
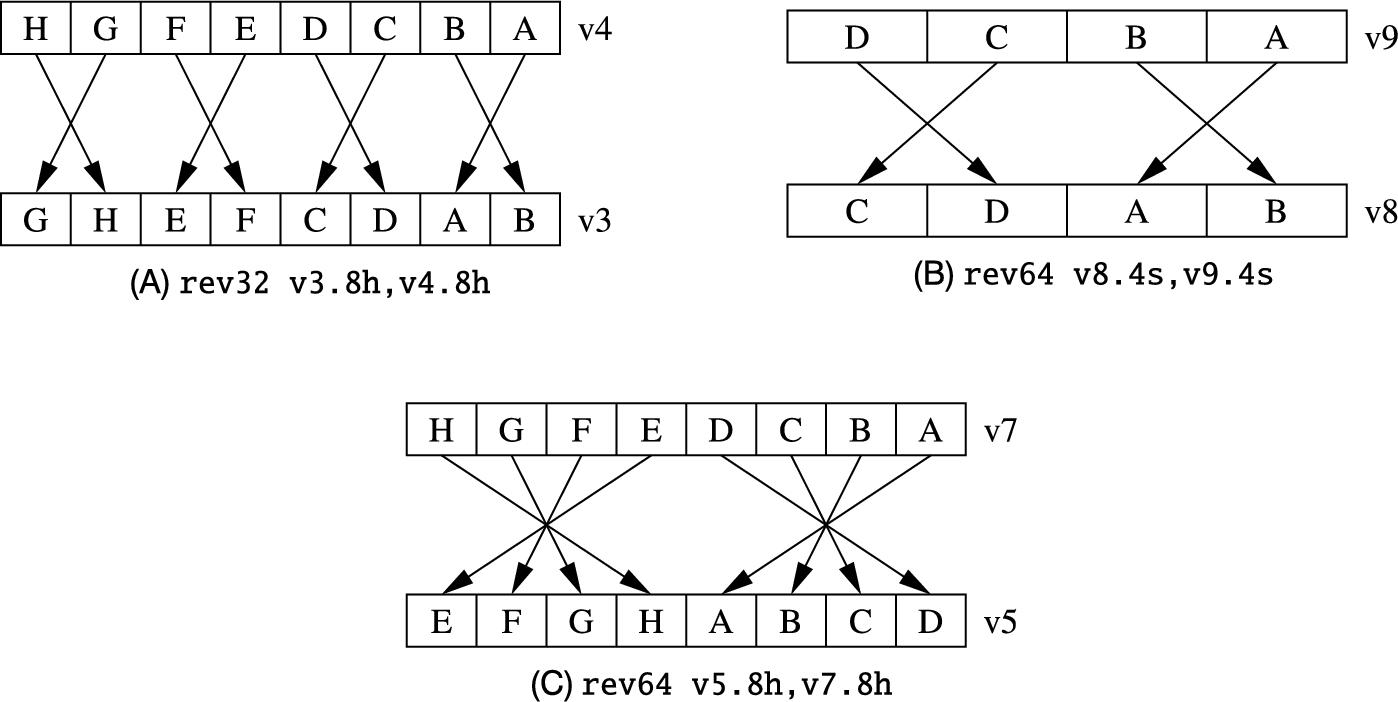
Advanced SIMD instructions
Keywords
SIMD; Advanced SIMD load and store instructions; Advanced SIMD data movement instructions; Advanced SIMD bitwise logical operations; Advanced SIMD basic arithmetic instructions; Advanced SIMD multiplication; Advanced SIMD division; Advanced SIMD shift instructions; Advanced SIMD comparison operations
In addition to the FP/NEON instructions described in the previous chapter, AArch64 also supports Advanced SIMD instructions, which allow the programmer to treat the FP/NEON registers as vectors (arrays) of data. Advanced SIMD uses the same set of registers described in Chapter 9, but adds new views to provide the ability to access the registers in more ways. Advanced SIMD adds about 125 instructions and pseudo-instructions to support not only floating point, but also integer and fixed point.
A single Advanced SIMD instruction can operate on up to 128 bits, which may represent multiple integer, fixed point, or floating point numbers. For example, if two of the 128-bit registers each contain eight 16-bit integers, then a single Advanced SIMD instruction can add all eight integers from one register to the corresponding integers in the other register, resulting in eight simultaneous additions. For certain applications, this vector architecture can result in extremely fast and efficient implementations. Advanced SIMD is particularly useful at handling streaming video and audio, but also can give very good performance on floating point intensive tasks.
The 32 FP/NEON/Advanced SIMD registers, originally introduced in Chapter 9, can be accessed using various views. Some SIMD instructions use the byte, half-word, word, and double-word views from Chapter 9, but most of them use the Advanced SIMD views. Fig. 10.1 shows the different ways of viewing an Advanced SIMD register. Each register can be viewed as containing a vector of 2, 4, 8, or 16 elements, all of the same size and type. Individual elements of each vector can also be accessed by some instructions. The scalar register names and views introduced in Chapter 9 are also used by some instructions. A scalar can be 8 bits, 16 bits, 32 bits, or 64 bits. The instruction syntax is extended to refer to elements of a vector register by using an index, ![]() . For example
. For example ![]() is element
is element ![]() in register
in register ![]() , where
, where ![]() is treated as a vector of four single-word (32-bit) elements.
is treated as a vector of four single-word (32-bit) elements.

10.1 Instruction syntax
The syntax of Advanced SIMD instructions can be described using an extension of the notation used throughout this book. Each instruction operates on certain types of register(s), and there are many registers. Advanced SIMD instruction syntax may use any of the following register definitions:
Xy Refers to a 64-bit AArch64 integer register.
Wy Refers to 32-bit AArch64 integer register.
By Refers to the lower 8-bits, or byte, of an Advanced SIMD register.
Hy Refers to the lower 16-bits, or half-word, of an Advanced SIMD register.
Sy Refers to the lower 32-bits, or single-word, of an Advanced SIMD register.
Dy Refers to the lower 64-bits, or double-word, of an Advanced SIMD register.
Fy Is used to indicate either a single-word or double-word FP/NEON register. F must be either ![]() for a single word register,
for a single word register, ![]() for a double word register.
for a double word register.
Vy A 128-bit Advanced SIMD register. ![]() can be any valid register number.
can be any valid register number.
Vy.T A 128-bit Advanced SIMD register, treated as a vector of elements of type T, where T may be one of:
b A vector of 16 bytes.
h A vector of 8 half-words.
s A vector of 4 words.
d A vector of 2 double-words.
Some instructions can only allow a subset of these types.
Vy.nT A 128-bit Advanced SIMD register, or the lower 64 bits of an Advanced SIMD register, treated as a vector of elements of type T, where T may be one of:
16b A 128-bit Advanced SIMD register, treated as a vector of sixteen bytes.
8b The lower 64 bits of an Advanced SIMD register, treated as a vector of eight bytes.
8h A 128-bit Advanced SIMD register, treated as a vector of eight half-words.
4h The lower 64 bits of an Advanced SIMD register, treated as a vector of four half-words.
4s A 128-bit Advanced SIMD register, treated as a vector of four words.
2s The lower 64 bits of an Advanced SIMD register, treated as a vector of two words.
2d A 128-bit Advanced SIMD register, treated as a vector of two double-words.
Some instructions can only allow a subset of these types.
Vy.nT[x] Element x of an Advanced SIMD register, treated as a vector of type ![]() .
.
Each instruction has its own set of restrictions on legal values for the registers and types used. For example, one possible form of the ![]() instruction is:
instruction is:
![]()
which indicates that a 32-bit AArch32 register is used as the source operand, and any element of any Advanced SIMD register may be used as the destination. However, the instruction further requires that ![]() must be either
must be either ![]() or
or ![]() , in order to match the size of
, in order to match the size of ![]() .
.
Instructions may have several forms. In those cases, the following syntax is used to specify possible forms:
{opt} Braces around a string indicate that the string is optional. For example, several operations have an optional r which indicates that the result is rounded instead of truncated.
(s|u) Parentheses indicate a choice between two or more possible characters or strings, separated by the pipe “|” character. For example, (s|u)shr would describe two forms for the shr instruction: sshr and ushr.
<Tn> A string inside the < and > symbols indicates a choice or special syntax that is too complex to be easily described using the parenthesis and pipe (a|b) syntax, and is described in the following text. It is also used to define a syntactical token when simply using a character would lead to confusion.
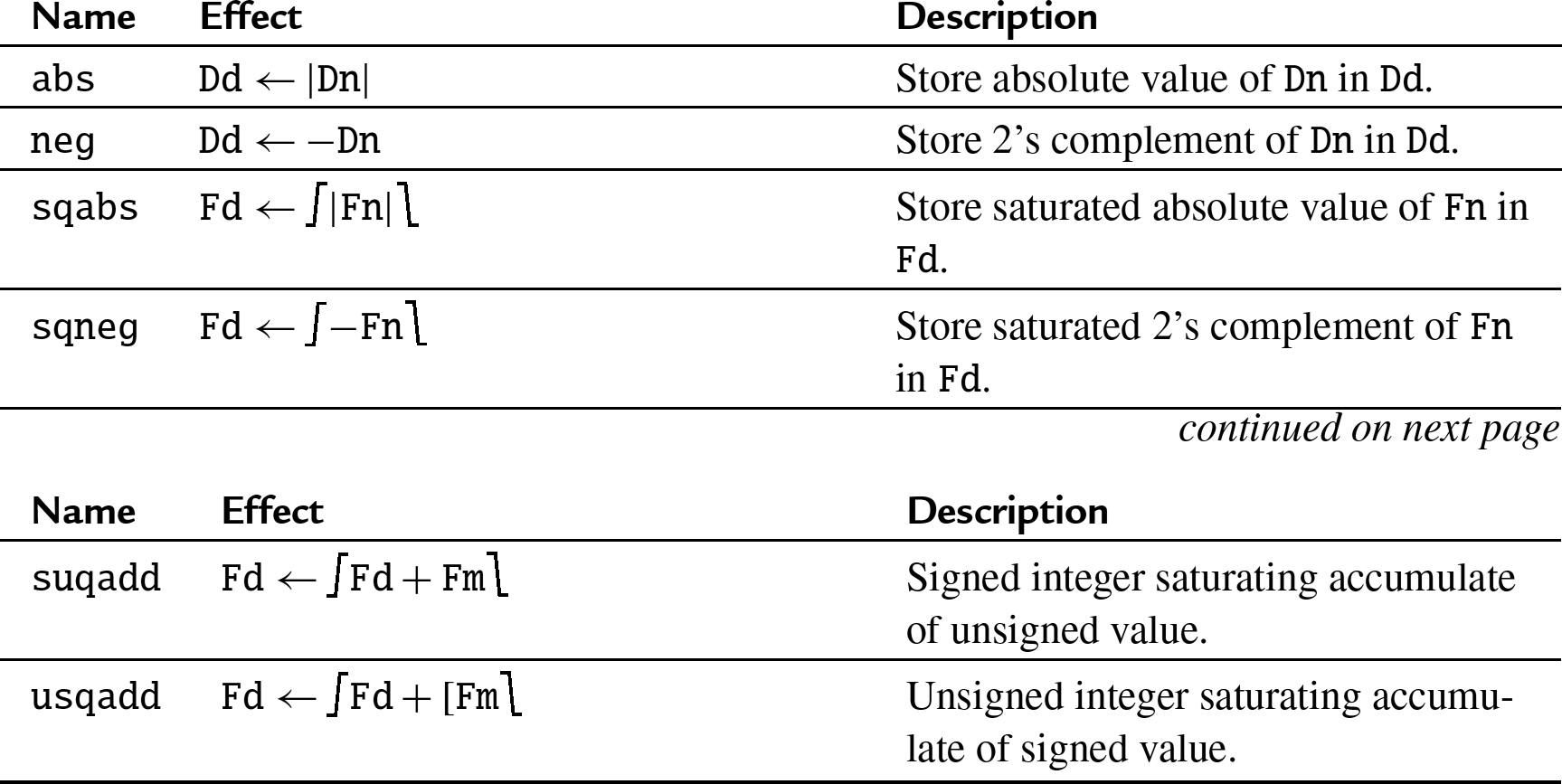
The following function definitions are used in describing the effects of many of the instructions:
![]() The floor function maps a real number, x, to the next smallest integer.
The floor function maps a real number, x, to the next smallest integer.
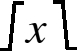 The saturate function limits the value of x to the highest or lowest value that can be stored in the destination register. Saturation is a method used to prevent overflow.
The saturate function limits the value of x to the highest or lowest value that can be stored in the destination register. Saturation is a method used to prevent overflow.
![]() The round function maps a real number, x, to the nearest integer.
The round function maps a real number, x, to the nearest integer.
![]() The narrow function reduces a 2n bit number to an n bit number, by taking the n least significant bits.
The narrow function reduces a 2n bit number to an n bit number, by taking the n least significant bits.
![]() The extend function converts an n bit number to a 2n bit number, performing zero extension if the number is unsigned, or sign extension if the number is signed.
The extend function converts an n bit number to a 2n bit number, performing zero extension if the number is unsigned, or sign extension if the number is signed.
10.2 Load and store instructions
These instructions can be used to perform interleaving of data when structured data is loaded or stored. The data should be properly aligned for best performance. These instructions are very useful for common multimedia data types.
For example, image data is typically stored in arrays of pixels, where each pixel is a small data structure such as the ![]() struct shown in Listing 5.38. Since each pixel is three bytes, and a
struct shown in Listing 5.38. Since each pixel is three bytes, and a ![]() register is 8 bytes, loading a single pixel into one register would be inefficient. It would be much better to load multiple pixels at once, but an even number of pixels will not fit in a register. It will take three doubleword or quadword registers to hold an even number of pixels without wasting space, as shown in Fig. 10.2. This is the way data would be loaded using an Advanced SIMD
register is 8 bytes, loading a single pixel into one register would be inefficient. It would be much better to load multiple pixels at once, but an even number of pixels will not fit in a register. It will take three doubleword or quadword registers to hold an even number of pixels without wasting space, as shown in Fig. 10.2. This is the way data would be loaded using an Advanced SIMD ![]() instruction. Many image processing operations work best if each color “channel” is processed separately. The SIMD load and store instructions can be used to split the image data into color channels, where each channel is stored in a different register, as shown in Fig. 10.3.
instruction. Many image processing operations work best if each color “channel” is processed separately. The SIMD load and store instructions can be used to split the image data into color channels, where each channel is stored in a different register, as shown in Fig. 10.3.

