
13. Concurrency
Keep it simple:
as simple as possible,
but no simpler.
– A. Einstein
future and promise; packaged_task; async()
• Advice
13.1. Introduction
Concurrency – the execution of several tasks simultaneously – is widely used to improve throughput (by using several processors for a single computation) or to improve responsiveness (by allowing one part of a program to progress while another is waiting for a response). All modern programming languages provide support for this. The support provided by the C++ standard library is a portable and type-safe variant of what has been used in C++ for more than 20 years and is almost universally supported by modern hardware. The standard-library support is primarily aimed at supporting systems-level concurrency rather than directly providing sophisticated higher-level concurrency models; those can be supplied as libraries built using the standard-library facilities.
The standard library directly supports concurrent execution of multiple threads in a single address space. To allow that, C++ provides a suitable memory model and a set of atomic operations. The atomic operations allows lock-free programming [Dechev,2012]. The memory model ensures that as long as a programmer avoids data races (uncontrolled concurrent access to mutable data), everything works as one would naively expect. However, most users will see concurrency only in terms of the standard library and libraries built on top of that. This section briefly gives examples of the main standard-library concurrency support facilities: threads, mutexes, lock() operations, packaged_tasks, and futures. These features are built directly upon what operating systems offer and do not incur performance penalties compared with those. Neither do they guarantee significant performance improvements compared to what the operating system offers.
Do not consider concurrency a panacea. If a task can be done sequentially, it is often simpler and faster to do so.
13.2. Tasks and threads
We call a computation that can potentially be executed concurrently with other computations a task. A thread is the system-level representation of a task in a program. A task to be executed concurrently with other tasks is launched by constructing a std::thread (found in <thread>) with the task as its argument. A task is a function or a function object:
void f(); // function
struct F { // function object
void operator()(); // F's call operator (§5.5)
};
void user()
{
thread t1 {f}; // f() executes in separate thread
thread t2 {F()}; // F()() executes in separate thread
t1.join(); // wait for t1
t2.join(); // wait for t2
}
The join()s ensure that we don’t exit user() until the threads have completed. To “join” a thread means to “wait for the thread to terminate.”
Threads of a program share a single address space. In this, threads differ from processes, which generally do not directly share data. Since threads share an address space, they can communicate through shared objects (§13.5). Such communication is typically controlled by locks or other mechanisms to prevent data races (uncontrolled concurrent access to a variable).
Programming concurrent tasks can be very tricky. Consider possible implementations of the tasks f (a function) and F (a function object):
void f() { cout << "Hello "; }
struct F {
void operator()() { cout << "Parallel World!
"; }
};
This is an example of a bad error: Here, f and F() each use the object cout without any form of synchronization. The resulting output would be unpredictable and could vary between different executions of the program because the order of execution of the individual operations in the two tasks is not defined. The program may produce “odd” output, such as
PaHerallllel o World!
When defining tasks of a concurrent program, our aim is to keep tasks completely separate except where they communicate in simple and obvious ways. The simplest way of thinking of a concurrent task is as a function that happens to run concurrently with its caller. For that to work, we just have to pass arguments, get a result back, and make sure that there is no use of shared data in between (no data races).
13.3. Passing Arguments
Typically, a task needs data to work upon. We can easily pass data (or pointers or references to the data) as arguments. Consider:
void f(vector<double>& v); // function do something with v
struct F { // function object: do something with v
vector<double>& v;
F(vector<double>& vv) :v{vv} { }
void operator()(); // application operator; §5.5
};
int main()
{
vector<double> some_vec {1,2,3,4,5,6,7,8,9};
vector<double> vec2 {10,11,12,13,14};
thread t1 {f,ref(some_vec)}; // f(some_vec) executes in a separate thread
thread t2 {F{vec2}}; // F(vec2)() executes in a separate thread
t1.join();
t2.join();
}
Obviously, F{vec2} saves a reference to the argument vector in F. F can now use that vector and hopefully no other task accesses vec2 while F is executing. Passing vec2 by value would eliminate that risk.
The initialization with {f,ref(some_vec)} uses a thread variadic template constructor that can accept an arbitrary sequence of arguments (§5.6). The ref() is a type function from <functional> that unfortunately is needed to tell the variadic template to treat some_vec as a reference, rather than as an object. The compiler checks that the first argument can be invoked given the following arguments and builds the necessary function object to pass to the thread. Thus, if F::operator()() and f() perform the same algorithm, the handling of the two tasks are roughly equivalent: in both cases, a function object is constructed for the thread to execute.
