
5. Physical Disasters with Cultural Foundations and Business Implications
“The last line of defense against errors is usually a safety system.”
—Columbia Accident Investigation Board 200324
We have seen a number of business mistake chains related to execution, strategy, or both. We have hinted that some of these, such as Xerox, Intel, and Kodak, also involved strong cultural underpinnings that made it easier for a mistake chain to start and/or continue, whereas cultural forces helped save a company like J&J from what could have been a disaster. In this and two subsequent chapters, we will examine the cultural context for mistakes because this turns out to be one of the strongest forces driving multiple-mistake scenarios, regardless of industry.
Titanic, Three Mile Island, and NASA’s space shuttles Challenger and Columbia were worlds apart in time and technology, but each created front-page headlines for months. Your initial thought might be that the 70- to 90-year time span would yield few similarities across these disasters. Yet if it were not for multiple mistakes of the most severe variety, the instant worldwide recognition of names like Titanic, Three Mile Island (TMI), Challenger, and Columbia would not exist.
Both Titanic and TMI involved systems whose designers understood that the benefits of new, advanced technologies also require a measure of caution to ensure safe operation. In both cases, very specific design decisions were made that were oriented toward improving performance and safety with minimal operator intervention, but in both cases, humans interfered with the safety designs in one way or another. The result was designs that appeared safe but turned out to be far more dangerous than imagined. In NASA’s case, the technologies were in an earlier stage of evolution and were less robust that previously believed. The real issue for NASA, however, was not the technology but human decision-making that was at the heart of the mistake chain.
Mistakes made by humans is a common theme throughout the incidents described in this book, but Titanic, TMI, and NASA are special cases because they are such extreme examples of assumptions that were incorrect, systems that were misunderstood, and actions that exhibited extraordinary lack of preparation and insight. In short, these were disasters that were completely preventable, but incorrect human actions either created or failed to stop a dangerous sequence of events that led to disaster.
No, these are not business disasters, but they have much to teach you. You could be only a few employees away from a disaster of this magnitude because in some of the largest, best-known, and most damaging business and physical disasters in history, it took surprisingly few people, with the power to make decisions or execute, to do the damage. In these examples, the combination of cultural arrogance and poor execution was truly stunning.
Titanic
When the movie Titanic came out, my wife was eager to see it. I, of course, joked that I didn’t need to see a mushy love story, especially one where I knew the ending. We all know the ending because the 1912 saga of the Titanic is one of the saddest, most publicized disasters of the twentieth century. It was made popular for another couple of generations by the 1985 discovery of the wreckage and recovery of artifacts, along with the 1997 Academy Award–winning movie.
Walter Lord tells the stories25 of two great ships, the Titanic and Great Eastern, each of which suffered hull damage below the waterline. Great Eastern was constructed in 1858 and was a monster for her time, at 680 feet in length with a double hull and enough bulkheads to provide 50 watertight compartments to improve survivability in the event of damage. While not her originally intended mission, she plied the North Atlantic for a few years and then struck an uncharted rock in 1862 in Long Island Sound, resulting in an 83-foot-long, 9-foot-wide gash in the outer hull. The reason you may not have heard of the Great Eastern is that her first line of defense, the double hull, worked and her inner hull held, allowing her to steam into New York Harbor.
Although this technical design saved the Great Eastern, she was a victim of multiple mistakes as a business venture. She was a massive and innovative ship for her day, with steam-driven twin paddle wheels and a center screw along with six masts for sails. She was designed to compete effectively with fast clipper ships on the England-to-Far East route around the Cape of Good Hope. She was large enough to carry 4,000 passengers and cargo but was also large enough to carry enough coal for a round-trip voyage since coal was not available everywhere along her intended routes.
The complexity resulting from her size and safety enhancements was compounded by the use of a new material—iron—for her hull. At this early stage, the weight and lack of experience with iron as a shipbuilding material resulted in a tedious process of riveting plates (strips) of iron together to form the hull*. This meant an expensive learning process for shipbuilders and a very slow construction process. The project was so large and expensive that it attracted great notoriety, and it is reported that 10,000 people showed up to witness the launching, which actually failed because the ship was so large that the builders could not get it to move off the shipway until hydraulic jacks were used a year later.
* Later, steel was used with rivets, and eventually welding advanced the design and construction process. The shift from iron to steel, which continued to improve quality, and from rivets to welding improved strength and reduced weight.
By the time she was completed the Suez Canal had opened, but Great Eastern was too big for passage, so even the slower, less capable ships she was designed to pass on the voyage around the Cape of Good Hope could now complete the shorter route much faster, making Great Eastern a technical marvel that was instantly obsolete.26 She began transatlantic passenger service and had very limited success. Her greatest success, after bankrupting a few owners, came after conversion to the world’s first cable laying ship, laying the first transatlantic cable in 1866. She finished her life from 1885 to 1888 ignominiously as a floating amusement park. It is reported that even when she was finally sold for scrap in 1888, she was built with such strength that it took 200 men two years to dismantle her.
Great Eastern was a ship that avoided the physical disaster that later struck Titanic, but it was a business disaster for a whole series of owners, perhaps with the exception of the salvage yard that took her apart for scrap; it may have made the largest profit anyone did from owning Great Eastern. From a business perspective, the mistakes included:
• Being socially responsible regarding safety at a time when the technology was still too cumbersome to make it affordable, which resulted in overengineering for safety and size at the expense of cost and flexibility of operation
• Assuming that people would want to travel on a ship carrying 4,000 passengers
• Assuming that there would be no impact of the Suez Canal on the operating assumptions
This mistake chain is fairly benign as multiple mistakes go, and while this disaster hurt investors and owners, it did not hurt passengers. In fact, the ship was so massive and complex to build that the jobs created probably benefited the local economy in England. But this was a business disaster nonetheless. Unfortunately, the safety lessons learned here from innovative advanced design features did not carry over to the Titanic.
Within a few years, other ships began using advanced safety features, and Brander discusses the case of the liner Arizona27 that hit an iceberg while doing 15 knots in dense fog. Arizona’s bow telescoped (collapsed) 25 feet, but because she had transverse bulkheads that went all the way to the top deck, she survived and made port in Halifax. This and other incidents helped increase public perception that iron and steel ships were safe. We could even argue that the advanced safety features incorporated into Great Eastern and later ships worked so well that the public, especially operators and naval architects, became overconfident about the safety of the “modern” ships of the day. As competitive pressures increased, tradeoffs and compromises were made.
We can assume that when Titanic was launched 53 years after Great Eastern, marine architects knew of the success of the safety aspect of designs like Great Eastern and Arizona. They probably also knew that Great Eastern was a commercial failure and from all accounts made commercial versus safety tradeoffs. Titanic and her sister ships, Olympic and Britannic, were designed as the largest ships of their day at nearly 900 feet in length and had double hulls and supposedly watertight compartments.
The White Star Line set out to build the ships with an emphasis on speed and world-class comfort, but they clearly did not want to repeat the business folly of the Great Eastern. While safety was apparently a concern, there clearly was not enough learning from the well-engineered design of the Great Eastern that included 15 transverse bulkheads and one longitudinal bulkhead along with watertight lower decks. Significantly, Great Eastern’s bulkheads were built up to 30 feet above the waterline.
Titanic’s designers divided her into 16 separate compartments using 15 transverse bulkheads but no longitudinal bulkhead. Additionally, the bulkheads were only 10 feet above the waterline versus Great Eastern’s 30 feet. As Lord put it:
“Passengers demanded attention; stewards could serve them more easily if doors were cut in the watertight bulkheads. A grand staircase required a spacious opening at every level, making a watertight deck impossible. ... A double hull ate up valuable passenger and cargo space; a double bottom would be enough.”28
The result was a design that was hailed as both an engineering marvel and the most lavish ship to ever sail. Titanic offered every modern luxury and convenience, and J. Bruce Ismay, managing director of the White Star Line, believed this would allow his company to compete with the Cunard Line’s already faster ships29. Often referred to as a “floating palace,” Titanic also included windows forward on the A deck to shield passengers from spray, and the Café Parisian was designed to give the air of a Paris sidewalk restaurant.
But the lack of true watertight compartments was a design mistake made to accommodate fashion and convenience that was perhaps the mostly deadly mistake in the long chain. Truly watertight compartments* require the ability to fully isolate all sources of entry or exit of water. It is possible to put isolation valves in piping and ventilation systems, but for a door to be watertight it must be capable of being “dogged,” or secured with multiple strong mechanisms all the way around. This is the reason why watertight doors (as in warships) have an oval opening, including a lower section that provides watertight integrity at the bottom. You must step over this lower portion of the bulkhead to get through each door. While desirable aboard warships, the thought of well-dressed ladies tripping as they stepped up and over the lips of watertight doors was obviously thought to be undesirable aboard the most fashionable luxury liner in the world. The designers considered this safety enhancement unnecessary above a certain height above the waterline, in this case 10 feet, a judgment that would prove to be disastrous.
* To understand a truly watertight compartment, remember the case of the battleship USS Oklahoma (BB-37) that capsized when Japan attacked Pearl Harbor on December 7, 1941. In the next few days, 32 men were cut out of the hull of Oklahoma. They survived because true watertight compartments kept the water out and provided an air pocket that allowed them to survive until rescued.
In fact, this mistake was so serious that one could argue that there was almost no way to prevent a serious catastrophe with this design once a collision of any significance occurred. However, there were many other human mistakes that contributed to the collision itself and significantly increased the needless loss of life. The public’s perception was that Titanic was unsinkable, something that was the result of press coverage that discussed the claim that she could stay afloat with 2 of her 16 compartments flooded, thus labeling the ship as “practically unsinkable.”
