
Chapter 10. Internals
This chapter describes the internal workings of Accumulo. Although Accumulo can be used without a knowledge of its internals, developing an increased understanding of how Accumulo works will make it easier to understand and make decisions about how best to interact with Accumulo.
Tablet Server
Accumulo tables are split into contiguous ranges called tablets. Each tablet is assigned to a tablet server, also known as a tserver, that is responsible for all reads and writes for the tablet. Each tablet server can be assigned hundreds or even thousands of tablets. If an Accumulo instance reaches well over 1,000 tablets per server, it is time to start making adjustments: merging tablets, deleting old data, rethinking the table design, or increasing the size of the cluster.
An Accumulo instance typically runs one tablet server per slave node (for example, each server that is running an HDFS DataNode). A tablet server registers with an Accumulo instance by obtaining a lock in ZooKeeper. If a tablet server loses or is unable to monitor its lock, it will kill itself. It is important for Accumulo to be able to keep track of properly functioning tablet servers and to automatically shut down unresponsive tablet servers in order to ensure that a tablet is never assigned to more than one tablet server. ZooKeeper locks assist this process.
The following sections describe many of the operations tablet servers perform on their tablets.
Discussion of Log-Structured Merge Tree
The reading and writing for an individual tablet are governed by a log-structured merge-tree approach1 as interpreted in the BigTable design. This technique is designed to take best advantage of hardware that performs fast sequential writes and is most useful when much more data is written than is read.
When reading or writing new data, the Accumulo client library first locates which tablet should contain the data and which tablet server is hosting that tablet. This is accomplished by looking up the location of the root table, which contains information about the tablets of the metadata table. Once the desired metadata tablet and its location are read from the root tablet, the desired data tablet and its location are looked up in the metadata tablet. The client library caches tablet locations that it has found previously, so when data is looked up again it may be able to skip one or more of these steps.
Starting in Accumulo 1.6, the root tablet is considered to be in a separate root table that is never split. In earlier versions, the root tablet is considered to be part of the metadata table. This change does not affect how the client interacts with Accumulo, but it simplifies Accumulo’s internal implementation.
Write Path
Within a tablet, incoming writes are committed to an on-disk write-ahead log. (Write-ahead logging can optionally be disabled per table, at the risk of losing data if a single tablet server goes down with data in memory that has not made it onto disk.) The write-ahead log is not sorted by key, because new data is appended to it. In Accumulo 1.5.0 and later, the write-ahead log is stored directly in HDFS. The number of replicas required for the write-ahead logfiles can be configured. In Accumulo 1.4 a custom logging process writes to local disk instead. The write-ahead logs are manually replicated onto the disk of one remote server in addition to local disk.
Once the new data is confirmed to be on disk, it is inserted into a sorted in-memory structure. At this point, the write is successful and the data will available for reads (Figure 10-1).
When the resource manager determines that a tablet server’s allocated memory is becoming full, it selects some tablets for minor compaction, which means flushing data from memory to disk. Successful minor compaction results in a new sorted HDFS file associated with the tablet.

Figure 10-1. Write path
Read Path
Within a tablet, reads consist of constructing a merged view of sorted in-memory and on-disk structures (Figure 10-2). The on-disk structures are HDFS files associated with the tablet and do not include write-ahead logfiles, which are unsorted.

Figure 10-2. Read path
Resource Manager
Each tablet server has a resource manager that maintains thread pools for minor and major compaction, tablet splits, migration and assignment, and a read-ahead pipeline. The sizes of these thread pools are configurable via appropriate properties, with the exception of the split and assignment thread pools, which each contain a single thread:
tserver.compaction.major.concurrent.max tserver.compaction.minor.concurrent.max tserver.migrations.concurrent.max tserver.readahead.concurrent.max tserver.metadata.readahead.concurrent.max
Minor compaction
Minor compaction is the process of flushing data that is sorted in memory onto a sorted file on disk (Figure 10-3).
The resource manager includes a memory manager that periodically evaluates the current states of the server’s assigned tablets and returns a list of tablets that should be minor-compacted.
The memory manager is pluggable, with its class being configured by tserver.memory.manager.
The default memory manager is the LargestFirstMemoryManager.
If the total memory usage of all the tablets on the tablet server exceeds a dynamic threshold, or if the time of a tablet’s last write is far enough in the past, a tablet will be selected for minor compaction.
The threshold is adjusted over time so that the highest memory usage before a minor compaction is between 80 and 90 percent of the maximum memory allowed for the tablet server, tserver.memory.maps.max.
If too many minor compactions are already queued, it will not select additional tablets for minor compaction until the queue has decreased.
