
Chapter 6. XPath 2.0
Even when the W3C promulgates a spec in its final Recommendation form, the spec does not become fixed in stone.[1] Any product expressed in human language always requires further tweaking — filling gaps, fixing ambiguities, and making room for new developments in related specs and technologies. This is the case with the next, still-upcoming version of XPath: Version 2.0.
The XPath 2.0 spec, as of late 2001, still exists in a very tentative state. Not only is it a Working Draft (one of the very first rungs a spec must negotiate on its way up the ladder to full Recommendation status). It’s not yet a specification of syntax, but rather a simple statement of requirements. All you’ll learn from perusing the XPath 2.0 documentation at this point is what XPath 2.0 may ultimately permit you to accomplish — not the specific means you will use to accomplish those ends.
The XPath 2.0 Requirements document explored in this chapter was issued in February, 2001. You can find it on the W3C web site, at http://www.w3.org/TR/xpath20req.
Tip
In December 2001, the W3C finally published a Working Draft of the XPath 2.0 spec. In April 2002, this December WD was followed up by another version. This chapter will make occasional reference to this version of the WD as well as the Requirements document.
General Goals
The XML 1.0 Recommendation implicitly established something of a precedent for future XML-related standards, particularly in its opening statement of 10 “design principles” from which all the individual details flowed. Likewise, the XPath 2.0 Requirements document (which I’ll hereafter most often refer to as “XPath 2.0”) states eight general goals it hopes to accomplish. The general goals are distinct from the five general requirements XPath 2.0 lays out in some detail. I’ll discuss each of the former briefly, then in the next section, break down the latter.
Warning
Be aware that I’m not a member of the joint Working Group preparing the standard and not privy to their confidential discussions; what follows in this section, therefore, is at best informed interpretation of publicly available documents.
Simplify Manipulation of XML Schema-Typed Content
Well before the W3C’s XML Schema standard acquired Recommendation status, it loomed large in the thinking of other W3C Working Groups preparing — or even having finished — specs of their own.
That’s what this general XPath 2.0 goal shoots for: reconciling, in XPath 2.0, the existence of XPath 1.0 with the existence of XML Schema 1.0. For instance, it might be useful for XPath 2.0 processors to locate all of a Schema-based document’s dates or integers, ignoring the floating-point values and string-values.
Simplify Manipulation of String Content
XPath 1.0 provides a core set of string-handling features — particularly the string functions. But users coming to XPath from other computing languages are occasionally often frustrated by the things you can’t do with strings.
For example, the translate( ) function provides
easy one-for-one character substitution. What it
doesn’t provide is the ability to substitute, say, a
multicharacter string for a given single character (or for a given
pair of characters, or whatever).
Support Related XML Standards
Aside from XML Schema, XPath 2.0 also needs to take into consideration the requirements of certain other XML-based standards dependent on it. In particular, it needs to address the upcoming XSLT 2.0 and XML Query specifications. The joint W3C Working Group currently responsible for XPath 2.0 is composed of individuals from the two separate Working Groups responsible for those two standards, so this should be (in theory!) an easily achieved goal.
Potentially more problematic is how to continue to support XPointer 1.0, which kind of falls into a crack in the timeline between XPath 1.0 and 2.0.
Improve Ease of Use
On the whole, I think XPath 1.0 is much easier to use than it seems at first glance. But there’s no denying that it’s got its share of idiosyncrasies and counterintuitive crotchets, too, and this goal of XPath 2.0 addresses these obstacles.
For instance, as you know, you can use the union operator,
|, to construct compound location paths.
But — somewhat arbitrarily — you can’t use
it in a location step. XPath 2.0 will let you do
that.
Improve Interoperability
While XPath 2.0 doesn’t use the word “interoperability” (or any of its other forms) anywhere else but in the statement of this goal, it seems pretty clear what it’s referring to. This is not interoperability among products — XPath-aware processors — but among XPath and other standards.
