
4.1 Introduction and Use Cases
In this chapter, I present a unified framework to derive and discuss ten adaptive algorithms (some well-known) for principal eigenvector computation, which is also known as principal component analysis (PCA) or the Karhunen-Loeve [Karhunen–Loève theorem, Wikipedia] transform. The first principal eigenvector of a symmetric positive definite matrix A∈ℜnXn is the eigenvector ϕ1 corresponding to the largest eigenvalue λ1 of A. Here Aϕi= λiϕi for i=1,…,n, where λ1>λ2≥...≥λn>0 are the n largest eigenvalues of A corresponding to eigenvectors ϕ1,…,ϕn.
An important problem in machine learning is to extract the most significant feature that represents the variations in the multi-dimensional data. This reduces the multi-dimensional data into one dimension that can be easily modeled. However, in real-world applications, the data statistics change over time (non-stationary). Hence it is challenging to design a solution that adapts to changing data on a low-memory and low-computation edge device.

Rapid convergence of the first principal eigenvector is computed by an adaptive algorithm in spite of abrupt changes in data
Besides this example, there are several applications in machine learning, pattern analysis, signal processing, cellular communications, and automatic control [Haykin 94, Owsley 78, Pisarenko 73, Chatterjee et al. 97-99, Chen et al. 99, Diamantaras and Strintzis 97], where an online (i.e., real-time) solution of principal eigen-decomposition is desired. As discussed in Chapter 2, in these real-time situations, the underlying correlation matrix A is unknown. Instead, we have a sequence of random vectors {xk∈ℜn} from which we obtain an instantaneous matrix sequence {Ak∈ℜnxn}, such that A = limk→∞E[Ak]. For every incoming sample xk, we need to obtain the current estimate wk of the principal eigenvector ϕ1, such that wk converges strongly to its true value ϕ1.
A common method of computing the online estimate wk of ϕ1 is to maximize the Rayleigh quotient (RQ) [Golub and VanLoan 83] criterion J(wk;Ak), where
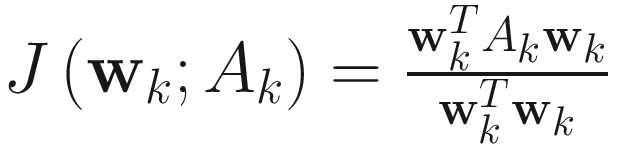 . (4.1)
. (4.1)
The signal xk can be compressed to a single value by projecting it onto wk as 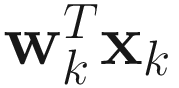 .
.
The literature for PCA algorithms is very diverse and practitioners have approached the problem from a variety of backgrounds including signal processing, neural learning, and statistical pattern recognition. Within each discipline, adaptive PCA algorithms are derived from their own perspectives, which may include ad hoc methods. Since the approaches and solutions to PCA algorithms are distributed along disciplinary lines, a unified framework for deriving and analyzing these algorithms is necessary.
In this chapter, I offer a common framework for derivation, convergence, and rate analyses for the ten adaptive algorithms in four steps outlined in Section 1.4. For each algorithm, I present the results for each of these steps. The unified framework helps in conducting a comparative study of the ten algorithms. In the process, I offer fresh perspectives on known algorithms and present two new adaptive algorithms for PCA. For known algorithms, if results exist from prior implementations, I state them; otherwise, I provide the new results. For the new algorithms, I prove my results.
Outline of This Chapter
In Section 4.2, I list the adaptive PCA algorithms that I derive and discuss in this chapter. I also list the objective functions from which I derive these algorithms and the necessary assumptions. Section 4.3 presents the Oja PCA algorithm and describes its convergence properties. In Section 4.4, I analyze three algorithms based on the Rayleigh quotient criterion (4.1). In Section 4.5, I discuss PCA algorithms based on the information theoretic criterion. Section 4.6 describes the mean squared error objective function and algorithms. In Section 4.7, I discuss penalty function-based algorithms. Sections 4.8 and 4.9 present new PCA algorithms based on the augmented Lagrangian criteria. Section 4.10 presents the summary of convergence results. Section 4.11 discusses the experimental results. Finally, section 4.12 concludes the chapter.
4.2 Algorithms and Objective Functions
Adaptive Algorithms
[Chatterjee Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
I have itemized the algorithms based on their inventors or on the objective functions from which they are derived. All algorithms are of the form
wk + 1 = wk + ηkh(wk, Ak), (4.2)
OJA:
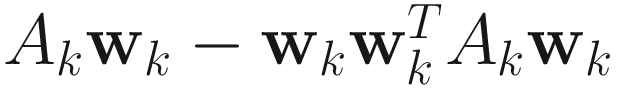 .
.RQ:
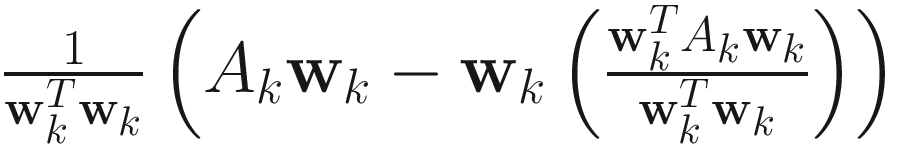 .
.OJAN:
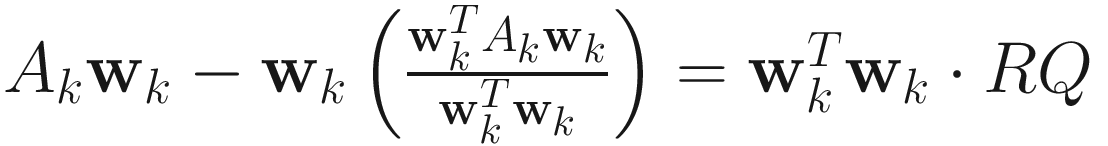 .
.LUO:
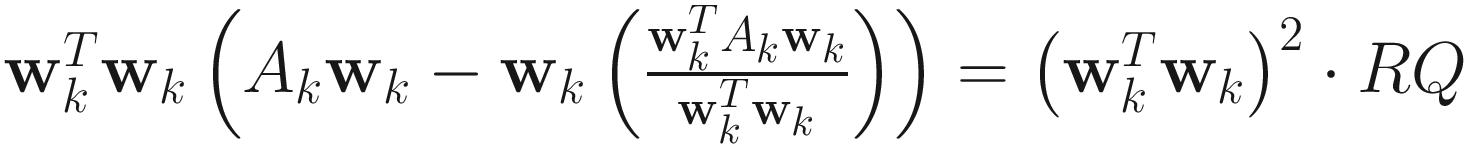 .