The number of minor-compaction tasks allowed in the queue is twice the number that can be executed concurrently, which is controlled by the global tserver.compaction.minor.concurrent.max configuration property . The per-table table.compaction.minor.idle property controls how long a tablet can be idle before becoming a candidate for minor compaction.
The memory manager selects the tablet with the highest combination of memory usage and idle time—memory * 2^(minutes idle / 15)—or, if memory is not too full, the idle tablet with the highest combination of these.
If a tablet has more than a specified number of write-ahead logfiles (table.compaction.minor.logs.threshold), it will be minor compacted outside of the memory management system.
This is to reduce recovery time in the case of tablet server failure.

Figure 10-3. Minor compaction
Major compaction
When there are too many files for a tablet, read performance will suffer because each lookup must perform a merged read of all the sorted files and in-memory structures for the tablet. For this reason, each tablet server has a thread pool devoted to merging together files within a tablet. This process of merging together some or all of a tablet’s files is called major compaction (Figure 10-4). If all of a tablet’s files are merged into a single file, it is called a full major compaction. The full major compaction is noted as a special case because additional cleaning up of obsolete data is possible when all of a tablet’s existing data is being rewritten.
You can request a full major compaction for a table through the shell or the API. The compaction can be restricted to a range of tablets specified by start and end rows. A user-initiated compaction can also be canceled.
Major compactions are also initiated automatically by tablet servers.
Tablet servers evaluate whether files need to be merged periodically.
How long the tablet servers wait between evaluations is controlled by the global tserver.compaction.major.delay property.
In Accumulo 1.6 and later, the strategy for performing major compactions is pluggable and is configured per table with the table.majc.compaction.strategy property.
The per-table table.compaction.major.ratio property influences the tablet server’s decision whether to merge files and which files are merged.
To determine whether a tablet’s files are in need of major compaction, the tablet server first sorts the files by size.
If the size of the largest file times the compaction ratio is less than or equal to the sum of the sizes of all the files, the set of files is merged into a single file.
If this is not true, the largest file is removed from the set and the remaining files are evaluated.
This is repeated until a set of files is selected for compaction or until there is only one file left in the set.
This algorithm is chosen to reduce the number of times data is rewritten through major compaction.
Effectively, it tries to compact small files into significantly larger files that won’t need to be compacted as often.
There is a maximum for the number of files a single major compaction thread is allowed to open, tserver.compaction.major.thread.files.open.max.
If a set of files selected for major compaction contains more files than this maximum, the compaction will merge the N-smallest files, where N is the number of files that are allowed.
The remaining uncompacted files will eventually be compacted in multiple passes.

Figure 10-4. Major compaction
Merging minor compaction
The major compaction algorithm can result in a large number of files as the tablet size grows.
This can reduce read performance and increase memory usage requirements for the tablet server.
There is a per-table property that provides a hard maximum on the number of files per tablet, table.file.max.
When a tablet reaches this number of files, the tablet server will not create new files via minor compaction.
Instead, the tablet server will choose the tablet’s smallest file, and merge the data from this file and the in-memory structure into a new file (Figure 10-5).
This process is called a merging minor compaction.
Caution
Consider adjustments to the table.file.max property carefully.
Making it low can increase read performance while decreasing write performance. The performance of bulk-loading data is not affected.

Figure 10-5. Merging minor compaction
Splits
When a tablet’s size reaches a configurable threshold, the tablet server will decide to split it into two tablets (Figure 10-6).
Splitting tablets into smaller pieces allows Accumulo to spread load more evenly across tablet servers.
Tablets are split on row boundaries only, so that a row is never spread across more than a single tablet.
The threshold for tablet size is set in bytes via table.split.threshold.
Conceptually, the server must create two new tablets, split the original tablet’s data appropriately between the two new tablets, and update the metadata table with information about the two new tablets, removing information about the original tablet as needed.
To make splitting a lightweight metadata operation that does not require rewriting the original tablet’s data, the names of a tablet’s files are stored in the metadata table. This allows files to be associated with more than one tablet. When reading data from its files, a tablet restricts its reads to the range of keys in its own domain. When a tablet is split into two new tablets, both of the new tablets will use the files of the original tablet. Splitting takes priority over compaction so that a tablet that is growing very quickly can be split into as many tablets as needed before the new tablets start compacting their files, which would otherwise be an ingest bottleneck.
Splitting requires multiple rows in the metadata table to be updated. This means that it is not inherently an atomic operation. To achieve fault tolerance during splitting, the tablet server performs the following process. First the tablet is closed so that no new writes are accepted. Then three writes are made to the metadata table: the tablet is made smaller and is marked as splitting; a new tablet is added; and the original tablet’s splitting marks are removed. The tablet server swaps the new tablets for the old tablet in its online tablet list, and the master is informed of the new tablets. If the tablet server goes down during the splitting process, a new tablet server will pick up the splitting process where it left off. The new server determines that splitting must be continued if a tablet it is assigned has splitting marks in the metadata table.
