
It’s halfway through spring, and the delivery teams at WonderTek are just starting to realize how much of their work is falling between the cracks.
That’s not saying there haven’t been some encouraging signs of progress. By setting up and enforcing blame-free postmortems, they’ve made significant headway in encouraging a culture that is more focused on learning from mistakes instead of punishment, blame, and evasion. They’re cutting down the time they spend on dead ends and red herrings by treating their development stories and features as guesses – experiments – bets that they can either double down on or abandon if they don’t hit predetermined marks.
By far, the best changes are in the fundamental way that Operations and Development are learning to work together. Ben and Emily are starting to show a commitment in the things valued by their other partner – well coordinated and thought out release plans by Ops and delivery retrospectives and planning by Dev. Having displays everywhere that focus on business-centric KPIs like response time, availability, and defects is having a subtle but penetrating effect; developers and operations are starting to see problems from a common, global point of view.
As positive as these developments are, there’s still so much work left undone. Engineers are still drowning in tickets turfed to them by Operations, who are using a completely separate ticket queue. Security is still an afterthought. Most seriously, a seemingly positive and long-overdue development – a true value stream map – threatens to break up that fragile truce that he and Emily have established.
It’s clear that testing and quality, which used to be the limiting factor in their delivery life cycle, has become much less of a problem. Taking its place as a constraint is infrastructure – the time it takes to spin up environments and configure them properly. WonderTek is still very much a political swamp in many ways, and old habits die hard. Will that tenuous working relationship between dev and IT fall back into the old game of finger pointing and blame?
Leaner and Meaner (Small Cross-Functional Teams)
Karen’s audit and the aftermath hit us like a bomb. It was like somebody had poked a stick into an anthill.
Emily and I had talked with Karen shortly after her presentation, and we started to form a plan. Over the next few weeks, I was very busy talking to security and our architects, often folding Karen in over the phone. I also stepped up my discussions with Tabrez. I felt confident that once the audit report appeared, we’d be ready.
A few weeks later, the audit report came in. Thankfully, it wasn’t a tree-killing dictionary of “best practices” – just a few dozen pages summarizing Karen’s assessment of WonderTek’s delivery cycle and some simple steps she recommended to resolve our current delivery bottleneck. Most of this was around infrastructure.
In the old days, not so many months ago, getting ammunition like this to use against my rival would have been cause for rejoicing. But Emily and I have been having lunch or coffee together a few times a week, and she and Kevin have been incredibly busy trying to wrap his arms around how to best create immutable infrastructure on demand. Somehow, I can’t find it in myself to start putting in the dagger on a problem that both of us share.
Not that there aren’t temptations. During my weekly 1x1 with Douglas, he brought up the audit again, and you couldn’t have asked for a better opportunity to throw IT under the bus. He begins by complaining, “You know, I told you a year ago that WonderTek just isn’t ready for this DevOps thing. I think we’ve gone a bridge too far here, Ben. It’s time to scale this back, we shouldn’t have to deal with this much stress and friction.”
I have to walk cautiously here. Douglas has a point that there’s a strong undercurrent of suspicion that “this DevOps thing” is a fad, and we’ve gotten a lot of resistance. I’ve been very careful to narrow my focus to specific workstreams, not even using that loaded (and imperfect!) word “DevOps” in any meetings. Instead, I put things in terms like “delivering value,” “driving efficiency,” or “eliminating waste.” We’ve found that if we keep a laser focus on delivering business value and streamlining our release pipeline, and back it up with monitor displays of our current and desired future state, we win. But if it comes across as a dev-centered movement around better tooling or process refactoring, it falls flat.
I tell Douglas that we aren’t trying to do DevOps – just straightening out the kinks in the hose that are preventing us from delivering value. This particular morning, that isn’t working for me. He stares at the ceiling, eyelids half closed, jaw jutting out. “Don’t piss on me and tell me it’s raining, Ben. I’m telling you, every organization has a turning radius. WonderTek isn’t a sportscar, it’s a supertanker. You’re risking the ship by trying too much change, too fast.”
I get the message, and I’m concerned about where this is coming from; we’ve been very careful with our bets and have tried to keep a low profile. He’s evasive about where he’s getting this information, and ultimately it doesn’t matter; I have to bring our attention back to the future we’re trying to create and leave the office scuttlebutt alone. I reply, “You’ve read the audit – the numbers speak for themselves. We don’t have an Ops problem, or a Dev problem, or a PM/BSA problem – regardless of how people try to frame things. The issue is the blinks – the spaces in between these different delivery groups. If you want faster and better delivery of value, we need to seal those gaps.”
I just get a groan in response; his eyes are still on the ceiling. Time to try a different tack. “Douglas, you’re a military guy. What do you think about Grant’s campaign at Vicksburg during the Civil War?”
This gets his attention, and he arrows a sour look in my direction. It’s an irresistible gambit; Douglas loves military history and especially the Civil War. He slowly says, “Vicksburg? Ah, that was kind of genius. You know, people think General Lee was the dominant military genius of the war, but I always say that if those two men had switched places, Grant would have acted exactly as Lee had. Both could take great risks when they needed to.”
Bait taken! “If I remember right, Grant didn’t succeed the first time, did he?”
“Ha! No, far from it. He failed so many times. He had to cross the Mississippi river against a prepared enemy that outnumbered him. First he tried approaching from two sides; that failed, twice – then he tried digging canals to bypass the city’s forts, which failed… shoot, had to be a half dozen different things he tried. All losers, and it cost him months.” He’s starting to warm up and then catches himself. “Why?”
“What ended up being the winning formula for Grant?”
“Ah… well, he did the bold and unexpected thing. He risked crossing the river, completely away from his supply lines and any hope of retreat, and fought a series of battles away from the city that forced the enemy commander to make guesses. His opponent guessed wrong, and the North ended up defeating them in detail. It was the biggest turning point of the war, in my opinion.”
I’m not Douglas’ match when it comes to history, but I have read enough to try to make my point. “So, let me put this to you – Lee said Grant would ‘hang on like a bulldog and never let go.’ Grant’s greatest quality was persistence, even when things looked grim. Grant tried, what, six different approaches at Vicksburg and they all failed miserably – everyone but the last. Any other general would have quit months earlier. Can we take a page from his book and show some persistence and courage here? To try to do something different?”
The sour look is gone; Douglas looks intrigued. “You mean, Karen’s SWAT team recommendation?”
“That’s exactly what I’m talking about.” I open my tablet to that page of the report:
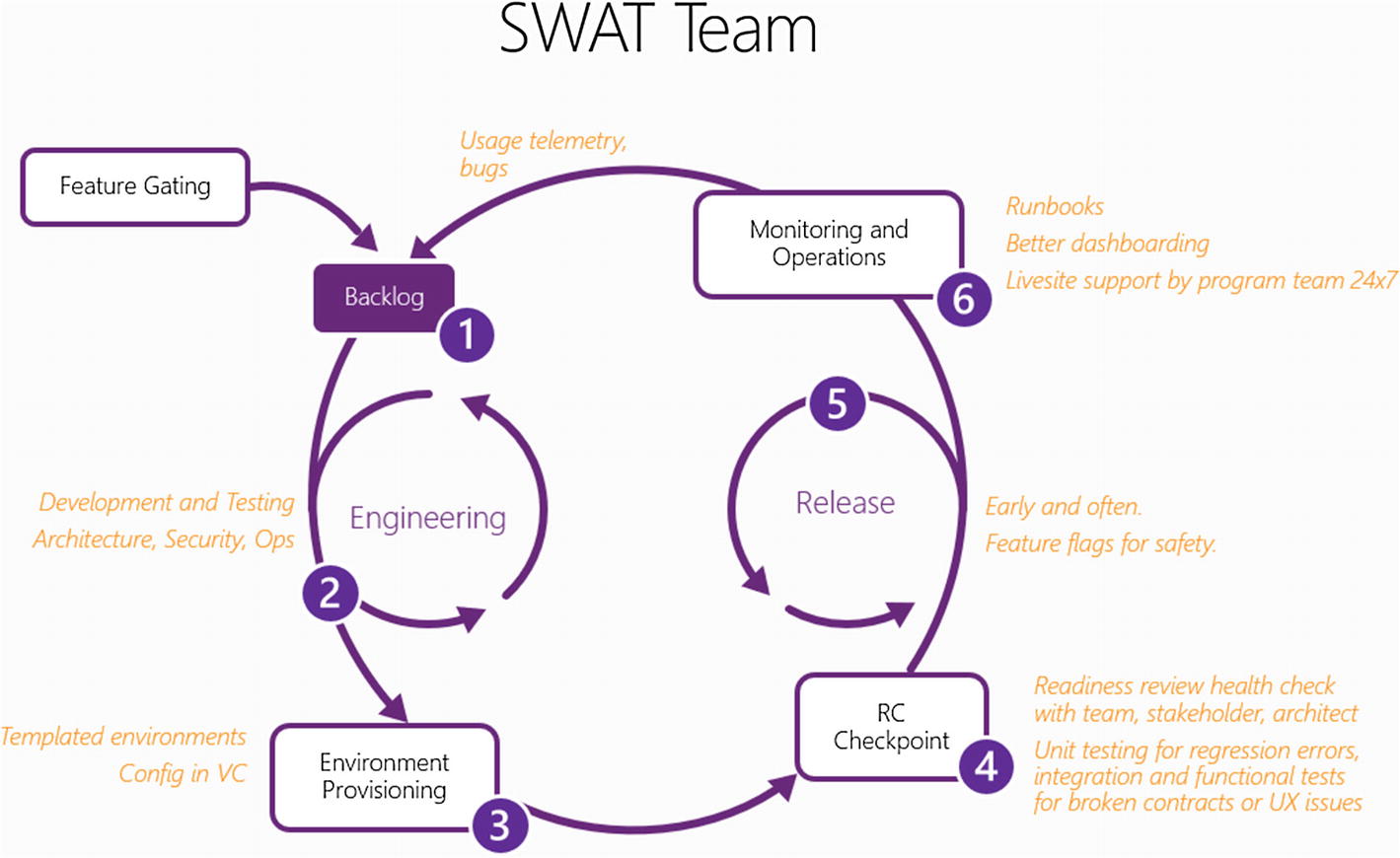
“Karen is proposing that we try something new,” I continue. “She’s asking us if we’re ready to cross the river. The report proposes that for our future releases with Footwear, we try using a very small team – like under 10 people – that can deliver a single feature end to end in two weeks. With this, we close the ‘blinks’ – we should have none of the delays or lost information and rework that we’ve suffered in every release in the past.”
I build up some steam as I continue talking about some of the benefits; it’s something Emily and I are starting to get excited about. We already have a lot of the building blocks in place with better version control and continuous integration.
Better yet, I might have some very powerful allies in the wings. I know that our architects – who always complain about being brought in late or not at all – are very enthusiastic about this as a concept. We’re still working out how this might look, but it could be in the form of part time involvement – maybe a day each sprint, more if needed – by an architect embedded with the product team directly. Security is also onboard; they’re thinking about a similar engagement model, where they give us some best practices training on folding security in as part of our development life cycle. Music to my ears, they’re even floating ideas around about making this as painless as possible to implement by creating a community-curated security framework.
As I expected, this resonates with Douglas as we’re talking better-integrated teams – and reducing the hassles and static he gets from both of these very vocal groups. Still, the core problem remains. “Ben, what worries Emily and I the most is how this report is sandbagging on her IT team; it’s divisive and doesn’t take into account how hard her people are working. And Karen’s recommending that we make the jump to the cloud, which is off the table. It’s a massive security risk, not to mention throwing away the millions of dollars we’ve invested in our own datacenters. Yet this is one of the key recommendations in the audit – saying moving to the cloud is the only way we’ll be able to deliver truly scalable and resilient infrastructure in the timeline that Footwear is wanting. That’s just not based on reality, at all.”
I’m going to need to sidestep a little; any mention of the cloud provokes a strong allergic reaction from anyone at IT and Operations. But I also know how long it takes us to spin up a single VM and get it configured correctly, and the beating our availability takes due to untested patches and configuration changes that are impossible to roll back. I’m convinced that Karen is right; we are going to have to step away from our supply lines and try something new. My guess is, if we empower our teams to handle end-to-end support and deployments and not mandate one specific platform, exactly where our services are hosted will cease to become such a contentious question.
“Karen recommended that we have at least one and preferably two Operations specialists on each team,” I reply. “That’s like a quarter of the team, Douglas – so it’s not like Emily’s people aren’t being involved enough. Just the fact that we’re going to be in the same room and talking to each other is a huge win. When it comes to the cloud – I agree with you, whether the apps run there or on our own datacenters is not the question to be asking. I think we should have as a goal that faster end to end delivery cycle that Tabrez is asking for. Anything that gets in the way of that turnaround needs to be eliminated, without remorse.
“Right now our scoreboard is saying we’re taking 9 days for each release, but that’s just out the door to QA. That’s not the actual finish line – when our bits make it out the door to production. And you know what that number actually is – we’re talking in months, not days. 23 days of work – and 53 days of delays due to handoffs. I think we can cut that delivery time in half, or better, if we adopt some of Karen’s proposals.”
