
Autumn had been a train wreck of a season, no question about it.
Ben has suffered a high-level defection, losing a very capable professional that would be tough to replace. The team is drowning in support costs for a creaky set of undocumented legacy systems. And that vital connection with his business customers and his IT/Operations partners is fraying at the edges. The chasm between the developers producing code and the people supporting that code seems to be growing bigger by the day, with constant sniping and nasty politics undermining any hope of cooperation.
As bad as things are looking, they still have some advantages. Ben’s team is still able to crank out work thanks to their now instinctive work pattern of daily scrums and honest retrospectives. And most of the tension and drama is being kept external to the team; everyone is drawing together tightly in a circle, guarding each other’s back. Ben is proud of his team’s cohesion under attack; they were an oasis of sanity and demonstrated a strong commitment to getting better.
It’s a new season though. Winter is a time of new beginnings, for gathering strength. Change is in the air for the team…
A Fishing Trip (Ratcheting Change)
January brings some of my best days of the year. When the rains come and drenches the streets of Hillsboro, and the gray clouds lower and shadow the faces of morning commuters, I know steelhead are starting to make their way upstream along the Pacific coast. I start to compulsively watch the river levels online and the fishing reports for a telltale spike of flow that could bring with it a strong pulse of fish.
Soon enough, there’s a spike on one of my favorite north Oregon Coast rivers near the town of Tillamook, but I’m too slammed to make a getaway. Sure enough, I get the dreaded gloating phone call that afternoon from my friend Dean. “I pulled in yesterday about one in the afternoon, the parking lot was empty, and the water was the color of my morning chocolate milkshake. But, I decided what the hey, and stopped by a few hours later. Let me tell ya – I think I had three fish hooked in the first 15 casts! Big, bright fish – they looked like bars of aluminum.” Dean chuckles. “And it’s just going to get better, that nice emerald green water... It’s going to be so good tomorrow, we’ll have to put bait on behind the bushes, or they’ll come out of the water and BITE us!”
That was all I needed to hear. The next day, I was on my way west, leaving at 3 in the morning to meet Dean at one of our favorite bankside spots. The clock on my truck was just ticking over to 6 a.m. when I pull up to the parking spot. There was still a light rainfall that dampened my shirt as I hopped out of the truck and began pulling on my waders. I make sure my Simms waterproof backpack and two fishing rods are in the boat and all rigged up and ready to go, and we slide the boat into the inky black water.
The espresso I’d picked up from a roadside stand is warming my tummy pleasantly, and I can feel my heart pounding with anticipation as we slide down into the first run we’ll be working. We are just in time. The light was just starting to come into the valley – it was still thirty minutes until the sky would lighten to a ghostly blue-black and I could start casting. This was a bad year for returns but my timing could not have been better – right after a heavy storm, the rain had scoured the river bottom clean of leaves and debris, and I was confident there were dozens of fish moving upstream to complete their life’s cycle and spawn. With luck, I will be able to limit out early and bring home some fish for the barbecue.
If only wishes were fishes. After 2 hours, I had succeeded only in losing gear to the greedy river bed. The cold is starting to seep into my bones, and I could feel my casting gradually becoming robotic. I was going “on tilt” – mechanically thrashing water dozens of times, reeling in impatiently, hopelessly going through the motions. Unfortunately, my fishing partner is doing far better today than I am, with two already caught. One was a smaller nickel-bright hen, but the colored-up buck was a real trophy – easily 16 pounds, and more than 3 feet in length. Dean is grinning ear to ear as he tells the story of the line just barely hesitating after his cast; he’d slightly lifted the rod and felt that slight telltale pressure, then set the hook.
The standard, cliched line on the river was “the tug is the drug,” yet it was true – that feeling was better than any amphetamine. The fight of a great fish is electrifying and – perhaps because it comes so rarely – can be remembered and retold for years. Dean had to chase the fish downstream after it had neatly wrapped the line around a large rock below the tailout of the pool where it had been hooked. After having to wade out to his waist in the icy water to free up the line from its snag, he reeled in – and miraculously, the fish was still hooked. It was an epic battle and the fish had nearly taken all his line as it thrashed the surface and fought him up and down the creek, but after 10 minutes, Dean was able to tire the giant out and smoothly sweep it into his net.
That evening in the grimy, smelly trailer that we had stashed at a friend’s place near the seaside town of Rockaway, Dean’s teeth gleamed as he talked about how the fish had thrashed about wildly, leaping into the air and twisting its body several times. The strength and beauty of these fish was always breathtaking.
I feel a familiar wave of admiration tinged with a little envy at my friend’s focus. I remember his hand moving almost imperceptibly as the rod slowly sweeps downstream in an arc, the tip twitching like the antenna of a predatory insect. The slightest move or hesitation of the line, and that hand comes up sharply as he brings the line tight and sets the hook. More often than not, the rod bends into nearly a half circle as it bucks under the heavy weight of a very surprised and angry steelhead.
The worst humiliation had come late in the day. Dean had stepped in behind me just as I was leaving a run – one of our favorite spots, a little greasy table-sized patch of slower moving water between two fast current seams. I thought he was wasting his time; I’d thrashed it for an hour with not a nibble. Not even 3 minutes later, I heard a whoop – and sure enough, upstream there was a spray of water and a huge splash as a monster steelhead – the biggest of the day – thrashed and jumped into the air, Dean in hot pursuit. My pocket had been picked.
Fishing had been challenging today and I noticed that most of the fisherman had gone home empty-handed, like me. Small comfort that was, as I watch Dean neatly fillet his fish and slide the carrot-red strips of flesh into Ziploc bags for the freezer back home. As a good friend and longtime fishing buddy, Dean limited himself to just a couple comments about me “needing to use a hook next time” and some helpful hints about me “not pulling your own weight.” I feel, as always, a little outclassed; Dean had been a fishing guide for 20 years, still fished almost half the year, and had an almost supernatural ability to snuffle out and hook fish in the worst of conditions.
I grump out some compliments sprinkled with a few comments about a certain blind squirrel finding some random nuts to balance things out as the we close out the evening with a few cocktails. Swallowing a little pride, I finally ask Dean what I’d gotten wrong today.
“Well….” says Dean, staring into his second cocktail, swirling the golden whiskey around in his coffee cup to hear the ice tinkle. He's in a classic Old Man of the River mood. “You know, you’re a good fisherman and you’ve come a long way... Usually, you’d have caught something on a day like today.”
“Yeah, I’m a good fisherman, just not great.” It eats at me, but I have to admit it – Dean was simply on another level.
Dean chuckles again. “That takes practice. Probably more time than you have at your age and with your career.” He takes a long sip from his cup, beaming in satisfaction. “I’ll tell you one thing I noticed – you weren’t in it today like you usually are. You just seemed to be on remote control. The fish can tell, man. I’d say on most of your drifts, you weren’t even close to being in the zone – I looked over a few times and your yarn was right on the surface. There’s not a steelhead alive that will bite that.”
“What about at that river curve, when you came behind me and pulled out that nice fish? I’d beaten the crap out of that water!”
“Yep… I noticed you were there a while. What do you think I did that you didn’t do?”
I shrug again. Dean takes another long sip and leans back in his camp chair, adopting a professorial tone. “You needed to adjust your approach, man. You didn’t have enough lead on your line – you were fishing too light to get on the river bottom, so you never even gave the fish a chance to bite. And, one thing you’ll notice, I’m always changing things up. I’ll try eggs for five minutes – then if that doesn’t work, I’ll cut over to a yarnball, or a bead under a float. Two weeks ago on the Trask for instance, I hammered this one spot for like ten minutes, and then – I clipped off the bead under my float and put on a nightmare jig. First float through, bang! A big hatchery buck fish grabbed my line and took off for the Pacific. I didn’t think I’d ever land that one.”
I know what he’s talking about. A lot of times, success or failure in fishing just came down to persistence and time on the water. I am a good fisherman, and I catch more than my fair share each year – but to be great, I’d have to learn to stay sharp, be ready to try new things, and not zone out and become complacent. Dean was always laser focused and was constantly changing things up.
“Just remember, I’m just like you,” says Dean, putting a comforting hand on my shoulder and looking sympathetically into my eyes. He breaks into a grin: “Only successful.”
The next day after the daily standup, Kevin asks me how fishing had was; it’s a dreary story of failure that I hastily cut short once I see eyes glazing over. Kevin though has done some fishing in the past with his son, and can relate. “Been there, man. That’s why they call it fishing, not catching…” We both laugh.
The next day as we are wrapping up our daily scrum, I get groans as I start to say, “You know, DevOps is kind of like…” Alex fakes slipping into a coma and collapses over his keyboard. “For God’s sake, ANOTHER DevOps metaphor? Let me guess, it’s like ballet, right? Or a tractor?”
I have to laugh. There’s something about DevOps that seems to pick up metaphors like lint. But I forge ahead anyway: “As I was saying… the takeout was really nasty yesterday, because it was low tide. So we had to winch the boat up at the takeout as the bank was at a really steep angle. I will tell you honestly, we never would have made it without the ratcheting winch we had on the trailer.”
Some really lucky people have an electric winch on the front of their trucks; we had a manual winch that required a little elbow grease to get the boat up the slippery hillside to the trailer. But without that beautifully simple mechanical design, we never would have made it up the slope. There was a clicking sound as we turned the handle of the winch; with each click, a spring-loaded metal finger or pawl slid into a groove between the teeth of the round gear being turned. We could stop and take a break whenever we wanted; as long as the pawl was engaged, the gear couldn’t roll backward.
Looked at linearly, the gear travel could have looked something like this:
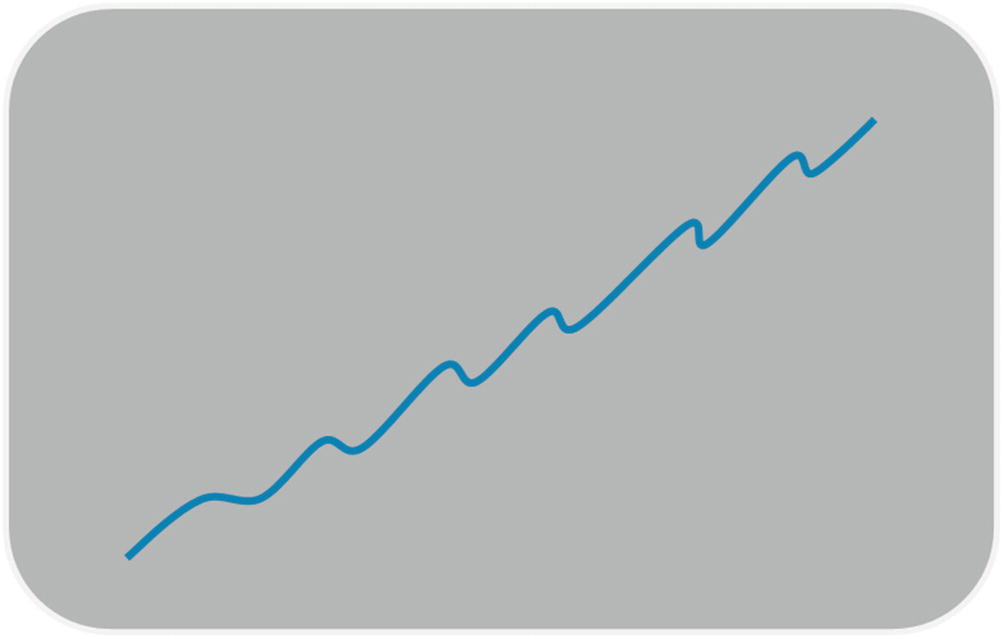
I sketch this on the whiteboard and turn to the team. “All the pending work and improvements we’re thinking about kind of become like that hillside in my mind sometimes – indomitable, vast, endless challenges. If I stare at it as a single block, it’s an impossible, overwhelming task, and I start to feel stressed and overwhelmed. But I keep going back to that ratchet design . It’s mechanically beautiful, because it does one thing and does it well – allowing the application of force in one direction and one direction only. We knew that boat was going to make it up the hill. It might be one inch at a time, but that ratchet design prevented the boat from sliding back into the river.”
George sees where I’m going. “So, in your view, it’s OK if we slow down or even pause our rate of change. It’s all right to change in tiny increments – in fact, that might be safer. As long as we don’t roll back to where we started.”
“Yeah, that’s right. The military has a saying – “slow is smooth, and smooth is fast.” It’s obvious there’s change ahead for us, whether we want to prevent it or not. But the surest way to not meet that challenge is to try to change everything at once. We need to take this nice and slow, one tooth of the gear at a time. But if we find something to be of value in the team, we can’t allow ourselves to drop it because there’s a new crisis du jour. We keep our standards consistent and reasonable, and gradually inch our way forward.”