Note
Splitting a table into enough tablets is essential to being able to take advantage of the parallelism of the system. By default, a table’s tablets will be spread evenly across the tablet servers. For some applications it is better not to leave the split points to chance. Split points can be specified when a table is created, or added to an existing table.
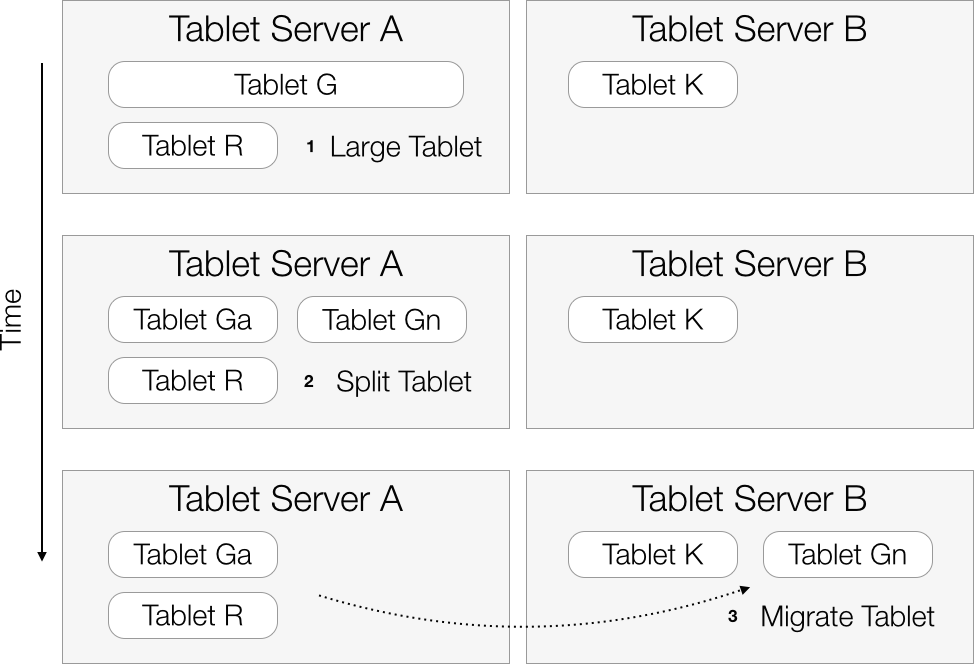
Figure 10-6. Tablet splitting process
Write-Ahead Logs
Write-ahead logs are used to guarantee data integrity in the presence of hardware or software failures. Because each tablet contains an in-memory map that stores recently written data, this data must be persisted to disk first to ensure that it isn’t lost. A single write-ahead logfile is only written to by a single tablet server, but log entries for all tablets assigned to that server can be intermingled in the same logfile. Bulk ingest does not utilize the write-ahead log or the in-memory map for a tablet, because this involves introducing new sorted files to a tablet.
The logging mechanisms are different in different versions of Accumulo. Accumulo 1.4 and earlier used custom logging processes. Each slave node would typically be configured to run one tablet server process and one logger process. When a tablet server received new data, it would log the data to the local logger process, if present, and to one remote logger process. It would send data to two remote loggers if a local logger was not present.
In Accumulo 1.5 and later, data is logged directly to a file in HDFS, so that separate logger processes are not needed.
The tablet server waits until the data is replicated appropriately by HDFS, and then it proceeds with inserting the data into the in-memory map for the appropriate tablet.
The HDFS replication of write-ahead logfiles is controlled with the tserver.wal.replication property.
If this property is set to 0, the HDFS default replication is used.
Setting this property to 2 will provide similar performance and data protection to Accumulo 1.4. Setting it to 3 will provide even better data protection, ensuring that data is written to three different disks before it is committed to Accumulo.
However, this will use more disk I/O resources when writing and can affect ingest performance.
It is not recommended that the replication of write-ahead logfiles be set to 1, because a single server failure could result in data loss.
Recovery
Like regular data files, the write-ahead logfiles containing data for a given tablet are written to the metadata table row for that tablet.
If a tablet server is assigned a tablet that has write-ahead log entries in the metadata table, the tablet server will conduct a log recovery before bringing the tablet online (Figure 10-7).
Because the logs contain unsorted data for multiple tablets, the files are first sorted so that servers don’t need to read through irrelevant data to recover the data for a single tablet.
Sorting of logfiles is done by a work queue managed in ZooKeeper.
The master submits files to this work queue when it reassigns tablets that have write-ahead log entries.