.IT:
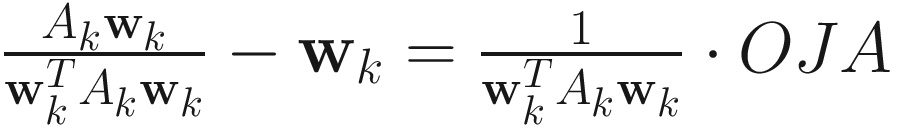
XU:
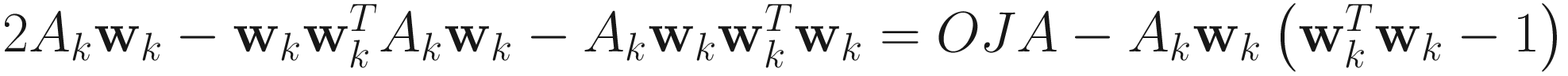 .
.PF:
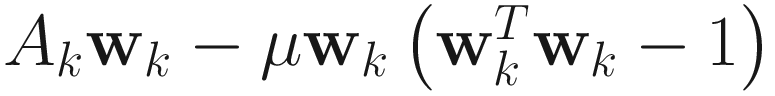 .
.OJA+:
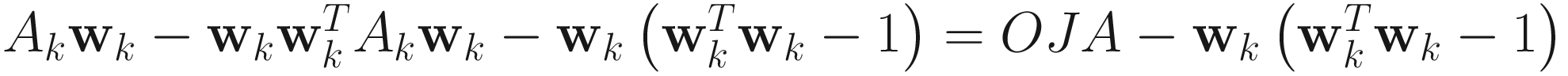
AL1:
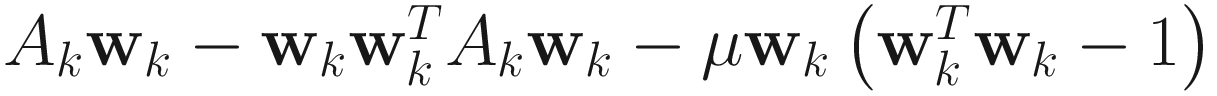 .
.AL2:
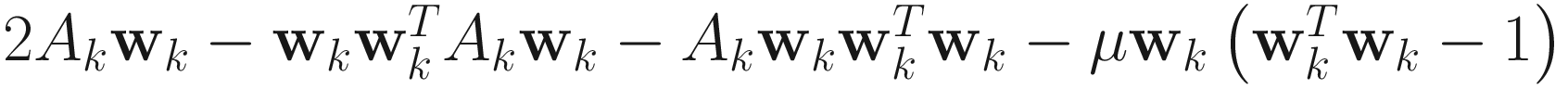 .
.
Here IT denotes information theory, and AL denotes augmented Lagrangian. Although most of these algorithms are known, the new AL1 and AL2 algorithms are derived from an augmented Lagrangian objective function discussed later in this chapter.
Objective Functions
Objective function for the OJA algorithm,
Least mean squared error criterion,
Rayleigh quotient criterion,
Penalty function method,
Information theory criterion, and
Augmented Lagrangian method.
4.3 OJA Algorithm
This algorithm was given by Oja et al. [Oja 85, 89, 92]. Intuitively, the OJA algorithm is derived from the Rayleigh quotient criterion by representing it as a Lagrange function, which minimizes 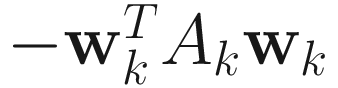 under the constraint
under the constraint 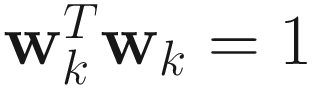 .
.
Objective Function
In terms of the data samples xk, the objective function for the OJA algorithm can be written as
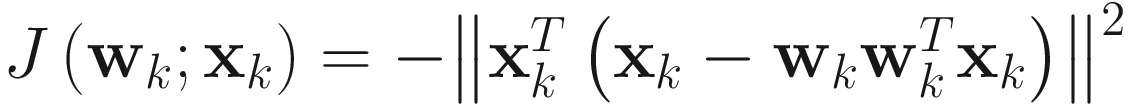 (4.3)
(4.3)
If we represent the data correlation matrix Ak by its instantaneous value 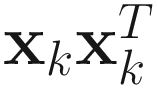 , then (4.3) is equivalent to the following objective function:
, then (4.3) is equivalent to the following objective function:
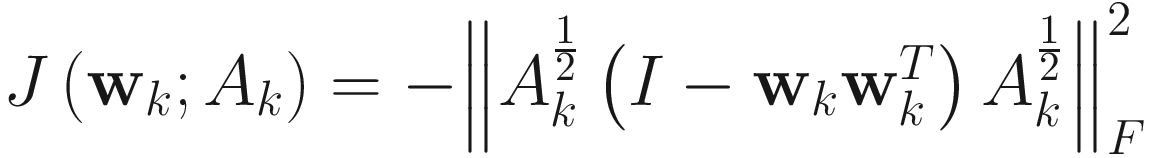 . (4.4)
. (4.4)
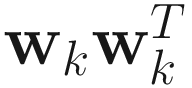 . In neural networks, this transform is called auto-association1 [Haykin 94]. Figure 4-2 shows a two-layer auto-associative network.
. In neural networks, this transform is called auto-association1 [Haykin 94]. Figure 4-2 shows a two-layer auto-associative network.
Two-layer linear auto-associative neural network for the first principal eigenvector
Adaptive Algorithm
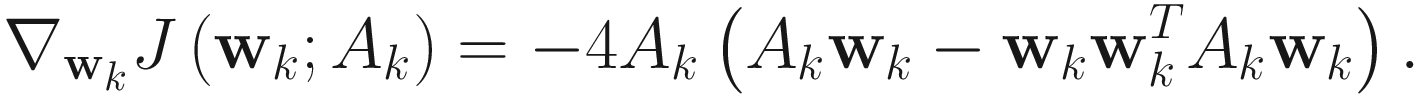
The adaptive gradient descent OJA algorithm for PCA is
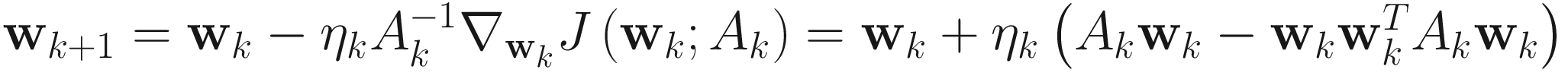 , (4.5)
, (4.5)
where ηk is a small decreasing constant.
Rate of Convergence
The convergence time constant for the principal eigenvector ϕ1 is 1/λ1 and for the minor eigenvectors ϕi is 1/(λ1–λi) for i=2,…,n. The time constants are dependent on the eigen-structure of the data correlation matrix A.