I get some bemused looks, and at least half the team has stopped listening; it’s time to move along. But I remember that winch in the months ahead, and I’m very careful about how I position DevOps. In fact, usually I don’t even mention the word; we stick to generic executive-friendly terms like delivery of business value, flow, and elimination of waste as our buzzwords. Going around preaching DevOps as a revolutionary concept is threatening and risky. Instead, we try to take a more experimental approach, one tiny evolutionary step at a time.
The Worst Form of Laziness (Kanban)
A few weeks go by, and we’re halfway through the team retrospective; our Kanban board was open, and Alex was checking on the status of one of the features that Padma was working on for HR. As usual for Padma, she was almost frighteningly competent – tests were complete, unit tests created, delivered to production, and the users had looked it over and given it an enthusiastic thumbs-up.
The Admin screens, surprisingly, ended up being the hangup. Harry looked up as Alex was moving the task through to “Done” and said, “Oh, so that means unit tests are written, right? I don’t remember a code review either.”
Padma grumbled at him, “Harry, you know very well there wasn’t time this sprint for that. We got this request right before the sprint began; the idea is just to throw a detail screen out there for admins to update user login information. Nice and simple. It’s internal facing only – not anything the customers are going to see. We can add unit testing – even if it’s of value, which I doubt – to a future sprint.”
Harry’s chair creaked as he leaned back and crossed his arms over his bulging midriff. “Padma, it’s like being pregnant. Either you’re done or you’re not done. It’s binary. If you don’t have any unit tests, you’re hurting the team scoreboard, and setting a bad precedent. Sorry, we can’t take this off the board yet, and it can’t be cleared for release. Let’s try again in two weeks.”
Padma’s jaw gaped. “Are you serious? The customer – HR, I’ll remind you, they produce your paycheck Harry – wants this functionality done. I still haven’t heard a good reason why we’re being nitpicky on an internal-facing detail screen. This is a MVP effort Harry – minimum viable, right? So the emphasis is on getting something out the door quickly, not trying to nail down every detail.”
Alex jumped in. “Padma, I hate to say this, but I think Harry’s got a point here. It’s true that we love prototyping and MVP’s, but the word ‘viable’ there means it meets our standards. We got into this hole through expediency, remember? We always deferred testing and quality always took a back seat to making our dates. We can’t just assume that we’ll get to this later. To me, I don’t think this task is done yet.”
Padma’s chin was jutting forward. “Look, sit on this if you want. But to me it’s a little unfair that you’re coming in last second and holding up a release based on a ‘tested in production’ type requirement. You didn’t ask that of Ryan a few weeks back with his app, and he was working with something that was a lot more sensitive. I don’t get why I’m being held to a higher standard here – it seems petty.”
Alex looked around the room – “Padma, I get where you’re coming from. I wouldn’t like it if I was given a higher bar to clear than others on the team. It seems to me though that the problem isn’t a personal one – you’re one of our best coders we’ve got and your work is always top-notch. I think the core issue is that our process is inconsistent, and our rules are unspoken. I mean, we’ve never really had a team definition of done. Is this a good time to talk about this as a group?”
Heads nodded in agreement around the table; they’d batted around the idea of a formal definition of done for some time. I was glad this was coming up as a topic. After some discussion, they decided on something simple – “Done” for the team meant that unit tests were written, their functional tests updated, the changes were peer reviewed, and it was tested in a production-like environment.
Harry objected. “We’re missing the point, guys. We could get faster releases and much better testing if we adopted feature flags, like I’ve been saying. That decouples the release of code to when features are actually turned on for our end users. And it means we can roll back with a toggle.”
Alex and George looked at each other; George slowly said, “I love the concept of feature toggles and I really want to explore it, Harry, you know that. Everything you said makes sense. But, that’s separate from this discussion. It’ll take time to prepare the ground and get signoff from our end users on this new way of releasing; I know for a fact HR isn’t going to love the idea of using our end users as guinea pigs if we’re testing in production. For right now, it’s just a bridge too far. Can we nail down a single definition of what ‘done’ means first before we mix in new release strategies?”
Harry grouched and moaned, but eventually the group conceded George’s point and moved on. I’d been sitting in the back of the room observing the conversational badminton match and decided to launch a volley of my own. “People, before we move on, can I ask a question – Padma, how did that task get on the board for this sprint?”
Padma replied, “Well, it seemed like I had plenty of capacity – a few free days at the end of the sprint. When my contact came to me before the sprint with the ask to bump this up in priority, I thought it was a good decision to scoot it forward.”
I said, “That’s awesome! Really good responsiveness and it shows a commitment to a quick turnaround. But looking at the backlog and what we committed to this sprint, didn’t you feel a little pressured?”
“Comes with the territory,” Padma laughed. “I had to put in a few late nights because our authentication model changed, and the COTS gridview component we used ended up having some performance issues that we couldn’t fix. So yeah, it took longer than I wanted, but the customer is happy – which is all that matters.”
“OK, so now I want to widen this – Padma this isn’t about you specifically. But we’re now saying things are either ready for a production release and tested – or they’re not ready, and it gets kicked forward. So I’m taking two things away from this discussion, and I’ll put it in the notes.
“First off, and Elaine this will especially interest you, I think we need to split up what we deliver even finer. We can’t have more of these bowling ball requirements , where they’re large sized and impenetrable. We need to commit to much less if we’re truly saying ‘done means DONE’.
“Second, I think we need to put a cap on what we’re delivering. What would happen if we capped our WIP in the Kanban board, so only 3 tasks could be worked on at a time?”
The group started to laugh. Alex said, “Ben, look around – there’s only 7 people here in the room. Just some basic math here, but if you cap our WIP at 3 active tasks, you’re handicapping us. We’ve got about 30 tasks to do every sprint; there’s no way we can get it all done and we’ll have people sitting around doing nothing all day. I don’t think you want that.”
I said slowly, “Correct me if I’m wrong here, but I don’t think the business loves us for overcommitting and underdelivering. I was talking to Lisa in HR – she loves you Padma, by the way – but overall she gave us a very low grade when I asked her if we follow through on our commitments. I hear that from Footwear and a few other of our customers as well.
“This isn’t a criticism of anyone here. In fact I’m commending you – you’re taking on a ton of work and it shows with our velocity. But 60-hour workweeks and heroic efforts to push something out the door aren’t sustainable. So I’m going to ask again – what would it look like if we capped our active tasks at 3?”
George looked shocked, and his brow was furrowed. “Looking at this last sprint, that means we only would have delivered about half our value. Like Alex said, you’d be crippling our velocity.”
Now, it was my turn to laugh. “I’m not doing anything. I’m asking a question, it’s up to the team to decide. Using the last sprint as an example, did we take on too much?” Looking around, he smiled – most people, Padma and Harry excepted, were nodding their heads vigorously. “I haven’t asked, but I’ll bet one of the first things we threw out was that 20% time we’ve asked you to use for improving our capacity and maturity. That’s our seed corn – we’re falling back into bad habits. So – if we capped our WIP at 3 – let’s say we produce half the work we did last sprint. But most of those tasks that we’ve moved to ‘Done’ really aren’t done are they for this sprint – there’s a lot of carryover work that is spilling into the next few weeks. So I’m thinking, we may do less, but what we do deliver will be bulletproof.”
Alex started to smile. “You know, that may not be such a crazy idea after all. I mean, we could try it. Padma, you started talking to us months ago about XP programming and pair programming . We keep saying we’re going to do cross training but when it comes right down to it – we never seem to have the time. And that means, if there’s a problem with the HR app, we have to go to Padma. She’s the owner of the code, and no one else can fix it. That’s a huge limiting factor for us.”
Instituting the cap limit – once the team was in consensus that they’d try it as an experiment – took a few sprints to settle out. Despite Harry’s dour predictions of locust plagues and fired developers due to chronic laziness, the team found that the really important things were getting out the door more reliably. In several projects, their stakeholders noticed they were doing much better in delivering on their commitments. In other projects, having people in a waiting state caused some visible pain, exposing some problems with tasks being handed off either incomplete or needing to be redone; these were discussed in the retrospectives and improvements folded into the delivery cycle. And during standups, they had people available – for the first time – that could hop on open bugs or blocking tasks in tandem, leading to much better thought out solutions.
It was one of those little things that ended up – as I looked back months later – making a huge difference. Capping their WIP, it turned out, forced the team to focus on only the most important things. Their pace after a few weeks seemed much less hectic, more sustainable. As George said just a few sprints after this, “We’re off the hamster wheel!”
Setting Up Base Camp (Version Control)
As always, demo day and the end of sprint seemed to be creeping up on us before we were ready. The team was about halfway through their bug list from the last release. As we go through our work items, I see gaps around the table; some of my people have been calling in sick lately. It looks like yet another failed sprint. I’m already dreading writing the retrospective showing the bleeding from our technical debt and how it was impacting progress against our backlog of work.
This afternoon though looked to be trending up a little. The to-dos on the whiteboard continue to mock me; we decided that getting our version control in shape would be our first target. I hosted a brownbag for the team on the subject, with Erik presenting his findings and recommendations. Surprisingly, we get nearly a full audience – perhaps, the free pizza helped.
I splurged for this event with lots of hot pizza pies and Caesar salad from Pizzicato, one of our faves. I love the Roma pie, with the fennel-saturated homemade sausage, red onions, and roasted peppers. Load it up with parmesan and hot peppers, and it’s heaven. We’re a happy group of locusts now, and everyone is settling comfortably into their chairs as Erik gets his laptop out and starts up his presentation.
“So, you guys asked me to do some work on version control. To me, this is the base camp of software development – if we can’t get version control right, we’re dead in the water.
“One of the main goals of continuous delivery is the ability for us to deploy and release any version of our software, to any environment, using a fully automated process. People often look at that and think, ‘oh, automation!’ – and start to think about Chef or buying some release management tool. But application code is just half of the puzzle; the other piece we often forget about, infrastructure. That’s basic housekeeping – we need to have everything in version control. That’s everything we need to build, deploy, test, and release.
“As you all know, we’re not there yet. We’ve already identified as a major cause in many of our recent tickets that manual fixes were happening in our environments, which don’t match each other. And for code – some of our apps have been patched in production. We had two outages in the past three months just because changes we made to fix something in config didn’t get rolled back to our other environments or show up in version control. So, the same issue cropped up again in the next build, and it cost us several days to find and reapply the change.
“My recommendation is that we take care of some basic hygiene and make sure we finally have version control that’s complete. An authoritative source of record for everything we need. That includes our infrastructure and everything supporting the application. And this needs to be living and enforced – we use this as a base for any release candidates. And any hotfixes use the same repository as a source, and the same build process – no more shortcuts.
Harry, predictably lounging in a dark corner in the back of the room, has his arms folded. “Hey, I’m not arguing any of this, especially for our web-based projects. But like I keep saying, 90% of our stuff doesn’t fit in that bucket. We’ve got a lot of legacy applications – some are in COBOL for God’s sake. Our mainframe deployments don’t fit in that space either. I just don’t see any need for us to launch on a major rewrite effort when we’ve got bigger fish to fry. I mean, I was here till 11 last night trying to clear the decks – we just don’t have the time for this.”
Jeff, one of Harry’s closest friends on the team, chips in. “Hate to say it, but Harry’s right. We’re all scrambling and worn out. And it’s not like we don’t have and use version control here. Maybe it’s not perfect, but it shouldn’t be the priority for us right now.”
My head snaps up – I’m out of my pizza-induced stupor now. “Guys, let’s hold on here before we start playing Whack-A-Mole. Erik, I’m struggling to get where you’re going here. Jeff is saying we do have version control; you’re saying we don’t. You guys can’t both be right.”
Erik rubs his jaw and laughs shortly, then says, “Most of the outfits I’ve worked at say the same thing – ‘oh sure, we use version control’. That means their app code is stuffed into a repository somewhere – but it’s incomplete. It’s not used as the source of record when there’s a hotfix, and what’s in production has been manually tweaked to where it diverges from what’s supposed to be our canonical build source. In other words, it’s an artifact – and an untrustworthy one.
“For example, George, let’s take the Footwear app. Next Monday let’s say you have a new programmer coming in and she’s sitting in my chair, with a brand-new workstation. Can she check out the project’s source code, make a single change, and deploy it to any environment he wants? Let’s say that our QA environments suddenly evaporate. Can he rebuild it using only what’s in version control? Including the OS, patches, the network configuration, OS binaries, and the app config?”
There was an uncomfortable silence; Footwear was a relatively new app, but only the application code was in version control. Builds were manually created and handed off to Operations as a package or executable. And hotfixes were usually manually applied, as there was a lot of variation applied as patches or configuration tweaks in production that didn’t show up in source control or in other environments.
