
Chapter 8. Asynchronous I/O and the ACE Proactor Framework
Applications that must perform I/O on multiple endpoints—whether network sockets, pipes, or files—historically use one of two I/O models:
- Reactive. An application based on the reactive model registers event handler objects that are notified when it's possible to perform one or more desired I/O operations, such as receiving data on a socket, with a high likelihood of immediate, successful completion. The ACE Reactor framework, described in Chapter 7, supports the reactive model.
- Multithreaded. An application spawns multiple threads that each perform synchronous, often blocking, I/O operations. This model doesn't scale very well for applications with large numbers of open endpoints.
Reactive I/O is the most common model, especially for networked applications. It was popularized by wide use of the select() function to demultiplex I/O across file descriptors in the BSD Sockets API. Asynchronous I/O, also known as proactive I/O, is often a more scalable way to perform I/O on many endpoints. It is asynchronous because the I/O request and its completion are separate, distinct events that occur at different times. Proactive I/O allows an application to initiate one or more I/O requests on multiple I/O endpoints in parallel without blocking for their completion. As each operation completes, the OS notifies a completion handler that then processes the results.
Asynchronous I/O has been in use for many years on such OS platforms as OpenVMS and on IBM mainframes. It's also been available for a number of years on Windows and more recently on some POSIX platforms. This chapter explains more about asynchronous I/O and the proactive model and then explains how to use the ACE Proactor framework to your best advantage.
8.1 Why Use Asynchronous I/O?
Reactive I/O operations are often performed in a single thread, driven by the reactor's event-dispatching loop. Each thread, however, can execute only one I/O operation at a time. This sequential nature can be a bottleneck, as applications that transfer large amounts of data on multiple endpoints can't use the parallelism available from the OS and/or multiple CPUs or network interfaces.
Multithreaded I/O alleviates the main bottleneck of single-threaded reactive I/O by taking advantage of concurrency strategies, such as the thread-pool model, available using the ACE_TP_Reactor and ACE_WFMO_Reactor reactor implementations, or the thread-per-connection model, which often uses synchronous, blocking I/O. Multithreading can help parallelize an application's I/O operations, which may improve performance. This technique can also be very intuitive, especially when using serial, blocking function calls. However, it is not always the best choice, for the following reasons:
• Threading policy tightly coupled to concurrency policy. A separate thread is required for each desired concurrent operation or request. It would be much better to define threading policy by available resources, possibly factoring in the number of available CPUs, using a thread pool.
• Increased synchronization complexity. If request processing requires shared access to data, all threads must serialize data access. This involves another level of analysis and design, as well as further complexity.
• Synchronization performance penalty. Overhead related to context switching and scheduling, as well as interlocking/competing threads, can degrade performance significantly.
Therefore, using multiple threads is not always a good choice if done solely to increase I/O parallelism.
The proactive I/O model entails two distinct steps.
These two steps are essentially the inverse of those in the reactive I/O model.
- Use an event demultiplexer to determine when an I/O operation is possible and likely to complete immediately.
- Perform the operation.
Unlike conventional reactive or synchronous I/O models, the proactive model allows a single application thread to initiate multiple operations simultaneously. This design allows a single-threaded application to execute I/O operations concurrently without incurring the overhead or design complexity associated with conventional multithreaded mechanisms.
Choose the proactive I/O model when
• The IPC mechanisms in use, such as Windows Named Pipes, require it
• The application can benefit significantly from parallel I/O operations
• Reactive model limitations—limited handles or performance—prevent its use
8.2 How to Send and Receive Data
The procedure for sending and receiving data asynchronously is a bit different from using synchronous transfers. We'll look at an example, explore what the example does, and point out some similarities and differences between using the Proactor framework and the Reactor framework.
The Proactor framework encompasses a relatively large set of highly related classes, so it's impossible to discuss them in order without forward references. We will get through them all by the end of the chapter. Figure 8.1 shows the Proactor framework's classes in relation to each other; you can use the figure to keep some context as we progress through the chapter.
