
Another 3 months goes by, and spring gives way to the full heat of summer. After a difficult adjustment period, some of the efforts that the team has put into a “shift left” movement – including breaking up their siloed QA team – starts to bear fruit. Both their defect rate and release velocity numbers show significant improvement after a slight sag early on. Even better, that vital connection to Ben’s customers and stakeholders seems to be thawing somewhat. Putting quality first instead of speed, it turns out, enabled the team to deliver both.
A start in mapping out the flow of value with their more sensitive work streams, identifying limiting factors, and pain points
More productive code reviews, catching defects earlier in the delivery cycle
Shifting left – beginning to move toward test-driven development and a more robust automated test layer
A community-driven Center of Excellence (CoE) around quality, exploring more testable app designs and improving reusable test frameworks
Scorecards tracking technical debt and quality, visible to all
This doesn’t mean smooth sailing however. Ben’s team still hasn’t done enough when it comes to engaging with stakeholders. They’re still spending too much time on gold-plating features that are delivering negative value, and their infrastructure provisioning process is still manual, time-intensive, and error-prone. There is still a lot of debt to pay down. And they aren’t really paying any kind of attention to improving the limiting factors constricting their flow around provisioning environments.
Will Ben and his team be able to keep ratcheting forward on their quality-driven initiatives, or will old habits and the politically charged atmosphere of WonderTek start to drag on their progress?
No Shame, No Blame (Blameless Postmortems )
“I was up most of the night on the Slack channel war room, so if I’m a little groggy you’ll have to forgive me.” Emily smiles grimly. She doesn’t look tired, I think. She looks angry . “So once again, we find ourselves in this room trying to figure out how to dig our way out of the mess the development team has made.”
We are making some progress but critsits still happen, and it’s become obvious that we’ll need to change some of our behaviors and reactions on a fundamental level. Thankfully, I’ve been preparing the ground for this for some weeks now. Elaine nods and gives me a slow smile, and says to Emily brightly, “Well, we know many of us were up for much of the night, and we appreciate you attending this meeting now while it’s still fresh. I’m the facilitator of this meeting, which means I’m responsible to enforce our ground rules. But anyone and everyone in this room can call out when we start straying.” She displays the following slide:

Emily snorts contemptuously. “Sounds like this is a pretty weak attempt to get out of accountability, Ben. I’ve never run a retrospective like this – if we don’t hold people responsible, our failure rates are going to get worse, not better.” She leans back, folding her arms and glaring at me. “I’m not leaving this room until we know who caused this failure and what they’re going to do to fix it.”
Alex says, “I think we all know that in complex systems there’s rarely one root cause. I’m agreeing with the ground rules here – we need to explore what happened, and get the facts straight. But I’m not worried about our people, whether they’re wearing an Operations hat or a Developer hat, being accountable. I know everyone here made decisions last night the same way they do every day, based on what they thought was right for the company. It’s our processes that may need some tweaking, so those decisions are better informed. Usually that means putting up some guardrails.”
Emily is smirking contemptuously at what she clearly thinks is a bunch of hippie nonsense. Her back is to the door, so she doesn’t see Douglas coming in as she says, “On my team and on the systems we support, we’ve found that things don’t just break on their own. Someone rolled out a patch, or someone changed an application, and due diligence wasn’t done. If you don’t want these things to repeat over and over again, we have to bring them out in the open.”
Elaine says evenly, “I completely agree. We’re not going to sugarcoat what happened or try to sweep things under the table. Our objective here is to collect a full account of what happened – in fact, we’re going to spend the next hour coming up with a complete timeline of the facts. We won’t move on until the events and contributing factors are listed and we agree on them. But we’re not going to name, blame or shame anyone for what happened yesterday. For us to collect all the detail we need, everyone here needs to understand and agree that failure is a normal part of maintaining complex systems. Our objective is not to punish but to learn what we can do to prevent this from reoccurring or limit the blast radius next time.
“Now, first and most important question – is everyone that we need here in this room?”
Emily stabs her finger at me. “Hang on. My people were up most of the night because of the devs pulling their usual cowboy shenanigans. These problems aren’t going away and they need to be addressed, with names. If we’re not going to drill down to who did what and when, why for God’s sake are we even here?”
Like I said before, I respect Emily, and she does a fantastic job of protecting and supporting her team. But her instinct to point fingers when something goes awry is hurting us, and I decided weeks ago to put some countermeasures in place to head off any Ops-instigated witch hunts.
For the past quarter, we’ve put our focus as a team on testing early and often, with the goal of improving our release reliability and frequency. Alex, George, and I have been talking for weeks at changing the way we react to mistakes and outages. I remember in particular in a past company a manager I used to work for named Cliff, who believed whole-heartedly in the “bad apple theory” – that a little public shaming was key to prevent people from making errors in judgment. If a build broke, Cliff would bring by a dancing chipmunk doll and leave it at the desk of whoever broke the latest release. Anyone who wanted to could walk by that cubicle and hit a button, and the chipmunk would start jiggling around, singing “I’m All Right.” He’d also hold weekly “Zero Defect” meetings where upper level management would call in the offending developer and put them through a gauntlet of would-have, should-have interrogation.
This drive for “better visibility and accountability ” had an immediate impact, but not like Cliff expected. His team’s releases dried up almost immediately, going slower and slower as people tried to keep their heads down and avoid the dreaded dancing chipmunk. But this caused more work to pile up and the release changes to get bigger, increasing the risk of breakages and lengthening resolution time. And root causes were rarely addressed; by making the person the problem, they missed opportunities to improve their process.
I learned a lot from how Cliff’s worldview impacted his team. One thing was – it’s never people that are the problem – there’s always something missing or flawed with the process. The team is starting to reduce its technical debt, but I can’t let what I call process debt accumulate unseen. Process debt is as big a problem as technical debt in every company I’ve ever worked for, and it always seems to come down to how we view errors, and whether learning is safe. Right now, our lack of automation or controls in several spots in our release process makes learning a very risky proposition.
I pick my battles but decided a month ago that this was one that was worth fighting. I lean forward and address Emily directly. “There’s two ways of looking at faults like these. We can say, these people are bad, our systems would be fine if we didn’t have these careless, incompetent people messing around with them and creating work for everyone else. By calling them out and shaming them, we’ll prevent this from happening again and make them be more careful. That’s a very comforting, satisfying way of looking at things, and it’s how we’ve run our postmortems in the past. Like Elaine says, though, it won’t help us in prevention down the road because we haven’t identified the root cause.”
Emily smiles like a cat with a fresh bowl of milk. “It sounds to me like you don’t like process period, Ben. I’ve never seen you at our CAB meetings, or at the Zero Defect meetings I’ve held.”
I actually have attended a few but stopped after a few rounds when it became clear what the tone would be. I have to tread lightly here though; both of these meetings are held in high esteem by some of our management team. Calling them out as unproductive snipe hunts will not win me any friends in the executive suites. “The company is asking us to do work, Emily. Mistakes are a byproduct of work. I’m OK with people making stupid mistakes – because I do too, every day. But a zero-defect meeting is coming at things from the wrong angle. I’m not a zero-defect person, and you’re not either.
“What I’m not OK with is people making the same stupid mistakes as last time. That means we will be sharing this openly with everyone. That kind of transparency requires us to be honest and focus on the context of good people making decisions based on limited information and complex and imperfect processes. Now, these rules shouldn’t surprise anyone. They’re right there in the meeting agenda. If anyone disagrees with them, they need to either adjust their thinking or leave the room. Can we move forward now?”
While I’ve been talking, Emily has been scanning the room and spots Douglas, who has a carefully neutral expression on his face but is paying very close attention to this showdown. She smiles sweetly at me, all sugar and sparkles. “Of course! Just as long as we make clear exactly what happened and publish it, I think that would satisfy everyone.”
Elaine continues to explain the meeting structure. For the next 30 minutes, we’re going to reconstruct a timeline of what happened. Here, our goal is not to rush to any fixes – we’re just listing what happened, what our expectations were and assumptions that were made, and what effects we observed. Until the timeline and events are agreed upon, the meeting will not move forward to potential remediation items.
The engineer who made the changes in this broken release, Ryan, groans softly. With slumped shoulders, he begins displaying the release notes and logs. Most of the great programmers don’t exactly have the presentation skills of Steve Jobs; that, combined with the harsh glare of being under a microscope, is definitely working against Ryan. His forehead is sweaty, and he’s having trouble looking anyone in the eye, the picture of guilt and shame.
The facts as they are don’t reflect particularly well on anyone. Ryan had been working on a change that involved trimming some user accounts and adding a new column to the users table. The PowerShell script implementing this had been tested and was checked into source control as part of a scheduled build at 5:30 p.m., about the end of the working day. At 7:45 that evening, they started getting reports from users that logins were not working, neither were payments or searches. The support team had tried reaching the on-call developer, Alex, but he was at the gym and had his phone on airplane mode.
Rolling back the release failed to resolve the issue, as the database model changes weren’t rolled back to the previous version and it left the UI in an inconsistent state. It took several more hours for the developers on call and the support team to track down the account issue, get Ryan on the phone, and get the website back to a stable state.
I’d been on the war room channel along with several others, but felt helpless to influence the outcome. It looked for a while like the website might be out for an entire day, a very visible disaster and one their competitors were sure to capitalize on. Douglas had been surprisingly calm when I updated him on what had happened, and I took the opportunity to explain to him how we were going to handle the postmortem process.
Ivan from the Ops team was filling out some events for the rollback timeline. My head snaps up as he finishes by saying, “It seems pretty obvious from the logs that Ryan should have noticed this flaw earlier in the release process, and we wasted hours trying to get ahold of him. The fact that he went dark like he did really slowed us up.”
Elaine, who has been writing down some notes, stops and says, “OK, so we all remember the ground rules right? Here, let’s display them again.” She shows the first screen and the item about counterfactual thinking being verboten. “My job as a facilitator is to make sure we don’t say anything like ‘could have’ or ‘should have’. That’s hindsight bias – it assumes that there’s a neat, linear, predictable path where everything goes perfectly if X didn’t happen.”
Emily laughs shortly. “Elaine, with all due respect, all WOULD have gone perfectly if Ryan hadn’t kicked off a release that he hadn’t tested thoroughly and then gone to polish his guns at the gym.”
I say sternly, “It seems to me like we keep getting back into this rut of trying to blame and punish, and that’s not productive. Maybe we need to change our habits so we are checking in and pushing releases earlier in the day, but I don’t remember us ever making that a written rule in the past. Ryan didn’t do anything that I and a few others haven’t done in the past.”
George is nodding his head in agreement. “Decisions aren’t made in a vacuum. We’re trying to understand the context better and what we knew at the time, and dig a little behind the obvious. It’s what Etsy calls ‘second stories’ when they’re doing their postmortems.”
“If that rollback script had been checked over by anyone with an eye for detail, it would have clearly obvious that it was removing some admin level accounts,” Ivan counters. “And not checking for the database rollback script was a particularly egregious oversight. I wish you guys would fold us in earlier when it comes to these deployments. It leaves us holding the bag when things break.”
Alex and Elaine’s face both go scarlet in unison, but before they can respond, Douglas slams his hand on the table. “Stop. Everybody just STOP.”
The entire room goes silent, and Douglas stands up. His jaw is set, and he’s glaring at Ivan and Emily. “In the military, we commonly did after-action reports. The one thing we NEVER did was to assume infallibility or perfect knowledge by the operatives. And we’re looking for actionable, specific goals to target so problems don’t reoccur.”