Other examples of interleaved data include stereo audio, which is two interleaved channels, and surround sound, which may have up to nine interleaved channels. In all of these cases, most processing operations are simplified when the data is separated into non-interleaved channels.
10.2.1 Load or store single structure using one lane
These instructions are used to load and store structured data across multiple registers:
ld<n> Load Structured Data, and
st<n> Store Structured Data.
They can be used for interleaving or deinterleaving the data as it is loaded or stored, as shown in Fig. 10.3.
10.2.1.1 Syntax

- •
 must be either
must be either  or
or  .
. - •
 must be one of
must be one of 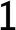 ,
, 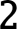 ,
,  , or
, or  .
. - •
 specifies the list of registers. There are four list formats:
specifies the list of registers. There are four list formats: - 1. {Vt.T}
- 2. {Vt.T, V(t+1).T} or {Vt.T-V(t+1).T}
- 3. {Vt.T, V(t+1).T, V(t+2).T} or {Vt.T-V(t+2).T}
- 4. {Vt.T, V(t+1).T, V(t+2).T, V(t+3).T} or {Vt.T-V(t+3).T}
- •
 must be b, h, s, or d.
must be b, h, s, or d. - • The immediate
 specifies which element of each register is to be used, and must be appropriate for the data size specified by . The same element will be used for all registers.
specifies which element of each register is to be used, and must be appropriate for the data size specified by . The same element will be used for all registers. - •
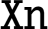 is the AARCH64 register containing the base address.
is the AARCH64 register containing the base address. - •
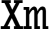 is the AARCH64 register containing an offset.
is the AARCH64 register containing an offset. - • If a register or immediate offset is given, then the base register, , will be post-incremented.
- • The post-increment immediate offset, if present, must be 8, 16, 24, 32, 48, or 64, depending on the number of elements transferred and the size specified by .
10.2.1.2 Operations

10.2.1.3 Examples

10.2.2 Load or store multiple structures
These instructions are used to load and store multiple data structures across multiple registers with interleaving or deinterleaving:
ld<n> Load Multiple Structured Data, and
st<n> Store Multiple Structured Data.
10.2.2.1 Syntax

![]() must be either
must be either ![]() or
or ![]() .
.![]() must be one of
must be one of ![]() ,
, ![]() ,
, ![]() , or
, or ![]() .
. ![]() specifies the list of registers. There are four list formats:
specifies the list of registers. There are four list formats:
The registers must be consecutive. Register 0 is consecutive to register 31.![]() must be 16b, 8b, 8h, 4h, 4s, 2s, or 2d. If
must be 16b, 8b, 8h, 4h, 4s, 2s, or 2d. If ![]() is 1, then
is 1, then ![]() can be 1d.
can be 1d.![]() is the AARCH64 register containing the base address.
is the AARCH64 register containing the base address.![]() is the AARCH64 register containing an offset.
is the AARCH64 register containing an offset.![]() , will be post-incremented.
, will be post-incremented.![]() .
.10.2.2.2 Operations

10.2.2.3 Examples

10.2.3 Load copies of a structure to all lanes
This instruction is used to load multiple copies of structured data across multiple registers:
ld<n>r Load Copies of Structured Data.
The data is copied to all lanes. This instruction is useful for initializing vectors for use in later instructions.
10.2.3.1 Syntax

- • must be one of , , , or .
- • specifies the list of registers. There are four list formats:
- 1. {Vt.T}
- 2. {Vt.T, V(t+1).T} or {Vt.T-V(t+1).T}
- 3. {Vt.T, V(t+1).T, V(t+2).T} or {Vt.T-V(t+2).T}
- 4. {Vt.T, V(t+1).T, V(t+2).T, V(t+3).T} or {Vt.T-V(t+3).T}
- • must be 16b, 8b, 8h, 4h, 4s, 2s, or 2d. If is 1, then can be 1d.
- • is the AARCH64 register containing the base address.
- • is the AARCH64 register containing an offset.
- • If a register or immediate offset is given, then the base register, , will be post-incremented.
- • The post-increment immediate offset, if present, must be 1, 2, 3, 4, 6, 8, 12, 16, 24, or 32, depending on the number of elements transferred and the size specified by .
10.2.3.2 Operations

10.2.3.3 Examples

10.3 Data movement instructions
With the additional register views added by Advanced SIMD, there are many more ways to specify data movement. Instructions are provided to move data using the Advanced SIMD views, the FP/NEON views, and the AArch64 integer register views. This results in a large number of possible move instructions.
10.3.1 Duplicate scalar
The duplicate instruction copies a scalar into every element of the destination vector. The scalar can be in an Advanced SIMD register or an AARCH64 integer register. The instruction is:
dup Duplicate Scalar.
10.3.1.1 Syntax

![]() .
.10.3.1.2 Operations

10.3.1.3 Examples

10.3.2 Move vector element
These instructions copy one element into a vector:
mov Copy element into vector,
umov Copy unsigned integer element from vector to AARCH64 register, and
smov Copy signed integer element from vector to AARCH64 register.
10.3.2.1 Syntax

10.3.2.2 Operations

10.3.2.3 Examples

10.3.3 Move immediate
These instructions are used to load immediate data into the vector registers:
movi Vector Move Immediate,
mvni Vector Move NOT Immediate, and
fmov Vector Floating Point Move Immediate.
10.3.3.1 Syntax

sop T shift Description lsl 4h or 8h 0 or 8 Replicate LSL(uimm8,shift) into each 16-bit element. lsl 2s or 4s 0, 8, 16, or 24 Replicate LSL(uimm8,shift) into each 32-bit element. msl 2s or 4s 8 or 16 Replicate MSL(uimm8,shift) into each 32-bit element. 
![]() , if sop is not present, then T may be 8b or 16b, in addition to the values shown in the previous table.
, if sop is not present, then T may be 8b or 16b, in addition to the values shown in the previous table.![]() , where n and r are integers such that
, where n and r are integers such that ![]() and
and ![]() . It is encoded as a normalized binary floating point number with sign, 4 bits of fraction, and a 3-bit exponent.
. It is encoded as a normalized binary floating point number with sign, 4 bits of fraction, and a 3-bit exponent.10.3.3.2 Operations

10.3.3.3 Examples

10.3.4 Transpose matrix
Advanced SIMD provides two versions of the transpose instruction that can be used together for transposing ![]() matrices. Fig. 10.4 shows two examples of this instruction. The instruction is:
matrices. Fig. 10.4 shows two examples of this instruction. The instruction is:
trn Transpose Matrix.

 instruction.
instruction.10.3.4.1 Syntax

- • T must be 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- • Larger matrices can be transposed using a divide-and-conquer approach.
10.3.4.2 Operation

10.3.4.3 Examples

Fig. 10.5 shows how the ![]() instruction can be used to transpose a
instruction can be used to transpose a ![]() matrix.
matrix.

10.3.5 Vector permute
These instructions are used to interleave or deinterleave the data from two vectors, or to extract bits from a vector:
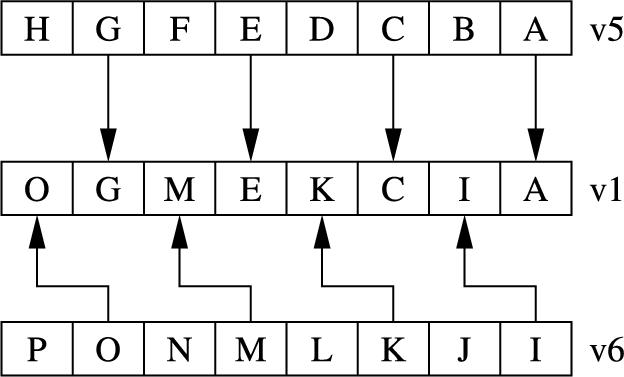
zip Zip Vectors,
uzp Unzip Vectors, and
ext Byte Extract.
Fig. 10.6 gives an example of the ![]() instruction. The
instruction. The ![]() instruction performs the inverse operation.
instruction performs the inverse operation.
 . The
. The  instruction does the same thing, but uses the odd elements of the source registers, rather than the even elements.
instruction does the same thing, but uses the odd elements of the source registers, rather than the even elements.10.3.5.1 Syntax

- • T is 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- • For
 and
and  :
:- – If 1 is present, use lower half of source registers.
- – If 2 is present, use upper half of source registers.
- • Ta is either 8b (use only 64 bits of each register) or 16b (use all 128 bits of each register).
- • index is an immediate value in the range 0 to
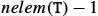 .
.
10.3.5.2 Operations

10.3.5.3 Examples

10.3.6 Table lookup
The table lookup instructions use indices held in one vector to lookup values from a table held in one or more other vectors. The resulting values are stored in the destination vector. The table lookup instructions are:
tbl Table Lookup, and
tbx Table Lookup with Extend.
10.3.6.1 Syntax

![]() is one of
is one of ![]() or
or ![]() .
.![]() specifies the list of registers. There are five list formats:
specifies the list of registers. There are five list formats:![]() is the register holding the indices.
is the register holding the indices.10.3.6.2 Operations

10.3.6.3 Examples

10.4 Data conversion
When high precision is not required, The IEEE half-precision format can be used to store floating point numbers in memory. This can reduce memory requirements by up to 50%. This can also result in a significant performance improvement, since only half as much data needs to be moved between the CPU and main memory. However, on most processors half-precision data must be converted to single or double precision before it is used in calculations. Advanced SIMD provides instructions to support conversion to and from IEEE half precision. There are also functions to perform integer or fixed-point to floating-point conversions, and convert between IEEE single and double precision.
10.4.1 Convert between integer or fixed point and floating point
These instructions can be used to perform data conversion between floating point and fixed point (or integer) on each element in a vector:
fcvt Vector convert floating point to integer or fixed point, and
cvtf Vector convert integer or fixed point to floating point.
The elements in the result vector must be the same size as the elements in the source vector. An out of range integer or fixed-point result will be saturated to the destination size.
Fixed point (or integer) arithmetic operations are up to twice as fast as floating point operations. In some cases it is much more efficient to make this conversion, perform the calculations, then convert the results back to floating point.
10.4.1.1 Syntax