How does “interoperability among” differ from “support for”? Well, it’s conceivable that some hypothetical XPath 2.0 standard might support XSLT, XPointer, and XML Query equally well but use different syntaxes, say, or different data models. This goal mandates the development of common solutions to common problems. An XPath 2.0 processor, you might say, should be plug-compatible whether it’s used in the context of a larger XSLT application, XPointer application, or XML Query application. That said, there’s little likelihood of XPath 2.0’s use in an XPointer application — given (as you will see) XPointer’s lagging progress through the standards process.
A little more tricky may be that word “improve.” XSLT has been around for a while and thus has a fairly large base of processors based on it, which by necessity understand XPath 1.0 expressions. XPointer and XML Query are still in their infancy; hence, in one respect, there wouldn’t seem to be much in the way of any interoperability at all, improvable or otherwise. But remember that this isn’t a question so much about the interoperability of processing applications as the interoperability of related standards behind the applications.
Improve i18n Support
The term “i18n” is a shorthand expression. To expand it, simply take the initial “i,” follow it with 18 other letters, and conclude with the letter “n”: the word internationalization. This goal is going to be both important and (I think) rather difficult to meet. Importantly, the goal says that i18n support should be improved, not outright resolved. Its intention is to facilitate the use of XPath with documents in non-Western languages, particularly those requiring the use of full Unicode-based character sets.
This goal addresses such questions, for instance, as:
Must an XPath-aware processor be able to perform mathematical operations, particularly with the (explicit or implicit)
number( )function, on non-Arabic representations of the text string “2”?What should happen when you convert a character from a caseless language, such as Japanese, to upper- or lowercase?
Maintain Backward Compatibility
This one’s easy to explain, if not necessarily to achieve. One implication of this goal is that a processor that fully supports XPath 1.0 should still be able to operate in an XPath 2.0 context (albeit with a mere subset of the latter’s functionality). More importantly, an XPath 1.0 expression should “mean” the same thing to an XPath 2.0 application that it does to an application that’s been doing useful work for years. (You might want to recode your XSLT stylesheets to take advantage of new XPath 2.0 features, but you wouldn’t expect — let alone want — them to break outright.)
Enable Improved Processor Efficiency
One of the knocks on using XML as a data-storage format, especially relative to established tools such as database management systems (DBMSs), is that the tool for locating specific content (XPath) is rather cumbersome for processors to implement, let alone to implement efficiently. In a database, for example, you can construct an index on virtually any field or combination of fields; when a new record is added, all the corresponding indexes are added to or updated as well. For a DBMS to work efficiently in this regard, it simply needs to load all indexes up-front, not all tables.
XML itself, and particularly XPath 1.0, provide a halfway kind of solution to this problem, by using ID-type attributes to ensure that each element (or at least each element that we particularly care about) has a unique identifier. It’s common for XML parsers, or rather the processors built on them, to then build indexes to the uniquely-identified elements for speedy location. XSLT builds further on this, allowing you to construct non-unique keys on almost any kind of content in a given document, even one lacking any attributes at all. There’s a point of diminishing returns, of course, where it takes longer and is generally less efficient to build a host of indexes (unique or otherwise) than it does to simply hold the document in memory. And still, there’s no way for an XML document’s “index” to be somehow part and parcel of the document itself; even a document heavily keyed with ID-type attributes still has to be read in from beginning to end to be sure you’ve collected all the key values.
My reading of this goal might be considered a pessimistic one — not so much that processor efficiency will be outright improved (despite the goal’s wording). Rather, processor efficiency should not be made worse, even with the addition of new and improved XPath 2.0 features.
Specific Requirements
XPath 2.0 breaks down a list of 25 specific requirements into five general categories:
Must support the XML “family” of standards
Must improve ease of use
Must support string matching using regular expressions
Must add support for XML Schema primitive data types
Should add support for XML Schema structures
XPath 2.0 does not explicitly tie these five general categories back to the list of eight overall goals. That said, a careful reading of the spec might result in a grid something like that represented by Table 6-1. To see the general goal(s) addressed by a category of requirements, read down; to see which requirement(s) address a given general goal, read across.