Figure 8.1. Classes in the Proactor framework
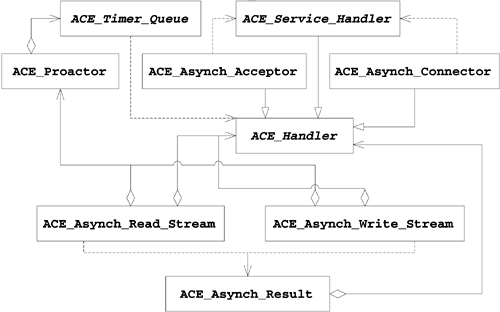
The following code declares a class that performs the same basic work as the examples in the previous two chapters, introducing the primary classes involved in initiating and completing I/O requests on a connected TCP/IP socket:
#include "ace/Asynch_IO.h"
class HA_Proactive_Service : public ACE_Service_Handler
{
public:
~HA_Proactive_Service ()
{
if (this->handle () != ACE_INVALID_HANDLE)
ACE_OS::closesocket (this->handle ());
}
virtual void open (ACE_HANDLE h, ACE_Message_Block&);
// This method will be called when an asynchronous read
// completes on a stream.
virtual void handle_read_stream
(const ACE_Asynch_Read_Stream::Result &result);
// This method will be called when an asynchronous write
// completes on a stream.
virtual void handle_write_stream
(const ACE_Asynch_Write_Stream::Result &result);
private:
ACE_Asynch_Read_Stream reader_;
ACE_Asynch_Write_Stream writer_;
};
This example begins by including the necessary header files for the Proactor framework classes that this example uses:
• ACE_Service_Handler, the target class for creation of new service handlers in the Proactor framework, similar to the role played by ACE_Svc_Handler in the Acceptor-Connector framework.
• ACE_Handler, the parent class of ACE_Service_Handler, which defines the interface for handling asynchronous I/O completions via the Proactor framework. The ACE_Handler class is analogous to the ACE_Event_Handler in the Reactor framework.
• ACE_Asynch_Read_Stream, the I/O factory class for initiating read operations on a connected TCP/IP socket.
• ACE_Asynch_Write_Stream, the I/O factory class for initiating write operations on a connected TCP/IP socket.
• Result, which each I/O factory class defines as a nested class to contain the result of each operation the factory initiates. All the Result classes are derived from ACE_Asynch_Result and have added data and methods particular to the type of I/O they're defined for. Because the initiation and completion of each asynchronous I/O operation are separate and distinct events, a mechanism is needed to “remember” the operation parameters and relay them, along with the result, to the completion handler.
So why are there all these classes, many of which seem so close in purpose to classes in the Acceptor-Connector framework we saw in Chapter 7? The asynchronous I/O model splits the I/O initiation and completion actions, as they're not coupled. ACE needs to do this without cluttering the classes that are designed for reactive or synchronous operation.
8.2.1 Setting up the Handler and Initiating I/O
When a TCP connection is opened, the handle of the new socket should be passed to the handler object—in this example's case, HA_Proactive_Service. It's helpful to put the handle in the handler for the following reasons.
• It is a convenient point of control for the socket's lifetime, as it's the target of the connection factories.
• It's most often the class from which I/O operations are initiated.
When using the Proactor framework's asynchronous connection establishment classes (we'll look at these in Section 8.3), the ACE_Service_Handler::open() hook method is called when a new connection is established. Our example's open() hook follows:
void
HA_Proactive_Service::open (ACE_HANDLE h, ACE_Message_Block&)
{
this->handle (h);
if (this->reader_.open (*this) != 0 ||
this->writer_.open (*this) != 0 )
{
ACE_ERROR ((LM_ERROR, ACE_TEXT ("%p
"),
ACE_TEXT ("HA_Proactive_Service open")));
delete this;
return;
}
ACE_Message_Block *mb;
ACE_NEW_NORETURN (mb, ACE_Message_Block (1024));
if (this->reader_.read (*mb, mb->space ()) != 0)
{
ACE_ERROR ((LM_ERROR, ACE_TEXT ("%p
"),
ACE_TEXT ("HA_Proactive_Service begin read")));
mb->release ();
delete this;
return;
}
// mb is now controlled by Proactor framework.
return;
}
Right at the beginning, the new socket's handle is saved using the inherited ACE_Handler::handle() method. This method stores the handle in a convenient place for, among other things, access by the HA_Proactive_Service destructor, shown on page 189. This is part of the socket handle's lifetime management implemented in this class.