It’s a sore spot, and George temperature raises a bit. “You know we don’t have control over that Erik. We’ve got what’s in our ducks in a row from a coding standpoint, and that’s our only responsibility.”
Erik says, “I’m not trying to snipe at you George, actually the Footwear app is further along than any of our other apps that we support in terms of completeness. But for us to reach base camp, we have to rethink the way we’re using version control and get more of our artifacts in there. At a minimum we need to think about systems configuration and app configuration as equally valuable as source code. We need to be able to answer these questions – I robbed this from Continuous Delivery – with a ‘yes’:

Henry scoffs. “Again, not all of our applications will support version control. And what you’re really talking about here is automated builds . You’re saying this will only work if we hook up version control to every build. You’re saying everyone needs to have full access to every environment, which is crazy, and we should have these godlike powers to roll back on a whim. Our security governance will never go for that, and we’d be stepping right on Operations toes. They’ll murder us. Operations doesn’t see the need for automated builds, Erik, like I’ve told you many times. They just want their WIX package or MSI installer and a script. We hand off the baton like a good boy at the 100-meter mark and” – he slaps his hands – “done, easy-peasy. We might not like it but it is the way things work here.”
I can see some red appearing at the base of Erik’s neck – a sure trouble sign. The last thing we need is the team tearing itself apart over what should be a very pat discussion over fundamentals. “OK everyone, Erik’s made a lot of effort here,” I interrupt just before Erik launches into a defense. “I think we owe it to him to at least listen respectfully. And is anyone seriously arguing that we need to improve with how we use version control?”
Even Harry keeps his head down with that question. I continue, “What I’m walking away with from this discussion is, we need to devote some serious effort to getting our quality under control, and that starts with version control. Right now, it can’t be trusted, and it isn’t complete.”
I can see Harry starting to object and decide to cut him off. “Harry, you’re making some good points – it’s true that we have a huge number of applications to support. It’s also true that we control only part of the build and release process. But it does seem like we’re impacted directly by a lot of bugs that are caused by environmental changes and patches we’re not aware of and that aren’t tracked anywhere. That’s a bigger governance problem that I think our friends in Security and Operations would want to get ahead of. And our releases keep running red, which means – though we’re using version control to create builds – that there’s gaps in our testing, and problems with how our environments are being created and our configurations maintained. Right now, no one seems to trust our build process or the environments it’s pointing to. I think it’s worth some time to address this.”
Harry isn’t done though. “Again, too much work, too few people. And it’s a bad fit for the type of work we do.”
George interrupts Harry before he gets a full head of steam. “Yeah, point taken. It’s a massive list of applications, and a vast amount of work. So let’s focus first on getting our code trustworthy, and then move on to environments and configurations. We already have a list of the applications we support, right? So, let’s use that as a starting point and do what my general contractors call ‘snapping a line.’”
Blank stares across the room. George patiently explains: “From that long laundry list of applications, I’m guessing most are static or less important. So let’s flag the applications that are actually generating a high number of tickets, the ones that have infrastructure that abends frequently, those that are most visible to the business. If we’ve got a hundred applications to support – well, that leaves 25 or so that we support frequently on a day to day basis. So to get our codebase in shape, we snap a line. We take what’s in production, match it up with what’s in source control, and overwrite VC if there’s a mismatch.”
There’s some static, and Harry continues sniping a little and prophesying doom from his corner, but – just as I predicted to George ahead of the meeting – there’s no serious resistance. Without a reliable source for our builds, we truly are stuck. Erik’s right – this is our base camp, and we need to make sure it’s in order before we tackle anything else.
As we wrap up, I tell the team that we’re going to keep this as a focus going forward. “This isn’t something we can dump on one person. I want us to spend 20% of every sprint getting source control up to speed. Harry has made a valid point – this is going to require some kind of agreement with Operations – that’s on my to-do list. We’re assuming that they don’t care about how we deliver work to them. I’m guessing they very much do.”
Selling the Plan
On the way back to my office, on impulse I take a sharp right turn and walk by Douglas’ office. Douglas keeps odd hours, and his calendar is usually booked wall to wall. Today, though, his office is empty – and he gives me a half smile and motions for me to come in.
We chat a little. Douglas’ passion was racing Miata racecars; he shows me some clips on YouTube from last weekend’s race. I can see the appeal; it was exciting watching from the helmet camera recording where the little car almost lost traction on sharp turns. It was a little too NASCAR for my taste though and definitely a hobby well above what I can afford.
Finally, Douglas gives me that half smile again and says, “So – have you given any thought to our discussion? You promised me a remediation plan.”
“Yeah, so let’s talk about that. I’ve had meetings with the team and I think we have some good ideas.” I sum up for Douglas some of the thoughts we’ve been batting around as a team, especially around source control. Then, I pause. “Listen, last time we talked, we got off to a bad start. You had just had Footwear and Operations climbing on your back about our team and just after a big push – the team and I feel like we’ve moved mountains and we’re not getting credit. That being said – it’s obvious there’s a kink in our hose somewhere. Value is just not getting out the door. I’m not sure exactly where it lies – maybe it’s the way we are gathering requirements and structuring our projects, maybe it has to do with our testing layer dragging us down. Maybe we are shooting ourselves in the foot somehow with the way we’re coding.
“But the main point you made with me was that we need to strengthen that bridge with Operations. After having sat through a very uncomfortable recap meeting with Emily and Ivan, it’s obvious we have some work to do there. Somehow, our push to go Agile is making things much harder on them. I’m not sure what the answer is there either, but at least we’re starting to get a good grasp on where that pain point is.”
“I was worried you’d be coming in here with a grand plan selling this magic word, DevOps.” Douglas says this with a sideways grin, like a racing champion holding up the trophy. “You know, I just can’t see that flying around here.”
“No, at least at this point, I have to agree. That being said, I’m giving the team some room to brush up and come to the table with some ideas to straighten out our deployment and quality issues.” Now’s not the time to dig in on terminology, and I’m not an evangelist.
“Douglas, it’s funny – we’re a clothing manufacturer. It’s not a field I know anything about. But I mean – look at us.” I grab my shirt collar. “I mean, I’m wearing WonderTek. You are too. We make good stuff – it lasts, it looks great. There’s a lesson there – somehow, our factories and suppliers figured out how to deliver consistency and quality at speed. From what little I know about Lean Manufacturing, this has been going on for fifty years. If the code we were producing had this same quality, we’d be made in the shade.”
“At last, we’re starting to see things the same way!” Douglas says with a gleam in his eye. “Ben, as you know, I started my career in the Army and I’ve never forgotten the lessons I learned there – in fact, I run my teams today based on the principles I was taught in my twenties. I look for discipline and loyalty – disagree with me all you want, but outside these doors I expect you to toe the line. That’s the biggest reason why you’re sitting in this chair now and not your predecessor – I’ve never caught you talking behind my back.
“That being said, I’m the only one that I know of with that kind of background here. Most of my peers and my manager come from the world of manufacturing, marketing, or have MBA’s. They understand Lean intuitively, it’s in their DNA. I’ve been in several meetings recently where our CEO has been talking about realigning along Lean principles, the way he got his Asian factories humming back in the mid 90’s. He expects us to perform the same way. If you’re talking Lean, then maybe we might have some common ground here. Anything else – frankly, it’ll just be seen as another delay tactic, an excuse so you can miss on your deliveries.
“What gives me pause though is that you say you don’t know exactly where the problem lies. If you don’t know now, after this length of time working for us, when will you know?”
I feel the hairs on the back of my neck stand up; looks like sword is still very much above my head. I hold Douglas’ gaze calmly though and reply, “I want to make this metrics based. We’ll take the last Footwear release as a case study. Once I go through each step in the process, I’ll know exactly where the problem is. And having it based on numbers means there’s no emotion, it’s objective. Not a finger-pointing exercise. So… one week from now?”
“OK. One week.” Douglas turns back to his desk but calls out to me as I walk out the door. “I look forward to seeing what you come up with. And make sure you invite Ops too. Good talk!”
I leave feeling like a condemned man who’s just gotten a call from the Governor. That was as good as it was going to get – now to get some kind of agreement set with Emily.
Nice But Not Nicey-Nice (Effective Peer Reviews )
I was one of the last ones into the team meeting room; Padma was at the board shuffling some of her notes. There was the usual few minutes of fiddling around with the projector, and finally the screen showed the following:
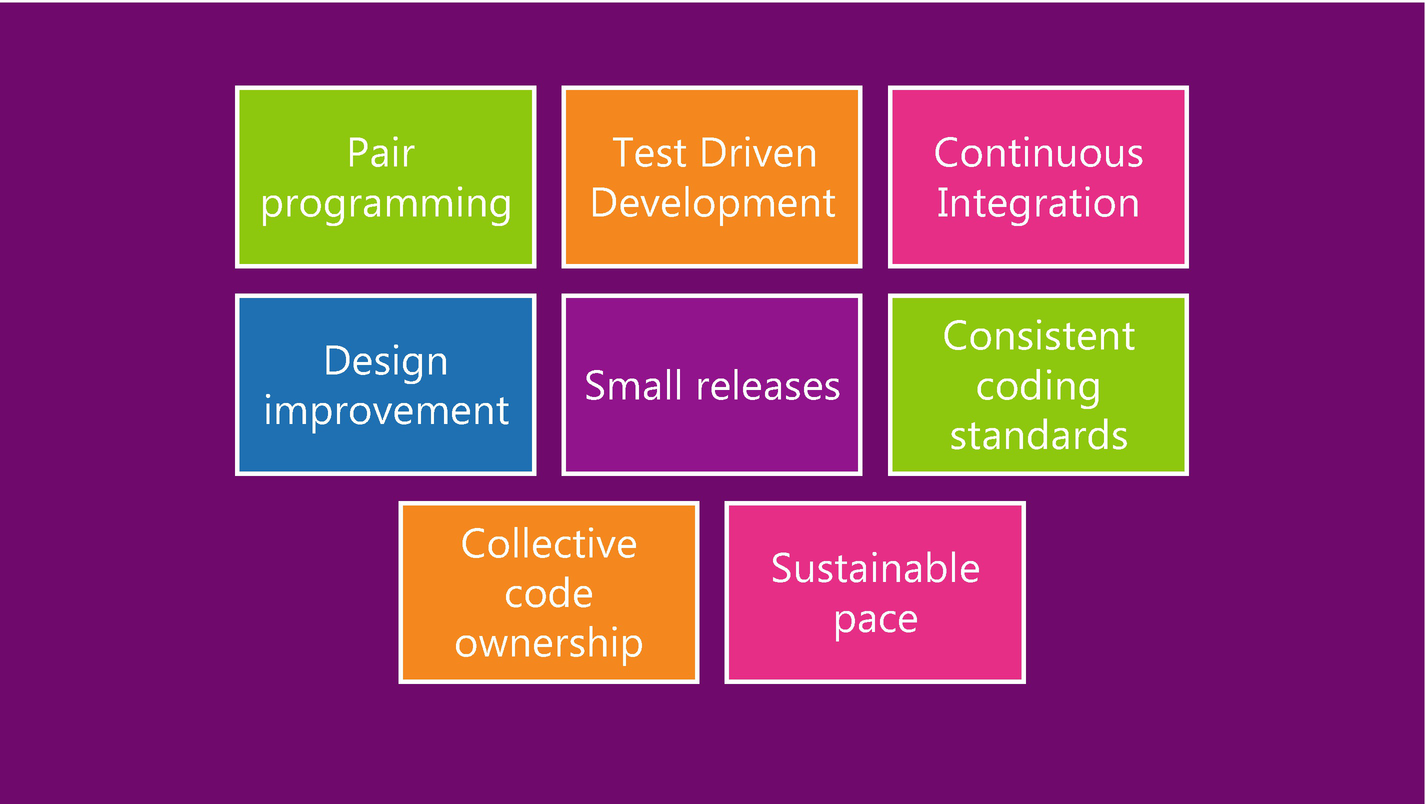
“My eyes!” George yelps. We laugh; the vibrant purple background is burning into my retinas. Padma rolls her eyes and snips, “I forgot I was talking to a bunch of middle-aged white dudes, sorry guys. Next time I’ll stick to browns and grays. Anyway – may I continue? – here’s the principles stressed with XP programming . You’ll notice there’s nothing here that is inconsistent with who we are as a team or where we want to go.
“Just for example, take the ‘design improvement’ item – that means you only build what is needed today, and refactor as needed. That eliminates a lot of wasted time gold plating work on features that are misunderstood or not needed. It also means the customer sets reasonable limits on what they expect and that they’re available to us at all times when we have questions.” This gets some loud snorts, but Padma soldiers on. “We rely on frequent releases to production and demo to our customer, then we work together on the fine tuning and adjustments we know we’re going to make.