|
General Goals |
Support XML “family” |
Improve ease of use |
Regular-expression matching |
Schema data types |
Schema structures |
|
XML Schema-typed content |
yes |
yes | |||
|
Simpler string manipulation |
yes |
yes | |||
|
Support of related standards |
yes |
yes |
yes | ||
|
Improve ease of use |
yes |
yes |
yes |
yes |
yes |
|
Improve interoperability |
yes |
yes |
yes |
yes | |
|
Improve i18n support |
yes |
yes | |||
|
Backward compatibility |
yes | ||||
|
Processor efficiency |
yes |
yes |
yes |
One thing about the list of categories is very interesting: the use of the words “must” and “should.” Categories 1 through 4 are pretty clearly meant to represent nonoptional things XPath 2.0 must achieve; category 5 is a bit more weasel-worded, implying (at the least) a certain amount of ambivalence among the XPath 2.0 authors. The distinction between these two words continues throughout the XPath 2.0 Requirements document.
It’s such an important distinction, in fact, that I’m going to depart from the structure of the document itself in discussing the 25 specific requirements. Rather than list them on a category-by-category basis, I’m going to break them down into separate “must-do” and “should-do” sections. Note that within a given category, regardless of the must/should associated with it, specific requirements are must-/should-valued independently. Also note that one of the general categories (#3, “Support string matching with regular expressions”) is not further broken down into specific requirements.
Alongside the heading for each specific requirement discussed below, I’ll indicate the number assigned to it by the XPath 2.0 Requirements document; you can use this number to trace, via the numbered list of requirements categories above, to which of the five categories it belongs. For instance, the “MUST requirement” headed “Provide a conditional expression” is requirement #2.2, making it one of the “Improve ease of use” categories.
XPath 2.0 MUSTs
The following sections describe those things that are required by the spec.
Express its data model in terms of the XML Infoset (1.1)
A data model is a formal expression of the kinds of objects and their properties accessible under the terms of a particular data storage/transmission specification, such as XPath. The XML Infoset is a W3C Recommendation (finalized October 2001) that sets forth the data model — the information set — of XML documents. The XML Infoset spec is located at http://www.w3.org/TR/xml-infoset.
This information set is defined as a collection of 11 information items. An information set is analogous to the tree of nodes in a document; information items, to nodes in the tree.
Most of the information items possible in an XML document conform to what you’d expect: the document itself, elements, attributes, and so on. There are a couple of nonobvious information items, though, such as unexpanded entity references (the “things” that exist in a document when a parser does not, for one reason or another, actually expand the entity references to their full forms) and notations. Also noteworthy are the things you might find in a document that are not considered part of the Infoset: content models, whitespace outside the document element and immediately following the target of a PI, and so on. (The complete list of 20 excluded object types appears in Appendix D of the spec.)
What this requirement means for XPath 2.0 is probably that the language used to name various object types and properties will be brought into synch with that used in the XML Infoset spec, to eliminate ambiguities among XPath 2.0 and other XML specifications (such as XML Query and XSLT) that refer to the same object types. It may also result in the introduction of new object types and properties into XPath. For instance, the Infoset defines a “Base URI” property for various information items such as the document entity itself and each element in the document. (Personally, I hope that the language isn’t brought too much into synch with the Infoset’s. Carried to a zealous extreme, this might produce such awful terms as “information item-set” instead of “node-set.” I’m all in favor of consistency, but I think reasonable people can be expected to make the intellectual leap, in this case, from “node” to “information item” without having to actually say the latter.)
Provide common core syntax and semantics for XSLT and XML Query (1.2)
As I mentioned, the XPath 2.0 Requirements document is a joint product of two separate W3C bodies: the XSL Working Group (responsible for XSLT 2.0) and the XML Query Working group (XML Query, or XQuery, 1.0). This requirement says that XPath 2.0 will boil down the content-location needs of the two specs into a single common body of features, which may be extended by the separate specs as required to cover their distinct needs. The general idea is illustrated by Figure 6-1.
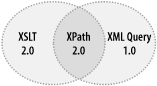
In this classic Venn-diagram figure, the core syntax and semantics to
be provided by XPath 2.0 is the shaded area where the other two specs
overlap. Content may also be located by extension features provided
by the other two specs — features of no common use. For instance,
XSLT 1.0 extended the XPath set of core functions with a
document( ) function for accessing the contents of
other XML documents (source trees) than the one nominally being
processed by a given stylesheet. This function is considered
desirable by XML Query as well, and it has accordingly moved into
XPath 2.0’s set of core functions and out of XSLT
2.0.