- •
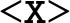 is a single character which specifies the rounding mode:
is a single character which specifies the rounding mode: N: round to nearest with ties to even,
A: round to nearest with ties away from zero,
P: round towards +∞,
M: round towards −∞, or
Z: round towards zero.
- • T may be either 2s, 4s, or 2d.
- •
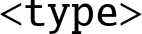 must be either
must be either 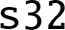 or
or  .
. - •
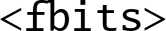 specifies the number of fraction bits for a fixed point number, and must be between 1 and the number of bits specified by T. If it is omitted, then it is assumed to be zero.
specifies the number of fraction bits for a fixed point number, and must be between 1 and the number of bits specified by T. If it is omitted, then it is assumed to be zero.
10.4.1.2 Operations
| Name | Effect | Description |
|---|---|---|
| fcvt<x>s | Vd[]←fixed(Vm[],fbits) | Convert single precision to 32-bit signed fixed point or integer. |
| fcvt<x>u | Vd[]←ufixed(Vm[],fbits) | Convert single precision to 32-bit unsigned fixed point or integer. |
| scvtf | Vd[]←float(Vm[]) | Convert signed 32-bit fixed point or integer to single precision |
| ucvtf | Vd[]←single(Vm[]) | Convert unsigned 32-bit fixed point or integer to single precision |
10.4.1.3 Examples

10.4.2 Convert between half, single, and double precision
The following instructions can be used to convert between floating point formats:
fcvtl Vector convert from half to single precision,
fcvtn Vector convert from single to half precision, and
fcvtxn Vector convert from double to single precision.
These instructions operate on vectors. There are additional conversion instructions available, but they only operate on scalar values.
10.4.2.1 Syntax

- • If 2 is present, then the upper 64 bits of the register containing the smaller elements will be used. Otherwise, the lower 64 bits are used.
- • Td /Ts may be 4s /4h or 2d /2s.
- • Td2/Ts2 may be 4s /8h or 2d /4s.
- • Td3/Ts3 may be 4h /4s or 2s /2d.
- • Td4/Ts4 may be 8h /4s or 4s /2d.
10.4.2.2 Operations
| Name | Effect | Description |
|---|---|---|
| fcvtl | Vd[]←single(Vn[]) | Convert half precision to single precision. |
| fcvtn | Vd[]←half(Vn[]) | Convert single precision to half precision. |
| fcvtxn | Vd[]←single(Vd[]) | Convert double precision to single precision. |
10.4.2.3 Examples

10.4.3 Round floating point to integer
The following instruction can be used to round a vector of floating point values to integers:
frint Round Floating Point to Integer.
N: round to nearest with ties to even, A: round to nearest with ties away from zero, P: round towards +∞, M: round towards −∞, Z: round towards zero, I: round using FPCR rounding mode, and X: round using FPCR rounding mode with exactness test.10.4.3.1 Syntax

10.4.3.2 Operations
Name Effect Description frintx Vd[]←roundx(Vn[],x) Round to integer using specified rounding mode. 10.4.3.3 Examples

10.5 Bitwise logical operations
Advanced SIMD provides instructions to perform bitwise logical operations on the vector register set. These operations add a great deal of power to the AARCH64 processor.
10.5.1 Vector logical operations
The bitwise logical operations are:
and Vector bitwise AND,
orr Vector bitwise OR,
orn Vector bitwise NOR,
eor Vector bitwise Exclusive-OR,
bic Vector bit clear,
bif Vector insert if false,
bit Vector insert if true, and
bsl Vector bitwise select.
10.5.1.1 Syntax

![]() must be one of
must be one of ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , or
, or ![]() .
.10.5.1.2 Operations

10.5.1.3 Examples

10.5.2 Bitwise logical operations with immediate data
Advanced SIMD provides vector versions of the logical OR and bit clear instructions:
orr Vector bitwise OR immediate, and
bic Vector Bit clear immediate.
10.5.2.1 Syntax

![]() must be either
must be either ![]() , or
, or ![]() .
.![]() is an 8-bit unsigned immediate value, which is shifted left by shift bits to create the desired pattern for the
is an 8-bit unsigned immediate value, which is shifted left by shift bits to create the desired pattern for the ![]() , or
, or ![]() operation on each vector element.
operation on each vector element.10.5.2.2 Operations
Name Effect Description vorr Vd[]←Vd[]∨(uimm8 ≪ shift) Logical OR vbic Vd[]←Vd[]∧(uimm8 ≪ shift) Bit Clear 10.5.2.3 Examples

10.6 Basic arithmetic instructions
Advanced SIMD provides many instructions for addition, subtraction, and multiplication, but does not provide an integer divide instruction. When division cannot be avoided, it is performed by multiplying the reciprocal, as was described in Chapter 7 and Chapter 8. When dividing by a constant, the reciprocal can be calculated in advance. For dividing by variables, Advanced SIMD provides instructions for quickly calculating the reciprocals of the elements in a vector. In most cases, this is faster than using a divide instruction. For floating point numbers, the FP/NEON divide instructions can be used.
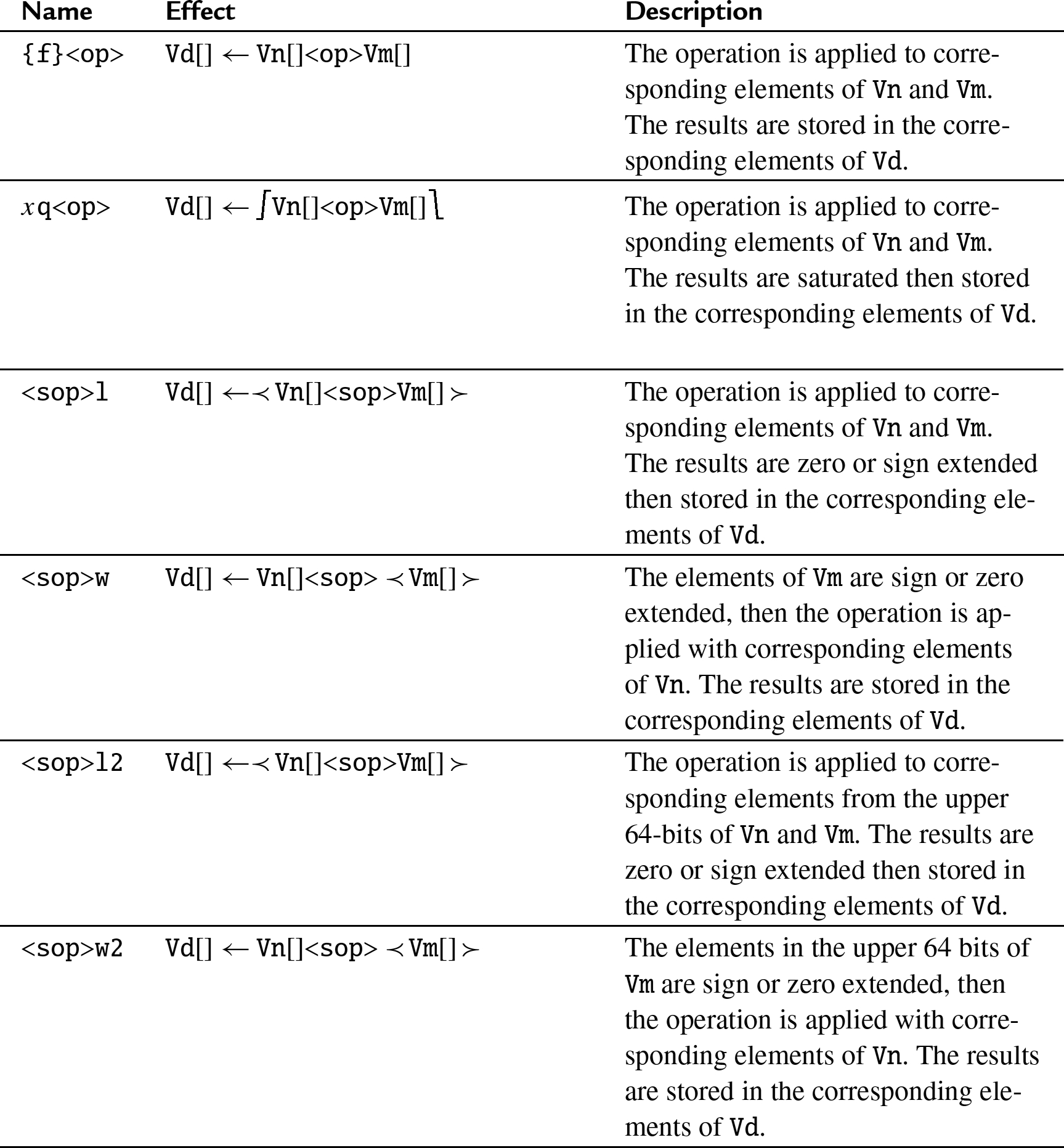
10.6.1 Vector add and subtract
The ![]() and
and ![]() instructions add corresponding elements in two vectors and store the results in the corresponding elements of the destination register. The
instructions add corresponding elements in two vectors and store the results in the corresponding elements of the destination register. The ![]() and
and ![]() instructions subtract elements in one vector from corresponding elements in another vector and store the results in the corresponding elements of the destination register. Other versions of the add and subtract instructions allow mismatched operand and destination sizes, and the saturating versions prevent overflow by limiting the range of the results. The following instructions perform vector addition and subtraction:
instructions subtract elements in one vector from corresponding elements in another vector and store the results in the corresponding elements of the destination register. Other versions of the add and subtract instructions allow mismatched operand and destination sizes, and the saturating versions prevent overflow by limiting the range of the results. The following instructions perform vector addition and subtraction:
add Vector integer add,
fadd Vector floating point add,
qadd Vector saturating add,
addl Vector add long,
addw Vector add wide,
sub Vector integer subtract,
fsub Vector floating point subtract,
qsub Vector saturating subtract,
subl Vector subtract long, and
subw Vector subtract wide.
10.6.1.1 Syntax

- • <op> can be add or sub.
- • If double word registers are specified (Dd, Dn, Dm ) then the operation is a simple add or subtract of scalar 64-bit integer values, and not a vector operation.
- • The valid choices for T are given in the following table:
| Opcode | Valid Values for T |
|---|---|
| <op> | 8b, 16b, 4h, 8h, 2s, 4s, or 2d |
| f<op> | 2s, 4s, 2d |
| (s|u)q<op> | 8b, 16b, 4h, 8h, 2s, 4s, 2d |
- • <sop> can be uadd, sadd, usub, or ssub.
- • If the modifier 2 is present, then the operation is performed using the upper 64 bits of the registers holding the narrower elements.
- • The valid choices for Td /Ts are given in the following table:
| Opcode | Valid Values for Td /Ts |
|---|---|
| <sop>l | 8h /8b, 4s /4h, 2d /2s |
| <sop>l2 | 8h /16b, 4s /8h, 2d /4s |
| <sop>w | 8h /8b, 4s /4h, 2d /2s |
| <sop>w2 | 8h /16b, 4s /8h, 2d /4s |
10.6.1.2 Operations
10.6.1.3 Examples

10.6.2 Vector add and subtract with narrowing
These instructions add or subtract the corresponding elements of two vectors and narrow the resulting elements by taking the upper (most significant) half:
addhn Vector add and narrow,
raddhn Vector add, round, and narrow,
subhn Vector subtract and narrow, and
rsubhn Vector subtract, round, and narrow.
The results are stored in the corresponding elements of the destination register. Results can be optionally rounded instead of truncated.
10.6.2.1 Syntax

