
Chapter 11. Content Model Depth Issues and Their Impact on Round-Tripping XML
InDesign is a shallow content model when it comes to text and images on a page. There are no built-in XML tags for titles, lists, extracts, figure captions, and other element. So any XML structure that you create for text has to be modeled in an InDesign template or imported as a DTD to create tag names in the Tags panel.
Even more limiting is that there is no concept of text divisions such as chapter, sections, sidebars, notes, and so on. From an InDesign point of view, everything is a paragraph or a run of styled text within a paragraph; it wouldn’t make sense to “nest” a paragraph inside a paragraph. All of the deep structure of XML is superfluous to InDesign’s tasks of making nice-looking text on a page.
Despite these limitations, many people are trying to read and write complex XML within InDesign.
The Challenge of Mapping Deep DTDs to Shallow InDesign Structures
It is possible to transform the deep content structures of DocBook
or DITA XML to paragraph and character styles. See Upcasting Versus Downcasting and Downcasting to HTML for explanations of the downcasting
process used to flatten XML structure. The challenge here is the
proliferation of styles required for enabling the upcasting that will be
performed later. For example: in the XML, there may be an element called
title at many different levels in the structure. In
InDesign, you want the title to be styled according to its relative
position in the hierarchy, its context. If it is the title of a <chapter>, then you want it to become a
paragraph styled as “CH-T”. If it is the title of a first-level <sect1> element, you want it to become a
paragraph styled as “Sect1-T”. If it is the title of a <glossary>, then you want it to become a
paragraph styled as “GLS-T”, and so on. So you have a one-to-many
relationship from the <title>
element to the InDesign content, for which you can use XSLT to apply the
required aid: namespace to generate the
styles on the XML, according to the context of the <title> in the XML structure. (See The Special Case of InDesign Tables (Namespaced XML) for a description of
the aid: namespace.)
Note
To use the aid: namespace when
validating in your XML in InDesign, you must add it to the DTD.
Generally this means that the namespaced attribute must be added to all
the elements that you need to map to styles in InDesign. See the section
“4.4. Namespaces and DTDs” in XML in a
Nutshell, 2nd ed. (O’Reilly, 2002) for a
discussion.
You can use the InDesign DTD itself for developing a flattened
form of XML instead of adding support for the aid: namespace to an existing DTD. The
InDesign DTDs are in the InDesign Developer’s SDK, which is available
from Adobe.
For XSLT developers: An XSLT for inserting the
styles can be written with a set of templates for <chapter>, <sect1>, and <glossary> that adds the aid:pstyle with the desired paragraph style to the title. A more
robust approach is to write a template for the <title> element that is called
within the templates for <chapter>, <sect1>, and <glossary> using
xsl:apply-templates, that passes the context of the
<title> to an xsl:choose statement. The result should be
<title aid:pstyle="CH-T">,
<title aid:pstyle="Sect1-T">,
<title aid:pstyle="GLS-T">, and
so on.
The Challenge of Mapping Shallow Structures to Deep DTD Structures
When you have the same element with different aid:pstyle values, you can use the logic of the
aid:pstyle during upcasting to restore
a deeper structure from a flat InDesign structure. It is not foolproof and
takes some care in naming the styles. You would export the InDesign XML
that has the aid: namespace attributes
and transform it with XSLT with logic that creates the “container”
elements required. For example, based on the exported InDesign XML having
a <title aid:pstyle="CH-T">, you
first generate the wrapper element <chapter> and then within it generate the
<title> element. Similarly, you generate the <sect1> containing a <title> from the <title aid:pstyle="Sect1-T">.
The inherent problem in this approach is the content editing that
may go on after the XML is inside InDesign. If a new set of elements is
created after the initial XML import, those new elements won’t
automatically take on the styles in InDesign, because it is during the
import process that InDesign uses the aid: namespace. So the new content needs to have
both XML structure markup and InDesign styles applied when it is created
in InDesign. Then the correct aid:
attribute values must be added to the new XML elements so that when the
XML is exported, those elements will have the “hook” to restore the deeper
XML content structure.
