses the default JDBCProvider template for that database to fill in some default information about your database driver. The description you specify will appear in the Administrative Console.
6 See the reference section at the end of this chapter. Our discussion of the scope parameter of AdminTask.createJDBCProvider() has examples of how to specify each scope.
There are two possible choices for implementationType: “XA data source” and “Connection pool data source”. You must specify one of these case sensitive strings.7 The first string specifies a driver class that gives your JDBCProvider the ability to perform a two-phase commit. This allows your driver class to participate in transactions that span multiple databases. The second string specifies a driver class that lacks this ability. Both strings result in a JDBCProvider that can support pools of connections.
7 See the reference section at the end of this chapter for a more complete discussion of the arguments for AdminTask.createJDBCProvider().
Once you have a JDBCProvider, you can create a DataSource, which manages a pool of connections to a database. The DataSource created here is as follows:

The name, description, and category of the DataSource are purely descriptive. You can specify any value you’d like for them. They are there for your benefit and for your documentation. The componentManagedAuthenticationAlias8 and the xaRecoveryAuthAlias provide the credentials that the database requires to access data in the database and to roll back failed transactions. The list of lists that follows configureResourceProperties is database-specific and arbitrary. You can see what you need to supply here, either by examining the documentation that comes with the database driver class for your database or by calling AdminTask.createDataSource('-interactive').
8 Some versions of IBM help documents fail to mention this argument. See the reference section at the end of this chapter for a description of all arguments for this method.
Troubleshooting Configuration Problems
Once you have created a JDBCProvider and a DataSource, you can test that connection with one or two lines of script. In the code that follows, assume that d holds the configuration ID of a DataSource that you would like to test:
print AdminControl.testConnection( d )
In order for this connection test to work, you might have to configure either the preTestConfig attribute9 of this DataSource configuration or some attributes of the DataSource MBean10 for this DataSource or both.
9 This attribute holds a ConnectionTest object. Its preTestConnection attribute must be set to “true” and both its retryInterval attribute and its retryLimit attribute must be nonzero integers.
10 See the comments for the testConnection attribute and the testConnectionInterval attribute of the DataSource MBean under “Useful MBeans” in the reference section at the end of this chapter.
Testing the connection11 verifies that the drivers you installed work properly, that the network between your server and the database works, and that your security credentials work on the database. The only thing that AdminControl.testConnection() ignores is the JNDI name that you specified in your JDBCProvider. If your connection passes AdminConfig.testConnection() but you cannot connect to the database, check the spelling of the JNDI name and the scope in which you installed that JNDI name. These are the problems you are most likely to encounter when you try to create JDBCProviders and DataSources:
11 For detailed information about this test and the actual SQL query used for this test, see Listing 13.8.
• Failure to install JDBC driver jar files or installing files in the wrong place
• Specifying an incorrect path to JDBC driver jar files
• Misspelling the names of WebSphere variables in various configurations
• Misspelling the values mapped to WebSphere variables
These problems occur when you create a JDBCProvider, but you won’t see them until you create a DataSource and try to test the connection. If your connection fails, make sure the driver files are where you specified. You should also examine the classpath attribute of your JDBCProvider and compare that with your file system. If there are any WebSphere variables in your classpath, print out those variables, too, and make sure that there are no typos. Typos occur in both the variable names and the variable values. In addition, WebSphere variables and their values are case-sensitive. The data type of a WebSphere variable is VariableSubstitutionEntry. You can look at all the VariableSubstitutionEntrys in your cell or just the VariableSubstitutionEntrys at a particular scope.

Each VariableSubstitutionEntry has a description, a symbolic name, and a value. Check that the symbolic name attribute matches the case-sensitive spelling of any variable in your classpath. Then check that the value attribute matches the case-sensitive spelling of your file system.
