
15.2. Verifying Scalability—the Third Pillar
Beyond pure performance testing, or testing designed to prove your high-availability strategy works as expected, there is great value in validating the scalability of your Production environment (or a system configured to emulate it in a key way, like in terms of processing power or disk throughput). Scalability, the ability to address incremental workload needs or needs beyond what was originally envisioned, is at odds with cost. That is, a high level of scalability is easily achievable—it's easy to supersize your system—if you don't mind writing a big check for something you may rarely need. It's for this reason that I believe scalability testing is so vital. The concept is simple – it's better to understand the load a system can handle well before you might be required to handle that load.
Different kinds of scalability exist. The first, in-the-box scalability, speaks to the processing headroom (or other available bandwidth relevant to perhaps memory, network throughput, and so on) above and beyond what you absolutely need. Thus, scalability usually is not looked at as the solution for meeting regular month-end financial closes or other scheduled events; these events should have been planned for and taken into account from the beginning. Instead, I believe scalability is more often all about addressing unplanned workloads, and doing so in a manner that still meets the minimum response time and throughput metrics of the system's end users. This underscores what I've often said in the past—when deploying or upgrading SAP, it's crazy to buy exactly what you think you need at the time, because invariably a need will evolve later that was never understood or envisioned up front. I believe that scalability is therefore an integral part of sizing and should naturally take into account an organization's foreseen growth in workload as well as provide a certain level of scalability to meet unforeseen needs over the next 2 to 4 years. Traditional in-the-box server scalability approaches include the following:
Buying a server with additional CPUs, RAM, or disks built in, essentially oversizing SAP now to address future workload unknowns. In doing so, the system will naturally benefit from better-than-required response time and throughput performance, though at a price of course.
Buying a server capable of scaling or growing in terms of the number and speed of CPUs, RAM, disk capacity, I/O slots, and so on, but forgoing actually purchasing these components. In this way, the system is ready to grow with only minimal downtime required. The downside is that you may actually wind up buying a server that supports more in-the-box growth than you'll ever need—usually a minimal cost, but not always.
The second kind of scalability common in SAP environments is usually referred to as horizontal scalability. In a classic sense, this distributed approach to computing is seen, for example, when an organization chooses to purchase a large number of relatively inexpensive servers (or other components) rather than deploying fewer though larger and more expensive servers. An organization investing in 16 different two-CPU systems rather than one well-equipped 32-way server is taking such an approach to computing, one that implies that
The different technology layers of the solution being deployed must therefore support horizontal scalability.
A TCO analysis has indicated that it's the best way to go in terms of technology, people, and process costs incurred initially as well as over time.
Perhaps a more consolidated approach is simply not possible; not all applications scale well in the box, for example.
High-availability concerns might be driving the architecture decision; perhaps the high-level redundancy is preferred to mitigate the risk of one or few servers taking down an entire system.
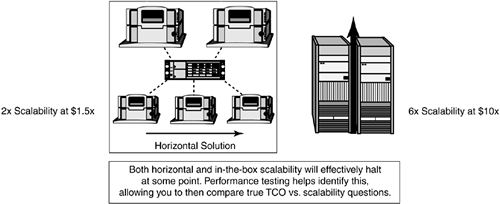
Iterative load testing is a perfect fit for helping an organization determine which scalability scheme works best for it, as shown in Figure 15-2. To determine the best fit for a particular organization, I take into account an organization's high-availability requirements, application needs and constraints, unique workloads and the history with which these workloads grow and shrink throughout the year, any technology biases, general people skill-sets, and overall familiarity with deploying and maintaining distributed versus consolidated SAP solutions.
Figure 15-2. Although both in-the-box and horizontal scalability options are viable in most situations, one approach tends to provide greater value than another based on the circumstances—iterative load testing helps solidify this value.
Scalability goes way beyond merely server hardware, too; the disk subsystem, OS, database, SAP application components, and middleware solutions all exhibit different levels of in-the-box and horizontal scalability. That is, you can buy more than you need of any of these technology stack components, in effect creating bandwidth on demand. Organizations that make the decision to purchase a more robust disk subsystem or more capable OS release without a current need for the capabilities inherent to these better than required versions are actually investing in scalability.
