
Chapter 1 – What is Columnar?
“When you go into court you, are putting your fate into the hands of twelve people who weren’t smart enough to get out of jury duty.”
– Norm Crosby
What is Parallel Processing?
"After enlightenment, the laundry"
- Zen Proverb

"After parallel processing the laundry, enlightenment!"
-Matrix Zen Proverb
Two guys were having fun on a Saturday night when one said, “I’ve got to go and do my laundry.” The other said, "What!?" The first man explained that if he went to the laundry mat the next morning, he would be lucky to get one machine and be there all day. But if he went on Saturday night, he could get all the machines. Then, he could do all his wash and dry in two hours. Now that's parallel processing mixed in with a little dry humor!
The Basics of a Single Computer

“When you are courting a nice girl, an hour seems like a second. When you
sit on a red-hot cinder, a second seems like an hour. That’s relativity.”
– Albert Einstein
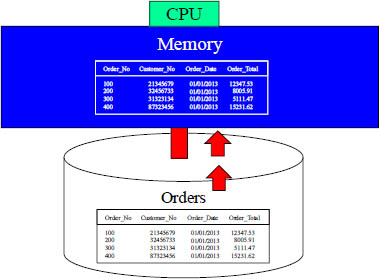
Data on disk does absolutely nothing. When data is requested, the computer moves the data one block at a time from disk into memory. Once the data is in memory, it is processed by the CPU at lightning speed. All computers work this way. The "Achilles Heel" of every computer is the slow process of moving data from disk to memory. The real theory of relativity is to find out how to get blocks of data from the disk into memory faster!
Data in Memory is fast as Lightning
“You can observe a lot by watching.”
– Yogi Berra
Once the data block is moved off of the disk and into memory, the processing of that block happens as fast as lightning. It is the movement of the block from disk into memory that slows down every computer. Data being processed in memory is so fast that even Yogi Berra couldn't catch it!
Parallel Processing Of Data

"If the facts don't fit the theory, change the facts."
-Albert Einstein
Big Data is all about parallel processing. Parallel processing is all about taking the rows of a table and spreading them among many parallel processing units. Above, we can see a table called Orders. There are 16 rows in the table. Each parallel processor holds four rows. Now they can process the data in parallel and be four times as fast. What Albert Einstein meant to say was, “If the theory doesn't fit the dimension table, change it to a fact."
A Table has Columns and Rows

The table above has 9 rows. Our small system above has three parallel processing units. Each unit holds three rows.
Rows are Placed Inside a Data Block

The rows of a table are stored on disk in a data block. Above, you can see we have four rows in each data block. Think of the data block as a suitcase you might take to the airport (without the $50 fee).
Moving Data Blocks is Like Checking In Luggage

Please put your data block on the scale (inside memory)
To a computer, the data block on disk is as heavy as a large suitcase. It is difficult and cumbersome to lift.
Facts That Are Disturbing
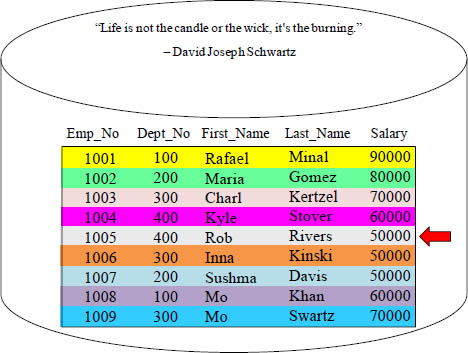
The data block above has 9 rows and five columns. If someone requested to see Rob Rivers’ salary, the entire data block would still have to move into memory. Then, a salary of 50000 would be returned. That is a lot of heavy lifting just to analyze one row and return one column. It is just like burning an entire candle just because you need a flicker of light!
Why Columnar?