Keep in mind, there was also a bug on some versions of WebSphere Application Server that caused misinterpretation of classpath if a VariableSubstitutionEntry in a different scope had an identical symbolic name and a value less than one character long. You might consider removing any VariableSubstitutionEntry that has a value less than one character long. In the code here, assume that v holds the configuration ID of a VariableSubstitutionEntry:
if len( AdminConfig.showAttribute( v, 'value' ) ) < 1:
AdminConfig.remove( v )
If you know the symbolic name of the variable and the scope in which it lives, you can use the methods in the VariableConfiguration command group of AdminTask. If you have a node named Node01 and a variable in that scope with a symbolic name of LOG_ROOT, the following line of script displays its value:
![]()
If you know the symbolicName of the VariableSubstitutionEntry that you want to change, you can use the following:
![]()
In general, if you know the symbolicName of the VariableSubstitutionEntry that you want to manipulate, it is easier to use the AdminTask methods. If you have to search for variables, AdminConfig is easier albeit a bit more cryptic and circumspect.
Let’s say that you create a JDBCProvider and a DataSource. Let’s also say that you test the connection, and your test fails. Now, let’s say you look in your SystemOut log file and see text similar to this:
DSRA8040I: Failed to connect to the DataSource. Encountered "":
java.lang.ClassNotFoundException: com.ibm.db2.jcc.DB2XADataSource
That ClassNotFoundException speaks for itself. For one reason or another, the application server cannot find your jar file, or the jar file is corrupted. When you check the classpath attribute of the JDBCProvider, you can see that the classpath contained a WebSphere variable called UNIVERSAL_JDBC_DRIVER_PATH:
![]()
The preceding code showed that the WebSphere variable had no value. After checking the file system, we found the jar file and fixed the problem with the following code:

The most common configuration problems involving databases are variables with incorrect values and missing jar files. Both problems are easy to fix.
Many times, your DataSource might work, but the response might be slow. Check the IBM Documentation12 for procedures to troubleshoot13 slow response and for performance tuning14 information. Common attributes that need modification include minimum and maximum connections, various timeouts, and various trace strings. Most of these settings involve modifying attributes of the ConnectionPool that belongs to the DataSource. Assuming that ds[2] holds the configuration ID of a DataSource, the following script changes the values of minimum and maximum connections and various timeouts.15 If you are setting the maximum number of connections for a server that is part of a cluster, remember to add the maximum connection number from each server in the cluster and to make sure that your database can handle that number of connections.
12 http://www.IBM.com/support/docview.wss?rs=180&uid=swg21247168.
13 For specific troubleshooting techniques, consider the IBM redbook, WebSphere Application Server v6.1 Problem Determination (SG247461).
14 For concepts and topics that affect system performance, consider Chapter 7 of the IBM redbook, WebSphere Application Server v7.0: Concepts, Planning and Design (SG247708).
15 The description of the DataSource MBean in the reference section in the back of this chapter has an extensive discussion of all of these values and their implications.

Remember that none of these modifications to configuration take effect until you synchronize the nodes in your cell and restart your servers. If you would like to test the modifications you are about to make without restarting servers, you can change the appropriate attributes of the DataSource MBean. Changes to MBeans take effect immediately. They disappear when you stop the server. Keep in mind that you modify the configuration for things like minimum and maximum connections and various time outs by modifying attributes of a ConnectionPool configuration object. But you modify the runtime behavior by modifying the attributes of a DataSource MBean.
In addition to modifying various attributes on the ConnectionPool and the DataSource, you can also specify the amount of tracing and what components will be traced. Tracing is done on a per server basis. The trace service controls tracing. You can make permanent changes to the things you trace by changing the configuration of the trace service.
Permanent changes do not take effect until you save your configuration and reboot the server in question. In a network deployment environment, you will have to synchronize your nodes before you restart your server(s). You can make immediate but temporary changes to the trace service by calling operations or changing attributes of the TraceService MBean. These changes disappear when you stop the server. Or you can make immediate changes that survive server restart by changing both the trace service configuration and the TraceService MBean.
