
![]()
This chapter will delve deeper into some issues you might encounter using C#. It covers some topics of interest to the library/framework author, such as style guidelines and XML documentation, and it also discusses how to write unsafe code and how the .NET Runtime’s garbage collector works.
Most languages develop an expected idiom for expression. When dealing with C character strings, for example, the usual idiom involves pointer arithmetic rather than array references. There are a number of different C# guidelines around, and a popular one is the “Class Library Design Guidelines” section in the .NET documentation.
![]() Note The published guidelines are designed for those who write class libraries that are used by other teams and/or customers. If you are not doing that, some of the guidelines do not apply.
Note The published guidelines are designed for those who write class libraries that are used by other teams and/or customers. If you are not doing that, some of the guidelines do not apply.
The examples in this book conform to the guidelines, so they should be fairly familiar already. The .NET Common Language Runtime classes and samples also have many examples.
Two naming conventions are used.
- PascalCasing capitalizes the first character of each word.
- camelCasing is the same as PascalCasing, except the first character of the first word isn’t capitalized.
In general, PascalCasing is used for anything that would be visible externally from a class, such as classes, enums, methods, and so on. The exception to this is method parameters, which are defined using camelCasing.
Private members of classes, such as fields, are defined using camelCasing.
There are a few other conventions in naming.
- Avoid common keywords in naming to decrease the chance of collisions in other languages.
- Event classes should end with EventArgs.
- Exception classes should end with Exception.
- Interfaces should start with I.
- Attribute classes should end in Attribute.
Hungarian naming (prefixing the name of the variable with the type of the variable) is discouraged for C# code because the added information about the variable isn’t as important as making the code easier to read. For example, strEmployeeName is tougher to read than employeeName.1
Conventions such as adding m_ or _ at the beginning of fields to denote that the field belongs to an instance is a matter of personal choice.
Guidelines for the Library Author
The following guidelines are useful to programmers who are writing libraries that will be used by others.
To help prevent collisions between namespaces and classes provided by different companies, namespaces should be named using the CompanyName.TechnologyName convention. For example, the full name of a class to control an X-ray laser would be something like this:
AppliedEnergy.XRayLaser.Controller
There are many benefits of code verification in the .NET Runtime. Being able to verify that code is typesafe not only enables download scenarios but also prevents many common programming errors.
When dealing with binary structures or talking to COM objects that take structures containing pointers or when performance is critical, more control is needed. In these situations, unsafe code can be used.
Unsafe simply means that the runtime cannot verify that the code is safe to execute. It therefore can be executed only if the assembly has full trust, which means it cannot be used in download scenarios or any other scenario lacking full trust.
The following is an example of using unsafe code to copy arrays of structures quickly. The structure being copied is a point structure consisting of x and y values.
There are three versions of the function that clone arrays of points. ClonePointArray() is written without using unsafe features and merely copies the array entries over. The second version, ClonePointArrayUnsafe(), uses pointers to iterate through the memory and copy it over. The final version, ClonePointArrayMemcpy(), calls the system function CopyMemory() to perform the copy.
To give some time comparisons, the following code is instrumented:
public struct Point
{
public Point(int x, int y)
{
m_x = x;
m_y = y;
}
// safe version
public static Point[] ClonePointArray(Point[] sourceArray)
{
Point[] result = new Point[sourceArray.Length];
for (int index = 0; index < sourceArray.Length; index++)
{
result[index] = sourceArray[index];
}
return (result);
}
// unsafe version using pointer arithmetic
unsafe public static Point[] ClonePointArrayUnsafe(Point[] sourceArray)
{
Point[] result = new Point[sourceArray.Length];
// sourceArray and result are pinned; they cannot be moved by
// the garbage collector inside the fixed block.
