
Chapter 9. Performance and profiling
This chapter covers
- Measuring performance with the xUnit.Performance library
- Profiling with PerfView
- Options on Linux for performance profiling
Premature optimization is the root of all evil.
Sir C. Antony R. Hoare
This quote by Sir Tony Hoare, popularized by Donald Knuth, is perhaps the most misunderstood guidance for writing applications that perform well. Optimizations, in this context, refer to CPU cycle counting and tuning low-level operations. Programmers love to do these things, but they can often get lost in the minutiae and miss the big picture. Sir Tony wasn’t trying to tell us to forgo considering performance when designing our applications. He was warning us against getting mired down in optimizing the wrong things.
The Bing search engine has an internal plugin system. Teams build services (plugins) that receive the search query sent by the user, and they must provide a response within a certain time limit. If the service responds too slowly, the Bing infrastructure notifies the team of the performance issue and turns off the plugin. In order to provide a new feature in Bing, teams must meet the performance criteria.
Learn more about .NET performance
If you want to learn more about performance from one of the engineers that built the Bing system, seek out Ben Watson’s book, Writing High-Performance .NET Code (Ben Watson, 2014).
Let’s contemplate how you’d build a new feature in this environment. You wouldn’t start by writing code and optimizing blindly. You’d start by measuring everything. What data store provides the fastest response while still providing the functionality you need? Where are the bottlenecks as scale increases? What are all the components in your service, and how much time do they take to respond?
Good perf does not just happen. You have to plan, and to plan you have to measure.
Vance Morrison
In this chapter, we’ll explore how you can measure and analyze performance in .NET Core. Every application works differently, so it’s up to the developers to determine performance targets. There’s no “go faster” button in software development, which is why measurement is paramount. We’ll go through some examples of identifying poor-performing code, analyzing why it’s slow, and making iterative adjustments.
9.1. Creating a test application
Back in chapter 3 you built a small CSV parser. In this chapter you’ll build a CSV writer. Writing large amounts of data to files is a fairly common task for C# applications. If you want your CSV-writing library to succeed, you’ll need to outperform the other libraries.
First you’ll build some simple CSV-writing code. Then we’ll look at how you can measure it.
Start by creating a new library called CsvWriter: dotnet new library -o CsvWriter. Create a new class called SimpleWriter, and add the following code.
Listing 9.1. A SimpleWriter class that writes comma-separated values to a stream
using System;
using System.Collections.Generic;
using System.IO;
namespace CsvWriter
{
public class SimpleWriter
{
private TextWriter target;
private string[] columns;
public SimpleWriter(TextWriter target)
{
this.target = target;
}
public void WriteHeader(params string[] columns) 1
{
this.columns = columns;
this.target.Write(columns[0]);
for (int i = 1; i < columns.Length; i++)
this.target.Write("," + columns[i]);
this.target.WriteLine();
}
public void WriteLine(Dictionary<string, string> 2
values)
{
this.target.Write(values[columns[0]]);
for (int i = 1; i < columns.Length; i++)
this.target.Write("," + values[columns[i]]);
this.target.WriteLine();
}
}
}
- 1 Specifies name and order of columns
- 2 Dictionary has key/value pairs with keys matching column names
For those not familiar with C#
The params keyword allows the caller to specify a variable number of arguments. The caller doesn’t need to create the string array themselves—C# will do this automatically. This makes the code easier to read. See the unit test code to find out how this is used.
Next, create an xUnit project to test the functionality of SimpleWriter. Use the command dotnet new xunit -o CsvWriterUnitTests. Copy the Marvel.csv file from chapter 3 to the new project folder (or use the sample code that accompanies this book). Be sure that Marvel.csv has an empty line at the end.
Then modify the project file as follows.
Listing 9.2. Modifying the project file for CsvWriterUnitTests
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netcoreapp2.0</TargetFramework>
<IsPackable>false</IsPackable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.NET.Test.Sdk"
Version="15.3.0" />
<PackageReference Include="xunit" Version="2.2.0" />
<PackageReference Include="xunit.runner.visualstudio"
Version="2.2.0" />
<ProjectReference 1
Include="../CsvWriter/CsvWriter.csproj" />
</ItemGroup>
<ItemGroup>
<EmbeddedResource Include="Marvel.csv" /> 2
</ItemGroup>
</Project>
- 1 Add reference to CsvWriter
- 2 Embed Marvel.csv.
Finally, you’ll build a unit test to make sure SimpleWriter is able to produce the same output as your original file. In the UnitTest1.cs file created with the unit test project, add the code from the following listing.