If you need to trace a connection leak, you can use one of the following trace strings:
• ConnLeakLogic=finest
• WAS.j2c=finest
Assume that ts[1] is a string containing the name of an MBean that controls the trace service on the server of interest to you. The code that follows will append our string to the existing trace specification. Modifying the traceSpecification attribute directly causes your modification to be appended to any existing trace specification. Notice that you should save the old trace specification before making any modifications.16
16 Changing the trace specification does not work exactly as you might expect. See the description of the TraceService MBean in the reference section at the end of this chapter for the different operations that modify the traceSpecification.

As soon as this code executes, the application server starts using the new trace specification. At some point, you will want to go back to your original trace specification. To do that, you need the following code:17
17 Changing the trace specification does not work exactly as you might expect. See the description of the TraceService MBean in the reference section at the end of this chapter for the different operations that modify the traceSpecification.
AdminControl.invoke( ts[1], 'setTraceState', oldSpec )
Advanced Settings
In the following code examples, the more advanced settings of JDBCProvider, DataSource, and ConnectionPool are modified. You might do this because you have complex database needs, you have to integrate an arcane version of an unsupported database, you are troubleshooting a database problem, or you are trying to tune database performance. If you have to integrate an old version of a database driver class or if you have to integrate some exotic and possibly unsupported database, you might experience problems with the database driver class that appears to be class loader-related. One option to consider is isolating the database driver class by loading it from its own class loader. You can do this as long as you (or the default template that creates your JDBCProvider) do not set a value for the nativepath attribute of your JDBCProvider.
In previous code examples, you saw a JDBCProvider for IBM’s DB2® database. The default template for DB2 sets a value for nativepath. Therefore, you cannot set the isolatedClassLoader attribute of our JDBCProvider to true. But if you could, this would be the line of script to do it:
AdminConfig.modify( p, [ ['isolatedClassLoader', 'true'] ] )
The DataSource object has an interesting attribute called propertySet, which holds a configuration ID. If you pass that configuration ID to AdminConfig.show(), you will see what is effectively a list of configuration IDs. Examining the attributes of each of these configuration IDs tells you a lot about the tunable features of your database driver. The code in Listing 13.1 shows you how to find the configuration ID of the list of property sets for a given DataSource. These features can change from version to version of the driver and from version to version of the product.
Listing 13.1 Show propertySet Configuration IDs

Listing 13.2 shows a dump utility method that displays the data to which each configuration ID points. The propertySet attribute of a DataSource is a Jacl list. To do anything useful with that list, you have to write some code to parse a Jacl list. Use the code from Listing 13.1 to display the raw Jacl list of property sets. Line 04 in Listing 13.2 shows you where in that Jacl list to find the property set name. Line 07 of Listing 13.2 modifies the Jacl list so that Jython can easily parse it. And the loop starting on line 10 of Listing 13.2 prints each property set from the list.
Listing 13.2 Parse a Jacl List in Order to Display a DataSource propertySet


What you see when you run the dumpPropertySet method will vary depending on the DataSource propertySet you are exploring. Some excerpts from the printout are displayed in Listing 13.3. This is the propertySet from the DataSource for the DB2 provider that was installed earlier in this chapter.
Listing 13.3 First Four Properties from a propertySet

The top line of each paragraph of the dump will tell you the following:
• The name of the property
• The type of data it expects
• The current value (if any)
The rest of each paragraph of the dump is a description of the property. These descriptions are exactly what is provided by either the JDBCProvider template or by whoever installed the JDBCProvider.
As you can see, there are 64 properties in this particular propertySet. The Derby DataSource has a propertySet with only eight. The properties just listed are pretty straightforward; however, Listing 13.4 shows some other properties that shed some light on less clearly understood driver behavior.
Listing 13.4 Three Arcane Properties from a propertySet
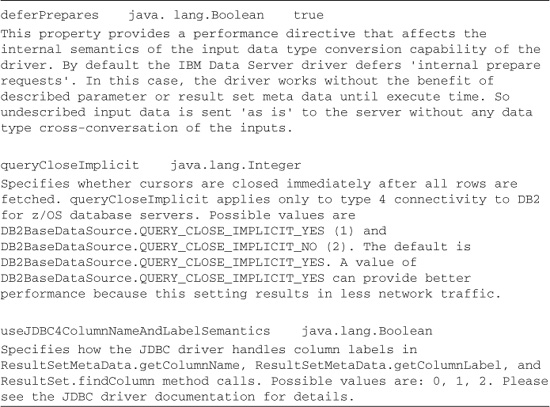
Other properties illuminate the various ways we impact the security of the communication between the driver and the database, as shown in Listing 13.5.