fixed (Point* src = sourceArray, dest = result)
{
Point* pSrc = src;
Point* pDest = dest;
for (int index = 0; index < sourceArray.Length; index++)
{
*pDest = *pSrc;
pSrc++;
pDest++;
}
}
return (result);
}
// import CopyMemory from kernel32
[DllImport("kernel32.dll")]
unsafe public static extern void
CopyMemory(void* dest, void* src, int length);
// unsafe version calling CopyMemory()
unsafe public static Point[] ClonePointArrayCopyMemory(Point[] sourceArray)
{
Point[] result = new Point[sourceArray.Length];
fixed (Point* src = sourceArray, dest = result)
{
CopyMemory(dest, src, sourceArray.Length * sizeof(Point));
}
return (result);
}
public override string ToString()
{
return (String.Format("({0}, {1})", m_x, m_y));
}
int m_x;
int m_y;
}
class Test
{
const int Iterations = 20000; // # to do copy
const int Points = 1000; // # of points in array
const int TimeCount = 5; // # of times to time
public delegate Point[] CloneFunction(Point[] sourceArray);
public static void TimeFunction(Point[] sourceArray,
CloneFunction cloneFunction, string label)
{
Point[] result = null;
TimeSpan minimumElapsedTime = TimeSpan.MaxValue;
Stopwatch stopwatch = new Stopwatch();
// do the whole copy TimeCount times, find fastest time
for (int retry = 0; retry < TimeCount; retry++)
{
stopwatch.Start();
for (int iteration = 0; iteration < Iterations; iteration++)
{
result = cloneFunction(sourceArray);
}
stopwatch.Stop();
if (stopwatch.Elapsed < minimumElapsedTime)
{
minimumElapsedTime = stopwatch.Elapsed;
}
}
Console.WriteLine("{0}: {1} seconds", label, minimumElapsedTime);
}
public static void Main()
{
Console.WriteLine("Points, Iterations: {0} {1}", Points, Iterations);
Point[] sourceArray = new Point[Points];
for (int index = 0; index < Points; index++)
{
sourceArray[index] = new Point(3, 5);
}
TimeFunction(sourceArray, Point.ClonePointArrayCopyMemory, "Memcpy");
TimeFunction(sourceArray, Point.ClonePointArrayUnsafe, "Unsafe");
TimeFunction(sourceArray, Point.ClonePointArray, "Baseline");
}
}
The timer function uses a delegate to describe the clone function so that it can use any of the clone functions.
As with any benchmarking, the initial state of memory is very important. To help control for this, TimeFunction() does each method five times and prints out only the shortest time. Typically, the first iteration is slower, because the CPU cache isn’t ready yet, and subsequent times get faster.
The program was run with several different values for points and iterations. Table 39-1 summarizes the results.
Table 39-1. Copy Array Timings
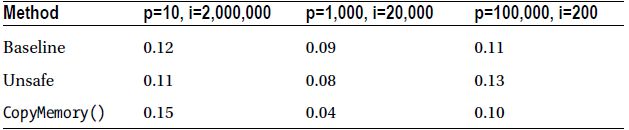
For small arrays, the overhead of calling CopyMemory() (which involves an interop transition) makes it slower. It is faster for medium-sized arrays, and for large arrays, it’s a dead heat.
The point here is that unsafe isn’t always faster, so if you are thinking of using it, make sure you measure the performance. It will vary across scenarios, and it will also vary across machines.
Keeping documentation synchronized with the actual implementation is always a challenge. One way of keeping it up-to-date is to write the documentation as part of the source and then extract it into a separate file.
C# supports an XML-based documentation format. The compiler verifies that the XML is well-formed, does some context-based validation, adds some information that only a compiler can get consistently correct, and writes it out to a separate file.
C# XML support can be divided into two sections: compiler support and documentation convention. In the compiler support section, there are tags that are specially processed by the compiler, for verification of contents or symbol lookup. The remaining tags define the .NET documentation convention and are passed through unchanged by the compiler.
The compiler support tags are a good example of compiler magic; they are processed using information that is known only to the compiler. The following example illustrates the use of the support tags:
// file: employee.cs
using System;
namespace Payroll
{
/// <summary>
/// The Employee class holds data about an employee.
/// This class class contains a <see cref="String">string</see>
/// </summary>
public class Employee
{
/// <summary>
/// Constructor for an Employee instance. Note that
/// <paramref name="name">name2</paramref> is a string.
