
![]()
C# QuickStart and Developing in C#
This chapter presents a quick overview of the C# language. It assumes a certain level of programming knowledge and therefore doesn’t present very much detail. If the explanation here doesn’t make sense, look for a more detailed explanation of the particular topic later in the book.
The second part of the chapter discusses how to obtain the C# compiler and the advantages of using Visual Studio to develop C# applications.
Hello, Universe
As a supporter of SETI,1 I thought that it would be appropriate to do a “Hello, Universe” program rather than the canonical “Hello, World” program.
using System;
class Hello
{
public static void Main(string[] args)
{
Console.WriteLine("Hello, Universe");
// iterate over command-line arguments,
// and print them out
for (int arg = 0; arg < args.Length; arg++)
{
Console.WriteLine("Arg {0}: {1}", arg, args[arg]);
}
}
}
As discussed earlier, the .NET Runtime has a unified namespace for all program information (or metadata). The using System clause is a way of referencing the classes that are in the System namespace so they can be used without having to put System in front of the type name. The System namespace contains many useful classes, one of which is the Console class, which is used (not surprisingly) to communicate with the console (or DOS box, or command line, for those who have never seen a console).
Because there are no global functions in C#, the example declares a class called Hello that contains the static Main() function, which serves as the starting point for execution. Main() can be declared with no parameters or with a string array. Since it’s the starting function, it must be a static function, which means it isn’t associated with an instance of an object.
The first line of the function calls the WriteLine() function of the Console class, which will write “Hello, Universe” to the console. The for loop iterates over the parameters that are passed in and then writes out a line for each parameter on the command line.
Namespace and Using Statements
Namespaces in the .NET Runtime are used to organize classes and other types into a single hierarchical structure. The proper use of namespaces will make classes easy to use and prevent collisions with classes written by other authors.
Namespaces can also be thought of as a way to specify long and useful names for classes and other types without having to always type a full name.
Namespaces are defined using the namespace statement. For multiple levels of organization, namespaces can be nested:
namespace Outer
{
namespace Inner
{
class MyClass
{
public static void Function() {}
}
}
}
That’s a fair amount of typing and indenting, so it can be simplified by using the following instead:
namespace Outer.Inner
{
class MyClass
{
public static void Function() {}
}
}
A source file can define more than one namespace, but in the majority of cases, all the code within one file lives in a single namespace.
The fully qualified name of a class—the name of the namespace followed by the name of the class—can become quite long. The following is an example of such a class:
System.Xml.Serialization.Advanced.SchemaImporterExtension
It would be very tedious to have to write that full class name every time we wanted to use it, so we can add a using statement:
using System.Xml.Serialization.Advanced;
This statement says, “treat all of the types defined inside this namespace as if they don’t have a namespace in front of them,” which allows us to use
SchemaImporterExtension
instead of the full name. The using statement only works for types directly inside the namespace; if we had the following using statement:
using System.Xml.Serialization;
we would not be able to use the following name:
Advanced.SchemaImporterExtension
With a limited number of names in the world, there will sometimes be cases where the same name is used in two different namespaces. Collisions between types or namespaces that have the same name can always be resolved by using a type’s fully qualified name. This could be a very long name if the class is deeply nested, so there is a variant of the using clause that allows an alias to be defined to a class:
using ThatConsoleClass = System.Console;
class Hello
{
public static void Main()
{
ThatConsoleClass.WriteLine("Hello");
}
}
To make the code more readable, the examples in this book rarely use namespaces, but they should be used in most real code.
An object can be used from within a C# source file only if that object can be located by the C# compiler. By default, the compiler will only open the single assembly known as mscorlib.dll, which contains the core functions for the Common Language Runtime.
To reference objects located in other assemblies, the name of the assembly file must be passed to the compiler. This can be done on the command line using the /r:<assembly> option or from within the Visual Studio IDE by adding a reference to the C# project.
Typically, there is a correlation between the namespace that an object is in and the name of the assembly in which it resides. For example, the types in the System.Net namespace and child namespaces reside in the System.Net.dll assembly. This may be revised based on the usage patterns of the objects in that assembly; a large or rarely used type in a namespace may reside in a separate assembly.
The exact name of the assembly that an object is contained in can be found in the online MSDN documentation for that object.