Listing 13.5 Some Properties That Configure Communications Security


And yet other properties have implications for debugging problems, as shown in Listing 13.6.
Listing 13.6 Properties That Aid Debugging
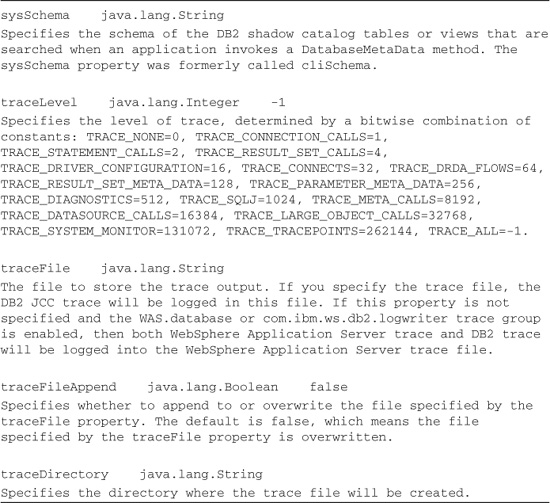
Still other properties have implications for performance, as shown in Listing 13.7. These properties and their values vary from database vendor to database vendor.
Listing 13.7 Properties That Fine-Tune Performance

The default values for all of these properties work well for the vast majority of situations. The debugging properties are very useful when things go wrong. The optimizing properties should not be adjusted until all the traditional optimizations (setting the number of connections, setting various timeouts, and so on) have been performed. Because all of these settings are a part of server configuration, none of them take effect until you save the configuration, synchronize all your affected nodes, and restart the affected servers.
Someday, for whatever reason, you might need to pass specialized, driver-specific values to the driver. You would do this by creating an entire propertySet for the JDBCProvider or by modifying one or more existing values in the propertySet. One value you might choose to modify is the test query. The preTestSQLString holds the SQL query that AdminControl.testConnection()18 sends to your database. If AdminControl.testConnection() receives a result set in response to this query, it reports that your server can connect to your database. If it receives any other response or no response at all, AdminControl .testConnection() reports that your server cannot connect to your database. That query is one of the properties you can expect to find in the JDBCProvider’s propertySet. Listing 13.8 shows the description of the preTestSQLString from one database vendor.
18 Be aware that you might have to do some additional configuration to make this test work. See the footnotes at the beginning of “Troubleshooting Configuration Problems” in this chapter.
Listing 13.8 Property That Specifies the SQL Test Query

You can execute any SQL query you choose, but you want to make sure that the query will work when you first configure your system. You probably want a query that does not take long to execute and does not return a lot of data. Listing 13.9 shows how to change one property within a propertySet. The changes do not take effect until you save your changes, synchronize any affected nodes, and restart the affected servers.
Listing 13.9 Code That Modifies Values in a propertySet

Databases Reference Section
This section provides detailed information about the AdminTask methods that configure all aspects of database connectivity. You need two groups of AdminTask methods and two MBeans any time one of your scripts creates the “plumbing” to interact with databases. AdminTask methods from the JDBCProviderManagement group and the VariableConfiguration group, as well as from the DataSource MBean and the TraceService MBean will all be documented.
Finally, the arguments to each method have been divided into groups. The first group contains the required arguments. The second group is made up of arguments that are not required, but that you are very likely to have to use. The third group is comprised of arguments that are optional and seldom used. The fourth group is arguments that you will have to supply if you are configuring a secure environment. The general pattern for calling AdminTask methods is

There might or might not be a target. If there is, it might be a configuration ID or it might be a name. Targets are usually containment parents. There might or might not be arguments. Arguments are almost always names followed by values. There might or might not be steps as well. Think of steps as arguments that require either a list of names followed by values or nothing at all. Bundle all the arguments and steps into one big list and pass it to the method.