Those who were superstitious might have been worried about certain events as Titanic’s departure time approached. It had been four years from the conception of plans for the sister ships Olympic, Britannic, and Titanic until the sailing of Titanic in 1912, and her owners were eager to have her begin to generate revenue. Sea trials were abbreviated to one day following a weather delay. Immediately upon completion of sea trials, she made the voyage from Belfast to Southampton for final work, provisioning, and to pick up passengers. A near collision with the moored liner New York was not a good sign as Titanic left port in Southampton en route to Cherbourg to pick up additional passengers. During the early days of the voyage, the crew had to cope with a coalbunker fire, a wireless that did not work, and other new-vessel-related items.
Provisions boarded at Southampton included all the necessary linens, china, food, and drink befitting the finest luxury liner of the time. Among the items on the list of provisions were 40 tons of potatoes, 6,000 pounds of butter, 12,000 dinner plates, and 7,500 bath towels. Drinks reflected the mix of three classes of passengers and their preferences for 20,000 bottles of beer, 1,200 bottles of wine, 850 bottles of spirits, and 15,000 bottles of mineral water.30
Workmen were still finishing final touches on paint and carpet as passengers arrived. Titanic departed Southampton on April 10 with a fuel load of 4,400 tons of coal that her owners managed to acquire only because other liners’ trips were cancelled because of a coal strike.
One of the modern conveniences aboard Titanic was a wireless telegraph set with two operators provided by Marconi’s under agreement with the White Star Line. Known as Cable & Wireless today, The Wireless Telegraph and Signal Company was founded in 1897 and in 1900 changed its name to Marconi’s Wireless Telegraph Company31. Transatlantic wireless service began in 1909 and was thus only three years old when Titanic sailed. Titanic and other passenger ships later involved in the rescue of Titanic’s passengers, such as Carpathia and California, had the latest wireless technology, but operators were still learning how to use it effectively. The technology was understood to have significant potential but was in an early stage of adoption. Even though state-of-the-art for the time, this fledgling technology played a critical role in the loss of life aboard Titanic as a result of the limited technological capability and lack of standard operating procedures.
The initial impetus for the adoption of the wireless technology that played such a crucial role in the mistake chain of Titanic was not safety but revenue generation. Passengers wanted to use the new technology to stay in touch and to get business news and stock quotes32.
Does this sound like today’s desire to stay connected with BlackBerry™, WiFi, and airline Internet links via satellite? The issues are no different—customer convenience in return for revenue—and Titanic carried the most powerful transmitter then at sea. This revenue focus meant that, on Titanic and other passenger ships, the incoming and outgoing passenger messages had priority. In fact, cargo ships did not immediately adopt the wireless technology at the same rate as passenger ships because it appeared to increase cost for little practical use.
After departing Southampton, it took Titanic another day to pick up passengers in Cherbourg, France and Queenstown (now Cobh) near Cork, Ireland before she started her much anticipated Atlantic crossing in the early afternoon on April 11, 1912 with over 2,200 passengers and crew. The seas were smooth and Captain E.J. Smith was in command, expecting that Titanic’s Atlantic crossing would be his last before retiring after spending 40 years at sea. When asked about his experience, he remarked that his career had been rather uneventful, never having even been near a disaster or in a threatening situation.33
This comfort with the sea on the part of Captain Smith, the result of a long accident-free career, when combined with the perception held by the public that his ship was unsinkable, certainly set a dangerous context for decision making. Smith’s confidence, and exceptionally good weather, led him to continue to increase speed, with some speculating that one of the objectives on the first voyage was to beat sister ship Olympic’s first voyage crossing time. Whether he was trying to set a company record or not, he clearly exercised extremely poor judgment when he proceeded at full speed, even as he received reports of icebergs in the area.
Following the third warning of ice, J. Bruce Ismay, chairman of White Star, suggested to a passenger that Titanic might speed up to get clear of the ice field.34 Captain Smith was aware of a number of ice warnings from other ships as he attended a dinner party until approximately 9:00 PM on April 14. Following the dinner party, he went to the bridge to check on the status of his ship. It was a clear, starlit night with no moon and a calm sea. He instructed the officer on watch to inform him if visibility decreased and retired to his cabin about 9:30 PM.
This combination of Captain Smith’s past experience, his chairman’s clear interest in speed, the calm weather, and perceived minimal risk was leading the Captain to ignore numerous warnings of potential danger. The fact that he had ignored warnings all afternoon was known to his crew because the wireless operators had been delivering the messages to the bridge and the captain, and there had been no change in operations and standing orders that you would expect from a confident captain in good conditions—”Full steam ahead, let me know if the visibility changes.”
This is one of the most powerful mistakes made in accidents, the setting of a tone by a senior authority figure that subordinates then interpret for themselves as empowerment to continue in the same manner regardless of new facts. And at sea, the captain is the authority figure. His judgment is rarely questioned, especially at that time in the world, with a new ship and a 40-year officer with an unblemished record in charge. This was not a technical question—it was judgment, and who was strong enough to question the captain on such a matter?
Titanic was making good progress. The lookouts were in the crow’s nest*, and the machinery was working smoothly. There were three ice warnings that evening. The captain did not receive the first because he was at dinner. A later one arrived after he retired, and the wireless operator was busy with wireless traffic for passengers and did not see fit to send the warning to the bridge or bother the captain.
* A lookout platform mounted high on a mast to provide longer-range visibility in good weather. Such lookouts are not used on commercial ships at sea in today’s radar-equipped world.
The pattern of mistakes was set and building further at this point, and while not recognized by the captain or his crew, the only thing that would have saved Titanic would have been an exceptional effort by someone in the crew to take personal responsibility to break the chain. This did not happen, just as it does not happen in a variety of situations, business or otherwise, with an imperious leader. The crew trusted his judgment, knew his experience, and while some may have experienced trepidation, they were likely calmed by his lack of concern. The scene was set to test how the crew would react to the total shock of an unexpected event.
What would it have taken to break the chain that, as each of us now knows, was about to unfold? While the magnitude of the final disaster can be partially blamed on technology-related design decisions, it was human factors that really caused this accident, and right up until the moment of impact, humans could have intervened to prevent the accident. Some “normal” actions that might have avoided the accident include:
• Making information sharing and analysis a priority.
• The many warnings of ice in the area were ignored, often arrogantly, as indicated by Ismay’s comment. Many reports gave general positions with their ice warnings, but there were at least two reports on April 14 that gave specific position reports of the iceberg that Titanic ultimately hit, at exactly the position where it had been reported by Amerika at 11:00 AM that day and by Mesnaba at 9:40 PM, just two hours before the collision.35 The message from Mesnaba never reached the bridge, but all the others had reached various officers, including the captain, and had been posted on the bridge and in the chart room. The extent of the warnings that Captain Smith and his crew ignored from ships that were stopped in or moving slowly through the ice field was significant:
• Six warnings from other ships on April 11
• Five warnings on April 12
• Three warnings on April 13
• Seven warnings on April 14, the day of the collision36
Information was trying to save them, and they ignored it. What would have happened if:
• One officer or wireless operator who had seen some or all of the traffic had suggested caution? Would the captain have rebuked this person as overly cautious? Would the captain have consulted Ismay (chairman of White Star), who would likely have pushed to continue the speed? Or would the captain, faced with a mounting volume of warnings, have seen the potential danger and broken the chain by stopping until daybreak, slowing down, or changing course away from the location of the specific warnings about an ice field?
• The captain had changed the routine because of the warnings and had a more formal meeting of his top officers to discuss the warnings and the possible scenarios? Would concern have emerged in a group discussion, or would the captain’s inclination and vast experience simply have overwhelmed any concern expressed by others?
• Changing the mental mindset.
• What if J. Bruce Ismay had been concerned and had interfered with his captain’s authority for the ship at sea and suggested that he be more cautious? This would have at least implied that safety was more important than a speed-related public relations win for the voyage.
• What if someone in the officer corps of the ship had realized that Titanic’s design would fail in certain kinds of collisions? Could an energetic discussion have changed the outcome if someone had successfully argued that the ship was being pushed to or past a safety limit with the speed and conditions that existed?
• Titanic received many incoming messages warning of ice, but there is no mention of her inquiring of others for updates or more information. What if someone was curious enough to ask for more information from the ships in the area? Would a discussion have ensued that would have created alarm? In fact, to the contrary, the infamous action of the wireless operator, Jack Phillips, showed complete disregard for the stream of very important but unsolicited information*, as evidenced by Phillips telling a wireless operator who sent another ice warning from the nearby Californian to “Shut up” because he was busy with passenger traffic. Phillips’ now infamous snub highlighted that generating revenue (from messages) and passenger service was more important than ice warnings.37
* The technology of the day was limited. All ships were using the same frequency, thus there was “limited bandwidth” to use today’s term. All ships and the shore stations within range were sharing a common frequency and thus traffic by one ship was done at the expense of others ability to use the frequency. Titanic’s focus on the passenger traffic clearly interfered with more important operational matters.
Any of these actions could have broken the chain of mistakes or limited damage, but no action was taken. Titanic was set up for the exponential damage associated with unconstrained multiple mistake chains brought about through a combination of external circumstances and serious mistakes of internal origin, as shown in Figure 5.1.
Figure 5.1. Mistake escalation for Titanic.