There’s a pause for a few seconds as Douglas scans me. “Have you talked to Tabrez about this?”
“Yes. He’s totally onboard. He has a space available – a large conference room, really comfortable, big enough to fit 20, right next to his designers there in Footwear. He loves the thought of having the team close by and accessible.”
“I’ll bet he does.” Douglas groans again, “You realize you’re opening up your team to all kinds of problems, don’t you? They’re going to be interrupted ninety times a day now with Tabrez and his people stopping by with their little requests.”
“Maybe.” That’s something else I haven’t thought about; I like our little cocoon of silence. Was that mystery voice right – am I introducing more chaos in our work patterns than we can handle? I decide to brazen it out. “Our thinking is, the closer we can get to the customer, the quicker we can understand what they really want. I’m confident they’ll play by the rules, and personally I’m excited about seeing them more at our retrospectives as stakeholders. I’m getting pretty tired of presenting our work to an empty room, Douglas.”
“Mmmmm.” Douglas is looking back at his monitor display. “You know, I don’t agree with everything Karen said, and I agree with Emily that she should have talked more to senior management ahead of launching this little bombshell. But, I like the thoughts in here about first responder training. I know for a fact that our customers are complaining about their tickets waiting around for days or weeks for a developer to get to them; we’d be much better off if we could knock down the easy stuff in a few minutes. You know, I’ve said to Ivan a hundred times, having his team act as some kind of glorified turnstile that churns out bugs isn’t helping us at all. Lack of good triage has always been a pain point.”
I propose a weekly review where the team can present progress transparently. “Let’s be up front and tell people that this is an experiment, an open lab. We’re going to be trying some new things and making some mistakes, and we want to share our wins and losses openly with everyone. For example, how do we use feature flags? We think it’ll really help us be able to safely toggle new functionality on and off so our releases will be less disruptive – but that’s just a guess right now. And what about monitoring – do we go with a vendor or roll our own? How do we set up dashboarding so everyone is looking at work the same way? How do we fold usage data back in to our backlog prioritization before each sprint? What about – well, you get the idea. We’re going to try a different approach, because we’re wanting a different result.”
It takes another hour of back-and-forth negotiations, but I walk out with what I needed. We’re going to give the SWAT team a 3-month try. Our judge will be Footwear; if after 3 months the needle doesn’t budge or if there is excessive thrash, Douglas will pull the plug.
McEnvironments (Configuration Management and Infrastructure As Code)
Like I said, Kevin and Emily had been talking about immutable infrastructure. But talk it seems was still a long way from action, and for the next few weeks we suffered through incident after incident caused by environmental instability.
First, we had a charming outage caused by a distributed denial-of-service attack against our DNS nameservers; it took some scrambling to figure out what was going on, and a few days more to figure out a fix with our caching and a failover strategy for what had become a sneaky single point of failure for our network. Then, we had one of our production services not restart after the host servers were up-patched; our monitoring missed that completely. In an embarrassing repeat of the Footwear services abend a few months earlier, it took some customers calling in to realize that the service was unresponsive and force a restart. And we kept having to spend valuable time determining if an issue was code related or environmental related. As none of our environments really matched each other as yet, piecing together what had happened and when took much longer than it should. If I was to take George and Alex at their word – easily 75% of our ticket resolution time was spent isolating problems and turfing server or environmental-related problems back to Operations.
This made for a somewhat chilling impact on my lunches with Emily; no doubt, she was getting an earful from her people as well. After our postmortem on the DDoS attack, Emily agreed quickly to a powwow on our next step with infrastructure as code.
I got in a little late, just in time for Kevin to hit his concluding remarks. “Alex, Ivan and I have been looking over our production-down issues from the last three months. It’s very common for networking elements like routers, DNS, and directory services to break our services and apps in prod, as well as causing ripple effects with our network availability and performance. Our recommendation is that we beef up our network monitoring software to catch these issues while they’re still in a yellow state, and make sure that every time a connection times out or is closed our apps need to be logging warnings. And our test environment topology needs to be beefed up so that we’ve got more assurance that what works in QA will perform similarly in production.”
Alex nodded. It was a good sign that he and Kevin were sitting next to each other and both relatively calm. “One other aspect that Kevin and Emily are in favor of is making sure every part of our networking infrastructure is in version control. That means that we need to make sure that our switches, routers, everything can be externally configured, and that we are able to roll out changes to these elements using code. That’s true of a lot of our infrastructure but not everything; it’s going to be a gradual process.”
If this is like our move to version control, I’m confident that what seems to be an overwhelming task will end up being triage. We’ll take one batch of networking elements at a time, starting with the most troublesome, and gradually isolate out and shoot the parts that can’t be configured and updated externally. Just the fact that we’re talking about automation and infrastructure as code is a positive step. Still, this isn’t a postmortem about one isolated incident; I’m hoping that we can begin a larger discussion around enabling self-service environments. After saying that, I offer up some tech candy: “Do we have the tools we need to recover faster from failure?”
Ivan snorts. “You’re talking about configuration management, right Ben? Well, we’ve had Puppet here for about three years. We spend a fortune on it with licensing every year, and frankly it fails more often than it works. If we can’t get it to work reliably outside of ad hoc script commands, we’re going to scrap it in favor of something cheaper.” His tone is flat and emphatic.
A few more ideas get batted around of different software solutions. As people talk animatedly about their own pet favorites – containers, Packer, Terraform, Ansible – I stay silent and absent-mindedly swirl my coffee cup around. I keep thinking back to that value stream map that’s taunting me from the conference room; 53 days of delay caused by handoffs and delays in provisioning infrastructure. The problem isn’t that Emily’s team is lazy or incompetent; I know from my visits over there that they’re constantly under the gun and putting in long hours. The problem is that gap, the blink between the developers needing new environments and the way software is built out at WonderTek. We need to figure out a better way of closing the gap, something that can please both sides. I’m not convinced that new software would actually help, but my guess is that it’s our use of that software – our process – that needs to get tightened up.
I look up from my coffee cup just in time to catch Emily giving me a significant look. We’ve been talking about better ways of configuring our servers over the past few weeks. She reaches out and pats Ivan on the hand; it’s not a condescending gesture, but it does get his attention and stops him mid-rant. “I’m not sold on the idea of Puppet being a loser yet, Ivan. Right now, we’re running Puppet on an ad hoc basis, for a few workstreams in our portfolio. And we use it to maintain an asset library and catch licensing compliance issues. That’s a good start, but I think we need to trust the tool more, and use it like it’s designed to be used.”
Ivan is incredulous. “Emily, we’ve never been able to get it to work. It seems to break down after a few weeks on any of our servers, and it’s a nightmare trying to find out what the proper template is for our environments. Sorry, but configuration management given our working constraints – and the constellation of servers and environments we have to manage – is a dead end.”
Alex’s eyebrows go up at this conversational hand grenade, but before he can get a word out Kevin speaks up: “Agreed, it’s going to be challenging finding the proper source of truth with our environments. But we all know that configuration drift is a problem that’s not going away, and it seems to be getting worse. Puppet – really any configuration management tool, but that’s the one we’ve got – is purpose built to fix this problem.”
Alex chimes in, “We had to force ourselves to use version control as the single point of truth for all our application builds. Yeah, it wasn’t easy, but we started with the most fragile, important workstreams – and one at a time, we put up some guardrails. We didn’t allow any manual config changes and used our CI/CD release pipeline for any and all changes, including hotfixes. No change, no matter how small or how urgent, was allowed to be rolled out manually. Could we use the same approach in managing our infrastructure?”
Ivan puffs out his cheeks in disbelief and says slowly, “Once again, we can’t get it to work. It breaks. What works on one app server, doesn’t run green on another – the Puppet run fails, and we even had a few servers go down. And we’re too busy to invest more time in this. Now, maybe if we had the people I’ve been asking for…”
Emily is drumming her fingers on the table. “Ivan, we gave you more people, three months ago. Is anyone here seriously arguing that setting up and keeping our machines configured using automated scripts a bad idea?” Ivan starts to speak, then snaps his jaw shut as Emily gives him a hard look. “On this subject, Ben and I have been in agreement for some time. If we tighten things up so we run our environments through the same release process we do code – with a pipeline, one we can roll back or inspect – I’m betting we’ll knock out most of the trouble tickets your team is loaded down with, Ivan.”
Kevin says, “What would happen if we let Puppet run unattended across our entire domain?” There’s now a few people shaking their heads no; there was just too much variance for this kind of a switch-flip to work. He squinches up his face a little, in thought. “OK, then we run this in segments. Let’s take a single set of servers handling one workstream – make sure that our configuration definitions are set and work properly, and then we let Puppet run unattended on them. If that works, after two weeks, we start rolling this out to other batches.”
Ivan is fighting a rearguard action now; he allows that, if Kevin is willing to try this experiment first with the apps he’s managing, including Footwear, then perhaps it wouldn’t be a complete disaster. I suppress an irritated twitch to my mouth; Ivan’s fear of automation is almost pathological. I keep telling myself that servers and environments are complex and unsafe, with lots of moving breakable parts; his caution is a learned behavior from years of dodging hammers.
If this gets us to where our environments are more consistent, it’s a big win. Perhaps, I should be satisfied with that, but there’s still that vision of true end-to-end responsibility, where the SWAT teams handle both production support and maintain their own set of environments. There’s so much left to be done for us to get to where we are self-service. It’s clearly the elephant in the room; of those 53 days of delay, most is wait time on provisioned environments. I could make my delivery promises with room to spare if we had more direct control and responsibility.
The thought of being able to create a new set of environments with a pushbutton script, without waiting weeks on the infrastructure CAB process and coming up with business case justification arguments, is just too appealing to pass up. Best of all, it’d give Emily’s infrastructure team a higher purpose and more rewarding work, overseeing and strengthening the framework instead of doing low-level work like spinning up VM’s manually.
However, Emily and I are not there yet, and I have no desire to continue pressing the point if it’ll cost us our gains. Last week, she told me point-blank that she didn’t think our developers can or should handle infrastructure support directly; she still clearly views provisioning as being the exclusive domain of her team.
I have to give her credit though – in a conciliatory move, Emily has been working with our cloud provider to allow us to select from one of three possible templates on demand. As a first effort, it’s a start, but these approved images are so plain-vanilla and locked down that Alex told me that they were functionally useless as true application servers. In a rare burst of humor, he called them “McEnvironments” – fast, mass-produced, and junky.
So, half a loaf it is. I’ll keep the pain points we have around provisioning environments visible. I’m convinced that over time those self-service options will become less rigid, and that core question – who has responsibility over creating and maintaining environments? – will be resolved in a way that will help free up the infrastructure team from tedious grunt work and help the coders take more ownership over the systems their applications and services run on.
An Insecurity Complex (Security As Part of the Life Cycle)
Brian, a balding middle-aged man who always reminds me a little of Elmer Fudd, sighs deeply. “Like I told you, this software can’t be released. Your version of Bouncy Castle has a weak hash-based messaging authentication code that’s susceptible to cracking.” He sees my blank look and tries again, his voice having just a tinge of a whine – “Your application uses a cryptographic API called Bouncy Castle; the version you chose is not on our list of approved versions, for good reason – we’ve known for several months now that it can be brute forced in just a few seconds by a hacker using a hash collision attack. It’s beyond me why you guys chose it.”
Try as I might, whenever I talk with Brian, I can’t help but think of Looney Tunes and “Wabbit Season”; it makes it nearly impossible to take what he says seriously. I swivel to Alex and ask: “I have no idea really what’s going on here, but Brian seems to think that we have a problem with our authentication library. How widespread is this?”
Alex is slouching in his chair, slumped in frustration. “For this application, updating this out of date library to a more current version is just a few keystrokes. Then we have to kick off a whole new round of testing – not that big of a deal, thanks to our shiny new release pipeline. But it’s not just this application – we have dozens to support, and we’ll have to check each one. Most of them don’t have any kind of a release pipeline other than walking over with a thumbdrive to Ops, and there’s no test layer to protect us. Honestly, it could take us weeks, more likely months. This is going to kill our velocity, Ben.”
The teeth-grating whine again, this time a little louder: “That’s hardly MY fault! We’ve asked you guys for months to do a little better checking on your deployments using the known Top 10 threats published by OWASP. That’s a basic level of competence, Alex. If you would have thought ahead even a little, this update would have been easy!”
I cut him off. “Brian, I’m convinced you have our best interests – and the safety of our users and our data – at heart. You don’t have to worry about us shooting the messenger; we’re better off knowing about this than living in ignorance.”
George interrupts, “I’m not so worried about this particular attack vector. I know this will get fixed, now that we’re aware. I’m worried about the next one. It seems like these vulnerabilities keep popping up more and more often. It’s causing us a lot of headaches, usually right before a release. And it seems like our dependencies are usually the vulnerable spot – stuff like this Bouncy Castle API. Brian, do you have any ideas on how we can get a little ahead of this?”
Brian says slowly and patiently, “Just the things you already know about. Your team needs to make security a first-priority concern. Right now it’s last, and that’s why this release is going to miss its dates.”