Each tablet server monitors the work queue for new files that need to be sorted and maintains a thread pool for sorting tasks.
The size of the thread pool is controlled with the tserver.recovery.concurrent.max property.
A single tablet server will win the race to grab a file from the work queue and begin sorting it.
It reads a large chunk of the file into memory and writes it out sorted by entry type, tablet, and original order in the file.
It repeats this process, creating a new file for each chunk that fits in memory, until the entire file is sorted.
The size of the sorted chunks defaults to 200 MB and can be adjusted by changing the tserver.sort.buffer.size property.
A typical write-ahead logfile size is 1 GB, controlled by tserver.walog.max.size.
Under normal circumstances a tablet will only have one or two write-ahead logfiles, so with the default settings there may be 5 to 10 sorted file chunks to read during data recovery.
In addition to logged data, the file contains minor compaction start and finish markers and specifies a concise tablet ID for each tablet referenced. The usual identifier for a tablet is its key extent (start row exclusive, end row inclusive), but a short ID is assigned in the write-ahead logs so that it can be specified in fewer bytes. Once the sorting is completed, the tablet server that will host the tablet begins recovering the data for that tablet. It conducts a merged read of all the sorted log chunks that can contain data for the tablet. First it finds the tablet ID, then it uses the ID to find the last minor compaction that succeeded for the tablet. This determines which log entries must be replayed. Once the tablet server has replayed the log entries, it minor-compacts the tablet. Currently, a tablet server only recovers one tablet at a time, because newly assigned tablets are only loaded one at a time.

Figure 10-7. Recovery from tablet server failure
File formats
BigTable’s SSTable file format is described as a sequence of compressed data blocks followed by a block index. Both the data blocks and the index consist of key-value pairs sorted by key, with the index containing the first key of each data block (or perhaps a smaller equivalent key) paired with the location in the file of the beginning of that data block. When the file is opened, the index is read into memory. To locate a key in the file, a binary search is performed on the index to find the location of the data block containing the desired key. Then this data block is read from disk and scanned sequentially until the desired key is reached.
The file format used by Accumulo is the RFile, which stands for relative key file. RFiles have a similar structure to SSTables with a few additional optimizations. The size of the compressed blocks in an RFile is controlled per table with the table.file.compress.blocksize property, which defaults to 100 KB. This size is prior to compression.
Tip
Note that compressed blocks (~100 KB) are not the same as HDFS blocks (128 MB or more). There are many compressed blocks per HDFS block.
RFile optimizations
A single-index approach doesn’t work well for very large files because as the file size grows, so must the size of the index.
Because the index is read into memory when the file is opened, it will take longer to open larger files.
This can be mitigated somewhat by increasing the compressed block size to decrease the size of the index, but then lookup times will also increase because the data blocks are scanned sequentially when looking up keys.
To support very large files, Accumulo 1.4 introduces a multilevel index.
The table.file.compress.blocksize.index property, defaulting to 128 KB prior to compression, sets the maximum size of an index block.
When a file is written, the index to the beginnings of the compressed data blocks is accumulated in memory.
When the index reaches its maximum size, a level 0 index block is written out, a level 1 index is started with a pointer to the level 0 index block, and a new level 0 index block is started with pointers to data blocks.
When all the data has been written out, any remaining index blocks are written to the file.
When the file is opened, only the highest level index must be read into memory.
There is no limit to the number of index levels, but a two-level index is sufficient for files in the tens of gigabytes with the default settings.
See Figure 10-8 for an illustration of the on-disk data layout for a two-level index.
Accumulo 1.5 features an additional optimization to reduce the time needed to sequentially scan a data block. Once a given data block has been accessed once, it is cached in memory. When the data block has been accessed twice, the RFile begins building a dynamic, ephemeral index by storing the key and pointer corresponding to the midpoint of the block. As the block continues to be used, when it is accessed 2^N times, N additional keys will be added to the ephemeral index.
Relative key encoding
Within a compressed block, Accumulo performs compression of identical portions and identical prefixes of portions of consecutive keys. A single byte is used to encode whether the row, column family, column qualifier, column visibility, and/or timestamp match those of the previous key. Of the remaining three bits in that byte, one is used to indicate whether any prefix compression is present for the key, another is used as the deletion flag for the key, and the last is unused. Prefix compression is only available in Accumulo 1.5 and later. If prefix compression is present, an additional byte is used to indicate whether the row, column family, column qualifier, and/or column visibility have a common prefix as the previous key, and whether the timestamp is expressed as a difference from the previous timestamp. A common prefix must be at least two bytes. The remaining three bits of the prefix compression byte are unused.