- • is either
 or
or 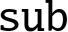 .
. - • If
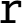 is present, then the result is rounded instead of truncated.
is present, then the result is rounded instead of truncated. - • If is present, then the upper 64 bits of the destination vector are used.
- • The valid choices for Td /Ts are given in the following table:
| Opcode | Valid Values for Td /Ts |
|---|---|
| r<op>hn | 8b /8h, 4h /4s, 2s /2d |
| r<op>hn2 | 16b /8h, 8h /4s, 4s /2d |
10.6.2.2 Operations
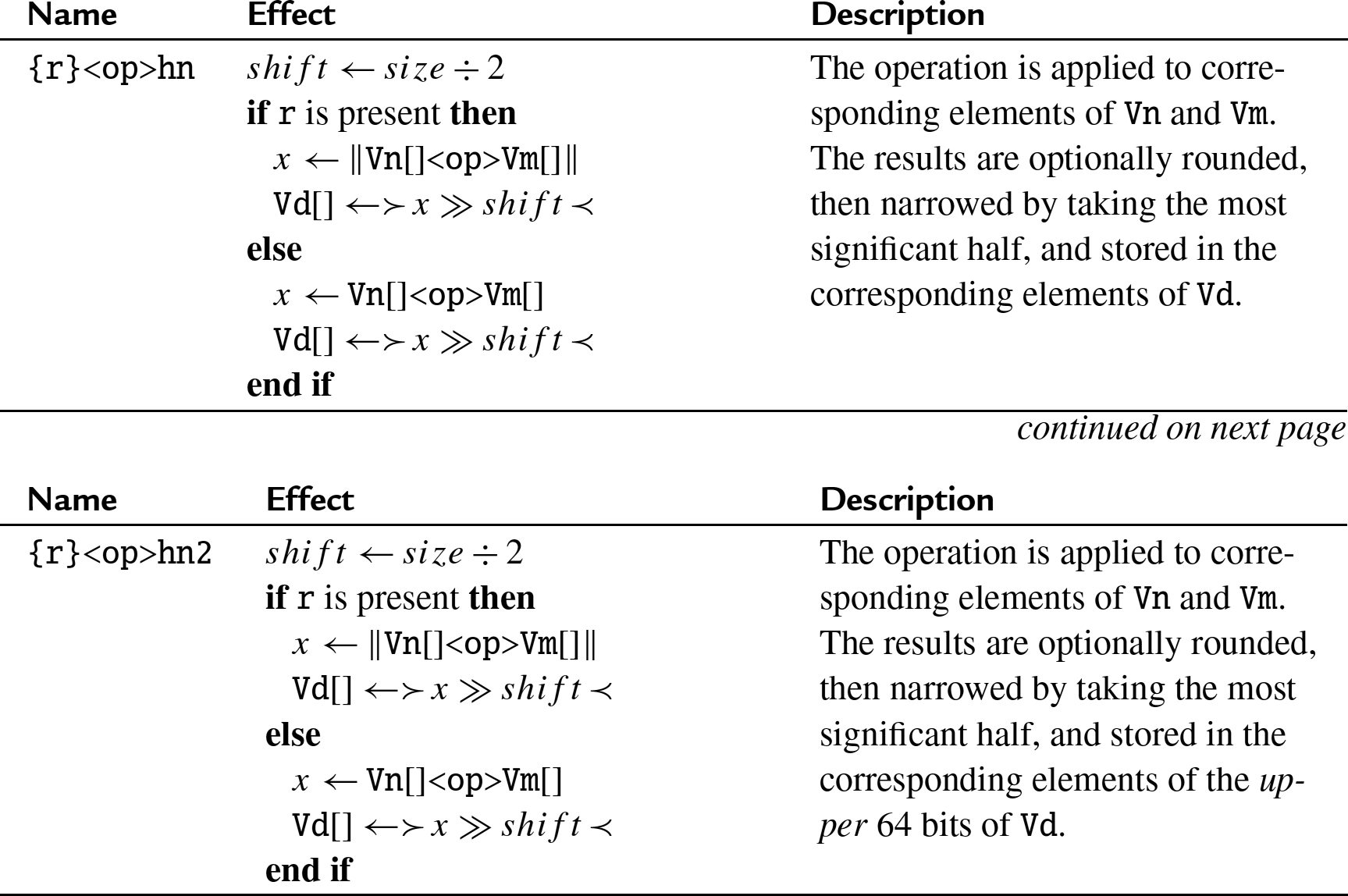
10.6.2.3 Examples

10.6.3 Add or subtract and divide by two
These instructions add or subtract corresponding integer elements from two vectors, then shift the result right by one bit:
hadd Vector halving add,
rhadd Vector halving add and round, and
hsub Vector halving subtract.
The results are stored in corresponding elements of the destination vector.
10.6.3.1 Syntax

- • If
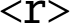 is specified, then the result is rounded instead of truncated.
is specified, then the result is rounded instead of truncated. - • T must be 8b, 16b, 4h, 8h, 2s, or 4s.
10.6.3.2 Operations

10.6.3.3 Examples

10.6.4 Add elements pairwise
These instructions add vector elements pairwise:
addp Vector add pairwise,
addlp Vector add long pairwise, and
adalp Vector add and accumulate long pairwise.
The long versions can be used to prevent overflow.
10.6.4.1 Syntax

- • T must be 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- • Tf must be 2s, 4s, or 2d.
- • Td /Ts must be 4h /8b, 8h /16b, 2s /4h, 4s /8h, 1d /2s, or 2d /4s.
10.6.4.2 Operations

10.6.4.3 Examples

10.6.5 Absolute difference
These instructions subtract the elements of one vector from another and store or accumulate the absolute value of the results:
abd Vector integer absolute difference,
fabd Vector floating point absolute difference,
aba Vector integer absolute difference and accumulate,
faba Vector floating point absolute difference and accumulate,
abal Vector absolute difference and accumulate long, and
abdl Vector absolute difference long.
The long versions can be used to prevent overflow.
10.6.5.1 Syntax

- • is either
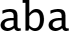 or
or 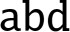 .
. - • When a scalar register is specified (F is S or D), a scalar operation is performed instead of a vector operation.
- • If is present, then the upper 64 bits of the source registers are used.
- • T must be 8b, 16b, 4h, 8h, 2s, or 4s.
- • Tf must be 2s, 4s, or 2d.
- • Td /Ts must be one of 4s /8h, 8h /16b, or 2d /4s.
- • The valid choices for Td /Ts are given in the following table:
| Opcode | Valid Types for Td /Ts |
|---|---|
| (s|u)<op>l | 8h /8b, 4s /4h, 2d /2s |
| (s|u)<op>l2 | 8h /16b, 4s /8h, 2d /4s |
10.6.5.2 Operations

10.6.5.3 Examples

10.6.6 Absolute value and negate
These operations compute the absolute value or negate each element in a vector:
abs Vector absolute value,
neg Vector negate,
fabs Vector floating point absolute value, and
fneg Vector floating point negate,
The saturating versions can be used to prevent overflow.
10.6.6.1 Syntax

- • is either
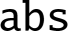 or
or 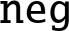 .
. - • T may be 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- • Tf may be 2s, 4s, or 2d.
10.6.6.2 Operations
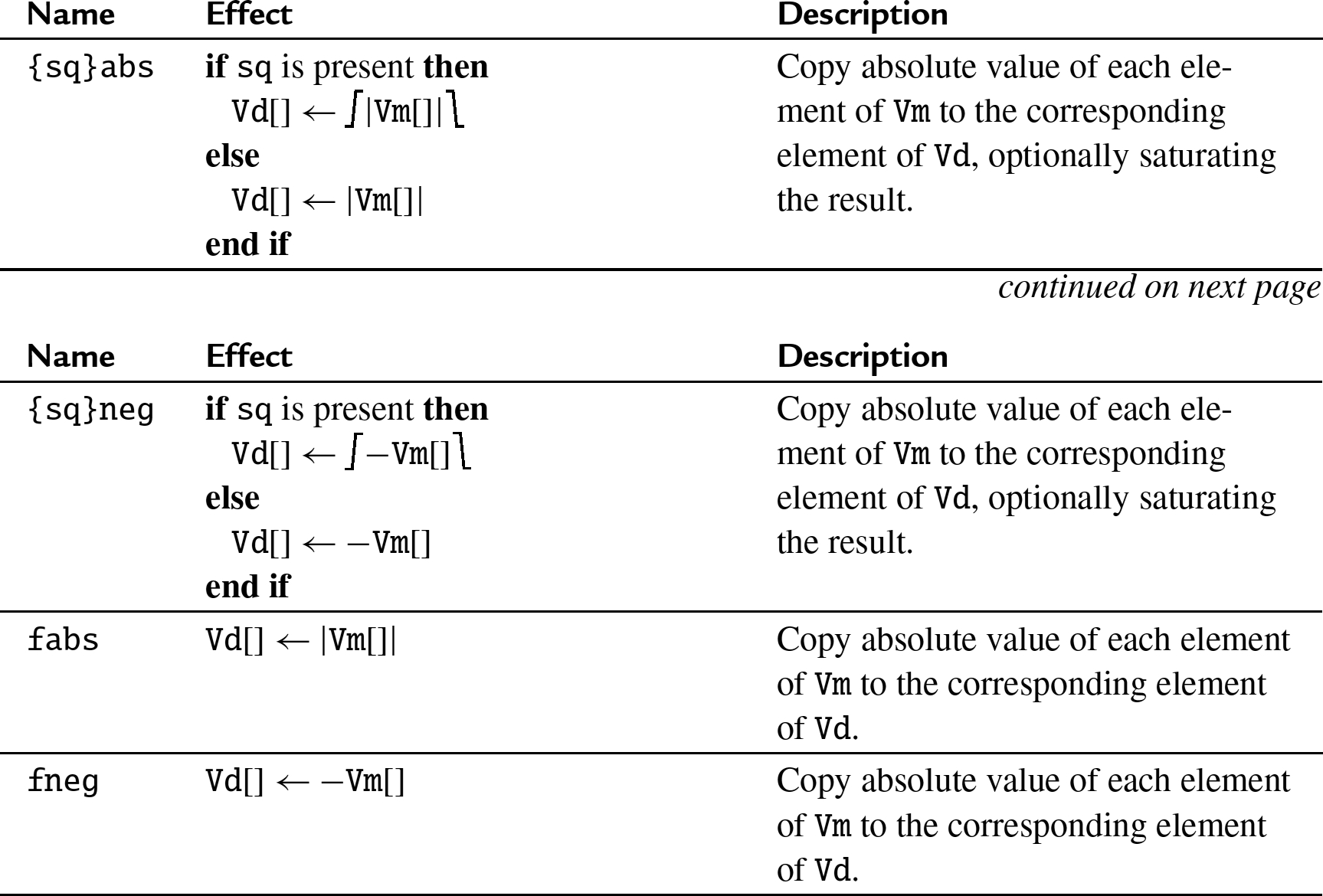
10.6.6.3 Examples

10.6.7 Get maximum or minimum elements
The following four instructions select the maximum or minimum elements and store the results in the destination vector:
max Vector integer maximum,
min Vector integer minimum,
fmax Vector floating point maximum,
fmin Vector floating point minimum,
maxp Vector integer pairwise maximum,
minp Vector integer pairwise minimum,
fmaxp Vector floating point pairwise maximum,
fminp Vector floating point pairwise minimum,
fmaxnm Vector floating point maxnum,
fminnm Vector floating point minnum,
fmaxnmp Vector floating point pairwise maxnum, and
fminnmp Vector floating point pairwise minnum.



10.6.8 Count bits
These instructions can be used to count leading sign bits or zeros, or to count the number of bits that are set, for each element in a vector:
cls Vector count leading sign bits,
clz Vector count leading zero bits, and
cnt Vector count set bits.
10.6.8.1 Syntax

10.6.8.2 Operations

10.6.8.3 Examples

10.6.9 Scalar saturating operations
The following instructions perform basic saturating operations on scalars:
qadd Scalar saturating add,
qsub Scalar saturating subtract,
qdmulh Scalar saturating multiply (high half), and
qshl Scalar saturating shift left.
10.6.9.1 Syntax

10.6.9.2 Operations

10.6.9.3 Examples

10.7 Multiplication and division
There is no integer divide instruction in Advanced SIMD. Integer division is accomplished with multiplication by the reciprocal, as was described in Chapter 7 and Chapter 8. For division by a constant, the constant reciprocal can be computed in advance, and simply loaded into a register. For division by a variable, special instructions are provided for computing the reciprocal.
10.7.1 Vector multiply and divide
These instructions are used to multiply the corresponding elements from two vectors:
mul Vector integer multiply,
mla Vector integer multiply accumulate,
mls Vector integer multiply subtract,
fmul Vector floating point multiply,
fdiv Vector floating point divide,
fmla Vector floating point multiply accumulate,
fmls Vector floating point multiply subtract,
mull Vector multiply long,
mlal Vector multiply accumulate long,
mlsl Vector multiply subtract long,
pmul Vector polynomial multiply, and
pmull Vector polynomial multiply long.
10.7.1.1 Syntax

![]() (vector).
(vector).10.7.1.2 Operations

10.7.1.3 Examples

10.7.2 Multiply vector by element
These instructions are used to multiply each element in a vector by a scalar:
mul Vector by scalar integer multiply,
mla Vector by scalar integer multiply accumulate,
mls Vector by scalar integer multiply subtract,
fmul Vector by scalar floating point multiply,
fmla Vector by scalar floating point multiply accumulate,
fmls Vector by scalar floating point multiply subtract,
mull Vector by scalar multiply long,
mlal Vector by scalar multiply accumulate long, and
mlsl Vector by scalar multiply subtract long.
10.7.2.1 Syntax

![]() (vector).
(vector).10.7.2.2 Operations

10.7.2.3 Examples

10.7.3 Saturating vector multiply and double
These instructions perform multiplication, double the results, and perform saturation:
sqdmull Saturating Multiply Double,
sqdmlal Saturating Multiply Double Accumulate, and
sqdmlsl Saturating Multiply Double Subtract.
10.7.3.1 Syntax