/// </summary>
/// <param name="id">Employee id number</param>
/// <param name="name">Employee Name</param>
public Employee(int id, string name)
{
m_id = id;
m_name = name;
}
/// <summary>
/// Parameterless constructor for an employee instance
/// </summary>
/// <remarks>
/// <seealso cref="Employee(int, string)">Employee(int, string)</seealso>
/// </remarks>
public Employee()
{
m_id = −1;
m_name = null;
}
int m_id;
string m_name;
}
}
The compiler performs special processing on four of the documentation tags. For the param and paramref tags, it validates that the name referred to inside the tag is the name of a parameter to the function.
For the see and seealso tags, it takes the name passed in the cref attribute and looks it up using the identifier lookup rules so that the name can be resolved to a fully qualified name. It then places a code at the front of the name to tell what the name refers to. For example, the following:
<see cref="String">
becomes the following:
<see cref="T:System.String">
String resolved to the System.String class, and T: means that it’s a type.
The seealso tag is handled in a similar manner. The following:
<seealso cref="Employee(int, string)">
becomes the following:
<seealso cref="M:Payroll.Employee.#ctor(System.Int32,System.String)">
The reference was to a constructor method that had an int as the first parameter and a string as the second parameter.
In addition to the preceding translations, the compiler wraps the XML information about each code element in a member tag that specifies the name of the member using the same encoding. This allows a postprocessing tool to easily match up members and references to members.
The generated XML file from the preceding example is as follows (with a few word wraps):
<?xml version="1.0"?>
<doc>
<assembly>
<name>employee</name>
</assembly>
<members>
<member name="T:Payroll.Employee">
<summary>
The Employee class holds data about an employee.
This class class contains a <see cref="T:System.String">string</see>
</summary>
</member>
<member name="M:Payroll.Employee.#ctor(System.Int32,System.String)">
<summary>
Constructor for an Employee instance. Note that
<paramref name="name2">name</paramref> is a string.
</summary>
<param name="id">Employee id number</param>
<param name="name">Employee Name</param>
</member>
<member name="M:Payroll.Employee.#ctor">
<summary>
Parameterless constructor for an employee instance
</summary>
<remarks>
<seealso cref="M:Payroll.Employee.#ctor(System.Int32,System.String)"
>Employee(int, string)</seealso>
</remarks>
</member>
</members>
</doc>
The best way to generate documentation from the XML output of the compiler is by using SandCastle,2 a free tool supported by Microsoft. It can generate documentation that looks like the MSDN documentation.
The remaining XML documentation tags describe the .NET documentation conventions. The tags are listed in Table 39-2.
Table 39-2 . XML Documentation Tags
| Tag | Description |
|---|---|
| <c> | Formats characters as code within other text |
| <code> | Multiline section of code—usually used in an <example> section |
| <example> | An example of using a class or method |
| <exception> | The exceptions a class throws |
| <include> | Includes XML from an external file |
| <list> | A list of items |
| <para> | Adds paragraph to the text |
| <param> | Describes a parameter to a member function |
| <paramref> | A reference to a parameter in other text |
| <permission> | The permission applied to a member |
| <remarks> | A long description of an item |
| <returns> | The return value of a function |
| <see cref="member"> | A link to a member or field in the current compilation environment |
| <seealso cref="member"> | A link in the “see also” section of the documentation |
| <summary> | A short description of the item |
| <value> | Describes the value of a property |
| <typeparam> | Describes a generic type parameter |
| <typeparamref> | Identifies a word that is a generic type parameter |
The compiler does not enforce a specific schema on the XML tags that are used in the XML comments; it requires only that the XML be well-formed. This allows it to be extended at will; a team could add an 272103_1_En tag or a <version> tag if desired, and it will be passed into the resulting XML file.
In a project that has a separate technical-writing team, it may be more convenient to keep the XML text outside of the code. To support this, C# provides an include syntax for XML documentation. Instead of having all the documentation before a function, the following include statement can be used:
/// <include file='Foo.csx' path='doc/member[@name="Foo.Comp"]' />
This will open the Foo.csx file and look for a <doc> tag. Inside the doc section, it will then look for a <member> tag that has the name Foo.Comp specified as an attribute. Here’s an example:
<doc>
<member name="Foo.Comp">
<summary>A description of the routine</summary>
<param name="obj1">the first object</param>
</member>
. . .