Brian may know security, but he doesn’t understand the repercussions of missing dates and how that’s viewed here. I counter, “Brian, I don’t miss dates. We can scale back on the features we deliver, but two things don’t change on my teams – quality and the delivery date. The business cares very much about getting what they need out on time. To me, something like this security bug is a quality issue. So, we’ll fix it – and we’ll make our date.”
George breaks in again. “Brian, help us out a little here. This isn’t something written in COBOL back in the 70’s. We’ve got a lot of cutting edge stuff packed into this site and it’s rolling out fully automated. We can make changes on the fly, safely – nothing is fixed in stone. So how can we get a better picture of these security gaps early on?”
Brian waves a pudgy hand and says dismissively, “Well, not knowing your code or anything about the design, I really can’t say. Just stick to what the checklist pointed out in my latest security scan.”
“Brian, that security scan is three weeks old,” Alex says, grating his teeth. “That’s a lifetime ago when we’re talking about software – how do I know that when you run your audit again, that we won’t have other holes pop up?”
Brian looks like he has Bugs Bunny staring right down the barrel of his 12-gauge shotgun. “You don’t. But I don’t think you want to get your name on the front page of the paper, do you? Or hear from management after I submit my report?” He gives us a self-satisfied, smug, almost sleepy grin. Classic Elmer.
Once we pledge fealty and promise to address this new vulnerability as our “top priority,” the meeting peters out and Brian shuffles off to his next victim. Alex throws his notepad at the whiteboard. “Dammit! We were almost there! Now, I have to waste days satisfying this bureaucratic nightmare of a checklist! And I guarantee you, that’s not the end of the story. He’ll find something else.”
I say, “You know, I’m not so sure. I’ve been talking to Erik about this – he’s a lot more helpful than Brian is, and it helps he’s an actual decisionmaker with InfoSec. They’re onboard with the idea of having someone from their team bundled up with our new SWAT teams, a half day a week.”
I get a suspicious sideways glance from Alex. “It’s not Brian, is it?”
“I don’t know. For God’s sake, let’s not make Elmer – I mean Brian, sorry – the problem here. He’s not telling us anything we didn’t need to know. We just didn’t hear it soon enough. Now, how are we going to get ahead of this next time?”
George looks thoughtful. “You know, we’ve been getting pretty slack lately with some of our basic hygiene. There’s no reason why we can’t gate our check-ins so that it looks for those top 10 vulnerabilities. That would give us early feedback – and it won’t allow checking in code we know is insecure. And it’s a lot more objective than Brian coming in at the 11th hour with a red octagon sign based on his vulnerability du jour.”
“Will this lengthen our build times?” Alex wonders, his brow furrowed. Alex watches check-in times like a hawk and is merciless about forcing developers to rewrite slow-running tests. He was the originator of the now-infamous “Nine Minutes Or Doom” rule at WonderTek – throwing a royal hissy fit and hunting down culprits if it took longer to check in code than it took to grab a cup of coffee from the cafeteria.
Both George and I chuckle, remembering the last particularly epic tantrum with great fondness. “No, it takes almost no time at all to run some basic security checks,” George says. “If we’re smart, we’ll need to augment this with some penetration testing. We can’t keep on trying to harden our apps when they’re 90% baked like this.”
I ask, “Isn’t this overkill? I mean, is there any information here that someone would actually WANT to steal?”
“On this app, no.” Alex smirks wearily. “This is what I mean – those security guys have a hammer, every single frigging thing is a nail. There’s absolutely no proprietary information here at all. No sensitive records, no socials, no credit card info, nada. We’re clean.”
“OK, so there’s no PI data. But we still have information in there we need to keep private,” George muses. “Otherwise it’d be an open system and you wouldn’t need to authenticate at all. At the very least, we need to make sure the user information we use for logins is protected and that the site itself doesn’t get hacked and users get directed elsewhere.”
I’m convinced this is a gap that we need to fill – and that it’ll bring a powerful advocate to my side. “I’m convinced this is a gap we need to fill. Security reviews need to be a part of every feature design – Erik will totally be behind that. But we can’t do it ourselves, and static scans aren’t enough. We need a better framework that’s preauthorized – make it easy on our guys to do the right thing.”
Alex says, “These guys see themselves as gatekeepers, Ben. They’re not going to want to sink time into being at our design sessions and looking over our deployment code.”
If we were talking about Brian, Alex’s assumptions would be dead on. Thankfully, Erik’s made of different stuff; since our talk he’s been five steps ahead of me, championing the creation of a curated framework that was community-owned and blessed by our security gods. But I just smile and say, “Give them some credit. I think they’re ready for a more cooperative model. I’ll meet with Erik later today and see what his thoughts are. I’ll tell him we want to do the right thing – and that we need his help. He’ll love that – especially if I make him think it’s his idea!”
Like magic, a few weeks later Brian starts appearing at our biweekly design sessions. The hated checklist stops making such frequent appearances as we begin folding in security scans into our check-in gating.
We’re still a ways away from a comprehensive security framework – but I trust Erik and I know it’ll come, soon. And now we’re getting regular feedback on security as part of our development life cycle.
Effective First Response (Automated Jobs and Dev Production Support)
Ivan takes a long slurp on his coffee and lets the silence build a little. As usual, his hackles are up. “Folks, I’m a little surprised to see this meeting fall on my calendar this week. We weren’t given any time to prepare and I don’t like the agenda, to be honest. Seems kind of dev-driven to me. Is this another pin-the-tail-on-the-Ops guy session? If so, I’m walking.”
Try as I might, our relationship with Ivan and his support team hasn’t thawed like it has with Emily; my charm offensive (such as it was) was stopped in its tracks. I’m not giving up yet on the campaign, but it does look like we’ve got at least one very vocal detractor who’s dug in.
I lean forward and say, “I appreciate your concern, Ivan – I’ve been in a few meetings like that here myself. This isn’t a blame session; we’re trying to figure out ways we can work together better in handling support.”
“Yeah, that seems like the same thing.” Ivan takes another long sip, drawing it out to show his contempt. “My people are already working very hard, round the clock, to try to support your crap. Forgive me for being blunt here, Ben, but it seems to me like you’re angling to shuffle more support work on my guys. That’s not going to fly with me, and I think Emily will back me up on that one.”
Tabrez, our Footwear stakeholder, now steps in. “I’m sure we’d all love another round of Ops and Devs playing tag, but that’s not the point. I called this meeting for one purpose. We’re seeing a lot of tickets lately with our new app; our customers are getting angry that these tickets just seem to sit there in queue, awaiting developer attention. And we’ve had a few high-profile outages that seemed to drag on and on. What can we do collectively to turn this situation around with our support system?”
The charts Tabrez displays tell the story, and it’s a grim one. “As you can see, we seem to be treading water. Our response time on our high severity tickets are getting worse, and those third tier tickets – things like customers getting authentication errors or timeout issues – they’re totally circling the drain. It’s taking us on average more than 10 hours to knock down these local issues, by which time the customer has often moved on to other, more reliable apps.
“I don’t even want to read to you the comments we’re getting in the app store for both Google and Apple – they could remove paint. Our ratings are in the toilet. We’re hemorrhaging customers. This just can’t go on.”
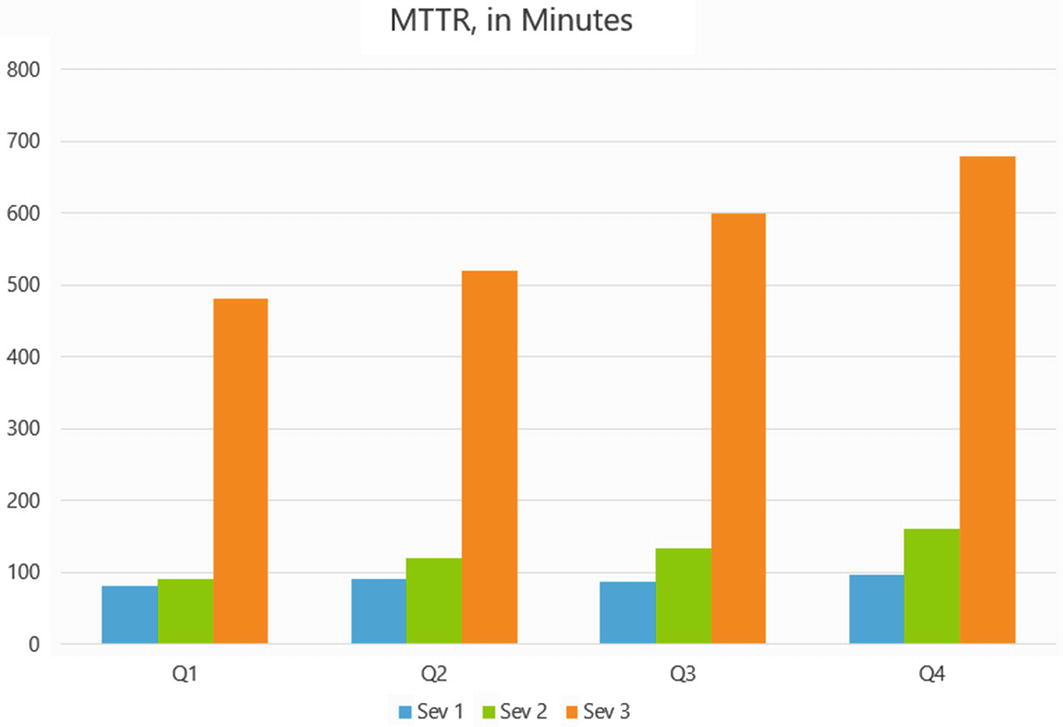
Ivan snorts derisively. “See, that’s exactly what I’m talking about. For this app, we received zero training. Ben’s team just dropped it on us, out of nowhere. And you’ll notice, the changes I instituted about three months ago are working. We’re processing more tickets than ever, and it’s automated – meaning less time per ticket by the Ops team. That’s nearly doubling our efficiency. We’re a multibillion dollar company with a global scope, and I have a lot more apps to support than just Footwear. I don’t think anyone here has any idea of how difficult it is to be in the firing line like we are, 7 days a week.”
I’m wearing my best poker face but have to fight not to roll my eyes. Ivan’s claims of weary serfdom and powerless victimhood are starting to wear a little thin. We did training, exhaustively, and Alex tells me that we’ve provided a list of “Top 10” issues that we expected Ivan’s team to help knock down.
“As you can see, our ticket numbers are escalating,” Tabrez says, continuing with the next slide. “If we view success narrowly as being ‘efficiency in intake of tickets,’ then maybe this is a win. But from the customer’s point of view, this is a disaster. We do need to provide true global support, 24x7, and if the ticket has to wait for the next available dev – that’s just too long for most of our customers.”

Ivan smirks derisively, looking thoroughly unimpressed. “Again, sounds like a problem for the coders to figure out. Reliability is all about architecture; maybe a better thought out design would give you the numbers you need.”
I say flatly, “We aren’t breaking out separately here the number of noncode related problems; we can do that if you want. I don’t think it’d be productive personally. But a large number of these escalations were caused by patches to the infrastructure. And Ivan, a win for us here has to be global. The tickets are spending too long in queue, and our first touches aren’t helping knock down easily triaged bugs – look at that flag green line there on the bottom. We need a better definition of success here, one that’s more customer-driven.”
“Well then, put your money where your mouth is, Ben. Start sharing the load. If you want better first-touch resolution rates, put your people in the call center.”
Tabrez and I start to laugh. After gathering myself, I say sunnily, “Great minds think alike! That’s exactly what we’re talking about, Ivan – sharing the load. What if we made support and reliability more of a commitment for everyone, not just your Operations team?”
Finally, the cat-with-a-mouse smirk was gone. “Still seems like an end-run to me. What are we talking about here exactly?”
- 1.
Noncode-related issues (OS patches, networking or config issues, or scheduled downtimes)
- 2.
Code changes or deployment-related issues
- 3.
Interrupts
I say, “That last one is important. These are the bulk of the service requests we’re seeing for the app. These are the Sev 3 tickets Tabrez mentioned earlier – user login issues, timeouts, caching problems. Most of these problems are small, and they’re repeatable – they could be fixed with a simple service restart or a job that updates login credentials for example. In fact, if we had those documented ‘Top 10’ issues available as automated jobs for your support team to remediate, almost 75% of these incoming tickets would have been resolved within 15 minutes. That’s very low-hanging fruit, Ivan. It’s a win for you, as we can close tickets faster. We’ll have happier customers – and my team spends less time playing Sherlock Holmes with long-dead tickets.”
Tabrez is smiling in agreement. “Ivan, up to now we’ve been defining success in narrow, localized terms, like lines of code delivered for devs; or availability and server metrics for Ops. We need to change our incentives and our point of view. Success for our customers means reliability, pure and simple. How fast can a user authenticate and get to the second screen of the app? That’s something they actually care about. And if there’s a problem – how long does it take for a ticket to get fixed? Not just put in a queue, but actually addressed and done? If we can fix this – we’ll get the app back on track and our user base will start growing instead of cratering.”