In order to initiate I/O, you have to initialize the I/O factory objects you need. After storing the socket handle, our open() method initializes the reader_ and writer_ I/O factory objects in preparation for initiating I/O operations. The complete signature of the open() method on both classes is:
int open (ACE_Handler &handler,
ACE_HANDLE handle = ACE_INVALID_HANDLE,
const void *completion_key = 0,
ACE_Proactor *proactor = 0);
This first argument represents the completion handler for operations initiated by the factory object. The Proactor framework will call back to this object when I/O operations initiated via the factory object complete. That's why the handler object is referred to as a completion handler. In our example, the HA_Proactive_Service class is a descendant of ACE_Handler and will be the completion handler for both read and write operations, so *this is the handler argument. All other arguments are defaulted. Because we don't pass a handle, the I/O factories will call HA_Proactive_Service::handle() to obtain the socket handle. This is another reason we stored the handle value immediately on entry to open().
The completion_key argument is used only on Windows; it is seldom used, so we don't discuss it here. The proactor argument is also defaulted. In this case, a processwide singleton ACE_Proactor object will be used. If a specific ACE_Proactor instance is needed, the proactor argument must be supplied.
The last thing our open() hook method does is initiate a read operation on the new socket by calling the ACE_Asynch_Read_Stream::read() method. The signature for ACE_Asynch_Read_Stream::read() is:
int read (ACE_Message_Block &message_block,
size_t num_bytes_to_read,
const void *act = 0,
int priority = 0,
int signal_number = ACE_SIGRTMIN);
The most obvious difference between asynchronous read operations and their synchronous counterparts is that an ACE_Message_Block rather than a buffer pointer or iovec array is specified for the transfer. This makes buffer management easier, as you can take advantage of ACE_Message_Block's capabilities and integration with other parts of ACE, such as ACE_Message_Queue. ACE_Message_Block is described in more detail starting on page 261. When a read is initiated, data is read into the block starting at the block's write pointer, as the read data will be written into the block.
8.2.2 Completing I/O Operations
Both the Proactor framework and the Reactor framework (Chapter 7) are event based. However, rather than registering event handler objects to be notified when I/O is possible, the I/O factories establish an association between each operation and the completion handler that should be called back when the operation completes. Each type of I/O operation has its own callback method. In our example using TCP/IP, the Proactor framework calls the ACE_Handler::handle_read_stream() hook method when the read completes. Our example's hook method follows:
void
HA_Proactive_Service::handle_read_stream
(const ACE_Asynch_Read_Stream::Result &result)
{
ACE_Message_Block &mb = result.message_block ();
if (!result.success () || result.bytes_transferred () == 0)
{
mb.release ();
delete this;
}
else
{
if (this->writer_.write (mb, mb.length ()) != 0)
{
ACE_ERROR ((LM_ERROR,
ACE_TEXT ("%p
"),
ACE_TEXT ("starting write")));
mb.release ();
}
else
{
ACE_Message_Block *new_mb;
ACE_NEW_NORETURN (new_mb, ACE_Message_Block (1024));
this->reader_.read (*new_mb, new_mb->space ());
}
}
return;
}
The passed-in ACE_Asynch_Read_Stream::Result refers to the object holding the results of the read operation. Each I/O factory class defines its own Result class to hold both the parameters each operation is initiated with and the results of the operation. The message block used in the operation is referred to via the message_block() method. The Proactor framework automatically advances the block's write pointer to reflect the added data, if any. The handle_read_stream() method first checks whether the operation either failed or completed successfully but read 0 bytes. (As in synchronous socket reads, a 0-byte read indicates that the peer has closed its end of the connection.) If either of these cases is true, the message block is released and the handler object deleted. The handler's destructor will close the socket.
If the read operation read any data, we do two things:
- Initiate a write operation to echo the received data back to the peer. Because the Proactor framework has already updated the message block's write pointer, we can simply use the block as is. The read pointer is still pointing to the start of the data, and a write operation uses the block's read pointer to read data out of the block and write it on the socket.
- Allocate a new
ACE_Message_Blockand initiate a new read operation to read the next set of data from the peer.
When the write operation completes, the Proactor framework calls the following handle_write_stream() method:
void
HA_Proactive_Service::handle_write_stream
(const ACE_Asynch_Write_Stream::Result &result)
{
result.message_block ().release ();
return;
}
Regardless of whether the write completed successfully, the message block that was used in the operation is released. If a socket is broken, the previously initiated read operation will also complete with an error, and handle_read_stream() will clean up the object and socket handle. More important, note that the same ACE_Message_Block object was used to read data from the peer and echo it back. After it has been used for both operations, it is released.