Listing 9.3. Unit test for SimpleWriter
using System;
using System.Collections.Generic;
using System.IO;
using System.Reflection;
using Xunit;
using CsvWriter;
namespace CsvWriterUnitTests
{
public class UnitTest1
{
const string Marvel = "Marvel Studios"; 1
const string Fox = "20th Century Fox";
[Fact]
public void TestSimpleWriter()
{
var memoryStream = new MemoryStream(); 2
var streamWriter = new StreamWriter(memoryStream);
var simpleWriter = new SimpleWriter(streamWriter);
WriteMarvelCsv(simpleWriter);
streamWriter.Flush(); 3
memoryStream.Seek(0, SeekOrigin.Begin); 4
var streamReader = new StreamReader(memoryStream);
var testString = streamReader.ReadToEnd(); 5
var refString = GetReferenceMarvelCsv();
Assert.Equal(refString, testString);
}
private void WriteMarvelCsv(SimpleWriter simpleWriter)
{
simpleWriter.WriteHeader("Year", "Title", 6
"Production Studio");
var values = new Dictionary<string, string>();
values["Year"] = "2008";
values["Title"] = "Iron Man";
values["Production Studio"] = Marvel;
simpleWriter.WriteLine(values);
values["Title"] = "The Incredible Hulk";
simpleWriter.WriteLine(values);
values["Title"] = "Punisher: War Zone";
simpleWriter.WriteLine(values);
values["Year"] = "2009";
values["Title"] = "X-Men Origins: Wolverine";
values["Production Studio"] = Fox;
simpleWriter.WriteLine(values);
values["Year"] = "2010";
values["Title"] = "Iron Man 2";
values["Production Studio"] = Marvel;
simpleWriter.WriteLine(values);
values["Year"] = "2011";
values["Title"] = "Thor";
simpleWriter.WriteLine(values);
values["Title"] = "X-Men: First Class";
values["Production Studio"] = Fox;
simpleWriter.WriteLine(values);
}
private string GetReferenceMarvelCsv()
{
var stream = typeof(UnitTest1).GetTypeInfo().Assembly.
GetManifestResourceStream( 7
"CsvWriterUnitTests.Marvel.csv");
var reader = new StreamReader(stream);
return reader.ReadToEnd();
}
}
}
- 1 Make these constants, because they’re reused.
- 2 MemoryStream manages an in-memory buffer for you.
- 3 Guarantees StreamWriter has written everything to the MemoryStream
- 4 Rewinds MemoryStream to the beginning
- 5 Reads the contents of the MemoryStream to a string
- 6 The params keyword on WriteHeader will turn the arguments into an array.
- 7 Reads the embedded Marvel.csv file
Run the test to make sure everything works correctly.
Once you’ve verified that this works properly, how well does it perform? You could put timers into the unit test, but that doesn’t provide much information, and it may yield inconsistent results. Luckily, there’s a .NET Standard library for performance testing called xUnit.Performance.
9.2. xUnit.Performance makes it easy to run performance tests
In test-driven development (TDD), test cases are written from requirements, and developers iterate on the software until it passes all the tests. TDD tends to focus on small units of code, and unit-testing frameworks (like xUnit) help developers get quick feedback. The xUnit.Performance library offers a similar feedback loop on performance. It allows you to try new things and share your performance tests and results with others in a standardized way.
xUnit.Performance is still in the beta stage, so it’s not as polished as xUnit. If you find it useful, I encourage you to participate in the project (https://github.com/Microsoft/xunit-performance). Because of the early stage of development, you’ll need to create your own harness and get the NuGet packages from a different NuGet feed (chapter 12 has more on NuGet feeds).
Start by creating a file called nuget.config in the parent folder of your projects with the following contents.
Listing 9.4. nuget.config file with local feed
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<packageSources>
<add key="dotnet-core" value= 1
"https://dotnet.myget.org/F/dotnet-core/api/v3/index.json" />
</packageSources>
</configuration>
- 1 The dotnet-core myget feed has beta projects.
Then, create a new console project called CsvWriterPerfTests with the command dotnet new console -o CsvWriterPerfTests. Modify the project file to include a reference to xUnit.Performance, as follows.
Listing 9.5. Add reference to xUnit.Performance in the CsvWriterPerfTests project file
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>netcoreapp2.0</TargetFramework>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="xunit.performance.api" Version="1.0.0-*" />
</ItemGroup>
</Project>
The Program.cs file will serve as the harness for running the performance tests. With regular xUnit, you don’t have to do this because an entry point is provided via the xunit.runner.visualstudio package. Fortunately, as the following listing shows, creating the harness is simple.
Listing 9.6. Program.cs modified to start the xUnit.Performance test harness
using System.Reflection;
using Microsoft.Xunit.Performance.Api;
namespace CsvWriterPerfTests
{
class Program
{
static void Main(string[] args)
{
using (var harness = new XunitPerformanceHarness(args))
{
var entryAssemblyPath = Assembly.GetEntryAssembly().Location;
harness.RunBenchmarks(entryAssemblyPath); 1
}
}
}
}
- 1 Tells the harness to search for tests in the current assembly
Now, create a performance test. Writing a performance test is a bit different than writing a unit test. The performance test will run many iterations and compute averages, because factors beyond your control can affect the measurements from one execution to the next. Also, you need to consider that the memory use of the test code can affect the measurement of the product code, because the garbage collector will pause threads regardless of where they are.