Ivan is smirking again; the well of sarcasm runs deep with him. “Yeah, like I said – an end-run. I love how you put noncode related problems up top. What about all those problems with deployments? What are you going to be doing to stop these bugs early on, Ben?”
I exhale in frustration; I’ve given it my best. “Ivan, cut it out. We’re trying to partner with you here so we can better meet our customer’s needs. So let’s drop the ‘tude. Here’s what we’re thinking – and this is a rough sketch at the moment, so everyone in the room here can come in with their thoughts:”
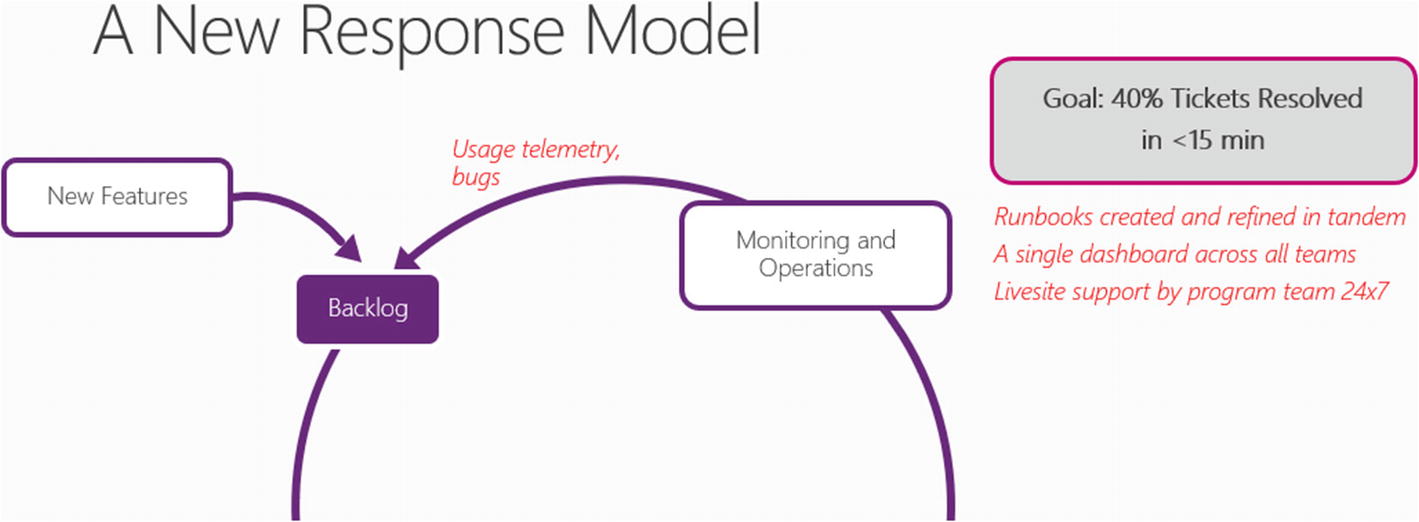
I continue: “You say we – meaning the devs – haven’t been stepping it up when it comes to production support; I’ll meet you halfway and agree with you. Right now everything you’re seeing in red doesn’t exist at the moment. We aren’t getting any usage information, bugs are flowing through untouched, and we have completely different metrics and dashboarding than your support teams. Even our ticket queues are separate.
“So let’s start over with a fresh approach. Let’s say I put some skin in the game. I dedicate two people on each team to handle livesite support. They work with your team, in the same room, and for 4 hours a day they take incoming calls. I think, with a little time spent in the foxholes, they’d have a much better appreciation of what it takes to create and support highly available software.”
I’ve screwed up. Emily, George and I have been going over this, but I forgot to include Alex – and now his mouth drops in shock. “Ben, you can’t ask us to do this. We’ll be stuck in the mud. Our people are very expensive, highly trained specialists. You’re yanking them into a call center? They’ll quit, Ben. And I shouldn’t have to tell you, it’ll take us months to find a replacement. A call center person takes a single phone call, and we can get them the next day – 16 bucks an hour.”
I tell him as best I can – we can’t continue begging for more coders and complaining about the tickets we’re drowning in and refusing to make any tradeoffs. “Ivan is right when he says we’re not doing enough. I want to try this – as an experiment.”
Alex says desperately, “Ben, once again, we’ll lose these people. No one wants to work in a call center. No one. For us to do our jobs effectively, we need to not be interrupt driven. Come on, you know how context switching works – it’s slow death for any programmer. I can’t imagine anyone on our team being willing to swallow this.”
I reply firmly, “We can talk about this later if you want – nothing’s been decided. But if we want something to change, we’re going to have to stop thinking of support as being some other person’s job. And you can’t tell me this isn’t costing us anyway. Last sprint, we lost half the team to firefighting on the third day of the sprint. What would you rather have – a 25% reduction in firepower, or 50%?”
Gears are starting to turn, so I press my advantage. I explain that we’ll rotate support on the team so no one is stuck with a pager full time. And the people embedded with the support teams will be spending at least half their time doing what they’ve always done and are best at – coding. This means automating those manual tasks – creating runbooks and jobs that can be executed single-click. I make some headway with Alex, but you can tell he’s still convinced we’ll see a mass exodus of talent once we saddle them with any amount of livesite support.
Ivan, for once, is also thinking. “So you’re to help with support. What’s this going to cost me in trade?”
“What’s it going to cost you? Information. We need information, Ivan, because we’re working blind right now. We need to know what’s working and what isn’t for our customers, and your team is closer to that source than anyone.
We need your teams to commit to using those runbooks as they’re created – and then help us make them better. We’re not trying to automate everything here – just the most common, manual tasks that crop up repeatedly. The kind of stuff that’s better done by a machine than a human being.”
Ivan isn’t smirking anymore, but he’s still deeply suspicious. “Really. Hmm. So if we go ahead with this – attempt – this means you’ll meet, every week, for an hour with us? We’ll go over all the bugs opened in the past week and work together on these automated jobs? Come on, Ben, some new crisis will pop up and you’ll flit off elsewhere. I doubt you have the attention span for this kind of effort. Really, don’t you think it’s smarter not to start?”
I tell him to put me to the test – for 3 months. We’ll experiment with creating these runbooks and a single queue displaying open support tickets that’s the same as the work queue for the devs. I even offer to pay out of my budget for new monitors in their war room. “And yes, the entire support team – that includes you and I – will meet every Monday for one hour and go over the tickets, just like you said. I’ll bet you a steak dinner Ivan – in 3 months, we’ll hit our target. That means 40% of our tickets resolved in less than 15 minutes.”
The only thing that kept Ivan in the room long enough to broker a deal was the fact that Tabrez was there. Even then, it takes a few more haggling sessions with Ivan – and finally a Come-To-Jesus moment with Emily – to kick this off as an experiment. I’d love to say it took off like a rocket, but Alex’s concerns about developer grumbling were well founded. Our first few rounds of support were a little ragged, and there was still too much cross-team sniping.
But in the end, no one walked out the door. There would come a time when it was hard to believe that we’d ever worked any differently; it made a fundamental difference in getting us a better connection to the customer and knocking down our firefighting costs. And best of all, I got to enjoy an enormous T-bone steak, medium rare, courtesy of Emily and Ivan.
Behind the Story
During this chapter, Ben introduces the concept of working in smaller-sized teams that have true end-to-end-responsibility, in an effort to reduce the waste they are seeing because of handoffs between siloed groups. The role of security as part of their “Shift Left” movement makes an appearance, as does improving their initial support and remediation capabilities through the use of runbooks and automated jobs. Let’s go into a little more detail on each of these topics.
Small Cross-Functional Teams
My own version of the networked system is small, multidisciplinary teams focused on solving a particular business challenge. As the requirements of the company shifts, the initial teams might be joined by more small teams, each tackling a different problem. …Simple physics tells us that change requires energy, and I think there is far more momentum created when people are minded to want to go in a particular direction rather than being told to. It’s heart, and not just head, supported by a big opportunity that people can believe in. – Neil Perkin 1
You know, I’m all for progress. It’s change I object to. – Mark Twain
The team’s first foray into a value stream map was way back in Chapter 2, in the section “A Focus on Flow, Not on Quality.” Now, months later, they’re doing a second pass. This actually isn’t unusual; in fact, it’s healthy to do a reassessment from time to time. It never ceases to amaze us what an immediate impact a simple sticky-note flowchart can have, especially on numbers- and results-oriented executives. Most of us have never seen what it actually takes in effort to move an idea from concept through to delivery. Value stream maps expose friction and gaps in our processes and can become a powerful catalyst for global-scope improvements.
We’re indebted to the books Making Work Visible and The DevOps Handbook for their much more detailed discussions on creating actionable and useful value stream maps. Making Work Visible in particular outlines an alternative approach that seeks to engage that vital upper stratosphere we’ll need to create lasting change. Instead of an outside agent proscribing a course as in our story, which can backfire badly, the committed leadership members are “locked into a room” and build the flow map themselves over several days. Having an enterprise diagnose itself using nonbiased elapsed time metrics – vs. a report coming from a disengaged outside party – creates a much better environment of buy-in and cooperation. Often, the coordinators will have to put on the brakes, forcing participants to finish mapping out the problem before driving to potential solutions – an excellent problem to have!2
Finding the Blinks
Ben’s proposal to Douglas in the section “Leaner and Meaner” gets the winning nod for a few reasons. First, this is a timeboxed trial period of 3 months only. After 3 months, if there’s not improvement, rolling the attempt back won’t come with a huge cost in terms of rep. Secondly, he did his prework. Soliciting and getting the buy-in from the architects and security auditors made for some nice trump cards in his discussion, and it will set the groundwork for a much better holistic solution down the road.
But the biggest single reason why the SWAT team proposal won out was that it had the strong backing of the business, Footwear. They’re clearly not happy with the cost, lack of transparency, and the effectiveness of the siloized process as it currently stands. Each group has been trying to do their work in a vacuum with a local mandate and criteria for success; with Tabrez’s backing, Ben can try as an experiment delivering value with very small cross-functional teams – and get feedback from Tabrez on a regular basis so they can make adjustments on the fly.
Ben is betting that if they break down feature requests to very small pieces of functionality – there’s only so much work that can be done with a 6–12 person team after all – and focus all their efforts on a successful release to production in 2 weeks, Tabrez and his Footwear customer base will start to see some improvements, and they’ll start to pick up speed in a meaningful, sustainable way.
We commonly see executives drilling into deep-level detail about the individual artifacts and steps themselves, even on the first few passes. However, the primary value of the value stream map is to expose, not what’s working, but what isn’t working – waste. This can be in the form of manual information flow, but more than likely – as we’ve mentioned before – this waste is happening as work is handed off to a separate team’s work queue – what was called “blinks” in the book Team of Teams.
WonderTek is no exception. Most of their waste has come in the form of delays due to handoffs. Ben is proposing a change where delivery is happening across a single cross-functional team. It comes with a cost; the delivery teams will have to accept directions from the stakeholder much more frequently, and the stakeholders will need to invest time into providing accurate and timely feedback, so the work stays on course.
This is comparable to a restaurant breaking down the walls between the kitchen and the seating area and having all the meal preparation happen in the open. This can be undesirable; it exposes a lot more mess and noise and can be limiting. However, many top-end restaurants have found an open and transparent kitchen to be a deciding factor in having a clean, safe, and productive working area; the lack of physical walls leads to a stronger connection between the people preparing the food and those enjoying it.
Expectations are being set up front that this is a learning opportunity and that mistakes will be made. There’s simply too much unknown at the starting line; they don’t know yet how to set up robust monitoring, or feed usage back to set priorities in their work. Runbooks and better job automation are still a blank page. Using feature flags is still an unknown space, as is templated environments for the most part.
Still, this is a huge turning point. A smaller team will be much tighter knit and lose less due to communication overhead than a larger bloated team. They’re getting early feedback from security and architects – meaning fewer heart attack-inducing surprises late in the game as the application is halted just before release for refactoring. Karen is proposing a readiness review as part of an ongoing effort – where the team, stakeholders, and architects jointly review self-graded scorecards and flag a few priorities to address over the next few sprints – meaning quality and addressing technical debt won’t be victimized by a single-minded focus on flow.
The SWAT Team Model
A separate offsite location. In this case, Tabrez is hooking the team up with a common work area very close to their end user base. Despite Douglas’ objections, we think a closer tie to Footwear will in the end be a net positive – there’ll be less delays in communication and the developers will feel and be seen as part of the business flow, vs. an isolated, remote group.
Work is visible, and there’s a single definition of value. WonderTek has already made some advances in this area; Karen’s proposal takes this even further. We can’t overstate the importance of displaying the flow of work and finding ways to continually make those displays powerful and omnipresent. Toyota made information radiators and omnipresent displays a key part of their Lean transformation. In the fight against Al Qaeda, General McChrystal broke down calcified organizational siloes with a constant barrage of information and huge war room displays in one common location.3 This new SWAT team will have large displays showing their key business-facing metrics everywhere as well. Operations might have special modules or subdisplays showing numbers like availability or CPU metrics, or page response time. Developers might have their own minidashboards showing bug counts and delivery velocity. But the real coin of the realm, the common language and focus, will be the numbers that matter to the business – in WonderTek’s case, cycle time, global availability, response time, and # of unique logins by month.