The sequence of events in this example is illustrated in Figure 8.2. The example presented in this section illustrates the following principles and guidelines for using asynchronous I/O in the ACE Proactor framework.
• ACE_Message_Block is used for all transfers. All read and write transfers use ACE_Message_Block rather than other types of buffer pointers and counts. This enables ease of data movement around other parts of ACE, such as queueing data to an ACE_Message_Queue, or other frameworks that reuse ACE_Message_Queue, such as the ACE Task framework (described in Chapter 12) or the ACE Streams framework (described in Chapter 18). Using the common message block class makes it possible for the Proactor framework to automatically update the block's read and write pointers as data is transferred, relieving you of this tedious task. When you design the class(es) involved in initiating and completing I/O operations, you must decide on how the blocks are allocated: statically or dynamically. However, it is generally more flexible to allocate the blocks dynamically.
• Cleanup has very few restrictions but must be managed carefully. In the preceding example, the usual response to an error condition is to delete the handler object. After working with the ACE Reactor framework and its rules for event handler registration and cleanup, this “just delete it” simplicity may seem odd. Remember that the Proactor framework has no explicit handler registrations, as there are with the Reactor framework.1 The only connection between the Proactor and the completion handler object is an outstanding I/O operation. Therein lies an important restriction on completion handler cleanup. If any I/O operations are outstanding, you can't release the ACE_Message_Block that an outstanding operation refers to. Even if the Proactor event loop isn't running, an initiated operation may be processed by the OS. If it is a receive, the data will still be put where the original message block used to be. If the operation is a send, something will be sent; if the block has since been released, you don't know what will be sent. If the Proactor event loop is still running, the Proactor framework will, when the I/O operation(s) complete, issue callback(s) to the associated handler, which must be valid, or your program's behavior will be undefined and almost surely wrong.
Each I/O factory class offers a cancel() method that can be used to attempt to cancel any outstanding I/O operations. Not all operations can be canceled, however. Different operating systems offer different levels of support for canceling operations, sometimes varying with I/O type on the same system. For example, many disk I/O requests that haven't started to execute can be canceled, but many socket operations cannot. Sometimes, closing the I/O handle on which the I/O is being performed will abort an I/O request and sometimes not. It's often a good idea to keep track of the number of outstanding I/O requests and wait for them all to complete before destroying a handler.
Figure 8.2. Sequence diagram for asynchronous data echo example
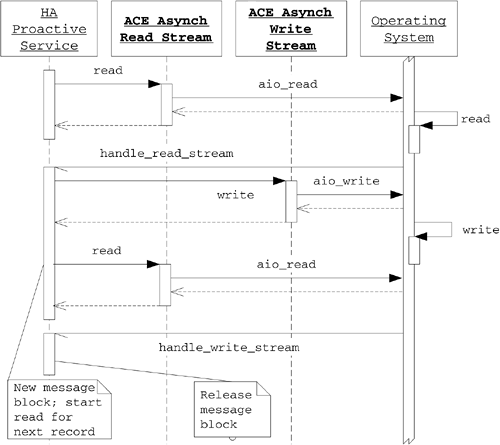
8.3 Establishing Connections
ACE provides two factory classes for proactively establishing TCP/IP connections using the Proactor framework:
ACE_Asynch_Acceptor, to initiate passive connection establishmentACE_Asynch_Connectorto initiate active connection establishment
When a TCP/IP connection is established using either of these classes, the ACE Proactor framework creates a service handler derived from ACE_Service_Handler, such as HA_Proactive_Service, to handle the new connection. The ACE_Service_Handler class, the base class of all asynchronously connected services in the ACE Proactor framework, is derived from ACE_Handler, so the service class can also handle I/O completions initiated in the service.