“All of these things fit together. Just for example, if we used pair programming, we naturally start growing a culture that favors collective code ownership. The team is working together in teams, one person taking lead, the other person watching and learning, and suggesting improvements. So that second person now understands the system context, they’ve contributed to the code and helped improve quality; the next time, there’s a problem we don’t have just one person, and only one person that can help fix it. Once the pair is done with the work, you have a natural code review already done, and it can be released quickly as a single, small change out to where it can be reviewed by the customer. And we rotate the teams so everyone gains knowledge of the work we do as a group, not just our little piece of the puzzle.”
George says, “Padma, this is great and I know XP programming is great. It is a big change from the way we have done things as a team though – I thought we were just going to be talking about peer reviews.”
“Yeah, and I’ve done pair programming in the past,” Harry chips in. “Suddenly our productivity drops by 50% because we’re both chained to a single keyboard. And honestly, I don’t know if there’s enough breath mints in the world for me to share my terrible coffee breath, day in day out, with anyone.” A ripple of laughter.
I’m rubbing my chin; maybe, there’s something here that’s useful. “I think Padma’s on to something here. We just finished a major release beat down, and all of you put in hero type hours. But that’s just not sustainable – we’ll lose everyone here if we make that a habit. Is anyone seriously arguing that we want to continue with release after release breaking or putting us through hell trying to get it to work in production?”
George says slowly, “We just committed a big chunk of our time to getting our source control in gear, Ben. Do we want to change the way we code and release – at the same time? That seems like a lot to take on.”
From the faces around the room, I can tell George isn’t alone in his thinking. Padma says, “I wasn’t seriously proposing we implement everything on this list, all at once. I was suggesting that we put some of these on the list as things to explore, down the road, as an experiment. XP programming could be a game changer for us when it comes to development. It means we’re releasing in lockstep with the customers, small bits at a time. It means no more craftsman-type problems we have with our code – where each of us owns a chunk of code, and if we’re hit by a bus or get sick things have to wait. It means that our code is being reviewed early, like before check-in, so we’re catching bugs before they ever hit QA. Isn’t that where we are trying to go?”
A few smiles now. I can’t believe we haven’t put collective code ownership on our written list of team values yet. Padma’s right – I could think of at least three high-visibility outages recently because people were unavailable and “their” code broke.
George is shaking his head still. “Still too much change at once. Let’s say you’ve got one bullet in your gun, Padma. You know this team . What’s the target you’d shoot at?”
Padma answers immediately, “Peer reviews. That’s the most bang for the buck. I’ve worked on teams that have it as part of their standard process, and it’s amazing the difference it makes.”
“I’ve also worked on teams that used peer reviews,” Alex interrupts. “It just ends up being a code syntax beatdown session – a gauntlet less experienced developers have to run as the senior programmers beat the crap out of them in public. We don’t want that kind of negative culture happening here.”
“I agree, if we start going down that road it’ll make it harder for us to change things out of fear,” Padma answers, smiling sweetly. “A lot of companies enforce some kind of static code analysis on check-in, and that should be something to look into. But for now – we need to make sure it’s a part of our culture that someone, anyone, looks at our code before we check it in. That’s not a beatdown – that’s basic due diligence. If we really want to get ahead of our quality issues, it’s a have to have.”
George is starting to warm up to this. He says, “I don’t think this is going to add to our workload if we do it right. It’s just a change in the way we go about things. People can choose to work in pairs – that’s best practice, because it ensures we have multiple people that can help with the app going forward. Or we can choose to have someone look at our code and provide a signoff in our IDE before we check our code in. But either way, having someone do a peer review is fundamental, it’s hard to argue with that.”
Of course, we do our best to prove him wrong. There’s some grumbling and grim prophecies of doom muttered over the next 15 minutes, but in the end we decided to give this a try as a team – and check in after 2 weeks to see if it hamstrings us. I promise the team that if everyone decides pair programming is not effective, we’ll try something else.
What Isn’t Working Rising technical debt Untrustworthy VC repository Branch integration issues Code coverage dropping Business changing its mind Too many bugs – stuck in firefighting Bad communication pre-release with IT Long list of aging features Dependencies holding up releases Infrastructure creaky, inconsistent, difficult to manage Alerts and monitoring nonexistent | To Do Peer Review (Padma) Version Control (Erik) Code coverage and testing (Rajesh) |
Maybe Later Better teamwork with outside teams i.e. Ops Continuous integration & delivery Smaller releases Refining requirements gathering Paying down technical debt Infrastructure as code / a set of “golden images” | |
What We Value in our Tribe Open, honest communication – you will never get in trouble for saying the truth Collective code ownership Every line of code checked by a peer before checkin. (Peer review and/or pair programming) |
Easy There, Pardner
It was heading toward end of day; I reach for my iPhone and send Emily a quick message: You available? Ten minutes later, I’m in the cafeteria. The place was deserted, and all the staff had already gone home for the day. It was a perfect neutral ground for our talk.
We spend a few minutes talking about our teams and how things were going, and our plans for the weekend. Emily has been with WonderTek for a few years longer than me, which meant that at times there was just a hint of condescension; just teaching the new kid the lay of the land. Still, at least I get a hint of a smile every now and then, and a more-or-less honest dialogue. Anything is better than the postmortem battle royale both of us are still recovering from. Perhaps, just perhaps, there is something salvageable here.
Finally, Emily leans back and gives me a hard stare. “So, you wanted to talk. I think I’ve already told you how our group feels and I’m interested in what you want to do to fix things.”
Ah, the blame game again; it’s a game she never seems to tire of. I bite my lip but reply calmly, “Well, it’s obvious that our releases are not well coordinated; you mentioned us handing you documentation two days before launch, and that was the first time your team had gotten notice that a release was coming up. In your shoes, I’d be irate because that means a long weekend running the release and cleaning up messes afterward. You asked for better attendance at your CAB meetings – and I don’t think I’ve missed one since. You also said your resources are stretched thin and with our team’s shift to Agile we are putting too much of a strain on your people, including one of your best – Kevin. Did I get that right?”
A slow smile creeps across Emily’s face. “Yep, that about covers it. I don’t think your team has any concept of how hard it is to roll out and support software in production. It’s our job to work with you, but can you honestly say that you’re doing all you can to make it easy on us?”
I find myself laughing a little. “You know, I think I understand a little of how you feel. For us, we’re downstream of someone too – our business partners and the project management layer – and it really sucks to be responsible for something you had no say in and couldn’t control. That’s the definition of stress.” I glance at Emily again and decide to take a gamble. “Did I ever tell you about my near-divorce, about five years ago?”
Emily looks at me and raises an eyebrow. “You’re kidding me – you always talk so much about your family! I thought you and Julie were some of the lucky ones.”
“Yeah, it’s something I’m not proud of. Julie and I had been married a long time by that point, and of course we had our ups and downs. But we’d been trying to have a child – and when it happened, I found myself on the outside looking in. I started hunting and fishing more; being at home just seemed so BORING, like house arrest. There’s only so much burping and diaper changing you can do before you have to get some air. That, and the sleep deprivation, well, we really started fraying at the edges. For a few months we barely talked, just walked around in icy silence – or she would scream at me that I was still trying to act like a single man, and I would storm off, hit the bars. It really got ugly. After a while neither of us really wanted to be together anymore or enjoyed each other’s company.
“Like I said, this isn’t a part of my life that I am proud of. Both of us at this point were only seeing each other’s flaws and the relationship just didn’t look fixable. But, as one last try, we ended up going into therapy. I’ll never forget on our third session together, the therapist talked about what a dysfunctional relationship is – that it’s where both parties feel victimized, held hostage by the other. Neither side is getting what they need, and neither is really taking a good look at what they are bringing to the table. So, long story short, we had this long talk in the car on the way back and really opened up about how hurt and angry we were, and how disappointed we felt. It felt like kneeling on broken glass, but for the first time in months I looked at Julie and said sincerely that my behavior was selfish, that I wasn’t being a good partner and that I didn’t want to keep on repeating my actions that were so disrespectful, that it wasn’t fair to her. And over a few months we set some common goals that we could work towards together.”
This is getting a little uncomfortable; I’m revealing a bit more than I’d wanted. “Anyway, no, Julie and I aren’t a perfect couple. We really had to work at our marriage to stay together, and it all started back in that talk in the car – saying that we weren’t being fair to each other and that we wanted to do things differently.”
I sigh. “In a sense, your team and mine are married. And right now it’s definitely a dysfunctional marriage, where we both feel trapped and dissatisfied. You’re saying your team isn’t being partnered with, that we are dropping things out of nowhere on you – I believe that. You’ve also said we need to coordinate better. I think, with our rush to deliver working software at the end of every sprint out to QA, we have been missing the downstream impacts. So, what does that look like from your perspective?”
Emily is smiling at me and nodding, but there’s steel behind her smile. She says, “Well, yes, you’re right – this is a dysfunctional marriage.” We both laugh, and she grips her cup of tea a little tighter. “I’m just tired of hearing complaints about what it’s like running builds for your group, and I don’t get this kind of static from the Java team or the SQL folks. There’s some basic hygiene that your team needs to think about so we don’t get a mess dropped on us every two weeks. And I can’t afford to lose someone like Kevin. You know the Portland market – it could take me a year to find someone at his level and then get him or her trained up to that level of competence. I am hearing you say the right things though Ben – for the first time.” She looks at me over the rim of her teacup and takes a deliberately long sip. “Now let’s see if you can follow through with the actions.”
It’s hard for me not to roll my eyes a little at Emily’s speech. Emily has been trashing my name every chance she can get for months; now the same old tune, my team is always at fault. I have to swallow this though and keep in mind what I want out of our little café summit. “All right, so we have common goals – we want our teams to work together smoothly with less friction. What I’m hearing from this is that your teams and mine are stuck under the same rock. We are both drowning in firefighting, in unplanned work. Every week we lose most of our firepower with handling support and triage, and our broken releases are gobbling up the rest.
“So, Douglas wants me to talk about a plan to move towards a more stable release pattern. I think both of us want to learn some lessons from our last Footwear app release and move onward and upward. So, what do you think about coming up with a plan and presenting it to management together?”
Emily mulls this over and comes up with a winner – we’ll pair the two people closest to the last release debacle, Kevin and Alex, and put them in a room for a few days to brainstorm. I have to push back on including Ivan – who would have hijacked any discussion into ticket-routing as a cure-all – but we leave with what looks like the beginnings of an agreement.
Sticking to the 20% Rule (Capacity Planning)
Before I knew it, we were wrapping up another sprint and clearing the decks for the next one.
I find my attention wandering during the sprint planning session. The room has a good energy level though; we can already show some progress, just a few weeks in. Perhaps, most surprisingly – Harry, of all people, teamed up with Padma and came up with the number of tickets created by each app on our list for the previous 90 days, broken into major and minor buckets.
This freaking report, believe it or not, was an actual game changer for us. It looks like George’s hunch was right – out of the dozens of apps and services we have to maintain, really only a handful are true problem children – with a high business value and a large number of relatively painful bugs. Wrapping better release management and version control practices around our codebase is now looking a lot more possible. We can focus on just a few of the most temperamental, highly visible apps, and leave the rest for now.
The last of our demos is finishing up; now’s the time. “As you know, this is Erik’s last meeting with us,” I announce. “Erik, I know we’re all going to miss your energy and drive. As you are heading out the door, I thought you could tell us up front – how are we doing with our push for better version control discipline?”
“Well, it’s still really early on.” Erik shoots me an irritated look; once again, I’ve got him under the spotlight. “It’s unreasonable to expect a turnaround in such a short period of time. But yeah, I’m seeing some positive trends. We’ve got some environmental and config code moving to version control and that’s really good to see, and I’m satisfied that what we’ve got in version control right now matches production for our major headaches. But we still have a mountain of work ahead of us.”
The rest of the group is silent. I wait a few beats then say, “I take it the rest of you agree. To me, it’s really good news that out of the 80 some apps that we have to support, less than 10 need to be prioritized. That cuts down our to-do list by quite a bit. What about our push for better quality on check-in with more consistent peer reviews?”
There’s a little dead space, and then finally Alex pipes up. “Well, I think we’re still very early on, but there’s some positive signs around the concepts of collective ownership and our peer review system is making some progress. But pair programming, my God...” Loud sounds of agreement were heard around the table.
Padma is fuming. “Alex, pair programming is a key part of XP programming and we’ll never have true quality without it.”