C# supports the usual set of data types. For each data type that C# supports, there is a corresponding underlying .NET Common Language Runtime type. For example, the int type in C# maps to the System.Int32 type in the runtime. System.Int32 can be used in most of the places where int is used, but that isn’t recommended because it makes the code tougher to read.
The basic data types are described in Table 2-1. The runtime types can all be found in the System namespace of the .NET Common Language Runtime.
Table 2-1. Basic Data Types in C#
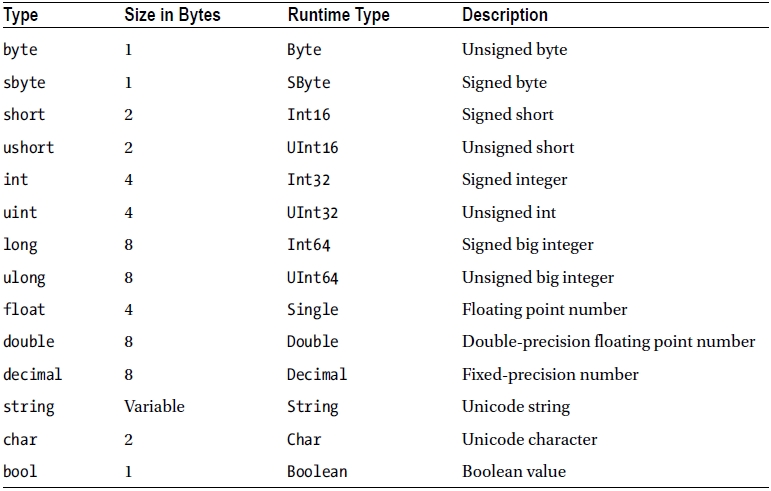
The distinction between basic (or built-in) types and user-defined ones is largely an artificial one, as user-defined types can operate in the same manner as the built-in ones. In fact, the only real difference between the built-in data types and user-defined data types is that it is possible to write literal values for the built-in types.
Data types are separated into value types and reference types. Value types are either stack allocated or allocated inline in a structure. Reference types are heap allocated.
Both reference and value types are derived from the ultimate base class object. In cases where a value type needs to act like an object, a wrapper that makes the value type look like a reference object is allocated on the heap, and the value type’s value is copied into it. This process is known as boxing, and the reverse process is known as unboxing. Boxing and unboxing let you treat any type as an object. That allows the following to be written:
using System;
class Hello
{
public static void Main(string[] args)
{
Console.WriteLine("Value is: {0}", 3);
}
}
In this case, the integer 3 is boxed, and the Int32.ToString() function is called on the boxed value.
C# arrays can be declared in either the multidimensional or jagged forms. More advanced data structures, such as stacks and hash tables, can be found in the System.Collections and System.Collections.Generic namespaces.
Classes, Structs, and Interfaces
In C#, the class keyword is used to declare a reference (a heap-allocated) type, and the struct keyword is used to declare a value type. Structs are used for lightweight objects that need to act like the built-in types, and classes are used in all other cases. For example, the int type is a value type, and the string type is a reference type. Figure 2-1 details how these work.
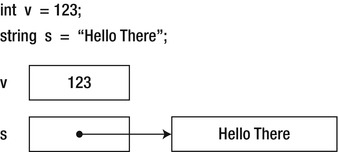
Figure 2-1 . Value and reference type allocation
C# and the .NET Runtime do not support multiple inheritance for classes but do support multiple implementation of interfaces.
The statements in C# are similar to C++ statements, with a few modifications to make errors less likely,2 and a few new statements. The foreach statement is used to iterate over arrays and collections, the lock statement is used for mutual exclusion in threading scenarios, and the checked and unchecked statements are used to control overflow checking in arithmetic operations and conversions.
Enumerations are used to declare a set of related constants—such as the colors that a control can take—in a clear and type-safe manner. For example:
enum Colors
{
red,
green,
blue
}
Enumerations are covered in more detail in Chapter 20.
Delegates are a type-safe, object-oriented implementation of function pointers and are used in many situations where a component needs to call back to the component that is using it. They are used as the basis for events, which allows a delegate to easily be registered for an event. They are discussed in Chapter 22.