ACE_Asynch_Acceptor is a fairly easy class to program with. It is very straightforward in its default case and adds two hooks for extending its capabilities. The following example uses one of the hooks:
#include "ace/Asynch_Acceptor.h"
#include "ace/INET_Addr.h"
class HA_Proactive_Acceptor :
public ACE_Asynch_Acceptor<HA_Proactive_Service>
{
public:
virtual int validate_connection
(const ACE_Asynch_Accept::Result& result,
const ACE_INET_Addr &remote,
const ACE_INET_Addr &local);
};
We declare HA_Proactive_Acceptor to be a new class derived from ACE_Asynch_Acceptor. As you can see, ACE_Asynch_Acceptor is a class template, similar to the way ACE_Acceptor is. The template argument is the type of ACE_Service_Handler-derived class to use for each new connection.
The validate_connection() method is a hook method defined on both ACE_Asynch_Acceptor and ACE_Asynch_Connector. The framework calls this method after accepting a new connection, before obtaining a new service handler for it. This method gives the application a chance to verify the connection and/or the address of the peer. Our example checks whether the peer is on the same IP network as we are:
int
HA_Proactive_Acceptor::validate_connection (
const ACE_Asynch_Accept::Result&,
const ACE_INET_Addr& remote,
const ACE_INET_Addr& local)
{
struct in_addr *remote_addr =
ACE_reinterpret_cast (struct in_addr*,
remote.get_addr ());
struct in_addr *local_addr =
ACE_reinterpret_cast (struct in_addr*,
local.get_addr ());
if (inet_netof (*local_addr) == inet_netof (*remote_addr))
return 0;
return -1;
}
This check is fairly simple and works only for IPv4 networks but is an example of the hook's use. The handle of the newly accepted socket is available via the ACE_Asynch_Accept::Result::accept_handle() method, so it is possible to do more involved checks that require data exchange. For example, an SSL (Secure Sockets Layer) handshake could be added at this point. If validate_connection() returns –1, the new connection is immediately aborted.
The other hook method available via ACE_Asynch_Acceptor is a protected virtual method: make_handler(). The Proactor framework calls this method to obtain an ACE_Service_Handler object to service the new connection. The default implementation simply allocates a new handler and is, essentially:
template <class HANDLER>
class ACE_Asynch_Acceptor : public ACE_Handler
...
protected:
virtual HANDLER *make_handler (void)
{
return new HANDLER;
}
If your application requires a different way of obtaining a handler, you should override the make_handler() hook method. For example, a singleton handler could be used, or you could keep a list of handlers in use.
The following code shows how we use the HA_Proactive_Acceptor class just described:
ACE_INET_Addr listen_addr; // Set up with listen port
HA_Proactive_Acceptor aio_acceptor;
if (0 != aio_acceptor.open (listen_addr,
0, // bytes_to_read
0, // pass_addresses
ACE_DEFAULT_BACKLOG,
1, // reuse_addr
0, // proactor
1)) // validate_new_connection
ACE_ERROR_RETURN ((LM_ERROR, ACE_TEXT ("%p
"),
ACE_TEXT ("acceptor open")), 1);
To initialize the acceptor object and begin accepting connections, call the open() method. The only required argument is the first: the address to listen on. The backlog and reuse_addr parameters are the same as for ACE_SOCK_Acceptor, and the default proactor argument selects the process's singleton instance. The nonzero validate_new_connection argument directs the framework to call the validate_connection() method on the new handler when accepting a new connection, as discussed earlier.
The bytes_to_read argument can specify a number of bytes to read immediately on connection acceptance. This is not universally supported by underlying protocol implementations and is very seldom used. If used, however, it would be what causes data to be available in the message block passed to ACE_Service_Handler::open(), as we saw in our example on page 192.
The pass_addresses argument is of some importance if your handler requires the local and peer addresses when running the service. The only portable way to obtain the local and peer addresses for asynchronously established connections is to implement the ACE_Service_Handler::addresses() hook method and pass a nonzero value as the pass_addresses argument to ACE_Asynch_Acceptor::open().
