
 Unity in diversity
Unity in diversity
In the last two chapters, we have learned about lists and dictionaries. These are two very important data structures which .NET Generics has to offer. The ability to query these in an efficient manner is a very important factor for the all-over efficiency of an app.
Imperative programming languages enforce the how part of the program more than the what part. Let me explain that a little bit. Suppose you want to sort a list of
studentobjects. In an imperative style, you are bound to use a looping construct. So the what part is to sort the elements and the how part is the instructions that you write as part of the program, to achieve sorting.However, we are living in a very exciting time where a purist programming approach is fast becoming a thing of the past. Computing power is more popular than ever. Programming languages are going through a change. Declarative syntax that allows programmers to concentrate on the what part more than the how part is the new trend. This allows compiler developers to tune the compiler to emit optimized machine code for any given declarative syntax. This will eventually increase the performance of the application.
.NET 3.5 came up a step ahead with the introduction of Language Integrated Query (LINQ). This allows programmers to query in-memory objects and databases (in fact any data source) alike, while it does the required optimization in the background.
In this chapter, we shall learn:
How to put your own method for existing classes using Extension methods
How to use Functors
How to use Actions
Lambda expressions
LINQ Standard Query Operators (LSQO)
Some of the LSQO for joining have been left out deliberately as they are not very useful for LINQ to Objects in general. A couple of other operators such as Aggregate and Average are also left out as they are not very applicable to LINQ to Objects in general; they find specific usage while dealing with numeric data types.
After reading this chapter, you should be able to appreciate how LINQ drastically removes the complexity for querying in-memory collections and the usage of looping constructs and its side effects. There is a lot more in LINQ to Objects than we can discuss in this chapter. We shall concentrate more on the LSQO as we need them to be able to query-out generic collections in a better optimized way.
LINQ is not a technology in itself, instead it is made up using different building blocks. These are the things that make LINQ.
.NET Generics follows a good design philosophy. This API is open for extension, but closed for modification. Think about the .NET string API. You can't change the source code for any member method. However, if you want you can always put a new method that can behave as if it was built-in.
The technology that allows us to do this legal stretching (if you will) is known as the Extension method. Here are a few very important details about Extension methods:
Every Extension method must be in a static class.
Every Extension method must be static.
Every Extension method must take at least one parameter, passed as this
Type <parameter name>.One example is
this string name.The argument declared with
thishas to be the first one in the parameter list. Every other parameter (which is optional, if any) should follow.This gives a feel that this newly introduced method is like one of those inbuilt ones. If we want to inject a method for all concrete types of an interface, the Extension method declared on the interface is the only option.
Let's say that you have a List of strings and you want to find out how many match a given regular expression pattern. This is a very common activity:
Create a class library project. Call it
StringEx. We are trying to extendstringclass functionalities, so I named itStringEx.Rename the generated class as
StringExtenstions.cs.Mark the class as static:
public static class StringExtensions
Add the following using directive to the header of the class:
using System.Text.RegularExpressions;
Add the following code snippet as the method body:
public static bool IsMatching(this string input, string pattern) { return Regex.IsMatch(input, pattern,RegexOptions.CultureInvariant); }
We just created an Extension method called IsMatching() for the string class. The first argument of the method is the calling object. pattern is the regular expression against which we want to validate the input string. We want to compare the strings ignoring the culture.
So, while calling IsMatching(), we shall just have to pass the pattern and not the string.
Now, let's see how we can consume this method:
Stay in the project you created. Add a console application. Call it
StringExTest.Add a reference of
StringExclass library to this project:
Add the following using directive in
Program.cs:using StringEx;
Add the following string variable in the
Main()method. This validates Swedish zip codes:string pattern = @"^(s-|S-){0,1}[0-9]{3}s?[0-9]{2}$";Add a few test input strings in a
Listof strings:List<string> testInputs = new List<string>() {"12345", "425611", "932 68", "S-621 46", "5367", "31 545" };Iterate through all these test inputs to find out whether they match the given regular expression pattern or not:
foreach (string testInput in testInputs) { if (testInput.IsMatching(pattern)) Console.WriteLine(testInput + " is a valid Swedish ZIP code"); else Console.WriteLine(testInput + " is NOT a valid Swedish ZIP code"); }
When run, this program should generate the following output:

As this IsMatching() method is described as an Extension method in StringEx; and StringEx is referenced in this StringExTest project, IsMatching() will be available for invocation on any string object in the StringExTest project.
Any Extension method appears with a downward arrow, as shown in the following screenshot. Also the compiler shows the intelligence support (if it is selected) mentioning that this is an Extension method:
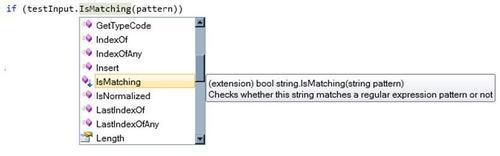
Notice that while calling the Extension method, we do not need to pass the string argument. testInput is the string object on which we call this Extension method.
The keyword this in the parameter list did the trick.
It is possible to define the Extension method for any type of .NET class. So all you have to do is add a static class and add the static Extension methods to the class. You can find an API for string processing written using the Extension method at http://www.codeplex.com/StringDefs. I created this for different kinds of string processing needs. This will give you an idea about how Extension methods can be written for several purposes.
For using LINQ to Objects, we shall need System.Linq namespace. The standard query operators of LINQ are based on the Extension methods that extend any type that implements IEnumerable<T>.
Although an Extension method might seem to solve your problem, too much usage of the Extension method is probably an indication that you should re-think your design a little bit. Remember; they are meant to extend the functionality of an existing type. So, if the functionality you want to achieve can't be done using already existing methods, you are better off creating your own type by inheriting the type you wanted to extend.
Assume that you have a class called Student and you want to initialize student objects using different variables at different times. Sometimes, you will only have name and age, while at other times you might also have the course they are enrolled in as part of the input. These situations call for a set of parameterized constructors in the Student class.
Otherwise, we can have a blank constructor and public properties for the Student class attributes. In this situation, the code to assign a student object might look similar to the following:
Student sam = new Student(); sam.FirstName = "Sam"; sam.LastName = "Hood"; Student dorothy = new Student(); dorothy.Gender = "F"; dorothy.LastName = "Hudson";
This type of object initialization spans over multiple code lines and, at times, is difficult to read and keep up. Thus, C# 3.0 came up with a feature called object initializers that allows programmers to construct and assign an object in a single line. Any public field or property can be assigned in the initialization statement by assigning that property name to a value. Multiple assignments can be made by the comma-separated assignment list. The C# compiler calls the default constructor behind the scene and assigns each public field or property as if they were previously declared and assigned one after another. So, the previous two initializations will be changed to the following:

Although this technical advancement might, at first, look like syntactical sugar, while writing LINQ queries, we shall find ourselves using this feature quite often to construct object instances as part of the result set by setting property values on the fly.
Taking the object initializers a step ahead, the ability to add elements to the collections at the time of creating them is added. This is called a collection initializer. The only constraint is that the collection has to implement the IEnumerable interface and provide an appropriate Add() method implementation that will be used to add the elements.
The good thing is that collection initializers can use object initialization technique to create objects on the fly while adding them to the collection. Here are some examples:
List<string> names = new List<string>() { "Anders", "David", "James", "Jeff", "Joe", "Erik" };
List<int> numbers = new List<int>() {56, 12, 134, 113, 41, 1, 0};
List<Student> myStudents = new List<Student>()
{
new Student(){Name = "Sam", Course = "C#"},
new Student(){Name = "Dorothy", Course = "VB.NET"}
};C# 3.5 introduced a new way to declare variables using the var keyword. This type of a new variable is inferred from the initialization expression. These types of variables are strongly typed.
Here are a few examples:
var shirtSize = "L";
var shoeSize = 10;
var age = 29;
var coursesTaken = new List<string>() { "C#", "C++", "Java", "Ruby" };
Console.WriteLine(shirtSize + " " + shirtSize.GetType().Name);
Console.WriteLine(shoeSize + " " + shoeSize.GetType().Name);
Console.WriteLine(age + " " + age.GetType().Name);
Console.WriteLine(coursesTaken + " " + coursesTaken.GetType().Name);And here is the output for the preceding snippet:
L String 10 Int32 29 Int32 System.Collections.Generic.List`1[System.String] List`1
Although declaring a variable in this way may seem to have little value, it is a necessary feature for declaring some types that can't be declared in any other way; for example, anonymous types.
Anonymous types are compile-time generated types where the public properties are inferred from the object initialization expression at compile time. These types serve the purpose of temporary storage. This saves us from building specific classes for any operation.
Anonymous types are declared using the var keyword as an implicit variable and their type is inferred from the expression used to initialize.
Anonymous types are declared by omitting the type after the new keyword. Here are a few examples:
var item = new { Name = "Sam", Age = 30 };
var car = new { Make = "Honda", Price = 30000 };These types are used in queries where collections are built using a subset of properties from an existing type also known as projections . We shall see how these help in LINQ in a short while.
Lambda expressions are built on an anonymous method. These are basically delegates in a very brief syntax. Most of the time these expressions are passed as an argument to the LINQ Extension methods. This type of expression can be compound and can span multiple lines while used in LINQ Extension methods also known as LINQ Standard Query Operators or LSQO in short.
Lambda expressions use the operator => to separate parameters from expressions.
Before the Lambda expression came into existence, we had to write query using delegates as follows:
Students.Find(delegate(Student s) {return s.Course == "C#";});Using the Lambda expression, the query will be as follows:
Students.Find(s => s.Course == "C#");
The highlighted part in the second code line is the Lambda expression. One way to visualize this is to think about mathematical sets. Assume => stands for rule of membership. So the preceding line is basically trying to find all the students where course is C# and s denotes a temporary variable of the data source being queried; in this case the Students collection.
This is a very important concept for understanding and using LINQ.
Functors are basically space holders for Lambda expressions. It is a parameterized type in C#. There are 17 overloaded constructors to declare different types of Functors. These are created by the
Func<> keyword as follows:
Notice the tooltip. It is expecting a method name that accepts no parameter but returns a Boolean value. So
boolMethod can hold any method that matches that signature.
So if we have a method as shown in the following snippet:
private static bool IsTime()
{
return DateTime.Today.Day == 8 && DateTime.Today.Month == 7;
}the Functor can be created using the method name as an argument to the constructor, as follows:
Func<bool> boolMethod = new Func<bool>(Program.IsTime);
The last parameter to a Functor is the output and the rest all are input. So the following Functor constructor expects a method that accepts an integer and returns a bool:

These types of Functors that take some argument and return a Boolean variable (in most cases due to some operation on the input argument) are also known as Predicates.
You can also use Lambda expression syntax to declare Functors as follows:
//Declaring the Functor that takes an integer and checks if it is odd //When the Functor takes only one input it is not needed to wrap the //input by parenthesis. Highlighted part is the Lambda expression //So you see, Lambda expressions can be used directly where the //argument type is of Func<> Func<int, bool> isEven = x => x % 2 == 0; //Invoking the Functor bool result = isEven.Invoke(8);
Most of the LSQO accept Functors as selector functions. A selector function is a function that operates on each of the element in a collection. The outcome of these operations decide which values will be projected in the resulted collection. This will be more clear as we discuss all the LSQO in a while.
Predicates are essentially Func<int, bool>. You can use Lambda expressions to initialize them like Functors as follows:
Predicate<int> isEven = new Predicate<int>(c => c % 2 == 0);
Here is how you can call this Functor:
int[] nums = Enumerable.Range(1, 10).ToArray(); foreach (int i in nums) if(isEven(i)) Console.WriteLine(i.ToString() + " " + " is even " );
The Lambda expression is hidden. It is advisable to use Func<> for LINQ-related operations as it matches the signatures of the LSQO. Predicates was introduced with System.Collections.Generic in .NET Framework 2.0 and Func<> was introduced in .NET 3.5.
Although they behave similarly, there are a couple of key differences between a Predicate and a Functor:
Predicate always returns a Boolean value whereas Functors can be programmed to return a custom type:
public delegate bool Predicate<T>(T obj); public delegate TResult Func<TResult>();
Predicates can't take more than one parameter while Functors can be programmed to take a maximum of four input parameters:
public delegate TResult Func<T1, T2, T3, T4, TResult> (T1 arg1, T2 arg2, T3 arg3, T4 arg4);
This is a built-in delegate, introduced in .NET Framework 4.0. There are several overloaded versions to handle different styles of delegates.
Here is an example:
Action<string> sayHello = new Action<string> (c=>Console.WriteLine("Hello " + c));
List<string> names = new List<string>() { "Sam", "Dave", "Jeff", "Erik"};
names.ForEach(sayHello);
ForEach() is a method in the List<T> class that takes an argument of the type Action<T>. The preceding snippet prints the following output:
Hello Sam Hello Dave Hello Jeff Hello Erik
There are several operators (which are basically Extension methods) based on the IEnumerable<T> type. These can be broadly classified as follows:
We shall use LINQPad for running our LINQ snippets, as described next in this chapter. Source Collection is the collection on which the operator is invoked. Every time we refer to Source Collection please assume this definition.
Download LINQPad from www.linqpad.net/.
Download the executable for .NET Framework 4.0 from the website:

Start LINQPad.
LINQPad is capable of running C# Expressions, Statements, and complete C# Programs.
Type the following query in the query area in the tab space to the right, as shown in the following screenshot. Select C# Statement(s) from the drop-down, as shown in the following screenshot. The query comprises complete C# Statements. A C# Expression is a partial C# Statement:
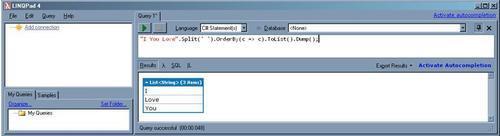
"I You Love".Split(' ').OrderBy(c => c).ToList().ForEach(c=>Console.Write(c+" ")); Console.Write("Linq");
Press the green play button on the top left-hand corner.
See the result at the bottom:
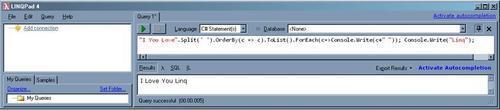
You did expect to see something that is shown in the screenshot. Didn't you?
One important method of LINQPad is
Dump(). It's a very useful function because it shows the data type of the query results. You can useDump()to see the result without explicitly channeling the data to the console output.Here is how you can use it:
Basically, you terminate any query with
Dump()and it will give you the result type.The other version of
Dump()takes an argument. This argument will be used as a header of the result as follows: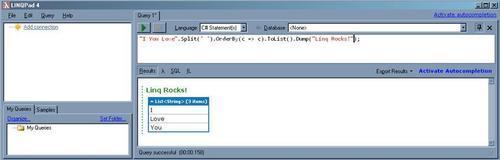
In this section, we will discuss the following Restriction operators:
This query operator allows the user to filter their data source for some condition passed as a predicate. With .NET 3.5+ this can be a Lambda expression.
There are two overloads of this operator:

This one takes a predicate that accepts an element of type T and returns a bool applying some logic on the element passed. So, if we are operating this operator on an array of strings, then this version of Where() would expect a Func<string, bool>.
Both overloaded versions return an IEnumerable<T> instance so that we can pass the result obtained as input to another LSQO.
Here is the first problem:
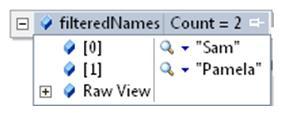
Say we have a List of names and we want to find all those names where "am" occurs:
Copy the following code snippet on LINQPad:
string[] names = { "Sam", "Pamela", "Dave", "Pascal", "Erik" }; List<string> filteredNames = names.Where(c => c.Contains("am")).ToList().Dump("Names with pattern *am*");Run the snippet. Make sure C# Statement(s) is selected in the Language drop-down, otherwise it will not work. Once successfully run, you should expect the output shown in the following screenshot:

The first version of Where() takes a Func<T, bool> (T is the type of source collection). In this case, T is a string. So in this case, it will expect a Func<string, bool>. As described earlier, Functors can be expressed as Lambda expressions. This leads to much shorter code.
The highlighted part in the query is the Lambda expression that takes the form of a Func<string, bool>. c represents an element in the source being queried (in this case, names). Where() loops through the entire source and outputs those to the returned IEnumerable<T> instance. As we want to store the result in a List of strings, I have used the ToList() Extension method to convert the results from IEnumerable<string> to List<string>.
filteredNames will have "Sam" and "Pamela", as shown in the following screenshot:
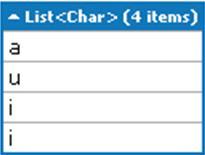
Finding all the vowels in a string:
Copy the following code snippet as a query in LINQPad:
List<char> vowels = "Packt Publishing".ToLower().Where(c => "aeiou".Contains(c)).ToList(); vowels.Dump();
Run the query. You will get the following output:
Finding all processes where process names match a regular expression pattern:
Copy the following code snippet as a query in LINQPad:
//Finding all processes that match the directions string pattern = "win+"; var myProcesses = Process.GetProcesses().Where(p => Regex.IsMatch(p.ProcessName,pattern)); //Iterating over the result to print records foreach (Process proc in myProcesses) Console.WriteLine(proc.ProcessName + " " + proc.MachineName);
Run the query. You will get the following output:

Process.GetProcesses() returns an array of System.Diagnostics.Process and thus, it is an IEnumerable<Process> so Where() can operate on this. LSQO is being written as an Extension method of the IEnumerable<T> interface which can operate on any collection that implements this interface. System.Array() implements IEnumerable(), which is also inherited by IEnumerable<T>. This is because of the
Liskov Substitution Principle.
Note, implicit variable declaration is used to store the result of the query. However, later on, a strongly typed variable is used in the loop to iterate over the result. This is proof that var actually enforces strong typing implicitly.
The second overloaded version lets you use the index of a particular element in the source collection in the query:

So in this case, the Lambda expression will expect two input parameters. The item and its index. Then it will return a bool depending on the parameters.
This can be particularly handy when you want to exclude certain elements from the source collection; while processing:
Copy the following code snippet to LINQPad:
//This will find all the names in the array "names". //where length of the name is less than or equal to the index of //the element + 1 string[] names = { "Sam", "Pamela", "Dave", "Pascal", "Erik" }; var nameList = names.Where((c, index) => c.Length <= index + 1); nameList.Dump();Run the query. You will get the following output:

In the Lambda expression (c,index) => c.Length <= index + 1, c denotes any variable in the array names, while index denotes the index of that particular element in the array names. So, for example, if the current element being scanned is "Dave" then the index will be 2 (the array index starts from zero).
c.Length means the length of the current element. So c.Length <= index + 1 will return true if the length of the current element being scanned is less than or equal to the expression index plus unity.
Now, if we scan from the first element, the results will be as follows:
|
c |
index |
c.Length |
c.Length <= index + 1 |
|---|---|---|---|
|
Sam |
0 |
3 |
false |
|
Pamela |
1 |
6 |
false |
|
Dave |
2 |
4 |
false |
|
Pascal |
3 |
6 |
false |
|
Erik |
4 |
4 |
true |
As only "Erik" matches the Lambda expression, it gets added to the returned IEnumerable<string>.
You can do pretty much anything depending on the index of the element.
Suppose there is a Student class and we want to find only those students who have enrolled for the C# course:
We want to find all students whose
CourseisC#. Write the Lambda expression for that:s => s.Course.Equals("C#")Pass this Lambda expression to the
Where()clause (sometimes, LSQO are referred to as clauses) as follows:Students.Where(s => s.Course.Equals("C#") );Receive the result of this operation in an implicit variable, as shown next:
var cSharpStudents = Students.Where(s => s.Course.Equals("C#") );
We have a List of Student objects and we wanted to find all the students that have opted for C#. Assuming Course is a public property of the Student object, s.Course gives the course of the current student on the collection, while we keep moving along the collection.
s => s.Course.Equals("C#") is the expression that evaluates to true when the course of the current student is C# and that Student object gets added to the List of IEnumerable<Student>, which is returned after the operation is complete.
We used the var keyword to use implicit typing while receiving this IEnumerable<Student> instance. Later in this chapter, you will learn some conversion operators, so that we can project the result on a concrete collection.
The following screenshot shows how we can visualize Where():
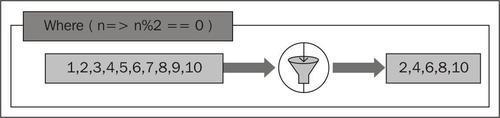

In this section, we will discuss the following Projection operators:
This operator allows you to project the elements in the result collection in a customized manner. Like Where() this also comes in two overloaded versions. The first version takes a Lambda expression that describes how the projection has to be made. The other version allows us to consider the index of the element:

Here is the first problem:
Say we have a List of names and we want to print "Hello" in front of all the names:
Copy the following code snippet as a query to the LINQPad:
List<string> nameList1 = new List<string> (){ "Anders", "David", "James", "Jeff", "Joe", "Erik" }; nameList1.Select(c => "Hello! " + c).ToList().ForEach(c => Console.WriteLine(c));Run the query.
The preceding code snippet will give the following output:

The Lambda expression c => "Hello!" + c is basically creating a projection of the elements of nameList1 List and the result will be an instance of IEnumerable<string> with all the elements of nameList1 and a "Hello!" in front of them.
ToList() is a conversion operator, which we shall learn later in this chapter. This converts the generated IEnumerable<string> to a List<string>. I used this conversion because I wanted to use the
ForEach() method of the List<T> class that accepts an action.
Now that we have the List of processed strings, we need to tell the computer how we want it to be printed. The last Lambda expression c => Console.WriteLine(c) does just that. This means taking a string from the List and printing it to the console, one per line.
Suppose you are writing a program for a radio station where you need to find every third name in the array and say "Hi! <Name> You are the Lucky 3rd Caller". So you see in this case, the index of the element currently being projected is of importance. A little change in the Lambda expression used in the previous example, is all it will take to make this happen:
Copy the following code snippet as a query to LINQPad:
List<int> First100LuckyCallerIndices = new List<int>(); //First lucky third caller's index in the array will be 2. First100LuckyCallerIndices.Add(2); for (int i = 0; i < 100; i++) First100LuckyCallerIndices.Add(First100LuckyCallerIndices.Last() + 3); List<string> nameList1 = new List<string>() { "Anders", "David", "James", "Jeff", "Joe", "Erik", "A", "B", "C", "D", "E" }; var query = nameList1.Select((c, index) => new { Name = c, Prize = First100LuckyCallerIndices.Contains(index) }); foreach (var person in query) { if (person.Prize) { Console.WriteLine("Hello! {0} You are the Lucky 3rd Caller.", person.Name); } }Run the query.
The previous code snippet will generate the following output:
This query makes use of the anonymous type. The Lambda expression: nameList1.Select((c,index) => new {Name = c, Prize = index % 3 == 0}) uses the index of the current element. Instead of projecting the current string or some concatenated string, this time we want to project an anonymous type. The properties of this type get populated by the current element and its index.
The name of this anonymous object is assigned as the current element by the code Name = c, while whether this person has won a prize or not depends on the index of the current element.
Prize = index % 3 == 0 means if the index of the current element is a multiple of 3 then the attribute Prize for the anonymous object gets set to true, otherwise it gets set to false.
So the query Select((c,index)=> new {Name = c, Prize = index % 3 == 0}); returns an instance of IEnumerable<string> that has the names of the lucky winners.
So once we have it, we iterate over the instance to print the results.
Can you predict what will be the result of the following query?
nameList1.Select((c,index)=> new {Name = c, Prize = index % 3 == 0})
.Select(c=>c.Prize==true?"Hello! " + c.Name + " You are the Lucky 3rd Caller":"no")
.ToList()
.Where(c=>c.StartsWith("Hello!"))
.ToList()
.ForEach(c=>Console.WriteLine(c));Hint: In order to understand it, you can break the query into parts and put them in LINQPad and execute them step-by-step.
This operator projects each element of a sequence to an IEnumerable<T> instance and flattens the resulting sequences into one sequence.
This lets us query the data of the source collection using a normal key selector or an indexed version, where we can use the index of the elements in the source collection to be a deciding factor in their inclusion in the result.
Suppose, we have a dictionary such that each key has a list of values attached to them. Now, we want to project all the elements in a single collection:
Copy the following code snippet as a query to LINQPad:
Dictionary<string, List<string>> map = new Dictionary<string, List<string>>(); map.Add("UK", new List<string>() { "Bermingham", "Bradford", "Liverpool" }); map.Add("USA", new List<string>() { "NYC", "New Jersey", "Boston", "Buffalo" }); var cities = map.SelectMany(c => c.Value).ToList(); cities.Dump("All Cities");Run the query. You should see the following output:
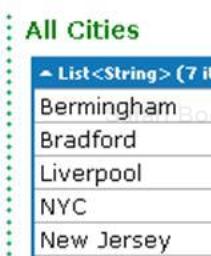
In this example, we use the first version of the
SelectMany() method that has the following signature:

Note that it accepts a Functor that accepts a string and returns an instance of IEnumerable<T>.
In this case, the Lambda expression c => c.Value means that each key returns the list of values associated with that key.
The second overloaded version allows us to use the index of the current element in the source collection in the Lambda expression.
Later in this chapter, you will see some other applications of this operator.
In this section, we will discuss the following Partitioning operators:
Suppose we are only interested in the first few values of a collection and we don't want to consider the rest for now. In this situation, in the absence of LINQ, we had to create a blank collection and iterate over the original one to populate the other empty collection.
With the introduction of LSQO, Take() all that is going to be history. Take() takes an integer parameter and returns IEnumerable<T> (where the source collection is of type T) containing as many elements as you want starting from the first element in the source collection.
The method signature is as shown in the following screenshot:

Follow the given steps:

Numbers is an int array, int in C# is an alias for System.Int32 type in CTS. Thus, the query numbers.Take(4); returns an IEnumerable<System.Int32> that has first four elements.
One good thing about Take() is that it doesn't throw an exception if the argument number is out of range (say negative, or more than the number of elements in the collection).
If a negative index is passed, Take() returns the entire collection. The following is a visual representation of this operator:
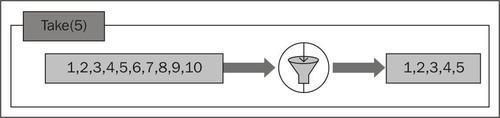
Suppose you have to pick elements from a collection as long as those elements meet a certain criterion. We have already learned about Take() that lets you pick from the start of the collection. In order to allow conditional picking, TakeWhile() was introduced. This operator takes a Lambda expression that describes the condition.
There are two overloaded versions of the method. The first one takes a Functor, as shown in the following screenshot:

Here is the first problem:
Say we have a List of names and we want to create another List picking names from this List as long as the names start with "S". Here is how we can do that using TakeWhile():
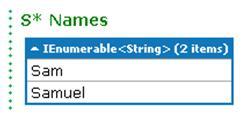
If you are thinking, why "Sid" didn't make it to the List of the matching names, you are not alone. I thought so too initially. However, you must understand that TakeWhile() operates on the collection as it is, without any modification or sorting. So it processes the elements as they appear in the List.
TakeWhile() picks elements from the start of the collection as long as the given condition expressed as the argument Lambda expression is true.
"Sam" and "Samuel" are two names that match the condition and the next name "Dave" does not match the expression and thus scanning stops there. Did you get the While of TakeWhile() now? This essentially means Take as long as the condition is satisfied.
So, if the expression was c => c.StartsWith("D"), it would have returned an empty IEnumerable<string> as shown in the following screenshot:

The following is a visual representation of the TakeWhile() operator:

Like Where(), TakeWhile() queries can also be indexed using the second version of the method.

Say we want to check whether every second name starts with "S" or not:
var sNames = names.TakeWhile((c,index) => index%2==0 && c.StartsWith("S"));Like Take(), TakeWhile() doesn't throw any exception when the number is out of bounds. Notice that TakeWhile() doesn't take an explicit number of items to pick. It just stops scanning as soon as the condition is dissatisfied.

Say we have a List of names, and we want to create another List leaving the first few names:

Skip() creates an IEnumerable<T> instance that will have only the chosen few elements. In this case, we wanted to skip the first three elements. If you want to conditionally skip elements, then you would need SkipWhile(). That's next!
However, if you want to filter the entire collection, your best bet is Where(). This works without sorting.
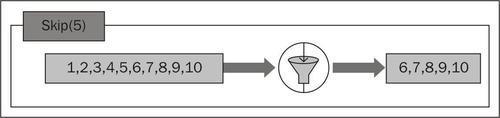
Similar to Take(), it doesn't throw any exception when the number passed is out of bounds of the source collection. It returns an empty IEnumerable<T> when the source collection is of type T. Interestingly, if a negative argument is passed to Skip(), it doesn't skip anything and returns the entire source collection.
This is a conditional skip from the source collection. The elements from the source collection do not get added to the projected output as long as the given condition holds good:

Say we have a List of integers and we don't want to get anything that is less than 10. Following is the code:
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,20 };
int[] nums = numbers.ToArray();
var skippedList = nums.SkipWhile(c=>c<10);//Leaving everything less
//than ten
foreach (var v in skippedList)
Console.WriteLine(v);This code snippet will output as follows:

Like TakeWhile(), SkipWhile() also has an indexed version that lets us use the index of the element in the query.
Copy the following code snippet as a query to LINQPad:
string sentence = ".NET Generics is a great API"; sentence.Split('').Reverse().ToList().ForEach(c=>Console.Write(c+""));Execute the query. You will get the following result:

Palindromes are fascinating and it is more fun to find them. Here we shall write a program to demonstrate how we can find whether a string is a palindrome or not, using the operators we have learned so far:
Copy the following code snippet as a query to LINQPad:
string sentence = "A Man, A Plan, A Canal, Panama"; //Listing the characters of the original input string. var original = sentence .ToLower() .Replace(" ",string.Empty) .Split(',') .SelectMany(c=>c.ToCharArray()); //Storing the reversed one. var reversed = original.Reverse(); //Checking if the original character sequence matches with the //reveresed one. string verdict = original.SequenceEqual(reversed) ? "This is a Palindrome" : "This is not a Palindrome"; Console.Write(verdict);Run the query. You will see the following output:
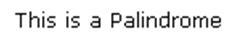
In this case, we are cleaning all the whitespaces. Then the cleaned string is tokenized by a comma (,) and this gives us a List of strings.
This is where SelectMany() steps in, to create an IEnumerable<char> from all the characters of the strings, of the string array generated out of Split(',') call.
So, the original now has the list of all the characters of all the words in the sentence.
Using original.Reverse();, we create an IEnumerable<char> that has all the characters in reverse order.
The next line compares these two character sequences using the operator: SequenceEqual(). If both the character streams are the same, the verdict will be set to "This is a Palindrome".
There are several long palindromic sentences. You can find a long list at http://www.cs.arizona.edu/icon/oddsends/palinsen.htm.
This operator allows us to sort the elements of the source collection depending on some parameter, if the type of the collection already implements IComparable. It also allows us to sort elements of a collection of user defined objects (denoted by T) by letting us pass an instance of IComparer<T> to it.
The following are some examples:
Copy the following code snippet as a query to LINQPad:
string[] names = { "Sam", "Pamela", "Dave", "Anders", "Erik" }; names.Dump("Before Alphabetical Sorting"); names = names.OrderBy(c => c).ToArray(); names.Dump("Alphabetically Sorted");Run the query. You will see the
namessorted, as shown in the following screenshot:
The following query uses a funny looking Lambda expression, which can be quite confusing at the first glance:
c => c
Which essentially means sort by the string itself.
Now, if you want to sort the elements by their length, here is how to make the change:
string[] names = { "Sam", "Pamela", "Dave", "Anders", "Erik" };
names.Dump("Before Sorting");
names = names.OrderBy(c => c.Length).ToArray();
names.Dump("Sorted by Length");And the results will be as follows:

Let's say we have an array of points in 2D and we want to sort them as per their X co-ordinates. Here is how to do it:
Copy the following code snippet as a query to LINQPad:
System.Drawing.PointF[] points = { new System.Drawing.PointF(0, -1), new System.Drawing.PointF(-1, 1), new System.Drawing.PointF(3, 3) }; var sortedPoints = points.Select(c=>new {X = c.X, Y = c.Y}).OrderBy(c => c.X).ToList(); sortedPoints.Dump("Sorted Points");Run the query. You should see the following output:
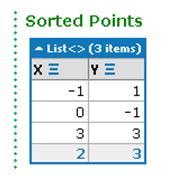
We have a List of points in 2D and we wanted to sort them by their X co-ordinates. We created an anonymous type out of these points and projected them to an IEnumerable<> by Select().
Next, OrderBy() comes and sorts this List by their X co-ordinates. This sorting intent has been described by the Lambda expression c => c.X.
At the end, we converted the result to a List of the anonymous type. Notice that the header of the table in the output, shown in the preceding screenshot, doesn't have any data type, as the result is of anonymous type.
Suppose, we have a List of some user-defined Student objects as follows:
Student[] someStudents =
{
new Student(){Age = 20, Course = "C#", Name = "Sam" },
new Student(){Age = 19, Course = "Ruby", Name = "Bobby" },
new Student(){Age = 18, Course = "F#", Name = "Shakira" }
};
//Sorting the students by their age.Can you sort these students by their age using the LINQ OrderBy() operator?
This operator does just the reverse of the OrderBy(), as the name suggests. OrderBy() sorts elements in ascending order, while this operator sorts everything in descending order.
After the source collection is sorted, if you want to sort it again by some other parameter, you shall have to use ThenBy(). This sorts the elements in ascending order like OrderBy(). However, if you want to sort elements in descending order, you shall have to use ThenByDescending().
Say we have a List called fruits. We shall first sort the List by the length of the fruit name and then sort the List alphabetically. The following snippet shows how we can do it:
Copy the following code snippet as a query to LINQPad:
string[] fruits = { "grape", "passionfruit", "banana", "apple", "orange", "raspberry", "mango", "blueberry" }; //Sort the strings first by their length. var sortedFruits = fruits.OrderBy(fruit => fruit.Length); sortedFruits.Dump("Sorted Fruits by Length");Run the query. You should get the following output:
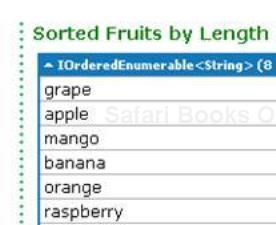
So you see the fruit names are sorted in ascending order of their length.
Now, let's see what happens if we sort the elements alphabetically, maintaining this primary sorting as per their length.
Change the query and paste the following query in LINQPad:
string[] fruits = {"grape", "passionfruit", "banana", "apple", "orange", "raspberry", "mango", "blueberry" }; //Sort the strings first by their length and then alphabetically. //preserving the first order. var sortedFruits = fruits.OrderBy(fruit => fruit.Length).ThenBy(fruit => fruit); sortedFruits.Dump("Sorted Fruits by Length and then Alphabetically");Run the query. You will get the following output:
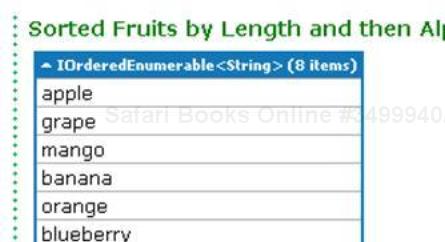
ThenBy() preserves the previous ordering of data, while a cascaded OrderBy() will only have the last one's order preserved.
The following is the first problem:
Group names by the first two characters. This can be used in indexing algorithms:
Copy the following code snippet as a query to LINQPad:
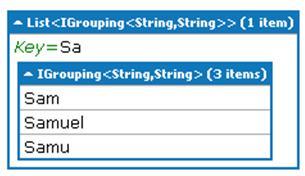
string[] names = { "Sam", "Samuel", "Samu", "Ravi", "Ratna", "Barsha" }; var groups = names.GroupBy(c => c.Substring(0, 2)); groups.Dump(); foreach (var gr in groups) { Console.WriteLine(gr.Key); foreach (var p in gr) Console.WriteLine("---- " + p); }Run the query. You shall get the following output:

GroupBy() returns an instance of IEnumerable<IGrouping<Tkey, TValue>>.
Assume this is a dictionary of dictionaries. TKey is the key of the entries and TValue is the value of the entries. So, in this case, each key will be associated with an IGrouping<string, string>.
The first part of the output (that is the table) is generated by the Dump() command. Here you can see how the data structure is organized within.
The second part is generated manually by iterating the group. Each group entry has a read-only property called Key, and this looping construct used is typically how you can extract data from a group (IGrouping<TKey, TValue>).
We have successfully created the index. Now you might ask the question, how do we get items for the particular Key, such as dictionaries?
Here is how to do it. Suppose I want to find out all the entries for the Key "Sa" from the preceding group. The syntax will be as follows:
groups.Where(c=>c.Key=="Sa").ToList().Dump();
Add the preceding line after the previous query in LINQPad and you should get the following output:
We can change the indexing key to anything we like. For example, say we want to group names as per their length. Only the Lambda expression will need the following change, everything else will remain the same. However, to give the output a better view, I changed the way the group key is printed:
Copy the following code snippet as a query to LINQPad:
string[] names = {"Sam", "Samuel", "Samu", "Ravi", "Ratna", "Barsha"}; var groups = names.GroupBy(c => c.Length); foreach (var gr in groups) { Console.WriteLine("Words of Length {0}", gr.Key); foreach (var p in gr) Console.WriteLine("----" + p); }Run the query. You should get the following output:

This operator can also be used to project elements of the collection using a specified generic result selector method. That way, we can only project the elements we need.
The following is an example:
Copy the following code snippet as a query to LINQPad:
//Some junk license plate numbers string[] licensePlateNumbers = {"MO 123 X#4552", "MO 923 AS#", "MAN HATTON", "MADONNA", "MARINE" }; var plateGroup = licensePlateNumbers.GroupBy(//Key selector lambda expression c => c.Substring(0, 2), //Result selector lambda expression (c, values) => values.Count()>2?values.Skip(2):values ); foreach (var pg in plateGroup) { Console.WriteLine(pg.ElementAt(0).Substring(0, 2)); foreach (var g in pg) { Console.WriteLine("----- " + g); } }Run the query and you will get the following output:

In this example, we have used an overloaded version of the method. It takes two Lambda expressions. The first one is the key selector, which will determine the keys of the elements added in the group. The second one is called the result selector, which is a function to create a result value from each group.
Let's see, what it means:
//Key selector lambda expression c => c.Substring(0, 2)
This means we need to take only the first two characters of the string as the key of the group:
//Result selector lambda expression (c, values) => values.Count()>2?values.Skip(2):values
This means if the strings matching the key are more than two, then skip the first two elements and put the rest as the result.
Now, note that there are three license plate numbers starting with "MA". That's why the first two are skipped from the result. However, plates starting with "MO" were only two in number, thus, they appear as it is in the result.
Try removing the second Lambda and you should get the following output:

In this section, we will discuss the following Set operators:
This is a Set operator. This returns the intersection (or the common elements) of two collections. There are two overloaded versions of this method. The first one takes a collection of type IComparable, so explicit IEqualityComparer is not needed.