He looks directly at Emily again, and there’s not a trace of a smile. “Ben has been talking to me about this for the past few weeks, and I’m in agreement with him that this is the way our postmortems need to go. I’m comfortable that he’s not trying to deflect responsibility or point fingers. If anyone here – anyone – is putting their political position ahead of the company’s wellbeing, or trying to position this as a developer vs. operations problem, they’re not thinking in terms of the team. And they don’t belong here. Does everyone understand?”
Douglas’ stance isn’t a surprise to me; he cares very much about team cohesion and preaches unity and consensus. Ivan has gone silent under the assault; Emily is white-lipped with anger. I’ve never seen her at a loss for words like this, but I have to give her credit; she’s unsinkable and unrelenting in her stance, even when her direct manager is in opposition.
Elaine begins the open discussion part of the meeting, and people began bringing out some options for fixes. Ryan offers that they should have considered doing additive changes only to the backend update script, where entities and columns can be added but never deleted – that way a database side rollback would be unnecessary. On changing the test layer, the group agrees that the unit tests had passed – the issue was higher level, something had broken major pieces of their functionality and had not been caught with their integration testing.
I decide it is time to offer an olive branch. “Ivan, Kevin, and Emily – I know you were all on the hot spot when this was going on. Did we detect something was wrong fast enough?” It turns out that alerts had gone out soon after the site went dead – but they were buried in thousands of other low- and midlevel alerts that day. The Operations dashboard showed all server-related metrics, like CPU and disk utilization. But there was no display of the uptime of the main site, response time for users displayed across all regions, or cart transactions per hour – any of which would have caught the issue several hours earlier.
As Elaine is writing down the need for a consistent dashboard showing the actual user experience – and an alerting system that isn’t yipping like a hyperactive chihuahua – Emily interjects again. “Am I allowed to point out that this is not my team’s responsibility? We build and provision the servers according to specs, keep our operating systems up-patched and maintain security of the network and infrastructure. That’s it. We build the house, and we keep it standing, but we’re not responsible for anything going on inside.”
I’ve rarely seen Douglas this angry. “Emily, we seem to keep coming back to this. Ivan said a little earlier that Ops didn’t feel included in this change. I’m confused – did Ben not invite you or anyone on your team to their daily sprint? Their retrospectives? What about their release planning session?” Emily’s lips compress again into a thin white line, as Ivan mumbles something about being too tied down with an OS upgrade project. Douglas continues, “It seems to me that if our main site is down, then WE – the entire team – has a problem. And it seems to me that there’s likely room for improvement across the entire team. Now if out of this mess we end up with a less noisy, more effective alerting system, that alone is worth it. I’d be delighted to see everyone looking at the same screen too. If all Operations is looking at are server uptime metrics, we’re missing the point. Not one of our customers cares about our CPU utilization. Elaine, make sure that gets in the notes you send out.” He looks at his phone, and says, “I have to go; thanks for inviting me. I am very interested in what you decide to implement so that this doesn’t happen again. Remember, keep it small, keep it actionable, and make sure it gets done.”
After he leaves, there’s a silence that stretches on for a few uncomfortable moments. Emily and Ivan are on a slow simmer, Kevin is avoiding eye contact, and Alex and Elaine look unsettled and upset. Only George seems to have that unflappable calm that he wears like a coat.
We finally move on to discussing remediation steps around our on-call process. Kevin muses, “It seems to me like any release process where we have to hunt down a single developer to figure out what happened and how to reverse it has some weak points.” This gets a general agreement, but we don’t seem to have any specific ideas on how to address that; we put this as an open issue in our report and move on.
The subject of feature flags and canary releases came up – would the release have been safer if it could have been toggled or released out to specific customers in rings? Ryan says, “I really love the thought of being able to run out a release in one sprint – and then turning it on when we’re good and ready. I’m not sure how that will work with a database model change like we’re discussing though.” This also gets added to our growing list of things to explore.
Another area of concern – the initial responders, it turned out, had not known how to do even basic troubleshooting or triage, and their contact list was months out of date. Alex takes as a to-do to meet with them next week and show how they could do some basic smoketesting and diagnose a few common issues.
As the meeting begins to wrap up, I add one more item to the to-do list. I say, “Ivan brought up that these changes came out of nowhere for the Operations team; I’m accepting that. I could have been involved in the weekly release planning meetings. I’ll start attending, beginning next week.”
Emily replies, “I thought you didn’t like ‘pin the tail on the donkey’ games, Ben.” Her smile is all honey and arsenic. Even as I grit my teeth, I find myself admiring her toughness; she’s an indomitable political machine. If I don’t mend some fences, I’m risking a very bloody trench war with my delivery partner that very well could end with my departure. I say quietly, “I’ll cut you a deal. It might be too much to ask someone from your team to attend every single daily scrum we have. But it seems to me like we both need to work harder at coordination. So how does sound: if you attend our retrospectives and demo sessions, I’ll attend the weekly release planning session. That way our retrospectives will have the whole story, including Operation’s point of view. And I can keep your team better informed of what’s going out the door.”
I keep my promise and rarely miss a release planning session from that day on. Elaine’s writeup is posted on our wiki, and we make sure that our bite-sized remediation steps are dropped onto our backlog.
I’d love to say that this ends the cold war, but old habits die hard. Emily’s default position is – and probably always will be – to point fingers; it makes her a challenging and unreliable partner. But Douglas seems to be satisfied with our remediation steps, especially with the new dashboarding that began to appear in both the developer and support work areas. Showing numbers that mattered – like site response times and availability – and having the same displays in both areas began to have a subtle and very positive impact on how problems are handled at WonderTek.
When Is a “Requirement” Not a Requirement? (Hypothesis-Driven Development )
Padma has been working on a certification site for Human Resources for several months now; the design has gone through several changes, and it looks like at least another few sprints will be required to reach “feature complete” stage. At her request, I sit in on the next design review meeting along with Alex and their stakeholders. Invited to the meeting are a few people I have met only a few times in the past – the project business analyst, Torrey, and their HR stakeholder, Lisa.
The first thing I notice is that Lisa’s chair is empty. Later, I find out from Padma that this was not unusual; Lisa had stopped attending after the initial design and planning sessions.
Padma finishes a quick demo of the previous sprint’s work. We have come a long way from the wireframe stage, and to me the site looks 90% complete. Padma is most excited about the nifty look and feel of the UI and its responsiveness and mobile-friendly CSS theme. Much of the features and settings on the site could be customized by the user, including sliders that concealed or exposed the data behind each of their subsidiaries, contractor facilities, and warehouses.
Torrey, however, is not as thrilled, and he makes it clear that the demo was falling well short of HR’s expectations. Torrey’s rep is that of someone that’s determined, highly competent, and a stickler for detail. He has a strong background as a DBA and even provided SQL snippets for Padma to follow in creating detail and summary views. This was his pet project, and he’s vocal in his disapproval; he wants the entire detail page for the main user view redone and several admin screens to be refactored. I grimace; this was setting us back to square 1, and Padma was badly needed elsewhere.
Finally, I speak up. “Hey, Torrey, I love the work you’ve put into this and the passion here. Can I ask though – what’s the actual customer problem we’re trying to solve here?”
Torrey smiles condescendingly and runs a hand through his thinning blonde hair. “Always great to have management come in several months after the fact and start questioning things. As you might have heard, WonderTek makes things like shoes and athletic apparel. We have factories and subsidiaries overseas that are producing our goods. Auditors need to come in and mark off safety and occupational health risk factors, and track progress on action items we’ve identified. If we don’t see improvements, we need to be able to make that visible so we can sever ties. We need this app to be highly secure and segmented by user and role, but really ethics is the main driver. And it needs to be performant, hopefully with offline availability – a lot of our records are going to be entered in very remote regions with limited 3G wireless access connectivity. We discussed all of this back in the design stages months ago, Ben – you were there.”
Fair enough, I tell him. “So then I have to ask – is this solving a problem for a customer? How is it going to make us money, or save us money?”
Torrey looks at me with the expression you’d use with a fairly dim 6-year old. “Ben, that’s a really naive question, and like I said – it’s months too late in the game. Like I said, this is about ethics. We just can’t spend enough on something like this. A leak or a perceived deaf ear on this could set us back potentially years in the market and leave us open to all kinds of liability. You remember what happened to Nike in the late 90’s when they were accused of running sweatshops in China and Vietnam, it really damaged their brand. We have VP’s and division leads asking for this information; giving them a secure view of our compliance status is considered top level in priority.”
I say, “With that kind of visibility, I’m a little surprised we didn’t investigate further the possibility of buying this as a COTS product instead of trying to build something custom to fit our own internal preferences.” Torrey rolls his eyes contemptuously again; this is an old argument I was digging up. He had gone back and forth multiple times on funding and resources during the planning stages months ago, with Torrey eventually carrying the day by insisting that it could be done with two people in three months. With Lisa and HR, a powerful proponent, taking his side, the project was pushed through. Five months later, we are still looking for an endgame.
Torrey says flatly, “Ben, this is dead ground. We’ve gone over this, and you lost. So live with it. These are the requirements, and they come from Lisa. Now, Padma, when are you going to get these new screens done? And these reports – I have to have them for our upcoming delivery view in three weeks.”
I don’t like to play trump cards like this, but this project is tying up several of my best people, and we need to put a bow on it. “Hang on one second Torrey – I’m totally appreciative of where you’re coming from and I know you have the best interests of the company at heart. That being said – I only have so many people, and this effort is already several months behind schedule. It’s my responsibility to make sure we’re aligning ourselves with the delivery of actual value to our customers. This is an internal application, and internal apps are often most vulnerable to time drains like gold-plating and endless scope creep. So, do we really need to have all these features delivered to know if this is going to take off or not? What’s really our minimum viable product here, and how are we going to measure if it’s going to be a success?”
Torrey’s jaw drops. “Gold-plating – are you serious… dammit, this isn’t a game. Lisa expects these screens, soon. Are you really going to make me go back to her and tell her that our development team is dragging their feet on something the business needs?”
I reply calmly, “Correct me if I’m wrong, but I don’t believe those screens were part of the original ask, at all. It’s not in anyone’s best interests to have our commitments spiral upward endlessly. We need to have a clear finish line everyone agrees on.”
“I thought you guys were Agile,” Torrey snorts. “I kept on hearing about how you didn’t want me to give you a full-size requirements doc, like I typically do, just a PowerPoint wireframe. The customer’s needs have shifted, and it’s your job now to roll with the punches and deliver according to the new ask. Anything else – well, we’d need to take that up with Lisa.” He sat back in his chair, grinning triumphantly.
I decide to call his bluff. “Yes, I think that’d be a great idea. Let’s get Lisa in here, I want her to look over what we’ve delivered to date and what you’re asking for here and see if it’s weighted correctly.”
At least I’ve stopped the eye-rolling; Torrey is suddenly almost angry at being defied. “This is exactly why I wanted to take this to a third party. You guys are just too slow and inflexible to get this done on the timeline HR needs.”
“I agree with that first statement,” I said. “When this project came up for review, I argued against it. I said that this doesn’t give us any kind of a competitive advantage; to me, it was a textbook use case for a third-party app. That option is still open to us, by the way. If we truly are back to square one after this design session, six months in, I think we definitely need to present this to Lisa and our HR partners and have them make the call.”
“I never said we were back to square one,” Torrey says. He frowns and mutters disgustedly, “We just need to finish up these reports and these two admin screens and we’ll be good to go.”