4.4 RQ, OJAN, and LUO Algorithms
Objective Function
These three algorithms are different derivations of the following Rayleigh quotient objective function:
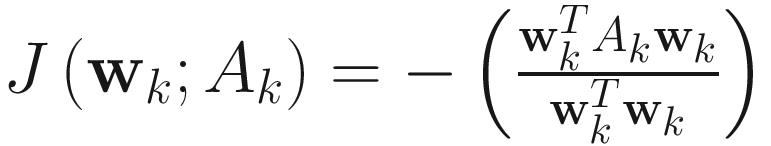 . (4.6)
. (4.6)
These algorithms were initially presented by Luo et al. [Luo et al. 97; Taleb et al. 99; Cirrincione et al. 00] and Oja et al. [Oja et al. 92]. Variations of the RQ algorithm have been presented by many practitioners [Chauvin 89; Sarkar et al. 89; Yang et al. 89; Fu and Dowling 95; Taleb et al. 99; Cirrincione et al. 00].
Adaptive Algorithms
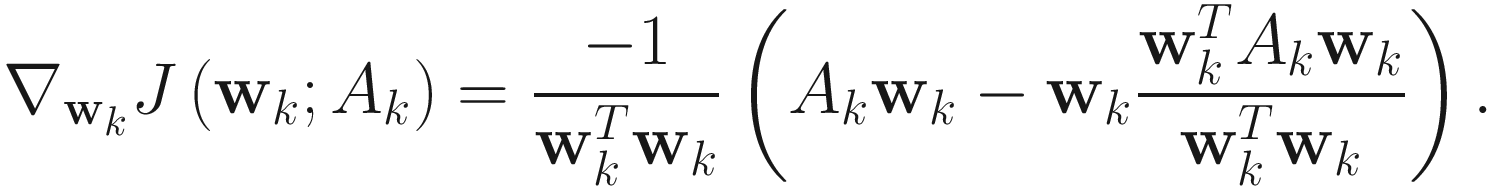
The adaptive gradient descent RQ algorithm for PCA is
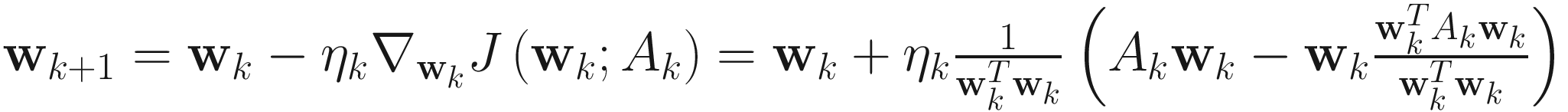 . (4.7)
. (4.7)
The adaptive gradient descent OJAN algorithm for PCA is
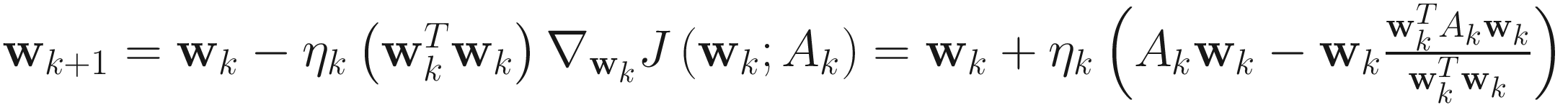 . (4.8)
. (4.8)
The adaptive gradient descent LUO algorithm for PCA is
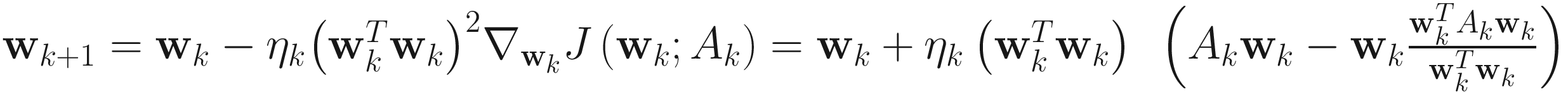 . (4.9)
. (4.9)
Rate of Convergence
The convergence time constants for principal eigenvector ϕ1 are
RQ: ‖w0‖2/λ1.
OJAN: 1/λ1.
LUO: ‖w0‖–2/λ1.
The convergence time constants for the minor eigenvectors ϕi (i=2,…,n) are
RQ: ‖w0‖2/(λ1–λi) for i=2,…,n.
OJAN: 1/(λ1–λi) for i=2,…,n.
LUO: ‖w0‖–2/(λ1–λi) for i=2,…,n.
The time constants are dependent on the eigen-structure of A.
4.5 IT Algorithm
Objective Function
The objective function for the information theory (IT) criterion is
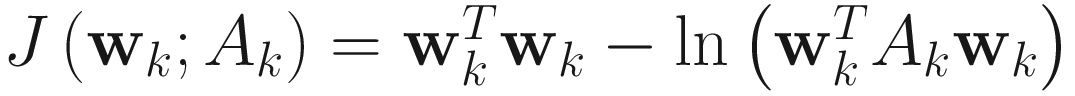 . (4.10)
. (4.10)
Plumbley [Pumbley 95] and Miao and Hua [Miao and Hua 98] have studied this objective function.
Adaptive Algorithm
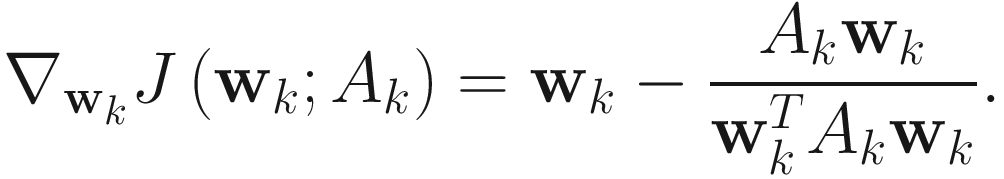
The adaptive gradient descent IT algorithm for PCA is
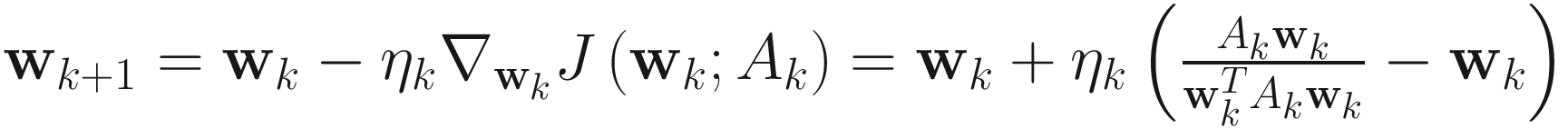 . (4.11)
. (4.11)
Rate of Convergence
A unique feature of this algorithm is that the time constant for ‖w(t)‖ is 1 and it is independent of the eigen-structure of A.