A common work queue. Bugs, feature stories, and tasks, and environment and configuration requests are all the same thing – work. Having a single queue showing work for an entire project across every delivery team will be key for them to expose cross-team blockers quickly and maintain that open, honest, transparent behavior in working with their customers. And as we discussed earlier in Chapter 4, there’s going to be a strong need to gate the work the team is acting on. BSAs and PMs will still very much be needed to help shape requirements into actionable work and ask the hard questions:
What business problem are we trying to solve?
How will we know we’re on the right track?
What monitoring do we have in place to gather this information, and what numbers do we need to track to confirm our assumptions and validate the design? 4
Hopefully, this gating will turn away a significant amount of work before a line of code is ever written. Studies have found that lead time – not the number of releases a day – is one of the greatest predictors of both customer satisfaction and employee happiness. A large backlog of work waiting in queue, which we used to think was a comforting sign of job security, is as damaging to a software delivery team as a huge inventory sitting on shelves are to a manufacturer.
A learning friendly environment. Besides a blame-free postmortem ethos that favors learning from errors, the team is committing to regular weekly demos that are open to all in the company. Some argue that having a single “DevOps team” is an antipattern; we do not agree. Past experience shows that having several pilot teams experimenting with DevOps is a much less disruptive and necessary part of the “pioneers/settlers” early on growth phase. One definite antipattern we’d want to avoid is exclusiveness; if this new team is showered with all kinds of attention and shiny new gadgets while the rest of the organization languishes as “legacy,” resentment will build. Treating this work as an open experiment can help spread enthusiasm and defuse potential friction.
Destructible, resilient environments. What form this will take is still unknown. Will the team use Chaos Monkey or Simian Army type approach to force high availability on their production systems? Will they explore Docker or Kubernetes? Will their architecture use worker roles to help with scalability? Will they end up using Chef, Puppet, or Ansible to help configure and script their environments and enforce consistency? All of this is still in the gray areas of the map still; but early on, with global availability being a very visible indicator, the entire team will be thinking of ways of taming their ecosystem problems.
Self-organizing, self-disciplining teams. They didn’t propose blowing up the organization – an idea completely above their grasp. Instead, each SWAT team is both small and virtual, with each team member having the same direct report they did previously. Ben for example might have two to three engineers on each delivery team that still reports to him, and he handles resourcing and administration. Architecture might have one architect spread out among five or six of these virtual teams, spending perhaps one day every 2 weeks embedded with them. And Emily’s IT team may have two or more people writing environment and configuration recipes alongside the developers; perhaps, over time as the need for new environments drops, their involvement could shrink to a single halftime IT admin on the team.
Are Shared Services Models a Dead End?
The point earlier about a virtual self-organizing team is important. The proposal doesn’t depend on breaking up the organization into horizontal small delivery groups – a reshuffle that isn’t always possible with many organizations. We’ve seen several examples of “virtual” cross-functional teams that have different direct reports – but still function as a single unit, with the same incentives and goals. This is imperfect, but workable, and far from a serious limitation.
As tempting as it seems, one cannot reorganize your way to continuous improvement and adaptiveness. What is decisive is not the form of the organization, but how people act and react. The roots of Toyota’s success lie not in its organizational structures, but in developing capability and habits in people. It surprises many people, in fact, to find that Toyota is largely organized in a traditional, functional-department style. 5
We do feel that having the physical org match the way software is being delivered is a powerful asset and works in line with Conway’s Law – as powerfully demonstrated by Amazon. Reshuffling the delivery teams, removing the middle layer to make the org more horizontal, and creating a new standard common title were identified by the Azure DevOps management team as key contributors to instituting real change and improving velocity. But we won’t be dogmatic on the subject; there’s too many winning examples of teams that made their delivery teams work without a complete reshuffle.
Every Azure DevOps program team has a consistent size and shape – about 8-12 people, working across the stack all the way to production support. This helps not just with delivering value faster in incremental sizes but gives us a common taxonomy so we can work across teams at scale. Whenever we break that rule – teams that are smaller than that, or bloat out to 20 people for example – we start to see antipatterns crop up; resource horse-trading and things like that. I love the ‘two pizza rule’ at Amazon; there’s no reason not to use that approach, ever. 6
You could argue that the decisions Ben made in this section should have happened much earlier. And perhaps, Ben missed an opportunity by not folding in the business earlier and taking a more holistic view of things. But, no one gets it perfect right out of the gate – and the pieces they put in place around source control, release management, and CI/CD were all necessary leaps in maturity they had to make to get to where global problems with delivery could be addressed. It’s hard to dispute with the careful, conservative approach of taking it one step at a time and choosing to focus first on what Ben’s team was bringing to the table.
You’ll notice, at no point did the proposal mention the word “microservices” or even “DevOps.” The SWAT team proposal is really a Trojan horse, introducing not just those concepts but also enabling a better way of handling legacy heartburn with the strangler fig or scaffolding pattern. Reasonably sized teams using services-oriented interfaces and responsible for smaller capsules of functionality are not far off from our ideal of Continuous Delivery and microservices, with little or no delays due to handoffs, unstable environments, or outside dependencies.
Configuration Management and Infrastructure as Code
Your greatest danger is letting the urgent things crowd out the important.
– Charles E. Hummel
Provisioning new servers is manual, repetitive, resource-intensive, and error-prone process – exactly the kind of problem that can be solved with automation.
– Continuous Delivery
Consistency is more important than perfection. As an admin, I’d rather have a bad thing done 100 times the same terrible way, than the right thing done once – and who the hell knows what the other 99 configs look like?
– Michael Stahnke
This book is written primarily from the perspective of a group of developers moving toward the DevOps model. We’ve discussed at length topics like peer review, Kanban, continuous integration, MVP, and hypothesis-driven development – all are coding-centric attempts to try to catch defects earlier and deploy software in smaller, safer batches.
Putting the onus on the development team was a deliberate choice. There’s a common misperception among the development community that DevOps means “NoOps,” and they can finally throw off the shackles of IT and manage their own environments independently. It’s important for development teams to realize that for DevOps to work, producing quality code becomes much more important. It’s a massive shift in thinking for most development teams to have to worry about customer satisfaction, feature acceptance, and how their apps are actually performing in the real world; ultimately, that’s what true end-to-end responsibility means. Far from “NoOps” or “ShadowOps,” coders will need to find ways to engage more frequently with their compadres that are handling infrastructure and operations support.
We’re only able to spend a few pages skimming the basics of configuration management software and infrastructure as code, a vast and fast-moving landscape. But it was important that we give it some consideration, as arguably this is the best bang-for-the-buck value that the DevOps movement offers. As our software has gotten better and containerization and cloud platforms have matured, there are fewer and fewer obstacles to having servers and environments maintained with code just as we would software.
…Even with the latest and best new tools and platforms, IT operations teams still find that they can’t keep up with their daily workload. They don’t have the time to fix longstanding problems with their systems, much less revamp them to make the best use of new tools. In fact, cloud and automation often makes things worse. The ease of provisioning new infrastructure leads to an ever-growing portfolio of systems, and it takes an ever-increasing amount of time just to keep everything from collapsing. Adopting cloud and automation tools immediately lowers barriers for making changes to infrastructure. But managing changes in a way that improves consistency and reliability doesn’t come out of the box with the software. It takes people to think through how they will use the tools and put in place the systems, processes, and habits to use them effectively. 7
And that’s the problem – we rarely give these people the bandwidth to think about anything beyond the short term. Most IT teams are suffering from the tyranny of the urgent, where important things that bring long-term benefits are constantly being deferred or shuffled to the back of the deck. As with the problems we’ve experienced with software delivery teams, the issue is rarely the people – it’s the processes and tools we give them to work with. Poor performing IT and Operations teams rarely have the capacity to think beyond the demands of the day.
As with software delivery teams, delivering infrastructure more reliably and repeatably comes down to better automation and better process. Having infrastructure teams track their work and make it visible in Kanban promotes transparency and helps drive tasks through to completion – and limits work in progress so people are not overwhelmed with attempting to multitask multiple critical tasks at once. Managers and orgs that truly care about their people will take care to track the amount of time they’re spending on urgent, nonvalue added tasks – what Google’s SRE movement appropriately labels toil – and make sure it’s capped so that at least 20%, and preferably 50%, of their time is spent on more rewarding work that looks to the future. Better process and tools in the form of infrastructure as code – especially the use of configuration management and scripted environments, containers, and orchestration – promote portability and lessen the problems caused by unique, invaluable, and brittle environments.
Either You Own Your Environments or Your Environments Own You
At his first day at one former assignment, Dave was shown his desk workspace. Oddly, there was an antique desktop computer humming away below his desk, but it didn’t appear to have any monitor display hooked up. When he asked what the desktop was doing under his desk, he was told, “Don’t turn that off! The last time we powered that desktop down, it shut down parts of our order processing system. We’re not sure what it does, and the guy that set it up left a long time ago. Just leave it alone.”
In the old way of doing things, we treat our servers like pets, for example Bob the mail server. If Bob goes down, it’s all hands on deck. The CEO can’t get his email and it’s the end of the world. In the new way, servers are numbered, like cattle in a herd. For example, www001 to www100. When one server goes down, it’s taken out back, shot, and replaced on the line. 8
Mainframes, servers, networking components, or database systems that are unique, indispensable, and can never be down are “pets” – they are manually built, lovingly named, and keeping these static and increasingly creaky environments well fed and happy becomes an increasingly important part of our worklife. Gene Kim called these precious, impossible to replace artifacts “works of art” in the classic Visible Ops Handbook; Martin Fowler called them “snowflake environments,” with each server boasting a unique and special configuration.
The rise of modern cloud-based environments and the challenges of maintaining datacenters at scale has led to the realization that servers and environments are best treated as cattle – replaceable, mass-produced, modular, predictable, and disaster tolerant. The core tenet here is that it should always be easier and cheaper to create a new environment than to patch or repair an old one. Those of us who grew up on farms knew why our parents told us not to name new baby lambs, goats, or cows; these animals were here to serve a purpose, and they wouldn’t be here forever – so don’t get attached!
The Netflix operations team, for example, knows that a certain percentage of their AWS instances will perform much worse than average. Instead of trying to isolate and track down the exact cause, which might be a unique or temporary condition, they treat these instances as “cattle.” They have their provisioning scripts test each new instance’s performance, and if they don’t meet a predetermined standard, the script destroys the instance and creates a new one.
The situation has gotten much better in the past 10 years with the rise of configuration management. Still, in too many organizations we find manually configured environments and a significant amount of drift that comes with making one-off scripting changes and ad hoc adjustments in flight. As one IT manager we talked with put it, “Pets?! WE are the pets! Our servers own us!”
What Is Infrastructure As Code?
Infrastructure as Code (IAC) is a movement that aims to bring the same benefits to infrastructure that the software development world has experienced with automation. Modern configuration management tools can treat infrastructure as if it was software and data; servers and systems can be maintained and governed through code kept on a version control system, tested and validated, and deployed alongside code as part of a delivery pipeline. Instead of manual or ad-hoc custom scripts, it emphasizes consistent, repeatable routines for provisioning systems and governing their configuration. Applying the tools we found so useful in the “first wave” of Agile development: version control, continuous integration, code review, and automated testing to the Operations space allow us to make infrastructure changes much more safe, reliable, and easy.
IAC is best described by the end results: your application and all the environmental infrastructure it depends on – OS, patches, the app stack and its config, data, and all config – can be deployed without human intervention. When IAC is set up properly, operators should never need to log onto a machine to complete setup. Instead, code is written to describe the desired state, which is run on a regular cadence and ensures the systems are brought back to convergence. And once running, no changes should ever be made separate from the build pipeline. (Some organizations have actually disabled SSH to prevent ad hoc changes!) John Willis once infamously described this as the “Mojito Test” – can I deploy my application to a completely new environment while holding a Mojito?
It took some bold steps to get our infrastructure under control. Each application had its own unique and beautiful configuration, and no two environments were alike – dev, QA, test, production, they were all different. Trying to figure out where these artifacts were and what the proper source of truth was required a lot of weekends playing “Where’s Waldo”! Introducing practices like configuration transforms gave us confidence we could deploy repeatedly and get the same behavior and it really helped us enforce some consistency. The movement toward a standardized infrastructure – no snowflakes, everything the same, infrastructure as code – has been a key enabler for fighting the config drift monster. 9
We keep beating the configuration problem drum, but we truly believe it is the root cause of many organizations’ software problems. Instead of treating configuration like a software development afterthought, treat it like the first-class citizen that it is. By solving the configuration problem, you ensure a consistent process which will inevitably lead you towards software that is easy to operate. 10
While in general we are not a fan of locking things down and establishing approval processes, when it comes to your production infrastructure it is essential. And since you should treat your testing environments the same way you treat production – this impacts both. Otherwise it is just too tempting, when things go wrong, to log onto an environment and poke around to resolve problems. …The best way to enforce auditability is to have all changes made by automated scripts which can be referenced later (we favor automation over documentation for this reason). Written documentation is never a guarantee that the documented change was performed correctly. 11
This was what Gene Kim was referring to when he spoke about “stabilizing the patient.” Keeping all the changes and patches the Operations team is rolling out as part of a script in VC and deployed as part of a pipeline means there’s a reliable record of what is being done and when, which dramatically simplifies reproducing problems. Having all your configuration information in version control is a giant step forward in preventing inadvertent changes and allowing easier rollbacks. It’s the only way to ensure our end goal of easier to operate software; this depends on a consistent process and stable, well-functioning systems.
