
Chapter 4 – Compression
“Speak in a moment of anger and you’ll deliver the greatest speech you’ll ever regret.”
– Anonymous
Compression Types

The table above identifies the supported compression encodings and the data types that support the encoding. Compression reduces the size of data when it is stored, and it is a column-level operation. Compression conserves storage space and reduces the size of data that is read from storage, which will then reduce the amount of disk I/O, thus improving query performance. By default, Actian Matrix stores data in its raw, uncompressed format, but you can apply a compression type, or encoding, to the columns in a table manually (when the table is created). Or, you can use the COPY command to analyze and apply compression automatically. Either way, it is important to compress your data.
Byte Dictionary Compression
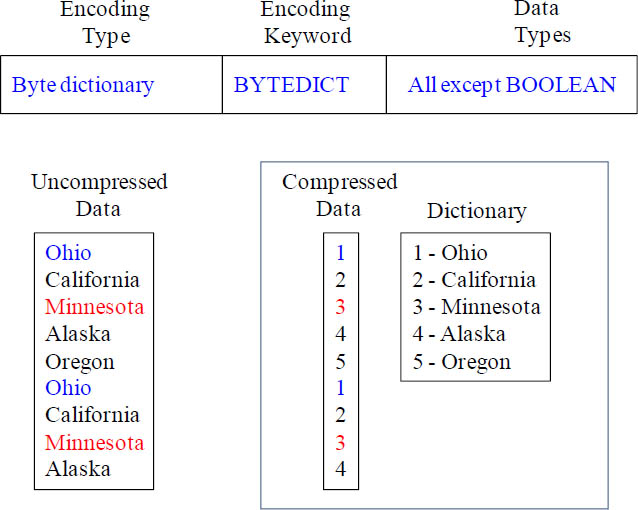
Byte dictionary encoding utilizes a separate dictionary of unique values for each block of column values on disk. Remember, each Actian Matrix disk block occupies 1 MB. The dictionary contains up to 256 one-byte values that are stored as indexes to the original data values. If more than 256 values are stored in a single block, the extra values are written into the block in raw, uncompressed form. The process repeats for each disk block. This encoding is very effective when a column contains a limited number of unique values, and it is especially optimal when there wware less than 256 unique values.
Delta Encoding

Delta encodings are very useful for date and time columns. Delta encoding compresses data by recording the difference between values that follow each other in the column. These differences are recorded in a separate dictionary for each block of column values on disk. If the column contains 10 integers in sequence from 1 to 10, the first will be stored as a 4-byte integer (plus a 1-byte flag), and the next 9 will each be stored as a byte with the value 1, indicating that it is one greater than the previous value. Delta encoding comes in two variations. DELTA records the differences as 1-byte values (8-bit integers), and DELTA32K records differences as 2-byte values (16-bit integers)
Deflate Encoding - Lempel–Ziv–Oberhumer (LZO)

•Designed to work best with Char and Varchar data that store long character strings
•Is a portable lossless data compression library written in ANSI C
•Offers fast compression but extremely fast decompression
•Includes slower compression levels achieving a quite competitive compression ratio while still decompressing at this very high speed
•Often implemented with a tool called LZOP
Lempel–Ziv–Oberhumer (LZO) is a lossless data compression algorithm that is focused on decompression speed. LZO encoding provides a high compression ratio with good performance. LZO encoding is designed to work well with character data. It is especially good for CHAR and VARCHAR columns that store very long character strings especially free form text such as product descriptions, user comments, or JSON strings.
Mostly Encoding

Mostly encodings are useful when the data type for a column is larger than the majority of the stored values require. By specifying a mostly encoding for this type of column, you can compress the majority of the values in the column to a smaller standard storage size. The remaining values that cannot be compressed are stored in their raw form.
Runlength encoding
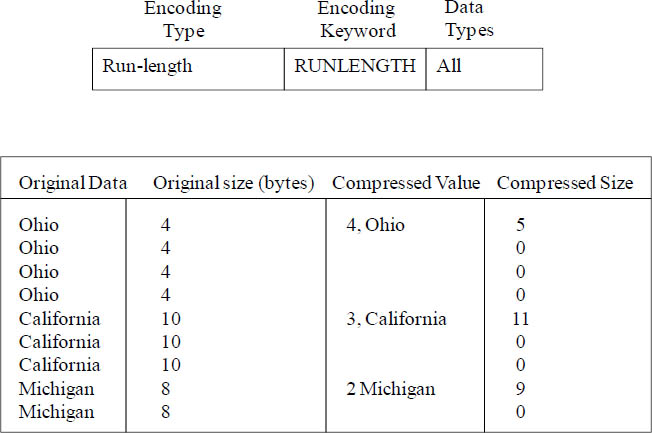
Runlength encoding replaces a value that is repeated consecutively with a token that consists of the value and a count of the number of consecutive occurrences (the length of the run). This is where the name Runlength comes into play. A separate dictionary of unique values is created for each block of column values on disk. This encoding is best suited to a table in which data values are often repeated consecutively, for example, when the table is sorted by those values.
Text255 and Text32k Encodings