</doc>
Once the compiler has identified the matching section from the include file, it proceeds as if the XML were contained in the source file.
Garbage Collection in the .NET Runtime
Garbage collection has a bad reputation in a few areas of the software world. Some programmers feel they can do a better job at memory allocation than a garbage collector (GC) can.
They’re correct; they can do a better job, but only with a custom allocator for each program and possibly for each class. Custom allocators are a lot of work to write, to understand, and to maintain.
In the vast majority of cases, a well-tuned garbage collector will give similar or better performance to an unmanaged heap allocator.
This section will explain a bit about how the garbage collector works, how it can be controlled, and what can’t be controlled in a garbage-collected world. The information presented here describes the situation for platforms such as the PC. Systems with more constrained resources are likely to have simpler GC systems.
Note also that there are optimizations performed for multiproc and server machines, which will be covered later in this section.
Heap allocation in the .NET Runtime world is very fast; all the system has to do is make sure that there’s enough room in the managed heap for the requested object, return a pointer to that memory, and increment the pointer to the end of the object.
Garbage collectors trade simplicity at allocation time for complexity at cleanup time. Allocations are really, really fast in most cases, though if there isn’t enough room, a garbage collection might be required to obtain enough room for object allocation.
Of course, to make sure that there’s enough room, the system might have to perform a garbage collection.
To improve performance, large objects (greater than 85KB in size, though this number is subject to change) are allocated from a large object heap.
The .NET garbage collector uses a “Mark and Compact” algorithm. When a collection is performed, the garbage collector starts at root objects (including globals, statics, locals, and CPU registers) and finds all the objects that are referenced from those root objects. This collection of objects denotes the objects that are in use at the time of the collection, and therefore all other objects in the system are no longer needed.
To finish the collection process, all the referenced objects are copied down in the managed heap, and the pointers to those objects are all fixed up. Then, the pointer for the next available spot is moved to the end of the referenced objects.
Since the garbage collector is moving objects and object references, there can’t be any other operations going on in the system. In other words, all useful work must be stopped while the GC takes place.
![]() Note This discussion refers to the behavior of the garbage collector that runs on desktop computers. The behavior in other variants of the runtime—the server version, the compact version, and the micro version—may differ in significant ways.
Note This discussion refers to the behavior of the garbage collector that runs on desktop computers. The behavior in other variants of the runtime—the server version, the compact version, and the micro version—may differ in significant ways.
It’s costly to walk through all the objects that are currently referenced. Much of the work in doing this will be wasted work, since the older an object is, the more likely it is to stay around. Conversely, the younger an object is, the more likely it is to be unreferenced.
The runtime capitalizes on this behavior by implementing generations in the garbage collector. It divides the objects in the heap into three generations.
Generation 0 objects are newly allocated objects that have never been considered for collection. Generation 1 objects have survived a single garbage collection, and generation 2 objects have survived multiple garbage collections. In design terms, generation 2 tends to contain long-lived objects such as applications, generation 1 tends to contain objects with medium lifetimes such as forms or lists, and generation 0 tends to contain short-lived objects such as local variables.
When the runtime needs to perform a collection, it first performs a generation 0 collection. This generation contains the largest percentage of unreferenced objects and will therefore yield the most memory for the least work. If collecting that generation doesn’t generate enough memory, generation 1 will then be collected and finally, if required, generation 2.
Figure 39-1 illustrates some objects allocated on the heap before a garbage collection takes place. The numerical suffix indicates the generation of the object; initially, all objects will be of generation 0. Active objects are the only ones shown on the heap, but there is space for additional objects to be allocated.
![]()
Figure 39-1 . Initial memory state before any garbage collection
At the time of the first garbage collection, B and D are the only objects that are still in use. The heap looks like Figure 39-2 after collection.
![]()
Figure 39-2 . Memory state after first garbage collection
Since B and D survived a collection, their generation is incremented to 1. New objects are then allocated, as shown in Figure 39-3.