It will be extremely important that the people working on the
InDesign files containing the XML understand these issues and how to
maintain the aid: attribute values for
each element according to where it is used.
An alternate approach is to have elaborate InDesign scripts that run
on the XML and check the style name and apply the necessary aid: namespace attribute values for any XML
elements that don’t have them before the XML is exported from InDesign.
These scripts can use a mapping logic to check where the new element has
been inserted and what style has been applied to it and then create the
aid: attribute as needed. This level of
programming will require an experienced InDesign developer with knowledge
of both the InDesign SDK and XML.
Use of Semantic ids and Style Names (Expert-Level Development)
An improvement over the use of the aid: namespace alone is to use both an id value and a styling attribute value in the
XML to help with a parallel upcasting and downcasting scenario
(round-tripping). For example, in DITA XML, you can have an id on most
elements, and you can have an outputclass attribute. You can develop a
systematic use of the combination of the id and the outputclass naming conventions to help keep
track of the XML content going in and out of InDesign.
An example is having a title element whose id includes some type of “context” information and the desired InDesign styling
such as <title id="ch01"
outputclass="CH-T">, <title
id="ch01-sect1-01" outputclass="Sect1-T">, and <title id="ch01-glossary-01"
outputclass="GLS-T">. During downcasting, the ids are copied onto the XML elements that will
be placed in InDesign, and the outputclass attribute values are used to
generate the aid: namespace attribute
values. This approach keeps more of the context for the future downcasting
as long as the id values are never
changed. During downcasting, the original XML file can be used
as an input, compared to the exported XML. If a matching id value is found, then the exported XML is
processed to put it into the same XML structure as the original XML. A set
of templates will be required in the XSLT to handle unmatched content, but
if the id values have been maintained
during import and export, it will be possible to reconstruct the majority
of the deeper XML structure.
The same concept can be used with DocBook XML files. Note how the
id and aid: values are carried over from DocBook to
InDesign in the examples in Figure 11-1.

Note
In Figure 11-1, I
made use of DocBook’s role attribute
to insert the aid: namespace values.
If the role attribute is needed for
other functions in the DocBook content, then it may be best to add
support for the aid: namespace
attributes directly to the DocBook DTD.
The aid: namespace attribute
values must match the InDesign style names and the InDesign template must
be set up for the XML tags for the styling to be applied when the XML is
placed in the layout.
A fully developed DocBook XML file, InDesign template, and XSLT
would use an id on every paragraph (and
conceivably on every inline element), whose value could be made unique by
using the generate-id() function. In
the example in Figure 11-2, more semantic names
assist the reader of this book to follow the relationship between the
DocBook and InDesign XML. The InDesign template in Figure 11-2 has a unique
paragraph style for each of the different title types.

Each of the example text paragraphs are tagged with either a
<title> or <para> from the simple Tags menu. The “Map
Tags to Styles” feature of InDesign is not used
because there is not a 1:1 relationship between the tag names and style
names. There are multiple styles that are based on the <title> tag. The Story Editor view of the
InDesign template shows that each paragraph has been tagged and styled
(Figure 11-3).

If the InDesign template is exported as an IDML file, there is a list of all the styles inside the IDML; see A Brief Note about IDML and ICML. This style list can be used to get the name of every style the template designer has used so that a developer can extract the paragraph and character style names to create a style configuration file.