It also keeps your Ops teams from going crazy, spending all their time firefighting issues caused by unplanned and destructive changes. Changes to systems change from becoming high-stress, traumatic events to routine. Users can provision and manage the resources they need without involving IT staff; in turn, IT staff are freed up to work on more valuable and creative tasks, enabling change and more robust infrastructure frameworks.
There is another very important, and often overlooked, reason for why you should use IAC: happiness. Deploying code and managing infrastructure manually is repetitive and tedious. Developers and sysadmins resent this type of work, as it involves no creativity, no challenge, and no recognition. You could deploy code perfectly for months, and no one will take notice – until that one day when you mess it up. That creates a stressful and unpleasant environment. IAC offers a better alternative that allows computers to do what they do best (automation) and developers to do what they do best (coding). 12
One often overlooked benefit is the way it changes the Development and Operations dynamic to a virtuous cycle. Before, when there was problems, it was hard to tell if the problem was caused by server variability or an environmental change, which wastes valuable time and causes finger pointing. And in “throwing it over the fence,” developers often miss or provide incomplete setup information to the release engineers in charge of getting new features to work in production. Moving to coding environments and IAC forces these two separate groups to work together on a common set of scripts that are tracked and released from version control. There’s a tighter alignment and communication cycle with this model, so changes will work at every stage of the delivery plan.
Infrastructure as code leads to a more robust infrastructure, where systems can withstand failure, external threats, and abnormal loading. Contrary to what we used to believe, gating changes for long periods or preventing them (“don’t touch that server!”) does not make our servers and network more robust; instead, it weakens them and makes them more vulnerable, increasing the risk of disruption when long-delayed changes are rolled out in a massive push. Just as software becomes more resilient and robust as teams make smaller changes more often, servers and environments that are constantly being improved upon and replaced are more ready to handle disaster. Combined with another principle we learned from software development – the art of the blameless postmortem – IT teams that use IAC tools properly focus on improving and hardening systems after incidents, instead of patching and praying.
For us, automating everything is the #1 principle. It reduces security concerns, drops the human error factor; increases our ability to experiment faster with infrastructure our codebase. Being able to spin up environments and roll out POC’s is so much easier with automation. It all comes down to speed. The more automation you have in place, the faster you can get things done. It does take effort to set up initially; the payoff is more than worth it. Getting your stuff out the door as fast as possible with small, iterative changes is the only really safe way; that’s only possible with automation.
You would think everyone would be onboard with the idea of automation over manually logging on and poking around on VM’s when there’s trouble, but – believe it or not – that’s not always the case. And sometimes our strongest resistance to this comes from the director/CTO level! 13
IAC and Configuration Management Tools
There’s some subtle (and not-so-subtle) differences in the commercially available products around IAC in the market today. Server provisioning tools (such as Terraform, CloudFormation, or OpenStack Heat) that can create servers and networking environments – databases, caches, load balancers, subnet and firewall configs, routing rules, etc. Server templating tools like Docker, Packer, and Vagrant all work by uploading an image or machine snapshot, which can then be installed as a template using another IAC tool. Configuration management tools – among which are included Chef, Ansible, Puppet, and SaltStack – install and manage software on existing servers. They can scan your network continuously, discover and track details about what software and configurations are in place, and create a complete server inventory, flagging out of date software and inaccurate user accounts.
Ansible, Chef, Puppet, and SaltStack all use externalized configuration files. Some (like Ansible) use a push model, where a central server pushes updates to servers. But most still use a pull model, where an agent on each server runs periodically and pulls the latest definition from a central repository and applies it to the server configuration.
Enterprises often mix and match these tools. Some use Terraform to provision servers and Chef to keep them configured properly. Others use Docker or Packer to create a library of images, which are then used as a source when new servers are rolled out with a tool like Ansible.
Using any of these tools gains reliability, reproducibility, consistency, and better governance over your entire system; new instances can be spun up on demand and changes can be pushed out en masse.
Which of these is best? We’d be doing you a disservice by anointing one of these IAC tools as the “best in class,” as these packages are maturing so quickly. There’s a bit of an arms race going on at the moment as each vendor tries to assert dominance and leapfrog the competition. And it only takes a little poking around to find out that the “best choice” is a highly subjective thing.
We interviewed several brilliant people from leading configuration management software companies in writing this book and expected them to have been very vocal and opinionated on why their particular software was the unequivocal best choice. No doubt they felt that way – but to our surprise, we kept hearing variations on the same theme: it’s not the software choice that matters as much as the process. Having people buy into the need for configuration management and IAC, and be willing to change the way they’re used to working, is far more important than picking a particular “best in class” vendor.
It feels like cheating to say “any of these will work for you” – though that might very well be true. We’ll just say about IAC and change management software what we say about CI/CD software: if your people feel they had a voice and were able to choose the best tool for the job, they’ll work hard to make it a success. If one single tool is mandated and forced externally upon IT teams from on high, it’ll end up being used incorrectly or not at all.
We can judge the effectiveness of an IAC team – not by the awesome capabilities of the configuration management system they’re using – but by results. For example, we know that a software development team is truly successful with CI/CD when they can handle change better; safety and velocity both go on the uptick. Lead time drops and as new requirements are broken down into bite-size pieces and rolled out frequently, minimizing the impact of change. Recovery time improves as monitoring, automation, and postmortem processes tighten up and harden applications, making them more portable and reproducible. Instead of MTBF, they focus less on avoiding failures and more on improving their recovery time, MTTR.
The same is true with how infrastructure and IT are managed in an organization. Highly effective IT/Ops teams are able to rebuild any element of infrastructure at a whim and with a single command – perhaps while holding a Mojito. The infrastructure team is never needed to handle common requests like building out a standard set of environments, and there’s no waste in the form of service tickets to external groups; environments can be tailored and provisioned within minutes by the teams themselves, self-service. Most work is done during the day; there is rarely or never a need for a maintenance window. Systems are up to date, consistently up-patched, and kept consistent with automated tools running constantly in the background. Failures are treated as an opportunity to learn and improve recovery time for the next incident.
If It Ain’t Within Minutes, It Ain’t Self-Service
In the ‘iron age’ of IT, systems were directly bound to physical hardware. Provisioning and maintaining infrastructure was manual work, forcing humans to spend their time pointing, clicking, and typing to keep the gears turning. Because changes involved so much work, change management processes emphasized careful up-front consideration, design, and review work. This made sense because getting it wrong was expensive. 14
There’s still more than a few Iron Age processes still lying about in many IT shops, even the ones that boast of cloud capabilities. These artifacts show up in various ways: teams are allowed one of a very narrow set of choices (such as a web server, app server, or a database server), but have no ability to customize or optimize these vanilla choices. Or a new environment request requires a detailed request form and specifications and an implementation plan, followed by a review period and weeks of delay. Even if the delay from creating a ticket to getting back login information is only a few days, this is far from an autonomous, self-service model. The end result is the same: environments can’t be spun up on demand, quickly and with a single command, and they can’t be customized to fit the needs of the solution.
Here, our old friend from Chapter 4 – the value stream map – again proves its worth. Make sure the time it takes to provision environments is mapped out and kept visible. This will tell you where to invest your energy: if making a change takes 45 hours to make it to production, and tasks that can be automated only take up an hour of this, there is little value in sinking time and money into speeding up automation. And remember that we are looking for wait time and wastes due to handoff; it’s not uncommon that 95% or more of cycle time for a task or change is spent waiting on other requirements. So, a “cloud-ready” infrastructure team may boast a 5- to 10-minute turnaround time to stand up a new environment, but the actual turnaround time to from when an environment is needed to when it’s fully available could be much later. It’s not unusual to see that 10-minute turnaround time, once we factor in the time it really takes to get that environment ready – filling in a business case and a request ticket, setting up networking and adding user accounts, and performing post-provisioning testing – is actually better measured in weeks.
One large organization … started their DevOps initiative by trying to understand how long it would take to get up Hello World! in an environment using their standard processes. They did this to understand where the biggest constraints were in their organization. They quit this experiment after 250 days even though they still did not have Hello World! up and running because they felt they had identified the biggest constraints. Next, they ran the same experiment in Amazon Web Services and showed it could be done in two hours. This experiment provided a good understanding of the issues in their organization and also provided a view of what was possible. 15
Infrastructure as code requires that teams have the ability to use scripts to automatically provision resources and custom fit it to their needs, instead of having centralized teams act as gatekeepers. Provisioning a machine should not require any human involvement; there should never be a need to create a ticket or a change request, and provisioning requests should be handled within minutes at most. As Carla Geisser from Google put it: “If a human operator needs to touch your system during normal operations, you have a bug.”
If your IT department claims to have self-service capability but still requires days or weeks for approval and provisioning, it’s quite likely that either an overly rigid cloud provider agreement, a threadbare resource pool, or antique Iron Age manual processes are holding them back. These need to be reexamined for infrastructure provisioning to be truly on-demand and able to keep up with the pace of application development.
Golden Image Libraries and Immutable Servers
One concept in many DevOps books from a decade ago that has not weathered particularly well in practice is that of the concept of the library of golden images. We know it’s much easier to operate and govern complex systems if we keep the variance to a bare minimum. With a very limited set of available images to select from, as the theory goes, it should be much easier to troubleshoot and keep configurations from drifting. This also fits the traditional way IT teams have worked; architects come up with a single “optimal” server environment to support web services or a database server, and this design spec is handed off as an approved, fixed template; any variance is verboten.
The library of golden images sounds like an excellent idea in theory; in practice, we’ve found most enterprises pay lip service to the concept but found it difficult to implement. Part of this has to do with the nature of self-service and on-demand provisioning as we discussed in the previous section. Teams need to be able to take responsibility for their own environments, and – unless lack of governance is demonstrably hurting the org – tweak them as they go, so they are optimized for the applications they support.
It’s a common misperception that every time a code deploy happens, every target server environment should be destroyed and rebuilt. In this strategy, servers are immutable; nothing is changed, any new build requires a complete teardown and recreation of environments from that “golden” set of images. There’s no question that this practice will increase predictability and offers a cleaner slate. Although there’s nothing wrong with immutable server theory and some enterprises have found success with it in practice, others have found it to be unacceptably slow as part of a code delivery cycle. A typical team doing CI/CD might be deploying dozens of builds a day; building a new server template for each build might be impractical.
There’s always a strong pull to this concept of a set of golden images. Of course this is a solid concept but in actual practice, many companies struggle with it. Much like the container wave – they’re immutable, you build them, it does its thing, and then you kill it. But this assumes a level of maturity and rigor that most orgs can’t handle. Even in the cloud, most simply aren’t ready for the rapid creation and destruction of resources like this, and you get old defunct instances spiraling out of control, a maintenance and governance nightmare.
A common misunderstanding is that you need to rebuild your environments every time you do a build from that “golden image” template. Well, if it takes you 45 minutes to install software on a system, no amount of automation will make that go faster if you’re installing from scratch every time. We say, build it with a tool – a dry run build – and use that to snap a chalk line: these are our build times on this date. Now you have your first step, the image creation process. But you won’t do that every time, that’s just a process you will run on a regular schedule – perhaps daily, or weekly, or monthly. To cover the gaps in between destroying and recreating these images, you go to step 2 – configuration management.
Run software that detects variances and enforces it, bringing your systems in line. If you don’t follow something like this process, almost immediately you’ll have drifts. How our software works at Chef is – you form a policy set, configure your system to match that, detect changes and correct them. Four phases essentially. Chef’s perfectly capable of detecting and correcting variances immediately. It’s very common for companies to want a pause button though – they want to know, but they also want to decide when that correction happens. 16
I’m not a big believer in the mythical golden set of builds. First off, stability by itself is a really crappy goal. A better question is – what’s your current state? Where do you want to be? What are the characteristics you’re after? I’m betting you don’t really want to have a golden image of Windows that stays static for months. You want a Windows image that’s up to date and conforms to all your standards. You want up to date user accounts and security patches. In almost zero cases, a set of golden images is really not the destination you should be shooting for. 17
Do you need to really clamp down and enforce a set of “golden images”? Well that’s a tradeoff. If you allow a hundred different versions of Tomcat, or the .NET Framework, you’re increasing your operational complexity. If you choose to constrain these and enforce some consistency, you’re going to help reduce complexity, but you’re also reducing your developer’s capacity to innovate. 18
Trust the Tool
We found ourselves a bit like Mickey Mouse in “The Sorcerer’s Apprentice” from Fantasia. We spawned virtual servers, then more, then even more. They overwhelmed us. When something broke, we tracked down the VM and fixed whatever was wrong with it, but we couldn’t keep track of what changes we’d made where. …The problem was that, although Puppet (and Chef and the others) should have been set up and left running unattended across all of our servers, we couldn’t trust it. Our servers were just too different. We would write manifests to configure and manage a particular application server. But when we ran it against another, theoretically similar app server, we found that different versions of Java, application software, and OS components would cause the Puppet run to fail, or worse, break the application server.