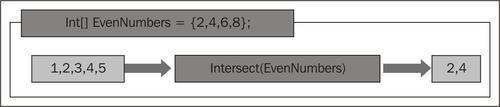
Say we have two string lists and we want to find out what the common elements in them, are here is how we can do that using Intersect() on List<T>.
Follow the given steps:
Copy the following code snippet as a query to LINQPad:
List<string> nameList1 = new List<string>(){"Anders", "David", "James", "Jeff", "Joe", "Erik"}; List<string> nameList2 = new List<string>() {"Erik","David","Derik"}; var commonNames = nameList1.Intersect(nameList2); foreach (var name in commonNames) Console.WriteLine(name);Run the query. You will see the following output:

Intersect() returns an IEnumerable<T>, including only the elements that appear in both the collections. Intersect() has two overloaded versions. One works with the primitive data type and the other requires an explicit IEqualityComparer to know how to compare the elements of the collection.
The order in which the results appear in the result collection, depends on the sequence of calling.
Note that the sequence of appearance of the objects, in the intersected List, is that of the first collection or the collection on which this operator is invoked.
So, if you change the invoking object to the second collection, we shall get a different order:
Copy the following code snippet as a query to LINQPad:
List<string> nameList1 = new List<string>(){"Anders", "David", "James", "Jeff", "Joe", "Erik"}; List<string> nameList2 = new List<string>(){"Erik","David","Derik"}; var commonNames = nameList2.Intersect(nameList1); foreach (var name in commonNames) Console.WriteLine(name);Run the query. You will see the following output:

This happened because "Erik" appears before "David" in the invoking collection.
However, if you must enforce alphabetical order, use OrderBy(c=>c) on the result obtained.
See this action in the following diagram:
The other version, however, needs to know how to compare objects in the collection. So, an IEqualityComparer needs to be passed explicitly.
This operator provides what a set union is for any collection that implements IEnumerable<T>. This, unlike Concat(), removes the duplicates.
Union(), like Intersect(), has two overloaded versions. The first one deals with the collections of type that implements IComparable.

The other one needs an explicit IEqualityComparer for comparing objects in the collection.

The following diagram shows how Union() works:
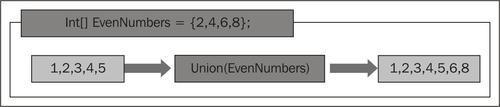
Copy the following code snippet as a query to LINQPad. Using the previous example, the change is highlighted:
List<string> nameList1 = new List<string>(){"Anders", "David", "James", "Jeff", "Joe", "Erik"}; List<string> nameList2 = new List<string>(){"Erik","David","Derik"}; var commonNames = nameList1.Union(nameList2); foreach (var name in commonNames) Console.WriteLine(name);Run the query. You should see the following output:

Union() returns a list of all the strings in both the collections, removing duplicates. Like Itersect(), it also has an overloaded version that needs an IEqualityComparer instance to compare elements of the collection.
As "Erik" and "David" appear in both the lists, they are added only once.
Follow the given steps:
Just change the preceding query by replacing
Union()withConcat().Run the query and you should see the following output:

However, you can still get the same result as Union() if you apply a Distinct() operator on this result. Distinct() removes the duplicates from a collection.
This operator returns the mutually exclusive elements of two collections. This operator extracts the elements present in one collection and not in the other one. Like Union() and Intersection(), Except() also has two overloaded versions. The first one takes an instance IEnumerable<T>, where T implements IComparable. While the other version does need an IEqualityComparer interface:

The following diagram shows how Except() works:
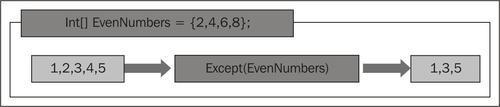
Follow the given steps:
Copy the following code snippet as a query to LINQPad:
List<string> nameList1 = new List<string> (){"Anders", "David", "James", "Jeff", "Joe", "Erik"}; List<string> nameList2 = new List<string>() {"Erik", "David", "Derik"}; //This will store the names that appear in nameList2 but not in //nameList1. var exclusiveNames = nameList2.Except(nameList1); foreach (var v in exclusiveNames) Console.WriteLine(v);Run the query. You should get the following output:

The name "Derik" is present only in nameList2 and not in nameList1, so it is returned. However, the sequence matters! Suppose, we want to find out what is in collection A and not in collection B, then the call will be made to Except() such as A.Except(B) and vice-versa.
So, we change the invoking collection to nameList1 as follows:
var exclusiveNames = nameList1.Except(nameList2);
The output will be as shown in the following screenshot:

Like its cousins Intersect() and Union(), Except() also comes with a different version, where you can pass an EqualityComparer<T> instance that will tell it how to compare the elements of the source collection.
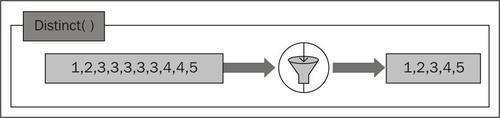
This removes any duplicate from the given source collection. This method has two versions. If the type of the collection has implementation of IComparable then the method doesn't need any explicit IEqualityComparer to compare objects in the source collection.

Assume that you are writing software for a radio station, where songs are played on demand. Lot of people send the same song ID as a request. The radio jokey wants to make sure he/she plays the song only once. In such a queue, removing duplicates is needed. Distinct() does this quite gracefully.
Copy the following code snippet as a query to LINQPad:
string[] songIds = {"Song#1", "Song#2", "Song#2", "Song#2", "Song#3", "Song#1"}; //This will work as strings implement IComparable var uniqueSongIds = songIds.Distinct(); //Iterating through the list of unique song IDs foreach (var songId in uniqueSongIds) Console.WriteLine(songId);Run the query. You should see the following output:

Assume, Distinct() as a filter that removes duplicate items and returns a collection with only unique items:
However, if that's not the case, an IEqualityComparer is passed, which will be needed to compare objects of the source collection.

In order to use this second version, we shall have to write a custom comparer first by implementing IEqualityComparer<T> for the Student class.
Assume we already have a Student class with the public property ID:
public class StudentComparer : IEqualityComparer<Student>
{
#region IEqualityComparer<Student> Members
bool IEqualityComparer<Student>.Equals(Student x, Student y)
{
//Check whether the compared objects reference the same data.
if (Object.ReferenceEquals(x, y))
return true;
//Check whether any of the compared objects is null.
if (Object.ReferenceEquals(x, null) || Object.ReferenceEquals(y, null))
return false;
//If two students have same ID
//they are same
return x.ID == y.ID;
}
int IEqualityComparer<Student>.GetHashCode(Student obj)
{
return obj.GetHashCode();
}
#endregion
}After we have this in place, we can use this to call the second version of Distinct() as follows:
List<Student> uniqueStudents = someStudents.Distinct(new StudentComparer()).ToList();
In this section, we will discuss the following Conversion operators:
This method converts the IEnumerable<T> to Array<T>. This is used if you want to project your data as an array of the result set. This calls for immediate execution of the query:

The main objective is to generate a strongly typed array, instead of using the var keyword (which is also strongly typed). If the source collection is empty, it doesn't complain and returns an empty array.
Here is an example:
Copy the following code snippet as a query to LINQPad:
string[] firstNames = {"Samuel", "Jenny", "Joyace", "Sam"}; string[] matchingFirstNames = firstNames.Where(name=>name.StartsWith("Sa")).ToArray(); matchingFirstNames.Dump("Name Array");Run the query. It will result in the following output:
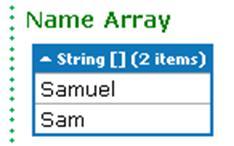