You know that your code is functionally correct, so you don’t need to verify the output during a performance test. But keep in mind that code, especially multithreaded code, can produce inconsistent results under stress. To detect this, you can write stress tests. Stress tests usually run for long periods of time (hours to days) and try to simulate heavy user load. For performance testing, we generally only care about speed.
Add a class called PerfTests with the following code.
Listing 9.7. PerfTests class with a test of the SimpleWriter class
using System.Collections.Generic;
using System.IO;
using System.Text;
using Microsoft.Xunit.Performance;
using CsvWriter;
namespace CsvWriterPerfTests
{
public class PerfTests
{
[Benchmark(InnerIterationCount=10000)] 1
public void BenchmarkSimpleWriter()
{
var buffer = new byte[500000]; 2
var memoryStream = new MemoryStream(buffer);
var values = new Dictionary<string, string>(); 3
values["Year"] = "2008";
values["Title"] = "Iron Man";
values["Production Studio"] = "Marvel Studios";
foreach (var iteration in Benchmark.Iterations)
{
using (var streamWriter = new StreamWriter( 4
memoryStream, Encoding.Default, 512, true)) 5
{
using (iteration.StartMeasurement())
{
var simpleWriter = new SimpleWriter(streamWriter);
simpleWriter.WriteHeader("Year", "Title", "Production Studio");
for (int innerIteration = 0;
innerIteration < Benchmark.InnerIterationCount;
innerIteration++) 6
{
simpleWriter.WriteLine(values);
}
streamWriter.Flush();
}
}
memoryStream.Seek(0, SeekOrigin.Begin); 7
}
}
}
}
- 1 Number of lines you’ll write to the CSV
- 2 Creates a static memory buffer ahead of time
- 3 Preps the dictionary ahead of time
- 4 Creates StreamWriter outside of measurement
- 5 512 is the buffer size for the StreamWriter; “true” leaves the stream open.
- 6 Writes many lines to the CSV
- 7 Rewinds the stream before the next iteration
Use the following command to execute the performance test:
dotnet run --perf:collect stopwatch 1
- 1 Does only stopwatch timing of the iterations
In the System.Diagnostics namespace, there’s a StopWatch class. It has Start and Stop methods and a set of properties for getting the elapsed time. The stopwatch is implemented on all operating systems. When running performance tests on non-Windows platforms, only timing operations via StopWatch are supported, so you only get the times for the tests. If you’re running on Windows, other facilities are available, such as kernel ETW events and CPU performance counters that can give you in-depth data, such as CPU branch mispredictions or how often you’re hitting the L2 cache. That kind of performance data is beyond the scope of this book.
As part of the test, xUnit.Performance will write the test results table to the console. It will also put the results into a CSV, a Markdown file, and an XML file. The results should look similar to those in table 9.1.
Table 9.1. Test results from performance benchmark of SimpleWriter with 10k lines written to memory
|
Test Name |
Metric |
Iterations |
AVERAGE |
STDEV.S |
MIN |
MAX |
|---|---|---|---|---|---|---|
| BenchmarkSimpleWriter | Duration | 100 | 2.229 | 0.380 | 1.949 | 5.077 |
In table 9.1, the measurements are in milliseconds. On average, SimpleWriter only takes 2.229 milliseconds to write 10,000 lines.
Let’s see what happens when you write to a file instead of memory. Add another method to PerfTests.cs, as follows.
Listing 9.8. Measures the performance of writing to a file instead of memory
[Benchmark(InnerIterationCount=10000)] 1
public void BenchmarkSimpleWriterToFile()
{
var values = new Dictionary<string, string>();
values["Year"] = "2008";
values["Title"] = "Iron Man";
values["Production Studio"] = "Marvel Studios";
int outerIterations = 0;
foreach (var iteration in Benchmark.Iterations)
{
var fileStream = new FileStream(
$"tempfile{outerIterations++}.csv", 2
FileMode.Create, 3
FileAccess.Write);
using (var streamWriter = new StreamWriter(fileStream,
Encoding.Default, 512, false)) 4
{
using (iteration.StartMeasurement()) 5
{
var simpleWriter = new SimpleWriter(streamWriter);
simpleWriter.WriteHeader("Year", "Title", "Production Studio");
for (int innerIteration = 0;
innerIteration < Benchmark.InnerIterationCount;
innerIteration++)
{
simpleWriter.WriteLine(values);
}
streamWriter.Flush(); 6
}
}
}
}
- 1 Start off with a low count and increase based on time for inner loop
- 2 Writes to a different file for each iteration
- 3 Overwrites file if it already exists
- 4 false closes the stream at the end of the using block.
- 5 Doesn’t measure the time it takes to open the file
- 6 Makes sure everything’s written to the file
Start low with InnerIterationCount
When first trying this, set the InnerIterationCount low and increase it based on the test results. If your disk is slow, you may wait a long time for the performance test to finish.
Running this test with a couple of different solid state disks (SSDs), I got results like those shown in table 9.2.