JDBCProviderManagement Group
This section details the JDBCProviderManagement Group methods.
createJDBCProvider
This method creates a new JDBCProvider that is used to connect with a relational database for data access. It uses the default JDBCProvider template for the database in question on the environment in which the application server lives to create a useful working installation and configuration for a supported database driver.
• scope—Scope for the new JDBCProvider. Must be one of the following:
Cell=nameOfYourCell
Node=nameOfSomeNode
Node=nameOfSomeNode,Server=nameOfSomeServer
Cluster=nameOfSomeCluster
Application=displayNameOfSomeApplication
• databaseType19—The type of database used by this JDBCProvider.
19 Print AdminConfig.listTemplates('JDBCProvider') in order to see both providerType and databaseType available to you.
• providerType—The JDBCProvider type used by this JDBCProvider.
• implementationType—The implementation type for this JDBCProvider. Use 'Connection pool data source' if your application runs in a single phase or local transaction. Use 'XA data source' to run in a global transaction. You must use one of those two case-sensitive strings.
Frequently used optional arguments:
• name—The name of the JDBCProvider.
• description—Text to describe the part that this JDBCProvider plays in your topology.
• implementationClassName—The name of the Java class for the JDBC driver implementation.
• classpath—Specifies a list of paths or jar file names that together form the location for the resource provider classes. The classpath can contain multiple elements provided that they are separated with a colon, semicolon, or comma.
• nativePath—Specifies a list of paths that forms the location for the resource provider native libraries. The native path can contain multiple elements provided that they are separated with a colon, semicolon, or comma.
createDataSource
This method creates a new DataSource to access the backend data store. Application components use the DataSource to connect to a database. Each DataSource has a connection pool. This allows connections to be shared.
Target:
The configuration ID of the JDBCProvider that will provide the actual connections to the database. This target is required.
• name—The name of the DataSource.
• jndiName—The Java Naming and Directory Interface (JNDI) name for this DataSource.
Optional arguments that matter if you enable security:
• componentManagedAuthenticationAlias—The alias used for database authentication when querying or updating the database.
• xaRecoveryAuthAlias—The alias used for database authentication during transaction recovery processing.
Frequently used optional arguments:
• description—Some text to describe the purpose this DataSource plays in your topology.
• category—The category that can be used to classify or group the resource. Although this argument is optional, it is very useful for documentation purposes.
Occasionally used optional arguments:
• acknowledgeMode—How the session acknowledges any messages it receives.
Steps:
• configureResourceProperties—Configures the resource properties for the DataSource. These are required properties specific to the type of DataSource being configured. This is a required step. The arguments below are part of a collection. In addition, each of these arguments is read-only. Once they are passed to the DataSource, they cannot be modified or deleted. If you need to change them, you must create another DataSource. Required arguments for this step:
You need a set of these arguments for each resource property, which are resource-specific. The documentation for the names and legal values of these properties comes from whoever provides the resource:
• Name—The name of the resource property. This is a read-only parameter.
• Type—The resource property type. This is a read-only parameter.
• Value—The resource property value. This is a required parameter.
listJDBCProviders
This method returns the configuration ID of each JDBCProvider in the specified scope. If you do not provide a scope argument, you get a list of the configuration IDs of all JDBCProviders.
Frequently used optional arguments:
• scope—Scope for the JDBCProviders that are to be listed. If you do not supply this argument, the default result is to return the configuration IDs of all JDBCProviders. Permitted values are as follows:
Cell=nameOfYourCell
Node=nameOfSomeNode
Node=nameOfSomeNode,Server=nameOfSomeServer
Cluster=nameOfSomeCluster
Application=displayNameOfSomeApplication
listDataSources
This method returns the configuration ID of each DataSource in the specified scope. If you do not provide a scope argument, you get a list of the configuration IDs of all DataSources.