Follow the given steps:
Copy the following code snippet as a query to LINQPad:
string[] firstNames = { "Samuel", "Jenny", "Joyace", "Sam" }; List<string> matchingFirstNames = firstNames.Where(name=>name.StartsWith("Sa")).ToList(); matchingFirstNames.Dump("Name List");Run the query. You should get the following output:
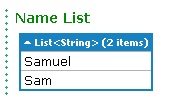
This proves that ToList<T>() essentially converts the results to a List<T>. This operator can come in particularly handy when we need to use the ForEach() method of List<T> for running some action on each element of the collection. However I don't recommend heavy usage of these conversion operators as these affect query performance.
This operator lets us create a Dictionary out of the source collection by letting us tag each element of the collection. All the elements in the source collection will be keys of the dictionary. As a dictionary can't have duplicate keys, it will throw an exception complaining about a duplicate key being added.
Copy the following code snippet as a query to LINQPad:
List<string> boys = new List<string> {"Anders", "Anders", "David", "James", "Jeff", "Joe", "Erik"}; List<string> girls = new List<string> {"Anna", "Anzena", "Dorothy", "Jenny", "Josephine", "Julee"}; List<string> nameList1 = new List<string>() {"Anders", "Anna", "Joe", "Jenny", "Anzena", "Josephine", "Erik"}; Dictionary<string, string> nameMap = nameList1.ToDictionary(c => c,c=>boys.Contains(c)?"boy":"girl"); nameMap.Keys.Dump("All Members"); nameMap.Keys.Where(c => nameMap[c] == "boy").Dump("Boys"); nameMap.Keys.Where(c => nameMap[c] == "girl").Dump("Girls");Run the query. You will see the following output:
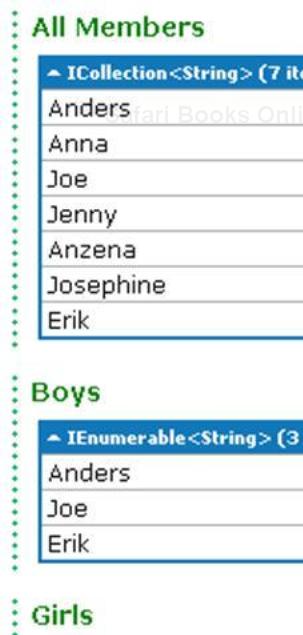
The Lambda expression c => c,c=>boys contains(c)?"boy":"girl" means that if c is in the List of boys names (boys) then return boy as the value for this key else return girl in the resultant Dictionary.
The first Dump() command nameMap.Keys.Dump("All Members"); prints all the names.
The second Dump() command nameMap.Keys.Where(c => nameMap[c] == "boy").Dump("Boys"); first does a filtering over the Dictionary to find the boys names and then only prints them.
The third command nameMap.Keys.Where(c => nameMap[c] == "girl").Dump("Girls"); does the same thing for girls.
This returns a one-to-many lookup table from the given source collection as per the provided keySelector() method. There are four different overloaded versions of this method. It also lets us select the elements of the source collection that we want to use in the conversion.
The following is an example that uses the first version, which just takes a Lambda expression as the keySelector():

Suppose, we have a List of names and we want to index them as per the first two letters of these names:
Copy the following code snippet as a query to LINQPad:
string[] firstNames = { "Samuel", "Jenny", "Joyace", "Sam" }; var map = firstNames.ToLookup(c => c.Length); foreach (var m in map) { Console.WriteLine(m.Key); foreach (var n in m) { Console.WriteLine("--" + n); } }Run the query and you should get the following output:

Copy the following code snippet as a query to LINQPad:
string[] names = {"Sam", "Danny", "Jeff", "Erik", "Anders","Derik"}; string firstName = names.First(); string firstNameConditional = names.First(c => c.Length == 5); firstName.Dump("First Name"); firstNameConditional.Dump("First Name with length 5");Run the query. The following output will be generated:
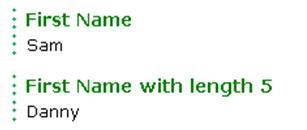
There are two overloaded versions of the method. The first one doesn't take an input and returns the first element of the collection. The second version takes a predicate in the form of a Lambda expression and returns the first matching element.
So, in this case, the first element is returned when First() is used, on the other hand the second call returns the first name of length 5 matching the Lambda expression.
Please note that there is no sorting involved. So don't expect the first element after sorting. First() picks elements as they are laid out.
If there is no element in the source collection, it throws InvalidOperationException like Single(). That's why there is FirstOrDefault like SingleOrDefault.
First() checks whether there is more than one element present in the collection. Single() does the same thing. However, First(Func<T, bool>) does not complain if there is more than one element in the collection, matching the given Lambda expression. However, Single() throws an exception if there is more than one element in the sequence, matching the Lambda expression pattern.
Follow the given steps:
Copy the following code snippet as a query to LINQPad:
string[] names = {}; string defaultName = names.FirstOrDefault(); defaultName.Dump();Run this query. You will see the following output:
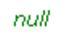
As there is no element in the array names, FirstOrDefault()
puts the default value for the string (which is null) in the variable defaultName.
It's the same as First(); however, it returns the last element instead. It throws an exception if there is no element. If you want to push the default value when the collection is empty, use LastOrDefault() instead, which works in exactly the same way as FirstOrDefault().
It's the same as FirstOrDefault(). It doesn't throw an exception if there is no element, rather it fills the blank with the default value.
This operator checks whether two given instances of IEnumerable<T> are the same or not by comparing the elements by the default comparer. Otherwise, if the type doesn't have a default comparer implementation, then the overloaded version allows you to pass in a IEqualityComparer.
Here is an example, where SequenceEquals
and Reverse are used together to find whether a sequence of strings is palindromic in nature or not.
Change the language to C# Program in the Language box of LINQPad.
Paste the following query in LINQPad:
static bool IsPalindromic(string sentence) { List<string> wordsInOrder = sentence.Split(' ').ToList(); List<string> wordsInReverseOrder = sentence.Split(' ').Reverse().ToList(); return wordsInOrder.SequenceEqual(wordsInReverseOrder); } void Main() { string response = IsPalindromic("Veni, vidi, vici") ? ""Veni, vidi, vici" Is Palindromic":""Veni, vidi, vici" Is Not Palindromic"; response.Dump(); response = IsPalindromic("Nada Ney Nada") ? ""Nada, Ney, Nada" Is Palindromic":""Nada, Ney, Nada" Is Not Palindromic"; response.Dump(); }Run the query. This should generate the following output:

In the IsPalindromic() method, the original sentence is split into words and then these words are stored in a collection. Next, this collection of words is reversed and stored into another List.
Then these two collections are checked for equality. Like other standard operators SequenceEqual() has another overloaded version that takes an EqualityComparer, which tells it how to compare items of the collection that don't already implement IComparable<>.
This operator returns the element at the index that is passed. This operates on a zero-based indexing as in an array. Using this Extension method, you can peek through any data structure that implements the IEnumerable<T> interface, a Stack for instance.
However, use this judiciously as there is no other way than a linear search to get to the element at index i in an unsorted source collection. If you are needing this method quite often, you are better off reviewing your existing design.
Copy the following as a query to LINQPad:
Stack<string> tags = new Stack<string>(); tags.Push("<html>"); tags.Push("<body>"); List<string> tagList = new List<string>(); tagList.Add("<html>"); tagList.Add("<body>"); Queue<string> queue = new Queue<string>(); queue.Enqueue("<html>"); queue.Enqueue("<body>"); LinkedList<string> linkedTags = new LinkedList<string>(); linkedTags.AddLast("<html>"); linkedTags.AddLast("<body>"); string lastStackTag = tags.ElementAt(tags.Count - 1); string lastListTag = tagList.ElementAt(tagList.Count - 1); string lastQueueTag = queue.ElementAt(queue.Count - 1); string lastLinkedListTag = linkedTags.ElementAt(linkedTags.Count - 1); lastStackTag.Dump("Last Stack<T> Element"); lastListTag.Dump("Last List<T> Element"); lastQueueTag.Dump("Last Queue<T> Element"); lastLinkedListTag.Dump("Last LinkedList<T> Element");Run the query and you should see the following output:

Internally, the elements are stored differently for different data structures. Thus, for Stack<> the last element stored at lastStackTag comes as <html> instead of <body>, as you would expect for a List<>. All the list-based containers, however, store the element in the same way.
It's the same as ElementAt(). However, this one won't complain if there isn't an element in the location at index i, unlike ElementAt() that will throw an exception if it doesn't find an element at the index mentioned.
So, if there is no element in the source collection at the given index, this method returns the default value of that data type.
The following is an example:

The value of ElementAt() and ElementAtOrDefault() is not very evident on the collections that primitively support zero-based indexing; such as list and array.
However, it can be pretty useful for other containers such as stack, which doesn't offer a peek at elements. ElementAtOrDefault() saves you from extensive usage of exception handling techniques.
This is kind of misnamed. It should instead be called SetDefaultIfEmpty(), because it allows you to set a default value as the sole value of an IEnumerable<T> instance; unlike ElementAtOrDefault() that forces you to choose the .NET CTS default value for that particular data type.
This can be particularly handy when working with external resources such as web services. Assume you are writing a weather monitoring application and if the service hasn't responded back within a predefined time span, you would want one of your variables—that you and your team have agreed upon—to be set to a default value.
Follow the given steps:
Copy the following as a query to LINQPad:
public static List<double> GetLastWeekHumidity() { //Assume this is where we get the result from the Web Service List<double> humidityThisWeek = new List<double>(); //Assume Web Service didn't return anything return humidityThisWeek.DefaultIfEmpty(80.0).ToList(); } static void Main() { List<double> humidity = GetLastWeekHumidity(); humidity.Dump("Humidity"); }Run the query. You should see the following output:

DefaultIfEmpty() allows you to push only one default value in the source collection. In this case, 80.0 was pushed and ToList() converted the result to a List<double>.
In this section, we will discuss the following Generation operators:
Suppose we want a List of constantly increasing positive integers starting from a seed number. This can be done by a single loop. However, using Range() solves the problem very easily. Range() is a static method of the Enumerable class.
Say, for example, we want integers 1 to 10.
Here is how to create that using Range().
Copy the following as a query to LINQPad:
var naturalNumbers = Enumerable.Range(1, 10); naturalNumbers.Dump("First 10 Natural Numbers");Run the query and you should get the following output:

Assume that you want to find all the numbers in the previously-mentioned range that are multiples of 11. Here is how we can do that using Range() and Where():
Copy the following as a query to LINQPad:
var multiplesOfEleven = Enumerable.Range(1, 100).Where(c => c % 11 == 0); multiplesOfEleven.Dump("Multiples of 11 from 1 to 100");Run the query and you should get the following output:

Follow the given steps:
Copy the following as a query to LINQPad:
Enumerable.Repeat<string>("World is not enough", 5) .ToList() .ForEach(c => Console.Write(c+Environment.NewLine));Run the query. This will display the following output:

The Repeat() method works on a string type in the current query and the string to be repeated is passed as "World is not enough" and it has to be repeated five times.
Then ToList()
converted it to a List<string> and then ForEach() is used to print the result.
In this section, we will discuss the following Quantifier operators:
This is used to find out if there is only one element in the source collection that matches a given condition. There are two overloaded versions of this method.
The first one doesn't take any parameter and only checks whether there is more than one element present in the source. If there is more than one element, the invocation of this method throws InvalidOperationException and complains that the sequence contains more than one element. However, if the sequence contains only one element then this version returns that element:

Here is an example that uses the second version of Single() taking a Lambda expression as the predicate:

Copy the following as a query to LINQPad:
string[] names = { "Sam", "Danny", "Jeff", "Erik", "Anders" }; string onlyOne = names.Single(c => c.StartsWith("Dan")); onlyOne.Dump("Only name with Dan*");Run the query and you should get the following output:

This will have "Danny" stored in onlyOne as that's the only name in the sequence names that starts with "Dan". However, the following snippet will throw an exception as there is more than one element in the source collection:
What will happen when the following code snippet gets executed:
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 }; int n = numbers.Single(c => c % 2 == 0 && c % 5 == 0);It will throw an exception
It will not compile
It will return 10 in
n
What will happen when the following code snippet gets executed:
int[] numbers = {3,4,5,6}; int n = numbers.Single(c => c % 2 == 0 && c>6);It will throw an exception
It will not compile
It will return 10 in
n
As you can probably see, usage of Single() in a code can lead to an exception, if the source collection is not having exactly one element. However, to solve this problem, SingleOrDefault() was added to LINQ.
If no element is found in the source collection or if no element is found matching the given Lambda expression, then SingleOrDefault() returns the default value for the type of the source collection. For example, if the collection is of type Strings, then it will return null, if it is of System.Int16 it will return 0, and so on.
A few default values are listed in the following table:
|
Type |
Default value |
|---|---|
|
System.Int16 |
0 |
|
System.Int32 |
0 |
|
String |
Null |
|
DateTime |
1/1/0001 12:00:00 AM |
|
System.Double |
0.0 |
Follow the given steps:
Copy the following as a query to LINQPad:
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}; int n = numbers.SingleOrDefault(c => c % 2 == 0 && c % 6 == 0); n.Dump();Run the query and you will see the following output:
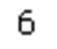
Output is 6 because numbers has 2 and 6 and only 6 matches the predicate passed as the argument to the SingleOrDefault() method call.
The following diagram explains how the SingleOrDefault() method behaves in two different situations:
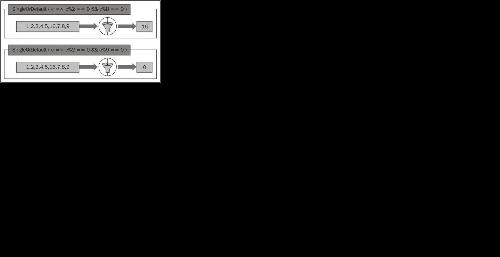
So SingleOrDefault() is just Single() with the default value attached. So, if you think usage of Single() can cause trouble and you wouldn't mind having the default value set to the return variable, SingleOrDefault() is the perfect package.
However, for obvious reasons such as you don't want to have the default value assigned to the return variable SingleOrDefault() can't be used to replace Single() calls.
This is used to find whether there are any element in the source collection. There are two overloaded versions. The first one checks whether there is any element in the source collection or not. This is more like checking whether the source collection is empty or not:

The other version takes a Lambda expression and returns true if any (can be more than one, unlike Single() or SingleOrDefault()) of the elements in the source collection satisfy the predicate described by the Lambda expression:

Here is a snippet that describes this operator:
Follow the given steps:
Copy the following as a query to LINQPad:
string[] names = {"Sam", "Danny", "Jeff", "Erik", "Anders","Derik"}; bool z = names.Any(); bool x = names.Any(c => c.Length == 5); z.Dump("There are some elements"); x.Dump("There is at least one element with length 5");Run the query and you will get the following output:

Both x and z will be true, in this case, as the source collection (names in this case) has some elements and a couple of them have a length of 5.
Unlike Single(), Any() doesn't complain if there is no element in the source collection or any that matches the Lambda expression.
This operator allows us to check whether all the parameters in the source collection satisfy the given condition. This expression can be passed to the method as a Lambda expression:

Suppose, we have a List of integers and we want to check whether all of them are even or not. This is the best method to do these kinds of operations.
Follow the given steps:
Copy the following as a query to LINQPad:
int[] numbers = { 0, 2, 34, 22, 14 }; bool allEven = numbers.All(c => c % 2 == 0); string status = allEven? "All numbers are even":"All numbers are not even"; status.Dump("Status");Run the query and you should get the following output:

As all the elements in numbers are even, allEven will be set to true.
In this section, we will discuss the following Merging operators:
This operator lets us combine the values of several collections and project them in a single collection of type IEnumerable<T>. This has only one version as follows:

The second argument is the Lambda expression that explains how we want these projections to be made. That's why it is called resultSelector
as it determines how the result will look. Assume this operator as a normal zipper of your bag. The following is a simple representation of how this operator works:

Say we have a list of first names, a last name and a set of salutations. We can zip all these together in a single List<string> as follows:
Copy the following as a query to LINQPad:
string[] salutations = {"Mr.", "Mrs.", "Ms", "Master"}; string[] firstNames = {"Samuel", "Jenny", "Joyace", "Sam"}; string lastName = "McEnzie"; salutations.Zip(firstNames, (sal, first) => sal + " " + first); .ToList(); .ForEach(c => Console.WriteLine(c + " " + lastName));Run the query and you should get the following output:

The Lambda expression: (sal, first) => sal + " " + first does the magic of concatenating the salutation and the first name of all the "McEnzie" family members.
Now once that is done, ToList() converts the resultant IEnumerable<string> holding the concatenated salutation and first name to a List<string> such that using ForEach()
last name can be concatenated to all of them in a single line of code.
That's how we get the list of names printed.