Upper Bound of ηk
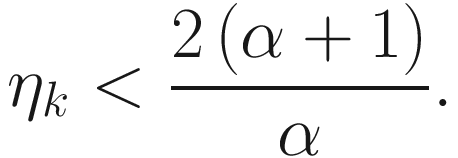
4.6 XU Algorithm
Objective Function
Originally presented by Xu [Xu 91, 93], the objective function for XU algorithm is
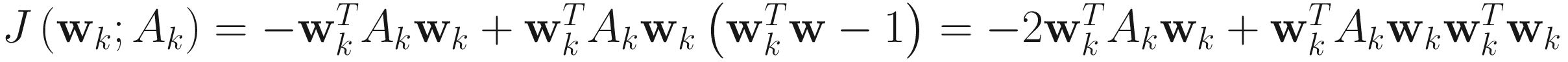 (4.12)
(4.12)
 . This transform, also known as auto-association, is shown in Figure 4-1. We define
. This transform, also known as auto-association, is shown in Figure 4-1. We define 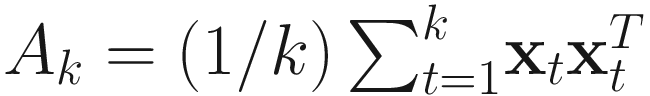 . Then, the mean squared error objective function is
. Then, the mean squared error objective function is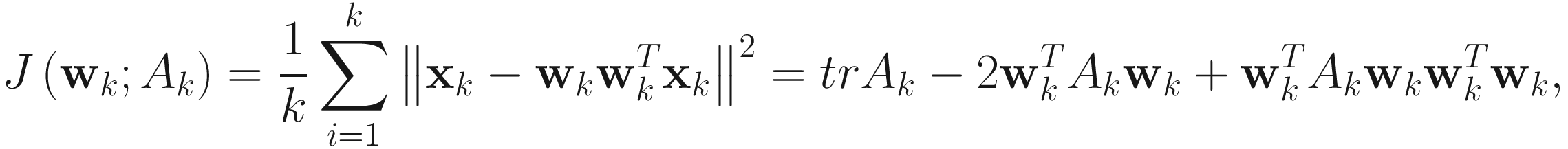
which is the same as (4.12).
Adaptive Algorithm
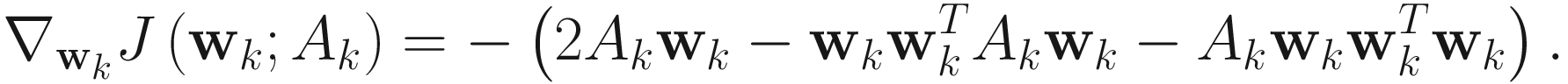
The adaptive gradient descent XU algorithm for PCA is
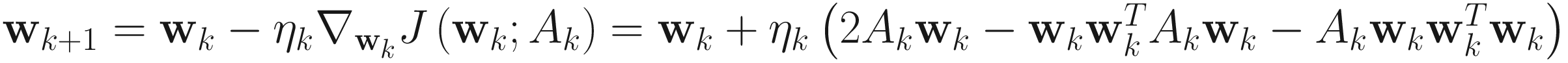 . (4.13)
. (4.13)
Rate of Convergence
The convergence time constant for the principal eigenvector ϕ1 is 1/λ1 and for the minor eigenvectors ϕi is 1/(λ1–λi) for i=2,…,n. The time constants are dependent on the eigen-structure of the data correlation matrix A.
Upper Bound of ηk
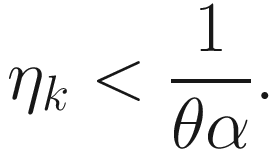
4.7 Penalty Function Algorithm
Objective Function
Originally given by Chauvin [Chauvin 89], the objective function for the penalty function (PF) algorithm is
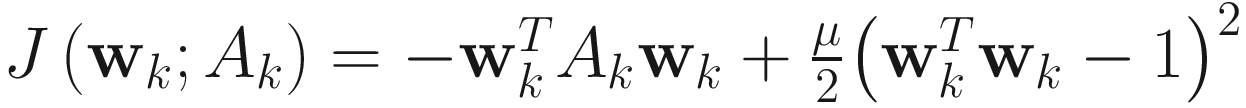 , μ > 0. (4.14)
, μ > 0. (4.14)
The objective function J(wk;Ak) is an implementation of the Rayleigh quotient criterion (4.1), where the constraint 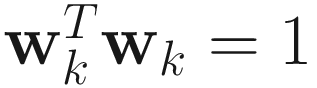 is enforced by the penalty function method of nonlinear optimization, and μ is a positive penalty constant.
is enforced by the penalty function method of nonlinear optimization, and μ is a positive penalty constant.
Adaptive Algorithm
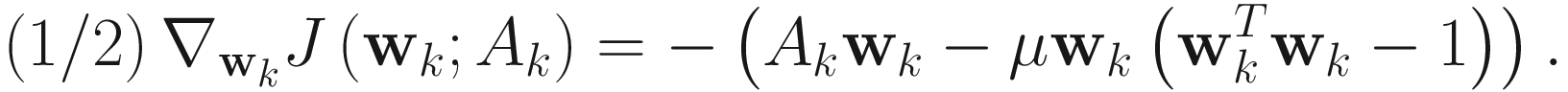
The adaptive gradient descent PF algorithm for PCA is
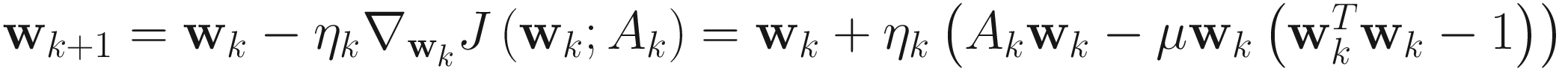 , (4.15)
, (4.15)
where μ > 0.
Rate of Convergence
The convergence time constant for the principal eigenvector ϕ1 is 1/(λ1 + μ) and for the minor eigenvectors ϕi is 1/(λ1–λi) for i=2,…,n. The time constants are dependent on the eigen-structure of the data correlation matrix A.
Upper Bound of ηk
Then there exists a uniform upper bound for ηk such that wk is uniformly bounded. If ‖wk‖2 ≤ α+1 and θ is the largest eigenvalue of Ak, then ‖wk+1‖2 ≤ ‖wk‖2 if
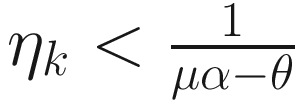 , assuming μα>θ.
, assuming μα>θ.