“With all respect, Padma, I disagree. It means we cut our capacity in half. And there’s times when I really need to think about something, focus and concentrate. I can’t do that with someone sitting three feet from me. Peer review, yes that’s working – pair programming is a loser. We need to drop it.”
“Well, I promised you it would be an experiment, one that we could drop if it’s not working out,” I say brightly. “So the question is, is it too early for us to judge if this is successful or not?”
“I don’t think it’s too early,” Alex replied. “We should know by now if something is actually helping us or not. We’ve had that time, and it’s just not working for us.”
Before Padma can break in again, I shrug and reply, “This is a group decision, not something I’m going to mandate. If we see pair programming as something that can help this team improve our quality, we should do it. If we see it as hurting or neutral in its effects, we need to drop it. Let’s see a show of hands – how many of you want to continue with pair programming?” I get a few hands up, but most of the devs keep their arms at their sides. “OK, I’ll put this in the retrospective – we tried it, it didn’t help us, we’re going to shelve it. I’m worried though that our customers might see this as us falling back on some commitments we’ve made around quality. Is every line of code we’re committing going through a peer review?”
“Yes, we’re doing that,” Harry says confidently. “For example, I usually call Rob or Ryan over before I do my daily check-ins for a quick look-see. It’s helped a little. Mostly though, it’s slowed me down. Sometimes there’s no one around and then I have to go ahead and check my changes in solo.”
“Harry, either we’re doing the right thing or we’re not!”, Alex snaps in exasperation. “I’d like to see us checking in our code much more frequently, like multiple times a day. Once a day or once a week – and I’ve seen your check-ins, once a week is more like it – just isn’t often enough for us.”
“If you want multiple releases a day, Alex, then get us a better test framework.” Harry’s lip is curling up in disdain. “Right now I’m a little more concerned with not ending my career every time we go to deploy. I have zero confidence that our test layer is going to catch actual bugs and I don’t want to spend my life tracking down regression issues.”
I can see both Padma and Rajesh starting to bristle now. I spread my hands on the table. “Let’s not waste time circling around like this. I’m worried about us falling back into our old habits. We agreed that we would have every change reviewed by a peer. From what I’m hearing, the process right now is informal and ad hoc. It looks like the best fix might be gating our code in some way. Of those apps that we flagged as being troublemakers – how much work would it be for us to enforce some sort of peer review on check-in?”
Padma frowns. “For the apps that we maintain in Visual Studio AND have in source control, it’s a checkbox. We could enforce this with approval on a Git pull request for example. But some of our worst apps are more than twenty years old, and it shows – we’re talking Coldfusion, COBOL FORTRAN, etc. We build and deploy these manually as executables. Those legacy apps can’t be gated, at least not easily.”
“I’m the team dev lead and it’s my job to make sure that our standards are consistent.” Alex looks around the room. “It bothers me that we’re not checking in often enough, and that when we do we go to a good ol’ buddy to rubber-stamp hundreds of lines of code he or she has never seen before. Any objections to us setting up a policy where any check-in must be reviewed before commit as a gated approval step?”
We get agreement on this; we also put in the retrospective and on the team whiteboard that our check-ins are too large and infrequent. Something keeps weighing on me though – finally I snap my fingers. “That’s it – I almost forgot. When we planned out our work this sprint and the last one, we made sure to leave 20% of the capacity – that’s two days for each of you – to start to pay down our technical debt . I got a lot of static from our business partners on this, as we’re already behind in our commitments. I told them that we would only be able to make real progress on quality if we stopped booking you up 100%. What I want to know is, how is that working for us?”
To my surprise, one of the quieter devs on the team – Rob – offers his thoughts. “Not so great. Yeah, I had two days blocked on my calendar, but we had a boatload of bugs drop the day before. I was going to use that time to shape up the codebase in VC, but I had to drop that to work on the bugs we found with the last release.”
As a few others in the room chime in with similar complaints, Alex rolls his eyes. “If it was really that bad, I would have expected to see more of you here Thursday and Friday instead of working from home. I’m just going to say it – that 20% time isn’t for us to go home and buff up our World of Warcraft characters. We need everyone to show a commitment to improving our quality for things to get better. Otherwise, we’re going to get what we deserve – long painful releases and a never-ending list of bugs.”
“We’re running out of time here and we need to get back to our sprint planning,” George says firmly. “I don’t think anyone here interprets those two days as ‘Netflix time’. Let’s do this – next sprint, for our retrospective, each person can spend five minutes talking about what was done on their 20% time . If it’s block-and-tackle stuff like version control and struggling with moving config/environmental code, so be it. If it’s something shiny and new you played around with and think could help us, even better. But let’s not lose sight of the goal – for us to get out of our rut, we need to be learning continually. That means bringing something new to the table every two weeks, something that can help the person next to you.”
Nothing to argue with here. George smiles broadly and says, “One quick story and then we’ll get back to it. Back in my early twenties I used to be a section hiker on the Pacific Crest Trail . And I’ll never forget when I first tried to put on that 50 lb pack and felt those straps cutting into my shoulder blades. I thought, there’s no way I can carry a mile, let alone a hundred. And the first few days of every hike was pure torture. But I learned two things – first off, to be successful I just had to keep putting one foot in front of the other and not look up at the mountain in front of me. I kept saying every few minutes, one step at a time, one step at a time.
“The second thing I learned was that my biggest blocker was really mental, not physical. Once I stopped comparing myself to other hikers and showed some patience, I got less frustrated. My goal shifted from putting in twenty miles a day to trying to do that day’s hike the right way at the right pace for that day. Those little habits started to kick in over time, I got injured less and spent more of my time enjoying the process instead of hating my pack, hating that bland oatmeal, hating the work. I think that’s where we are right now as a team – we’re learning the little habits it’ll take to be successful and a lot less stressed out.”
A Focus on Flow, Not Quality (Reliability First)
Today’s the big presentation to Douglas; I walk into the conference room a few minutes early. It isn’t enough though – Emily is already there, moving briskly ahead with setting up the presentation display. At least we got them to agree to present off the same deck, I think and grin a little. Douglas, true to his military background, shows up precisely on time – and motions impatiently for us to kick things off.
Emily begins by recounting some of the issues with the Footwear release, now many weeks back – highlighting the late notice of the upcoming release, the incomplete setup instructions, and the strain the weekend patch work and troubleshooting had put on her team. I have to give her credit here though – she is sticking to facts, and even ends on a somewhat conciliatory note: “Ben and I were joking recently that the relationship between our team is like a dysfunctional marriage – neither side is really getting what they want. I do know that Ops simply isn’t ready to handle this kind of a nightmare every two months, let alone every two weeks. We need a renewed focus on quality, which means slowing things down and better planning. We simply can’t focus on velocity without thinking about the disruptions it is causing the teams that have to support and operate this code that we’re shoveling out the door.” She sits down, glowing in triumph.
I stand up and square my shoulders. For the first time in weeks, I felt like I understood where Emily is coming from – and that there might be a way out of this cross-team mudslinging. “First off, I agree 100% with the problems Emily’s outlined with this release. Now that we’re starting to see problems the same way, we can start to work jointly toward a resolution.
“Let’s show each part of our that release – but without any groups or team names called out. Our objective here isn’t to pin blame on anyone, but simply to show the flow of work across WonderTek for this one product. Here’s what that looked like.”

He continued: “Top left is our starting point – where work enters the system and is dropped into our backlog. I’d love to talk about the pipeline of work going into development for a few minutes. We’re seeing issues here right off the bat – there’s constant churn and jostling over what the right priority should be as everyone champions their favorite pet feature. It’s not uncommon for us to bounce from one red-hot, must-be-done emergency project to another from sprint to sprint – enough to give anyone a bad case of whiplash. Having our priorities and focus shift like this is leading directly to a lack of traction as we constantly shift projects back and forth.
“We also have a long list of features waiting on development. Elaine tells me that we have 13 major features under development and about 120 minor features in our backlog, just for one application. That represents in total about 1,300 hours worth of development. Worse, those asks are aging on us – the average time these wait to be assigned to a sprint is stretching out to about 90 days, and that’s climbing steadily. You can imagine how that’s going over with Footwear.” Douglas is nodding vigorously; he’s been getting an earful lately. “At least half of the features that we’ve worked on in the past three months end up being unused or dropped as no longer being of value. A significant amount of our development work ends up on the cutting room floor – by the time we deliver, it’s not needed or we’ve spent a lot of time gold-plating a feature that ends up being a dead end.”
That’s two weak points already – a long list of aging features that are stacking up on us, and shifting priorities by the business. But I’m not done yet. “Next comes the problems we’ve seen in writing code. For our last release, we spent a lot of time consolidating our code so it was buildable – we call that integration. That took up a shocking amount of time, about 12 weeks total. And once we were able to get a releasable build ready, our headaches were just beginning. As we’re releasing more often, there’s less room for us to work on nonfunctional requirements. Some very fundamental aspects like security and performance are dropping by the wayside. If all work stopped now, we’d still have two months of work addressing this technical debt.
“I mentioned earlier how frustrated the business has become as they’ve seen their requests languish. The reason for that is simple – we’re having to pull away from new development work to knock down bugs . We have currently in production about 12 major bugs, and over 100 minor ones – all of which are sapping our firepower when it comes to taking on new development. We started tracking this a few weeks ago and found that about 60% of our team’s capacity is spent identifying and fixing bugs. Of these bugs, it turns out that about half were red herrings – either false alarms, environmental or noncode issues, or user errors. Another 20% could have been addressed by the first responder in a few minutes using the runbooks we’ve provided them. But each issue reported requires us to stop work and triage, since they’re passed along to us untouched. More than anything else, getting tied down in firefighting is the single biggest contributor to the perception by the business that work is not getting done. It is – just not the type of work that adds value.”
“It sounds to me like your QA team isn’t doing their job right,” Douglas interrupts. “Why are we sinking the money and time we are into testing, if it’s not catching these problems early on?”
“That’s a great question.” I wince a little. “I wish I had a pat answer for this. Rajesh and his team have moved mountains to get our code coverage up, but still QA seems to always lag behind development by a few weeks. That gap is hurting us – most of the bugs I just mentioned should have been caught on check-in. Instead, they make it out the door into production. By the time they’re found and backed out, which is its own nightmare, it’s cost us ten times what it should have.”
Emily is wrinkling her brow at this. I continue, “Emily, that’s not an exaggeration. Rolling selectively back what we think might have caused a problem and then validating our work is a huge overhead cost. I know the QA team is working very hard, and we can’t fault their intentions or competence. But there’s no doubt about it – our quality is hurting us right now, and it appears like we need to rethink the way we’re approaching testing so it’s more of a parallel effort with development.
“Making thing worse are our environmental anomalies. Currently when we prepare a build, it’s prepped as a WIX package and then sent to the IT/Ops team for implementation. They then take the baton and run with it – spinning up environments based on our instructions and specs and installing the package and libraries it’ll require to run. There’s a lot of wasted time as people run back and forth trying to get the package to run on a new server as it does on a dev workstation after weeks of tweaking.
“Our environments themselves have become priceless artifacts – we’re terrified to make any changes to them. A significant number of the bugs and performance problems we see are actually caused by environmental anomalies. This means whenever we have to troubleshoot something, we first need to figure out if it’s caused by non-code issues like a patch to the OS or a networking condition. That can sometimes take days to determine – it’s a big reason why our firefighting is so drawn out and costly.
“So there you have it – a nasty little vicious cycle we have going on right now.”
Douglas is getting impatient. “OK, I get it, life is tough. Get to the point though – you’re presenting this as a set of problems. My ask is for my people to present me with options and solutions, not just problems. What’s our way out of this mess?”
Issue | Metrics | Options |
|---|---|---|
Aging requests by business | 1300 hours development in wait status 90 days avg wait until tasked and in sprint | Better filter/prioritization and unified view Improve deployment and dev practices downstream |
Low quality – bugs in production | 12 major, 100 minor bugs Unit test code coverage – 25% 60% of developer time spent on bugfixes | Peer review Automated builds Configuration management Source control First responder triage training |
Integration Issues | 12 weeks to integrate code branches | Continuous integration Source control |
Risky releases | Change failure rate 70% Lead time 3 weeks MTTR – 8.5 days Release frequency – 2 weeks | Release management Improved diagnostics and monitoring Automated builds Source control |
“I’ve put Kevin in tandem with Alex on Ben’s team, and they think we can better automate our releases,” Emily continues. “There’s no reason why the builds for this application can’t be better automated so that we have a Christmas-tree like display with green and red builds on a dashboard. And on environment provisioning – we need to stop thinking about code as just being for software. Environments and servers can be scripted, and Kevin’s confident that with the current design of the Footwear app, it should be a matter of weeks to get to where we can spin up a VM environment from a script that is capable of running the app. That gives us apples-to-apples conformity from QA down to PROD.”