![]() is either
is either ![]() ,
, ![]() , or
, or ![]() .
.![]() is specified) and Tb is h, then Vm must be in the range
is specified) and Tb is h, then Vm must be in the range ![]() .
.10.7.3.2 Operations
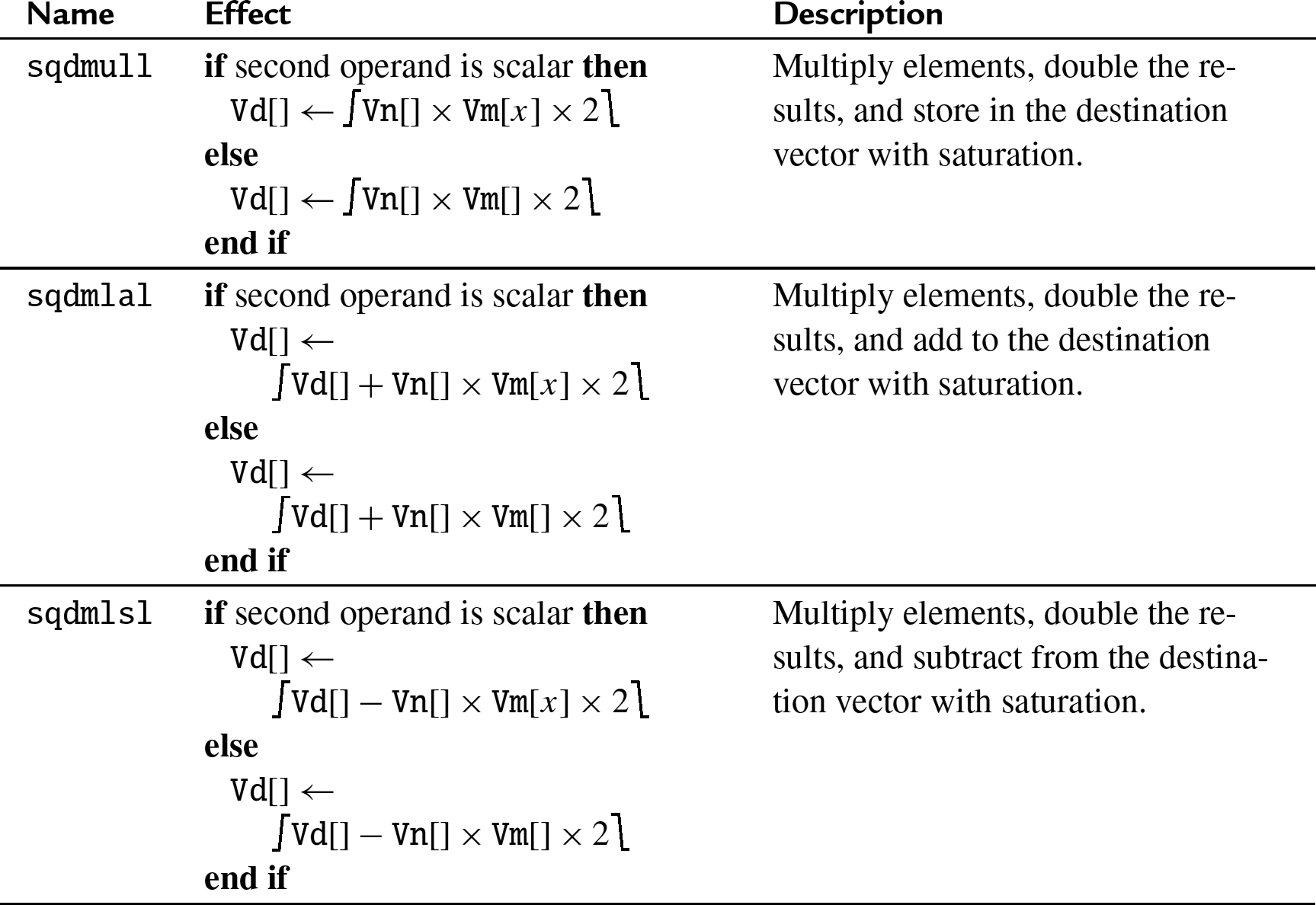
10.7.3.3 Examples

10.7.4 Saturating multiply and double (high)
These instructions perform multiplication, double the results, perform saturation, and store the high half of the results:
sqdmulh Saturating Multiply Double (High), and
sqrdmulh Saturating Multiply Double and Round (High).
10.7.4.1 Syntax

![]() .
.10.7.4.2 Operations

10.7.4.3 Examples

10.7.5 Estimate reciprocals
In general, multiplication is faster than division. In many cases of vector arithmetic, it is faster to calculate reciprocals and use multiplication. These instructions perform the initial estimates of the reciprocal values:
recpe Reciprocal Estimate, and
rsqrte Reciprocal Square Root Estimate.
These work on floating point and unsigned fixed point vectors. The estimates from this instruction are accurate to within about eight bits. If higher accuracy is desired, then the Newton-Raphson method can be used to improve the initial estimates. For more information, see the Reciprocal Step instructions on page 369.
10.7.5.1 Syntax

- • is either
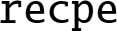 or
or  .
. - • Ta must be 2s or 4s.
- • Tb must be 2s, 4s, or 2d.
10.7.5.2 Operations

10.7.5.3 Examples

10.7.6 Reciprocal step
These instructions are used to perform one Newton-Raphson step for improving the reciprocal estimates:
frecps Reciprocal Step, and
frsqrts Reciprocal Square Root Step.
For each element in the vector, the following equation can be used to improve the estimates of the reciprocals:
Where ![]() is the estimated reciprocal from the previous step, and d is the number for which the reciprocal is desired. This equation converges to
is the estimated reciprocal from the previous step, and d is the number for which the reciprocal is desired. This equation converges to ![]() if
if ![]() is obtained using
is obtained using ![]() on d. The
on d. The ![]() instruction computes
instruction computes
so one additional multiplication is required to complete the update step. The initial estimate ![]() must be obtained using the
must be obtained using the ![]() instruction.
instruction.
For each element in the vector, the following equation can be used to improve the estimates of the reciprocals of the square roots:
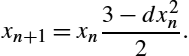
Where ![]() is the estimated reciprocal from the previous step, and d is the number for which the reciprocal is desired. This equation converges to
is the estimated reciprocal from the previous step, and d is the number for which the reciprocal is desired. This equation converges to ![]() if
if ![]() is obtained using
is obtained using ![]() on d. The
on d. The ![]() instruction computes
instruction computes
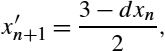
so two additional multiplications are required to complete the update step. The initial estimate ![]() must be obtained using the
must be obtained using the ![]() instruction.
instruction.
10.7.6.1 Syntax

- • is either
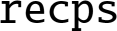 or
or 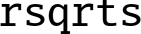 .
. - • T must be 2s, 4s, or 2d.
- • F is s or d.
10.7.6.2 Operations

10.7.6.3 Examples

10.7.7 Multiply scalar by element
These instructions are used to multiply each element in a vector by a scalar:
fmul Vector by scalar floating point multiply,
fmla Vector by scalar floating point multiply accumulate,
fmls Vector by scalar floating point multiply subtract.
10.7.7.1 Syntax

![]() (vector).
(vector). 10.7.7.2 Operations

10.7.7.3 Examples

10.7.8 Saturating multiply scalar by element and double
These instructions perform multiplication, double the results, and perform saturation:
sqdmull Saturating Multiply Scalar by Element and Double,
sqdmlal Saturating Multiply Scalar by Element, Double, and Accumulate, and
sqdmlsl Saturating Multiply Scalar by Element, Double, and Subtract.
10.7.8.1 Syntax

![]() is either
is either ![]() ,
, ![]() , or
, or ![]() .
.![]() .
.![]() .
.10.7.8.2 Operations

10.7.8.3 Examples

10.8 Shift instructions
The Advanced SIMD shift instructions operate on vectors. Shifts are often used for multiplication and division by powers of two. The results of a left shift may be larger than the destination register, resulting in overflow. A shift right is equivalent to division. In some cases, it may be useful to round the result of a division, rather than truncating. Advanced SIMD provides versions of the shift instruction which perform saturation and/or rounding of the result.
10.8.1 Vector shift left by immediate
These instructions shift each element in a vector left by an immediate value:
shl Unsigned Shift Left Immediate,
qshl Saturating Signed or Unsigned Shift Left Immediate,
sqshlu Saturating Signed Shift Left Immediate Unsigned, and
shll Signed or Unsigned Shift Left Immediate Long.
Overflow conditions can be avoided by using the saturating version, or by using the long version, in which case the destination is twice the size of the source.
10.8.1.1 Syntax

- •
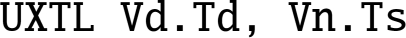 is an alias for
is an alias for 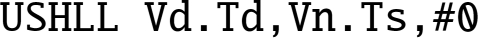 .
. - •
 is an alias for
is an alias for 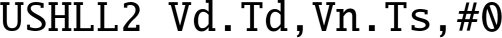 .
. - •
 is an alias for
is an alias for  .
. - •
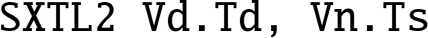 is an alias for
is an alias for  .
. - • T is 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- • If 2 is present, then Td /Ts is 8h /16b, 4s /8h, or 2d /4s.
- • If 2 is not present, then Td /Ts is 8h /8b, 4s /4h, or 2d /2s.
- • shift is in the range 0 to
 .
. - • If the instruction begins with
 , then the elements are treated as unsigned integers.
, then the elements are treated as unsigned integers. - • If
 is present, then the elements are treated as signed integers.
is present, then the elements are treated as signed integers.
10.8.1.2 Operations

10.8.1.3 Examples

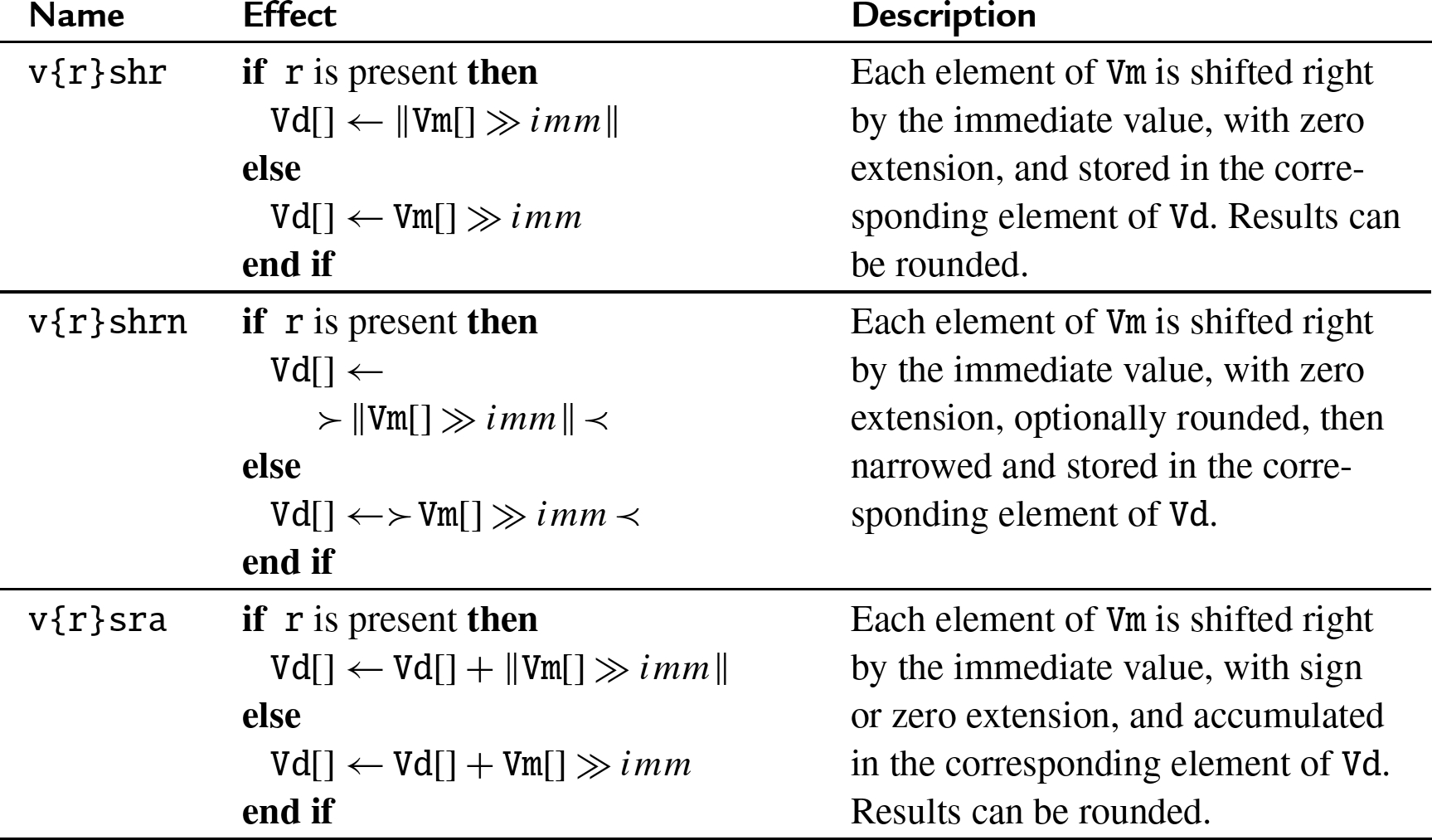
10.8.2 Vector shift right by immediate
These instructions shift each element in a vector right by an immediate value:
shr Shift Right Immediate,
rshr Shift Right Immediate and Round,
shrn Shift Right Immediate and Narrow,
rshrn Shift Right Immediate Round and Narrow,
sra Shift Right and Accumulate Immediate, and
rsra Shift Right Round and Accumulate Immediate.
10.8.2.1 Syntax