….I used automation selectively – for example, to help build new servers, or to make a specific configuration change. I tweaked the configuration each time I ran it, to suit the particular task I was doing. I was afraid to turn my back on my automation tools, because I lacked confidence in what they would do. I lacked confidence in my automation because my servers were not consistent. My servers were not consistent because I wasn’t running automation frequently and consistently. 19
Kief described this downward spin as the “automation fear spiral”; it leads to using automation selectively, in certain cases, such as spinning up a new server, but ultimately doesn’t address the problem of configuration drift. Teams stuck in this vicious downward cycle should attempt a graduated experiment to get out of the shallow end of the pool; pick a set of servers, ensure the configuration definitions you have work properly, and schedule your tooling to run unattended on them. If this experiment is successful – as we predict it will be – then begin with the next set of servers, until all your environments are being continuously updated.
One of the common problems I see is fearing the system. For example, with Chef, or Puppet, or any other config management tool out there – we can automatically remove any variances with your systems, easily. At one place I used to work, we had infrastructure as code, with an agent running and keeping things up to date. But we got scared of the risk, so we turned it off. And any time we’d make a change, we’d have to add new code, spin up an agent to test against to confirm it was good – and then apply it to production. But by that time there could have been all kinds of changes in production that weren’t in that test. So we made a change – we decided to run config management all the time in production, trust our monitoring, and trust our reaction time and our ability to recover.
To get to that point where you really trust the tool – and trust yourself – probably the best place to start is looking at your last outage and the postmortem process you followed. Can you now detect that issue faster, recover faster? Zero in on those questions, and if there’s a gap in tooling – THEN you buy software that will fill that particular need. 20
Trusting automation begins with a level of confidence that every server can be rebuilt from scratch as needed using the tools and resource database you have available. From there with some steady work, it should be possible to get to the point where all your servers are having configuration tooling running continuously. If automation breaks with some edge case server, either the process needs to be modified to handle the new design or the server needs to be paved over and replaced with something that can be reproduced with the automated IAC system.
One of the most consistent feedback points we received from configuration management vendors was to trust the tool and move away from ad hoc usage. If environments are being created with an automated process – as they certainly should be – then it’s a simple matter to track down with your scans environments that are out of spec, those that weren’t built or configured with automation. These can and should be either brought into the automated fold or replaced with conformant systems; it’s the only way to prevent the Sorcerer’s Apprentice nightmare facing many Ops teams.
Docker and the Rise of Containerization
We’re enamored by containers – which today is nearly synonymous with Docker – and the potential that this brings in the form of reproducible infrastructure and portable applications, especially in combination with microservices. The rise of containers and orchestration software happened after most of the configuration management software we know and love today was developed. Arguably, using an image created from a Dockerfile or a Packer template eliminates a host of problems that was traditionally handled by configuration management tools.
Docker I just can’t say enough about. Rolling back is so easy – when there’s a problem, we pull the cord and revert back to an older version of the container. That takes all the pressure off of trying to run out a hotfix with a production down system. 21
Since container template files are code, they can be managed in a version control system; this means the stage is set for gaining most of the positive benefits with infrastructure as code, including testing and automation. Container images can be run on any host server that supports the container runtime, creating a consistent environment – reducing or eliminating the problem of apples-to-oranges systems anomalies. The risk of environmental inconsistency is greatly minimized with the advent of containers.
With containers, moving applications from a developer’s laptop out to test and production, or from a physical machine out to the public cloud, a much easier barrier to hurdle. And it has demonstrably helped reduce the problem of cloud vendor lock-in; app-specific configurations are kept separate from the underlying host environments, making it – at least in theory – easier to jump ship when you want to move your datacenters to a different cloud vendor.
It’s been said that containers are the “next wave” of virtualization. It can take a VM minutes to spin up; startup of a container can take just a few seconds. This has some obvious advantages when it comes to scalability and handling high loads; while VMs allowed us to scale capacity in minutes, containers can do the same in seconds. And with the smaller footprint, server hardware resources can be much better utilized. It opens up new possibilities in the form of finer-grained control and optimization; it’s easy to tweak settings in the containers internally without impacting other services and jobs.
Perhaps, best of all, having that clean separation of concerns between infrastructure and applications drastically simplifies our infrastructure governance problemset. A clean host system can have the bare minimum needed to support the OS, perhaps some monitoring and logging libraries and a few other admin agents, and the container runtime software itself; all the applications and services and its dependencies, including language runtimes, OS packages, and libraries, are encapsulated in the container. This eliminates or simplifies a whole set of problems with conflicting dependencies and “DLL hell” and reduces the maintenance needs and vulnerability points in the host. A simplified, hardened OS/host layer with fewer moving parts will require fewer changes, moving us much closer to the immutable infrastructure model where servers can be easily destroyed and replaced. It also frees us from having to optimize each server or VM to fit the needs of a single application or service.
That’s not saying that there aren’t some downsides with containers and orchestration. Although there’s some benefits in reducing the host surface area exposed to threats, there’s still much weaker isolation with containers vs. a traditional VM because containers share a common OS kernel; a virus that can infect one container puts other containers sharing that kernel at risk. (It’s likely for this reason that containers are still relatively little used in production systems at the time this was written.) Untrusted code should be partitioned onto different environments than those running platform services.
[Containers and orchestration] allows developers to be lazy and think they can just plop their laptop on production. So they do all these things that are really horrible and think containerization will make their work portable and secure. My prediction is, we’re going to see some major security issues over the next few years. It won’t be the fault of Docker or Kubernetes, but it’ll be an exploit based on a vulnerability with the images themselves. 22
Containers also move some of the complexity of managing systems upward instead of eliminating it entirely. With hundreds of containers in play, each running a single service, the operating landscape becomes much more complex. Provisioning large numbers of containers running these services and scaling them up and down dynamically, as well as managing the interaction between them, can be a daunting task. (Not to say that there aren’t solutions for this problem, especially with the rapidly maturing orchestration tools such as Kubernetes; just that this needs to be allowed for in your planning.)
It’d be a mistake to “lift and shift” a monolithic app onto a container and think it will yield magical results. Data persistence and storage will still need to be planned for, and if the application is running just fine on a VM, there’s little reason to port it to a container. Certainly, it’s possible to lump together all your processes together into a single container – as Tyler brought out earlier – but that may not pay off as much as you’d expect. Containers are really best used as a way of packaging a single service, app, or job; the end state you want is multiple containers each running a single process, which can then be individually managed and scaled.
Don’t let us rain on your Docker parade though. Containers would be a natural choice as a new way to cut that mammoth legacy app down to size. We’ll get into this more in Chapter 7 as we discuss microservices – but Docker/Packer would be a natural fit for the “strangler fig” pattern many have used to gradually pare down troublesome monoliths.
Containers and microservices go together like peanut butter and jelly. Containers can scale stateless tasks or small units of functionality very well. The fact that containers come with a very well documented set of APIs makes operability a much easier task; administrators can be comfortable that the containers they are running have a set of common characteristics and interfaces.
Uber, eBay, Yelp, ADP, and Goldman Sachs – all have found great success in using containers and orchestration to provide a standardized infrastructure for packaging, shipping, and running applications. It’s proven itself as a powerful way of eliminating many of the obstacles to true self-service environment provisioning. We see its adoption continuing to skyrocket and grow as more enterprises become comfortable with running them in production environments.
Security as Part of the Life Cycle
I think computer viruses should count as life. I think it says something about human nature that the only form of life we have created so far is purely destructive. We’ve created life in our own image.
– Stephen Hawking
The sad thing about most of the data leaks and vulnerabilities you’ve read about is how many could have been prevented very easily and with minimal work. For example, in 2014, 97% of successful attacks were traced to ten vulnerabilities, all known. Of those ten, eight had fixes in place for over 10 years.23
Too Important to Come Last
This isn’t a book on security. In fact, security makes us fidget a little in our chairs. We’re used to churning out code, by the bucket; “security” was always something we were asked to do, usually in the form of an audit just before a release. It didn’t help that as a specialty field (as we thought) the threat landscape seemed to always be evolving in new and terrifying ways that put our users and data in peril.
Our distrust and antipathy to security was understandable; like cooking or sex, security is one of those things that gets better with practice. We simply had not done it enough so that it wasn’t painfully awkward.
It became increasingly obvious that security deserved a place in this book. We can’t be confident in our code if we don’t run checks early and often to make sure there’s no gaping security holes, or that users can see data or perform actions that they aren’t authorized for. And our systems and network need to be protected and monitored.
Security is one of those things that we often add as a bolt-on – part of an infrequent, last-second audit – as seen in the section “An Insecurity Complex.” The people conducting these audits are often in separate, insulated groups and are welcomed with as much warmth and enthusiasm as an IRS auditor. This afterthought type mindset of security being this “other person’s job” really belongs to another era. Nowadays, there is just no excuse for not doing some level of security checking – even just a routine vulnerability scan – as part of the normal development life cycle.
Shifting Left with Security
For software to be secure, code needs to be reviewed early and often for vulnerabilities and gaps. For this to happen, it needs to be a part of every check-in. This means a similar “Shift Left” movement to what WonderTek has done earlier with QA and testing – no longer can security be a disconnected, late-game process.
Security should be a byword and it’s never been easier to integrate. There are good frameworks that can help us identify security risks that didn’t exist 5 years ago, and there’s just no excuse for not using one. OWASP with its top 10 proactive security controls is the best – it’s even ranked in order, from most important to least. But when you talk to DevOps gurus about security, they just roll their eyes – security is something pushed on them, and it cramps their style.
But really it’s no different from code development, and done right it actually adds a little excitement to the routine. Do it at the very beginning and start with a risk assessment of the data. What are you trying to protect? If you’re trying to map stars or you’re storing GIS data, that’s no big deal. But if it’s healthcare related or you’ve got credit card information you’re handling, your security protocols had better be at the top of its game. And with most teams you don’t have to do it all. If you love data, focus on that – or if you’re more of a UI specialist, that’s what your security efforts should target. 24
The Security Development Life Cycle
Flow is the word. Security reviews need to happen especially on new feature work, but they can’t slow down your velocity. So, instead of an approval gate or a bolt-on, security needs to be part of the life cycle early on. Root causes need to be identified and folded into a revised release process.
It’s not just one thing. Over time your security controls should be getting better and more comprehensive beyond just static code analysis for known threats. This includes threat modeling, defensive design and secure coding training, and risk-based security testing.
Integrate Infosec people. Infosec in this “shift left” movement are no longer “gatekeepers” handing down edicts from on high; similar to QA and architecture, their feedback comes in early and often as an integrated part of the team, as peers. This means conversations early and often between your developers and your InfoSec teams, who should have a representative at key points reviewing the security protocols used in the design implementation.
Dashboarding and quick feedback are vital. Developers should have quick visibility into the vulnerabilities in their code on check-in, not late in the cycle.
Another argument for microservices. Smaller codebases (cough, microservices!) tend to be much easier to keep compliant and monitor than monolithic applications.
Threat intelligence needs to be shared openly. This is still very much debated in the community, as there are obvious reasons why enterprises hesitate to air their dirty laundry from a political and a threat containment standpoint. But hiding security flaws rarely pays off in the long-term; instead, it prolongs the exposure window and widens the damage.
Make It Easy to Do the Right Thing
The companies that we’ve seen be successful with this make it easy for people to do the right thing – providing a well-documented, usable framework so that security checks can be run on check-in and lots of ongoing training and interaction with InfoSec experts during design and product demo sessions.
Zane Lackey at Etsy found that more attention needed to be paid to the libraries and tools they were asking their development team to use. “We can’t just say that security is everyone’s responsibility and then not give them visibility or tools for security. The way in which you actually deliver on that as a security team is by bringing visibility to everyone... In the old secure development life cycle model, we built a lot of security controls that were very heavyweight and top-down. And they require a lot of investment to tune and work correctly; and in the end, we would get a report once a month or longer.”25
That lack of visibility and instant feedback was crippling their security improvements at the source; creating easier to adopt frameworks that gave instant, visible feedback – including feeding security bugs directly into the developer’s work queue – became a fulcrum point at Etsy.
Any strategy that depends on a change in human behavior is going to fail. So stop talking about what you care about, talk about what they want to care about. 26
It’s Not Just Your Code That’s Vulnerable
Our applications are made up of more than just our code. We rely on frameworks and libraries that were written by others; even the environments we deploy to, and those deployment processes themselves, use packages and services written by others. These need to be scanned to make sure they are up to date with the latest bug fixes and security patches.
Engineering choices can create a security nightmare for Infosec teams that are invited late to the party. For example, at the 2016 RSA conference, one security engineer told a story about a bank that used a particular Java library. Across all of its products, the developers used 60 different versions of this library. Of those, 57 had published security vulnerabilities.