C# supports properties and indexers, which are useful for separating the interface of an object from the implementation of the object. Rather than allowing a user to access a field or array directly, a property or indexer allows a code block to be specified to perform the access, while still allowing the field or array usage. Here’s a simple example:
using System;
class Circle
{
public int Radius
{
get
{
return(m_radius);
}
set
{
m_radius = value;
Draw();
}
}
public void Draw()
{
Console.WriteLine("Drawing circle of radius: {0}", radius);
}
int m_radius;
}
class Test
{
public static void Main()
{
Circle c = new Circle();
c.Radius = 35;
}
}
The code in the get or set blocks (known as accessors) is called when the value of the Radius property is get or set.
Attributes are used in C# and the .NET Frameworks to communicate declarative information from the writer of the code to other code that is interested in the information. They might be used to specify which fields of an object should be serialized, what transaction context to use when running an object, how to marshal fields to native functions, or how to display a class in a class browser.
Attributes are specified within square braces. A typical attribute usage might look like this:
[CodeReview("12/31/1999", Comment = "Well done")]
Attribute information is retrieved at runtime through a process known as reflection. New attributes can be easily written, applied to elements of the code (such as classes, members, or parameters), and retrieved through reflection.
Developing in C#
To program in C#, you’re going to need a way to build C# programs. You can do this with a command-line compiler, Visual Studio, or a C# package for a programming editor.
Visual Studio provides a great environment in which to develop C# programs. If cost is an issue, the Visual Studio Express product covers most development scenarios, and the SharpDevelop IDE is also available. Both are available free of charge.
If you are targeting non-Microsoft platforms, the Mono project provides a C# environment that can target Linux, iOS, and Android.
There are a number of tools that you may find useful when developing in C#. They are discussed in the following sections.
ILDASM (Intermediate Language [IL] Disassembler) is the most useful tool in the software development kit (SDK). It can open an assembly, show all the types in the assembly, what methods are defined for those types, and the IL that was generated for that method.
This is useful in a number of ways. Like the object browser, it can be used to find out what’s present in an assembly, but it can also be used to find out how a specific method is implemented. This capability can be used to answer some questions about C#.
If, for example, you want to know whether C# will concatenate constant strings at compile time, it’s easy to test. First, a short program is created:
using System;
class Test
{
public static void Main()
{
Console.WriteLine("Hello " + "World");
}
}
After the program is compiled, ILDASM can be used to view the IL for Main():
.method public hidebysig static void Main() cil managed
{
.entrypoint
// Code size 11 (0xb)
.maxstack 8
IL_0000: ldstr "Hello World"
IL_0005: call void [mscorlib]System.Console::WriteLine(string)
IL_000a: ret
} // end of method Test::Main
Even without knowing the details of the IL language, it’s pretty clear that the two strings are concatenated into a single string.
The presence of metadata in .NET assemblies makes it feasible to decompile an assembly back to C# code.3 There are a few decompilers available; I’ve been using DotPeek from JetBrains recently.
If you are concerned about the IP in your code, you can use an obfuscator on your code to make it harder to understand when decompiled. A limited version of Dotfuscator ships with Visual Studio.
Spend some time understanding what a specific obfuscator can give you before decided to use it to obfuscate your code.
NGEN (Native Image Generator)3 is a tool that performs the translation from IL to native processor code before the program is executed, rather than doing it on demand.
At first glance, this seems like a way to get around many of the disadvantages of the just-in-time (JIT) approach; simply pre-JIT the code, and performance will be better and nobody will be able to decode the IL.
Unfortunately, things don’t work that way. Pre-JIT is only a way to store the results of the compilation, but the metadata is still required to do class layout and support reflection. Further, the generated native code is only valid for a specific environment, and if configuration settings (such as the machine security policy) change, the Runtime will switch back to the normal JIT.
Although pre-JIT does eliminate the overhead of the JIT process, it also produces code that runs slightly slower because it requires a level of indirection that isn’t required with the normal JIT.
So, the real benefit of pre-JIT is to reduce the JIT overhead (and therefore the startup time) of a client application, and it isn’t really very useful elsewhere.
1 Search for Extraterrestrial Intelligence. See http://www.teamseti.org for more information.
2 In C#, the switch statement does not allow fall through, and it is not possible to accidentally write "if (x = 3)" instead of "if (x == 3)".
3 Or, at least, something that is good enough to understand.