Each data block holds a single column. The row can be rebuilt because everything is aligned perfectly. If someone runs a query that would return the average salary, then only one small data block is moved into memory. The salary block moves into memory where it is processed as fast as lightning. We just cut down on moving large blocks by 80%! Why columnar? Because, like our Yiddish Proverb says, "All data is not kneaded on every query, so that is why it costs so much dough."
Row Based Blocks vs. Columnar Based Blocks

Both designs have the same amount of data. Both take up just as much space. In this example, both have 9 rows and five columns. If a query needs to analyze all of the rows or return most of the columns, then the row based design is faster and more efficient. However, if the query only needs to analyze a few rows or merely a few columns, then the columnar design is much lighter because not all of the data is moved into memory. Just one or two columns move. Take the road less traveled.
As Row-Based Tables Get Bigger, the Blocks Split

When you go on vacation for two-weeks, you might pack a lot of clothes. As a result, you may need to take two suitcases. A data block can only get so big before it is forced to split, otherwise it might not fit into memory.
Data Blocks Are Processed One at a Time Per Unit

At the Airport luggage counter, each bag needs to be weighed. You put bag one on first, and then after it is processed, you put on bag two. That is how the processing of data blocks happen- One data block at a time.
Columnar Tables Store Each Column in Separate Blocks

This is the same data you saw on the previous page! The difference is that the above is a columnar design. I have color coded this for you. There are 8 rows in the table and five columns. Notice that the entire row stays on the same disk, but each column is a separate block. This is a brilliant design for Ad Hoc queries and analytics because when only a few columns are needed, columnar can move just the columns it needs to. Columnar can't be beat for queries because the blocks are so much smaller, and what isn't needed isn't moved.
Visualize the Data – Rows vs. Columns

Both examples above have the same data and the same amount of data. If your applications tend to need to analyze the majority of columns or read the entire table, then a row-based system (top example) can move more data into memory. Columnar tables are advantageous when only a few columns need to be read. This is just one of the reasons that analytics goes with columnar like bread goes with butter. A row-based system must move the entire block into memory even if it only needs to read one row or even a single column. If a user above needed to analyze the Salary, the columnar system would move 80% less block mass.
The Architecture of Actian Matrix
“Be the change that you want to see in the world.”
- Mahatma Gandhi
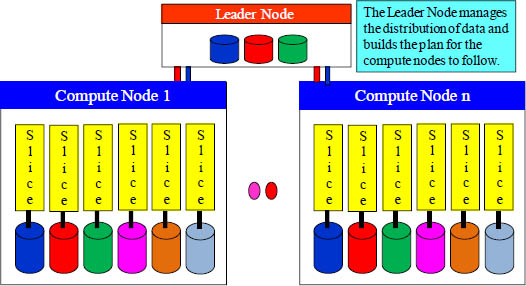
The leader node is the brains behind the entire operation. The user logs into the leader node, and for each SQL query, the leader node will come up with a plan to retrieve the data. It passes that compiled plan to each compute node, and each slice processes their portion of the data. If the data is spread evenly, parallel processing works perfectly. This technology is relatively inexpensive. It might not "be the change", but it will help your company "keep the change" because costs are low.
Matrix has Linear Scalability

"A Journey of a thousand miles begins with a single step."
- Lao Tzu
Actian Matrix was born to be parallel. With each query, a single step is performed in parallel by each Slice. A Matrix system consists of a series of slices that will work in parallel to store and process your data. This design allows you to start small and grow infinitely. If your Matrix system provides you with an excellent Return On Investment (ROI), then continue to invest by purchasing more nodes (adds additional slices). Most companies start small, but after seeing what Matrix can do, they continue to grow their ROI from the single step of implementing a Matrix system to millions of dollars in profits. Double your slices and double your speeds. . . . Forever. Matrix actually provides a journey of a thousand smiles!
Distribution Styles

Matrix gives you two great choices to distribute your tables. If you have two tables that are being joined together a lot and they are about the same size, then you want to give them both the same distribution key as the join key. This co-locates the matching rows on the same slice. Two rows being joined together must be on the same slice (or Matrix will move one or both of the rows temporarily to satisfy the join requirement). If you join two tables a lot, but one table is really big and the other is small, then you want to have the small table distributed by EVEN. Use your distribution key to ensure joins happen faster, but also use it to spread the data as evenly among the slices as possible.
Distribution Key Where the Data is Unique

The entire row of a table is on a slice, but each column in the row is in a separate container (block). A Unique Distribution Key spreads the rows of a table evenly across the slices. A good Distribution Key is the key to good distribution!
Another Way to Create a Table