If a portion of the key matches that portion of the previous key identically, as indicated in the first byte, no additional information needs to be written for that portion. If a portion of the key has a common prefix with that portion of the previous key, the length of the prefix is written followed by the remaining bytes for that portion of the key. In the case of the timestamp, there is no prefix length, but the difference from the previous key is written. If a portion of the key has no common prefix with the previous key, the entire portion is written.
Locality groups
To enable greater intermingling of different types of data in a single Accumulo table, RFiles also support locality groups. This feature allows sets of column families to be grouped together on disk, which can result in better compression. It also allows applications to tune a table’s disk layout to better suit its access patterns. For example, if two columns are always queried together, the columns could be put in a locality group. Alternatively, if one column contains very large data, such as image files, and another column contains much smaller data, such as text, these columns could be put in different locality groups to improve the lookup times when only text data is retrieved.
BigTable maintains separate SSTables for each locality group, whereas RFiles store locality groups in different sections of the same file. This makes the number of files Accumulo must manage independent of the number of locality groups or column families.
Unlike BigTable, Accumulo does not require column families to be specified before data can be inserted into those families. To accommodate the use of unspecified column families, Accumulo introduces the concept of a default locality group. All columns are stored in the default locality group unless configured otherwise. Locality group mappings can be added or changed at any time, but will only take effect for new files written. RFiles are immutable, so files remain in the locality groupings that were in effect when the files were created. When new files are created through minor or major compaction, they will use the newest locality group configuration.
Figure 10-8 illustrates how the file layout is modified to make accessing data within a locality group efficient.

Figure 10-8. File layout with and without locality groups
Bloom filters
Bloom filters are data structures used to help determine whether a set of elements contains a given element. Accumulo can use bloom filters to determine whether a given key might be found in a file, or whether that file does not need to be searched for the key.
Bloom filters can optionally be enabled per table.
The properties governing the bloom filter configuration are of the form table.bloom.*.
If enabled, a bloom filter layer maintains a set of bloom filters for each file. Each key in a file is hashed with a number of hash functions, and the resulting hashes are represented as a bit vector. A bloom filter is the OR of the bit vectors for each key in a file.2
When looking up a key in the file, the bloom filter can be used to determine if the file can contain the key, or definitively does not contain the key (Figure 10-9). This check can be performed more efficiently than seeking for the key in the file, especially if the bloom filter has already been loaded into memory.
By default, the bloom filter layer hashes the row portion of the key, so it can be used to determine if a particular row appears in the file.
However, it can be configured to hash the row and column family, or the row, column family, and column qualifier.
This is controlled by setting table.bloom.key.functor to one of the three classes one of three classes from the org.apache.accumulo.core.file.keyfunctor package: RowFunctor, ColumnFamilyFunctor, and ColumnQualifierFunctor.
Tip
Because seeks are specified for Accumulo in terms of a Range of keys, and not a specific key, the bloom filter layer will only provide improvements when the Range seeked only covers a single row in the case of the default RowFunctor, or a single row and column family in the case of the ColumnFamilyFunctor, or a single row, column family and column qualifier in the case of the ColumnQualifierFunctor.

Figure 10-9. Bloom filter
Caching
Each tablet server process holds two BlockCache instances, one for data blocks and one for index blocks.
These are caches in memory of individual compressed blocks of Accumulo RFiles.
Though compressed on disk, the blocks are cached uncompressed in memory and take up JVM heap.
The size of each cache is specified in bytes with the tserver.cache.data.size and tserver.cache.index.size properties.
When the amount of data stored in a cache exceeds its specified maximum size, the cache will evict its least recently accessed blocks. The cache roughly reserves a third of its size for blocks that have been accessed a single time and two-thirds of its size for blocks that have been accessed more than once. Blocks never need to be invalidated in a cache, because Accumulo’s RFiles are immutable.
The caches maintain counts including number of cache hits (block reads where the block was found in the cache) and total number of block reads, and Accumulo tracks this information and displays it on its monitor page.
Master
The master’s main function is to monitor the status of tablet servers and tablets and to perform tablet assignment and load balancing as necessary. The master can remove the ZooKeeper locks of unresponsive tablet servers, forcing those tablet server processes to stop. The master also handles administrative operations requested by users, such as creating tables or altering system or table configuration.
To find tablets that need to be assigned, the master continuously scans the metadata table.
Each tablet’s state is determined based on the loc, future, and last entries for that tablet in the metadata table.
If a tablet is not in its desired state—for example, if it is unassigned or is assigned to a dead tablet server—the master will assign the tablet by setting its future entry in the metadata table and by telling a selected tablet server that it should host the tablet.
A load balancer is used to select a server for the tablet.