Actively establishing connections is very similar to passively accepting them. The hook methods are similar. The following could be used to actively establish a connection and instantiate an HA_Proactive_Service object to service the new connection:
ACE_INET_Addr peer_addr; // Set up peer addr
ACE_Asynch_Connector<HA_Proactive_Service> aio_connect;
aio_connect.connect (peer_addr);
8.4 The ACE_Proactor Completion Demultiplexer
The ACE_Proactor class drives completion handling in the ACE Proactor framework. This class waits for completion events that indicate that one or more operations started by the I/O factory classes have completed, demultiplexes those events to the associated completion handlers, and dispatches the appropriate hook method on each completion handler. Thus, for any asynchronous I/O completion event processing to take place—whether I/O or connection establishment—your application must run the proactor's event loop. This is usually as simple as inserting the following in your application:
ACE_Proactor::instance ()->proactor_run_event_loop ();
Asynchronous I/O facilities vary wildly between operating systems. To maintain a uniform interface and programming method across all of them, the ACE_Proactor class, like ACE_Reactor, uses the Bridge pattern to maintain flexibility and extensibility while allowing the Proactor framework to function with differing asynchronous I/O implementations. We briefly describe the implementation-specific Proactor classes next.
8.4.1 ACE_WIN32_Proactor
ACE_WIN32_Proactor is the ACE_Proactor implementation on Windows. This class works on Windows NT 4.0 and newer Windows platforms, such as Windows 2000 and Windows XP, but not on Windows 95, 98, ME, or CE, however, as these platforms don't support asynchronous I/O.
ACE_WIN32_Proactor uses an I/O completion port for completion event detection. When initializing an asynchronous operation factory, such as ACE_Asynch_Read_Stream or ACE_Asynch_Write_Stream, the I/O handle is associated with the Proactor's I/O completion port. In this implementation, the Windows GetQueuedCompletionStatus() function paces the event loop. Multiple threads can execute the ACE_WIN32_Proactor event loop simultaneously.
8.4.2 ACE_POSIX_Proactor
The ACE Proactor implementations on POSIX systems present multiple mechanisms for initiating I/O operations and detecting their completions. Moreover, Sun's Solaris Operating Environment offers its own proprietary version of asynchronous I/O. On Solaris 2.6 and higher, the performance of the Sun-specific asynchronous I/O functions is significantly higher than that of Solaris's POSIX.4 AIO implementation. To take advantage of this performance improvement, ACE also encapsulates this mechanism in a separate set of classes.
The encapsulated POSIX asynchronous I/O mechanisms support read() and write() operations but not TCP/IP connection related operations. To support the functions of ACE_Asynch_Acceptor and ACE_Asynch_Connector, a separate thread is used to perform connection-related operations. Therefore, you should be aware that your program will be running multiple threads when using the Proactor framework on POSIX platforms. The internals of ACE keep you from needing to handle events in different threads, so you don't need to add any special locking or synchronization. Just be aware of what's going on if you're in the debugger and see threads that your program didn't spawn.
8.5 Using Timers
In addition to its I/O-related capabilities, the ACE Proactor framework offers settable timers, similar to those offered by the ACE Reactor framework. They're programmed in a manner very similar to programming timers with the Reactor framework, but the APIs are slightly different. Check the reference documentation for complete details.
8.6 Other I/O Factory Classes
As with the Reactor framework, the Proactor framework has facilities to work with many different types of I/O endpoints. Unlike the synchronous IPC wrapper classes in ACE, which have a separate class for each type of IPC, the Proactor framework offers a smaller set of factory classes and relies on you to supply each with a handle. An I/O handle from any ACE IPC wrapper class, such as ACE_SOCK_Stream or ACE_FILE_IO, may be used with these I/O factory classes as listed:
• ACE_Asynch_Read_File and ACE_Asynch_Write_File for files and Windows Named Pipes
• ACE_Asynch_Transmit_File to transmit files over a connected TCP/IP stream
• ACE_Asynch_Read_Dgram and ACE_Asynch_Write_Dgram for UDP/IP datagram sockets
8.7 Combining the Reactor and Proactor Frameworks
Sometimes, you have a Reactor-based system and need to add an IPC type that doesn't work with the Reactor model. Or, you may want to use a Reactor feature, such as signals or signalable handles, with a Proactor-based application. These situations occur most often on Windows or in a multiplatform application in which Windows is one of its platforms. Sometimes, your application's I/O needs work better with the Proactor in some situations and better with the Reactor in others and you want to simplify development and maintenance as much as possible. Three different scenarios can usually be used to accommodate mixing of the two frameworks.
8.7.1 Compile Time
It's possible to derive your application's service handler class(es) from either ACE_Svc_Handler or ACE_Service_Handler, switchable at compile time, based on whether you're building for the Reactor framework or the Proactor framework. Rather than perform any real data processing in the callbacks, arrange your class to follow these guidelines.