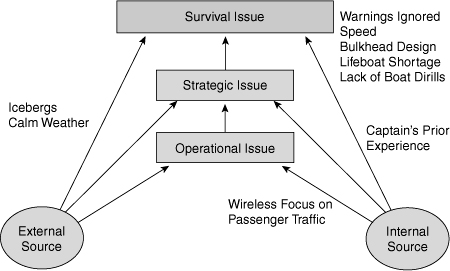
At 11:40 PM on April 14, 1912, lookout Frederick Fleet saw a mass in the dark, immediately signaled the bridge, and picked up a handset in the crow’s nest to report that he saw an iceberg ahead. Sixth Officer James Moody, who was on watch, immediately ordered a hard turn to port, shut the automatic watertight doors below decks, and attempted to reverse the propellers. The ship did turn slightly to port, avoiding a head-on collision with the iceberg but with a resulting scrape down the starboard side that opened a gash estimated to be 300 feet long. The dangerous aspect of this type of collision was that a number of the transverse watertight bulkheads were breached in the process, perhaps a result that was worse than a head-on collision might have been.
Once the collision occurred, the race was on to see whether the damage could be mitigated or if even more mistakes would lead to substantial loss of life. Unfortunately, the latter was the case as a result of a series of preordained mistakes compounded by more human error. These included:
• Delayed recognition of being “in extremis” because of the general perception that the ship was “almost unsinkable.” The crew seemed to go about a routine damage assessment following the collision. But Thomas Andrews, one of the ship’s designers, was on board, and he immediately made a tour below decks to assess damage. By the time he reported to Captain Smith, the news was not good. He told the captain directly that the ship would sink in two hours or less. It was at this point that the captain gave the order to prepare the lifeboats, but strangely he did not give the order to load them for another 30 minutes.
• Andrews knew that Titanic could sustain four flooded compartments, but he found out rather quickly that at least five had been breached. Since all were forward, the ship would sink lower by the bow, and once she did, water would spill over the top of the bulkheads that were built only ten feet above the waterline, flooding other compartments until the ship sank. The fact that Andrews apparently sensed this without equivocation from the start must have been an instant and horrible realization to him of the weakness of the design, something that had been decided three to four years earlier as Titanic’s sister ships were designed and built.
• Passengers reportedly wandered about for a time, inquiring about what was going on. The initial lack of concern on the part of the crew probably reassured them that the event was not serious.
• Titanic carried 20 lifeboats, an economy move decided on by White Star, even though the builders offered a new, more expensive davits that could have carried 48 boats in essentially the same space. The capacity of the boats amounted to about half of the passengers and crew embarked, but this was within the very outdated law in force at the time. The boats included 16 wooden boats, each 30 feet in length and designed to carry 65 persons, and 4 collapsible side canvas lifeboats with a capacity of 47 persons each.
• No lifeboat drills had been conducted since the passengers had boarded. Thus, when it came time to board lifeboats, the passengers were confused. The resulting confusion meant that most of the lifeboats departed with less than a full load of passengers. Those that were designed for 65 passengers departed with as few as 12 aboard. Toward the end, as all realized the severity of the situation, the last few boats were fully loaded, with one boat designed for 65 passengers carrying 70. Brander points out38 that, during World War I, ships of similar size (such as Arabic) that conducted life boat drills were sunk by German submarines with as many as 90 percent of those on board saved from a ship that sank in only nine minutes.
• Occupants of lifeboats with space available after launch “voted,” with few exceptions, to not return to pick up more survivors, fearful that too many would swamp the boat, endangering all.
• The Leyland Liner Californian, originally designed to carry cotton but modified with some staterooms to carry passengers, was 5 to 10 miles away but stopped for the night due to heavy ice in the area. In a conversation between her captain and the third mate, the captain speculated about a light that was seen nearby. A few minutes later, the captain asked the radio operator if there were any other ships nearby, and he replied that only Titanic was in the area. Captain Lord ordered his radio operator to warn Titanic about the ice, which he did. As late as 11:30 PM, just 10 minutes prior to Titanic’s collision, Captain Lord could see her starboard (green) running light and ordered his crew to try to make contact by signal lamp, but there was no reply.
• Between midnight and 2:00 AM, various members of the crew of Californian saw lights in the distance, but each time were convinced they were seeing shooting stars. The watch officer even awoke the captain at one point to report more lights, but when the captain asked if there were any colors in them, which would be the case for a distress signal, the reply was that they were white, further reinforcing the view that they were seeing stars.
• By about 12:30 AM Californian’s wireless operator secured his set and retired for the evening, neglecting to set a device that would have awakened him for incoming traffic. When he came on duty a few hours later, the captain asked him to inquire of a ship they had sighted visually (Frankfurt), and they were stunned to hear that the Titanic had sunk during the night. Californian had been the closest ship, but because her crew did not follow up the signals they saw more aggressively, they played no role in the rescue other than continuing to search for survivors after Carpathia left. Their mindset was that there were no problems present and that the lights they saw had to be natural occurrences.
To the extent that the mistake chain was broken at all, it was by Captain Arthur Rostran, who was in command of the RMS Carpathia, a Cunard passenger liner that was 58 miles away from Titanic at the time she transmitted her SOS*. Captain Rostran steamed at full speed to Titanic’s reported position and made full preparations for receiving and caring for survivors while in route. Even though Captain Rostran had never participated in an actual sea rescue, his actions were subsequently lauded as exemplary. These included preparing lifeboats, setting up first aid stations, preparing extra food and beverages, rigging electric lights, collecting blankets and clothing, briefing his crew, and a variety of other actions that he and his crew anticipated would be required.
* Initially transmitted as “CQD” for “come quick danger,” which had been the standard distress signal as wireless began to be used. SOS had just been adopted as the standard, and Jack Phillips, the wireless operator, shifted to this and became one of the first to use the new signal.
When Carpathia arrived at the reported position, she saw little and slowed almost to a stop to look more carefully for another half-hour. Finally, a lifeboat was spotted, and she maneuvered to begin picking up survivors. It would be over four hours until the last of the 705 survivors was aboard Carpathia. She stayed in the area another five or six hours, continuing to look for survivors, but there were no more.
Despite increasingly bad weather, Carpathia finished the crossing to New York uneventfully and delivered her passengers and the grateful Titanic survivors. Ironically, a German U boat sank Carpathia off the coast of Ireland in 1918, but most of her crew and passengers were rescued.
The numerous mistakes that contributed significantly to this accident or made it worse fall into a number of categories. Looking at the categories and not just the individual mistakes is instructive because the category patterns repeat over and over again in other business as well as physical contexts, while the specific mistakes might be unique to the situation. These categories of mistakes are eerily similar to those we see in major business mistake chains as well:
• Faulty assumptions and mindsets. The “watertight” compartment design that was not really watertight because of bulkhead height and lack of a longitudinal bulkhead was likely the most serious faulty assumption made in the design stage. It was made on the basis of an assumption about the worst-case scenario that was not broad enough. Further, these faulty assumptions created the illusion of safety and thus affected decisions about the number of lifeboats. If the ship is “nearly unsinkable,” why spend more money on lifeboats that will not be needed?
Californian had a number of clues that there was a problem but did not investigate beyond a cursory effort. Their wireless was secured, assuming that if they were not underway there was no use for it. The use of the device for safety was not yet seen as the primary mission for the technology, and thus the service was not staffed to allow around-the-clock operation.
Captain Smith’s assumption that his ship was the finest technology afloat clearly left him unconcerned about the danger of transiting a known ice field at night.
• Disregarding or not believing valid information. Disregard for information that one does not expect to hear is a powerful factor in many accidents. In some circumstances, one can argue that this comes directly from the faulty assumptions and mindsets just described. But in cases such as Titanic and others, the volume of information and direct warnings that could have alerted Titanic’s captain and officers to danger and was ignored is hard to believe. This is an area where we can all improve—training ourselves to at least investigate the unbelievable before disregarding it. Investigation in this case might have been at least a reduction in speed in the specific area where icebergs were reported by more than one source. We saw this pattern of disregarding bad news in business situations like Intel, AmEx, and Kodak as well.
• Inadequate training and preparation. The lack of lifeboat drills for the passengers and crew clearly contributed to confusion and incompetence in loading and assignment of trained crew to operate and supervise the boats. This is the reason that most boats left with less than a full load of passengers. Reportedly, there were also initial attempts to segregate passengers by attempting to keep third-class passengers below decks. The officer of the deck apparently took the appropriate actions once “in extremis” (collision imminent) by turning, reversing engines, and shutting watertight doors, but this was a mere formality that did little to reduce damage given the ship’s speed.
• Poor decision-making conditioned by previous experience. Clearly Captain Smith and Bruce Ismay perceived little risk in the speed Titanic maintained. This decision was not one based on a rational analysis of the risks, but one made on the basis of past experience of always missing icebergs. Some have suggested that Smith’s past experience with many successful passages without incident conditioned him to believe in what pilots call the “big sky theory.” The belief is that it is a big ocean (or sky) with relatively few ships in it and thus the probability of a collision is very small. Of course, this ignores the fact that those operating ships between nearby ports make similar choices about their routes. Extension of this idea to icebergs might yield the thought that an iceberg is very small and it is a very big ocean. What is the probability that we will end up in the same place at the same time? Obviously, the probability was finite. Experience can have a perverse effect on decision-making. In some cases, those who have taken risks in the past without adverse effect perceive the risk to be smaller going forward and take ever-bigger risks.