Support explicit “for any” and “for all” Boolean operations (1.3)
Here’s a typical XPath 1.0 location path with a predicate:
//book[price > 5.00]
This location path selects all book elements for
which the first price child has a numeric value
greater than 5.00. Now consider that location path in light of the
following document:
<books>
<book>
<price type="wholesale">12.00</price>
<price type="retail">16.95</price>
</book>
<book>
<price type="wholesale">4.95</price>
<price type="retail">6.95</price>
</book>
<book>
<price type="retail">5.25</price>
<price type="wholesale">4.75</price>
</book>
</books>Under XPath 1.0, all three of the above book
elements would be selected, because XPath 1.0 works in what might be
termed “any mode” — selecting
the book elements, in this case, for which
any
price child is greater
than 5.00. This requirement of XPath 2.0 says it would also be nice
to be able to select a book element if
all its price children are
greater than 5.00 (which would select only the first
book element in the above document).
Extend the existing set of aggregate functions (1.4)
The XSLT user community has been
especially vocal in its requests
(verging on outright demands in some cases) that extra functions be
made available for processing across a single selected node-set.
Currently there are only two such functions, sum(
) and count( ). Why not min(
) and max( ) functions? Why not
avg( )? Why not a distinct( )
function to locate unique nodes?
For meeting this requirement, the XPath 2.0 authors will look primarily to XML Query for inspiration. That spec, which will be informed by its authors’ experience with and knowledge of database manipulation languages such as SQL, is almost certain to provide a richer set of aggregate functions than XPath 1.0’s.
Tip
That said, there will probably be some difficult decisions ahead on
this requirement. For instance, if XML Query defines an npv(
) function for returning the net present value based on a
series of arguments, is this of general utility among the core
functions of XPath 2.0 and, therefore, available for use in XSLT and
XPointer as well?
Loosen restrictions on location steps (2.1)
XPath 1.0 places some bizarre, seemingly arbitrary constraints on what you can do in a location step:
You can’t use a node-set function itself as a location step. It might be very useful, for example, to retrieve a descendant of an element with a particular ID-type attribute using something like:
id("Belkin")/priceYou can’t use the union operator,
|, within a location step — only to delimit the components of a compound location path. In the previous chapter, you saw a rather complicated location step that looked like this://sign[count(ruling_planet) > 1]/symbol/@xlink:href | //sign[count(ruling_planet) > 1]/symbol/preceding-sibling::comment( )
This would be much more naturally coded (and easier to understand!) as:
//sign[count(ruling_planet) > 1]/symbol/
(@xlink:href | preceding-sibling::comment( ))(Note the parentheses enclosing the alternatives in the final location step.)
When used in XPointer, a location path cannot end with a node-set function, such as
count( )orsum( ). Thus, the following would be an illegal location path in an XPointer://last( )
This goal of XPath 2.0 would minimize these kinds of restrictions.
Provide a conditional expression (2.2)
Many computer languages provide a function that evaluates one argument for a true or false value, returning one value if the result of that evaluation is true or a different value if false. For instance, in a Microsoft Visual Basic program, you might see an expression such as:
iif(flasher = "yellow", "slow", "go")
The iif( ) function here tests the value of a
variable called flasher; if
flasher’s value is the string
“yellow,” the function returns the
string “slow,” or otherwise returns
the string “go.” Providing a
similar “if condition X, then result A, else result
B” logic is the intention behind this goal of XPath
2.0. The April 2002 Working Draft of the spec spells out a syntax
that looks as follows:
if (expr1) thenexpr2elseexpr3
The idea here, as you might expect, is to locate either the content
identified by expr2 or expr3,
depending on the true or false value of expr1.
Thus, you might do something like the following:
if (title="Callings" or title="Wishcraft") then title else "Unknown Title"
This first evaluates the string-value of the title
child of the context node. If the string-value is
“Callings” or
“Wishcraft,” the value of the
conditional expression as a whole is that string-value; otherwise,
the conditional expression as a whole has the value
“Unknown Title.”