![]() (or
(or ![]() ).
).10.8.2.2 Operations
10.8.2.3 Examples

10.8.3 Vector saturating shift right by immediate
These instructions shift each element in a quad word vector right by an immediate value:
qshrn Saturating Shift Right Narrow,
qrshrn Saturating Rounding Shift Right Narrow,
sqshrun Signed Saturating Shift Right Unsigned Narrow, and
sqrshrun Signed Saturating Rounding Shift Right Unsigned Immediate.
10.8.3.1 Syntax

![]() is present, the Td /Ts is 16b /8h, 8h /4s, or 4s /2d
is present, the Td /Ts is 16b /8h, 8h /4s, or 4s /2d![]() is not present, the Td /Ts is 8b /8h, 4h /4s, or 2s /2d to elsize(Td ).
is not present, the Td /Ts is 8b /8h, 4h /4s, or 2s /2d to elsize(Td ).![]() .
.10.8.3.2 Operations

10.8.3.3 Examples

10.8.4 Shift left or right by variable
These instructions shift each element in a vector left or right, using the least significant byte of the corresponding element of a second vector as the shift amount:
shl Shift Left or Right by Variable,
rshl Shift Left or Right by Variable and Round,
qshl Saturating Shift Left or Right by Variable, and
qrshl Saturating Shift Left or Right by Variable and Round.
10.8.4.1 Syntax

![]() is specified, then the result is rounded rather than truncated.
is specified, then the result is rounded rather than truncated.![]() is specified.
is specified.![]() is present, then the results are saturated.
is present, then the results are saturated.![]() is present, then right shifted values are rounded rather than truncated.
is present, then right shifted values are rounded rather than truncated.10.8.4.2 Operations

10.8.4.3 Examples

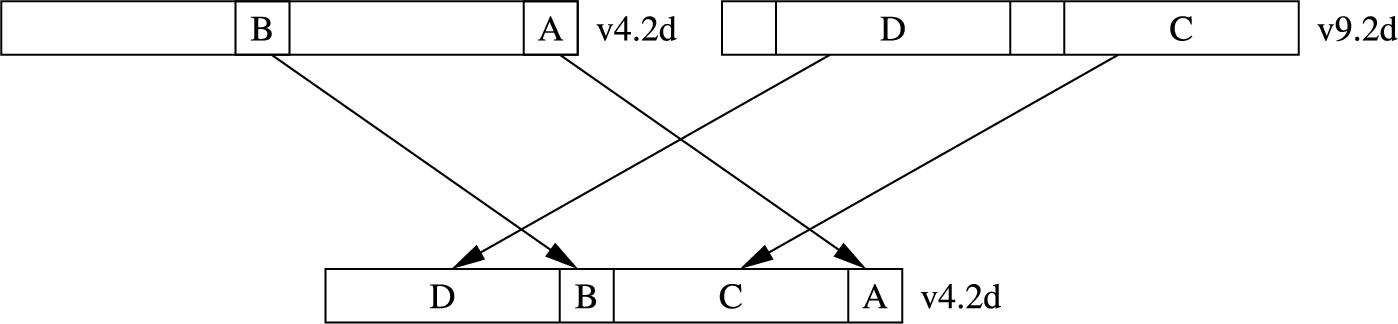
10.8.5 Shift and insert
These instructions perform bitwise shifting of each element in a vector, then combine bits from the source with bits from the destination. Fig. 10.7 provides an example. The instructions are:
sli Shift Left and Insert, and
sri Shift Right and Insert.
10.8.5.1 Syntax

- • T is 8b, 16b, 4h, 8h, 2s, 4s, or 2d.
- •
 must be l for a left shift, or r for a right shift.
must be l for a left shift, or r for a right shift. - •
 is the amount that elements are to be shifted, and must be between zero and for
is the amount that elements are to be shifted, and must be between zero and for  , or between one and
, or between one and 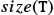 for
for  .
.
10.8.5.2 Operations

10.8.5.3 Examples

10.8.6 Scalar shift left by immediate
These instructions shift each element in a vector left by an immediate value:
shl Unsigned Shift Left Immediate,
qshl Saturating Signed or Unsigned Shift Left Immediate,
sqshlu Saturating Signed Shift Left Immediate Unsigned, and
shll Signed or Unsigned Shift Left Immediate Long.
Overflow conditions can be avoided by using the saturating version, or by using the long version, in which case the destination is twice the size of the source.
10.8.6.1 Syntax

- • F may be b, h, s, or d.
- • If the instruction begins with , then the scalars are treated as unsigned integers.
- • If is present, then the scalars are treated as signed integers.
10.8.6.2 Operations

10.8.6.3 Examples

10.8.7 Scalar shift right by immediate
These instructions shift each element in a vector right by an immediate value:
shr Shift Right Immediate,
rshr Shift Right Immediate and Round,
sra Shift Right and Accumulate Immediate, and
rsra Shift Right Round and Accumulate Immediate.
10.8.7.1 Syntax
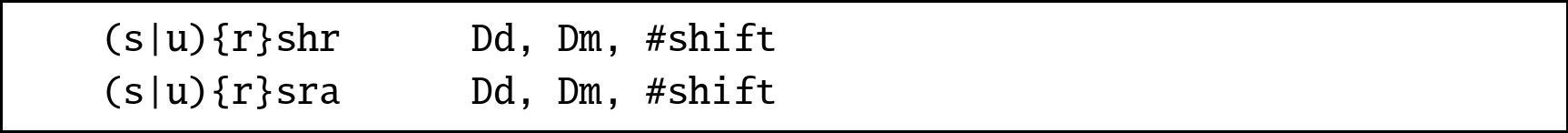
![]() (or
(or ![]() ).
).10.8.7.2 Operations

10.8.7.3 Examples

10.8.8 Scalar saturating shift right by immediate
These instructions shift each element in a quad word vector right by an immediate value:
qshrn Saturating Shift Right Narrow,
qrshrn Saturating Rounding Shift Right Narrow,
sqshrun Signed Saturating Shift Right Unsigned Narrow, and
sqrshrun Signed Saturating Rounding Shift Right Unsigned Immediate.
10.8.8.1 Syntax

10.8.8.2 Operations

10.8.8.3 Examples

10.9 Unary arithmetic
Advanced SIMD provides several unary operations for integer and floating point values. It provides instructions for bitwise complement, negation, reversing bits an elements, and other operations.
10.9.1 Vector unary arithmetic
not Vector 1's Complement,
qadd Vector Saturating Accumulate,
fsqrt Vector Floating Point Square Root,
rbit Vector bit reverse,
rev Reverse Elements.
Fig. 10.8 provides some illustrated examples of the 10.9.1.1 Syntax

10.9.1.2 Operations
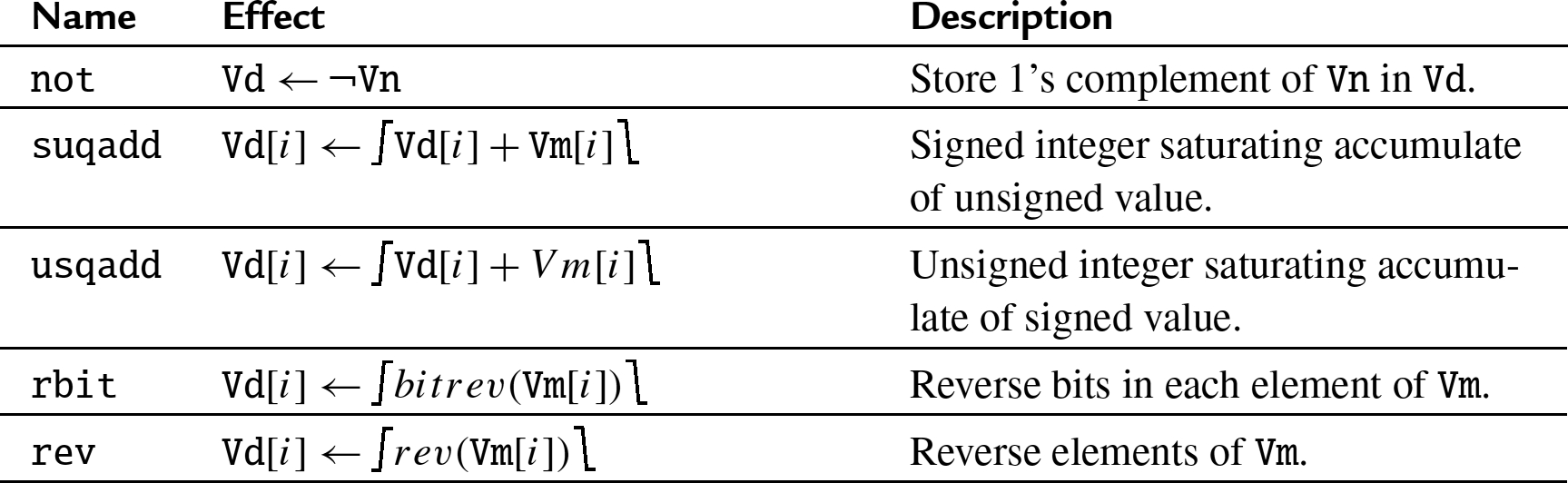
10.9.1.3 Examples
![]() instructions.
instructions.
10.9.2 Scalar unary arithmetic
abs Integer absolute value,
neg Integer absolute value,
qadd Vector Saturating Accumulate,
fsqrt Vector Floating Point Square Root,
rbit Vector bit reverse, and
rev Reverse Elements.
10.9.2.1 Syntax

10.9.2.2 Operations
10.9.2.3 Examples

10.10 Vector reduce instructions
These instructions operate across all lanes in a vector, and produce a scalar.
10.10.1 Reduce across lanes
Advanced SIMD provides instructions for summing the elements in a vector, and for getting the maximum or minimum value from a vector. These instructions are:
addv Integer Sum Elements to Scalar,
maxv Integer Maximum Element to Scalar,
minv Integer Minimum Element to Scalar,
fmaxv Floating Point Maximum Element to Scalar, and
fminv Floating Point Minimum Element to Scalar.
There are long versions of the ![]() instruction which will prevent overflow.
instruction which will prevent overflow.
10.10.1.1 Syntax

- • F /T may be b /8b, b /16b, h /4h, h /8h, s /2s, or s /4s.
- • Fa /Tn may be h /8b, h /16b, s /4h, s /8h, d /2s, or d /4s.
- • If nm is present, then comparison between a nan and a numerical value will return the numerical value.
10.10.1.2 Operations

10.10.1.3 Examples

10.10.2 Reduce pairwise
The pairwise instructions are similar to the vector reduce instructions, but always operate on two elements of the source vector. These instructions are:
addp Integer Sum Elements to Scalar,
faddp Integer Maximum Element to Scalar,
fmaxp Floating Point Maximum Element to Scalar, and
fminp Floating Point Minimum Element to Scalar.
There are long versions of the ![]() instruction which will prevent overflow.
instruction which will prevent overflow.
10.10.2.1 Syntax

- • F /T must be either s /2s or d /2d.
- • If nm is present, then comparison between a nan and a numerical value will return the numerical value.
10.10.2.2 Operations

10.10.2.3 Examples

10.11 Comparison operations
Advanced SIMD provides instructions to perform comparisons between vectors. Since there are multiple pairs of items to be compared, the comparison instructions set one element in a result vector for each pair of items. After the comparison operation, each element of the result vector will have every bit set to zero (for false) or one (for true). Note that if the elements of the result vector are interpreted as signed two's-complement numbers, then the value 0 represents false and the value −1 represents true. Note that summing the elements of the result vector (as signed integers) will give the two's complement of the number of comparisons which were true.
10.11.1 Vector compare mask
The following instructions perform comparisons of all of the corresponding elements of two vectors in parallel:
cm Vector integer compare mask, and
fcm Vector floating point compare mask.
10.11.1.1 Syntax