Douglas is looking at the third column and frowning. “Emily, I appreciate you being here and working with Ben jointly on a solution. That more than anything else gives me some hope. But let’s be honest here – this is a lot of ideas to take on. I think, maybe too much for where you are right now.”
I say slowly, “Yeah, I totally agree. We aren’t proposing taking on every aspect of these at the same time – that’s just not reasonable. What we’d like to do is focus on one thing – and see if we can’t make some measurable improvement, over three months. That one thing is our release process.
“Lack of maturity over how we handle changes and code releases is our limiting factor , and it’s tied in to everything else. If we had fewer bugs making it into production, we could focus more on the backlog requests and get the business the features they’re asking for. Our Operations and IT team would be a lot happier as they won’t be dragged into all-week war rooms trying to fix the latest broken build. Our releases would be safer, so we won’t feel like we’re making a career ending decision every time we go ahead with a production push.”
Douglas is nodding. Things are going well so far; this is running smoother than I anticipated. He asks, “So, let’s get down to it. What are you going to do to fix things?”
Emily shows the next slide:
Mission: Improve Release Process

Douglas is frowning again. “Ben, you’re already struggling getting your stuff out the door every two weeks. Why are you wanting to push your code out more frequently? And if you want to reduce firefighting – how come I’m not seeing anything here for your QA team?”
I reply, “On that second point about why we’re not targeting quality directly – two reasons. First, focus. You said it yourself – we can’t take on too much at once, we have limited capacity. Second, we’re drowning in bugs, true – but that’s a masking symptom, not the cause. The actual cause of all these bugs is lack of process, of automation.
“Our teams are telling us that if we have a pushbutton deployment that’s repeatable, to every environment, our rollbacks will be much easier; our firefighting will drop off as we begin using scripts more for templating our environments. We’re betting heavily on creating automated builds , running off of source control that’s the single source of truth for environments, configuration and code. That will have cascading benefits everywhere, including quality. And if we can turn half of those red dots on our manual releases to green – say get it to a 35% failure rate – I think a lot of the friction between Emily and myself suddenly goes away. We’ll know we’re making headway if each release carries less of a tax on us – if we’re only spending 150 hours prepping and rolling out a release, versus the 300 hours its currently costing our teams.”
He’s still frowning a little, but I’m getting a little bit of a nod. “OK, good plan. I like this because it’s specific and verifiable, we’ll know if we’re on track or not. I still think this is a lot to take on in one month, but let’s see how things go. Emily, are you onboard with this?”
Emily says, “I’m not happy about saying we’re going to release more often. Like I keep saying, we’re strained to the limit already. But, let’s wait and see. The big win from where I stand is the Release Management Tiger Team. This is a few people from my team and Ben’s, meeting together weekly to talk about current and future state with our release processes and build automation. Right there, we’ll see better communication and less dropped balls between our two teams.”
Douglas stands up. “Well, this has been a good discussion. I’m late for my next meeting – but the fact that at least I could get you two in a room to talk about this together was a good thing. Let’s move forward along these lines – and see how things go.”
Behind the Story
A few concepts in this chapter bear some exploration. For example, why are we discussing boat winches in a book about DevOps and software development? And why was the team’s decision to focus on improving velocity so short-sighted?
Lastly, a key part of DevOps is learning how to control queue size and limit work. Let’s explore what this process – which in software we implement with a process called Kanban – means in more detail.
Ratcheting Change
Fast is fine, but accuracy is everything. In a gun fight... You need to take your time in a hurry.
— Doc Holliday
Simplicity changes behavior.
— BJ Fogg 1
The power of sustaining your progress is that you end up blowing away anyone that chased success as fast as possible.
— Rob Hardy 2
As part of writing this book, we devoured nearly a hundred books on the subject of DevOps. But two in particular had the biggest impact on our thinking: the book Team of Teams by General McChrystal and The Power of Habit by Charles Duhigg . Neither mention DevOps anywhere in their text. But we suggest that both are essential to understanding why most organizations find the road to better change management and velocity so difficult.
We took an opportunity in the section “A Fishing Trip” to talk about the lessons these books and others reveal about human behavior and the difficulty of overcoming inertia and tradition. Setting a safe pace remains one of the most important factors so often overlooked in the “how-to” recipe books on DevOps.
Slow Is Smooth, Smooth Is Fast
There’s a lot of meaning in that classic military saying “slow is smooth, smooth is fast .” Moving fast or rushing our pace in any strategic-scale transformation is reckless, potentially fatal. When we move carefully, deliberately, at a measured pace, two wonderful things happen. First off, we avoid many rep-sapping mistakes and limit the blast radius of any missteps – meaning we’ll still be around to implement our next incremental change or improvement. Second, our progress actually becomes faster than big-lurch death marches.
Some of our teams though have been doing work in a particular way for 15 years; it’s extraordinarily hard to change these indoctrinated patterns. What we are finding is, we succeed if we show we are adding value. Even with these long-standing teams, once they see how a stable release pipeline can eliminate so much repetitive work from their lives, we begin to make some progress. 3
…we have to admit the challenge large, established enterprises face, is huge. The word ‘entrenched’ doesn’t even cover it. We’re talking about 150 years of corporate culture, everything based on incentives around competition. Do you want that raise? Do you want more vacation time, a better office? Then you have to step on your peers to get ahead. That culture doesn’t just go away overnight. You can’t just step in and say, ‘everybody get along now, we’re all about learning and not using people as stepping stones anymore.’ There’s a lot of history of unhealthy competition and fear that has to be unlearned first.
No company starts out with yearly deployments; all these struggling companies, when they first started, were likely incredibly agile – even before that movement existed! Services and software got rolled out the door frequently, but then there’s that one customer or account that is such a large value that you’ll do anything to keep them. Now we have to start slowing down releases because we care more about availability than we do augmenting these services. It builds up tension between the people that build services and those that keep it running. This ultimately leads to slowing or halting releases and adding unnecessary processes in the release process. 4
We’ll illustrate this with the personal story of a friend of ours, whom we’ll call James. James was like most of us in the programming and IT field: almost completely sedentary in his lifestyle, badly overweight, and badly overworked. He told us that he found himself out of breath just crossing the hundred feet from his office to his car. Then, as often happens, the debts his way of life were accruing came due; he had a visit to the emergency room, followed by months of physical therapy. On his first visit post-event to his physical therapist, the man looked at James and told him he had two decisions: “in ten years, do you want to be healthy, alive and well for your family? Or do you want to die?”
It was one of those dramatic forks in life’s road that forces a choice. The interesting thing is that James did not start out with a crash course, a complete reversal of his potato chips-and-the-sofa lifestyle to tofu and 3 hours of hitting the gym a day. Like many of us, James hated working out, but he did like riding a bike from time to time. So, he started a new habit, at the same time each day. He would hop on his bike and ride around his neighborhood, about 3 miles. This went on for a few months. Over time, he started riding with a group over longer distance; an older man was kind enough to hang back with him so he wasn’t left in the dust. Gradually, click by click, he was able to ratchet up his activity level till he was hitting almost 5000 miles a year – doing something that he enjoyed, every turn of the wheel.
Two years after this event, James doesn’t put on the mileage that he used to on his bike. But he still gets out several times a week, when he’s not doing other active things. He’s lost 30 pounds, and his health – due to his new lifelong habits – is back in the green.
Start with Tiny Habits
This is why our fathers often told us, “slow and steady wins the race.” If James had chosen the path most of us take when it comes to our new year’s resolutions, it’s safe to say that today he’d be back where he started, if not worse off. Most of us start our personal transformations on a grand scale, with high hopes of dramatic improvements in our health or mindset. Months later, our treadmill or exercise bike languishes unused in the garage, being used as a coat rack. What makes the difference here in having a new habit stick?
The studies and work conducted by Dr BJ Fogg of Stanford are very revealing on this topic. He noted that many of us start out thinking almost entirely about outcomes – “I’m going to lose 20 lbs by March!” There’s that familiar initial rush of enthusiasm – we make seismic changes to our lifestyle from top to bottom, a complete renovation for comprehensive fitness. Then, about 3 to 4 weeks later, we find it almost impossible to make that trip to the gym or to down yet another salad. Burnout and lethargy set in; we fall off the wagon. Within a few months, we are back to our unhealthy state; nothing has changed.
The seeds of failure were right there in the beginning when we started out thinking about life-changing outcomes vs. one habit at a time. Those who actually succeed in this very difficult quest tend to think less about outcomes and more in terms of habits. And they tend to build these habits like our friend James did, with a ridiculously easy starting point and very gradual, gentle increases over time.
For example, Dr Fogg found himself wanting to increase his physical fitness as he entered his 50s. But starting with 100 pushups a day – though that might have worked for a week or so – was simply too big a mountain to climb; 10–12 pushups a day was also too hard. He started with an anchor, a physical cue. In this case, it was every time he went to the bathroom. After peeing, he did two pushups. Then, he washed his hands – and felt a little burst of satisfaction.
That’s how the habit started – with a simple act, tiny in size, with the same physical cue or trigger – an anchor, as Dr Fogg calls it. Now, after months of gradually stepping it up, Dr Fogg does between 40 and 80 pushups a day – often outperforming his students. Dr Fogg calls these “Tiny Habits,” and it’s a proven way of encouraging lasting personal change at a sustainable, safe pace.
I never followed a magical program. I simply did the work and added 5 pounds every two weeks or so. Sure, the lower limit was important. I had to keep adding weight in order to get stronger. But the upper limit was just as critical. I had to grow slowly and methodically if I wanted to prevent inflammation and injury.
There were plenty of days when I could have added 10 pounds. Maybe even 15 pounds. But if I aggressively pursued growth I would have quickly hit a plateau (or worse, caused an injury). Instead, I chose stay within a safety margin of growth and avoided going too fast. I wanted every set to feel easy.
The power of setting an upper limit is that it becomes easier for you to sustain your progress. And the power of sustaining your progress is that you end up blowing away everyone who chased success as quickly as possible. 5
- 1.
Commitment: There’s a personal commitment and accountability – often communicated to others – to make a change.
- 2.
Habit Not Outcome Oriented: This change is communicated in the form of a habit (“I want to squat 300 lbs”) vs. an outcome (“I want to lose thirty pounds”).
- 3.
Simple, Clear, and Unambiguous: The habit is easily understood and something that can (and should) be done every day.
- 4.
Small and Achievable: Instead of being epic level achievements, successful changes begin with tiny nudges – perhaps only minutes a day – that are gradually ramped up over time.
Activation Energy , Bright Lines , and the Single Pushup
The problem is that big goals often require big activation energies. In the beginning, you might be able to find the energy to get started each day because you’re motivated and excited about your new goal, but pretty soon (often within a few weeks) that motivation starts to fade and suddenly you’re lacking the energy you need to activate your habit each day.
…Smaller habits require smaller activation energies and that makes them more sustainable. The bigger the activation energy is for your habit, the more difficult it will be to remain consistent over the long-run. When you require a lot of energy to get started there are bound to be days when starting never happens. 6
That’s why, if you want to get stronger, it’s better to start with one pushup a day instead of 80. One pushup a day will be like striking a match, nice and easy – a very low activation energy. It’s going to take a lot more activation energy to start with 80 pushups a day – and the odds tell us that within a week, maybe two, we’ll find the price too high to pay and keep motivated. We’ll miss a day, then two… and our old negative habits will reassert themselves.
Beyond just being bite-sized, the habit we’re trying to instill uses what is called in the world of contract law “bright lines” – a clear, unambiguous standard, or guidelines. Rules and commandments are easy to get around or subvert; deciding ahead of time that we are committed to a very specific change in our behavior – and making preparations so our environment encourages this change – is something else entirely.
Alcoholics Anonymous , for example, has found that it’s almost impossible to tell people to stop doing bad things or habits and hope for success. Instead, they try to replace bad habits with good ones. As Charles Duhigg brought out in “The Power of Habit ,” they incrementally try to replace bad habits with good ones. For most alcoholics, as an example, the bar is more of a social draw than anything else. Having a clear personal commitment, regular group discussions in a warm community, and an assigned mentor that a recovering alcoholic can call during moments of temptation replaces that bad habit of hitting the bar with a positive habit build on our natural social needs.7
DevOps really at its heart is really about changing habits at scale. Refinements like breaking down siloed walls, eliminating the “blink” or handoffs between groups, and improving the flow of communication and work are all changes in human behaviors and habits. This kind of dramatic change in human behavior is extremely challenging and comes with a high recession rate. Otherwise, there wouldn’t be a thriving $30B a year fitness and health industry in America alone!