Define consistent implicit semantics for collection-valued subexpressions (2.3)
To figure out what this is saying, let’s start with that phrase at the end. A subexpression, clearly, is a component (or possibly the entirety) of a normal XPath expression. The term collection-valued refers to those bits of an expression that are the names of groups of objects — particularly node-sets.
Thus, this goal asserts that any reference to (say) a node-set must always inherently “mean” the same thing, no matter what its syntactic context might be at the moment.
The XPath 2.0 Requirements document provides an example showing how XPath 1.0 fails to meet this requirement. Here’s a slight modification of that example. Consider an XML-based library application. In an XPath expression designed to locate content in a document built according to this application, you might do something like this:
shelf[books = 31]
This selects all shelf elements that have at least
one books child with a value of 31. However, if
you use the books element in a subexpression, you
get a slightly different result:
shelf[books + 1 = 32]
This returns all shelf elements for which only the
first
books element equals
31. (Slightly different, indeed!) Ironing out this and similar
inconsistencies will make XPath 2.0 easier both to learn and use than
its predecessor.
Support string matching with regular expressions (3)
Many computer languages — especially those with a background in the Unix operating system — support the use of regular expressions to manipulate string content. You’ve probably already been exposed to some of the more common types of regular expression, such as wildcard asterisks (meaning “zero or more occurrences of any characters”) and question marks (“exactly one occurrence of any character”) in listing the contents of a filesystem directory. Being able to use even these simple regular expressions in XPath would make the language terrifically more powerful. For instance:
//employee[name = "Simon*" or name = "*Lenz"]
would locate all employee elements with a child
name element whose string-value
starts with the string
“Simon” or
ends with the string
“Lenz.”
But fully supporting regular expressions would go beyond simple wildcard matching. Whole books have been written about the nuances and more exotic forms of regular expressions, and this isn’t the place to learn about them. But with them, you could tailor your selections to do things like:
Search for the strings “Calendar” or “calendar” (upper- and lowercase “C,” respectively) in a single step, without using the
translate( )function.Locate all strings formatted like a conventional U.S. telephone number (numeric strings separated into three-digit area code, three-digit exchange, and four-digit number, delimited by hyphens)
Define the operator matrix and conversions (4.1)
Well, that’s the way the requirement is worded in the spec. It’s followed by this explanation, evidently meant to be at least as helpful:
XPath 2.0 MUST support the operators and type-coercion rules defined by the joint XSLT/Schema/Query task force on operators.
You’ll search in vain, though, for more information on this joint task force or the “operator matrix.” What you can do productively is read further in the spec, looking especially at the four use cases (that is, specific reasons to pursue the requirement): general, DateTime, Boolean, and QName.
The requirement’s purpose is given away in the last three use cases. DateTime, Boolean, and QName are all data types supported by XML Schema alone or in concert with XPath. And what all this jargon about the operator matrix and type-coercion rules has to do with is, in short, the selection and manipulation of content on the basis of the content’s data type — not simply on the basis of its value.
Consider the DateTime data type, for example. In most fully-featured data systems, knowing that a particular datum is of DateTime type permits operations such as:
Subtracting one DateTime value from another, yielding an interval that is itself of the DateTime type
Adding an interval to a DateTime, yielding an end-time
Comparing one DateTime to another, yielding a Boolean true or false
For another example, given content of Boolean type, without meeting
this XPath 2.0 requirement the language will still lack a fundamental
component of a serious data manipulation language: the ability to
test for a literal Boolean value, such as
true and false (as opposed to
strings which have those values).
Allow scientific notation for numbers (4.2)
This simple requirement — again, intended
primarily to bring XPath
into XML Schema conformance — fine-tunes the number data type,
assuring that any floating-point or double-precision content can be
handled properly as long as it’s in one of the
various numeric formats defined by XML Schema. The Schema language
supports not only scientific notation (such as 7.25e2, representing
7.25 times 10 squared, or 725) but also certain exotic forms such as
INF and -INF for positive and
negative infinity.