![]()
Figure 39-3 . New objects are allocated
Time passes. When another garbage collection occurs, D, G, and H are the live objects. The garbage collector tries a generation 0 collection, which leads to the layout shown in Figure 39-4.

Figure 39-4 . Memory state after a generation 0 collection
Even though B is no longer live, it doesn’t get collected because the collection was only for generation 0. After a few new objects are allocated, the heap looks like Figure 39-5.
![]()
Figure 39-5 . More new objects are allocated
Time passes, and the live objects are D, G, and L. The next garbage collection does both generation 0 and generation 1 and leads to the layout shown in Figure 39-6.
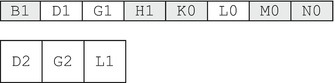
Figure 39-6 . Memory state after a generation 0 and generation 1 garbage collection
The garbage collector supports a concept known as finalization, which is somewhat analogous to destructors in C++. In the C# spec, they are known as destructors and are declared with the same syntax as C++ destructors (with the ∼ClassName syntax), but from the runtime perspective, they are known as finalizers,3 and that is the name that I will use.
Finalizers allow the opportunity to perform some cleanup before an object is garbage collected. They are useful in cases where the class owns a resource that the garbage collector doesn’t know something about; perhaps it created an unmanaged resource to perform interop.
When an object with a finalizer is allocated, the runtime adds the object reference to a list of objects that will need finalization. When a garbage collection occurs, if an object has no references but is contained on the finalization list, it is marked as ready for finalization.
After the garbage collection has completed, the finalizer thread wakes up and calls the finalizer for all objects that are ready for finalization. After the finalizer is called for an object, it is removed from the list of objects that need finalizers, which will make it available for collection the next time garbage collection occurs.
This scheme results in the following limitations regarding finalizers:
- Objects that have finalizers have more overhead in the system, and they hang around longer; an object that could be collected has to wait until the next collection. This also means that the object is promoted to the next generation, so you have to wait that much longer for the object to be collected.
- Finalization takes place on a separate thread from execution, which makes the timing of collection unspecified.
- There is no guaranteed order for finalization. If object a has a reference to object b and both objects have finalizers, the object b finalizer might run before the object a finalizer, and therefore object a might not have a valid object b to use during finalization.
- While finalizers are usually called on normal program exit, there are times where this will not occur. If a process is terminated aggressively (for example, if the Win32 TerminateProcess function is called), finalizers will not run. Finalizers can also fail to run if the finalization queue gets stuck running finalizers for a long time on process exit. In this case, attempts to run the finalizers will time out.
Finalizers should be used only in the following situations:
- A class holds an unmanaged resource and needs to dispose of it when an instance of the class is no longer being used. If at all possible, the class should use a SafeHandle instance to hold the unmanaged resource instead of creating a finalizer. If the class does declare a finalizer, it should also implement the Dispose() pattern.
- A singleton class needs to perform a shutdown operation.
- While a program is under development, a finalizer can identify cases where Dispose() is not being called.
At times, it may be useful to control the GC behavior. This should be done in moderation; the whole point of a managed environment is that it controls what’s going on, and controlling it tightly can lead to problems elsewhere.
The function System.GC.Collect() can be called to force a collection. There are two reasonable times to force a collection.
- If you know more than the garbage collector does. If, for example, you have just closed a big document and you know that there are tons of free objects around, you might choose to force a collection.
- If you are chasing a bug and want to be sure it isn’t because of a collection issue. If you forget to save a delegate that is passed to a native routine, it may cause a bug that shows up sporadically. If you force a collection, that may make it show up consistently.
As mentioned earlier, an instance of an object is placed on the finalization list when it is created. If it turns out that an object doesn’t need to be finalized (because the cleanup function has been called, for example), the System.GC.SupressFinalize() function can be used to remove the object from the finalization list.
Examples in the attributes section showed how to use reflection to determine the attributes that were attached to a class. Reflection can also be used to find all the types in an assembly or dynamically locate and call functions in an assembly. It can even be used to emit the .NET Intermediate Language on the fly to generate code that can be executed directly.