Table 9.2. Test results from performance benchmark of SimpleWriter with 10k lines written to memory and files
|
Test Name |
Metric |
Iterations |
AVERAGE |
STDEV.S |
MIN |
MAX |
|---|---|---|---|---|---|---|
| BenchmarkSimpleWriter | Duration | 100 | 2.469 | 0.709 | 1.954 | 4.922 |
| BenchmarkSimpleWriterToFile | Duration | 100 | 3.780 | 0.985 | 2.760 | 9.812 |
Compare these results with table 9.1. It’s common for there to be fluctuations in performance measurements. Some techniques for handling this include removing all unnecessary processes from the machine running the tests, running the tests multiple times, and increasing the number of iterations.
One pattern I noticed is that writing to files does have an impact, but not as big an impact as I originally thought. Try the test again with the files already created, and you’ll see that the impact is even less. This tells me that if I need to improve the performance of this library, optimizing the CSV-writing code rather than the file-writing code will have the most impact, because it uses the biggest percentage of the overall time.
Test this out by making a slight tweak to the SimpleWriter class. Add the following method.
Listing 9.9. Adding method to SimpleWriter
public void WriteLine(params string[] values)
{
this.target.WriteLine(string.Join(",", values));
}
This method assumes the user will provide the strings in the correct order.
You’ll also need to add a couple new benchmarks to the PerfTests class, as follows.
Listing 9.10. Adding benchmark tests to the PerfTests class
[Benchmark(InnerIterationCount=10000)]
public void BenchmarkSimpleWriterJoin()
{
var buffer = new byte[500000];
var memoryStream = new MemoryStream(buffer); 1
foreach (var iteration in Benchmark.Iterations)
{
using (var streamWriter = new StreamWriter(memoryStream,
Encoding.Default, 512, true))
{
using (iteration.StartMeasurement())
{
var simpleWriter = new SimpleWriter(streamWriter);
simpleWriter.WriteHeader("Year", "Title", "Production Studio");
for (int innerIteration = 0;
innerIteration < Benchmark.InnerIterationCount;
innerIteration++)
{
simpleWriter.WriteLine(
"2008", "Iron Man", "Marvel Studios"); 2
}
streamWriter.Flush();
}
}
memoryStream.Seek(0, SeekOrigin.Begin);
}
}
[Benchmark(InnerIterationCount=10000)]
public void BenchmarkSimpleWriterToFileJoin() 3
{
int outerIterations = 0;
foreach (var iteration in Benchmark.Iterations)
{
var fileStream = new FileStream( 4
$"tempfile{outerIterations++}.csv", FileMode.Create, FileAccess.Write);
using (var streamWriter = new StreamWriter(fileStream,
Encoding.Default, 512, false))
{
using (iteration.StartMeasurement())
{
var simpleWriter = new SimpleWriter(streamWriter);
simpleWriter.WriteHeader("Year", "Title", "Production Studio");
for (int innerIteration = 0;
innerIteration < Benchmark.InnerIterationCount;
innerIteration++)
{
simpleWriter.WriteLine(
"2008", "Iron Man", "Marvel Studios"); 5
}
streamWriter.Flush();
}
}
}
}
- 1 Writes to memory buffer
- 2 Writes the strings using the join method
- 3 Tests for writing to file.
- 4 Writes to file stream
- 5 Writes the strings using the join method
With these new tests, I got the results shown in table 9.3.
Table 9.3. Test results from performance benchmark of SimpleWriter
|
Test Name |
Metric |
Iterations |
AVERAGE |
STDEV.S |
MIN |
MAX |
|---|---|---|---|---|---|---|
| BenchmarkSimpleWriter | Duration | 100 | 2.529 | 1.646 | 1.706 | 13.312 |
| BenchmarkSimpleWriterJoin | Duration | 100 | 1.259 | 0.315 | 0.918 | 2.250 |
| BenchmarkSimpleWriterToFile | Duration | 100 | 3.780 | 0.985 | 2.760 | 9.812 |
| BenchmarkSimpleWriterToFileJoin | Duration | 100 | 2.122 | 0.689 | 1.429 | 6.985 |
Performance tests are impacted by external factors
The Max measurement for BenchmarkSimpleWriter is 13.312 milliseconds, which is much higher than any other measurement. If you look at the order in which the tests were run, you’ll notice this test came last. The likely explanation for the high maximum latency is that the garbage collector kicked in. Some ways to handle this would be randomizing the order of the tests, which would require a change to xUnit.Performance, or increasing the number of iterations to absorb the GC cost.
As you can see from the test results, using the new WriteLine method in SimpleWriter has a dramatic impact on performance. There are two changes in the method. One is that it doesn’t use a dictionary, and the other is that it uses string.Join instead of a custom loop to write the fields. Which change had the most impact? You can try to determine this by using a profiler like PerfView.
9.3. Using PerfView on .NET Core applications
PerfView is a Windows application invented by Vance Morrison, a performance legend at Microsoft. He actively maintains the project on GitHub (https://github.com/Microsoft/perfview) and has all kinds of tutorials on how to use it and how to understand performance in general.