Define cast and constructor functions (4.3)
Cast and constructor functions permit XPath-based applications to
force a particular bit of content to a desired data type. Some of
these are available already under XPath 1.0, in the form of the
number( ), string( ), and
boolean( ) functions. To align XPath 2.0 with XML
Schema, this requirement mandates the addition of equivalent
functions for converting content to XML Schema’s URI
and DateTime types.
Tip
Early in the chapter, a sidebar discussed a new spec, called XQuery 1.0 and XPath 2.0 Functions and Operators — the “F&O” document. In that spec, constructor and cast functions are defined differently. A cast function will take an expression (such as a location path) as an argument. A constructor function will always operate on literal arguments. (That is, in the latter case, a literal argument, such as 123.45, might be considered a typeless argument; to make it a value of a particular type, the function must construct a datum of that type and assign the argument’s value to that datum.)
Support accessing the simple-type values of elements and attributes (4.5)
As with the cast/constructor functions mentioned in the previous item, XPath 1.0 already satisfies part of this requirement by supporting content of the string, numeric, Boolean, and node-set data types. But then along comes XML Schema, which adds quite a few new data types to the stew, including binary, byte, century, double, QName, URI, and so on. XPath 2.0 must be able to address and manipulate these simple data types, as well as the four existing ones, without converting such content to (say) string values.
Define the behavior of operators for null arguments (4.6)
No matter whether you’re dealing with XPath or some other language for locating or otherwise handling data, the language needs to lay out some ground rules for processing data with a null value.
Null values are different from empty-string values. Nulls say something like “nothing at all,” as if the content were never assigned in the first place; an empty string, on the other hand, is a string of length 0. The issue with this requirement is that XML Schema allows content to be explicitly assigned a type of null if the content is not provided in the instance document.
What is the value, for example, of an empty element? of a legal attribute that is neither explicitly assigned in a document nor defaulted via a DTD or Schema? You already know what this XPath expression “means”:
unit_price * qty
It calculates the product of the unit_price child
of the context node and the qty child of the
context node. But what if there is no unit_price
child at all and/or no qty child,
and if unit_price and
qty are both explicitly typed as null when
unavailable? Should the result of this calculation be some
“default” value useful in other
computational contexts, like 0, or should the result itself be null?
XPath 2.0 SHOULDs
The following sections describe those things that are recommended by the spec.
Maintain backward compatibility with XPath 1.0 (1.5)
This may qualify as the very least surprising of all XPath 2.0 requirements. But it’s important that it’s made explicit. It says, in effect, “Do not break a given XPath 1.0 expression simply, because it’s being evaluated in an XPath 2.0 context.”
The only surprise may be that this requirement falls into the “SHOULD” category, rather than the “MUST.” I don’t know but am fairly certain that this simply recognizes the pragmatic truth of life in the post-XPath 1.0 world — particularly, the looming XSLT 2.0 and XML Schema. It may very well be possible that satisfying one or more of the MUSTs may make something about XPath 1.0 “break.” For instance, consider the last item in the MUST section which has to do with XML Schema-typed null values. Instead of treating an empty (i.e., null) element as having an empty string-value, XPath 2.0 will treat it as if it has the special null value. This may very well cause changes in the way processors treat an expression such as:
concat(title, ". ", surname)
if a given surname element is empty-and-null as a
result of the source document’s Schema.
Provide intersection and difference functions (1.6)
As you know, XPath 1.0 permits you
to “union
together” two or more node-sets with the union
operator, |. For full set-processing
functionality, XPath 2.0 should also allow you to extract the
intersection (overlapping content) and the
difference (areas of non-overlap) between two
node-sets.