“Ah, now we’re starting to get somewhere,” says Alex, leaning forward. “On these two screens – getting back to that minimum viable product question Ben asked – do you really need to have them for the application to work?”
Torrey hems and haws, but finally it comes out – yes, we have enough functionality to deliver something useful to our factory auditors for their reports. As Alex and I had guessed, the current “requirements” were both admin-facing features that Torrey had tacked on, likely without Lisa even knowing about them. I shiver. This is looking more and more like one of those dreaded headless zombie projects, with an absentee stakeholder and a shifting mission. The delays for the past few months as new requirements kept stacking up suddenly made sense – Torrey has hijacked the design UI based on his own personal point of view. Perhaps, his hunches were right; but with no way of verifying or validating them, his tacked-on features and stories remained guesses.
All that being out in the open, I have no more intent of scrapping months of work than Torrey does. I do need to cap things though and get this out the door, so we can get usable feedback. “Let’s assume that you’re right Torrey, and we really are almost there. We need a finish line to this race. That means a true, defined minimum viable product. Let’s say we only have two sprints more of work available. What features could we squeeze into that time?”
Torrey takes two deep breaths , 10 seconds to pull himself together. He’s not accustomed to being defied like this. “We need to have those two reports at a minimum. Without it, there’s no aggregate way to display results. We won’t be able to filter out the worst performing factories and mark their progress. That’s the key answer HR needs to have answered, and without it the app is DOA.”
Padma says, “Torrey has already given us the SQL for the reports, and we can use a third-party extension to provide both a web and a printable report view for our admins. I’m pretty sure we can knock both out in a few days, maybe a week.”
Most of my engineers tend to underestimate work by a factor of 2-5x; Padma may be the lone exception. She’s amazingly accurate, even with large unknown areas in the technical specs; I’m confident she can deliver what’s needed in a week. I ask Torrey and Padma to demo the app to Lisa as it currently works and let us know if she agrees – that with those two reports we have a complete MVP that’s customer-ready.
I continue, “Now, something else I want to talk about, this whole idea of ‘requirements’ being a fixed, immovable object. I don’t buy into that. We don’t know if this will meet our true business needs, and it seems like we don’t have our assumptions and the problem we are trying to solve written down anywhere. Torrey, is that correct?”
Torrey throws up his hands in frustration. “Ben, with all due respect, I don’t think the seagull treatment is helping here and I don’t appreciate you coming in here, 11th hour, and treating my project like a statue.” He starts speaking slowly and stressing every syllable – “No, of COURSE we didn’t do any of those basic, fundamental things at inception, because I’m a horrible mean person who likes to force nerds to break a sweat and I’m terrible at my job. If you had bothered to look at the documentation link in each meeting agenda, you’ll see that the mission statement was set the first week.”
Padma breaks in, “That’s true, Ben – we’ve got a clear problem statement and we’ve tried to adhere to it from day 1.” She pulls up the following on her screen from the project wiki:
“We believe that delivering this application for our Human Resources administrators will achieve a better safety and humane working conditions at WonderTek. We will know we are successful when we see a 95% compliance record with our factories and subcontractor manufacturing plants, with a zero red flag count three years after rollout.”
Padma explains that red flags were the truly sensitive, worst case safety or inhumane working conditions. Currently, HR suspects that at least five and as many as eight of our suppliers and subcontractors fall under this category; giving them clear notice and enforcing it as a program will allow WonderTek to phase out these underperformers and replace them with more progressive factory plants.
Torrey says smugly, “That is business value, Ben. Not having our name in the papers as an exploiter of our workers is business value. If we want to be mentioned in the same sentence as Columbia Sportswear or Patagonia with the upscale, socially progressive market that we are targeting – that means caring about ethics, right down to the materials we source and the way we run our factories.”
“Let’s stop trying to score points against each other, Torrey,” I reply. “I’ve acknowledged that you have good motives and I’d appreciate you giving me the same benefit of the doubt. This project is getting a reputation of being a money-losing time suck, and Douglas wants me to scrub our involvement in it. I can go back to him with a counterargument – two more sprints worth of work and we’ll have a product that can stand on its own. That’s a better outcome than pulling the plug on months of hard work from you and the team. But I have to cap it at two sprints – that’s four weeks, Torrey. It’s all we’ve got, we need to make it count.”
Padma says, “It’ll take us at most a week, possibly a week and a half to do these last changes. So why are we asking for a month?”
Alex answers, “Because we’re not sure if this project is going to be viable yet, Padma. Maybe what we roll out won’t be usable by our auditors over a thin pipe. Maybe the report data won’t be usable by HR – in fact I’d bet dollars to donuts that they’re going to want to refine the audit reports significantly after seeing what people are turning in from the field. And maybe they’ll find a third-party product that’s more flexible and doesn’t require two developers to build and maintain.”
I say, “In short, we’re making a bet. We’re thinking that this is going to give HR the data they need to ensure compliance, and it’s usable by our auditors. But we might be wrong . So we get this MVP out to our end users globally as soon as we possibly can. And then we need to see how our bet is doing. That means a way of collecting measurable usage data and incorporating what we learn into our workflow. So last question from me – what have we done as far as monitoring?”
The answer with some hedging was – very little. Now, even Torrey is showing some signs of interest; as a technical BSA, he loves data and ways of proving value to his partners. Padma muses that – given those two or three weeks – they could look into providing monitoring that would give HR a viewable dashboard of the site’s response times by region, and for admins a better view of security and threat monitoring. I’m relieved to see that she has no intention of rolling her own monitoring framework; there’s several SAAS-based monitoring solutions available that can provide what we need for what amounts to a few thousand dollars a year.
At this point, Torrey objects to what he sees as an unnecessary cost in setting up monitoring as a service. I tell him, “Torrey, you keep saying that this is a high priority project and very visible to the powers that be. So let’s give them some credit. By the time all is said and done here, we’ll have sunk almost a half year of development time into this from two developers, and it’ll cost us another year or two easy in providing post-rollout support and tweaks. That’s conservatively speaking about a million dollars just in direct labor costs. Are you telling me that HR – who knows exactly what a good developer in the Portland job market costs nowadays – won’t be willing to sink $1,000 a month into providing some basic monitoring?”
Torrey and I argue about this a little more; I flatly refuse to deploy anything to production without a healthy monitoring system in place. Torrey threatens to bring in Lisa again. I offer to bring in Douglas as a mediator on scrubbing the project – which settles things nicely. Torrey acts as if he’s being stonewalled but finally accepts my conditions with good grace.
He’s a cagey negotiator , and we both know that Douglas’ two-sprint mandate is a paper tiger; this project will likely spin along for some time. But I’m happy with our beta program approach, and I’m looking forward to a few months from now when we can finally put this zombie project back in the grave.
Finding the Real Bottleneck (Value Stream Map )
It’s been a few weeks since monitors started popping up like mushrooms in the IT and development areas. Douglas gave us some pretty firm guidelines – he wanted our release failure rate, frequency, and our defect count showing. Our recovery time, MTTR , still isn’t up there despite a few tries on my part; we also haven’t been able to figure out how to show the hours spent prepping each release or separating out noncode from code related defects.
As I feared, it doesn’t take long for some to figure out how to game the system. Alex has found a few cases where engineers are gating bugs so their overall defect rate looks better than it is. And some teams are focusing too much on keeping their releases green, which is slowing them down.
So, it’s not a perfect view of what is actually happening out there. But it’s better than what we had before, which was a murky view at best of one piece of the system. George gives me a huge grin one morning as we look over our release rates. “It’s like I keep telling you Ben – if you give an engineer a number, he’ll kill himself trying to make it better.” And I have to say – ramping up our release rates may not mean much by itself, but in combination with our other KPI’s it seems to be promoting some of the behavior we are looking for.
We try to use these numbers, not as a club, but as a start to a conversation with our teams, and not overreact to “red” values. If we start clamping down on negatives, we’re sure to get fake numbers and evasion – we want honest discussions and a better understanding of what’s blocking us. Often, there’s contributing factors we can help resolve as management that would remain hidden if we brought out the pitchforks and torches.
It’s a mixed bag as yet. I can’t claim any magical transformations as yet with this drive for transparency, but it does seem to be driving home the main message Douglas wants us to send: team first, no more localized incentives and KPIs.
I still have fences to mend with Footwear, my primary customer. I start making the trek across the street to their offices a part of my daily ritual; usually I can catch a few minutes with Tabrez first thing in the morning. It takes a few weeks of relentless pestering and a few lunches, but finally Tabrez and I are able to come to an agreement; yes, releases are happening more often and with fewer defects, but new features are still rolling out at an almost glacial pace. Tabrez and I agree that it’s past time that we take a second look at the overall flow of work and see if our constraints have changed.
This time, we decide to make the assessment and audit more of a metrics-based approach and done in a less home-grown way. For this exercise to work, we are going to need a truly neutral third party that can cut across team and department barriers with a clear, unbiased mandate. So I ask Emily to come up with a list of three consulting agencies that she had worked with in the past and trusted; after a round of interviews, Tabrez and Douglas select a well-known San Francisco based consulting firm that has an excellent track record.
I had some initial reservations, but I end up very impressed with the consultant they select for the audit. Karen comes from the manufacturing world and understands Lean theory very well; she’s sharp as a tack and has an impressive track record. No doubt the assessment will be both comprehensive and somewhat painful. Still, Tabrez is enthusiastic about the effort. Emily, somewhat mollified as I’ve been following through in participating in her release planning activities, is onboard as well.
By the time Karen is able to come onsite, I’ve almost forgotten about the audit and have to scramble a little to clear up room on my calendar. Surprisingly though, Karen doesn’t spend a lot of time interviewing the division heads or the team leads to get their thoughts. Instead, she mainly sits in the team areas as they conduct their daily scrums, or sets up shop on Emily’s side of the building. I catch a glimpse of her once talking animatedly to Elaine, and we pass each other in the corridor once when I’m leaving the Footwear offices. Otherwise, she’s a complete cipher to me. I have no idea what she’s going to put in her report; I’m worried about damage control in case she digs up something unpleasant about our team.
When I mention to George that I’m a little worried that Karen might not be getting the right strategic view of things, George chuckles and says, “Ben, I’ve been watching Karen, and I think you’ve got nothing to worry about. She doesn’t miss a trick. Let’s just watch this play out and see what she comes up with.”
At the end of the second week , Karen calls a leadership meeting with Tabrez, Douglas, Emily, and myself to go over her assessment. She begins by covering some of the changes that had been made over the past few months to their release management processes. “From what I can gather, a few months ago you determined that your releases were the likely pain point, but that seemed more of a guess than anything else. No one ever seems to have looked at the entire release process start to finish and put some numbers behind why features were creeping out the door. We did come up with some numbers that showed a lot of pain around integration and stabilization, and a very fragile release process.” She displays the following:

She continues, “Obviously wasting almost 300 hours getting a release ready and then having most of them fail – or have to spend more time trying to fix bugs post-release – isn’t sustainable. So the changes we’ve made to date – investing in version control as an authoritative source for all your releases, using automated builds and continuous integration, and a better partnership between Dev and Operations seems to be paying off. But we’re obviously not there yet – even with releases happening more often, new features still are not making it out to production fast enough for us to innovate and keep ahead of WonderTek’s competitors.”
Emily interrupts, “Nancy, with all due respect, you never took the time to meet with me and you couldn’t possibly be aware of all the history going on here in just two weeks. We have a track record of bringing in changes late that are unreliable and that force long war room releases that stretch on for days, into the evening and over weekends. No Operations team can survive this. I’m a little disappointed that you didn’t take more time to show a holistic view of what’s going on.”