The investigations following the Titanic disaster were front page news in both the United States and the United Kingdom. In the United States, a Senate committee held hearings for more than a month beginning four days after the sinking. In Britain Lord Mersey, the Wreck Commission headed the inquiry and conducted hearings through May and June 1912, resulting in recommendations for:
• Enough lifeboats to accommodate all on board
• Improved watertight compartments
• Wireless capability for all passenger ships with a 24-hour watch
• Staffing and training of boat crews with drills
• Prudent navigation in the vicinity of ice during night hours
• Regulation of lookouts
• Making failure to go to the aid of a vessel in distress a misdemeanor
• An international conference on standardizing these and other regulations
• Other branches of government that were criticized in the report for failing to keep regulations up-to-date with changing technology in the maritime industry
Interestingly, as in most disasters until recently, the inquiries focused on mechanical things and regulations that might fix problems. Other than the admonition for reducing speed and changing course in the presence of ice at night, there was little attention to judgment. It is, of course, impossible to legislate or regulate judgment. Requiring 24-hour manning of the wireless and making it a crime to fail to go to the aid of a ship in distress was a move to eliminate any need for judgment.
Even unmitigated disasters such as the Titanic can have small silver linings. There were numerous accounts of selfless acts of kindness and sacrifice toward others from strangers aboard Titanic, in the lifeboats, and aboard Carpathia after rescue.
One story that has endured is how the leadership of one Margaret “Molly” Brown of Denver in a lifeboat apparently earned her the famous nickname “The Unsinkable Molly Brown.” Molly Brown was the wife of a very successful gold mine owner in Colorado and was traveling in the first-class section of Titanic at a cost of $4,350 for the one-way passage, about the cost of today’s first-class airfare on the London-to-New York route (but obviously a great deal more in 1912 dollars). She reportedly helped other passengers to lifeboats before she was told to get into lifeboat #6, the first to be launched from the port side of the ship. It departed with only 24 persons on board a 65-person-capacity boat.
Once in the boat, with the ship’s quartermaster in charge, Molly Brown began to row with other women. An argument broke out, led by Molly Brown, about going back to seek other survivors. The quartermaster ultimately prevailed, and Carpathia rescued the group with the others later that morning. Once aboard Carpathia, Molly helped organize services to comfort others and, because of her language skills, provided interpretation services for some of the passengers. Additionally, “She compiled lists of survivors and arranged for information to be radioed to their families at her expense.... She rallied the first-class passengers to donate money to help less fortunate passengers. Before the Carpathia reached New York, $10,000 had been raised.”39
Our final note on the Titanic comes from Lawrence Beesley, a survivor who was encouraged to write a book about the accident within a few months of returning, while his memory was still fresh. While his description of the events is at times personal and touching, his final summary of the event and its causes is rather cold in its belief of the inevitability of such incidents. It is eerily applicable to a number of other situations nearly a century later:
“It is a blot on our civilization that these things are necessary from time to time, to arouse those responsible for the safety of human life from the lethargic selfishness which has governed them. The Titanic’s two thousand–odd passengers went aboard thinking they were on an absolutely safe ship, and all the time there were many people—designers, builders, experts, government officials—who knew there were insufficient boats on board, that the Titanic had no right to go fast in iceberg regions, who knew these things and took no steps and enacted no laws to prevent their happening. Not that they omitted to do these things deliberately, but were lulled into a state of selfish inaction from which it needed such a tragedy as this to arouse them.”40
Three Mile Island
It is hard to believe that it has been over 25 years—a quarter of a century—since Three Mile Island and “TMI” became well known parts of the lexicon. Airline flights into Philadelphia from the west descend over the area, and the Pennsylvania Turnpike runs nearby. Whether flying over or driving across the Susquehanna River, you cannot miss seeing four very large concrete stacks that are the natural draft cooling towers for Units 1 and 2 at the Three Mile Island nuclear power plant. Unit 1 still operates, so unless it is shut down for maintenance, you will see water vapor rising like smoke from a chimney from one or two of the cooling towers. But the other two towers are cold and have been for 25 years since the accident at Unit 2 made it America’s worst nuclear accident, resulting in a partial core meltdown and effectively stopping any consideration of expansion of the industry in the United States until recently.
The summary of the TMI disaster is straightforward and is one of the worst multiple-mistake scenarios ever seen. TMI Unit 2 was a new plant that had been on line producing electricity commercially for only about 90 days at the time of the accident. A malfunction in the non-nuclear part of the plant led to a chain of mechanical and human mistakes, some unnoticed and others initiated deliberately in fits of incompetence almost unparalleled in engineering history. There was significant physical disaster to the plant that was contained because of the ultimate safety measure—the design of the containment structure was sound.
The details are more complex but provide an extreme but enlightening example of the failure to manage multiple mistakes. Fortunately, one person finally broke the chain of mistakes by catching and stopping a serious ongoing mistake. Unfortunately, the plant was already “in extremis,” and while stopping the mistake at that point was crucial, the only result was to limit further damage. It was too late to stop the disaster from occurring.
“Turbine Trip—Reactor Trip” is a term that is familiar to nuclear plant operators and is the title of Chapter 1 of Volume 1 of the report41 produced in 1980 for the public to understand what happened at Three Mile Island. As an engineering officer of the watch overseeing the operation of a nuclear power plant, as I did as an officer in the U.S. Navy submarine force, hearing these or similar words* from one of the operators tells you instantly that you have a problem and that you are likely to be a while getting things straightened out. Even when training, with an instructor watching, you are nervous.
* Another common term used is “scram” to indicate a condition where the reactor control rods have been dropped on an emergency basis to shut down the reactor.
But hearing “turbine trip—reactor scram” unexpectedly in a real operating situation sends a quick chill through you. It starts adrenalin pumping, you start looking for status indicators, you start spouting memorized immediate responses, and you pull out the manual for verification. Your mind should go from trained reaction, for stabilization purposes, into problem analysis mode to understand what is really happening and to ensure appropriate continuing responses.
I am sure that the operators at TMI felt that chill up their spines when at 36 seconds past 4:00 AM on March 28, 1979, one of the feedwater pumps tripped (disconnected electrically). This stopped the supply of fresh water to the steam generators that produce the steam to drive the turbines to generate electricity. The turbine tripped as steam pressure decreased and eight seconds later the reactor automatically scrammed as the emergency systems worked, as designed, to prevent reactor damage. All of this was normal operation, with the exception of knowing why the feedwater pump tripped in the first place.
The type of reactor system at TMI is known as a pressurized water reactor (PWR). These systems were among the earliest commercial designs for nuclear reactors and are the type most widely used in the United States, although other types exist*. The U.S. Navy used PWRs exclusively in submarines (with the exception of one short-lived experiment) for a number of reasons related to safety and adaptability to their environment. The horrible accident at Chernobyl in 1986 was a reactor with an inherently less stable, less safe design that is not used elsewhere, other than the former Soviet Union and a few of her former allies in Eastern Europe.
* There are 103 operating nuclear reactors generating electricity commercially in the United States today. Of those, 69 are of the PWR type and 34 are what are called boiling water reactors (BWR). The BWR design is less complex but does not have the isolation of the primary and secondary systems that the PWR provides. There are ongoing debates about which design is most effective when considering safety, cost, and reliability.
The PWR, as shown here simplistically in Figure 5.2, is a complex design based on the fairly simple principle of heating water with nuclear fission in one loop (the primary loop) and transferring the heat to a secondary system (the secondary loop) that uses the heat to generate steam. Heat is transferred between the two loops, but the two fluids (reactor cooling water and steam generator feedwater) never physically come in contact with each other.
Figure 5.2. Simplified schematic of pressurized water reactor plant.

The primary loop in a PWR operates at a very high pressure (2,155psi* at TMI) to keep the hot water from boiling. This makes it easy to pump as a liquid to transfer heat to the steam generator where the steam is generated to drive the turbines.
* Atmospheric pressure on earth is 14.7psi (pounds per square inch), thus 2,155psi is 146 times atmospheric pressure. This is very high pressure and requires specially engineered systems to operate properly.
The size of a large commercial plant like those at TMI is staggering. At 850MW† (megawatts), each of these plants is many times the output of those used to power nuclear submarines when I was in the navy in the 1960s. The pipes in the primary loop are 36 inches in diameter and utilize four pumps driven by 3,600HP electric motors to circulate the hot water from the reactor core to the steam generators and back again.
† One megawatt (MW) is the ability to continuously generate heat that is the equivalent of a million watts. The two plants at TMI were together capable of providing enough power to supply 300,000 homes.
At TMI, the reactor vessel that holds the specially manufactured uranium fuel and the control rods was a cylindrical steel tank 40 feet high with 8 1/2-inch diameter walls. The control rods are made of materials that absorb (stop) the free flow of neutrons. When the rods are withdrawn from the reactor core‡, neutrons flow freely and strike enriched uranium atoms, causing them to split into other elements, releasing significant amounts of heat and more neutrons. The water carries the heat away for heating the secondary loop for steam generation.
‡ The rods are not completely withdrawn. They are withdrawn enough to allow the required neutron flow to take place for a self-sustaining chain reaction. Rod positions will change as a function of fuel hours used.
Using the steam to turn the turbines extracts energy from the steam and it begins to cool. It leaves the turbine and passes through a very large condenser, where it is cooled*. Once cooled back into water, the water is recirculated in the secondary loop and enters the steam generator to be turned into steam again.
* The condenser is cooled by water from an external source that does not come in direct contact with either the secondary or primary loop water. This coolant water is sprayed into the cooling towers, condensing and falling to a tank below to be recirculated through the condenser. Some waste is vaporized in the process, producing the characteristic white plume above the cooling towers. This water needs to be replenished in the system, which is why nuclear plants are usually located near a source of water like a river or ocean.