The master uses tablet server status information to balance the load of tablets across tablet servers. If there are active tablet servers that cannot be contacted, or there are unhosted tablets, or either the master or any tablet servers are in the process of shutting down, the master will not perform load balancing. See “Load Balancer” for more information on how tablets are balanced.
The status information collected from each tablet server includes the last contact time and some tablet server–wide information such as OS load, hold time (the amount of time the tablet server has been stuck waiting for minor compaction resources), number of lookups, cache hits, and write-ahead logs that are being sorted. Per-table information is also provided, including number of entries; entries in memory; number of tablets; number of online tables; ingest, query, and scan information; and number of minor and major compactions. If the master cannot obtain the status of a tablet server repeatedly, the master will request that the tablet server process halt.
The master is not a single point of failure, because Accumulo can continue running without it. However, if the master is down for too long, the tablets can become unbalanced, and if tablet server processes go down while the master is down, their tablets will not be reassigned.
Multiple masters can be configured, and they will create a queue of locks in ZooKeeper. If the active master goes down, losing its ZooKeeper lock, the next master having a lock in the queue will obtain the master lock and become the active master.
FATE
The master performs a number of administrative actions on behalf of a user. These actions can involve multiple steps, such as communicating with a tablet server, reading or writing data in ZooKeeper, and reading or writing data to the metadata table. If the master fails without completing all the steps needed for a particular action, Accumulo and the client process could be left in an undesired state. For this reason, Accumulo introduced a fault-tolerant execution system, FATE, to ensure that multistep administrative operations are made atomically—either all the steps succeed, or the original state of the system is restored.
A FATE operation breaks down an administrative action into a set of repeatable, persisted operations—objects that implement the Repo interface.
Each Repo must have the same end state when executed more than once, even if it has been partially executed previously.
It also should be able to undo any changes it has made.
On successful execution, a Repo returns the next Repo needed to continue the action.
Before a Repo is executed, it is stored in ZooKeeper along with a transaction ID associated with the FATE operation.
If the master goes down in the middle of performing a FATE operation, the next master that takes over will be able to continue the operation or roll it back based on the information recorded in ZooKeeper. The actions currently managed as FATE operations include bulk import, compact range, cancel compaction, create table, clone table, delete table, import table, export table, rename table, and shutdown tablet server.
Load Balancer
The load balancer that the Accumulo master uses to assign tablets to tablet servers is controlled by the master.tablet.balancer property.
The load balancer is responsible for finding assignments for tablets that are unassigned, at start time or any other time unassigned tablets are discovered (such as when a tablet server process goes down).
It is also responsible for determining when the tablet load across tablet servers is out of balance, and determining which tablets should be moved from one server to another.
This is called migration or reassignment.
If the default TableLoadBalancer is used, you can set a different balancer for each table by changing the table.balancer property, which defaults to the DefaultLoadBalancer.
Balancing each table independently is important, because otherwise a table’s tablets might not be evenly distributed, even if each tablet server is hosting the same number of tablets.
The DefaultLoadBalancer attempts to assign a tablet to the last server that hosted it, if possible.
If there is no last location, it will assign the tablet to a random server.
When determining whether tablets need to be reassigned to keep the tablet servers evenly loaded, the DefaultLoadBalancer looks at the number of online tablets for each server.
If there are tablet servers that have more and less than the average number of online tablets, this load balancer will move tablets from overloaded servers to underloaded servers.
It picks a pair of tablet servers, starting with the most loaded and least loaded, and moves the smallest number of tablets necessary to bring one of the two servers to average load.
When the DefaultLoadBalancer decides to move a tablet, it first decides which table the tablet should come from.
If the higher-loaded server has more tablets from any given table than the less-loaded server, the balancer picks the most out-of-balance table.
If none of the tables are out of balance, the balancer picks the busiest table (as defined by ingest rate plus query rate).
Once a table is chosen, the balancer selects the most recently split tablet from that table.
It repeats the tablet selection process until it selects the desired number of tablets for migration.
Garbage Collector
The garbage collector is a process that deletes files from HDFS when they are no longer used by Accumulo. This is a complex operation because a file can be used by more than one tablet. Early incarnations of the garbage collector compared the files in HDFS with the files listed in the metadata table. Prior to 1.6, the garbage collector still has the option to be run this way if Accumulo is not running and has been shut down cleanly. However, when Accumulo is running this method is not sufficient because files must be put in place before their metadata entries are inserted, with the result that the metadata table is expected to be slightly behind what exists on disk.
To address this issue, there is a section of the metadata table that records candidates for deletion. If a tablet doesn’t need a file anymore, it writes a deletion entry for that file to the appropriate section of the metadata table. A tablet no longer needs a file if it has performed a compaction that rewrites that file’s data into a new file. Major compaction, full major compaction, and merging minor compactions all result in files that can be deleted.