Nancy replies smoothly, “My mission here – and we discussed this well ahead of time – was to cut through all the clutter of that history that you mentioned, Emily. We’re trying to make this as facts-based as possible, from the point of view of your end customer, Footwear. As I said, no one has ever mapped out the entire release cycle – that’s from inception to entering the dev backlog, to it going out the door in a release to production and then post-release support. In the companies I’ve worked with, the problem is never a ‘bad’ team that is deliberately obstructing work; it’s usually a flaw in the process, where we aren’t seeing things in global context. Making this flow of work visible usually is the first step to making real progress.
“In the past few weeks, I’ve spent time with your business analysts, Footwear management, your architects, some developers and UAT people, and the Operations people handling release and infrastructure builds. Here’s the process from start to finish with the most recent release:”
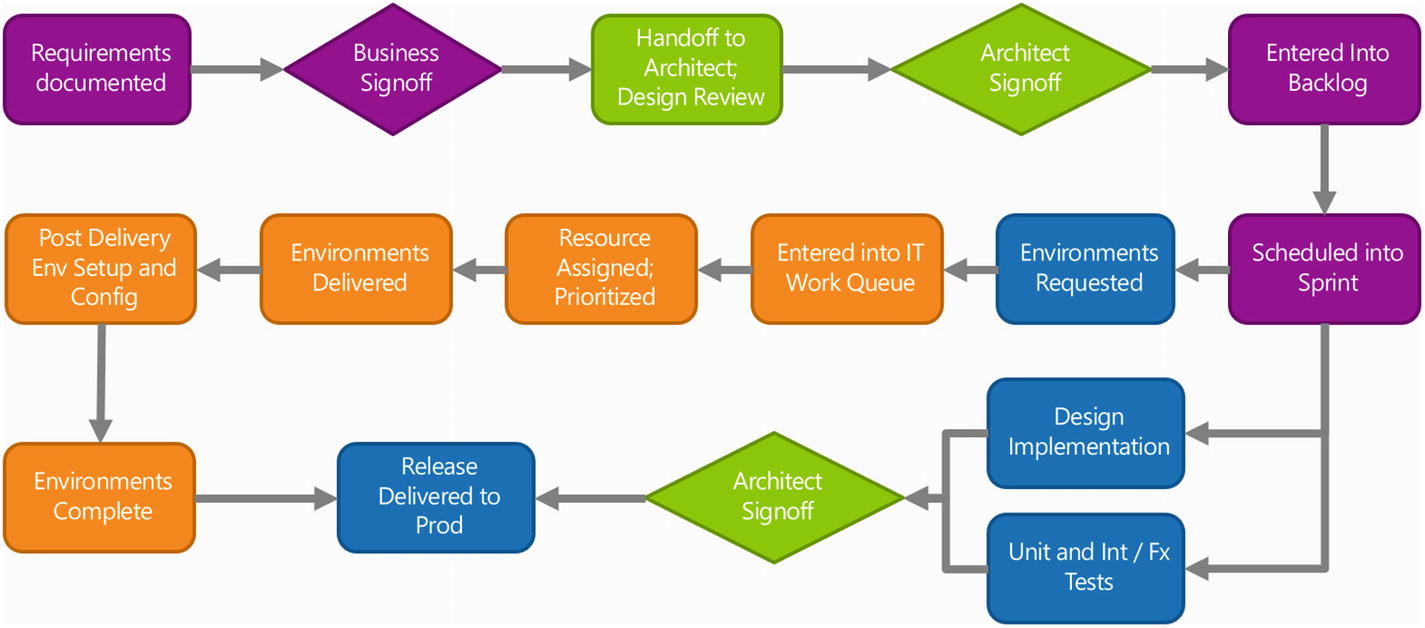
“Above, I put BA-centered activities in purple, architectural gates in green, development centered tasks in blue, and IT/infrastructure tasks in orange. You could argue that this isn’t a true end to end scenario, as I’m not covering the ‘fuzzy’ parts like initial conceptualization and post-release monitoring and operations. However, I think – big picture – this does capture every step needed to bring one release out the door. Did I get this about right?”
After a few seconds pause with no objections, she continues: “So, the Business Analyst documents requirements; these are signed off by the customer, at which point an architect looks over the requirements and drafts a design. That design might include libraries, a recommended web framework or programming language, or a specific design pattern that the architect favors. After this design is signed off by the architects, the BA enters it into the backlog and its prioritized. For this particular release, the changes requested were important enough that it was entered into the next sprint right away.
“From here the developers ask for new environments from the IT/Ops team if needed. In this particular case, we did need a full set of environments created for DEV/QA/STG/PROD to host the new services requested. While the new environments are being built out, the programmers begin work on creating the code implementation. I talked with Rajesh and some other QA people about the change made to create unit tests and integration/functional tests in parallel with code development; it seems like creating test code along with application code as part of every release is making a real difference in improving overall quality. But I’ll get back to that later.
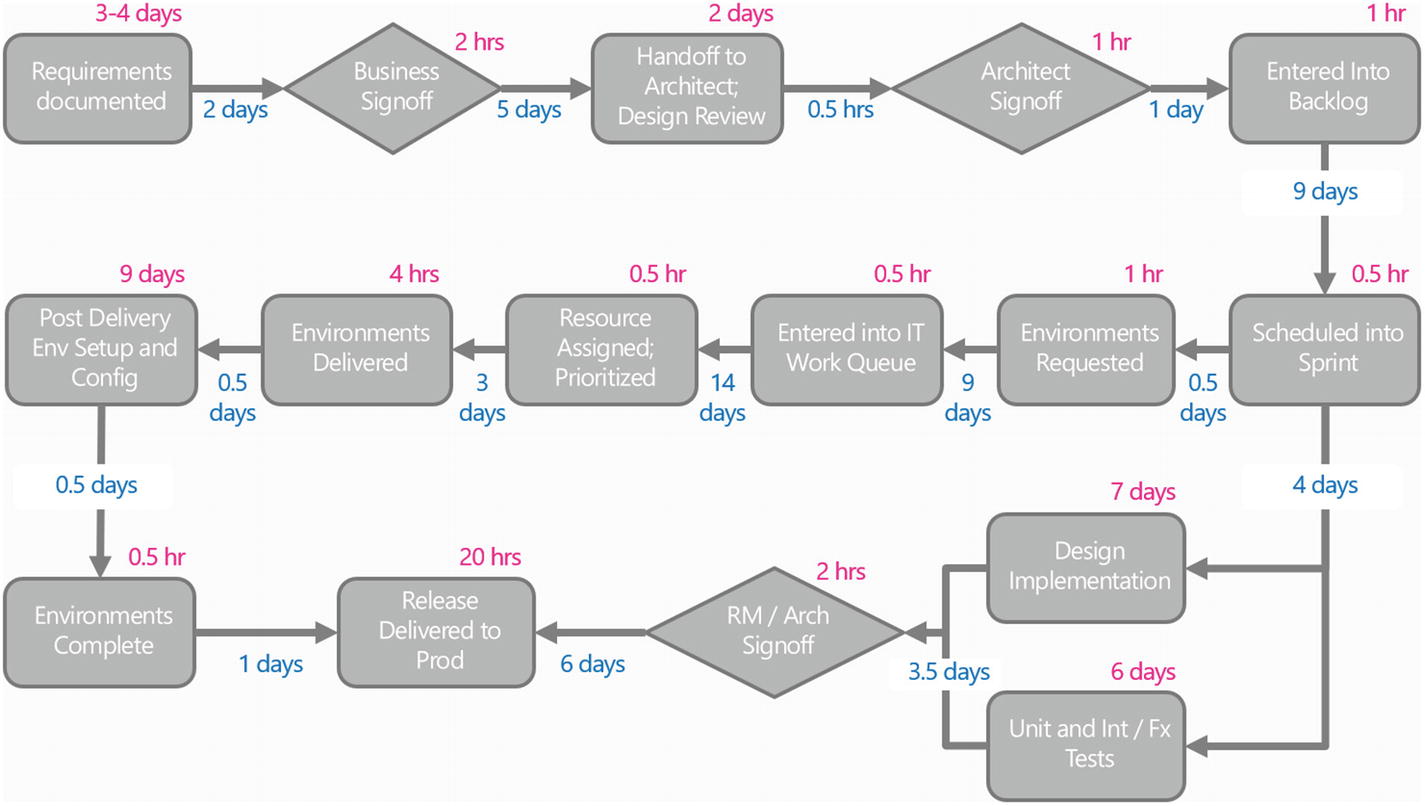
“A few interesting things here though – for this most recent release, creating those environments caused an almost four week delay in the project. During this time the code was actually done for several weeks – that’s why the dashboard shows a 9 day release cycle , which looks terrific. That’s deceiving, because the actual release date was much, much longer than that. Because environments were not ready, the release had to be delayed. Putting some numbers behind these steps exposed the problem even more clearly. Here I made the steps a neutral gray, put wait times in blue and process or work times in pink on the top right.”
She continues, “If we compress this down even further, we get a much better picture of the entire release cycle :”
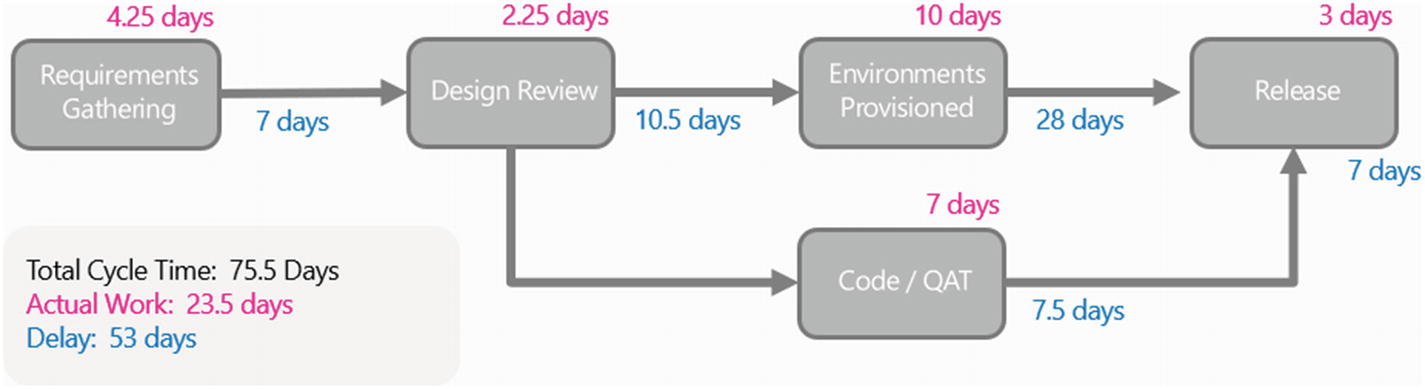
I could see jaws drop around the room; Tabrez looked like he’d been hit with a 2x4. He sputters, “This is our cycle time? I mean, I’m not surprised that it is taking almost a full quarter to get work done for even the most minor request, that’s not anything new. But are we really spending more than two months with work just sitting there waiting on a handoff?”
Douglas looks almost sick. “I set a really high standard of delivery for my teams, and this is a complete surprise for me. And I hate surprises. Which team is responsible for this awful performance?”
Karen replied, “Well, this will all be in my audit report. I can tell you, it’s not one particular team or person that is causing a problem. The process itself has gaps that we will need to close for the system to work efficiently. Here’s a few notes I took showing some of the positive and negative attributes of each step of the release cycle. You can see here, no single team is ‘the problem’. If you were thinking that releases and CI/CD was going to magically make things better – perhaps that was true six months ago, but it’s no longer true now.”