13.4. Returning Results
In the example in §13.3, I pass the arguments by non-const reference. I only do that if I expect the task to modify the value of the data referred to (§1.8). That’s a somewhat sneaky, but not uncommon, way of returning a result. A less obscure technique is to pass the input data by const reference and to pass the location of a place to deposit the result as a separate argument:
void f(const vector<double>& v, double* res); // take input from v; place result in *res
class F {
public:
F(const vector<double>& vv, double* p) :v{vv}, res{p} { }
void operator()(); // place result in *res
private:
const vector<double>& v; // source of input
double* res; // target for output
};
int main()
{
vector<double> some_vec;
vector<double> vec2;
// ...
double res1;
double res2;
thread t1 {f,cref(some_vec),&res1}; // f(some_vec,&res1) executes in a separate thread
thread t2 {F{vec2,&res2}}; // F{vec2,&res2}() executes in a separate thread
t1.join();
t2.join();
cout << res1 << ' ' << res2 << '
';
}
This works and the technique is very common, but I don’t consider returning results through arguments particularly elegant, so I return to this topic in §13.7.1.
13.5. Sharing Data
Sometimes tasks need to share data. In that case, the access has to be synchronized so that at most one task at a time has access. Experienced programmers will recognize this as a simplification (e.g., there is no problem with many tasks simultaneously reading immutable data), but consider how to ensure that at most one task at a time has access to a given set of objects.
The fundamental element of the solution is a mutex, a “mutual exclusion object.” A thread acquires a mutex using a lock() operation:
mutex m; // controlling mutex
int sh; // shared data
void f()
{
unique_lock<mutex> lck {m}; // acquire mutex
sh += 7; // manipulate shared data
} // release mutex implicitly
The unique_lock’s constructor acquires the mutex (through a call m.lock()). If another thread has already acquired the mutex, the thread waits (“blocks”) until the other thread completes its access. Once a thread has completed its access to the shared data, the unique_lock releases the mutex (with a call m.unlock()). When a mutex is released, threads waiting for it resume executing (“are woken up”). The mutual exclusion and locking facilities are found in <mutex>.
The correspondence between the shared data and a mutex is conventional: the programmer simply has to know which mutex is supposed to correspond to which data. Obviously, this is error-prone, and equally obviously we try to make the correspondence clear through various language means. For example:
class Record {
public:
mutex rm;
// ...
};
It doesn’t take a genius to guess that for a Record called rec, rec.rm is a mutex that you are supposed to acquire before accessing the other data of rec, though a comment or a better name might have helped a reader.
It is not uncommon to need to simultaneously access several resources to perform some action. This can lead to deadlock. For example, if thread1 acquires mutex1 and then tries to acquire mutex2 while thread2 acquires mutex2 and then tries to acquire mutex1, then neither task will ever proceed further. The standard library offers help in the form of an operation for acquiring several locks simultaneously:
void f()
{
// ...
unique_lock<mutex> lck1 {m1,defer_lock}; // defer_lock: don't yet try to acquire the mutex
unique_lock<mutex> lck2 {m2,defer_lock};
unique_lock<mutex> lck3 {m3,defer_lock};
// ...
lock(lck1,lck2,lck3); // acquire all three locks
// ... manipulate shared data ...
} // implicitly release all mutexes
This lock() will proceed only after acquiring all its mutex arguments and will never block (“go to sleep”) while holding a mutex. The destructors for the individual unique_locks ensure that the
mutexes are released when a thread leaves the scope.
Communicating through shared data is pretty low level. In particular, the programmer has to devise ways of knowing what work has and has not been done by various tasks. In that regard, use of shared data is inferior to the notion of call and return. On the other hand, some people are convinced that sharing must be more efficient than copying arguments and returns. That can indeed be so when large amounts of data are involved, but locking and unlocking are relatively expensive operations. On the other hand, modern machines are very good at copying data, especially compact data, such as vector elements. So don’t choose shared data for communication because of “efficiency” without thought and preferably not without measurement.
13.6. Waiting for Events
Sometimes, a thread needs to wait for some kind of external event, such as another thread completing a task or a certain amount of time having passed. The simplest “event” is simply time passing. Using the time facilities found in <chrono> I can write:
using namespace std::chrono; // see §11.4
auto t0 = high_resolution_clock::now();
this_thread::sleep_for(milliseconds{20});
auto t1 = high_resolution_clock::now();
cout << duration_cast<nanoseconds>(t1-t0).count() << " nanoseconds passed
";
Note that I didn’t even have to launch a thread; by default, this_thread refers to the one and only thread.
I used duration_cast to adjust the clock’s units to the nanoseconds I wanted.
The basic support for communicating using external events is provided by condition_variables found in <condition_variable>. A condition_variable is a mechanism allowing one thread to wait for another. In particular, it allows a thread to wait for some condition (often called an event) to occur as the result of work done by other threads.