The garbage collector reads the deletion section of the metadata table to identify candidates for deletion. Then the garbage collector looks to see if the deletion candidates are still in use elsewhere, if they appear as file or scan entries for any tablets, or if they are in a batch of files that are currently being bulk imported. After confirming the candidates that are no longer in use, the garbage collector removes those files from HDFS and removes the files’ deletion entries from the metadata table.
The garbage collector also deletes write-ahead logfiles that are no longer being used. Rather than using deletion entries to find candidate write-ahead logs for deletion, the garbage collector finds files in the write-ahead log directories, then determines if they are still in use.
Accumulo can run without the garbage collector. However, when the garbage collector is not running, Accumulo will not reclaim disk space used by files that are no longer needed. As with the master, multiple garbage collectors can be configured, and the inactive garbage collectors will monitor a ZooKeeper lock, waiting to obtain the lock in case the active garbage collector fails.
Monitor
The Accumulo monitor process provides a web service and UI for observing Accumulo’s state. It connects to the master and the garbage collector processes via Thrift RPC.
The monitor is not essential for running Accumulo, but it is a useful tool for observing Accumulo’s status and learning about any issues that Accumulo may be having. Currently Accumulo only works with a single active monitor process. If a second monitor is started, it will wait to take over in the event the first monitor fails.
One of the most useful features of the monitor is that it can aggregate log messages from all Accumulo processes.
By default, WARN and ERROR messages from all processes are forwarded to the monitor, which displays them under Recent Logs in its UI.
This behavior is configurable in the generic_logger log4j configuration files.
Tracer
Accumulo includes a distributed tracing functionality based on the Google Dapper paper that makes it possible to understand why some operations take longer than expected. This tracing functionality captures time measurements for different parts of the system across components and different threads.
Tracing is optional. To enable tracing, one or more tracing processes are started to capture tracing information from Accumulo client and server processes using Apache Thrift RPC. If no Accumulo tracer processes are running, tracing will be disabled. The start-all script will launch one tracer process for each host defined the ACCUMULO_CONF_DIR/tracers file. Usually one tracer is sufficient to handle the tracing data for even a substantial Accumulo instance.
One trace is defined as a series of spans that have timing information for a specific operation. In addition to start and stop times, each span has a description and IDs for itself, its trace, and its parent span if one exists. Clients that want to use tracing must enable it for an application and then start and stop traces for individual operations (see “Using Tracing” for an example of enabling tracing and retrieving the results). When tracing is started, or turned on, each span associated with a trace is sent to a tracer process chosen at random from the list of tracers that have registered in ZooKeeper. Spans are received by each tracer asynchronously using Thrift RPC and inserted into the trace table in Accumulo. When the client operation being analyzed is complete, the client should turn tracing off, at which point any remaining spans from previous asynchronous calls will be inserted into the trace table. The complete trace information can then be retrieved from the trace table through the Accumulo shell or monitor page.
Accumulo server processes also use tracing to obtain and log information about their internal operations. Operations traced by Accumulo include every minor and major compaction, as well as 1 out of every 100 garbage-collection rounds.
Client
Accumulo clients communicate with Accumulo server processes in a variety of ways.
Information such as the instance ID, instance name, master locations, tablet server locations, and root tablet location are retrieved by the client directly from ZooKeeper.
Whenever the client retrieves information from ZooKeeper, that information is cached in the ZooCache.
If the same information is looked up again, the client will first check the cache.
When the client obtains a connection to Accumulo, it reads the available tablet servers from ZooKeeper and connects to a tablet server to authenticate.
The Connector can then be used to retrieve various types of scanner or writer objects for reading from or writing to Accumulo.
It can also be used to retrieve objects that can perform table operations, instance operations, and security operations.
The operations that can be performed with these objects are covered in detail in Chapter 4.
Locating Keys
When a Range is scanned, the tablet or tablets that overlap the Range must be located. When a Mutation is written, there will always be a single tablet containing the row ID of the Mutation, and that tablet must be located. The location of a tablet is the IP address and port of the tablet server that hosts the tablet. Tablet locations are stored in the metadata table, which itself is split into multiple tablets. So, the metadata tablet containing information about the desired tablet must also be located. The locations of metadata tablets are stored in the root tablet.
Note
Before Accumulo 1.6, the root tablet was a special tablet in the metadata table. In 1.6, the root tablet is in a separate table called the root table.
In fact, all the information about the metadata tablets is stored in a single root tablet that is never split. The root tablet location is retrieved from ZooKeeper, while all other tablet locations (metadata and not) are retrieved from the tablet servers hosting the root and metadata tablets. The client looks up tablet locations by conducting appropriate scans of the metadata table, but the tablet server’s Thrift API is used directly rather than going through the client scan API.