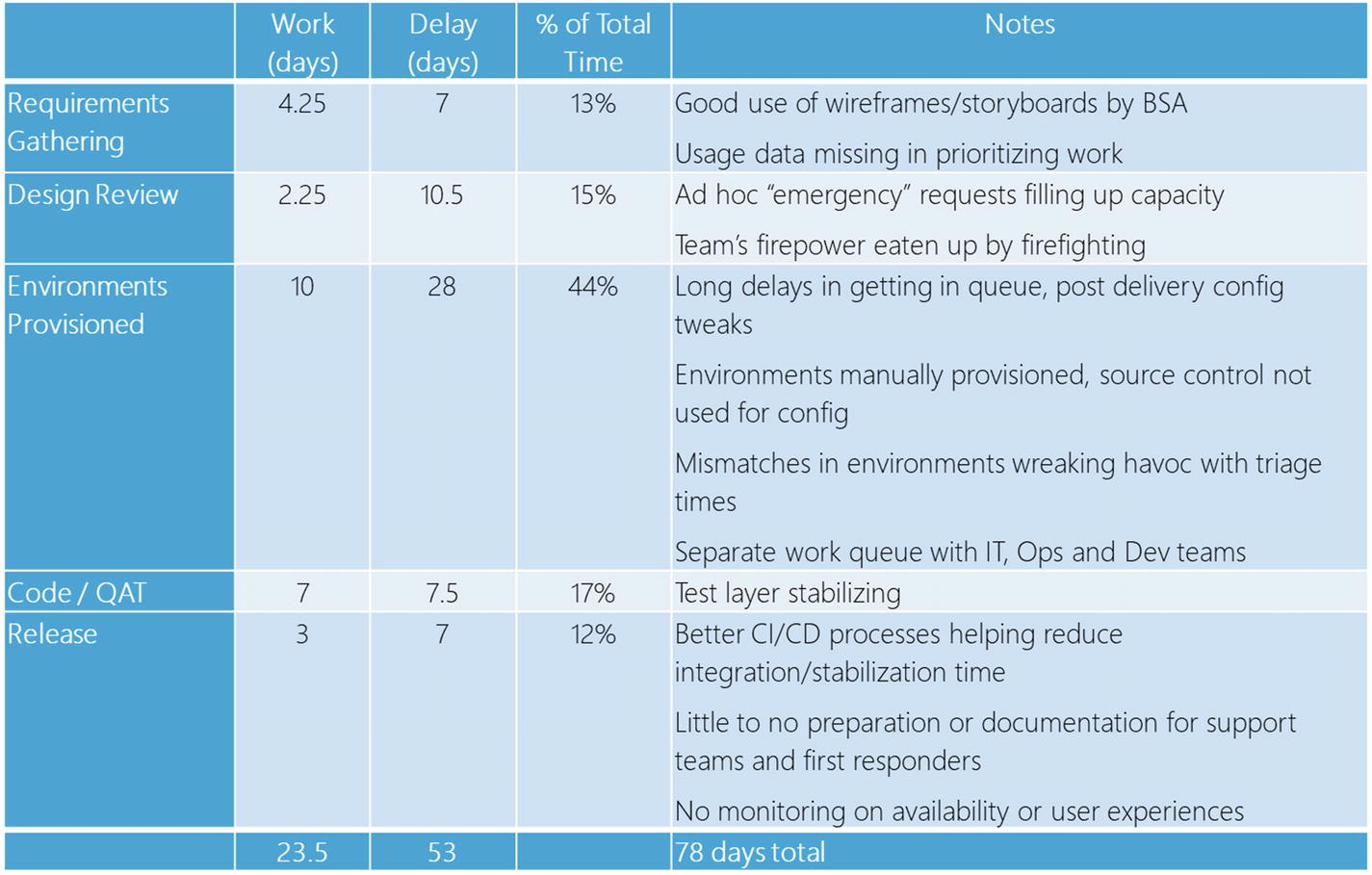
I feel a little bonked on the head as well. We’ve been working so hard for the last few months to get our house in order; how could we have made so little progress? I ask, “Are you saying that all our improvements have not budged the needle at all? That we’re stuck in a swamp? Because that doesn’t reflect what I hear from the team.”
Karen smiles consolingly and replies, “I think it’d be easy to look at this and feel discouraged. There are some positives and a lot of progress that we should celebrate. For example, it does seem like not having long stabilization periods and a better focus on delivering test code along with application code is helping. And there’s some real positives outside of the dev sphere – for example, the BSA’s are doing a great job of having their specifications be in wireframes or PowerPoint storyboards before vetting it with the stakeholders. That’s a real timesaver as it’s easier to rewrite or throw away a wireframe than it is code. IT is starting to use more version control when it comes to configurations and in templating out environments, although we’re only seeing this for just a few applications to date. It’s anecdotal, but I do hear from the IT and Operations team that there is a better handoff and coordination happening with the programming teams.”
Nancy continues, “There’s some problems we’re not showing. For example, I mentioned that there’s little to no prep work happening with the first responders. That’s having a direct downstream impact on your developers, Ben, in the form of false alarms and firefighting easily triaged bugs that are passing along untouched to hit the engineers directly. It also means customers are having to wait a frustratingly long time when their problems could be easily diagnosed and resolved within minutes by the first or second support level.
“There’s a few stage gates here that I think could be rethought – for example that 23 day period from requirements first being gathered to the design being written up. In the case I looked at, the design went through a lot of revisions during implementation, so most of that time spent coming up with an optimal design ended up in the trash can. With such a long approval cycle, we think it would be a good idea for you to explore concepts like a true minimum viable product. Because of that delay, work is finding its way in ungated through side doors. Each day I kept seeing people “just dropping by” to their favorite developer’s desk and asking for little tweaks or asks as a favor; it’s a rough estimate but I imagine at least a quarter of your team’s time is dribbling away here unseen, Ben. There’s a lot of disruption caused by these ad hoc requests and it shows the process as it currently stands isn’t lightweight enough if so much is coming in by a side door.
“But the overall picture shows these gaping holes that need to be closed by the management team. Let’s show them here.”

“Working backwards, you have a long list of aging features because the team is getting gobbled up by firefighting and fixing bugs from the last release. Because there is no effective usage monitoring for any of your applications, you have no idea what should be prioritized and what should be abandoned, so you are flailing when it comes to what little feature work is being done. Because your environments are inconsistent from PROD to DEV, there’s a lot of rework when it comes to setup and then separating out noncode related issues and bugs caused by patches or failing infrastructure. And you need a better prepared front line response so the team can spend more time on productive, innovative work.
“Like I said at the beginning, there’s not one particular culprit; the problem is systemic. If we are thinking of the release process end to end as a train, the problem is that there is no coupling between the groups handling the design, spinning up the environments, writing the code, and operationalizing and supporting the work. Each thinks they are doing the best they can, which they likely are – locally. But globally, because the train cars are uncoupled, work is not able to be delivered safely and on time.”
The next slide causes another ripple of discussion throughout the room. As I said, I’ve been working hard on building a better relationship with Emily and the Ops team. But it doesn’t take a genius to see that provisioning environments seemed to gobble up half our time on the project.
Karen has seen our dashboards, but she asks anyway how we measure what value means. I make my pitch for MTTR again, as resilience is something I definitely want showing. Douglas says, “I think that our change success rate is the key number. If we’re reliable in what we release, then we have happier customers and I get more sleep.”
Emily chips in, “We like CPU and memory counters to get ahead of problems, but it all comes down to reliability and availability. Three 9’s to me is a good baseline to start with – and it’s likely all we need to look at. If the environments aren’t available, then the applications won’t run.”
Karen says, “I see all kinds of metrics being thrown around, and it all comes from what you choose to value – is it speed to market? Security? Stability? There’s no wrong answer – but the fact that you are all coming in with a different answer of what value means should tell us that we’re not on the same page yet, that each team is thinking locally. We shouldn’t see the problem as ‘fixing’ IT or Operations,. The problem is the gap – that interstitial space between the boxes that I put in blue. In ‘Team of Teams ’ Stanley McChrystal called this the ‘blink’, and he made closing these gaps the centerpiece of the fight against Al Qaeda. As long as your teams are seeing their mission as being ‘99.9% uptime’, or ‘coding done in two sprints’, you won’t be able to win the battle.”
My head is hurting, and I pinch the bridge of my nose to try to think clearly. “If we get a thousand to-do’s thrown at us, I guarantee you that nothing will be done. I refuse to accept that this is an unfixable situation, and I don’t want us to get stuck in the mud here. Karen, we came into this meeting with a clear mandate from Footwear – they want more frequent releases, more reliably. So, Tabrez, am I correct when I say that if we could deliver an end to end release – that’s from concept to delivery – in two weeks, that this is the target we should be shooting for?”
Before Tabrez can answer, Emily starts to laugh. “Ben, more frequent releases by itself is where you guys were six months ago. That didn’t win you anything but a skyrocketing bug count, remember?”
I shrug off the migraine that’s hammering between my eyes, and say firmly: “From what I can see here, Emily, it looks like none of that time was wasted. In fact, it’s given us the foundation we needed to come up with a solution that can deliver real value, at tempo. As long as we’re pitching this as being the fault of one team and one team only – and pretending that our systems are perfectly safe as long as ‘bad people’ stop touching it – we’ll never make real progress. The enemy here isn’t anyone in this room – it’s the delays and waste whenever we pass work from one team to another.”
Douglas breaks in. “Obviously we’re still seeing some different point of views here that need to be reconciled. But that’s not the point of this meeting and I don’t want us picking out solutions when the problem itself isn’t defined clearly. Karen, thanks for coming and for this presentation. You’ve posed some good questions here that we will need to answer, and I’m looking forward to that audit report. Let’s talk again once it’s ready.”
Behind the Story
Three big hurdles were jumped in this chapter; holding blame-free postmortems , developing software features using hypothesis-driven development, and mapping out the flow of value comprehensively. What value are these three concepts going to offer Ben’s team in their journey?
Blameless Postmortems
Underneath every simple, obvious story about ‘human error,’ there is a deeper, more complex story about the organization.
—Sidney Dekker 1
By removing blame, you remove fear; by removing fear, you enable honesty; and honesty enables prevention.
—Bethany Macri 2
Jeff Bezos famously once said that “failure and invention are inseparable twins.” Yet for every company like Amazon that handles mistakes and failure as an opportunity to learn, we see a hundred others that follow instinctively JFK ’s saying after the Bay of Pigs fiasco: “Victory has a hundred fathers and defeat is an orphan.”
A few years ago, Dave was heading in to work and decided to stop by and grab a coffee at one of his favorite joints. He glanced at the paper by the checkout stand, and there it was – his company, right on the very front page, top and center. A recent mailer had accidentally printed the customer’s date of birth and social security number, right on the mailing envelope; it had been sent out to tens of thousands of people. This was a very public and visible gaffe that would require months of damage control; whoever made this mistake could look forward to weeks under a very public magnifying glass, at the very least. A cold wave of fear ran down his spine – oh crap, was that me?
Turns out the inadvertent leak wasn’t his fault, but it very well could have been. Those of you who have been in the room when a deployment fails and a rollback is not working know that sense of fear well.