4.8 Augmented Lagrangian 1 Algorithm
Objective Function and Adaptive Algorithm
The objective function for the augmented Lagrangian 1 (AL1) algorithm
is obtained by applying the augmented Lagrangian method of nonlinear optimization to minimize 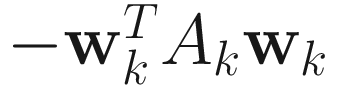 under the constraint
under the constraint 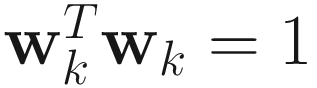 :
:
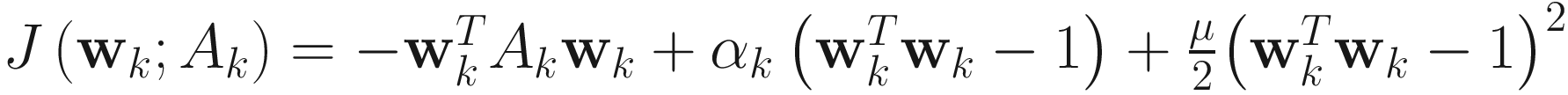 , (4.16)
, (4.16)
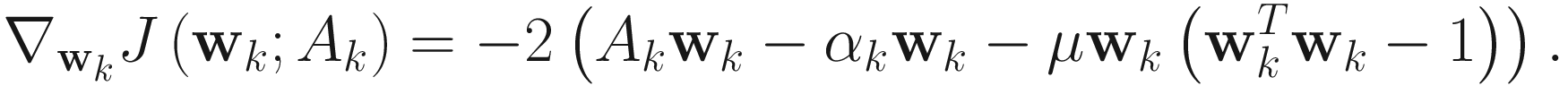
By equating the gradient to 0 and using the constraint 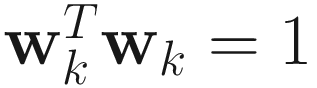 , we obtain αk=wkTAkwk. Replacing this αk in the gradient, we obtain the AL1 algorithm
, we obtain αk=wkTAkwk. Replacing this αk in the gradient, we obtain the AL1 algorithm
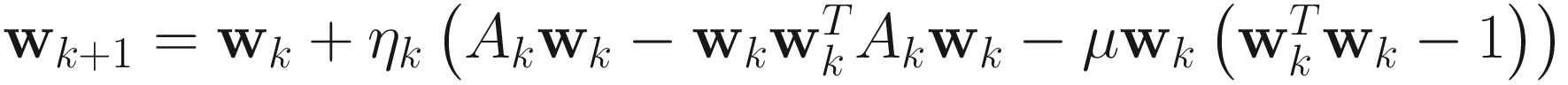 , (4.17)
, (4.17)
where μ > 0. Note that (4.17) is the same as OJA+ algorithm for μ =1.
Rate of Convergence
The convergence time constant for the principal eigenvector ϕ1 is 1/(λ1 + μ) and for the minor eigenvectors ϕi is 1/(λ1–λi) for i=2,…,n. The time constants are dependent on the eigen-structure of the data correlation matrix A.
Upper Bound of ηk
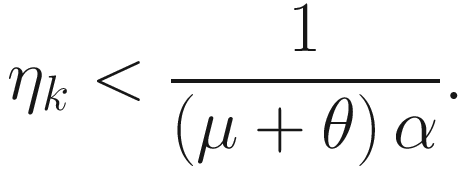
4.9 Augmented Lagrangian 2 Algorithm
Objective Function
The objective function for the augmented Lagrangian 2 (AL2) algorithm is
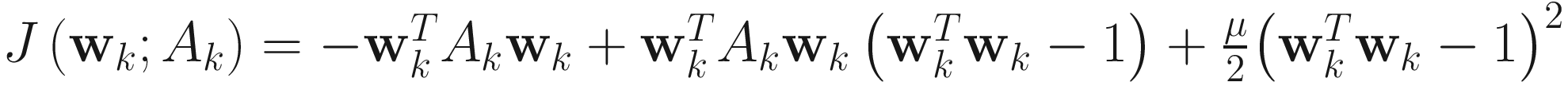 (4.18)
(4.18)
The objective function J(wk;Ak) is an application of the augmented Lagrangian method on the Rayleigh quotient criterion (4.1). It uses the XU objective function and also uses the penalty function method (4.14), where μ is a positive penalty constant.
Adaptive Algorithm
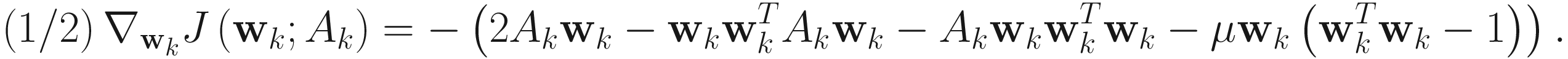
The adaptive gradient descent AL2 algorithm for PCA is
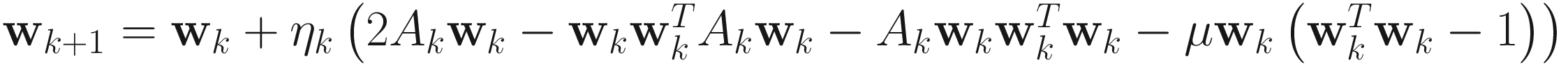 , (4.19)
, (4.19)
where μ > 0.
Rate of Convergence
The convergence time constant for the principal eigenvector ϕ1 is 1/(λ1 + (μ/2)) and for the minor eigenvectors ϕi is 1/(λ1–λi) for i=2,…,n. The time constants are dependent on the eigen-structure of the data correlation matrix A.
Upper Bound of ηk
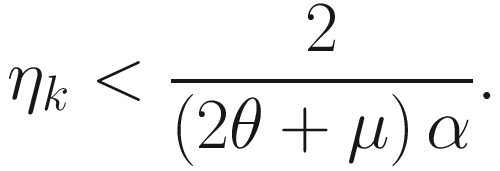
4.10 Summary of Algorithms
Summary of Convergence Results
Algorithm | Convergence Time Constants | Upper Bounds of ηk |
|---|---|---|
OJA | 1/λ1 | 2/αθ |
OJAN | 1/λ1 | Not Available |
LUO | ‖w0‖–2/λ1 | Not Available |
RQ | ‖w0‖2/λ1 | Not Available |
OJA+ | 1/(λ1+1) | 1/(α–θ) |
IT | 1 | 2(α+1)/α |
XU | 1/λ1 | 1/αθ |
PF | 1/(λ1+μ) | 1/(μα–θ) |
AL1 | 1/(λ1+μ) | 1/(μ+θ)α |
AL2 | 1/(λ1+(μ/2)) | 2/(μ+2θ)α |
- 1.
For all algorithms, except IT, convergence of ϕ1 improves for larger values of λ1.
- 2.
For LUO, the time constant decreases for larger ‖w0‖, which implies that convergence improves for larger initial weights.
- 3.
For RQ, convergence deteriorates for larger ‖w0‖.
- 4.
For the PF, AL1, and AL2 algorithms, the time constant decreases for larger μ, although very large values of μ will make the algorithm perform poorly due excessive emphasis on the constraints.
4.11 Experimental Results
- 1.
In the first experiment, I used the adaptive algorithms described before on a single data set with various starting vectors w0 [Chatterjee, Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
- 2.
In the second experiment, I generated several data samples and used the adaptive algorithms with the same starting vector w0 [Chatterjee, Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
- 3.