Following the feedwater pump trip just after 4:00 AM, the main steam turbine tripped, and in turn, the safety systems built into Unit 2 caused the reactor scram. The system worked as designed.
Since the heat being generated in the core was no longer being used to produce steam, the primary coolant (water) began to heat up†, causing the pressure in the loop to increase, which compressed the bubble in the pressurizer‡, increasing its pressure. When the pressure reached 2,250psi, or 100psi over the normal operating pressure, the PORV§ on the pressurizer opened, discharging steam into a drain tank located inside the containment building where it condensed into water (radioactive).
§ PORV is the pilot-operated relief valve that opens to relieve pressure in the primary loop if it gets too high.
‡ The pressurizer is a surge tank designed to keep pressure in the primary loop stable as temperature in the system changes. It operates with a steam bubble at the top to manage slight changes in volume of the water in the system. The pressurizer at TMI is large. Its 1,500 cubic feet are similar in volume to a 12’×15’×8’ bedroom.
† Even after being shut down, a reactor has residual heat from its large mass plus new heat generated from decaying radioactive elements, which is initially equivalent to about 6 percent power. It takes a few days to reach a point where there is so little heat generation that it can be safely removed by a small set of pumps and a heat exchanger called the “decay heat removal system.” This system must continue to run indefinitely for large reactors.
The PORV should have shut again as the pressure decreased, but it did not. The operators did not notice this problem for over two hours. During this time, steam that was the equivalent of 300 gallons per minute of water escaped. In the first 100 minutes of the accident, about 32,000 gallons of water, the equivalent of one third of the primary coolant system capacity, was lost and no one realized it.
Have you ever tried to have a conversation in your kitchen with your spouse or a friend while the TV on the kitchen counter blared the evening news, the TV in the nearby family room blasted a chorus from Sesame Street, the teenager in the room above was listening to music that vibrated the walls, the grandfather clock in the hall chimed seven times, the phone was ringing, and you failed to notice the pasta boiling over on the stove? Multiply that confusion by 100 times or more to imagine what the operators on watch in the control room at TMI saw and heard a little after 4:00 AM on March 28, 1979.
About 100 alarms were going off all over the control panels, with flashing lights, sirens, and horns all competing for the attention of Edward Frederick and Craig Faust, the two operators on duty in the TMI-2 control room. Available to assist them were Fred Scheimann, the TMI-2 shift foreman, and William Zewe, shift supervisor for both TMI-1 and 2.
Faust would later recall in testimony before the Nuclear Regulatory Commission (NRC), “I would have liked to have thrown away the alarm panel. It wasn’t giving us any useful information.”42 It was in this environment that the operators tried to figure out what was going on with the plant.
One thing was certain—things were not stable. Within 12 seconds, there had been a loss of feedwater, a turbine trip, the reactor scram, an expected rise in system pressure, and the PORV stuck open (unknown to the operators). Within the next two minutes, the primary system pressure had dropped nearly 25 percent from 2,155psi to 1,640psi.
The sequence was actually started by Scheimann and a crew who were working on the #7 condensate polisher* and using compressed air and water to try to break up a clog in the device. It is now believed that this process interfered with the automatic valve control system, causing the polisher valves to close, which shut off the flow of condensate that in turn caused the feedwater pumps to shut down when they received no flow.
* A device similar to, but more sophisticated than, a home water softener. It cleans the water in the secondary loop of chemicals and ions that might damage various system components. The polisher has to be cleaned periodically.
Later investigation would show that cleaning the polishers had been a persistent problem, compounded by the fact that the design did not allow for bypassing the system. This is a serious design flaw that was rectified with a full bypass system in other plants. While the polisher is needed, it was not urgent that it be in the loop 100 percent of the time. The designers obviously thought that if there were no bypass, this would ensure that the steam generator feedwater never had an undesirable level of impurities. This was the opposite of the Titanic designers building the watertight bulkheads to only 10 feet above the waterline to improve function but not safety. In this case, a design that had more to do with maintenance than safety ended up affecting safety adversely because it was too rigid.
In the control room, the plant initially responded as expected. After the scram, the pressure rose, the PORV opened briefly and then closed, or so the operators thought. In fact, the valve had stuck open, but the indicator light showed “closed.” This occurred because the indicator triggered the presence of electric power at the valve actuator, not whether or not the valve actually moved—another serious design flaw.
The operators got many signals that something was wrong, but unfortunately they became hopelessly confused and took dangerously incorrect actions that they thought would stabilize the situation. Their real impact was to prevent the system from saving itself.
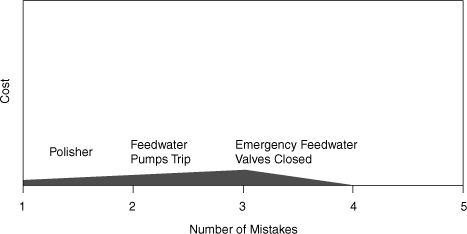
Even with the dangerous series of mechanical and human-related mistakes that occurred, TMI-2 would have safely tolerated at least the first three mistakes without serious damage. The TMI multiple-mistakes diagram would have looked like Figure 5.3, a minor incident that you would have never heard about. But it got worse for reasons that are both understandable and inexcusable. Not just inexcusable for the operators but for the designers, the operators, General Public Utilities (the owner), and the NRC.
Figure 5.3. What TMI should have been.
The alarms continued to sound, and there only two telephone lines in the control room to try to get help and advice. The supervisors in the plant came to the control room to help, and others were called in. The operators were adding water to the primary loop, as was expected when the reactor shut down and the coolant began to cool. The pressurized level was rising (apparently), but plant pressure was dropping faster. As the pressure dropped, the HPI* pumps came on, and the pressurizer level continued rising, even though plant pressure was lower than it should have been.
* High pressure injection pumps are designed to add large amounts of water to the primary coolant loop rapidly in an emergency.
It was at this point that the operators began to worry about another potential problem that all of us were scrupulously taught to avoid: “going solid.” This meant that the pressurizer bubble was collapsed, and every piece of pipe and attached devices was filled with water. The potential danger is that extreme pressure can be generated quickly if the plant is “solid.” This fear of accidentally taking the plant solid overrode any other thoughts the operators might have had about what was really going on, and they failed to focus on what other indicators were telling them.
In fact, the pressure had dropped while the pressurizer level (apparently) rose. Temperature had been rising but then leveled off. This is probably where the situation really became dangerous. The operators reduced the water injection and eventually shut it down completely because of their fear of going solid. About the same time, roughly five and a half minutes into the accident, the real damage began. The leveling of temperature probably indicated that the saturation† point had been reached, and the reactor was now a bubbling kettle producing steam bubbles inside that, if expanded, would uncover the core and damage the reactor.
† The temperature, for a given pressure, at which water will begin to boil, creating steam.
The reality is that TMI-2 was still losing coolant, but no one recognized it because it was happening through the open relief valve (PORV) that was still unnoticed. Shutting down the water injection system that was trying to automatically save the plant was a horrible mistake, brought on by the fear of another condition that could not have possibly existed under the circumstances. The sad irony is that if they had tried to purposely “go solid,” it might have saved the plant.
The symptoms were there though, and the fundamental issue that day was that the operators forgot that water boils if you reduce the pressure. The pressure in the plant dropped, and the water began to flash to steam, creating bubbles in the core, which prevented proper cooling and ultimately caused the damage that made the plant a physical memorial to the accident that we will see for a very long time.
The steam generators were also part of the emergency core cooling system (ECCS). In an emergency, a separate set of pumps called emergency feedwater pumps fed water to the steam generators to take the heat away from the primary coolant loop. The operators believed that the ECCS was working. At eight minutes into the accident, Ken Bryan, who had been asked to come over from Unit 1 to have the opportunity to see what went on following a reactor scram, walked into the control room. With a fresh set of eyes and a mind unencumbered by conflicting signals, he looked at the control panel and yelled out “The 12s are closed*.”43 Supervisor Zewe ordered the valves opened immediately.
* This refers to a set of valves in the emergency cooling system.
The emergency cooling system had not had an opportunity to cool the primary loop because the inlet valves for the steam generator were closed. It is still not clear how or why the valves were closed, but it is known that they were closed two days before the accident as part of a routine maintenance procedure. It is likely they were never reopened, a mistake that probably related to failing to use a checklist at the completion of the procedure and a failure by operators on a number of subsequent shifts to verify the status of the plant.
Only 20 minutes into the accident, a coolant drain tank was full and its rupture disk broke, a signal that the PORV was leaking. Radioactive water spilled to the floor of the containment vessel, and temperature and pressure in the building continued to increase for some time, another indication that the PORV was open and dumping into the containment building through the now open drain tank.
Throughout the accident, Zewe and others missed a continuous and consistent warning that could have stopped the whole scenario if it had been analyzed correctly in the first five minutes. Because of past problems with the PORV, the plant designers (Babcock & Wilcox [B&W]) had placed a remote controlled block valve in the line between the pressurizer and the PORV. This has to be used with care—no engineer ever wants to manually shut off a safety valve that is designed as the last resort to keep you from “going solid,” but it was there.
Additionally, a temperature sensor had been added downstream of the PORV in the pipe that carried the steam/water to the drain tank. If the temperature sensor was higher than the ambient temperature in the containment building, then it was likely that hot water from the pressurizer was passing through the pipe. It was a very strong signal about the status of the PORV. High temperature in this line was reported and known by Zewe and other operators over the entire course of the accident, but it was discounted because of the history of unreliability of the PORV itself.