![]() , then it is treated as a vector of the correct size in which every element is zero.
, then it is treated as a vector of the correct size in which every element is zero.![]() can be
can be ![]() or
or ![]() .
.10.11.1.2 Operations

10.11.1.3 Examples

10.11.2 Vector absolute compare mask
The following instruction performs comparisons between the absolute values of all of the corresponding elements of two vectors in parallel:
fac Vector floating point absolute compare mask.
10.11.2.1 Syntax

10.11.2.2 Operations

10.11.2.3 Examples

10.11.3 Vector test bits mask
Advanced SIMD provides the following vector version of the ARM ![]() instruction:
instruction:
cmtst Vector test bits compare mask.
10.11.3.1 Syntax

10.11.3.2 Operations

10.11.3.3 Examples

10.11.4 Scalar compare mask
The following instructions perform comparisons of the specified scalar registers:
cm Scalar integer compare mask, and
fcm Scalar floating point compare mask,
If the comparison is true, then all bits in the destination register are set to one. Otherwise, all bits in the destination register are set to zero.
10.11.4.1 Syntax

- • The integer comparison can only operate on 64-bit integers.
- • F can be either s for single precision, or d for double precision floating point.
- • <op> is one of eq, hs, ge, hi, gt, ls, le, lo, or lt.
- • <op2> is one of eq, ge, gt, le, or lt.
10.11.4.2 Operations

10.11.4.3 Examples

10.11.5 Scalar absolute compare mask
The following instruction performs comparisons between the absolute values of two scalars:
fac Scalar floating point absolute compare mask.
10.11.5.1 Syntax

10.11.5.2 Operations

10.11.5.3 Examples

10.11.6 Scalar test bits mask
The scalar test bits instruction performs a logical AND operation between two source registers. If the result is not zero, then every bit in the result register is set to one. Otherwise, every bit in the result register is set to zero. The instruction is:
cmtst Scalar test bits compare mask.
10.11.6.1 Syntax

10.11.6.2 Operations

10.11.6.3 Examples

10.12 Performance mathematics: a final look at sine
In Chapter 9, two versions of the sine function were given. Those implementations used scalar FP/NEON instructions for single-precision and double-precision. Those previous implementations are already faster than the implementations provided by GCC, However, it may be possible to gain a little more performance by taking advantage of the Advanced SIMD architecture.
10.12.1 Single precision
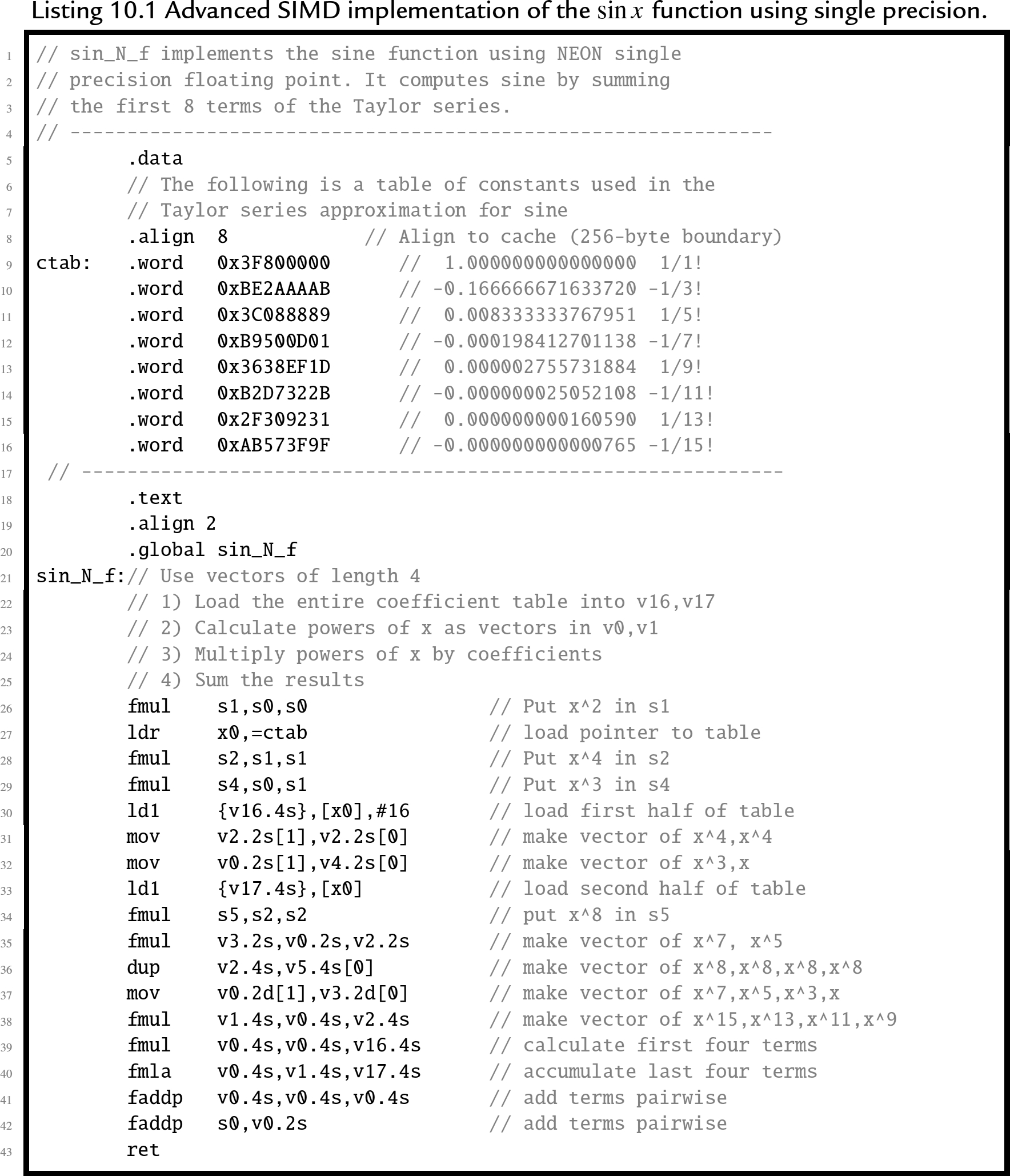
Listing 10.1 shows a single precision floating point implementation of the sine function, using Advanced SIMD vector instructions. It performs the same operations as the previous implementations of the sine function, but performs many of the calculations in parallel. This implementation is slightly faster than the previous version. In addition to being faster, it also uses nine terms of the Taylor series, so it should be more accurate as well.
10.12.2 Double precision