In the third experiment, I used a real-world non-stationary data set from a public dataset [V. Souza et al. 2020] to demonstrate the fast convergence of the adaptive algorithms to the first principal eigenvector of the ensemble correlation matrix.
Experiments with Various Starting Vectors w0
[Chatterjee, Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
I generated 1,000 samples of 10-dimensional Gaussian data (i.e., n=10) with the mean zero and covariance given below. The covariance matrix is obtained from the second covariance matrix in [Okada and Tomita 85] multiplied by 3, which is
 (4.20)
(4.20)
The eigenvalues of the covariance matrix are
17.9013, 10.2212, 8.6078, 6.5361, 2.2396, 1.8369, 1.1361, 0.7693, 0.2245, 0.1503.
I computed the principal eigenvector (i.e., the eigenvector corresponding to the largest eigenvalue = 17.9013) by the adaptive algorithms described before from different starting vectors w0. I obtained w0=c*r, where r∈ℜ10 is a N(0,1) random vector and c∈[0.05,2.0]. This causes a variation in ‖w0‖ from 0.1 to 5.0.
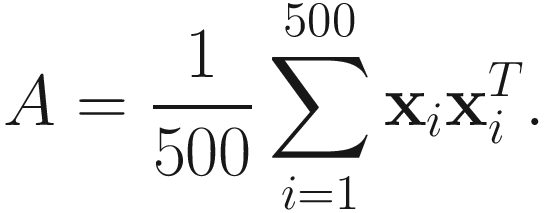
I refer to the eigenvectors and eigenvalues computed from this A by a standard numerical analysis method [Golub and VanLoan 83] as the actual values .
In order to measure the convergence and accuracy of the algorithms, I computed the percentage direction cosine at kth update of each adaptive algorithm as
Percentage Direction Cosine (k) = 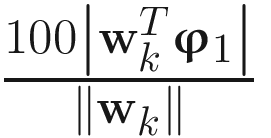 , (4.21)
, (4.21)
Convergence of the Principal Eigenvector of A by Adaptive Algorithms at Sample Values k={250,500} for Different Initial Values w0
‖w0‖ | k | OJA | OJAN | LUO | RQ | OJA+ | IT | XU | PF | AL1 | AL2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
0.1355 | 250 | 97.18 | 97.18 | 60.78 | 98.44 | 97.18 | 84.53 | 97.22 | 97.17 | 97.18 | 97.20 |
500 | 99.58 | 99.58 | 63.15 | 99.96 | 99.58 | 89.67 | 99.58 | 99.58 | 99.58 | 99.58 | |
0.4065 | 250 | 97.18 | 97.18 | 82.44 | 98.54 | 97.18 | 84.96 | 97.18 | 97.18 | 97.18 | 97.16 |
500 | 99.58 | 99.58 | 90.88 | 99.96 | 99.58 | 90.35 | 99.58 | 99.58 | 99.58 | 99.58 | |
0.6776 | 250 | 97.18 | 97.18 | 94.63 | 97.85 | 97.18 | 82.55 | 97.17 | 97.18 | 97.18 | 97.15 |
500 | 99.58 | 99.58 | 98.50 | 99.88 | 99.58 | 88.85 | 99.58 | 99.58 | 99.58 | 99.58 | |
0.9486 | 250 | 97.18 | 97.18 | 97.05 | 97.28 | 97.18 | 79.60 | 97.18 | 97.18 | 97.18 | 97.17 |
500 | 99.58 | 99.58 | 99.52 | 99.63 | 99.58 | 86.90 | 99.58 | 99.58 | 99.58 | 99.58 | |
1.2196 | 250 | 97.18 | 97.18 | 97.60 | 96.35 | 97.18 | 76.67 | 97.21 | 97.18 | 97.18 | 97.21 |
500 | 99.58 | 99.58 | 99.80 | 99.19 | 99.58 | 84.80 | 99.58 | 99.58 | 99.58 | 99.58 | |
1.4906 | 250 | 97.18 | 97.18 | 97.97 | 94.43 | 97.18 | 73.99 | 97.26 | 97.18 | 97.17 | 97.27 |
500 | 99.58 | 99.58 | 99.90 | 98.41 | 99.58 | 82.68 | 99.59 | 99.58 | 99.58 | 99.59 | |
1.7617 | 250 | 97.17 | 97.18 | 98.31 | 91.53 | 97.18 | 71.63 | 97.33 | 97.18 | 97.16 | 97.35 |
500 | 99.58 | 99.58 | 99.95 | 97.08 | 99.58 | 80.61 | 99.59 | 99.58 | 99.58 | 99.59 | |
2.0327 | 250 | 97.17 | 97.18 | 98.57 | 88.04 | 97.17 | 69.61 | 97.44 | 97.17 | 97.15 | 97.51 |
500 | 99.58 | 99.58 | 99.96 | 95.08 | 99.58 | 78.63 | 99.60 | 99.58 | 99.58 | 99.60 | |
2.3037 | 250 | 97.17 | 97.18 | 98.75 | 84.43 | 97.17 | 67.90 | 97.62 | 97.17 | 97.14 | 97.89 |
500 | 99.58 | 99.58 | 99.97 | 92.51 | 99.58 | 76.78 | 99.61 | 99.58 | 99.58 | 99.63 | |
2.5748 | 250 | 97.16 | 97.18 | 98.89 | 81.00 | 97.16 | 66.46 | 97.96 | 97.16 | 97.11 | 98.55 |
500 | 99.58 | 99.58 | 99.98 | 89.59 | 99.58 | 75.07 | 99.63 | 99.58 | 99.58 | 99.77 | |
2.8458 | 250 | 97.15 | 97.18 | 99.00 | 77.92 | 97.16 | 65.26 | 98.64 | 97.15 | 97.06 | 94.08 |
500 | 99.58 | 99.58 | 99.99 | 86.56 | 99.58 | 73.50 | 99.70 | 99.58 | 99.57 | 99.42 | |
3.1168 | 250 | 97.14 | 97.18 | 99.06 | 75.25 | 97.15 | 64.24 | 16.90 | 97.14 | 96.91 | 95.92 |
500 | 99.58 | 99.58 | 99.99 | 83.61 | 99.58 | 72.08 | 60.47 | 99.58 | 99.57 | 99.51 |
Convergence of all adaptive algorithms is similar except for the RQ and IT algorithms.
Other than IT, all algorithms converge with a time constant ∝ 1/λ1.
For the IT algorithm, the time constant of the principal eigenvector is 1. Since λ1=17.9, the convergence of all algorithms is faster than IT.
For the RQ and LUO algorithms, the time constants are ‖w0‖2/λ1 and ‖w0‖–2/λ1, respectively.
Clearly, for larger ‖w0‖, RQ converges at a slower rate than other algorithms and LUO converges faster than other algorithms whose time constants are 1/λ1.