Once again, the mind was conditioned by prior experience to not believe the indications of what was going on in the plant. This was no different than the captain of the Titanic ignoring multiple warnings of ice in the area. It is no different, other than in time frame, than Kodak ignoring signals that photography would shift toward digital. It began to leak out slowly and was ignored until it was too late.
By 6:00 AM, Brian Mehler arrived at work to relieve Bill Zewe as shift supervisor. After he had been there about 20 minutes, he looked at temperatures in different parts of the primary coolant system, noticed differences, and decided that there had to be a bubble in the system somewhere other than the pressurizer; otherwise, the temperatures would be more uniform. He also realized that the PORV must be leaking and ordered the blocking valve closed.
Finally! After more than two hours, someone had diagnosed the fundamental problem of inconsistent data that was telling the story all along. Significantly, it was someone who had been outside the operation at the onset of the incident who was able to take a fresh look and diagnose the problem.
Interestingly, the problem was diagnosed over the telephone at about the same time. Leland Rogers, the B&W site manager, had just learned about the accident and was being briefed on the accident over the phone at his home. One of the questions he asked was if the pressurized blocking valve was closed. Mehler had just walked in and ordered it closed, and when the operators checked, they told Rogers that it was closed.
The action of closing the PORV blocking valve was the most significant thing the team had done to stop the progress of the accident, but the challenge was not yet over. It is important to note that outside advice from other operators and technical advisors quickly zeroed in on the true problem. This is a dilemma that any of us could face. In the heat of straightening out a confusing situation, when is the right time to seek other advice and counsel? Will it be helpful or distracting?
There were so many ignored signals in the case of TMI-2 that listing them in one place illustrates the massive escalation of events from a straightforward operating anomaly to a serious case of failure to manage multiple mistakes:
• Failure to note the “12 valves” closed for a number of days, causing the steam generators to boil dry when the emergency occurred
• Failure to understand the PORV discharge pipe temperature indications
• Reducing and then shutting down the HPI (water injection system)
• Failure to understand that temperature leveling as pressure dropped was the saturation point
• Failure to see rising pressurizer levels with dropping pressure as inconsistent and requiring further analysis
• Ignoring the drain tank disk rupture as related to PORV status and coolant loss
• Shutting down the main coolant pumps that were cavitating*, fearing damage to the pumps or piping and not realizing steam was present
* Cavitate means the creation of bubbles in a fluid, usually because of reduced pressure.
• Ignoring readings of unexplained increased neutron density in the core, an indication that water was not present†
† Water is a natural “moderator,” slowing down neutrons. With the reactor shut down, water and the control rods prevent the reactor from starting.
The impact of the accident got worse. There were increasing radiation levels in the containment building caused by significant core damage and dumping radioactive water onto the floor through the open PORV.
The estimated radiation level inside the dome was 800 REM/hr‡, an extraordinary level and a definite sign that there was a loss of coolant and that the core was damaged. There were small airborne radiation releases outside the plant that were a result of the flow of overflow water between the containment building and an adjacent auxiliary building. This building was eventually isolated. The radiation release, while minimal, raised concern and unrest outside TMI about whether there would be a China Syndrome* meltdown.
* A movie about a reactor meltdown that was, ironically, in theatres at the time of the accident.
‡ REM is/was a standard measure of radiation received. For comparison, a standard chest x-ray might expose you to 750mrem (at that time; technology has since improved) or less than 1REM. As monitored by film badges, I received less than 800mrem of radiation in my entire five years in the Navy submarine force—less than I would have received from natural radiation if living in a brick house.
A hydrogen bubble did form in the reactor, and some of the hydrogen escaped into the containment building through the PORV, causing a small explosion that was contained. The “thud,” as it was called, was not diagnosed as an explosion until the next day, despite a rise in pressure in the containment building—another ignored signal. Debate went on for some time about whether the hydrogen bubble would collapse safely or explode.
The operators turned on and shut off the HPI pumps twice during the morning, finally leaving them on for a lengthy period between 8:26 AM and 10:30 AM. The core was probably partially uncovered from 5:15 AM until 10:30 AM. Later the operators decided to try to depressurize the plant in an attempt to start natural circulation cooling†, but in the process they uncovered the core again. The depressurization attempt went on until after 3:00 PM, but how long the core was uncovered is not known.
† A process that causes coolant water to circulate without pumps due to temperature differences.
There were many more blunders in public relations, government and regulatory processes, and emergency management. We will not pursue these further except to say they were a direct result of confusing, conflicting, and misunderstood information combined with a serious lack of preparedness and policies on the part of a variety of entities and agencies.
The pool of resources to deal with the aftermath was expanded in an effort to make sure that early mistakes of inexperience and lack of thought were not extended. In addition to the NRC and state and local governments, TMI became a learning and advisory experience for the nuclear industry. By Friday, March 30, two days after the accident, the president of the utility had worked with the industry to form an advisory committee to advise on the completion of the stabilization of the plant and ultimately the cleanup.
The bottom line on TMI was a damning report on the ability of humans to mess up a physical system that was designed to operate safely. However, the designers and regulators also came under sharp criticism for their lack of action on known problems in other plants and at TMI specifically.
Somewhere along the way, the industry that designed and delivered the systems, the operators who managed and ran them everyday, and the regulators who oversaw the situation all came to believe that things were going smoothly. Full speed ahead—don’t worry about icebergs, leaking PORVs, polishers that can’t be bypassed—the design is great and we’ve never had an accident, so everything must be OK.
The culture that tolerated small mistakes because the big picture had always worked out lost its curiosity, and operators who were able to do things by rote lost their ability to think and be analytic. How does this happen? Does it creep in because everything is going well and no one pushes the envelope? Is it from lack of rigor because real “worst-case” scenarios were never conceived or considered? Was it because operating nuclear plants is fundamentally different than operating other types of power-generating plants, and perhaps they should have been clustered with larger companies with more focused expertise?
It was a little of each of these, but it was fundamentally cultural. The lack of rigor in training, preparation, disaster preparedness, and even communications was significant. Multiple mistakes, not an accident, caused the TMI disaster, and the signs, signals, and lack of discipline were all there to be discovered for some time before it came apart. Learning seems to be very difficult here as in other situations we will explore.
The interesting thing about the Three Mile Island nuclear accident is that, although it occurred nearly 70 years after the Titanic and with unrelated technologies (with the exception that steam was being generated in both cases), the patterns and categories of mistakes are quite similar (see Figure 5.4). Of course, this reinforces the fact that a common element in most disaster scenarios, whether business or physical, is human intervention that is incompetent or inattentive. While systems can be improved with better design and more reliable components, man must continue to hone his analytic decision-making skills. Not only must we continue to learn, but until we develop “plug-compatible” brain dumps, each new generation must start learning from scratch but at a higher level. This makes understanding M3 in both substance and process more important than ever to accelerate learning about avoiding disasters. But most importantly, it is an organization’s culture that encourages, discourages, or is indifferent about rigorous learning and execution. Unless continuous learning is made part of the culture of an organization, from top to bottom, mediocrity will reign, and the probability of a disaster increases with time.
Figure 5.4. Multiple mistakes: The TMI result.

TMI-2 is owned by GPU (formerly General Public Utilities), which in the 1990s exited the generation business by selling off its plants to focus on transmission and delivery of power. In 2001, GPU merged with First Energy, which is the Ohio utility generally thought to be responsible for triggering the massive northeast blackout of August 2003. Some people in central Pennsylvania talk about the First Energy/GPU merger as a merger of equals because they can’t figure out which company had the worst culture around quality. GPU sold TMI-1, which still operates, to another utility but retains ownership of TMI-2 while it continues to be decontaminated and decommissioned.
NASA—Launch Unless Proven Unsafe
“NASA cannot afford financially or politically to lose another orbiter.”
—Elisabeth Paté-Cornell and Paul Fishbeck 199444
Anyone with access to news knows that the space shuttle Columbia, also known as STS-107, burned up on reentry into the atmosphere, scattering charred debris across north Texas and Louisiana, on February 1, 2003. This happened almost 41 years after the first manned venture into space by the Soviet Union’s Yuri Gagarin; his April 12, 1961 orbital flight lasted all of 108 minutes.
Mechanically, this disaster was due to a series of errors that caused a failure of the thermal protection system (TPS) on the space shuttle. TPS—the mechanism for safely dissipating the heat generated during high-velocity reentry into the Earth’s atmosphere from space without burning up—has been one of many serious scientific and engineering challenges that all space programs have faced.
When the reusable space shuttle was developed, NASA shifted away from the ablative heat shield used on earlier capsule-style vehicles. The older capsule shield was designed to burn up during reentry to protect the capsule and its occupants, and it was the reason for the fiery, but normal, reentry we were used to seeing. Instead a high-tech “tile” was developed as one of the elements of the TPS for the space shuttle. These tiles weigh only 10 percent as much as the older ablative material that would be required, are composed of approximately 10 percent silica and 90 percent air, are very effective insulators that resist heat transmission instead of being consumed by the heat, and are reusable. The individual tiles require very careful installation and inspection and, if damaged, must be replaced to maintain the integrity of the heat shield.
It turns out that the risk associated with a heat shield failure is extreme but not uniform over the entire vehicle. A 1990 study conducted at Stanford University by Elisabeth Paté-Cornell and Paul Fishbeck, published publicly in 1994 by NASA and paid for partially with NASA funds, estimated that 15 percent of the tiles are responsible for 85 percent of the tile-related risk on the space shuttle.45 This probabilistic risk assessment also looked, for the first time, at the role that management decisions and activities played in risk, albeit only for the tile subsystem. The analysis discussed operational management details that affected the quality of work, such as lack of enforcement of standard procedures for installation, lower pay of the important tile technicians as compared to other labor specialties, and a lack of priorities when it came to installation and maintenance of the tile subsystem.