PerfView works by recording Event Tracing for Windows (ETW) events. ETW is a powerful feature built into the Windows operating system that gives you all kinds of information on the operation of your computer. In chapter 10 you’ll learn how to emit your own ETW events. But for now, there are plenty of ETW events in .NET Core and the Windows kernel to help you diagnose your performance issues.
9.3.1. Getting a CPU profile
A profile gives you a window into what exactly your application is doing when it’s running. You could get a memory profile to see how memory is being allocated and freed, or you could get a disk profile to see disk reads and writes.
CPU profiles tell you how your application uses the processor. In most cases, this means recording what code is executing to see what methods take the most CPU or appear most often in the stack. PerfView is a free tool for CPU profiles and much more.
Suppose you have a program with a Main method. It calls the WriteLog method, which calls a ToString method. The stack in this scenario is Main→WriteLog→ToString with ToString on the top and Main at the bottom of the stack.
Your high-level, object-oriented language is doing some work under the covers to make each method call. Part of that work is to push the contents of the CPU registers to the stack before making the jump to the method (flash back to your assembly class in college). This is why the term stack is used to refer to the chain of method calls.
Each level of the stack (called a frame) needs some uniquely identifying information. Programs are divided into assemblies, assemblies into classes (and other types), and classes into methods. Most profilers will write each level of the stack with assembly, class name, and method name. Line-number information usually isn’t available in CPU profiles.
You can download PerfView from the GitHub site (https://github.com/Microsoft/perfview). PerfView is a single exe file that has no install. Just copy it to a machine and run it as administrator. You can run your application using the Collect > Run menu option, as shown in figure 9.1.
Figure 9.1. PerfView Run dialog

Circular profiling
Profiles can create big files on disk very quickly. This is OK, as long as the thing you’re trying to profile happens quickly. But if it takes some time to reproduce the issue, you could end up with a really large profile that takes a long time to analyze. This is where circular profiling comes in handy. If you specify that you only want 500 MB in your profile, only the latest 500 MB will be kept on disk. That allows you to start the profiler, wait until the performance issues reproduce, and then stop the profiler with the resulting profile being no larger than 500 MB.
Try to run your performance tests in PerfView. Close the Run dialog box, and find the text box directly below the File menu. Enter the full path to the CsvWriterPerfTests folder in this text box. It should update the tree below the text box to show the contents of that folder (without files).
Next, go to File > Set Symbol Path. As shown in figure 9.2, add the full path to the .pdb files built under the CsvWriterPerfTests folder.
Figure 9.2. PerfView Set Symbol Path dialog
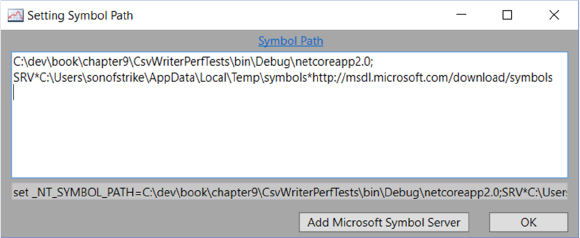
The other symbol path is the Microsoft Symbol Server. If you don’t see it in the text box, click the Add Microsoft Symbol Server button.
What are symbols for?
When debugging or profiling, you’ll use stacks to determine what code is executing. Each level (frame) of the stack indicates the assembly, class, and function or method. But sometimes this isn’t enough information to determine the exact line of code. By matching symbols, you’ll also be able to see the filename and line number of each stack frame. Keep in mind that stacks from .NET assemblies will show class and method names without symbols, but frames from natively compiled assemblies need symbols to show class and method names.
Next, open the Collect > Run menu option and fill out the dialog box as shown in figure 9.3.
Figure 9.3. PerfView Run dialog box with commands to run your xUnit.Performance tests

Once the profiling is complete, the Run dialog box will close, and the tree view on the left side of the main window will update to include your profile (see figure 9.4).
Figure 9.4. PerfView profile tree

9.3.2. Analyzing a CPU profile
Double-click the CPU Stacks item in the tree. PerfView will then let you pick the process you want to analyze—remember that a PerfView profile is machine-wide, so all CPU stacks from all processes active on the machine during the profile are recorded. The dotnet run command executes several child processes, which can make it tricky to find the right one. The CommandLine portion will help greatly. Figure 9.5 shows what the Select Process window looks like.
Figure 9.5. PerfView Select Process dialog box
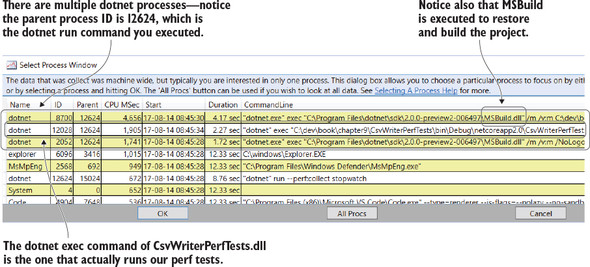
Identifying your application’s process name
To make it easier to identify the process, you can create a self-contained application, like you did in chapter 8. A self-contained application’s process will have the assembly’s name instead of dotnet, such as CsvWriterPerfTests.exe.