Frequently used optional arguments:
• scope—Scope for the DataSources that are to be listed. If you do not supply this argument, the default result is to return the configuration IDs of all JDBCProviders. Permitted values are as follows:
Cell=nameOfYourCell
Node=nameOfSomeNode
Node=nameOfSomeNode,Server=nameOfSomeServer
Cluster=nameOfSomeCluster
Application=displayNameOfSomeApplication
VariableConfiguration Group
You can create, modify, and display WebSphere variables in one of two ways. You can use the three methods in this group, or you can call AdminConfig.create(), AdminConfig.modify(), and AdminConfig.show(). The methods in this group are much easier to use. The AdminConfig methods require you to traverse WebSphere’s configuration tree to the correct scope, then find the VariableMap within that scope, then find the correct VariableSubstitutionEntry in that VariableMap. The methods in this group do that search for you.
showVariables
This method displays the name of one or more variables and the values of those variables. It can be limited to a certain scope, a certain variable name, or both.
Frequently used optional arguments:
• scope—Specifies the location of the variable.xml file you want to search. If you omit this argument, Cell scope is displayed. Scope can be specified in one of the following ways:
Cell=nameOfYourCell
Node=nameOfSomeNodeInYourCell
Server=nameOfSomeServer. If you have more than one server with the same name, you must specify both the node name and the server name. For instance: Node=Node15,Server=server1
Cluster=nameOfCluster
Application=nameOfApplication
• variableName—The name of the variable. You get the value of this variable as defined in the variable.xml file in the scope you specify. If you omit this argument, you get the name and value of every variable defined in the variable.xml within the scope you specify.
setVariable
This method assigns a value to a variable. If the variable does not yet exist, it will be created. If the variable does exist, any value it currently holds will be changed.
Required arguments:
• variableName—The name of the variable to be created or changed.
Frequently used optional arguments:
• scope—Specifies the location of the variable.xml file you want to search. If you omit this argument, Cell scope is displayed. Scope can be specified in one of the following ways:
Cell=nameOfYourCell
Node=nameOfSomeNodeInYourCell
Server=nameOfSomeServer. If you have more than one server with the same name, you must specify both the node name and the server name. For instance: Node=Node15,Server=server1
Cluster=nameOfCluster
Application=nameOfApplication
• variableValue—The value of the variable.
• variableDescription—Use this field to describe the role this variable plays in your topology.
removeVariable
This method deletes a variable.
Required arguments:
• variableName—The name of the variable to be created or changed.
Frequently used optional arguments:
• scope—Specifies the location of the variable.xml file you want to search. If you omit this argument, Cell scope is displayed. Scope can be specified in one of the following ways:
Cell=nameOfYourCell
Node=nameOfSomeNodeInYourCell
Server=nameOfSomeServer. If you have more than one server with the same name, you must specify both the node name and the server name. For instance: Node=Node15,Server=server1
Cluster=nameOfCluster
Application=nameOfApplication
Useful MBeans
In addition to the AdminTask methods that manipulate DataSources and JDBCProviders, it is sometimes useful to work directly with several MBeans. For each MBean, a subset of its attributes and a subset of its operations are described. These subsets are the attributions and operations that are the most useful for debugging and fine-tuning database access.
DataSource MBean
This MBean, as its name implies, controls and reports on the operation of a DataSource. It also controls and reports on the operation of the connection pool that each DataSource contains. Each DataSource has its own MBean. Many of the attributes of this MBean are also attributes of the DataSource configuration item. If you want to change the runtime behavior of a DataSource without stopping the server that hosts the DataSource, you can change the modifiable attributes of the DataSource MBean. That allows you to experiment and do some troubleshooting without having to synchronize nodes and restart servers.
Interesting Read/Write attributes:
• reapTime - java.lang.Integer—The thread that enforces all the other timeouts runs once each time this number of seconds expire. All other timeouts are effectively rounded up to the next even multiple of reapTime.
• minConnections - java.lang.Integer—Once this number of connections has been opened, the DataSource always keeps at least this number of connections open.
• maxConnections - java.lang.Integer—The DataSource will never open more than this number of connections.