We have chosen the Emp_No column as both the distribution key and the sort key. We can control both!
Distribution Key Where the Data is Non-Unique
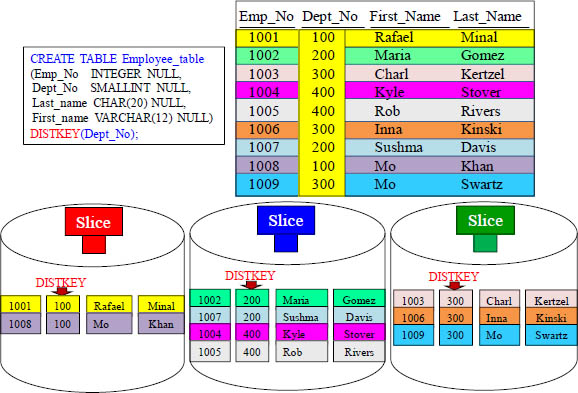
The data did not spread evenly among the slices for this table. Do you know why? The Distribution Key is Dept_No. All like values went to the same slice. This distribution isn't perfect, but it is reasonable, so it is an acceptable practice.
Even Distribution Key

The data did not spread evenly among the slices for this table. Do you know why? The Distribution Key is Dept_No. All like values went to the same slice. This distribution isn't perfect, but it is reasonable, so it is an acceptable practice.
Matching Distribution Keys for Co-Location of Joins
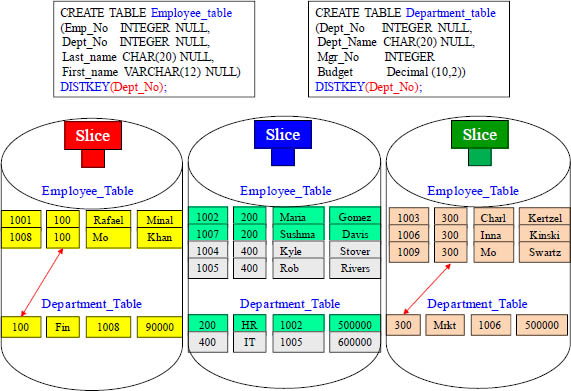
Notice that both tables are distributed on Dept_No. When these two tables are joined WHERE Dept_No = Dept_No, the rows with matching department numbers are on the same Slice. This is called Co-Location. This makes joins efficient and fast.
Big Table / Small Table Joins

Notice that the Department_Table has only six rows. Those six rows are evenly distributed across every slice. This is distributed by EVEN. When two joining tables have one large table (fact table) and one small table (dimension table), then use the EVEN keyword to distribute the smaller table. This will force the smaller table to be redistributed rather than the large table.
Fact and Dimension Table Distribution Key Designs

The fact table (Line_Order_Fact_Table) is the largest table, but the Part_Table is the largest dimension table. That is why you make Part_Key the distribution key for both tables. Now, when these two tables are joined together, the matching Part_Key rows are on the same slice. You can then distribute by EVEN on the other dimension tables which will ensure that the data on these smaller tables are spread evenly across all the nodes in the cluster.
Improving Performance By Defining a Sort Key

There are three basic reasons to use the sortkey keyword when creating a table. 1) If recent data is queried most frequently, specify the timestamp or date column as the leading column for the sort key. 2) If you do frequent range filtering or equality filtering on one column, specify that column as the sort key. 3) If you frequently join a (dimension) table, specify the join column as the sort key. Above, you can see we have made our sortkey the Order_Date column. Look how the data is sorted!
Sort Keys Help Group By, Order By and Window Functions

When data is sorted on a strategic column, it will improve (GROUP BY and ORDER BY operations), window functions (PARTITION BY and ORDER BY operations), and even as a means of optimizing compression. But, as new rows are incrementally loaded, these new rows are sorted but they reside temporarily in a separate region on disk. In order to maintain a fully sorted table, you need to run the VACUUM command at regular intervals. You will also need to run ANALYZE.
Each Block Comes With Metadata
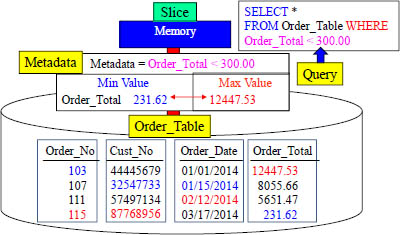
Actian Matrix stores columnar data in 1 MB disk blocks by default. The size can be reduced if queries typically include many columns. The min and max values for each block are stored as part of the metadata. If a range-restricted column is a sort key, the query processor is able to use the min and max values to rapidly skip over large numbers of blocks during table scanning. Where most databases use indexes to determine where data is, Matrix uses the block's metadata to determine where data is NOT!
Our query above is looking for data WHERE Order_Total < 300. The metadata shows this block will contain rows, and therefore it will be moved into memory for processing. Each slice has metadata for each of the blocks they own.
How Data Might Look On A Slice