• Standardize on handling data in ACE_Message_Block objects. Using the Proactor framework, you already need to do this, so this guideline has the most effect when working in the Reactor world. You simply need to get used to working with ACE_Message_Block instead of native arrays.
• Centralize the data-processing functionality in a private, or protected, method that's not one of the callbacks. For example, move the processing code to a method named do_the_work() or process_input(). The work method should accept an ACE_Message_Block with the data to work on. If the work requires that data also be sent in the other direction, put it in another ACE_Message_Block and return it.
• (Proactor): In the completion handler callback—for example, handle_read_stream(), after checking transfer status, pass the message block with the data to the work method.
• (Reactor): When receiving data in handle_input(), read it into an ACE_Message_Block and then call the work method, just as you do in the Proactor code.
8.7.2 Mix Models
Recall that it's possible to register a signalable handle with the ACE_WFMO_Reactor on Windows. Thus, if you want to use overlapped Windows I/O, you could use an event handle with the overlapped I/O and register the event handle with the reactor. This is a way to add a small amount of nonsockets I/O work—if, for example, you need to work with a named pipe—to the reactor on Windows but don't have the inclination or the interest in mixing Reactor and Proactor event loops.
8.7.3 Integrating Proactor and Reactor Events Loops
Both the Proactor and Reactor models require event-handling loops, and it is often useful to be able to use both models in the same program. One possible method for doing this is to run the event loops in separate threads. However, that introduces a need for multithreaded synchronization techniques. If the program is single threaded, however, it would be much better to integrate the event handling for both models into one mechanism. ACE provides this integration mechanism for Windows programs by providing a linkage from the Windows implementation of the ACE_Proactor class to the ACE_WFMO_Reactor class, which is the default reactor type on Windows.
The ACE mechanism is based on the ACE_WFMO_Reactor class's ability to include a HANDLE in the event sources it waits for (see Section 7.7.2). The ACE_WIN32_Proactor class uses an I/O completion port internally to manage its event dispatching. However, because an I/O completion port handle is not waitable, it can't be registered with the ACE_WFMO_Reactor. Therefore, ACE_WIN32_Proactor includes some optional functionality to associate a Windows event handle with each asynchronous I/O operation. The event handle is waitable and is signaled when each I/O operation completes. The event handle is registered with ACE_WFMO_Reactor, and ACE_WIN32_Proactor is the event handler class. Thus, when the reactor's event loop reacts to the event signaling the I/O completion, the handle_signal() callback in ACE_WIN32_Proactor simply runs the completion events on the I/O completion port, completing the integration of the two mechanisms.
To make use of this link, follow these steps.
- Instantiate an
ACE_WIN32_Proactorobject with second argument 1. This directs theACE_WIN32_Proactorobject to associate an event handle with I/O operations and make the handle available via theget_handle()method. - Instantiate an
ACE_Proactorobject with theACE_WIN32_Proactoras its implementation. - Register the
ACE_WIN32_Proactor's handle with the desiredACE_Reactorobject.
The following code shows the steps for creating an ACE_Proactor as described, making it the singleton, and registering it with the singleton reactor:
ACE_WIN32_Proactor proactor_impl (0, 1);
ACE_Proactor proactor (&proactor_impl);
ACE_Proactor::instance (&proactor);
ACE_Reactor::instance ()->register_handler (&proactor_impl,
proactor_impl.get_handle ());
After the program has completed its work and before the preceding proactors are destroyed, unregister the event handle to prevent any callbacks to an invalid object:
ACE_Reactor::instance ()->remove_handler
(impl->get_handle (), ACE_Event_Handler::DONT_CALL);
8.8 Summary
The ACE Proactor framework provides a portable way to implement asynchronous I/O capabilities into your application. Asynchronous I/O can often be an efficient way to handle more I/O endpoints than you can efficiently use with the Reactor framework. Asynchronous I/O can also be a good choice for situations in which you can benefit from highly parallelized I/O operations but don't want to use multiple threads.
This chapter described the Proactor framework's capabilities and showed how to implement the example server from earlier chapters, using the Proactor framework. Because asynchronous I/O is not universally available and not completely interchangeable with the Reactor framework, we also discussed ways to work with both frameworks in the same application.