Consider a simple XML document such as the following:
<animations>
<short>
<title>A Grand Day Out</title>
<character>Wallace</character>
<character>Grommit</character>
<character>Tin Robot</character>
</short>
<short>
<title>The Wrong Trousers</title>
<character>Wallace</character>
<character>Grommit</character>
<character>Feathers McGraw (The Penguin)</character>
<character>Techno Trousers</character>
</short>
<short>
<title>A Close Shave</title>
<character>Wallace</character>
<character>Grommit</character>
<character>Shawn</character>
<character>Wendolene</character>
</short>
</animations>The ability to select by intersection would allow you to easily locate all short animations in which Wallace, Grommit, and Wendolene appeared. The ability to select by difference would allow you to easily locate all films in which Grommit but not Feathers McGraw (The Penguin) appeared. According to the XPath 2.0 WD released in April 2002, the intersection might be accomplished as follows:
short[character = 'Wallace'] intersect short[character = 'Grommit'] intersect short[character = 'Wendolene']
The difference operation would be achieved using a special
except operator:
short[character = 'Grommit'] except short[character = 'Feathers McGraw (The Penguin)']
Support the unary plus operator (1.7)
This requirement, if satisfied in XPath 2.0, will simply
correct what to my mind is an oversight in
XPath 1.0: the failure to recognize a leading + sign as a legitimate
portion of a numeric value. (A value of -2.0 is
already recognized as numeric; +2.0, though, is
read as a string — or more exactly, if you pass it to the
number( ) function, the result returned is the
special NaN value.)
Simplify string replacement (2.4.1)
I mentioned earlier in this chapter a cardinal limitation
of the
translate( ) string function: it permits you to
replace characters only on a one-by-one basis. (Or, if the third
argument is shorter than the second, to remove
single characters.) This constantly frustrates newcomers to XPath,
who’d like (along with the rest of us!) to be able
to replace single characters with multiples, or vice versa.
As a simple example, consider an XML document of data concerning a
company’s employees. Such applications frequently
make heavy use of single-character codes to represent different
employee statuses (full- versus part-time and temporary versus
permanent), job categories, and so on. Under XPath 2.0,
there’s a new replace( ) function
whose syntax is (the slightly scary-looking):
replace(string1?,string2?,string3)
Here’s what the April 2002 WD of the XQuery 1.0/XPath 2.0 Functions and Operators spec says about this function:
Returns the value of [
string1] in which every substring of the value of [string1] that is matched by the regular expression that is the value of [string2], has been replaced by a copy of the value of [string3].
Teased apart into something a little less convoluted (albeit less
concise), this says to pass replace( ) the
following arguments:
string1is the entire string to be scanned for text to be replaced.string2represents the value to be located withinstring1. (Note that this is a regular expression, and hence can use various special characters such as an asterisk to represent “any number of any characters.”)string3represents the value with which to replace every occurrence, withinstring1, ofstring2.
Thus, in our hypothetical employee-information application, we might encounter XPath expressions such as:
replace(emp_status, "T", "Temporary Worker")
This evaluates the emp_status child of the context
node, returning a string in which the single character
“T” is replaced with the string
“Temporary Worker.”
Simplify string padding (2.4.2)
The issue here is that in many applications, it’s useful to know that a particular string always has a length of N characters (or possibly more). If the string is shorter, it should be padded with, for example, spaces or leading zeros.
Note that it’s possible to do this kind of string manipulation with XSLT. But it’s non-intuitive and, in any case, of no use if an XPointer or XQuery expression requires that the returned string have a particular length.
Simplify string case conversions (2.4.3)
As with the preceding “should”
requirement, there
already exists a way to achieve this
objective: use the translate( ) function,
specifying the entire uppercase alphabet as the second argument and
the lowercase equivalents as the third (or vice versa, if trying to
force a string to uppercase). Just as with the preceding requirement,
though, it would be much simpler to have a pair of
functions — call them upper( ) and
lower( ), perhaps — to achieve the same result
more simply and intuitively (to say nothing of its virtues in
supporting i18n goals!).
Support aggregation functions over collection-valued expressions (2.5)
Under XPath 1.0, as you know, some functions operate across all members of a node-set. For example:
sum(price)
This expression totals up the values of all price
children of the context node, returning the resulting sum. What you
can’t do with XPath 1.0, though, is pass to such an
aggregation function even a simple, non-node-set
expression. Assume what you’re
after isn’t a simple sum of a single node-set, but a
sum of some set of calculated values. For example:
sum(unit_price *qty)
You can’t do this because the sum(
) function operates only on arguments of the node-set data
type — and whatever else it may be, the expression
unit_price * qty is definitely not a node-set.