How We Respond to Mistakes Defines Us
Power Oriented (Pathological) | Rule Oriented (Bureaucratic) | Performance Oriented (Generative) |
|---|---|---|
Low cooperation | Modest cooperation | High cooperation |
Messengers shot | Messengers neglected | Messengers trained |
Responsibilities shirked | Narrow responsibilities | Risks are shared |
Bridging discouraged | Bridging tolerated | Bridging encouraged |
Failure ➤ scapegoating | Failure ➤ justice | Failure ➤ inquiry |
Novelty crushed | Novelty ➤ problems | Novelty implemented |
- 1.
Absence of trust (unwilling to be vulnerable within the group)
- 2.
Fear of conflict (seeking artificial harmony over constructive passionate debate)
- 3.
Lack of commitment (feigning buy-in for group decisions, ambiguity)
- 4.
Avoidance of accountability (ducking responsibility to call out peers on counterproductive behavior)
- 5.
Inattention to results (focusing on personal success, status, and ego before the team)
Westrum – Pathological Orgs | Lencioni – Five Dysfunctions |
|---|---|
Low cooperation Messengers shot Responsibilities shirked Bridging discouraged Failure leads to scapegoating Novelty crushed | Absence of trust Fear of conflict Lack of commitment and buy-in Avoidance of accountability Inattention to results |
The two very neatly overlap, as you can see. Pathological and bureaucratic organizations – the type where we’ve unfortunately spent the majority of our careers! – lean toward power/personality politics or a set of departmental fiefdoms governed by “rules.” This directly impacts how well information and work flow inside the organization and how trust, openness, and collaboration are actually valued.
Ultimately, this has a major impact on how well the company ship is run. If employees are aligned on a single mission, less effort is wasted on departmental infighting and blame-fixing exercises. Leaders in trust-based, generative cultures have better information available to them so they can follow up on good bets – and abandon bad ones without fear of taking a political hit.
In practice, we find that the Westrum study makes a great rear-view mirror but is a crappy windshield. It’s very helpful in diagnosing why poor performing companies tend to veer toward shame, name, and blame games when there’s failure – but depressing as hell when it comes to thinking about the future. In many cases, the cultural traits of an organization and how it responds to failure can be very ingrained and – in Ben’s case – well above his pay grade. What’s a mortal team lead or divisional manager to do?
Taking a lesson from SOA principles, it is possible – we’ve seen it many times – where even on a team level it is possible to create an oasis where the right behavior is encouraged; this in turn can have ripple effects elsewhere. Obviously, WonderTek is not generative by the way that high severity outages are being handled; mistakes are either minimized, blame is shifted, or a big red hammer comes out to punish the guilty. But Ben is starting in the right place by changing his behavior and that of his team when things go wrong, and expecting his partners to toe the same line.
This isn’t something that can wait; how Ben’s team and he react to this high-visibility outage could undermine months of work as they try to grow toward a more transparent, honest, and productive flow of work.
Postmortems with Teeth
You’ll notice that Ben’s team ends up with several action items that are immediately added to the developer work queue. John Allspaw was famous for not allowing people to leave postmortems at Etsy until remediation tasks were identified and dropped into their Jira work backlog. All of these items were typically actionable in 30 days, and it was rare for them to take longer than 6 months. These remediation steps followed the SMART rule established by George Doran – Specific, Measurable, Assignable, Realistic, Time-Related.6
Hindsight bias (assuming events are predictable despite incomplete info)
Confirmation bias (find and favor facts that support your pet theory)
Outcome bias (evaluate decisions based on bias and not info available at the time)
Recency bias (recent events are given more emphasis than those further in the past)
Fundamental attribution error (other people’s faults are intrinsic, due to personality or bad intentions, vs. situational)
The group will have a trend to slip into this type of bias instinctively, which is why Etsy forbids using terms like “could have” or “should have” during postmortems.7 The facilitator should state this during a brief introduction, and anyone should feel comfortable to call out bias to get the postmortem back on track.
Part 1, 30–40 minutes: What happened. Build a timeline of events, using logs, chatroom records, and release notes. Describe what happened – what was known at that time, and why the decisions made sense at the time. The goal here isn’t to come up with remediation steps – that comes later – but simply to get better understanding of the context. Consensus on these facts must be agreed to before the group can continue.
Part 2, 10–15 minutes: Open discussion. This is an exploration of what could make the organization better prepared for the next event. Many times the issue comes down to decisions being made with partial information or the “fog of war” – gaps in runbooks or documentation need to be improved, handoffs or support triage improved, better notifications and visibility to customers, stakeholders, or troubleshooting personnel. Any and all ideas here are welcome – anything that can especially improve the application’s robustness, lessening the time to detect problems and implement a fix. In this step – if the root cause is found to not include some tweak to sharing knowledge, adding better alerts and monitoring, or improving support triage – we suggest you haven’t dug deep enough into the “second story.”
Part 3, 5–10 minutes: Remediation items. These are usually actionable in 30 days, and typically not more than 6 months. Remember the SMART rule we mentioned earlier – Specific, Measurable, Assignable, Realistic, Time-Related. If the group leaves without having at least 1–2 new work items dropped into their work backlog – including hopefully some way of measuring if the changes are producing the desired outcomes – the meeting has not reached its objective.
One last comment – the results of this need to be broadcast, searchable, and transparent to everyone – including the business/stakeholder partners, and the teams both developing and supporting product work. Some groups have been very successful using some form of the Morgue OS tool; others use Wikis or the application knowledgebase. Any good postmortem will end up with at least one actionable and practical follow-up point; that’s the entire point of the exercise. Toothless, inconclusive retrospectives and postmortems are as useless as having a buddy rubberstamp a peer review.
A Focus on Guardrails Not Punishment
In “the traditional way of handling the aftermath of such an outage – we would now come together and yell at the person who was maintaining the system that broke. Or the one who wrote the code. Or the one working on fixing it. Surely if they had just done a better job, we wouldn’t have had that outage. This usually ends in a very unproductive meeting where afterwards everybody feels worse. And on top of that you didn’t even find out what really happened.” 8
It’s immensely satisfying and very easy to buy into the “bad apple” theory and try to make an example of someone who made a mistake. In pathological organizations, this is the currency of the realm; team leads and directors score points against other fiefdoms by successfully pinning blame and responsibility for mistakes elsewhere. Good organizations dig deeper than that; they begin every postmortem with the mindset of building guardrails. Acknowledging that these are complex systems and we have an imperfect understanding of our current state and dependencies, how do we make our changes safer, and provide more information for the next time?
These postmortems are blameless because we assume everyone makes mistakes from time to time. Post mortems aren’t criminal investigations, they’re an affirmative process designed to make us all a little smarter:
A blamelessly written postmortem assumes that everyone involved in an incident had good intentions and did the right thing with the information they had. If a culture of finger pointing and shaming individuals or teams for doing the “wrong” thing prevails, people will not bring issues to light for fear of punishment.
…When postmortems shift from allocating blame to investigating the systematic reasons why an individual or team had incomplete or incorrect information, effective prevention plans can be put in place. You can’t “fix” people, but you can fix systems and processes to better support people making the right choices when designing and maintaining complex systems. When an outage does occur, a postmortem is not written as a formality to be forgotten. Instead the postmortem is seen by engineers as an opportunity not only to fix a weakness, but to make Google more resilient as a whole. 9
People won’t take risks if there’s a fear of drastic failure. If we want people to experiment to get better performance, we have to convince them that if they mess something up, they won’t get fired. If every outage is treated as opportunity to blame someone, we’ll never learn anything.
There are some very well publicized incidents where an engineer caused a major outage by running a command against production. If you go into the postmortem looking to blame the engineer, that’s the wrong approach. This was fundamentally a problem with the architecture, with safety, not a human problem. Why did this user have read/write access to every row and table in the production system? Why does the staging database live on the same subnet as the production database? These questions become action items or specific steps that can improve the overall reliability and health of the system. But if your developers are afraid that if they break something they’ll get fired – they’re not going to be on the top of their game, they’re going to suck at their jobs, because you have a fear-based culture. 10
It’s never the fault of Dave, that guy who wrote the horrible code – why did we miss that as a best practice in our code review? Did we miss something in how we look at maintainability, security, performance? Are lead developers setting expectation properly, how can we improve in our training?
Blame is the enemy of learning and communication. The challenge for us is setting the expectation that failure is an expected outcome, a good thing that we can learn from. Let’s count the number of failures we’re going to have, and see how good our retrospectives can get. We’re going to fail, that’s OK – how we learn from these failures? 11
What About Accountability?
Doesn’t a blame-free postmortem really just mean that no one is accountable or held responsible? Etsy in particular has found that not to be the case; management (in particular John Allspaw) took great care to set up what they called a “just culture” that balanced safety and accountability. John noted the negative effects of blame culture, where details are hidden out of fear of punishment/CYA type actions, and its acidic effect on trust. “Less-skilled companies name, blame, and shame,” he noted.
A funny thing happens when engineers make mistakes and feel safe when giving details about it: they are not only willing to be held accountable, they are also enthusiastic in helping the rest of the company avoid the same error in the future. They are, after all, the most expert in their own error. They ought to be heavily involved in coming up with remediation items.
So technically, engineers are not at all “off the hook” with a blameless postmortem process. They are very much on the hook for helping Etsy become safer and more resilient, in the end. And lo and behold: most engineers I know find this idea of making things better for others a worthwhile exercise. 13
Far from preventing accountability, blameless postmortems may be the best way of maximizing a team’s effectiveness. In a recent 5-year study, Google found that a great team depends less about who was on the team, and more on intangible characteristics – how the team works together. Top on their list of five characteristics was psychological safety – an environment that is judgment free and where thoughts can be shared without fear, and where mistakes are learned from instead of punished.14
It’s no coincidence that many of the high performers we try to emulate – companies such as Netflix, Google, Etsy, Facebook – all had moments in their past where they were colossal dumpster fires from a maturity standpoint. What set them apart from their competitors is their ability to learn fast – both to acknowledge and learn from mistakes, a strong ability to improve. Dig far enough and you’ll find under each of these very different companies is a single common thread – a blame-free culture; an eagerness to acknowledge and learn from failure in a scientific way.
Your grandfather might have told you once that how we handle adversity shows character. How we handle mistakes as a culture is also often the ceiling of our organization. It could be the most common limiting factor that we see, regardless of size or company type. Without a healthy, generative approach to handling mistakes, any DevOps movement you initiate will end up being just words on the wall.
Hypothesis-Driven Development
The cheapest, fastest, and most reliable components of a computer system are those that aren’t there.
—Gordon Bell
A complex system that works is invariably found to have evolved from a simple system that worked. The inverse proposition also appears to be true: A complex system designed from scratch never works and cannot be made to work.
—John Gall
The code you write makes you a programmer. The code you delete makes you a good one. The code you don’t have to write makes you a great one.
—Mario Fusco
Let’s say you’re absolutely killing it at a big-money Texas Hold ‘Em Tournament – made it to the second day with a nice pile of chips, about $51,000. And things just keep getting better – you look at your pocket cards and two aces are staring back at you. This is the proverbial “bullet” or “rocket” hand – the strongest starting position in the game, a 221:1 lucky break. If you win the pot at this point, you’d nearly double your stack. Should you go all in?