Ask the two engineering groups [release and security] to research your software supply chain. One of the core tenets of rugged DevOps is that you should know where your software components come from and reduce those components to a minimum number in your software supply chain: the group of well-known, high-quality vendors with which you work. A good first step here is to have your release and security engineers look at your flagship products and determine which libraries they use.
This type of excavation is where release engineers excel and security engineers know how to make sifting through the results more actionable. That might mean addressing an incompatible licensing issue or updating to a newer version of a library that has had a critical security vulnerability fixed. Finding out what code is lurking in there is likely to be a revelation, and the exercise is highly valuable to boot. 27
Threat Vector Analysis
Talking about security in terms of costs and liabilities instead of audit checklists makes conversations easier, as it’s less subjective and more concrete. Once cost implications are explained, it’s easier to weed out and constrain insecure libraries and dependencies. For Paul, this transformed the way security used to work – the drag, the prohibition, the “you guys are sure a drag to go drinking with,” to the good parts – the stuff that enables more secure code and less unplanned work.
Security is a matter of assessing threat and risk and deciding on compromises. Think of security as a continuum: on one end you have “wet paper bag,” and on the other you have “Fort Knox.” You wouldn’t implement Fort Knox– level security for storing $ 100, nor would you leave it in the open on the center console of your car while shopping at the mall. In these cases, you’re assessing the threat (theft of your $100) and the level of risk (leaving it unattended while shopping at the mall). It doesn’t make sense to spend $1,000 to protect against losing $100. In other cases, the level of security is too intrusive and cumbersome on how you work.
Can you imagine if you had the same level of security at home as found at the White House? Wearing a badge around the house at all times, checking in and out with security staff, pat-downs, metal detectors, bulletproof glass… seems a bit much for the home, right? A good lock on the doors and windows would work much better for the annoyance factor. 28
In the design sessions, the InfoSec representative needs to discuss with the team the risks associated with each new feature. Is there something about this particular change that could require deeper inspection? Is there sensitive data like credit card or social security numbers? How do we know data or the identities used for authentication aren’t altered or fake? What protections do we have on the servers and network – such as a host intrusion detection system, or a network intrusion detection system running via a network tap? Do we ever actually check the logs and monitor what these systems are finding?
In the application release cycle itself, having that InfoSec representative present and checking over the release pipeline will help ensure that penetration testing is happening as an ongoing part of the product development – no software is ready for release unless it is hardened and user information and data kept private.
Netflix has taken a very careful position to empower their development teams without encouraging codependence. Diane Marsh, the Director of Engineering Tools at Netflix, has said that the engineering team’s charter is to “support our engineer teams’ innovation and velocity. We don’t build, bake, or deploy anything for these teams, nor do we manage their configurations. Instead, we build tools to enable self-service. It’s okay for people to be dependent on our tools, but it’s important that they don’t become dependent on us.” Ernest Mueller from Bazaarvoice echoed this by saying that they are careful to segregate architectural and foundational work; platform teams can accept requirements but not work from other teams.29
Think Rugged
We won’t hide our disdain for the clunky phrase “DevSecOps,” though it seems popular these days. (Where does this end exactly? DevArcDevTestSecOps?) Maybe, we’re being a little fussy here, but it seems like this misses the point. DevOps is just a metaphor for an inclusive culture. Language and terminology are important, and DevSecOps as a phrase seems to represent more of a divergence than we’re comfortable with.
Instead, we’ve adopted the Rugged Manifesto as our own personal working mantra in designing applications, and we encourage you to take a look at this as well. The Rugged Manifesto acknowledges that our software is going to be used in unexpected ways, that it will be submerged in a hostile environment and subjected to unending malicious attacks. This is, like it or not, our reality – the Rugged Manifesto challenges us to face that reality and pledge to do something about it.30
To us, this embraces the true spirit of folding security into part of the development life cycle, as a personal responsibility – without having to coin ugly new movement titles.
Automated Jobs and Dev Production Support
Simply put, things always had to be in a production-ready state: if you wrote it, you darn well had to be there to get it running!
– Mike Miller
It seems like hours until help arrives, but it was probably only a few minutes. As you are pulled from the wreckage of your car and placed on a stretcher, someone is at your side telling you that everything is going to be all right. You’re carried to the ambulance and as it speeds off in the direction of the hospital, you weakly ask if you can be given some painkillers, or at least stem the bleeding from your broken arm. “I’m so sorry,” the EMT person says, sadly shaking her head. “I’m not allowed access to painkillers, and we don’t have tourniquets or bandages in this vehicle. It’ll have to wait till we get to the hospital.”
As ridiculous and potentially tragic as this scenario is, it plays out every day in our service support and Ops centers. And it causes a huge drain on your development firepower, as we see in the section “Effective First Response.” If you find yourself tired of support demands bleeding away your work on new features, you’re likely stuck in the same situation as that faced by Ticketmaster not too long ago.
It’s a story that most of us can relate to. The Operations team at Ticketmaster was suffering a slow death by a thousand cuts – drowning in tickets and manual interventions, trying to support applications that each required a unique set of processes and tools. Deployments were a nightmare of handoffs and delays, with each environment from dev to production requiring a different team to deploy. There was no single place to look at the status of current or previous builds; no way of knowing what had been done or by whom, and what had happened pre- and postdeployment. The nightmare that resulted of support calls spilling directly onto the development teams created long delays that were expensive, painfully visible, and enraged their customer base.
You’d think the cure for this situation would have been a shiny new CI/CD tool and a years-long effort to force compliance. But the eventual solution they identified was both humbler and lower cost: providing better support for their first responders in Operations.
The Case for Runbooks
Runbooks – automation scripts that can be executed with a single push of a button – were introduced for most of the routine operations tasks, including service restarts, rebooting VMs, and performing cleanup jobs. Delivery teams started working with Operations to provide them a set of jobs that were continually refined and expanded. Operations provided reports back to the delivery teams so customer needs could be anticipated and bugs added to the queue.
As a result of these efforts, first responders gained a broad knowledge of the entire ecosystem and could knock down up to 80% of incoming tickets without the need for escalation. Helping first responders in Operations handle triage and remediation created dramatic results: a 40% drop in escalations and a reduction in time to recover (MTTR) by 50–150%. Overall support costs dropped in half.
We’ve worked in several enterprises where the team is drowning in firefighting. Often, leaders and the teams involved recognized that better training was called for; lip service was paid to creating automated jobs and enabling effective triage by the support/Ops team. This often ended up consisting of a few halfhearted training sessions and then a handoff of “Top 10” issues documentation – no meaningful ongoing collaboration with Ops or change in behavior followed. Predictably, the needle didn’t budge, and problems continued flowing through untouched.
Take that list and work on what’s causing pain for your on-call people, what’s causing your deployments to break. The more you can automate this, the better. And make it as self-service as possible – instead of having the devs fire off an email to you, where you create a ticket, then provision test environments – all those manual chokepoints – wouldn’t it be better to have the devs have the ability to call an API or click on a website button and get a test environment spun up automatically that’s set up just like production? That’s a force multiplier in terms of improving your quality right at the get-go. 31
First, it addresses the obvious waste of doing something manually when it could be automated. Automation also enables the tasks to be run more frequently, which helps with batch sizes and thus the triage process. Second, it dramatically reduces the time associated with these manual tasks so that the feedback cycles are much shorter, which helps to reduce the waste for new and unique work. Third, because the automated tasks are executed the same way every time, it reduces the amount of triage required to find manual mistakes or inconsistencies across environments. 32
How Important Is Shared Production Support?
Is production support and end-to-end responsibility by the team for their production running services and applications a must-have? We would answer: maybe, production support isn’t a requirement, but it’s damn close.
Some will argue that development resources are too scarce and offshoring support is so scalable and inexpensive that it makes no sense to hand any support work off to coders. And some smaller shops we interviewed chose to limit drastically the involvement by their development teams, to perhaps 5% of incoming calls.
But we never encountered a single successful, robust DevOps movement that didn’t have some involvement by the devs in helping share the load of production support. Not even one.
We feel that’s not a coincidence. Several people we spoke to mentioned the shocking lack of empathy that happens with the traditional “heads-down” programmer; introducing some type of regular support schedule caused immediate positive changes in the team’s view of quality and service availability. Having the team hold itself accountable, it seems, is worth more than any number of speeches or quality-driven initiatives instituted from higher levels.
This increased level of ownership leads to increased autonomy and speed of delivery. Having one team responsible for deploying and maintaining the application means it has an incentive to create services that are easy to deploy; that is, concerns about ‘throwing something over the wall’ dissipate when there is no one to throw it to! … It pushes the decisions to the people best able to make them, giving the team both increased power and autonomy, but also making it accountable for its work. 33
Google has also found production support to be a valuable crucible for their development teams. Contrary to common belief, most teams at Google handle most support independently, without an SRE involved; and before any SRE can be assigned to a team, they require that the team self-manage their service in production for at least 6 months. There are several review stages that the teams are also required to perform before handing support duties off or launching a new service. All of this drive home the message that operability and effective defect tracking and resolution are not somebody else’s job.
The hero jack-of-all-trades on-call engineer does work, but the practiced on-call engineer armed with a playbook works much better. While no playbook, no matter how comprehensive it may be, is a substitute for smart engineers able to think on the fly, clear and thorough troubleshooting steps and tips are valuable when responding to a high-stakes or time-sensitive page. Thus, Google SRE relies on on-call playbooks, in addition to exercises such as the “Wheel of Misfortune,” to prepare engineers to react to on-call events. 34
It’s easy to see the impact that a well-thought-out playbook can have on your support team. When a first responder gets an alert in the early morning, she’ll have immediately available a link to the playbook. At a glance, she will be able to understand what the service is, what its functionality includes, any dependency points, infrastructure supporting it, contact information and responsibility chains, and metrics and logs that can help with remediation. She also may have been in several rehearsal sessions earlier that went over restart scenarios to help with her diagnosis.
Ideally, she’ll have available one of the excellent support-oriented software available such as PagerDuty, VictorOps, and OpsGenie. Your support teams should have one of these tools available to help with reconstructing incident timelines and handling escalation paths. A clear timeline and an abundance of information available to first responders are critical to reducing MTTD and MTTR; the value of the recordings and automation capabilities with these software packages cannot be overstated.
A Real Partnership with Ops
The success story at Ticketmaster wasn’t an accident; it began with a plan backed by senior management and a significant commitment in time and energy to improve the response process. Specific metrics were watched very carefully over time at the highest levels. The partnership with Operations and support was more than a gesture; it was a viable two-way flow of information and coordination of work.
In our group, most system admins lasted only six months. Things were always breaking in production, the hours were insane, and app deployments were painful beyond belief… during each moment, we all felt like the developers personally hated us. 35
Why don’t Ops teams in large organizations give direct self-service access to the production environments to developers, to deploy continuously, as many startups do? The reason is simple: they don’t trust Dev teams to deliver stable, secure, and reliable applications. …This lack of trust in large organizations seems to extend beyond just Dev and Ops. Dev does not trust business analysts. Enterprise architecture does not trust Ops. QA does not trust the developers. The audit and compliance team trusts no one. No one trusts management, and so on. This lack of trust results in teams not being able to effectively communicate and collaborate across functional silos. 36
The best way we’ve found to break down these calcified walls and build empathy is by sharing the load. Having developers take a portion of frontline support invariably helps build trust between traditionally partitioned functional teams and improves the flow of feedback from customers to the feature delivery team.
Our teams own their features in production. If you start having siloed support or operations teams running things in production, almost immediately you start to see disruption in continuity and other bad behaviors. It doesn’t motivate people to ship quality and deliver end-to-end capabilities to users; instead it becomes a ‘not it’ game.
In handling support, our teams each sprint are broken up into an ‘F’ and an ‘L’ team. The F team is focused on new features; the L team is focused on disruptions and life cycle. We rotate these people, so every sprint a different pair of engineers are handling bugfixes and interruptions, and the other 10 new feature work. This helps people schedule their lives when they’re on call.
Our teams own features in production – we hire engineers who write code, test code, deploy code, and support code. In the end that’s DevOps. Now our folks have a relationship with the people handling support – they have to. If you start with that setup – the rest falls into place. If you have separate groups, each responsible for a piece of the puzzle – that’s a recipe for not succeeding, in my view. 37
Having a rotating support model like the “F” and “L” support model used by Microsoft might be useful. Or, you might find it better to gate work across the board, so developers have a few hours or a single ticket to support each week. However you choose to go about it, make sure your development teams share some responsibility for how their products are working in the real world. Besides helping us listen to the voice of the customer in our development priorities, this can have a very nice side benefit of helping bring more of a tools and automation orientation to your support team.
If your team is drowning in support costs and irate customer calls, take the same approach used so effectively by companies like Ticketmaster, Microsoft, and Google. Keep visible your metrics around reliability and SLA coverage, exposing the cost caused by pass-through tickets and long remediation times. Provide simple, push-button automation that is self-service or as close to the problem as possible; constantly engage with Ops to keep these runbooks up to date. And empower the people first on the scene to knock down as many problems as they can.