The documentation for the .NET Common Language Runtime contains more details on using reflection.
Listing All the Types in an Assembly
This example looks through an assembly and locates all the types in that assembly.
using System;
using System.Reflection;
enum MyEnum
{
Val1,
Val2,
Val3
}
class MyClass
{
}
struct MyStruct
{
}
class Test
{
public static void Main(String[] args)
{
// list all types in the assembly that is passed
// in as a parameter
Assembly assembly = Assembly.LoadFrom (args[0]);
Type[] types = assembly.GetTypes();
// look through each type, and write out some information
// about them.
foreach (Type type in types)
{
Console.WriteLine ("Name: {0}", type .FullName);
Console.WriteLine ("Namespace: {0}", type .Namespace);
Console.WriteLine ("Base Class: {0}", type .BaseType.FullName);
}
}
}
If this example is run, passing the name of the .exe in, it will generate the following output:
Name: MyEnum
Namespace:
Base Class: System.Enum
Name: MyClass
Namespace:
Base Class: System.Object
Name: MyStruct
Namespace:
Base Class: System.ValueType
Name: Test
Namespace:
Base Class: System.Object
This example will list the members of a type.
using System;
using System.Reflection;
class MyClass
{
MyClass() {}
static void Process()
{
}
public int DoThatThing(int i, Decimal d, string[] args)
{
return(55);
}
public int m_value = 0;
public float m_log = 1.0f;
public static int m_value2 = 44;
}
class Test
{
public static void Main(String[] args)
{
// Iterate through the fields of the class
Console.WriteLine("Fields of MyClass");
Type type = typeof (MyClass);
foreach (MemberInfo member in type.GetFields())
{
Console.WriteLine("{0}", member);
}
// and iterate through the methods of the class
Console.WriteLine("Methods of MyClass");
foreach (MethodInfo method in type.GetMethods())
{
Console.WriteLine("{0}", method);
foreach (ParameterInfo parameter in method.GetParameters())
{
Console.WriteLine(" Param: {0} {1}",
parameter.ParameterType, parameter.Name);
}
}
}
}
This example produces the following output:
Fields of MyClass
Int32 value
Single log
Int32 value2
Methods of MyClass
Void Finalize ()
Int32 GetHashCode ()
Boolean Equals (System.Object)
Param: System.Object obj
System.String ToString ()
Void Process ()
Int32 DoThatThing (Int32, System.Decimal, System.String[])
Param: Int32 i
Param: System.Decimal d
Param: System.String[] args
System.Type GetType ()
System.Object MemberwiseClone ()
For information on how to reflect over an enum, see Chapter 21.
When iterating over the methods in MyClass, the standard methods from object also show up.
In this example, reflection will be used to open the names of all the assemblies on the command lines, to search for the classes in them that implement a specific interface, and then to create an instance of those classes and invoke a function on the instance.
This is useful to provide a very late-bound architecture, where a component can be integrated with other components’ runtime.
This example consists of four files. The first one defines the IProcess interface that will be searched for. The second and third files contain classes that implement this interface, and each is compiled to a separate assembly. The last file is the driver file; it opens the assemblies passed on the command line and searches for classes that implement IProcess. When it finds one, it instantiates an instance of the class and calls the Process() function.
File IProcess.cs
namespace MamaSoft
{
interface IProcess // the interface we will search for.
{
string Process(int param);
}
}
File Process1.cs
using System;
namespace MamaSoft
{
class Processor1: IProcess
{
public Processor1() {}
public string Process(int param)
{
Console.WriteLine("In Processor1.Process(): {0}", param);
return("Raise the mainsail! ");
}
}
}
File Process2.cs
using System;
namespace MamaSoft
{
class Processor2: IProcess
{
public Processor2() {}
public string Process(int param)
{
Console.WriteLine("In Processor2.Process(): {0}", param);
return("Shiver me timbers! ");
}
}
}
class Unrelated
{
}
File Driver.cs
using System;
using System.Reflection;
using MamaSoft;
class Test
{
public static void ProcessAssembly(string aName)
{
Console.WriteLine("Loading: {0}", aName);
Assembly assembly = Assembly.LoadFrom (aName);
// walk through each type in the assembly
foreach (Type type in assembly .GetTypes())
{
// if it's a class, it might be one that we want.
if (type.IsClass)
{
Console.WriteLine(" Found Class: {0}", type.FullName);
// check to see if it implements IProcess
if (type.GetInterface("IProcess") == null)
continue;
// it implements IProcess. Create an instance
// of the object.
object o = Activator.CreateInstance(type);
// create the parameter list, call it,
// and print out the return value.