That’s exactly the position Benoit Lam was in on the second day of the 2017 Poker Stars Monte Carlo championship. Most players with pocket aces would go all-in in his position; it’s easy to fall in love with the beauty of a strong opening hand like this and get locked in, “married to the hand.” Yet as other cards came down and it became obvious that his hand was weakening, Lam chose to fold his hand in as a bad bet.15
Any investment is about betting when you have an edge and folding when you hold no advantage, or in poker terms, you have poor cards… Without getting clouded by the beauty of the Aces…, clearly focus on hand ranges and likely ranges just as you always do with any other starting hands and make your decision based on those facts rather than anything else. …Sometimes it’s not only fine to fold Aces, but essential if you are to become a winning poker player. 16
In the poker world, the bets you choose not to make is what sets you apart. The same thing is true in football – if distance thrown or arm strength were what counted, we’d have gunslingers like Jeff George and Brett Favre at the very top of the NFL pyramid. Instead, we consider accurate, rock-steady throwers like Tom Brady and Joe Montana the best of all time – judged by their touchdown-to-interception ratio, especially in crunch situations. In other words, just like with poker hands, it’s the throws you DON’T make that set you apart as a quarterback.
We wish that kind of dispassionate, logical decision-making – being willing to walk away from a bad bet, or throw the ball away instead of taking a sack or throwing a pick – was more common in the software world. Instead, companies often end up falling in love with a bad hand. In the section “When Is a “Requirement” Not a Requirement?”, Ben is trying to instill some more discipline around intake so the limited capacity of his team isn’t thrown away on bad bets. In the process, he’s taking head on a major source of waste in most software development teams – eliminating unwanted features.
Software Features Are Bets
We’re all well familiar with the 80:20 rule ; it’s a maxim in software that 20% of the highest priority features will satisfy 80% of customer needs. That same 80:20 rule also comes into play with the bets we choose to make with features; one study showed that only 20% of a software’s features are frequently used; by far, the majority (64%) of the features developed were rarely or never used.17
The features your team is working on are really bets. Forty years of software development demonstrates conclusively that most of these bets are in fact losers – offering negative or neutral value. Each feature or line of code we write in these dead-end missions ends up costing us time we could have invested elsewhere – we will now be building and maintaining vast rooms completely empty of customers, while actual viable and productive ideas languish, buried deep in the dusty caverns of our backlog.
We should stop using the word ‘requirements’ in product development, at least in the context of nontrivial features. What we have, rather, is hypotheses. We believe that a particular business model, or product, or feature, will prove valuable to customers. But we must test our assumptions. We can take a scientific approach to testing these assumptions by running experiments. 18
Quick – what’s the biggest waste in software development? Defects? Rework? Documentation? Work in progress? Communication? Coordination?
Those are all big wastes for sure. But the biggest waste is building features that nobody wants. We can put up with rework and defects if we at least get something useful at the end of the day. The problem with unwanted features is that you not only incur all the other wastes, but you end up developing nothing useful. Worse, you could have the best delivery process in the planet, and it still won’t save you from incurring this waste. 19
Both poker pros and manufacturing mavens would find our obstinate reliance on hard-set “requirements” and long delays in getting customer feedback incomprehensible. Unlike cars or virtually anything else, code is cheap and easy to play with; tailor-made for experimenting and prototypes. Early on, typically within a few weeks, we should be able to come up with something usable that can demonstrate an idea. Once we show this to a customer, there’s nothing stopping us from getting their input and quickly folding it into the next version of the design. It’s hard to imagine – with this kind of a safe, incremental, experimental approach – that our current rate of project success would stay as miserable as it currently is.
Yet, too often, there is no feedback loop set up to tell us early on if a product or feature will have the results we expect. And often, “agile” development teams are not allowed to change requirements or specifications en route without approval or authorization from some external group – usually, a project management team or executive board. Being handcuffed like this to a bad hand often results in a development team that is hopelessly out of touch with the customer base, working on features that will be rarely or never used.
Hypothesis-Driven Development
Thankfully there’s an alternative approach to this kind of joyless toil, and it isn’t a long jump from where Ben’s team already is. A team that is strong at decomposing work into small batches and making the flow of work visible to all is likely not far off from what we call “hypothesis-driven development.”
Improving your software delivery pipeline will improve your ability to work in small batches and incorporate customer feedback along the way. If we combine these models across years, it becomes a reciprocal model, or colloquially, a virtuous cycle.
In software organizations, the ability to work and deliver in small batches is especially important, because it allows you to gather user feedback quickly using techniques such as A/B testing. It’s worth noting that the ability to take an experimental approach to product development is highly correlated with the technical practices that contribute to continuous delivery. 20
This experimental approach to software – something called hypothesis driven development – is really just a matter of treating each “requirement” for what it really is – a guess – and setting in controls early on so you can tell if your guess is dead on or needs to be reworked. In short, hypothesis-driven development really comes down to knowing when to fold a bad bet.
Implementation is oh so easy. You simply gate any new story, feature, product backlog by asking a standard set of questions. PMI has long advocated the A3 system , which sounds intimidating but is really just a single piece of paper covering the project goals and experiment conditions at a high level. Others favor the Lean UX template , which is the one Ben’s team chose:
We believe that [building this feature] [for these people] will achieve [this outcome]. We will know we are successful when we see [this signal from the market.]
Hypothesis: We believe {customer segment} wants {product/feature} because {value prop}
Experiment: To prove or disprove the above, the team will conduct the following experiment(s): …’
Learn: The above experiment(s) proved or disproved the hypothesis by impacting the following metric(s): …
Again, quite nifty; it states explicitly that this is an experiment and provides a clear go/no go indicator to show whether the experiment is worth continuing.
We discuss this in Chapter 3, but Microsoft has found HDD so valuable that it has folded it into its official Definition of Done for code check-ins. Validation is so inexpensive compared to the cost of creating and supporting a new feature that we believe it should be a required part of any backlog item before any actual coding work is done.
Do We Still Need Project Managers?
It’s a common misperception among both Agile and DevOps devotees that project management – including PMO and the business analyst layer – is suddenly a thing of the past. We couldn’t disagree more. In fact, it’s been our experience that strong delivery-focused organizations rely more heavily on the strategic planning, resourcing, coordination, and customer engagement skills that both the beleaguered project manager and BSA bring to the table. Without strategic or epic-level guidance and budgeting, larger enterprises would suffer chaotic, incoherent product development and waste from cross-team friction and overlap. And a great BSA is the everyday hero and conscience of the team; they engage constantly with the customer to better identify and prioritize work, act as a team advocate to keep expectations of management in line with reality, help shape acceptance testing that is focused and value driven, and act as a guardrail to keep the product’s featureset useful and valuable to the end user.
Good project managers keep that engagement with your business partners and stakeholders humming. Mike Kwan once explained that as a PM, one of his most valuable lessons “wasn’t how to schedule better; it was how important it is to be in constant communication with sponsors, to document, to communicate. It’s incredibly important to define your success criteria right at the beginning.”21
And BSAs are a great check and balance on self-inflicted wounds by the devs. We should note here that – despite our using the big bad BSA as the black hat in this section – one of the most frequent culprits in dragging out project timelines are not PMs but – gasp! – the engineers. In the military, brilliant inspirations about the magical benefits of a new tool are said to be inspired by the Good Idea Fairy – a malignant creature definitely not friendly to humans or project timelines. In the DevOps world, we often see the Good Idea Fairy whispering in the ears of engineering teams with the promotion of some fantastic, world-changing language, holistic platform or toolset. A good BSA or PM will make sure that the team stays focused on driving true business value with each sprint, instead of working on a technically driven wish list of cool, cutting-edge glitter.
Breaking Down Bowling Balls
The natural enemy of the development team is the infamous Bowling Ball Story that we often receive unfiltered from customers or stakeholders – a big, heavy, impenetrable, seemingly indivisible requirement. Left alone or unquestioned by that hero BSA or by the team in its sprint planning, these “requirements” will act as a cover for all kinds of unintended scope creep. Basic Agile hygiene tells us to work with our stakeholders to follow the INVEST principle – Independent, Negotiable, Valuable, Estimable, Small, and Testable.
Again, the hero BSA can come to our rescue, by starting with acceptance criteria – what does the finish line look like from their perspective? – and working backward to small, bite-size stories that can be delivered in stages. This will also streamline the automated acceptance testing suite – as Continuous Delivery pointed out, “blindly automating badly written acceptance criteria is one of the major causes of unmaintainable acceptance test suites…. It should be possible to write an automated acceptance test proving that the value described is delivered to the user.”22
Limiting scope is something that is often preached but incredibly difficult to implement in practice – both developers and stakeholders are eager to deliver as much as possible. The road to hell is lined with good intentions and runaway scope creep. We’re reminded of one episode of the TV show “30 Rock ,” where the executive Jack Donaghy and his design team set out with the desire to build the perfect toaster for GE and end up with design plans for the Pontiac Aztek!
Internal-only projects in particular seem to be particularly susceptible to runaway feature creep. We’ve worked on several projects with internal customers who insisted on unrealistic uptime SLAs and gold-plated requirements that were expensive to implement – and impossible to test and support. One project in particular involved working with a very headstrong – and politically powerful – business analyst, who constantly tacked on pet features and extra requirements – and contemptuously waved developers aside with a sweeping motion when we’d come with questions, saying “Just go do it.” Another project we were on overran its timeline by 6 months because the BSA on the project kept changing requirements. With no direct customer feedback to inject reality, and no written list of goals, objectives, or success standards to guide us, the project was finally scrubbed as a failure. One manager we talked to recounted a story of laboring for months on a requirement from Marketing around reverse translating CAD models to a previous version – with very little supporting evidence that this was a viable scenario, or even something asked for by customers.
Here, thank goodness, that close and constant link to the customer – something we inherited from the original Agile Manifesto – comes to our rescue. Forcing the ritual of asking the Hypothesis/Experiment/Learn questions at the onsite forces us to think about where exactly the finish line is, what our assumptions are, and how to get feedback in measurable terms from our end user community, early and often.
If a requirement or story can’t be delivered in weeks or months, call it out in the planning/prioritization meeting for what it is – a bowling ball. Take the time to refactor and split that big, indivisible object into chunks. Our focus needs to be on solving a real and urgent customer problem as quickly as possible. If we can’t quantify what that means, it needs to be refined or dropped.
The Value of a True MVP
The first sprint is typically just a proof of concept of the CI/CD tools and how they can work on that top #1 feature we’ve identified. The development team works on it for perhaps 2 days, then sysops takes over and uses our tooling to get this feature into the sandbox environment and then production. This isn’t even a beta product, it’s a true MVP – something for friends and family. But it’s an opportunity to show the business and get that feedback that we’re looking for – is the UI ok? How does the flow look? And once the people driving business goals sit down and start playing with the product on that first demo, two weeks later, they’re hooked. And we explain – if you give us your suggestions, we can get them to staging and then onto production with a single click. It sells itself – we don’t need long speeches.
The typical reaction we get is – “great, you’ve delivered 5% of what I really want. Come back when it’s 100% done.” And the product is a little underwhelming. But that’s because we’re not always sticking to the true definition of a minimum viable product (MVP) . I always say, “If an MVP is not something you’re ashamed of, it’s not a MVP!” Companies like Google and Amazon are past masters at this – they throw something crude out there and see if it sticks. It’s like they’re not one company but 1,000 little startups. You’ve got to understand when to stop, and get that feedback.
I’ve seen customers go way down in the weeds and waste a ton of money on something that ends up just not being viable. One customer I worked with spent almost $250K and a year polishing and refactoring this mobile app endlessly, when we could have delivered something for about $80K – a year earlier! Think of how the market shifted in that time, all the insights we missed out on. Agile is all about small, iterative changes – but most companies are still failing at this. They’ll make small changes, and then gate them so they sit there for months. 23
Don’t Shift on Quality
The first problem is most conversations begin with a date. That is the first mistake. When you lead with a date then ask if can we make it, developers start to subtract back from that date in their heads and start making compromises. The first time-saver is to cut out testing, which will lead to customer satisfaction issues and technical debt. Technical debt, like credit card debt, accrues interest that you must pay eventually. The hit to your reputation with your customers will take even longer to repair.