Text255 and text32k encodings are useful for compressing VARCHAR columns only. Both compression techniques work best when the same words recur often. A separate dictionary of unique words is created for each block of column values on disk. Text255 has a dictionary that contains the first 245 unique words in the column. Those words are replaced on disk by a one-byte index value representing one of the 245 values, and any words that are not represented in the dictionary are stored uncompressed. This process is repeated for each block.
For the text32k encoding, the principle is the same, but the dictionary for each block does not capture a specific number of words. Instead, the dictionary indexes each unique word it finds until the combined entries reach a length of 32K, minus some overhead. The index values are stored in two bytes.
Analyze Compression using xpx ‘complyze’
psql <database> -c “xpx ‘complyze <tablename>
NOTE: The above example can only be executed using the Actian Matrix command line interface psql
Table_Name– You must specify a table_name. You can also analyze compression for temporary tables.
stl_complyze-Results will be written to a system table (stl_complyze) that summarize the results of various compression options on a per-column basis. Another table is also created with the count of nulls in the table (stl_nullyze). You can query these tables to derive the compression methods that will work best for you.
Unsupported compression methods:
Note that there are two types of compression not analyzed by complyze:
GLOBALDICT encoding
DEFLATE (a.k.a. LZ) encoding
There is a parameter that can be set to allow complyze to also analyze DEFLATE encodings as part of the analysis. Set the following parameter prior to running complyze in order to enable this behavior: set complyze_uses_deflate to on;
The xpx ‘complyze <tablename>’ command performs compression analysis and produces a report with the suggested column encoding schemes for the tables analyzed. The complyze command does not modify the column encodings of the table but merely makes suggestions. To implement the suggestions, you must recreate the table, or create a new table with the same schema. Complyze does not consider RUNLENGTH encoding on any column that is designated as a SORTKEY. This is because range-restricted scans might perform poorly when SORTKEY columns are compressed much more highly than other columns. Complyze acquires an exclusive table lock, which prevents concurrent reads and writes against the table. Only run the xpx complyze command when the table is idle.
Analyze Results from xpx ‘complyze’
CREATE A VIEW TO REVIEW RESULTS
You can query stl_complyze and manually include the groupings and sort or create a simple view to make it easier to analyze the output from xpx ‘complyze <tablename>’:
CREATE or REPLACE VIEW stl_complyze_v (
measuretime, tbl, tbl_name, col, col_name, encoding, size
) as
SELECT
TO_DATE(measuretime, 'YYYY-MM-DD HH24:MI:SS'), tbl, BTRIM(tbl_name), col,
BTRIM(col_name), format_encoding(encoding), SUM(size)
from stl_complyze
group by 1,2,3,4,5,6
order by 1,2,3,4,5,7;
Compression Best Practices:
1. “none” and “raw” are the same thing. If a “none” matches or is very close to the best compressor, use “none” as it has no decompression costs incurred at runtime.
2. If an alwaysN encoding type have almost the same block count as another type (i.e. within 10%), Choose the alwaysN type; there is a numerical bias against alwaysN.
3. If the always8, always16, always32 have almost the same block count, use the lowest N; ie. If always8 is only slightly more than always16, choose always8.
4. LZ is not enabled in the analyzer by default. You’ll need to make your own evaluation whether it is beneficial. If you have very wide varchar and char columns that are not included in your query predicates, you may find it to be very effective. To have complyze also consider DECODE: set complyze_uses_deflate to on;
5. The analyze compression doesn’t report on globaldictXX. You’ll need to make your own evaluation whether it is beneficial based on a count(distinct <column). Note: the count of globaldict* entries for a given column is over the lifetime of the column so you probably do not want to use globaldict* unless you have significantly fewer distinct values than the globaldict type holds.
Copy

The above example (two parts) gives the syntax for the COPY command. COPY invokes the high speed loader for Matrix and is the recommended way to load large amounts of data into the Matrix database. Most of the options are self explanatory. For example: the GZIP option allows one to load files compressed with the gzip utility directly into Matrix without decompressing first. EXPLICIT_IDS allows you to load data directly into the IDENTITY column of a table.