For example, by looking at the Styles.xml file (found in the IDML archive file for the sample InDesign template), the developer can find these style names:
<RootCharacterStyleGroup Self="u77">
<CharacterStyle Self="CharacterStyle/$ID/[No character style]"
Imported="false" Name="$ID/[No character style]" />
<CharacterStyle Self="CharacterStyle/italic" Imported="false"
KeyboardShortcut="0 0" Name="italic"
FontStyle="Italic">
<!-- some code omitted for brevity -->
</CharacterStyle>
</RootCharacterStyleGroup>
<RootParagraphStyleGroup Self="u76">
<ParagraphStyle Self="ParagraphStyle/BK-T" Name="BK-T" Imported="false"
NextStyle="ParagraphStyle/BK-T" KeyboardShortcut="0 0"
PointSize="36" Hyphenation="false" SpaceBefore="72"
SpaceAfter="24" Justification="CenterAlign">
<!-- some code omitted for brevity -->
</ParagraphStyle>
<ParagraphStyle Self="ParagraphStyle/PRFC-T" Name="PRFC-T"
Imported="false"
NextStyle="ParagraphStyle/$ID/NormalParagraphStyle"
KeyboardShortcut="0 0" FontStyle="Italic"
PointSize="18" Hyphenation="false"
StartParagraph="NextColumn">
...Using the list of styles from the IDML, and a sample of the layout to show how the styles are used, a developer can set up the appropriate values for each element.
After the XML with the aid:
namespace attributes is imported, any matching style names will affect the
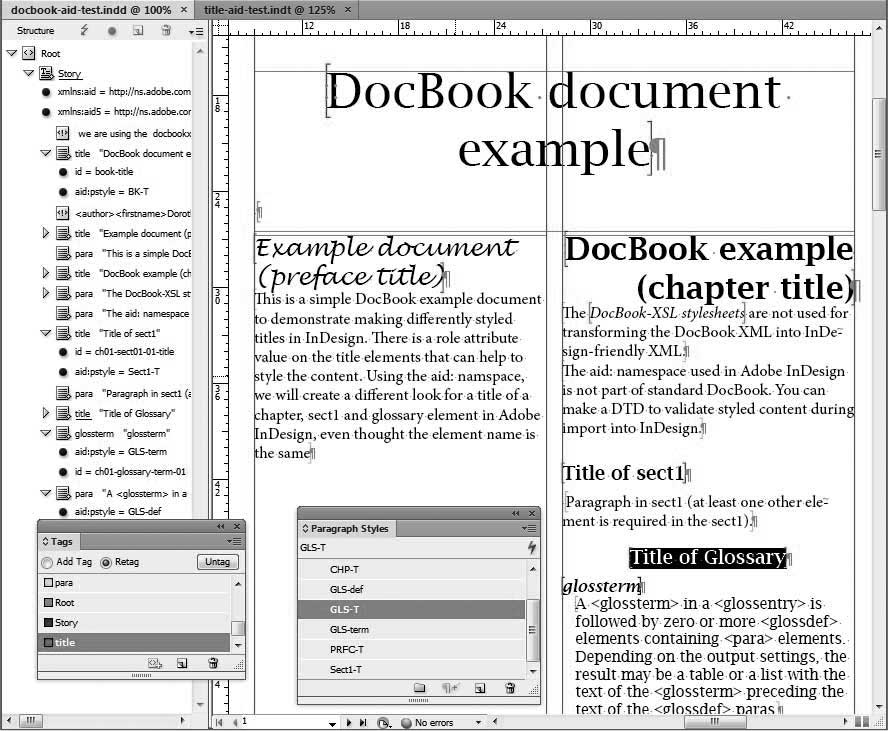
appearance of the text when it is placed in the layout (Figure 11-4). Notice how the
<title> element with the aid:pstyle "GLS-T" has been formatted as
centered and bold, while the title of the preface is formatted as a script
font.
If there are multiple text flows to create from a single XML file,
then the built-in <Root> element
can have multiple child <Story>
elements, each with its own id. Each
story-level element can be dragged onto a different text flow in the
layout.
As previously mentioned, the id
values of all XML elements are particularly important to any kind of
round-tripping that might occur. Style names alone won’t provide enough
data for the XSLT to reconstruct the original DocBook structure.
After the DocBook structure is re-established, you can use an XML comparison tool such as that built into Oxygen XML or another XML IDE to check the results.
This discussion just scratches the surface of what real round-tripping for DocBook, DITA, or other complex DTD may require. But the essential concepts here can provide the basis for a systematic downcast/upcast that will provide a good deal of a round-trip process.
Note
Developers should note that footnotes, cross-reference links, image metadata, and other common parts of complex XML DTDs are very difficult to create and manage in a round-trip scenario.