This 1990 study was eerily prescient of Columbia’s 2003 experience, discussing all the dangers and risks of mismanagement of the tile subsystem but especially faulting higher-level management decision-making at NASA. The authors point out that there was such pressure to produce results after the introduction of the space shuttles that NASA shifted from a “launch if proven safe” attitude to a clearly communicated “launch unless proven unsafe” mindset.
This was a very significant shift in priorities that became interpreted over time as, “We’ve got to find a way to launch.” When that begins to happen—in any business or organization, not just NASA—subtle signals ripple through an organization that change priorities, practices, and mindsets in ways that may not have been intended and are likely to be dangerous. This sounds strangely similar to the mindset that pervaded operations for the White Star Line and Titanic.
NASA actually forbade overall probabilistic risk assessment of flights dating back before the space shuttle program began. This resulted from an assessment prior to the Apollo manned moon mission that showed a relatively low probability of success. NASA’s fear of scaring the public about the mission led them to simply ban such total assessments. Instead they focused on analysis of individual subsystems and projections of mean time between failure (MTBF) for components that, while individually and directionally correct, do not adequately look at total risk for the overall system.
The National Aeronautics and Space Administration (NASA) was formed in 1958. The 1961 “We can go to the moon” challenge by President Kennedy resulted in massive funding, growth, and success for NASA. The first serious accident was in 1967; during a launch pad test, three astronauts were killed in a fire aboard the Apollo-1 capsule. The success of manned space flight programs, the moon landings, and the praiseworthy management and outcome of the Apollo 13 crisis created a “can do” culture at NASA—until Challenger in 1986.
The public began to believe, as NASA hoped they would, that spaceflight was safe and almost routine. The shuttle missions were being opened up to persons from all walks of life, and a schoolteacher, Christa McAuliffe, was onboard as the world saw Challenger explode due to the failure of O-rings used as seals in a solid rocket motor joint. The reason for the technical failure was soon clear, but the analysis and decision to launch under cold-weather conditions known to increase risk for the O-rings was fundamentally a chain of managerial and cultural mistakes:
• The O-rings were known to be vulnerable to failure at low temperatures.
• The launch team and engineers knew the temperatures were below limits.
• The team, in consultation with contractors, debated the problem but decided to launch.
• NASA senior management was unaware of the debate.
• In general, NASA was found to be an organization that had become more willing to accept higher risks and afforded the safety organization (within NASA) little clout.
This was clearly a chain of mistakes that was driven by a culture that wanted to prove that “everything is nominal,” “all systems are go,” and “it’s as safe as getting on an airplane.” With the most complex system ever built by man, NASA, its contractors, and the public had become complacent, and the Challenger disaster in 1986 was the price paid for cultural complacency.
Many changes were made as a result of the Rogers Commission that investigated the Challenger disaster, including the establishment of a more powerful safety office reporting directly to the NASA administrator. A variety of other changes were recommended, including some technical issues, launch review procedures, and importantly, recommendations for changes in the management culture at NASA. Many of these changes were implemented, and in a little less than three years space shuttles were being launched again.
Unfortunately, the changes in attitudes and safety systems did not last. Columbia was not lost to a failed O-ring as Challenger was, but it was lost to something far worse—a recurrence of a flawed cultural attitude toward risk that had been previously discovered, supposedly corrected, and reoccurred with a vengeance. The Columbia Accident Investigation Board said in its August 2003 report:
“By the eve of the Columbia accident, institutional practices that were in effect at the time of the Challenger accident—such as inadequate concern over deviations from expected performance, a silent safety program, and schedule pressure—had returned to NASA.”46
The loss of Columbia is well known and fresh in the minds of millions who followed it on live television or through the endless replays following the disaster. The series of mistakes that led to this stomach-turning disaster unfolded over the entire 17-day mission but really began much earlier with the culture that allowed an analysis of the importance of the tiles to be largely ignored for over 10 years. The short-term, mission-specific mistake chain evolved as follows:47
• The day after Columbia’s liftoff, a routine analysis by the Intercenter Photo Working Group* of higher-resolution images that had been developed overnight following the launch showed a debris strike to the orbiter at 81.9 seconds into the flight. A large object (suspected to be foam insulation from the external fuel tank) struck the orbiter on the underside of the left wing.
* An internal NASA organization that reviewed images.
• Concern about possible damage led personnel in the Photo Group to request that their superiors in NASA ask the Department of Defense (DOD) to obtain very high-resolution images of the shuttle while on-orbit (NASA terminology). This was the first of three such specific requests over a period of days; NASA management denied all of the requests.
• The Photo Group assembled a report and video clips that it sent to various groups within NASA and contractors with major shuttle responsibility. NASA engineers and contractors formed a “Debris Assessment Team” to conduct a formal review and met for the first time on day five (January 21) of the mission. This group also requested (through a number of layers of bureaucracy) that NASA request DOD assistance with imaging. This became the second denied request.
• Without images, the engineering team went to mathematical modeling as a tool for assessing potential damage and risk. They concluded over a six-day period that some localized heating damage was likely but could not state with certainty that this would lead to structural damage.
• Results and impressions from the Debris Assessment Team were passed along to the Mission Evaluation Room and then to the Mission Management Team as a verbal summary without data. This group decided the issue was a “turnaround” issue, meaning that it was classified as a small problem that should be checked after the shuttle landed and before its next flight. Note that on day eight of the mission, mission control e-mailed the shuttle crew that the foam strike situation had been reviewed and there was, “...absolutely no concern for entry.”48
• Engineers across NASA and mission control continued to exchange numerous e-mails expressing concern and speculating on possible events even after the decision had been made that this was a turnaround issue.
• Mission control, including specialist teams such as the Entry Flight Control Team, exhibited no concern about “de-orbit,” and by 8:10 AM on February 1, the Mission Control Center Entry Flight Director had polled all in mission control for a GO/NOGO decision and informed the Columbia crew they were “GO for de-orbit burn.”
The mistakes had all been made; a chain that started culturally a decade or more before could no longer be broken. It culminated as a group of engineers, who had doubts about the decisions their superiors had made, watched with the rest of us as Columbia burned up on reentry. As civilian, military, and police personnel began to find pieces of the wreckage across the countryside of northeast Texas and northwest Louisiana, people across the world showed deep respect for the astronauts on the most multinational and multicultural mission in history.
Respect for the bravery and sacrifice of the crew was countered with questions about the cause. Questions about the strike damage, the tiles, and NASA’s decision-making were on the table quickly. In terms of making progress against stamping out mistakes, it is unfortunate that the investigation could not have been completed in a week. Over time, the public emotion about a tragedy like this subsides, and we revert back to Perrow’s “normal accident” hypothesis and just accept that bad things sometimes happen when engaged in risky endeavors.
We should not kid ourselves. NASA has proven repeatedly that it cannot fix itself. Neither Challenger nor Columbia was an “accident;” they were the predictable outcome of management complacency and incompetence. In fact, it turns out that foam loss occurred on 80 percent of the 79 flights where imagery was available to determine if this occurred. This was once again a case of, “We’ve never hit an iceberg before—full speed ahead,” only this time it was foam icebergs coming off the fuel tank in a space launch. Complacency created by a lack of damage from similar occurrences in the past led NASA management to believe that this was an innocuous deficiency that should be tolerated and ignored. Once the organization saw the anomaly as “normal,” it led not only to disregarding information, but to blatant disregard for the opinions of those who were analytic and courageous enough to raise questions. The patterns of mistakes repeat over and over from different contexts, and we do not “connect the dots” and learn.
NASA’s engineering accomplishments have been extraordinary, but engineers know there are limitations; arrogant managers dismissed limitations as impediments to accomplishing the mission. Cultural problems that run this deep are not fixed with minor changes.
NASA announced some significant changes in operations leadership in July 2003, but only, apparently, in response to pressure from those who provide the funding—the United States Congress. Nothing short of dismantling NASA’s management structure is likely to fix a cultural problem this deep.
As this is written, NASA’s independent “Return To Flight Task Group” is working. Their charge is to assess NASA’s progress on implementation of both the specific and general recommendations in the Columbia Accident Investigation Board’s report. Their charge is not to determine whether the space shuttle system is too complex, unsafe, or unmanageable to return to flight; NASA seems to have already decided that: “Everything is GO.”
Common Cultural Issues
NASA, the operators of space shuttles Challenger and Columbia, and White Star Line, the operators of Titanic, had some common characteristics as organizations. Both built a number of identical vessels for transportation in relatively new ways, one whose passengers and crew existed in spartan functionality and the other with the most opulent appointments money and craftsmanship could provide.
Neither was the first in their realm, but both pioneered new designs. Both began with much excitement and public acclaim and ended in tragedy. Both organizations were respected for their accomplishments and discredited for their arrogance, flawed operating decisions, and complacency.
Sadly, following their brushes with disaster, organizational culture was identified as a significant contributor to their errors and affected the viability of White Star, General Public Utilities (TMI’s owner), and NASA. White Star ended up being acquired by another line. NASA will fight for more missions deserving of congressional appropriations, and GPU left the business of owning power generation plants, with the exception of TMI-2. Who would buy it?
Insights
History leaves us with interesting legacies, one of which is a visceral reaction to events with the mere mention of a name that has come to stand for tragedy, human suffering, or victory. In the United States, words such as “Gettysburg,” “Iwo Jima,” “9/11,” and “Normandy” that were once only words evoke meaning, memory, and emotion instantly—even for those who were not present. “Three Mile Island,” “Titanic,” “Challenger,” and “Columbia” are also words that now instantly communicate fear, suffering, loss, and empathy. For those who understand what really happened, there is another reaction—incredulity that these things could have happened at all. But if the chain of mistakes had been broken, those words would still just be words with no message to telegraph to anyone.