Once you pick the process, you’ll see the CPU Stacks window. It won’t make much sense at first because PerfView attempts to filter it to only what you need. You’ll need to change the filters to get a better view of the data. Figure 9.6 shows what the filters at the top of the stack window are for.
Figure 9.6. PerfView CPU Stacks filters
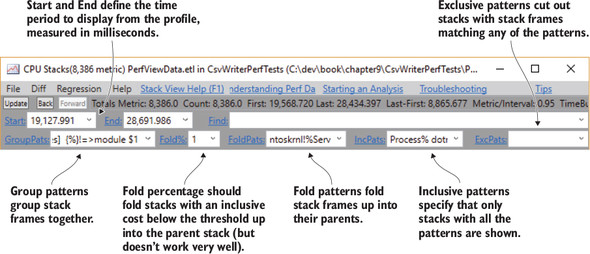
Every method contains some instructions that run on the CPU. The amount of time spent executing the instructions within a particular method is considered the exclusive cost of that method. Because that method is likely called multiple times, profiles sum up the total time and show that as the exclusive cost of the method. Costs are usually presented as percentages of the total CPU cost for the whole profile.
The inclusive cost of a method is its exclusive cost plus the cost of any methods it calls. Suppose you have a method, A, that calls methods B and C. The exclusive costs for A, B, and C are 1%, 5%, and 6% respectively. Let’s assume that B and C don’t call anything else, so their inclusive costs are equivalent to their exclusive costs. That makes method A’s inclusive cost 12%—1% exclusive for itself, plus 5% and 6% for the inclusive costs of B and C.
It may take some time to understand the difference between group, fold, include, and exclude patterns. You’ll use them to filter down to a couple of tests so you can get a better feel for how they work.
The first step is the group pattern. The default group pattern is very restrictive, as it will try to look for only your code. It does this by looking for the name of the application that you ran (dotnet), which isn’t helpful in this case. Setting the group pattern takes a bit of trial and error.
Start by clearing the field and pressing Enter—that will show all stacks. Switch over to the CallTree tab, and you’ll see a deep set of stacks. I start by looking for assemblies I’m not interested in and adding them to the group pattern.
In this case, I found that using xunit%->xunit;clr%=>coreclr worked best. I wanted to hide the xUnit library because I’m not interested in its internals, and it has pretty deep stacks. The -> groups everything together as xunit. For CLR (common language runtime) libraries, I cared about the entry point, but nothing inside. To see the entry point but nothing else inside the group, you use the => command instead of the ->. You can add as many of these as you like, separated by semicolons. Keep in mind that they run in order from left to right.
The next filter is the fold patterns. The default fold pattern, ntoskrnl!%ServiceCopyEnd, can remain. I add to that a pattern that folds the threads: ^Thread. For this profile, I’m not interested which thread a particular test was run on. Folding gets it out of the stack and simplifies the stack tree.
For .NET Core profiles, I found that two other stacks were uninteresting and added these entries to the fold patterns: system.private.corelib%;system.runtime .extensions%. I folded these because I don’t have the symbols for them, and it helped to declutter the stack.
PerfView has already set the inclusive pattern filter to the process ID that you picked. If you were to clear this filter, it would show all stacks from all processes. For this example, we’ll focus on the two tests that wrote to files. To do this, add this pattern to the inclusive patterns: csvwriterperftests!CsvWriterPerfTests .PerfTests.BenchmarkSimpleWriterToFile.
Right-click somewhere on the stack and choose Lookup Warm Symbols from the menu. At this point, you should have a good view of the stack involved in running the two file tests. Figure 9.7 shows how this could look.
What are CPU stacks, and how are they measured?
The CPU Stacks window measures percentages based on the number of samples that appeared in a particular stack versus the total number of samples included by the filters. It’s not a percentage of the whole profile. A sample in this context comes from a periodic sampling of all stacks. The default for PerfView is to take a sample every millisecond, but this is adjustable.
Figure 9.7. PerfView CPU Stacks window showing the xUnit.Performance tests that write to files
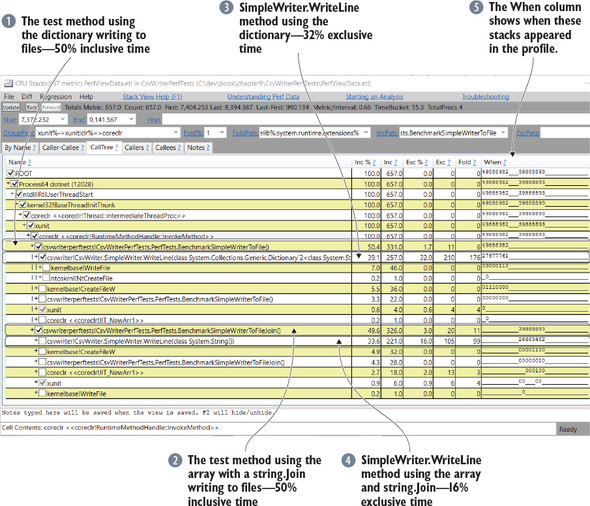
Notice that the two tests took the same amount of CPU time (compare the Inc column from figure 9.7 for lines 1 and 2), but the time spent in SimpleWriter varies greatly (compare the Inc column for lines 3 and 4). If you expand the stacks, you’ll see that the file manipulation is the source of the fluctuation. By viewing the profile, you can cancel these things out and compare the two WriteLine methods directly against each other. The performance difference is most notable in the exclusive percentage.