Matrix allocates 1 MB per block when a table begins loading. When a block is filled, another is allocated. I want you to imagine that we created a table that had only one column, and that column was Order_Date. On January 1st, data was loaded. Notice in the examples that as data is loaded, it continues to fill until the block reaches 1 MB. The Order_Date is ordered (because as each day is loaded, it fills up the next slot). Then, notice how the metadata has the min and max Order_Date. The metadata is designed to inform Matrix whether this block should be read when this table is queried. If a query is looking for data in April, then there is no reason to read block 1 because it falls outside of the min/max range.
Question – How Many Blocks Move Into Memory?

SELECT *
FROM Orders
WHERE Order_Total < 250.00
Looking at the SQL and the metadata, how many blocks will need to be moved into memory?
Answer – How Many Blocks Move Into Memory?

SELECT * FROM Orders
WHERE Order_Total < 250.00
Only one block moves into memory. The metadata shows that the min and max for Order_total only falls into the range for the last Slice. Only that Slice moves the block into memory.
Quiz – Master that Query With the Metadata

Looking at the SQL and the metadata, how many blocks will need to be moved into memory for each query?
Answer to Quiz – Master that Query With the Metadata

Above are your answers.
The ANALYZE Command Collects Statistics
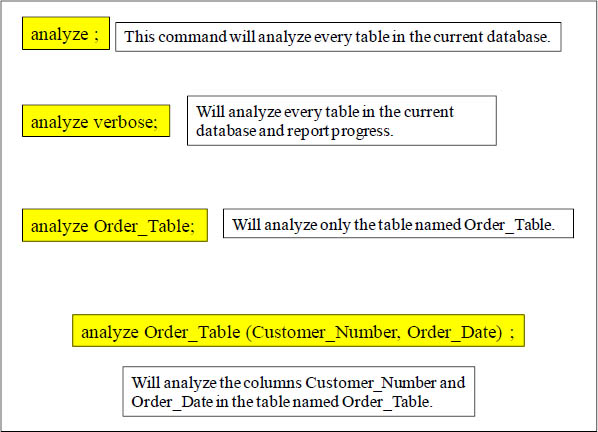
The Analyze command updates table statistics for use by the query planner. You can analyze all the tables in an entire database, or you can analyze specific tables including temporary tables. If you want to specifically analyze a table, you can, but not more than one table_name with a single ANALYZE table_name statement. If you do not specify a table_name, all of the tables in the currently connected database are analyzed including the persistent tables in the system catalog.
Matrix Automatically ANALYZES Some Create Statements
Matrix automatically analyzes tables that you
create with the following commands:
1. CREATE TABLE AS
2. CREATE TEMP TABLE AS
3. SELECT INTO
You do not need to run the ANALYZE command on these tables when
they are first created. If you modify them with additional inserts, updates,
or deletes, you should analyze them in the same way as other tables.