Using condition_variables supports many forms of elegant and efficient sharing, but can be rather tricky. Consider the classical example of two threads communicating by passing messages through a queue. For simplicity, I declare the queue and the mechanism for avoiding race conditions on that queue global to the producer and consumer:
class Message { // object to be communicated
// ...
};
queue<Message> mqueue; // the queue of messages
condition_variable mcond; // the variable communicating events
mutex mmutex; // the locking mechanism
The types queue, condition_variable, and mutex are provided by the standard library.
The consumer() reads and processes Messages:
void consumer()
{
while(true) {
unique_lock<mutex> lck{mmutex}; // acquire mmutex
while (mcond.wait(lck)) /* do nothing */; // release lck and wait;
// re-acquire lck upon wakeup
auto m = mqueue.front(); // get the message
mqueue.pop();
lck.unlock(); // release lck
// ... process m ...
}
}
Here, I explicitly protect the operations on the queue and on the condition_variable with a
unique_lock on the mutex. Waiting on condition_variable releases its lock argument until the wait is over (so that the queue is non-empty) and then reacquires it.
The corresponding producer looks like this:
void producer()
{
while(true) {
Message m;
// ... fill the message ...
unique_lock<mutex> lck {mmutex}; // protect operations
mqueue.push(m);
mcond.notify_one(); // notify
} // release lock (at end of scope)
}
13.7. Communicating Tasks
The standard library provides a few facilities to allow programmers to operate at the conceptual level of tasks (work to potentially be done concurrently) rather than directly at the lower level of threads and locks:
[1] future and promise for returning a value from a task spawned on a separate thread
[2] packaged_task to help launch tasks and connect up the mechanisms for returning a result
[3] async() for launching of a task in a manner very similar to calling a function. These facilities are found in <future>.
13.7.1. future and promise
The important point about future and promise is that they enable a transfer of a value between two tasks without explicit use of a lock; “the system” implements the transfer efficiently. The basic idea is simple: When a task wants to pass a value to another, it puts the value into a promise. Somehow, the implementation makes that value appear in the corresponding future, from which it can be read (typically by the launcher of the task). We can represent this graphically:
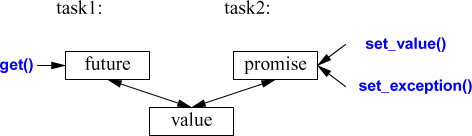
If we have a future<X> called fx, we can get() a value of type X from it:
X v = fx.get(); // if necessary, wait for the value to get computed
If the value isn’t there yet, our thread is blocked until it arrives. If the value couldn’t be computed,
get() might throw an exception (from the system or transmitted from the task from which we were trying to get() the value).
The main purpose of a promise is to provide simple “put” operations (called set_value() and set_exception()) to match future’s get(). The names “future” and “promise” are historical; please don’t blame or credit me. They are yet another fertile source of puns.
If you have a promise and need to send a result of type X to a future, you can do one of two things: pass a value or pass an exception. For example:
void f(promise<X>& px) // a task: place the result in px
{
// ...
try {
X res;
// ... compute a value for res ...
px.set_value(res);
}
catch (...) { // oops: couldn't compute res
px.set_exception(current_exception()); // pass the exception to the future's thread
}
}
The current_exception() refers to the caught exception.
To deal with an exception transmitted through a future, the caller of get() must be prepared to catch it somewhere. For example:
void g(future<X>& fx) // a task: get the result from fx
{
// ...
try {
X v = fx.get(); // if necessary, wait for the value to get computed
// ... use v ...
}
catch (...) { // oops: someone couldn't compute v
// ... handle error ...
}
}
If the error doesn’t need to be handled by g() itself, the code reduces to the minimal:
void g(future<X>& fx) // a task: get the result from fx
{
// ...
X v = fx.get(); // if necessary, wait for the value to get computed
// ... use v ...
}
13.7.2. packaged_task
How do we get a future into the task that needs a result and the corresponding promise into the thread that should produce that result? The packaged_task type is provided to simplify setting up tasks connected with futures and promises to be run on thread futures. A packaged_task provides wrapper code to put the return value or exception from the task into a promise (like the code shown in §13.7.1). If you ask it by calling get_future, a packaged_task will give you the future corresponding to its promise. For example, we can set up two tasks to each add half of the elements of a vector<double> using the standard-library accumulate() (§12.3):
double accum(double* beg, double* end, double init)
// compute the sum of [beg:end) starting with the initial value init
{
return accumulate(beg,end,init);
}
double comp2(vector<double>& v)
{
using Task_type = double(double*,double*,double); // type of task
packaged_task<Task_type> pt0 {accum}; // package the task (i.e., accum)
packaged_task<Task_type> pt1 {accum};
future<double> f0 {pt0.get_future()}; // get hold of pt0's future
future<double> f1 {pt1.get_future()}; // get hold of pt1's future
double* first = &v[0];
thread t1 {move(pt0),first,first+v.size()/2,0}; // start a thread for pt0
thread t2 {move(pt1),first+v.size()/2,first+v.size(),0}; // start athread for pt1
// ...