We tilt the odds in our favor when we take into consideration human psychology and the nature of building positive habits. Thinking that releasing 10,000 times a day like Amazon , Microsoft , or Facebook will fix things is really just outcome-based thinking. And, fundamentally, that kind of an imitation-based goal has nothing to do with delivering value or solving a specific business problem. The same is true of CIO-driven initiatives to become “cloud-native,” without thinking of the capabilities and advantages that would make such a movement desirable or even possible.
Usually when things go off the rails with DevOps it’s because incentives are misaligned with what you’re trying to do. To me it comes down to internal motivation – do you want to be demonstrably better today than yesterday? Everything is culture side for me.
You can’t pattern yourself after Etsy or Google. Guess what – they’re terrible at certain things, the same as you are. They just don’t talk about it onstage. The big unspoken secret of our movement is, no one, absolutely NO ONE is the best at DevOps. Everyone is still learning and trying to do their thing. 8
Some very big epic-level concepts being batted around in this book: configuration management; comprehensive automation and a robust test and release cycle; microservices and domain-driven design; small, cross-functional teams with production support responsibilities; feature flags and continuous delivery; and hypothesis-driven development. These are all big goals involving months or years of work – like doing 100 pushups a day, or trying to lose 40 pounds.
This book is about “one team, one year ,” and it’s technically possible to make progress in all of these things in a year. But we aren’t seriously suggesting you SHOULD do all these things in a year. It’s better to think less of these big-scale capabilities and epic improvements and more about some small, tiny habits you can instill tomorrow that won’t roll back, that can be something to build on. Something like a single pushup.
What does “one pushup” look like in the DevOps world? Perhaps, this could be having your developers begin meeting once a week with Operations for lunch, or dedicating some cycles to sharing production support. Perhaps, it’s instilling a better peer review process or experimenting with pair programming to produce better quality code. Maybe, you’ll spend a day or two and build out a map showing the delivery of value across one of your workstreams, from idea to product. Or – our personal favorite – you’ll take the advice of John-Daniel Trask and invest some time into setting up better instrumentation and monitoring. Any small, bite-sized habit that can give your team that quick positive burst of energy that comes from doing the right things the right way.
Changing habits is what led Ticketmaster to create an objective list of practices they wished to encourage in their maturity matrix model , which built toward their epic-level goal of self-disciplining teams.
Changing habits is what underlies Microsoft’s push toward forcing a release every 2–3 weeks across all their delivery teams for Azure DevOps . Aaron Bjork told us, “you can’t cheat shipping,” and said that this forced pace promoted “righteous behaviors,” good habits that avoided piling up technical debt and deferred work. That’s a bright line that actually helped resolve a true business problem, and it wasn’t allowed to be rolled back.
A consistent theme in our interviews was that the best roadmaps built positive habits that accrued gradually. Think less about grand imitative outcomes and more about changing habits with bright lines and a lowered activation energy.
Ben’s on the right course when he is thinking about change in terms of the principles behind the click-and-pawl ratchet. Habit changes work along similar lines: small, incremental gains that are gradually ramped up over time. It’s the only way to ensure that the changes in behavior we are trying to instill actually stick.
Kanban
The two pillars of the Toyota production system are just-in-time and automation with a human touch, or autonomation. The tool used to operate the system is kanban.
— Taiichi Ohno , Toyota
Controlling queue size is an extremely powerful management tool, as it is one of the few leading indicators of lead time – with most work items, we don’t know how long it will take until it’s actually completed. … it also makes it easier to see problems that prevent the completion of work. ….Bad multitasking often occurs when people are assigned to multiple projects, resulting in many prioritization problems.
— Dominica DeGrandis 9
Kanban is another one of those unglamorous topics; there’s not a lot of techy glitter about it, once the novelty of moving sticky notes about the screen fades. But the odds are that – just like with version control – you think you’re doing Kanban, but you’re not doing it right. And it’s one of those secrets hidden right in the open that separates the high performers from the imitators.
In the section “Behind the Story – The Worst Form of Laziness,” Ben’s team first begins to experiment with Kanban and limiting work.
The Software Hierarchy of Needs
Let Dave explain with a little story from his past: “A few years back, I was leading a team that was swamped in debt. Very little new work, was going on as our mission mostly was supporting creaky old orphaned applications. The perpetrators that created this swamp of undocumented, untestable, kludgy garbage had long ago fled the scene, of course. Every day was a terrifying nightmare of uncertainty; important things were breaking, and we had no clue of how to fix them. To say we were stuck in neutral would be too kind; we were stuck in the mud, with no way of getting out.
What got us out of that negative cycle of fear and uncertainty? One morning I read a post written by Scott Hanselman on Maslow’s hierarchy of needs. If you’re not familiar with it – here’s the original hierarchy :
The essential point is that all of those great and lovely things we enjoy about culture is built on something. If our basic needs aren’t being taken care of, if we’re not safe and have a healthy network of supportive friends and family, the top of the pyramid is weak. Scott applied this to programming in a way that immediately caught our attention:

Scott’s point was that it makes little difference what shiny new tech we’re using – if the base of the pyramid isn’t stable, we’re stuck. If we can’t deploy and roll back on a whim, if we are terrified of changing anything because of runaway environments and brittle, tightly coupled architectures – we’re cavemen, living day to day, just trying to survive. You can’t boast about all the cool stuff your apps do if you haven’t taken care of the foundation. And you can’t blame other groups either – this stuff is fundamental and is your responsibility to provide with every single line of code.
That morning, before our daily standup, I went over the article with my team and we mapped out what that meant to us. Over the following 30 minutes – and for the first time – we talked honestly about our applications big picture. Where were we falling short in having our code be revisable, buildable, maintainable, and refactorable? For us, it was clear – we had lots of room for improvement in having more productive design and peer reviews, and we desperately needed better tooling around our build process with CI and gated check-ins.
Here’s the whiteboard drawing that resulted, in all its kludgy glory:
We called this misshapen wizard hat – sorry Scott! – our “Harry Potter Hat of Greatness .” I can’t tell you what a powerful impact that article had on my entire team, and myself personally. For the first time, as a group, we stopped pissing and moaning about all the things those other bad people were doing and started focusing on what we needed to change. Now, that we had named the problem, it couldn’t hide anymore – we started making steady progress toward mastering our environments, making them more safe.
I remember going home that evening for the first time in months with a huge smile on my face; I was taking control of my destiny and finally earning my title as a team lead.
- 1.
We were too busy to be effective at anything. If things were going to get better, we’d need to focus less on the urgent and more on the important things that were getting back-burnered.
- 2.
For me to earn my pay as a lead, I’d need to set the example. That meant drilling in on one thing and one thing only.
Both of these lessons I should have learned months earlier; this is all Kanban 101. I was going through the motions of Kanban but not understanding the real intent.”
Kanban Is About WIP
Interestingly, if you had talked to anyone at Dave’s team at the time, they would have told you very confidently that they were following Kanban process. Yet, the team clearly wasn’t.
To be effective, Kanban isn’t just about showing your work and making it visible to everyone – though that’s a nice side benefit. Kanban is really a tool to limit your WIP , your work in progress. You and the team decide how many things you can focus on at a time. As a general rule – if it’s more than one task per person on the team, or five to seven for a group, you have too much work in play at once.
Why such a stringent limit? Isn’t it better to have multiple tasks in progress at once, in parallel, so we don’t have dead time waiting on dependencies?
First, the bar must be set low for a reason. Teams – and engineers especially – habitually underestimate what it takes to drive a task through to completion. (Remember the old general contractor’s rule, that the last 20% of the project inevitably takes up 80% of the project time?) And we buy into this myth of multitasking – that we can juggle seven to eight things at once and do justice to them all. Inevitably, telling ourselves this lie means we pay a high price in terms of stress and waste due to context switching. Worse, we end up surrounded by projects and work that is half-done, disappointing the very people we were trying to please by overcommitting.
Noncoders frequently underestimate the costs of context switching and interruptions on flow. The book Peopleware was one of the first that took the time to describe flow and how it relates to programmers. Flow is an ubercreative, Nirvana-like state where we are solving problems and creating cool new functionality almost effortlessly. But as Peopleware brought out, it’s not easy to get into that state; for most of us, it takes at least 15 minutes. Any break causes another 15 minute (minimum!) reset to get our mental train going again; a handful of interruptions can easily cost you a day’s work. (This is why we are not big fans of modern “collaborative” software that forces popup toast messages or IM windows on our screens; they kill productivity and creativity.)
One of the best parts of Agile was that it finally gave us a break from constant interruptions by our stakeholders – “is it done yet? Hey, can you do this little task here this afternoon?” Agile gave us a safe little bubble of isolation that coders and engineers need to work on a set list of defined tasks – a bubble (hopefully) free of interruptions, which we pay for with accountability and transparency through our regular planning sessions and retrospectives.
In the majority of the time where teams struggle in their adoption of Agile, the common factor seems to be not gating or limiting the amount of work in flight. Kanban drives that next step up in isolation and helps eliminate the waste caused by context switching. After a settling-in phase, we bet that you’ll notice is how much more seems to get done, with a lot less wear and tear on your people.
So if you’re really doing Kanban , take a second look at that board and the tasks that are in flight. You should only have a few, and the entire team should be focused on them and pitching in together to drive them to “done” status.
Capacity Planning and In-Parallel Work
This brings us to our second point – parallel vs. in-series work. Immediately you’ll hear cries of complaint when you institute these limits as a hard cap. It looks inefficient to have people waiting on work or complete artifacts – “people aren’t busy! They’re waiting on this other dependency to start work!” However, this is a very good thing – you’re exposing a weak point (what the military calls a “limfac”) in the process flow and forcing improvements at that constraint point in the value stream.
Remember that efficiency is not our goal – we are not trying to fully utilize our staff, to 100% of capacity . A fully utilized freeway is completely useless – it’s jam-packed with cars, but nothing is moving. We want flow. That means limiting the number of cars on the road.
Controlling queue size is an extremely powerful management tool, as it is one of the few leading indicators of lead time – with most work items, we don’t know how long it will tke until it’s actually completed. …It also makes it easier to see problems that prevent the completion of work. It’s tempting to start new work during that idle time as we are waiting – but a better action would be to find out what is causing the delay and help fix that problem. Bad multitasking often occurs when people are assigned to multiple projects, resulting in many prioritization problems. 10
Surprisingly, the cries of complaint you’re going to hear loudest aren’t going to come from outside your team. The loudest and most passionate arguments against capping work will come from the Atlases within your team – those long-suffering heroes who singlehandedly support everything. In the book The Phoenix Project, this much-hated person was called Brent; nothing could happen if Brent was sick or gone. He was a human limfac!
These people are often highly competent and very wide based in their tech judo as well as company lore. And the more difficult the assignment, the tighter the deadline, the less known the problem, and the more obscure the fix, the better! Secretly, these people – and you have at least a few in your company – LOVE the long nights, the weekend runs for pizza, kibitzing in the war room during a broken deployment.
It seems like these people are everywhere, with their hands on everything. Rarely is there time to document anything for the “next guy” – it’s on to the next crisis du jour! They are taking point, fighting their way out of ambushes, getting things done – usually nine things at once, and that’s on a Saturday. Saving the day comes with a significant payoff in terms of self-esteem and satisfaction – enough, perhaps, to justify in their minds the high price they often pay in terms of neglected relationships and their own health. Left to themselves, these self-sacrificing, highly competent heroes will lead the team into disaster; their work simply can’t be recreated by anyone else.
Before we jump in with cries to “fire Brent!”, let’s take a good long look in the mirror first and admit that there’s a secret adrenaline junky – a hidden Brent – in all of us. We check e-mail compulsively, monitor our work accounts during vacation, pride ourselves on our fast response time for any request, and a spotlessly clean inbox. We have to-do lists a hundred items long. We read websites on how to maximize our productivity and pride ourselves on how booked solid our calendars are – wall to wall meetings, everybody! And we start each morning and end the day with hours of streams of information and news that leaves us stressed and agitated. We move faster and faster; living the “full catastrophe life ” to its fullest. We’re crazy busy, which makes us irreplaceable. Is it possible though that in reality we are being… lazy?
Being Busy Is the Worst Form of Laziness
Timothy Ferris in the book The Four Hour Workweek made a very strong point: that we “busy” people are actually very lazy. Being busy is actually the worst form of laziness. Being busy is often caused by a failure to set priorities (despite the excuses we offer); our actions are indiscriminate, and we aren’t putting any effort into separating out the important things. We are too lazy to check ourselves and ask – Am I being productive or just active? Am I inventing things to avoid the important?11
Truly effective people know innately the 80/20 rule – and they limit tasks to the 20% of things that will pay off long term, the truly important things. Keeping in mind Parkinson’s Law – that tasks (cough, meetings!) expand to fill the time we allot for them – they hardcap their commitments ruthlessly. And they never even attempt multitasking. The book recommends that we have, at most, two goals or tasks to do each day – and they should be driven through to completion. If that isn’t happening, we need to commit to less.