The above examples won't need the analyze statement because it is done automatically. Yet, if you modify these tables, you will need to run the analyze command. The Analyze command updates table statistics for use by the query planner. You can analyze all the tables in an entire database, or you can analyze specific tables including temporary tables.
What is a Vacuum?
| What is a Vacuum? |
Actian Matrix doesn't automatically reclaim and reuse space that is freed when |
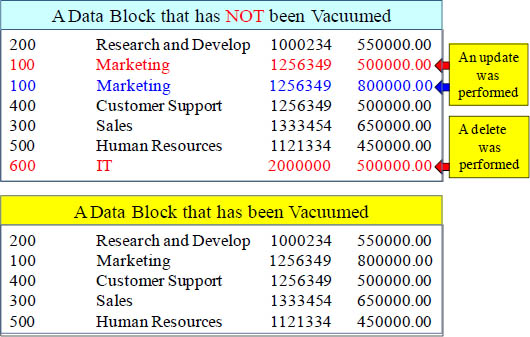
Actian Matrix doesn't automatically reclaim and reuse space that is freed when you delete rows and update rows. These rows are logically deleted, but not physically deleted (until you run a vacuum). To perform an update, Actian Matrix deletes the original row and appends the updated row, so every update is effectively a delete followed by an insert. When you perform a delete, the rows are marked for deletion but not removed.
When is a Good Time to Vacuum?
| When is a Good Time to Vacuum? |
Run VACUUM during maintenance, batch windows, or time periods when A large unsorted region results in longer vacuum times. If you delay VACUUM is an I/O intensive operation, so the longer it takes for your Concurrent queries and write operations are allowed during vacuum |
“Time flies like an arrow. Fruit flies like a banana.”
- Groucho Marx
A vacuum can be time consuming and it is very intensive. That is why the above advice is needed. Vacuum wisely. You can run the vacuum command to get rid of the logically deleted rows and resort the table 100% perfectly. When about 10% of the table has changed over time, it is a good practice to run both the Vacuum and Analyze commands. Like Groucho Marx has basically stated, "If data processing slows down and users get groucho, hit your marks and make if fly after a vacuum."
The VACUUM Command Grooms a Table

When tables are originally created and loaded, the rows are in perfect order (naturally) or because a sort key was specified. As additional inserts, updates, deletes are performed over time, two things happen. Rows that have been modified are done so logically, thus there are additional rows physically still there, but that have been logically deleted. The second thing that happens is that new rows that are inserted are stored on a different part of the disk, so the sort is no longer 100% accurate.
The Matrix database catalog also needs periodic vacuuming and indexing

When tables and views have been dropped from a database this leaves logically deleted records in the database catalog, which is stored in a Postgres database on the leader node. To physically remove wasted space and reindex the database catalog, Matrix uses the following commands: VACUUMCAT and INDEXCAT. If performance slows down when accessing the database catalog this indicates that it is time to free up wasted space and reindex.
Database Limits
Actian Matrix enforces these limits for databases.
1. Maximum of 60 user-defined databases per cluster.
2. Maximum of 127 characters for a database name.
3. Cannot be a reserved word.
CREATE DATABASE SQL_Class2
WITH OWNER TeraTom ;
“Where there is no patrol car, there is no speed limit.”
-Al Capone
The following example creates a database named SQL_Class2 and gives ownership to the user TeraTom. You can only create a maximum of 60 different databases per cluster, so get yours created before the mob!
Creating a Database
create database sql_class ;

“The best way to predict the future is to create it.”
- Sophia Bedford-Pierce
A Matrix cluster can have many databases. Above is the syntax to create a database. The database is named sql_class. The data in a database can help you predict the future, and Matrix makes it so easy to create it. I think Sophia Bedford-Pierce must be a DBA!
Creating a User
create user teratom
password 'TLc123123' ;
Password must:
•be between 8 and 64 characters
•have at least one uppercase letter
•have at least one lowercase letter
•have at least one number

To create a new user, specify the name of the new user and create a password. The password is required, and it must be reasonably secure. It must have between 8 and 64 characters, and it must include at least one uppercase letter, one lowercase letter, and one number.
LDAP/AD is supported if you want to synchronize and manage user passwords using this mechanism. In order to do this, users must be created in Matrix with the same name as used in the LDAP/AD namespace.
Dropping a User
Drop user teratom;
“All glory comes from daring to begin.”
– Anonymous
If you delete a database user account, the user will no longer be able to access any of the cluster databases. The quote above is the opposite of the DBA credo which states, "All glory comes from daring to drop a user."
Inserting Into a Table
INSERT INTO Customer_Table
VALUES (121346543, 'Lawn Drivers', '555-1234') ;
The INSERT command inserts individual rows into a database table.
Renaming a Table or a Column
ALTER TABLE Employee_Table
rename to Employee_Table_Backup ;
ALTER TABLE Student_Table
RENAME COLUMN Grade_Pt to Grade_Point;
The first command renames the Employee_Table to Employee_Table_Backup. The second example renames the column Grade_Pt to Grade_Point.
Adding and Dropping a Column to a Table
ALTER TABLE Employee_Table
ADD COLUMN Mgr int
default NULL;
ALTER TABLE Employee_Table
DROP COLUMN Mgr ;
In our first example we have added a new column called Mgr to the table Employee_Table. The second example drops that column.