For very large ‖w0‖ such as ‖w0‖=10.0, the LUO algorithm fails to converge for ηk=1/(200+k) because the convergence becomes unstable.
For smaller ‖w0‖, the convergence of RQ is better than other algorithms since its time constant ‖w0‖2/λ1 is smaller than other algorithms whose time constants are 1/λ1.
Experiments with Various Data Sets: Set 1
[Chatterjee, Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
Convergence of the Principal Eigenvector of A by Adaptive Algorithms at Sample Values k={250,500} for Different Data Sets
λ1, λ2 | k | OJA | OJAN | LUO | RQ | OJA+ | IT | XU | PF | AL1 | AL2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
11.58, 6.32 | 250 | 95.66 | 95.67 | 97.61 | 91.70 | 95.66 | 72.19 | 95.97 | 95.66 | 95.65 | 95.82 |
500 | 99.50 | 99.50 | 99.86 | 98.14 | 99.50 | 80.97 | 99.51 | 99.50 | 99.50 | 99.51 | |
11.63, 6.49 | 250 | 95.50 | 95.54 | 96.93 | 91.65 | 95.51 | 70.57 | 96.34 | 95.51 | 95.46 | 96.18 |
500 | 99.51 | 99.51 | 99.87 | 98.28 | 99.51 | 80.39 | 99.54 | 99.51 | 99.51 | 99.54 | |
11.73, 6.92 | 250 | 87.62 | 86.61 | 97.10 | 56.91 | 87.54 | 47.80 | 46.00 | 86.78 | 88.08 | 36.39 |
500 | 98.94 | 98.89 | 99.80 | 91.38 | 98.93 | 60.20 | 96.82 | 98.90 | 98.96 | 98.06 | |
11.84, 7.18 | 250 | 96.72 | 96.71 | 96.53 | 95.83 | 96.72 | 73.84 | 96.54 | 96.72 | 96.73 | 96.60 |
500 | 99.30 | 99.30 | 99.75 | 98.69 | 99.30 | 82.76 | 99.28 | 99.30 | 99.30 | 99.29 | |
12.14, 7.64 | 250 | 96.23 | 96.22 | 95.66 | 95.62 | 96.23 | 71.62 | 96.01 | 96.22 | 96.24 | 96.06 |
500 | 99.10 | 99.10 | 99.67 | 98.54 | 99.10 | 81.39 | 99.08 | 99.10 | 99.10 | 99.08 | |
12.52, 8.08 | 250 | 95.10 | 95.13 | 95.63 | 94.45 | 95.10 | 60.71 | 95.78 | 95.10 | 95.06 | 95.67 |
500 | 98.91 | 98.91 | 99.62 | 99.23 | 98.91 | 73.59 | 98.96 | 98.91 | 98.91 | 98.95 | |
12.87, 8.67 | 250 | 95.38 | 95.37 | 93.65 | 96.51 | 95.38 | 68.84 | 95.08 | 95.37 | 95.39 | 95.14 |
500 | 98.57 | 98.57 | 99.39 | 98.60 | 98.57 | 79.91 | 98.53 | 98.57 | 98.57 | 98.54 | |
13.57, 9.33 | 250 | 94.83 | 94.82 | 92.88 | 97.00 | 94.82 | 64.05 | 94.56 | 94.82 | 94.84 | 94.60 |
500 | 98.35 | 98.35 | 99.30 | 98.66 | 98.35 | 76.67 | 98.32 | 98.35 | 98.35 | 98.32 | |
14.09, 9.88 | 250 | 95.95 | 95.97 | 92.21 | 94.23 | 95.94 | 40.40 | 96.05 | 95.99 | 95.97 | 95.86 |
500 | 98.33 | 98.33 | 99.17 | 99.82 | 98.33 | 50.26 | 98.34 | 98.33 | 98.33 | 98.31 | |
17.97, 11.66 | 250 | 67.18 | 72.82 | 94.87 | 58.69 | 67.39 | 2.78 | 88.60 | 74.24 | 66.40 | 86.49 |
500 | 98.20 | 98.45 | 99.83 | 90.90 | 98.21 | 1.22 | 99.05 | 98.50 | 98.16 | 98.97 | |
21.54, 12.72 | 250 | 95.14 | 95.19 | 97.25 | 84.30 | 95.14 | 0.35 | 95.66 | 95.19 | 95.12 | 95.57 |
500 | 99.79 | 99.79 | 99.96 | 98.49 | 99.79 | 3.94 | 99.80 | 99.79 | 99.79 | 99.79 | |
25.66, 12.92 | 250 | 98.23 | 98.26 | 99.04 | 93.90 | 98.23 | 2.53 | 98.42 | 98.26 | 98.23 | 98.37 |
500 | 99.96 | 99.96 | 99.99 | 99.79 | 99.96 | 7.62 | 99.96 | 99.96 | 99.96 | 99.96 |
Once again, we observe that all algorithms converge in a similar manner except for the RQ and IT algorithms. Out of these two, RQ converges much better than IT, where IT fails to converge for some data sets. Of the remaining algorithms, LUO converges better than the rest for all data sets.
Experiments with Various Data Sets: Set 2
[Chatterjee, Neural Networks, Vol. 18, No. 2, pp. 145-149, March 2005].
I further generated 12 sets of 500 samples of 10-dimensional Gaussian data with a mean zero and random covariance matrix (4.20). Here I computed the eigenvectors and eigenvalues of the covariance matrix (4.20). Next, I changed the first two principal eigenvalues of (4.20) to λ1=25 and λ2=λ1/c, where c∈[1.1,10.0], and generated the data sets with the new eigenvalues and eigenvectors computed before. For all adaptive algorithms I used w0, ηk, and μ as described in Section 4.11.2. See Table 4-4.