return f0.get()+f1.get(); // get the results
}
The packaged_task template takes the type of the task as its template argument (here Task_type, an alias for double(double *, double *,double)) and the task as its constructor argument (here, accum). The move() operations are needed because a packaged_task cannot be copied. The reason that a packaged_task cannot be copied is that it is a resource handle: it owns its promise and is (indirectly) responsible for whatever resoures its task may own.
Please note the absence of explicit mention of locks in this code: we are able to concentrate on tasks to be done, rather than on the mechanisms used to manage their communication. The two tasks will be run on separate threads and thus potentially in parallel.
13.7.3. async()
The line of thinking I have pursued in this chapter is the one I believe to be the simplest yet still among the most powerful: Treat a task as a function that may happen to run concurrently with other tasks. It is far from the only model supported by the C++ standard library, but it serves well for a wide range of needs. More subtle and tricky models, e.g., styles of programming relying on shared memory, can be used as needed.
To launch tasks to potentially run asynchronously, we can use async():
double comp4(vector<double>& v)
// spawn many tasks if v is large enough
{
if (v.size()<10000) // is it worth using concurrency?
return accum(v.begin(),v.end(),0.0);
auto v0 = &v[0];
auto sz = v.size();
auto f0 = async(accum,v0,v0+sz/4,0.0); // first quarter
auto f1 = async(accum,v0+sz/4,v0+sz/2,0.0); // second quarter
auto f2 = async(accum,v0+sz/2,v0+sz*3/4,0.0); // third quarter
auto f3 = async(accum,v0+sz*3/4,v0+sz,0.0); // fourth quarter
return f0.get()+f1.get()+f2.get()+f3.get(); // collect and combine the results
}
Basically, async() separates the “call part” of a function call from the “get the result part,” and separates both from the actual execution of the task. Using async(), you don’t have to think about threads and locks. Instead, you think just in terms of tasks that potentially compute their results asynchronously. There is an obvious limitation: Don’t even think of using async() for tasks that share resources needing locking – with async() you don’t even know how many threads will be used because that’s up to async() to decide based on what it knows about the system resources available at the time of a call. For example, async() may check whether any idle cores (processors) are available before deciding how many threads to use.
Using a guess about the cost of computation relative to the cost of launching a thread, such as
v.size()<10000, is very primitive and prone to gross mistakes about performance. However, this is not the place for a proper disussion about how to manage threads. Don’t take this estimate as more than a simple and probably poor guess.
Please note that async() is not just a mechanism specialized for parallel computation for increased performance. For example, it can also be used to spawn a task for getting information from a user, leaving the “main program” active with something else (§13.7.3).
13.8. Advice
[1] The material in this chapter roughly corresponds to what is described in much greater detail in Chapters 41-42 of [Stroustrup,2013].
[2] Use concurrency to improve responsiveness or to improve throughput; §13.1.
[3] Work at the highest level of abstraction that you can afford; §13.1.
[4] Consider processes as an alternative to threads; §13.1.
[5] The standard-library concurrency facilities are type safe; §13.1.
[6] The memory model exists to save most programmers from having to think about the machine architecture level of computers; §13.1.
[7] The memory model makes memory appear roughly as naively expected; §13.1.
[8] Atomics allow for lock-free programming; §13.1.
[9] Leave lock-free programming to experts; §13.1.
[10] Sometimes, a sequential solution is simpler and faster than a concurrent solution; §13.1.
[11] Avoid data races; §13.1, §13.2.
[12] A thread is a type-safe interface to a system thread; §13.2.
[13] Use join() to wait for a thread to complete; §13.2.
[14] Avoid explicitly shared data whenever you can; §13.2.
[15] Use unique_lock to manage mutexes; §13.5.
[16] Use lock() to acquire multiple locks; §13.5.
[17] Use condition_variables to manage communication among threads; §13.6.
[18] Think in terms of tasks that can be executed concurrently, rather than directly in terms of
threads; §13.7.
[19] Value simplicity; §13.7.
[20] Prefer packaged_task and futures over direct use of threads and mutexes; §13.7.
[21] Return a result using a promise and get a result from a future; §13.7.1.
[22] Use packaged_tasks to handle exceptions thrown by tasks and to arrange for value return; §13.7.2.
[23] Use a packaged_task and a future to express a request to an external service and wait for its response; §13.7.2.
[24] Use async() to launch simple tasks; §13.7.3.