• testConnection - java.lang.Boolean—If this value is set to true and testConnectionInterval is greater than zero, you can call the testConnection method of AdminControl to send a test query over a connection from the free pool.
• testConnectionInterval - java.lang.Integer—This must be set to a value greater than zero in order to call the testConnection method of AdminControl. This value is the number of seconds that the DataSource will wait for a response from the database before failing the connection test.
• stuckTime - java.lang.Integer—Any active connection that does not respond and does not return to the connection pool within this number of seconds is considered “stuck.” It is strongly recommended that stuckTime be at least four times as long as the stuckTimerTime.
• stuckTimerTime - java.lang.Integer—How many seconds before the thread that looks for stuck connections runs. This thread marks connections as stuck or as unstuck. It is strongly recommended that this value be less than one fourth as long as stuckTime.
• stuckThreshold - java.lang.Integer—Once this number of connections are judged to be stuck, any request for a new connection from this pool generates a resource exception. Applications can trap this exception and continue processing if they so choose. One possible remediation available to administrators would be to call the purgePoolContents() method of this MBean. Another possible remediation would be to contact the administrator of the back-end resource.
• surgeThreshhold - java.lang.Integer—When there are more than this number of simultaneous20 requests for connections, each simultaneous request above the number specified here is forced to wait for surgeCreationInterval number of seconds. If your application(s) exhibit spikey, bursty traffic patterns that momentarily overload back-end resources, you might consider adjusting this attribute. The default value is -1. Any value below zero turns off surge protection. A value of zero delays every connection request.
20 Note that surgeThreshold deals with simultaneous requests, not total requests for connections.
• surgeCreationInterval - java.lang.Integer—See surgeThreshhold. The number of seconds that excessive simultaneous connection requests are forced to wait to give the back-end resource time to catch up.
• connectionTimeout - java.lang.Integer—Length of time in seconds before a connection request times out and throws an exception.
• unusedTimeout - java.lang.Integer—Interval in seconds after which an unused connection is discarded by the connection pool maintenance thread.
• agedTimeout - java.lang.Integer—Interval in seconds after which an unused aged connection is discarded by the connection pool maintenance thread.
• holdTimeLimit - java.lang.Integer—diagnosticMode 1 and 2 track the connection hold time by an application. If the hold time is greater than the holdTimeLimit, it is reported in the getPoolContents information. If the diagnosticMode is 2, it also collects the callstack at the time of the getConnection request for those connections exceeding the holdTimeLimit.
Interesting operations: (All of these operations have interesting potential for debugging or for performance tuning.)
• getRegisteredDiagnostics—Returns a list of all diagnostic information available from this MBean. This information varies from version to version of WebSphere Application Server. It can also vary based on any enhancements you purchase and based on your database vendor and version.
• getJndiName—Returns the JNDI name for this DataSource. This can be useful for either documentation reasons or troubleshooting reasons.
• showPoolContents—Dumps all the connections in the pool.
• purgePoolContents—Closes all the connections in the pool.
• getStatementCacheSize—The size of the statement cache affects performance.
TraceService MBean
This MBean controls the amount of debugging and performance information that an individual server records. The records could be stored in a file or held in memory. If held in memory, you can control the size of the memory buffer. Indirectly, that determines the number of events your server remembers. Although this MBean reports the name of the file used to hold trace results, this MBean cannot permanently change the name, location of the trace file, or the decision to store trace results in memory versus in a file. It can, however, do all of that on a temporary basis. None of these changes will survive a server stop.
Interesting Read / Write attributes:
• ringBufferSize - int—The size of the ring buffer that holds trace events if tracing is done in memory as opposed to dumping the trace data to a file.
• traceSpecification - java.lang.String—This string determines what the trace service traces and how much information it captures. If you directly manipulate the value of this string, your modification is processed by the appendTraceString operation of this MBean. Your modifications are appended to the existing traceSpecification. They do not replace the existing traceSpecification. Call the setTraceState operation if you want to replace the entire traceSpecification. The tracing is based on Log4J. You can trace IBM Java code and third-party Java code. You can also trace certain standard events depending on any combination of:
• Which Java package(s) you choose to trace
• Which groups of Java packages you choose to trace
• Which individual Java classes you choose to trace
• What level of information you choose to extract from each thing you choose to trace
Interesting operations: (All of these operations have interesting potential for debugging or for performance tuning.)