…What I needed was the teams honest, unbiased opinion of the effort of each task. Once that was established, the onus was on the product owner to set the priority of the items such that they got what they needed by the date only known to them. Dates became forbidden. The simple fact was if you need 9 days’ worth of work in 5 days, you were not getting it.
…We have all seen quality suffer to make a date. If anything should be nonnegotiable, it should be quality. …I know dates exist, but many are not as important as we are first led to believe. They are used to motivate but do more damage than good. How many times have you been told the date cannot be moved, but when you fail to deliver, the date moves? 24
That’s not to say that dates aren’t to be discussed, ever. Every organization we’ve worked with has a different view of what is important in the famous “Iron Triangle” of project management – Dates, Resources/Cost, and Functionality. Some enterprises demand a full set of features but are willing to add more resources and can shift on the dates. Other companies require a full production release by X date but can be negotiable on which features roll out the door. Quality however should be a fixed, nonnegotiable point. The date can get scooted, or we can reduce the feature set; but how work is delivered shouldn’t change. After all, how many civil engineers or architects do you know that change the approval protocols or specifications for a building or bridge because “we don’t have time for testing”?
Good vs. Bad Documentation
We’re asking people to write down more with HDD, which seems odd and a little anti-Agile. Wasn’t one of the best bits of the Agile Manifesto about favoring “working software over comprehensive documentation”? Are we creeping back to the bad old days creating reams of requirements and feature documentation?
Hardly! But there’s no denying it – documentation at the right time and place can be a real life-saver. For example, one project we worked on involved creating a data warehouse and a REST-based API displaying products, sales information, and images for a company site. The project had a reputation as being an albatross after several failed tries – nothing like it had been done before, the performance requirements were tight, visibility to a reactive management layer was red-hot, and it involved integrating five very different data stores.
Instead of rolling up our sleeves and beginning “real work” on Day 1, we took the time to write down in a single one-page document everything we knew about the project at an executive level – and had it signed off by our executive sponsors. This was a very simple statement of the problem or goal and how we meant to go about solving it with our experiment. We listed the problem statement and performance requirements and desired outcomes, any assumptions we were making, and how we were going to go about trying to reach this goal. We also showed specifically how we would know if this was a viable solution, including some risks that could end up causing us to scrub the effort.
It’s not an understatement to say that this single page saved the project. Having a defined finish line and conditions of acceptance in writing meant we could work on the problem without worrying about the finish line moving on us. When an architect dropped by midproject with an added “enhancement” that would have bloated out our data store, we used that document as a shield, an agreed upon contract. The project was delivered as a successful prototype in the third week – almost 3 months ahead of schedule, and the only effort in several years to come in ahead of time and under budget.
The Deming cycle that so revolutionized the Japanese car industry in the 1970s – and in turn came to software development in the form of Lean – is embodied in the Plan-Do-Check-Act cycle . As some have said, we’re very good at the Plan and Do portion – coming up with a hypothesis , and designing an experiment to test it – but not so good at the Check-Act portion, where we go over the results and change our model and approach. Having in writing our understanding of the problem or goal, and our conditions of success, is GOOD documentation that keeps us in a learning and experimenting mode, following up on success and abandoning failure quickly.
The Cutting Edge of the Saw
Hypothesis-Driven Development tends to lead to and complement the use of something we’ll be discussing later in more detail – feature flags. Once teams start adopting feature flags as part of their release cycle, they also gain the ability to tweak and test usage and adoption of new features. As any new feature wrapped in a flag can be easily killed, it leads to a more experimental-focused delivery with shorter validation windows – a nice, natural transition to hypothesis-driven development. Netflix , in particular, is an outstanding example of a company that uses feature flags and frequent updates based on usage validation from their customers.
The ability to be able to ideate – whip up a prototype, push it to a small subset of users, and get feedback – can be the cutting edge of your DevOps saw. Your product teams will be happier and more energized with that short turnaround time and narrow focus, as they’ll see the benefits from their work and a comfort level that they are not investing their time in dead ends. Your PMO team and stakeholders will know which features deserve refinement and promotion, and which to drop. And your customers will be delighted as the things they want appear instead of gathering dust in a backlog.
Value Stream Mapping
An army may be likened to water, for just as flowing water avoids the heights and hastens to the lowlands, so an army avoids strength and strikes weakness.
—Sun Tzu
One of the biggest failure points I see is that people often don’t make their work visible enough. If you don’t know what people are working on across the team, that creates a natural siloization which reduces ability to collaborate. Not being completely transparent across the org is one of the biggest pitfalls that I’ve seen.
—Michael Goetz , Chef
We’re still very much in trouble , as you can see from the section “Finding the Real Bottleneck.” The team is still completely blind about what features are useful and valuable to their end users, so their development and support is likely going to the wrong places. Mismatches in their environments – and the fact that each environment is a hand-created work of art – are wreaking havoc in terms of setup and maintenance costs, not to mention creating constant overhead when tickets come in as a significant number are caused by noncode-related issues; this also is likely causing a significant amount of distrust in their release testing as their test environments do not reflect production loading or configuration. Leaving aside the troubling anomalies and manual toil this creates, the developers are almost completely tied down with firefighting because their first and second line of defense – the Operations response team – isn’t trained or prepared to handle any kind of support.
The main issue though as Karen is bringing out in her assessment is what the book Team of Teams calls the “blinks” – the spaces between teams. It’s clear no single team is the “problem” – each is trying to do the best they can, and each is tasked up well past 100%. But Ben’s development team still sees their mission as writing code; Emily’s IT team as standing up environments with high availability; the BSAs and PMs as scoping and delivering requirements from the business; and the Operations team as creating and then reassigning tickets as fast as possible. Each group is describing value as part of the elephant; none can describe their mission in terms of the global whole. The fact that IT, Operations , and Developers all have completely separate work queues and dashboarding is a dead giveaway – there is work still to be done in embracing value delivery from one perspective, the customers.
Finding the Pinch Point
The value stream analysis does point out that one of the main pain points in terms of flow does come down to the way WonderTek is provisioning environments. Defining the pinch point is a key part of Lean and is defined as the “Theory of Constraints .” It can be compared to an actual bottleneck or dam on a stream – if we try to improve the flow of water upstream of the dam, it simply piles up more water as a load on the constraint downstream. If we try optimizations after the dam, they’ll be ineffective as the overall flow won’t change. The theory of constraints teaches that any changes outside of that single pain point are ephemeral and that local optimizations (“we’re releasing to QA twice as fast now!”) can actually destroy global optimization.
If developers are practicing continuous integration, ending each day with a build ready to test, and if the test organization is unable to test at that rate, then it needs to be addressed. If Dev-test is running two-week sprints but the Ops team takes three weeks to provision a new test server, it needs to be addressed. If Dev-test teams are able to operate continuously, delivering code with a high velocity through two-week sprints, but the business analysts are providing new user stories in large blocks once a quarter, which is slower than the delivery velocity, it needs to be addressed. If the security team is only able to run their security tests on new apps, only once per release cycle, and take 5 to 10 days to run their tests, it needs to be addressed. If integration builds are taking hours to complete because they build every component and module, even those that did not change, it needs to be addressed. If the lines of business expect projects to operate on project plans with fixed, gate-based schedules but in reality their requirements are not well understood, the project plans need to be addressed. 25
I love that phrase of progressive elaboration , and I use it all the time. So start by rolling it backwards. Start with getting it in the hands of your users – without even talking about what it is they’re doing. How frequently are you going to deliver it? How are you going to ensure that what you’re delivering is what the users expect? What’s your acceptance test on product features? How are you going to define quality?
Progressive elaboration allows us to learn from doing. Execution yields insights that just weren’t possible from extensive upfront planning – which is often informed by assumption or old experiences. It allows us to start, learn, and avoid being paralyzed by trying to completely plan upfront based on information that is likely to change or become stale.
These methods didn’t exist when we ported project management methods from hardware to software. The hardware development ramps included long lead time and expensive tooling and manufacturing costs. But software isn’t like that. We can write code early, and then throw it away if we learn something. And we can change it right up to the last moment. 26
We’re guessing that very few if any of your team has a clearly mapped and visible view of the flow of work end to end, from idea to product. Coming up with this picture isn’t a matter of a few minutes, but it also shouldn’t take more than a few days with the right people in the room and a little digging. We favor permanent markers and giant sticky notes to keep the moving parts as simple as possible so the group doesn’t bog down in minutiae.
The map doesn’t need to be revisited daily , or even weekly. But it’s an excellent idea to revisit it from time to time and see how things are improving. For shared services organizations, some have found it helpful to hold a regular collaboration workshop, where the leaders review the stream and commit to optimization steps as a group.27
There’s lots of metrics to choose from, but two metrics stand out – and they’re not new or shocking. Lead time and cycle time. Those two are the standard we always fall back on, and the only way we can tell if we’re really making progress. They won’t tell us where we have constraints, but it does tell us which parts of the org are having problems. We’re going after those with every fiber of our effort. There’s other line of sight metrics, but those two are dominant in determining how things are going.
We do value stream analysis and map out our cycle time, our wait time, and handoffs. It’s an incredibly useful tool in terms of being a bucket of cold water right to the face – it exposes the ridiculous amount of effort being wasted in doing things manually. That exercise has been critical in helping prove why we need to change the way we do things. Its specific, quantitative – people see the numbers and get immediately why waiting two weeks for someone to push a button is unacceptable. Until they see the numbers, it always seems to be emotional. 28
The pain point (what the military calls a “limfac ,” a limiting factor) may surprise you. Perhaps, the main pain point is at the very beginning – what we call the “fuzzy front end,” the length of time ideas and features spend in limbo until they’re assigned to a developer’s work queue as a backlog item. One leader we spoke to started out considering lead time as being relatively unimportant; once he realized how much his business partners were frustrated by apparent delay and slow progress on mission critical ideas, displaying progress in terms of lead time became his touchstone. It could also be the testing cycle, or a manual stage gate preproduction. Other times, as we see in this book, the time spent provisioning and readying environments is the limfac. The point is – until you measure it, and keep it displayed, it won’t get better.
I had lunch a few weeks ago with a CIO of a Manhattan-based Fortune 500 company in which I tried to help him understand his DevOps questions. I asked him if they had ever tried to use the Lean Value Stream Mapping process to understand their overall cycle times. He proceeded to give me a tongue lashing about how he has been studying Lean Sigma for over 1000 years and they had tried every trick in the book. I mention a few other DevOps hacks but we seem to be going nowhere fast. However, near the end of the conversation he says something about his operations team that gives me a clue to ask one more last question. I asked him, ‘When you did the Value Stream Mapping, did you do it across engineering and operations?’ After about 15 seconds of dead silence he sheepishly answered, ‘Shit, we never thought about that.’ 29
Value stream mapping are typically a very revealing exercise; for most people in the room, this may be the first time they’ve seen the amount of hard work and heroics required to get a release out the door . The amount of thrash and stress caused by long lead times and handoff delays is exposed in stark detail, with nowhere to hide. It could just be the ticket to get executive awareness of the price being paid with clunky manual processes and siloed entrenched teams of specialists – a great catalyst for change based on objective data.