We’ll get more into monitoring and dashboarding later. But it’s worth saying that Kanban by itself is only a piece of the puzzle:
What is most interesting is that WIP limits on their own do not strongly predict delivery performance. It’s only when they’re combined with the use of visual displays and have a feedback loop from production monitoring tools back to delivery teams or the business that we see a strong effect. When teams use these tools together, we see a much stronger positive effect on software delivery performance… [So beyond limiting WIP, effective teams] make obstacles to higher flow visible, and if teams remove these obstacles through process improvement, leading to improved throughput. WIP limits are no good if they don’t lead to improvements that increase flow. 12
This doesn’t have to be hugely complicated. For Dave's team, they kept that crude little Dr Seuss hat up on the whiteboard for 30 days and kept it front and center in our discussions and sprint retrospectives. Straightening out our flow pinch points was a longer journey. But, at least we were having the discussion, and the team was focused on a single mission.
Do One Thing
As long as we’re talking about focus, you’ll forgive us for a short rant. One of the disturbing trends we’ve seen recently in tooling is how many Kanban boards out there are missing the point. The cards themselves are displaying way too much text and attributes that should be kept in drilldown, which makes the screen cluttered and difficult to grasp at a glance. And what started as a simple three-lane board – “To Do,” “In Process,” “Done” – now is sprouting all kinds of extra alleys. We commonly see “In Integration,” or “Staging,” “Dev Design,” “Implementing,” or “Data Modeling” lanes. Not surprisingly, these same teams struggle with showing their actual progress in a single board, or with straightening out their limfac points. They’ve fallen in love with the allure of a complicated display and lost sight of the end question – which is binary. Is the work done or not?
Many farmers focus on “one thing.” If they get that one thing done a day – whatever is highest in priority – they can go to bed at night and sleep with a good conscience, knowing that they’re making steady progress in chipping away at the work and constant maintenance that comes with the job.
For our team, we decided that “one thing” was peer and design reviews as a regular part of our working routine. For 30 days, we just focused on that as a team. Every meeting, every day, I found some reason to bring this up as a theme. Steadily, slowly but surely, “one thing” at a time, we started knocking down some of that overwhelming technical debt until we could get to the point where as a team we could finally brag about our progress. We were out of the mud!
Reliability First
Simplicity is prerequisite for reliability.
— Edsger W. Dijkstra
It is not the strongest of the species that survive, nor the most intelligent, but the one most responsive to change.
— Charles Darwin
In the section “A Focus on Flow, Not Quality,” Ben opts to drive on flow and increasing velocity. This is a prime example of the numbers we choose to focus on having unintended consequences, and the biggest “road not taken” missed opportunity in the book. What would Ben’s journey would have looked like if they had chosen a different KPI that focused more on reliability and service availability?
Thankfully, we have a stellar example of a very successful movement that chose to do just that: the Site Reliability Engineering (SRE) movement, founded by a little startup called Google . What can the SRE paradigm teach us about the value of building quality and reliability into our development processes and team values?
DevOps and the SRE Movement
Google faced a serious problem in 2003; as a consequence of their exponential growth, their large-scale services and data centers were beginning to show signs of wear, and their operational teams were overburdened. How could they continue to grow and add new features without sacrificing quality and reliability?
Enter Ben Treynor and his group of software engineers, driven by a single mission: to make the company’s services run more reliably and at scale. Starting with a single team of seven, this group has now expanded to well over 1500 at Google. As a model, Site Reliability Engineering (SRE) is no longer unique to just Google; SRE teams have sprung up at companies like Apple , Microsoft , Facebook , Amazon , Target , IBM , and Dropbox .
Although Google’s success with the SRE model has led many to label SRE as being “DevOps 2.0” or “the future of DevOps,” interestingly, the people we interviewed at Google did not agree. At its core SRE is a very specific, proscribed implementation of DevOps principles. SRE happens to embody the philosophies of DevOps but has a much more prescriptive way of measuring and achieving reliability through engineering and operations work.
DevOps | SRE |
|---|---|
Reduce organization silos | Share ownership with developers by using the same tools and techniques across the stack |
Accept failure as normal | Have a formula for balancing accidents and failures against new releases |
Implement gradual change | Encourage moving quickly by reducing costs of failure |
Leverage tooling and automation | Encourages “automating this year’s job away” and minimizing manual systems work to focus on efforts that bring long-term value to the system |
Measure everything | Believes that operations is a software problem and defines prescriptive ways for measuring availability, uptime, outages, toil, etc . |
SRE teams are “responsible for the availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their services. We have codified rules of engagement and principles for how SRE teams interact with their environment – not only the production environment, but also the product development teams, the testing teams, the users, and so on. Those rules and work practices help us to maintain our focus on engineering work, as opposed to operations work.” 14
DevOps and SRE are not two competing methods for software development and operations, but rather close friends designed to break down organizational barriers to deliver better software faster. 15
We don’t envision SRE being “the way things are done” 10 years from now, as it’s just one possible way of implementing DevOps . We do see it becoming more of a standardized role within many companies; its growth is only going to increase. It’s a fantastic idea to have dedicated teams with a single obsession around reliability . Too many development teams out there ignore the maxim that over time, the cost of writing code compared to the cost of supporting it shrinks to zero. SRE forces a very rigorous and constant awareness of the cost of operability and the impacts of risks and cutting corners on quality with our releases.
If you are a heavily services-oriented company and want to put some teeth behind your customer-facing SLA’s , SRE is a proven and very robust model. It makes implicit, unspoken expectations around availability and velocity more explicit, forcing a consensus around a common set of goals – defusing much frustration and conflict. And the stress SRE puts on the real value of automation in reducing waste and meaningless repetitive work – toil – is dead on. And we love the very pragmatic and prescriptive way the SRE movement uses numbers to better balance out the power struggle between change agents and sysops.
Transferable Lessons from SRE
Have a single team(s) focused entirely on reliability
Use error budgets and gate launches on them
Have development teams share the pain of production support
Cap operational workloads
Let’s break this down piece by piece and see what we can learn.
A dedicated team focused on reliability
Most companies would agree that reliability is the single most important quality they are looking for in their software, much more important than adding new features. Yet open discussions setting expectations around this important metric rarely seem to happen; it’s also the first thing thrown out the door in the rush to get new features delivered. Worse, by the time an app becomes unreliable, it’s very challenging to recover; it can take months or years to isolate and roll back the changes that have introduced instability.16
Because reliability is so critical, SREs are focused on finding ways to improve the design and operation of systems to make them more scalable, more reliable, and more efficient. However, we expend effort in this direction only up to a point: when systems are “reliable enough,” we instead invest our efforts in adding features or building new products. 17
The SRE movement began and is centered around having an explicit SLA for every service; reliability is set and enforced as a budget based on availability. SRE teams don’t perform risk assessments or try to avoid outages. It forces a brokered conversation around reliability based on that single, explicit SLA.
Use error budgets to gate launches
There’s no denying that change introduces risk; every change introduced by developers is a potential source of an embarrassing, expensive outage – directly impacting the workload and often bonus levels of the IT/Operations people providing frontline support. So a kind of war begins; Operations institutes risk-mitigation methods like zero defect meetings , CAB reviews, launch reviews, and change review boards , all of which slow down or gate change. Development teams counter with end-run tactics around these obstacles – “dark launches” and feature flag/canary releases , “experiments,” “minor routine” changes – all intended to slip changes over, under, or around these barriers to release.
You might expect Google to try to build 100% reliable services – ones that never fail. It turns out that past a certain point, however, increasing reliability is worse for a service (and its users) rather than better! Extreme reliability comes at a cost: maximizing stability limits how fast new features can be developed and how quickly products can be delivered to users, and dramatically increases their cost, which in turn reduces the numbers of features a team can afford to offer. Further, users typically don’t notice the difference between high reliability and extreme reliability in a service, because the user experience is dominated by less reliable components like the cellular network or the device they are working with. Put simply, a user on a 99% reliable smartphone cannot tell the difference between 99.99% and 99.999% service reliability!
…The use of an error budget resolves the structural conflict of incentives between development and SRE. SRE’s goal is no longer ‘zero outages’; rather, SREs and product developers aim to spend the error budget getting maximum feature velocity. This change makes all the difference. An outage is no longer a ‘bad’ thing – it is an expected part of the process of innovation, and an occurrence that both development and SRE teams manage rather than fear. 18
The SRE approach makes the often unstated, implicit battles around expectations of reliability and pace explicit, bringing the conflict out in the open where an objective, specific goal can be agreed upon in consensus vs. waged in protracted wars of political attrition. It also encourages thoughtful risktaking; availability targets can be exceeded by ideally not by much, as it would waste opportunities to clean up technical debt, reduce operational costs, or add new features. Just the fact that these conversations around risk vs. reward are happening is a huge step forward in collaboration.
It can be challenging to have a productive conversation about software development without a consistent and agreed-upon way to describe a system’s uptime and availability. Operations teams are constantly putting out fires, some of which end up being bugs in developer’s code. But without a clear measurement of uptime and a clear prioritization on availability, product teams may not agree that reliability is a problem. This very challenge affected Google in the early 2000s, and it was one of the motivating factors for developing the SRE discipline. SRE ensures that everyone agrees on how to measure availability, and what to do when availability falls out of specification. 19
Like with most successful efforts we’ve seen, this strategy is self-sustaining and grassroots in implementation. Product development teams manage their own risk and share responsibility for uptime; so they begin pushing for slower velocity or more testing, as they don’t want to risk stalling a launch, and encourage a culture of quality by having developers challenge each other so they can get high-priority changes out the door. And if the expectations around availability are too high and throttling the pace of innovation, the error budget can be increased by stakeholders. Outages are recognized as a cost of doing business; postmortem discussions with stakeholders become much less toxic and more focused on increasing MTTR.
It also doesn’t attempt to change human nature or assume either bad or good intentions. It gives the same incentive to both devs and operations people; how can we maximize reliability so we can release more?
We love the idea of an error budget and wish it was used more often. It’s fascinating that Microsoft and Google faced the same problem with runaway code / spiraling technical debt and resolved it with caps using two entirely different metrics – Microsoft capped the number of bugs as a ratio to the number of engineers; Google focused on meeting a SLA as a percent of availability. Both ended up being valid; both show the benefits of making numbers the issue, not teams or people.
Have development teams share the pain of production support
At Google, this works by having a common staffing pool for SRE and the development team. Excess work (i.e. a creaky, unreliable service) overflows to the development teams once it passes the operational workload limit – more on this later. And at least 5% of production support is handled directly by the devs. Ben Treynor has brought out that there is no shortcut for this – without handling at least some production support workload, it’s a natural tendency for developers to lack empathy and think support is easy. Some pain has to be experienced by the development teams for SRE to work.
This is the one issue where you will likely get the most resistance; developers will come up with all sorts of creative and dramatic reasons why production support is a no-go for them. The underlying fear here is that their lives will shift from coding to support, 100%. Thankfully, this is rarely or never the case; Ben noted that after 6 months of engaging with SRE teams and handling support, the dev teams he’s worked with can’t imagine doing their development work any other way.20
One of our favorite sayings comes from the unofficial SRE motto at Google: “Hope is not a strategy .” We’ll get into this later in the book, but SRE teams take disaster planning and wargames very seriously. SRE teams constantly look for possible sources of outages, trying to get ahead of incidents before they lead to outages. Annually, they perform Disaster Recovery and Training (DIRT) drills to stress test production systems and try to inflict outages, looking for weak spots in their critsit handling and their ecology. And many of these events are treated as open labs where critsit triage and recovery approaches are discussed openly, ensuring that first responders are better informed and supported.
Cap operational workloads
Without constant engineering, operations load increases and teams will need more people just to keep pace with the workload. Eventually, a traditional ops-focused group scales linearly with service size: if the products supported by the service succeed, the operational load will grow with traffic. That means hiring more people to do the same tasks over and over again. To avoid this fate, the team tasked with managing a service needs to code or it will drown.
…So how do we enforce that threshold? In the first place, we have to measure how SRE time is spent. With that measurement in hand, we ensure that the teams consistently spending less than 50% of their time on development work change their practices. Often this means shifting some of the operations burden back to the development team, or adding staff to the team without assigning that team additional operational responsibilities. Consciously maintaining this balance between ops and development work allows us to ensure that SREs have the bandwidth to engage in creative, autonomous engineering, while still retaining the wisdom gleaned from the operations side of running a service. 21