• checkTraceString—Tells you if the string you pass in conforms to TraceString grammar.
• setTraceOutputToRingBuffer—Make the ring buffer the active trace destination to which trace is routed. If trace is currently being routed to the ring buffer, the existing ring buffer is simply resized. If trace is currently being routed to a file, the file is closed, and the listener that wraps it is removed from the listener list. This operation requires the following two arguments:
• ringBufferSize - int—The size in kilobytes for the ring buffer.
• traceFormat - java.lang.String—Must be one of the following case-sensitive strings:
• basic—Preserves only basic trace information. Select this option to minimize the amount of space taken up by the trace output.
• advanced—Preserves more specific trace information. Select this option to see detailed trace information for use in troubleshooting and problem determination.
• logicanalyzer—Preserves trace information in the same format as produced by Showlog tool.
• setTraceOutputToFile—Makes the specified file the active trace destination to which trace is routed. If trace is currently being routed to the ring buffer, the existing ring buffer is discarded. If trace is currently being routed to a file, the file is closed and a new one opened. Caution: The results could be unpredictable if the filename is the same as the name of the file currently in use. Requires the following arguments:
• nameOfFile - java.lang.String—Gets the trace output.
• rolloverSize - int—When the file grows to this size, it is renamed by adding the current timestamp to the end of the filename, and a new output file is opened. The number must be greater than zero. The number is the limit expressed in megabytes.
• numberOfBackups - int—This number must be zero or higher.
• format - java.lang.String—Must be one of the following case-sensitive strings:
• basic—Preserves only basic trace information. Select this option to minimize the amount of space taken up by the trace output.
• advanced—Preserves more specific trace information. Select this option to see detailed trace information for use in troubleshooting and problem determination.
• logicanalyzer—Preserves trace information in the same format as produced by Showlog tool.
• rolloverLogFileImmediate—If you have to troubleshoot a busy server, this operation can be a godsend. It immediately rolls over either the SystemOut or the SystemErr file. You pick the name of the backup file. Requires the following arguments:
• streamName - java.lang.String—Must be one of the following case-sensitive choices: SystemOut or SystemErr.
• backUpFileName - java.lang.String—The name of the file used to archive the contents of the chosen stream. May be null. If null is specified, the system generates a file name.
• setTraceState—Replaces the current trace specification with the string you supply. Requires the following argument:
• replacementSpecification - java.lang.String—The new trace specification.
• appendTraceString—Adds the string you supply to any existing trace specification. Note: If any part of this string duplicates an existing portion of a trace string, that portion is replaced rather than duplicated. If you directly manipulate the traceSpecification attribute of this MBean, this is the method that processes your new trace string. Requires the following argument:
• additionalSpecification - java.lang.String—This string will be appended to any existing trace string.
• dumpRingBuffer—Dump the contents of the ring buffer to a file of your choice. This only works if you are tracing to a ring buffer instead of tracing to a file. WebSphere Application Server must have operating system permission to write to the file you specify. Requires the following argument:
• nameOfFile - java.lang.String—The file name. Can be fully qualified. Use forward slashes to delimit directory names regardless of what the underlying operating system uses.
• listComponentsInGroup—Given the name of a trace group, it returns the names of all the packages that make up that group. Requires the following argument:
• nameOfGroup - java.lang.String—The trace group; can also be given as an array of strings containing multiple groups.
Summary
Database access is very important to almost every serious enterprise application. In this chapter, you learned how to manage database connectivity on the WebSphere Application Server platform. We explored the AdminTask methods you are most likely to need, as well as some MBeans that figure prominently in database connectivity. We explored ways to troubleshoot database connectivity and performance issues, and we provided both online and print references for further study. In the next chapter, we explore messaging on the WebSphere Application Server platform.