The calls to TextWriter.WriteLine and string.Join are still not visible in the stack. This can happen if the compiler “inlines” the methods, which is an optimization to avoid calling methods by sticking the code from one method directly into its caller. Another reason could be the lack of symbols. Usually PerfView will show a stack frame with a question mark (?) for any symbol it doesn’t have. The missing symbols likely come from system.private.corelib or system.runtime.extensions. Unfortunately, .NET Core symbols aren’t published to the public Microsoft symbol store or included in their NuGet packages.
9.3.3. Looking at GC information
Back in the main PerfView window, expand the Memory Group folder in the tree and double-click GCStats. This opens an HTML page with links at the top for each process. Find the one with the process ID you analyzed in the CPU Stacks window. It should look like dotnetc CsvWriterPerfTests.dll --perf:collect stopwatch. I think the c suffixed to dotnet means child process, but that’s just a guess.
The page includes a table of information about the garbage collections by generation, which should look similar to table 9.4.
Table 9.4. PerfView GC rollup by generation
|
GC Rollup By Generation |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
All times are in msec. |
||||||||||
|
Gen |
Count |
Max Pause |
Max Peak MB |
Max Alloc MB/sec |
Total Pause |
Total Alloc MB |
Alloc MB/MSec GC |
Survived MB/MSec GC |
Mean Pause |
Induced |
| ALL | 134 | 3.1 | 6.2 | 1,490.404 | 57.1 | 317.3 | 5.6 | 0.077 | 0.4 | 4 |
| 0 | 130 | 3.1 | 6.2 | 1,490.404 | 52.6 | 311.9 | 0.2 | 0.024 | 0.4 | 0 |
| 1 | 0 | 0.0 | 0.0 | 0.000 | 0.0 | 0.0 | 0.0 | NaN | NaN | 0 |
| 2 | 4 | 1.3 | 3.0 | 455.380 | 4.5 | 5.4 | 0.0 | 0.526 | 1.1 | 4 |
The .NET garbage collector has three generations: 0, 1, and 2. When an object is first allocated, it has never been through a garbage collection before, so its GC count is 0. When the .NET GC kicks in, it will first try to collect everything that has a count of 0, hence generation 0. Any object that still has references that are rooted, meaning it’s being used or needs to be accessible in some way, survives the garbage collection. The table shows the rate of survival. Survival also means an increment in GC count to 1.
Gen 1 garbage collections are done less often and have more impact. The same process happens for gen 2, which is the most impactful. Notice that table 9.4 has four gen 2 collections but no gen 1 collections. This may seem a bit odd until you look at the Induced column. Induced means that the gen 2 collection was triggered manually. In this case, xUnit.Performance induces a gen 2 collection before each test to prevent memory usage from one test causing a gen 2 during another test, which would skew the results. It’s not perfect, but it does help.
PerfView also includes some useful summary information for GC usage in the process:
- Total CPU Time: 1,905 msec
- Total GC CPU Time: 47 msec
- Total Allocs : 317.349 MB
- GC CPU MSec/MB Alloc : 0.148 MSec/MB
- Total GC Pause: 57.1 msec
- % Time paused for Garbage Collection: 3.5%
- % CPU Time spent Garbage Collecting: 2.5%
- Max GC Heap Size: 6.204 MB
- Peak Process Working Set: 36.209 MB
Out of the 1,905 milliseconds of CPU time used for the performance tests, only 47 milliseconds were spent in garbage collection. This is also shown in percentages and includes the time paused for GC. Your test only had a max heap size of 6 MB, so it’s normal to not see a lot of impact from garbage collection.
PerfView can also be used for memory investigations
If you suspect a memory issue with your application, the GC Stats window is a good place to start. PerfView also has an advanced option during collection to either sample .NET memory allocations or record all of them. These have an impact on the performance of the application, but they can give you all kinds of useful data for digging into who’s allocating objects and who’s holding them.
9.3.4. Exposing exceptions
One of the nice things about taking a PerfView profile is how much it reveals about your application that you didn’t know was going on. Take the multiple child processes spawned by the dotnet command, or how many stack frames go to xUnit if you don’t use a grouping. I also find it interesting to see how many exceptions are thrown and caught without my knowing.
Exceptions are generally bad for performance, so you don’t want them in your performance-critical areas. They may be OK in other areas, although most programmers would argue that exceptions should only be used in exceptional cases. In some cases, an exception thrown and handled by one of your dependent libraries can reveal optimizations or issues.