15.2.1. Baselining the Current State
I've harped on remembering to baseline your system prior to iterative testing. This is especially true of scalability testing, where the lack of a baseline makes it nearly impossible to later conduct apples-to-apples measurements between two or more system configurations. I also suggest that you baseline from a number of different angles; because you may not quite know what to look at up front, be sure to capture a variety of workloads, configuration settings, and so on.
15.2.2. Determining True Carrying Capacity
First of all, let me thank one of my newest SAP colleagues, Rolf Michelsen of HP, for sharing with me the term carrying capacity. I love this term, because it speaks clearly to both capacity planning and what I've in the past labeled real-world smoke testing (without the accompanying strange looks and questions about fire!). Carrying capacity is a fairly self-explanatory term that seeks to answer the following: What kind of load—online, batch, or otherwise—can a particular system configuration reasonably sustain in the real world? For example, given the desire to limit most CPU spikes to something below 70% and average RAM utilization to something less than 80%, how many users or batch processes may realistically be supported? That is, at what workload does the system exceed these self-imposed metrics? Working against a set of metrics to determine a system's carrying capacity is a great way to stay focused on the things that matter back in the real world—monitoring and managing Production response times and throughput rates to keep them from exceeding acceptable Production-like thresholds.
15.2.3. Capacity Planning and Reverse Engineering
Have you ever been asked to show your management team concrete evidence that speaks to the capacity your system may possess after you complete a large merger or acquisition? Have you ever been told that you have no money to buy additional gear, but your system needs to support a new functional area and 500 more users by year-end? Like carrying capacity, these questions traditionally beg for an exercise in “sizing” to be conducted. But sizing is not an exact science, and an organization's uniqueness—its SAP customization, the layout and performance of its database and disk subsystem, and more—is often difficult if not impossible to capture and model in a reasonable time.
For these reasons, many years ago, my colleagues and I at the SAP Competency Center devised a simple way of capturing the workload and performance statistics relevant to a particular company, so that we could then reverse-engineer the sizing process and ultimately understand a company's current workload-to-performance ratio. With these data, it was then possible to tweak our sizing and configuration tools, in effect customizing them to reflect the company's SAP implementation rather than a generic SAP sizing model. Finally, with a little bit of extrapolation it became possible to accurately size any number of what-if questions. And because the custom-sizing model had to take into account the entire custom solution stack deployed by the company, it was easy to determine a system's current-state carrying capacity as well. Bottom line, we were able to identify the precise bottlenecks that, left unaddressed, would artificially limit a system's potential throughput, while also pointing out when it made sense to add incremental in-the-box horsepower or incremental servers.
At the end of the day, though, even a company-specific sizing exercise is not foolproof. It is for this reason that a “mini” stress test, like one focused on the performance or scalability of a key technology-stack component, can help validate the accuracy of a sizing exercise, and provide the concrete proof that many organizations require. And with the primary bottleneck identified via this exercise, a full-blown test is often not required. Instead, in my experience, I've seen delta tests provide all the proof a company needs to give it either peace of mind in its current solution or the ammunition it needs to justify incremental technology purchases.
15.2.4. Smoke Testing
When the weight of the real world is not a concern, and you simply need to understand the maximum potential throughput a particular system is capable of sustaining without “melting” under the weight of its own workload, it's time to look into smoke testing. Another favorite term of mine, smoke testing, is near and dear to the true technologists and benchmarking fanatics among us. Smoke testing seeks to answer questions that are not often asked in the real world (e.g., “How many users can I actually support on an eight-way database server, regardless of CPU utilization?”). However, the answers to questions like this can provide valuable insight into where performance-limiting bottlenecks might crop up in a particular type of server platform, disk subsystem configuration, OS or database release, or even a particular SAP architecture or middleware component. Of course, whether or not to make such a technology purchase is not a question easily answered. During times like these, where financial decisions and business problems intersect, a TCO analysis can make all the difference.