The location of the root tablet is cached in the ZooCache, while the locations of other tablets are cached separately.
The separate tablet location cache is not invalidated when a tablet is moved to a different server, but if the client looks for a tablet by contacting a tablet server that is not hosting the tablet, the client will remove the location from the cache and retry.
Metadata Table
The metadata table (along with the root tablet/table) is the authoritative source of information on the tablets and files for an Accumulo instance. The files for the metadata table are typically stored at a higher replication: the default is five replicas, rather than the default of three for other tables’ files.
See Appendix B for details on the contents of the metadata table.
Uses of ZooKeeper
ZooKeeper is used heavily by Accumulo for determining liveness of processes, coordinating tasks, ensuring fault tolerance of administrative operations, and storing configuration that can be modified on the fly without restarting Accumulo.
See Appendix C for details on the data stored in ZooKeeper.
Accumulo and the CAP Theorem
It has been well-argued that it is basically impossible not to choose to be partition-tolerant when designing a distributed system because, in a distributed system, some messages between servers will inevitably be lost (which is the definition of a partition in this context).
With respect to the CAP Theorem, Accumulo is a CP system, choosing consistency over availability during a network partition. Accumulo is designed to only allow writes for a particular key to one and only one machine. Some other distributed databases allow writes for a particular key to happen at multiple machines, and they choose to replicate these writes between servers as fast as they can.
Accumulo is also designed to run within a single data center, which means it operates over a local area network (LAN) rather than a wide area network (WAN) spanning multiple data centers that are geographically distributed. In a LAN, network partitions can still occur in which some tablet servers cannot talk to other tablet servers or—more importantly—to ZooKeeper. However, when this happens the tablet servers that cannot talk to ZooKeeper cannot guarantee that they are the only server hosting a given tablet, and so they exit to avoid receiving writes and creating an inconsistent view of a tablet.
From Accumulo’s perspective, if a server isn’t responding to ZooKeeper (meaning it has let its tablet server lock expire), then the server may be down or it may be running and just unable to talk to ZooKeeper. So the master has a dilemma. Because the server might be running, Accumulo could allow any clients that can talk to the tablet server to continue to read from and write to it. Because there is no other place accepting changes to the tablets hosted by this tablet server, there is no problem with consistency per se. But because it is impossible to distinguish between the server being down and being unable to communicate with the ZooKeeper and master servers, tablet servers are designed to exit so the master can assign their tablets to other tablet servers that can still talk to ZooKeeper. This ensures that the tablets are available to clients and that there is only one place where a particular key can be modified.
This process takes only a few seconds or less depending on how the cluster is configured.
Any clients that cannot talk to ZooKeeper will be unable to perform any reads or writes. This amounts to a lack of availability. In a single data center, populations of client processes will not have much difference in how well they can connect to servers, as compared to client processes around the world talking to servers in multiple geographically distributed data centers. Many installations perform load balancing across clients and if for some reason some population of clients is unable to service requests, the load balancers will try to redirect requests to healthy clients.
This is different from systems that choose availability and partition-tolerance (AP) but not consistency. These systems are often designed to be run over machines in multiple data centers, separated by WAN links. These links may cease functioning for some period of time, resulting in a network partition. Even when they are functioning, the difference in latency between connecting to a machine in a near data center versus a machine in a faraway data center can result in clients attempting to talk only to machines in the near data center.
In this scenario clients can write a value to a particular key in either data center, whether the WAN link is functioning or not, and can read the value of the key from either data center. The values of these keys can be the same, but if the WAN link is down or if a read occurs after a client has written a new value in the far data center but before that value has been replicated to the near data center, the client talking to the near data center may read a stale value. Eventually, when the WAN link is back up or when enough time has passed for the new value to be replicated to the near data center, all clients will see the newest versions of values for all keys, giving rise to the term eventual consistency.
Because clients can write to the same key at multiple data centers, and because these databases are frequently distributed across data centers with high-latency WAN links between them, even when the WAN links are up some stale reads are possible because replication latency is always present and limited by the speed of light.
Because there is essentially no opportunity for data to get out of sync in Accumulo, it chooses consistency. Therefore we call Accumulo a CP system, because it can continue to operate in the presence of partitions, but not all clients can perform writes to machines on either side of a partition.
The crucial decision for distributed database designers is whether to design their databases to be globally distributed or highly consistent. Accumulo is a highly consistent, single–data center application.
1 See Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil. “The log-structured merge-tree (LSM-tree).” Acta Inf. 33, 4 (1996), 351–385.
2 For general information about bloom filters, see Burton H. Bloom, “Space/time trade-offs in hash coding with allowable errors”, Communications of the ACM 13, 7(July 1970), 422-426.