Listing 10.2 shows a double precision floating point implementation of the sine function. It also uses Advanced SIMD vector instructions. Both of the implementations in this chapter are faster than the corresponding implementations in Chapter 9 because they use a large number of registers, do not contain loops, and are written carefully to use vector instructions, ordered so that multiple instructions can be at different stages in the pipeline at the same time. This technique of gaining performance is known as loop unrolling. In addition to being faster, the vector implementations use more terms of the Taylor series, so they may also be more accurate.
10.12.3 Performance comparison
Table 10.1 compares the implementations from Listing 10.1 and Listing 10.2 with the FP/NEON implementations from Chapter 9 and the sine function provided by GCC. When compiler optimization is not used, the single precision scalar FP/NEON implementation achieves a speedup of about 3.41, and the Advanced SIMD implementation achieves a speedup of about 4.21 compared to the GCC implementation. The double precision scalar FP/NEON implementation achieves a speedup of about 2.22, and the Advanced SIMD achieves a speedup of about 2.41 compared to the GCC implementation.
Table 10.1
Performance of sine function with various implementations.
| Optimization | Implementation | CPU seconds |
|---|---|---|
| None | Single Precision C | 6.958 |
| Single Precision FP/NEON scalar Assembly | 2.038 | |
| Single Precision Advanced SIMD Assembly | 1.654 | |
| Double Precision C | 6.682 | |
| Double Precision FP/NEON scalar Assembly | 3.014 | |
| Double Precision Advanced SIMD Assembly | 2.778 | |
| Full | Single Precision C | 4.409 |
| Single Precision FP/NEON scalar Assembly | 1.449 | |
| Single Precision Advanced SIMD Assembly | 1.142 | |
| Double Precision C | 5.758 | |
| Double Precision FP/NEON scalar Assembly | 2.134 | |
| Double Precision Advanced SIMD Assembly | 1.941 |
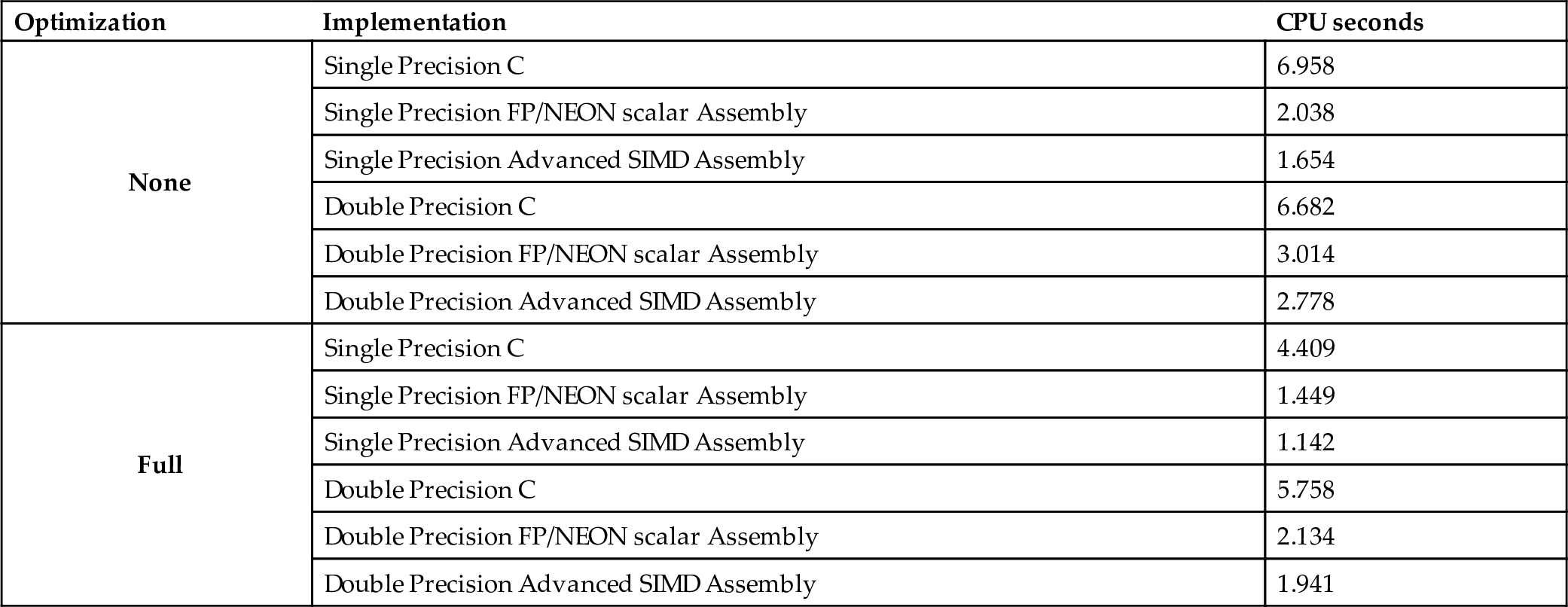
When the compiler optimization is used (-Ofast), the single precision scalar FP/NEON implementation achieves a speedup of about 3.04, and the Advanced SIMD implementation achieves a speedup of about 3.86 compared to the GCC implementation. The double precision scalar FP/NEON implementation achieves a speedup of about 2.70, and the Advanced SIMD implementation achieves a speedup of about 2.97 compared to the GCC implementation. The single precision Advanced SIMD version was 1.27 times as fast as the FP/NEON scalar version, and the double precision Advanced SIMD implementation was 1.10 times as fast as the FP/NEON scalar implementation.
Although the FP/NEON versions of the sine functions were already much faster than the C standard library, re-writing them using Advanced SIMD resulted in further performance improvement. The take-away lesson is that a programmer can improve performance by writing some functions in assembly that are specifically targeted to run on a specific platform. To achieve optimal or near-optimal performance, it is important for the programmer to be aware of advanced features available on the hardware platform that is being used.
10.13 Alphabetized list of advanced SIMD instructions
| Name | Page | Operation |
|---|---|---|
| aba | 354 | Vector integer absolute difference and accumulate |
| abal | 355 | Vector absolute difference and accumulate long |
| abd | 354 | Vector integer absolute difference |
| abdl | 355 | Vector absolute difference long |
| abs | 383 | Integer absolute value |
| abs | 356 | Vector absolute value |
| adalp | 353 | Vector add and accumulate long pairwise |
| add | 348 | Vector integer add |
| addhn | 351 | Vector add and narrow |
| addl | 348 | Vector add long |
| addlp | 353 | Vector add long pairwise |
| addp | 386 | Integer Sum Elements to Scalar |
| addp | 353 | Vector add pairwise |
| addv | 385 | Integer Sum Elements to Scalar |
| addw | 349 | Vector add wide |
| and | 346 | Vector bitwise AND |
| bic | 347 | Vector Bit clear immediate |
| bic | 346 | Vector bit clear |
| bif | 346 | Vector insert if false |
| bit | 346 | Vector insert if true |
| bsl | 346 | Vector bitwise select |
| cls | 359 | Vector count leading sign bits |
| clz | 359 | Vector count leading zero bits |
| cm | 391 | Scalar integer compare mask |
| cm | 388 | Vector integer compare mask |
| cmtst | 393 | Scalar test bits compare mask |
| cmtst | 390 | Vector test bits compare mask |
| cnt | 359 | Vector count set bits |
| cvtf | 343 | Vector convert integer or fixed point to floating point |
| dup | 333 | Duplicate Scalar |
| eor | 346 | Vector bitwise Exclusive-OR |
| ext | 339 | Byte Extract |
| faba | 355 | Vector floating point absolute difference and accumulate |
| fabd | 354 | Vector floating point absolute difference |
| fabs | 356 | Vector floating point absolute value |
| fac | 392 | Scalar floating point absolute compare mask |
| fac | 389 | Vector floating point absolute compare mask |
| fadd | 348 | Vector floating point add |
| faddp | 386 | Integer Maximum Element to Scalar |
| fcm | 391 | Scalar floating point compare mask |
| fcm | 388 | Vector floating point compare mask |
| fcvt | 343 | Vector convert floating point to integer or fixed point |
| fcvtl | 344 | Vector convert from half to single precision |
| fcvtn | 344 | Vector convert from single to half precision |
| fcvtxn | 344 | Vector convert from double to single precision |
| fdiv | 362 | Vector floating point divide |
| fmadd | 310 | Fused Multiply Accumulate |
| fmax | 357 | Vector floating point maximum |
| fmaxnm | 357 | Vector floating point maxnum |
| fmaxnmp | 357 | Vector floating point pairwise maxnum |
| fmaxp | 386 | Floating Point Maximum Element to Scalar |
| fmaxp | 357 | Vector floating point pairwise maximum |
| fmaxv | 385 | Floating Point Maximum Element to Scalar |
| fmin | 357 | Vector floating point minimum |
| fminnm | 357 | Vector floating point minnum |
| fminnmp | 357 | Vector floating point pairwise minnum |
| fminp | 387 | Floating Point Minimum Element to Scalar |
| fminp | 357 | Vector floating point pairwise minimum |
| fminv | 385 | Floating Point Minimum Element to Scalar |
| fmla | 364 | Vector by scalar floating point multiply accumulate |
| fmla | 370 | Vector by scalar floating point multiply accumulate |
| fmla | 362 | Vector floating point multiply accumulate |
| fmls | 364 | Vector by scalar floating point multiply subtract |
| fmls | 370 | Vector by scalar floating point multiply subtract |
| fmls | 362 | Vector floating point multiply subtract |
| fmov | 336 | Vector Floating Point Move Immediate |
| fmsub | 310 | Fused Multiply Subtract |
| fmul | 364 | Vector by scalar floating point multiply |
| fmul | 370 | Vector by scalar floating point multiply |
| fmul | 362 | Vector floating point multiply |
| fneg | 356 | Vector floating point negate |
| fnmadd | 310 | Fused Multiply Accumulate and Negate |
| fnmsub | 310 | Fused Multiply Subtract and Negate |
| frecps | 369 | Reciprocal Step |
| frint | 345 | Round Floating Point to Integer |
| frsqrts | 369 | Reciprocal Square Root Step |
| fsqrt | 382 | Vector Floating Point Square Root |
| fsqrt | 383 | Vector Floating Point Square Root |
| fsub | 349 | Vector floating point subtract |
| hadd | 352 | Vector halving add |
| hsub | 352 | Vector halving subtract |
| ld<n> | 329 | Load Multiple Structured Data |
| ld<n> | 327 | Load Structured Data |
| ld<n>r | 331 | Load Copies of Structured Data |
| max | 357 | Vector integer maximum |
| maxp | 357 | Vector integer pairwise maximum |
| maxv | 385 | Integer Maximum Element to Scalar |
| min | 357 | Vector integer minimum |
| minp | 357 | Vector integer pairwise minimum |
| minv | 385 | Integer Minimum Element to Scalar |
| mla | 364 | Vector by scalar integer multiply accumulate |
| mla | 362 | Vector integer multiply accumulate |
| mlal | 364 | Vector by scalar multiply accumulate long |
| mlal | 362 | Vector multiply accumulate long |
| mls | 364 | Vector by scalar integer multiply subtract |
| mls | 362 | Vector integer multiply subtract |
| mlsl | 364 | Vector by scalar multiply subtract long |
| mlsl | 362 | Vector multiply subtract long |
| mov | 334 | Copy element into vector |
| movi | 336 | Vector Move Immediate |
| mul | 364 | Vector by scalar integer multiply |
| mul | 362 | Vector integer multiply |
| mull | 364 | Vector by scalar multiply long |
| mull | 362 | Vector multiply long |
| mvni | 336 | Vector Move NOT Immediate |
| neg | 383 | Integer absolute value |
| neg | 356 | Vector negate |
| not | 382 | Vector 1's Complement |
| orn | 346 | Vector bitwise NOR |
| orr | 346 | Vector bitwise OR |
| orr | 347 | Vector bitwise OR immediate |
| pmul | 362 | Vector polynomial multiply |
| pmull | 362 | Vector polynomial multiply long |
| qadd | 360 | Scalar saturating add |
| qadd | 382 | Vector Saturating Accumulate |
| qadd | 383 | Vector Saturating Accumulate |
| qadd | 348 | Vector saturating add |
| qdmulh | 360 | Scalar saturating multiply (high half) |
| qrshl | 377 | Saturating Shift Left or Right by Variable and Round |
| qrshrn | 376 | Saturating Rounding Shift Right Narrow |
| qrshrn | 381 | Saturating Rounding Shift Right Narrow |
| qshl | 377 | Saturating Shift Left or Right by Variable |
| qshl | 373 | Saturating Signed or Unsigned Shift Left Immediate |
| qshl | 379 | Saturating Signed or Unsigned Shift Left Immediate |
| qshl | 360 | Scalar saturating shift left |
| qshrn | 376 | Saturating Shift Right Narrow |
| qshrn | 381 | Saturating Shift Right Narrow |
| qsub | 360 | Scalar saturating subtract |
| qsub | 349 | Vector saturating subtract |
| raddhn | 351 | Vector add, round, and narrow |
| rbit | 382 | Vector bit reverse |
| rbit | 384 | Vector bit reverse |
| recpe | 368 | Reciprocal Estimate |
| rev | 382 | Reverse Elements |
| rev | 384 | Reverse Elements |
| rhadd | 352 | Vector halving add and round |
| rshl | 377 | Shift Left or Right by Variable and Round |
| rshr | 374 | Shift Right Immediate and Round |
| rshr | 380 | Shift Right Immediate and Round |
| rshrn | 374 | Shift Right Immediate Round and Narrow |
| rsqrte | 368 | Reciprocal Square Root Estimate |
| rsra | 374 | Shift Right Round and Accumulate Immediate |
| rsra | 380 | Shift Right Round and Accumulate Immediate |
| rsubhn | 351 | Vector subtract, round, and narrow |
| shl | 377 | Shift Left or Right by Variable |
| shl | 373 | Unsigned Shift Left Immediate |
| shl | 379 | Unsigned Shift Left Immediate |
| shll | 373 | Signed or Unsigned Shift Left Immediate Long |
| shll | 379 | Signed or Unsigned Shift Left Immediate Long |
| shr | 374 | Shift Right Immediate |
| shr | 380 | Shift Right Immediate |
| shrn | 374 | Shift Right Immediate and Narrow |
| sli | 378 | Shift Left and Insert |
| smov | 334 | Copy signed integer element from vector to AARCH64 register |
| sqdmlal | 365 | Saturating Multiply Double Accumulate |
| sqdmlal | 371 | Saturating Multiply Scalar by Element, Double, and Accumulate |
| sqdmlsl | 365 | Saturating Multiply Double Subtract |
| sqdmlsl | 371 | Saturating Multiply Scalar by Element, Double, and Subtract |
| sqdmulh | 366 | Saturating Multiply Double (High) |
| sqdmull | 365 | Saturating Multiply Double |
| sqdmull | 371 | Saturating Multiply Scalar by Element and Double |
| sqrdmulh | 367 | Saturating Multiply Double and Round (High) |
| sqrshrun | 376 | Signed Saturating Rounding Shift Right Unsigned Immediate |
| sqrshrun | 381 | Signed Saturating Rounding Shift Right Unsigned Immediate |
| sqshlu | 373 | Saturating Signed Shift Left Immediate Unsigned |
| sqshlu | 379 | Saturating Signed Shift Left Immediate Unsigned |
| sqshrun | 376 | Signed Saturating Shift Right Unsigned Narrow |
| sqshrun | 381 | Signed Saturating Shift Right Unsigned Narrow |
| sra | 374 | Shift Right and Accumulate Immediate |
| sra | 380 | Shift Right and Accumulate Immediate |
| sri | 378 | Shift Right and Insert |
| st<n> | 329 | Store Multiple Structured Data |
| st<n> | 327 | Store Structured Data |
| sub | 349 | Vector integer subtract |
| subhn | 351 | Vector subtract and narrow |
| subl | 349 | Vector subtract long |
| subw | 349 | Vector subtract wide |
| tbl | 341 | Table Lookup |
| tbx | 341 | Table Lookup with Extend |
| trn | 337 | Transpose Matrix |
| umov | 334 | Copy unsigned integer element from vector to AARCH64 register |
| uzp | 339 | Unzip Vectors |
| zip | 339 | Zip Vectors |
10.14 Advanced SIMD intrinsics
The C compiler may provide C (and C++) programs direct access to the Advanced SIMD instructions through the Advanced SIMD intrinsics library. The intrinsics are a large set of functions that are built into the compiler. Most of the intrinsics functions map to one Advanced SIMD instruction. There are additional functions provided for typecasting (reinterpreting) SIMD vectors, so that the C compiler does not complain about mismatched types. It is usually shorter and more efficient to write the Advanced SIMD code directly as assembly language functions and link them to the C code. However only those who know assembly language are capable of doing that.
10.15 Chapter summary
Advanced SIMD can dramatically improve performance of algorithms that can take advantage of data parallelism. However, compiler support for automatically vectorizing and using Advanced SIMD instructions is still immature. Advanced SIMD intrinsics allow C and C++ programmers to access these instructions, by making them look like C functions. It is usually just as easy and more concise to write AArch64 assembly code as it is to use the intrinsics functions. A careful assembly language programmer can usually beat the compiler, sometimes by a wide margin.
Exercises
- 10.1. What is the advantage of using IEEE half-precision? What is the disadvantage?
- 10.2. Advanced SIMD achieved relatively modest performance gains on the sine function, when compared to FP/NEON.
- a. Why?
- b. List some tasks for which Advanced SIMD could significantly outperform scalar FP/NEON.
- 10.3. There are some limitations on the size of the structure that can be loaded or stored using the
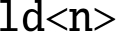 and
and  instructions. What are the limitations?
instructions. What are the limitations? - 10.4. The sine function in Listing 10.2 uses a technique known as “loop unrolling” to achieve higher performance. Name at least three reasons why this code is more efficient than using a loop?
- 10.5. Reimplement the fixed-point sine function from Listing 8.7 using Advanced SIMD instructions. Hint: you should not need to use a loop. Compare the performance of your Advanced SIMD implementation with the performance of the original implementation.
- 10.6. Reimplement Exercise 9.10. using Advanced SIMD instructions.
- 10.7. Fixed point operations may be faster than floating point operations. Modify your code from the previous example so that it uses the following definitions for points and transformation matrices:

- Use saturating instructions and/or any other techniques necessary to prevent overflow. Compare the performance of the two implementations.