PerfView has two ways to view exceptions. A PerfView profile, by default, listens to the CLR ETW events fired when exceptions are thrown. You can view these events by opening the Events item in the profile tree. Figure 9.8 shows the exceptions for your xUnit.Performance test.
Figure 9.8. PerfView Events window filtered to show exceptions
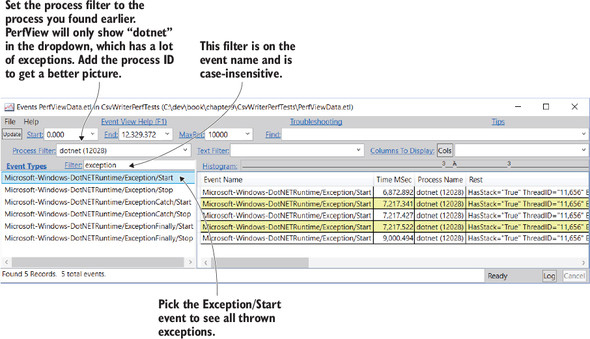
The Rest column in the event grid will have the exception type and message. Notice also that there’s a field called HasStack="true". The Events window doesn’t show the stack, but you can see it in the Exceptions Stacks item under the Advanced Group in the profile tree. Figure 9.9 shows the exceptions in this view.
Figure 9.9. PerfView Exceptions Stacks window

These exceptions don’t affect the performance tests, but they give some insight into the xUnit.Performance library.
After executing the performance tests, xUnit.Performance produces several output files. One of the files is an XML file with detailed test information. To produce that file, xUnit.Performance uses the System.Xml.XmlSerializer class, which can build the necessary components to serialize a given object graph to XML on the fly, or the library’s developers can choose to build a serialization assembly ahead of time. Generating the serialization assembly only works in .NET Framework at the time of this writing.
9.3.5. Collecting performance data on Linux
Linux Perf Events has similar capability to ETW in Windows. It can capture stacks machine-wide. Some Linux developers prefer flame graphs for viewing the data captured by Perf Events, but I find PerfView grouping and folding more powerful. Luckily, PerfView has a facility for viewing Perf Events data.
For the most up-to-date instructions on how to view Linux performance data in PerfView, consult the help topic “Viewing Linux Data,” which is available in the Help menu. The instructions are straightforward. Start by downloading and installing the perfcollect script using Curl, which you learned about in chapter 7, with the following commands:
curl -OL http://aka.ms/perfcollect chmod +x perfcollect sudo ./perfcollect install
You’ll need two terminals: one to run the application, and another to collect the profile. In the terminal that runs the application, you’ll need to set an environment variable that tells .NET to emit symbol information. Use this command:
export COMPlus_PerfMapEnabled=1
From the other terminal, you can start the collection with the following command:
sudo ./perfcollect collect mytrace
Perfcollect doesn’t have an equivalent to PerfView’s Run option. You’ll need to start collection manually and use Ctrl-C to stop the collection. Because you have to write the entry point for xUnit.Performance, you can put a Console.ReadKey() in the Main method before the benchmark starts. Perfcollect will produce a file called mytrace.trace.zip with the profile in it. Transfer this to your Windows machine to view the profile in PerfView.
Additional resources
To learn more about what we covered in this chapter, see the following resources:
- PerfView—https://github.com/Microsoft/perfview
- Writing High-Performance .NET Code by Ben Watson (Ben Watson, 2014)—http://www.writinghighperf.net/
- Vance Morrison’s blog—https://blogs.msdn.microsoft.com/vancem/
Summary
In this chapter, you learned how to write performance benchmarks and collect profiles. These were the key concepts we covered:
- xUnit.Performance provides a way to write performance tests similar to unit tests.
- Measuring is the best way to understand where to focus energy on optimization.
- External factors such as the garbage collector can impact performance.
- Profiling provides greater insight into the performance of an application.
- A powerful profile viewer like PerfView helps to visualize a profile in useful ways.
These are some important techniques to remember from this chapter:
- Be careful about memory use in performance benchmark tests, as you don’t want the tests to impact the results.
- Use group and fold patterns in PerfView to condense stacks to display only the portions you find important.
- The perfcollect script allows you to gather profile data from Linux and analyze it in PerfView.
There are many performance tools available, including the performance tools built into the more expensive versions of Visual Studio. Out of all the tools I’ve used, PerfView stands out as the most powerful—and it’s free. PerfView also doesn’t hide how it captures the performance data, so there’s no magic. That’s why I chose to focus on it in this chapter.
When it comes to performance benchmarks, Visual Studio provides a way to run performance tests using unit tests, and it’s definitely worth a try. With xUnit.Performance, you can run the tests from the command line. xUnit.Performance also has more interesting data-collection options using ETW on Windows, but the stopwatch method should work on all platforms. One other advantage of using xUnit.Performance is that it’s clear what the benchmarks are for. Unit tests are typically not written to be careful about memory and could introduce unwanted side effects when they’re repurposed as performance tests.