This kind of arbitrary (in truth, artificial) limitation on
aggregation functions (including any new ones to be added, such as
min( ) and max( )) will be
lifted if this requirement makes its way into the final version of
the XPath 2.0 spec.
Add a “list” data type (4.4)
Some computer languages, such as Python, include not only simple data types such as Boolean and string, but also a list data type. As the name implies, a list is a sequence of individual data objects that can be treated, alternatively, as a sequence or as separate items, depending on the need.
XPath 2.0 is expected to include a list data type as well. This will
simplify the manipulation of such common XML “plural
attribute types” as NMTOKENS and
IDREFS. It will also permit XPath 2.0 to handle
user-defined lists, locate the first or last item in the list, return
the range of integers between two adjacent list members, and so on.
Select elements/attributes based on an explicit XML Schema type (5.1)
Beginning with requirement 5.1, the XPath 2.0 Requirements document trails off into a final set of four SHOULDs, all having to do with support for XML Schema-defined documents.
This requirement in particular seems both very important and very
likely to make an appearance in XPath 2.0 in its final form. It will
allow a location path to select elements and attributes not on the
basis of their values, but on the basis of the
types of their values. And note that by
“type,” the selection criteria
won’t be limited just to simple types such as
integer, Boolean, URI, and so on. For instance, with XML Schema you
can build up application-specific “type
molecules” from the many simple types predefined by
the standard. Thus, you could define an ISBN
complex type, made up of the various pieces in a full ISBN (each of
which would have a simple type like integer or string). Then, with
XPath 2.0, you could easily extract all elements and/or attributes of
this ISBN type.
Select elements/attributes based on an XML Schema type hierarchy (5.2)
Not only does XML Schema allow for building application-specific
types from simple data types; it allows the designer to build types
based on other types. (That is,
there’s a hierarchy of content types analogous to
the hierarchy of content nodes in the document tree.) An
Address type, for example, might be derived from a
Street type or City type.
Satisfying this requirement would allow you to locate content of any
“subtype” descended from a
higher-order one and to locate any content of higher-order type(s)
derived from a given subtype.
Select elements based on XML Schema substitution groups (5.3)
XML Schema provides a feature called substitution groups as a means
whereby you can declare a generic element type, such as (say)
paragraph, and then declare (in this case)
specific kinds of paragraph elements:
narrative, blockquote, and so
on. The specific element types can be assigned to substitution
groups, such that anywhere in an instance document where a
paragraph can appear, so can one of the specific
types in the substitution group.
Given that freedom, this requirement says that XPath 2.0 should be
able to easily select the generic paragraph
element as well as any member of its
substitution group and perhaps simply to test whether a given element
is a member of the substitution group for
paragraph.
Support lookups based on XML Schema unique constraints and keys (5.4)
As you already know, you can do a simple lookup of any ID-typed
element in XPath 1.0, using the id( ) node-set
function.
Tip
XSLT goes a step further, allowing you to construct an index for and
then reference any element, even with nonunique values, using a
key( ) function.
XML Schema permits multipart keys to be assigned to elements. For
instance, in a simple CD-catalog application, the
artist’s name alone (except in the case of
“one-hit wonders”)
isn’t sufficient to locate a particular CD — and
in many cases, the CD’s title alone
wouldn’t be enough. But you could define a
CDKey key, for example, made up of the
Artist and Title elements.
Under XPath 2.0, you could then get ID-attribute-like indexing into
the document simply by invoking (say) an XPath index(
) function, passing it the name of the key and the value
sought:
index("CDKey", concat("Talking Heads", "Stop Making Sense")(Again, I emphasize that the name of this function is speculative — which is to say, purely a product of my imagination. Don’t look for it in the XPath 2.0 spec!)
[1] The main exception — and it’s a biggie — has been the Extensible Markup Language (XML) 1.0 standard itself, still mostly unchanged (except for minor editorial buffing) after four years. In my opinion, this is a testament to XML 1.0’s concise expression of far-reaching goals, especially in contrast to certain other specs’ swollen expression of minutiae. On the other hand, some would argue that the minutiae are the “hard part” and therefore warrant all the verbiage.