Console.WriteLine(" Calling Process() on {0}",
type.FullName);
object[] args = new object[] {55};
object result;
result = type.InvokeMember("Process",
BindingFlags.Default |
BindingFlags.InvokeMethod,
null, o, args);
Console.WriteLine(" Result: {0}", result);
}
}
}
public static void Main(String[] args)
{
foreach (string arg in args)
ProcessAssembly(arg);
}
}
After all the files have been compiled, it can be run with the following:
process process1.dll process2.dll
which will generate the following output:
Loading: process1.dll
Found Class: MamaSoft.Processor1
Calling Process() on MamaSoft.Processor1
In Processor1.Process(): 55
Result: Raise the mainsail!
Loading: process2.dll
Found Class: MamaSoft.Processor2
Calling Process() on MamaSoft.Processor2
In Processor2.Process(): 55
Result: Shiver me timbers!
Found Class: MamaSoft.Unrelated
For more information on generating code at execution time, see Chapter 32.
When calling functions with MemberInvoke(), any exceptions thrown will be wrapped in a TargetInvocationException, so the actual exception is accessed through the inner exception.
Reflection can also be used with generic types. The simplest way to determine whether a particular type is generic is the new property of Type called IsGenericTypeDefinition. This property will return true only if the type is generic and the generic types have not been bound to a nongeneric type.
class Program
{
static void Main(string[] args)
{
List<int> list = new List<int>();
//will be false
bool b1 = list.GetType().IsGenericTypeDefinition;
//will be true
bool b2 = list.GetType().GetGenericTypeDefinition().IsGenericTypeDefinition;
}
}
In this case, the IsGenericTypeDefinition returns false for the type List<int>, which is a type that does not have any generic parameters. The method GetGenericTypeDefinition() can be used to get a reference from the constructed type List<int> back to the unbound generic type List<T>. The IsGenericTypeDefinition property returns true for this unbound generic type.
The generic arguments for a type or method can be accessed via the GetGenericArguments() method. Consider the following generic type:
class MyGenericClass<T> { }
The generic parameter can be displayed by the following code:
static void DumpGenericTypeParams(Type type)
{
if (type.IsGenericTypeDefinition)
{
foreach (Type genericType in type.GetGenericArguments())
{
Console.WriteLine(genericType.Name);
}
}
}
The output from this code when run against typeof (MyGenericClass<>) is simply as follows:
T
While simply dumping out the type name may not be overly useful, various reflection methods exist to access information such as the constraints that apply to the generic parameters (Type.GetGenericParameterConstraints()) and to bind generic parameters to nongeneric types (Type.BindGenericParameters()).
The majority of the code optimizations performed in .NET are done by the runtime, but the C# compiler does perform a few optimizations when the /optimize+ flag is used.
- Local variables that are never read are eliminated, even if they are assigned to.
- Unreachable code (code after a return, for example) is eliminated.
- A try-catch with an empty try block is eliminated.
- A try-finally with an empty try is converted to normal code.
- A try-finally with an empty finally is converted to normal code.
- Branch optimization is performed.
- Field initializers that set a member variable to its default value are removed.
Additionally, when optimization is turned on, it enables optimizations by the JIT compiler.
1 My one exception is to use “p” in front of any pointer variables if I am writing unsafe code. That makes it very clear that the variable is something out of the ordinary.
2 Find it at http://www.sandcastledocs.com. Use it with Sandcastle Help File Builder, at http://shfb.codeplex.com.
3 Since their behavior is so different from C++ destructors, re-using the term was probably a bad choice.