Insight #23: Test and retest assumptions—until proven beyond a doubt. Assumptions are at the core of mistakes in physical systems and business. The problem is that we often make assumptions and draw what we think are conclusions on the basis of limited data, and then if nothing bad happens, we begin to view the assumptions as truth. Titanic was assumed to be unsinkable. TMI was assumed to be fail-safe under all conditions.
NASA assumed that since foam had been coming off the center fuel tank for more than 100 launches and had never caused any serious damage, that it could not cause serious damage. Yet in the investigation of the Columbia accident, it did not take long to show that a piece of foam moving at over 500mph relative to the shuttle wing could do enough damage to bring the shuttle down, but only if it hit in just the right place. This is the problem with assumptions, they are just that, and they have limitations that we may not realize. Once we believe them, we closed doors of understanding, killing curiosity and analysis.
Insight #24: Push or ignore engineered safety at your peril. Engineers and designers who build systems of all types build in features designed to enhance the capability of the system to perform the intended function, but they also include features to minimize the chance of damage in the event of partial or full failure. This is true for physical systems from airplanes to zoos and also is important in today’s more complicated business world where “systems” include complex human—software—process systems in a wide range of businesses. Do airline reservation systems, manufacturing control and supply chain systems, credit card billing systems, and billing and receivable systems for most businesses have anything in common with physical disasters? The same opportunity to damage a business is there because of the complexity of the design and operations interface of man and machine.
Although designers try to anticipate adverse conditions that threaten the success of the system, they will not always successfully design for every circumstance, and even if they do, human intervention can often overcome the most rigorous safety design. Understanding that built-in safety features are there for a reason should be a cause for understanding limits. Pushing such systems to their limits or ignoring threats that test or evade safety systems should be undertaken only with the greatest care and understanding of the extreme risk involved. Titanic, TMI, Challenger, and Columbia all pushed engineering limits and lost.
Insight #25: Believe the data. “Believe your indications” is something all of us in the nuclear navy learned. Failure to believe information that is staring you in the face is one of the most common causes of catastrophes. In Titanic, TMI, and at NASA, operators had warnings of danger and did not heed them. In the case of Titanic the warnings were well in advance and could have easily been acted if minds had been receptive. At TMI, damage could have been minimized if warnings that were part of the recovery process had been observed. With NASA, the warnings were repeatedly offered in advance and were analytically sound, but they were dismissed just as routinely as the captain of Titanic ignored the warnings he received.
Insight #26: Use available resources. Captain Smith of Titanic ignored available resources, other than consulting the ship’s designer after the collision, who told him exactly how long it would take the ship to go down. When it was clear the ship would sink, Smith began to seek rescue help.
At TMI, it was two hours before the team on watch seriously sought outside help, apparently believing mistakenly until then that they could handle the situation. Some of the help literally wandered in the door as the next shift reported for work. Others, such as the B&W representative, were sought out, and still others, such as the NRC and Pennsylvania government and regulatory officials, were required notifications.
NASA engineers repeatedly asked their superiors to use DOD capabilities to get close images of Columbia on-orbit and were denied. The debate will go on forever about whether anything could have been done to save the crew, but the opportunity was missed, not once but repeatedly.
Insight #27: Train for the “can’t happen” scenario. Those involved with Titanic, Columbia, and TMI all thought many things could not happen or at worst were very remote. This mindset is obviously dangerous, but so is an overly conservative “If I don’t go outside the sky can’t fall on me” attitude. You obviously train for known situations in operating any device from a car to the space shuttle. But thinking about how you would handle something “they” say “can’t happen” may be more important than an idle intellectual game.
Insight #28: Open your mind past your blinders. This is extremely difficult. How do you know that your response has been conditioned by the context of your experiences? Perhaps the only defense is to play “what if” games with yourself and your colleagues. Regardless of the business or physical context, these are useful exercises. If you find yourself in a confusing situation, perhaps the proper question when you have exhausted all avenues is, “What’s the other right answer?”* This question often opens the mind to looking at whether there is another answer by discarding what you have already thought about without success.
* This concept is a good one in many contexts, but I first came across it in Roger von Oech’s book A Whack on the Side of the Head published in 1983.
A Note on Big Ships, Big Planes, and Nuclear Power
In the steam age of the late nineteenth century, businessmen pushed for larger ships that could carry more passengers. Safety became a primary concern only when some major disasters, including Titanic, changed public opinion and governments demanded reforms through law and regulation. Construction and materials improved, operators complied with new regulations, crews learned, and eventually commerce at sea became relatively safe. There are still disasters at sea, and most of them are man-made, but they are rare by comparison. Man is capable of learning and operating complex systems, but there is, unfortunately, a cycle of learning that is punctuated by the school of hard knocks.
As aviation (and railroads for that matter) evolved, it went through the same technological and operator learning cycles. Man learned to do what he could do with the technology of the time, but accident rates were high. The technology improved dramatically as the jet age came along and safety improved somewhat, but there were still accidents that should not have happened. The operator learning was not complete.
Now Airbus is building the A380 that may eventually carry up to 800 passengers. Have our systems and operations evolved to a point where the safety level will be high enough to please society? I suspect for the 380 and as with the 747, we will see a very low accident rate. The good news is that technological learning, operational learning, systems learning, and attitudes have converged to improve the probability of success at levels that we will find acceptable with minimal shock.
What about the nuclear power industry—was TMI a sufficient learning experience? Yes and no. We clearly learned that systems can be designed to save the operators and other stakeholders from dangerous conditions and damage, but they have to be allowed to work. Inadequate training and certification, lax management and regulatory oversight, overly complex sensing, and control systems that provide data but fail to provide useful information all contributed to operator confusion and error that ultimately caused the TMI disaster. The interference and failure to act properly by humans at TMI literally set the nuclear power industry back a quarter century or more in the United States.
The U.S. Navy has proven that similar plants can be operated safely under even more challenging conditions but only with extreme attention to education, detail, discipline, and process. This lesson seemed lost in the public debate that raged after TMI. The technology at TMI worked—just barely. It did not save the plant, but it did not result in any external damage, despite all the incompetent and unintended efforts of people to overcome the built in safety features.
As people, we seem willing to trust technology to help us, but we back away from it when we witness human misuse of that technology, often inappropriately blaming the technology for the outcome. We have allowed those who believe we are incapable of learning to shut down the nuclear power industry that may be more important to our future than ever. We all consume increasing amounts of electricity but do not want to hear that nuclear power generates it. We want to hear that our required power growth is coming from some as-yet-unknown completely clean power source. Over 20 percent of U.S. electricity comes from nuclear sources now, but that will decrease over time as plants age and are taken offline, increasing other environmental problems if we do nothing.
Titanic, TMI, and Columbia/Challenger have extraordinary parallels because all involved unfortunate learning about the human role in evolving technologies. All were wakeup calls for improving not only technology and systems but also the training, education, and cultural norms that inform or destroy effective decision-making. We must come to see TMI, Columbia, and other disasters as the wakeup call that Titanic was—a call for improvement of the way we use technologies rather than the death knell for something that can benefit society.
Business Parallels
As we have seen in case after case, business does not do a good job of analyzing, understanding, and preventing management errors. Those responsible for operating physical systems that have the potential to inflict damage on others do this in a more disciplined fashion but do not always learn what they should.
Business has much to learn from the process of analyzing physical accidents and much more than is acknowledged to learn from the specific findings of physical accidents. People are involved, so the patterns of mistakes are similar. We have repeatedly seen patterns that apply to physical operations and managerial decision-making:
• Failure to believe and act on information
• Decision bias induced by history, culture, or desired outcomes
• Taking shortcuts and/or bypassing proven procedures
• Failure to use other resources that might be able to help
• Absence of impetus for change until there is a major error
• Failure to fully evaluate possible scenarios and consequences of actions
• Failure to analyze decisions and learn from the findings
One of my overriding beliefs, only partially tongue-in-cheek, is
“The world is incompetent.”
Those who know me have seen the sign in my office with the preceding saying and have heard me use this in talks since the mid-1970s, and I say it only half jokingly. Examples covered in this chapter prove again that if there is a way to mess things up, someone will usually find it.
Countering these examples are companies who have taken visible proactive actions that are effectively the opposite of the error-inducing behaviors of the preceding companies. That is not to say that the following companies listed do not make errors; they just seem less prone to error chains that become serious, or they have broken a chain that was on the verge of becoming very serious, regardless of the initiating incident source. There are certainly others that exhibit the same effective behaviors and processes but are not as visible. Examples include:
• Johnson & Johnson’s 70 years of sustained growth in changing markets and technologies
• Microsoft changing position on Internet strategy (despite mistakes in other areas)
• Southwest Airlines and Dell redefining the playing field in commoditized industries
• Toyota’s Lexus and U.S.-based manufacturing for Camry and other models
• Verizon for quickly building the leading U.S. wireless company as a joint venture
• Emerson Electric as one of the most consistently performing “invisible” businesses
• IBM and their dramatic recognition of and delivery on the need for change
• Hundreds of other companies that are delivering results and do not make the front pages
We will explore some of these examples in later chapters, but it is important to understand that we can learn a great deal from the companies and management teams that have made mistakes. It is just as important to understand that, although these examples are abundant, they do not represent the entire universe of businesses.