Convergence of the Principal Eigenvector of A by Adaptive Algorithms at Sample Values k={50,100} for Different Data Sets with Varying λ1/λ2
λ1/λ2 | k | OJA | OJAN | LUO | RQ | OJA+ | IT | XU | PF | AL1 | AL2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
1.1 | 50 | 87.75 | 87.64 | 94.14 | 67.29 | 87.75 | 7.60 | 85.95 | 87.52 | 87.78 | 86.37 |
100 | 96.65 | 96.64 | 97.40 | 90.38 | 96.65 | 5.57 | 96.53 | 96.64 | 96.65 | 96.55 | |
1.5 | 50 | 86.07 | 86.06 | 91.10 | 75.70 | 86.08 | 39.67 | 86.29 | 85.99 | 86.03 | 86.37 |
100 | 96.29 | 96.29 | 97.53 | 92.37 | 96.29 | 47.73 | 96.30 | 96.28 | 96.28 | 96.31 | |
2.0 | 50 | 92.43 | 92.39 | 94.56 | 83.52 | 92.43 | 48.30 | 91.99 | 92.34 | 92.42 | 92.19 |
100 | 98.04 | 98.04 | 98.60 | 96.00 | 98.04 | 55.39 | 98.00 | 98.04 | 98.04 | 98.01 | |
2.5 | 50 | 93.28 | 93.24 | 95.03 | 86.76 | 93.29 | 55.77 | 93.02 | 93.16 | 93.23 | 93.53 |
100 | 98.49 | 98.49 | 98.95 | 96.85 | 98.49 | 62.59 | 98.49 | 98.49 | 98.49 | 98.50 | |
3.0 | 50 | 94.39 | 94.37 | 96.02 | 89.18 | 94.39 | 60.94 | 94.50 | 94.34 | 94.36 | 94.53 |
100 | 98.78 | 98.78 | 99.08 | 97.69 | 98.78 | 67.92 | 98.77 | 98.78 | 98.78 | 98.78 | |
4.0 | 50 | 96.00 | 95.99 | 96.66 | 90.91 | 96.01 | 62.67 | 95.87 | 95.96 | 95.99 | 96.03 |
100 | 98.96 | 98.96 | 99.15 | 98.40 | 98.96 | 69.62 | 98.97 | 98.96 | 98.96 | 98.96 | |
5.0 | 50 | 94.55 | 94.55 | 96.64 | 89.99 | 94.55 | 65.33 | 94.89 | 94.52 | 94.52 | 94.84 |
100 | 98.93 | 98.93 | 99.16 | 97.85 | 98.93 | 71.30 | 98.94 | 98.93 | 98.93 | 98.93 | |
6.0 | 50 | 98.73 | 98.74 | 97.62 | 96.32 | 98.73 | 65.37 | 98.75 | 98.76 | 98.74 | 98.69 |
100 | 99.19 | 99.19 | 99.26 | 99.38 | 99.19 | 72.96 | 99.19 | 99.19 | 99.19 | 99.19 | |
7.0 | 50 | 99.36 | 99.37 | 98.00 | 96.29 | 99.36 | 64.25 | 99.41 | 99.39 | 99.37 | 99.33 |
100 | 99.26 | 99.26 | 99.29 | 99.71 | 99.26 | 73.32 | 99.27 | 99.26 | 99.26 | 99.26 | |
8.0 | 50 | 97.12 | 97.11 | 97.97 | 92.96 | 97.12 | 62.88 | 97.12 | 97.09 | 97.11 | 97.17 |
100 | 99.25 | 99.25 | 99.34 | 98.71 | 99.25 | 70.05 | 99.25 | 99.25 | 99.25 | 99.25 | |
9.0 | 50 | 97.32 | 97.31 | 98.18 | 92.85 | 97.32 | 63.17 | 97.27 | 97.28 | 97.31 | 97.34 |
100 | 99.33 | 99.33 | 99.41 | 98.87 | 99.33 | 70.33 | 99.33 | 99.33 | 99.33 | 99.33 | |
10.0 | 50 | 97.82 | 97.81 | 98.43 | 94.38 | 97.82 | 66.24 | 97.70 | 97.79 | 97.81 | 97.79 |
100 | 99.43 | 99.43 | 99.49 | 99.04 | 99.43 | 73.12 | 99.43 | 99.43 | 99.43 | 99.43 |
Experiments with Real-World Non-Stationary Data
In these experiments I use real-world non-stationary data from Publicly Real-World Datasets to Evaluate Stream Learning Algorithms [Vinicius Souza et al. 2020], INSECTS-incremental-abrupt_balanced_norm.arff. It is important to demonstrate the performance of these algorithms on real non-stationary data since in practical edge applications the data is usually time varying and changes over time.

Non-stationary real-world data with abrupt periodic changes
The first eight eigenvalues of the correlation matrix of all samples are
[18.704, 10.473, 8.994, 7.862, 7.276 6.636 5.565 4.894, …].

Convergence of the adaptive algorithms for first principal eigenvector on real-world non-stationary data (ideal value=100)
4.12 Concluding Remarks
The RQ, OJAN, and LUO algorithms require ‖w0‖=1 for the principal eigenvector wk to converge to unit norm (i.e., ‖wk‖→1). All other algorithms (except PF) converged to the unit norm for various non-zero values for w0. As per Theorem 4.8, the PF algorithm successfully converged to 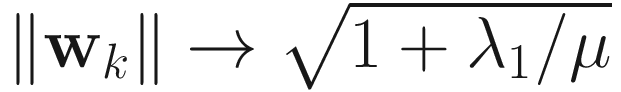 .
.
Comparison of Different Adaptive Algorithms [Chatterjee, Neural Networks 2005]
Alg. | Pros | Cons |
|---|---|---|
OJA | Convergence increases with larger λ1 and λ1/λ2. Upper bound of ηk can be determined. Fewer computations per iteration (Flops=460). | Convergence cannot be improved by larger ‖w0‖. |
OJAN | Convergence increases with larger λ1 and λ1/λ2. Fewer computations per iteration (Flops=481). | Upper bound of ηk not available. Convergence cannot be improved by larger ‖w0‖. Require ‖w0‖=1 for wk to converge to unit norm. |
LUO | Convergence increases with larger λ1 and λ1/λ2. Convergence increases for larger ‖w0‖. Fewer computations per iteration (Flops=502). | Upper bound of ηk not available. Convergence decreases for smaller ‖w0‖. Requires ‖w0‖=1 for wk to converge to unit norm. |
RQ | Convergence increases with larger λ1 and λ1/λ2. Convergence increases for smaller ‖w0‖. Fewer computations per iteration (Flops=503). | Upper bound of ηk not available. Convergence decreases for larger v. Requires ‖w0‖=1 for wk to converge to unit norm. |
OJA+ | Convergence increases with larger λ1 and λ1/λ2. Upper bound of ηk can be determined. Fewer computations per iteration (Flops=501). | Convergence cannot be improved by larger ‖w0‖. |
IT | Upper bound of ηk can be determined. Fewer computations per iteration (Flops=460). | Convergence independent of λ1. Experimental results show poor convergence. |
XU | Convergence increases with larger λ1 and λ1/λ2. Upper bound of ηk can be determined. | Convergence cannot be improved by larger ‖w0‖. More computations per iteration (Flops=800). |
PF | Convergence increases with larger λ1 and λ1/λ2. Convergence increases with μ. Upper bound of ηk can be determined. Smallest computations per iteration (Flops=271). | Convergence cannot be improved by larger ‖w0‖. wk does not converge to unit norm. |
AL1 | Convergence increases with larger λ1 and λ1/λ2. Convergence increases with μ. Upper bound of ηk can be determined. Fewer computations per iteration (Flops=511). | Convergence cannot be improved by larger ‖w0‖. |
AL2 | Convergence increases with larger λ1 and λ1/λ2. Convergence increases with μ. Upper bound of ηk can be determined. | Convergence cannot be improved by larger ‖w0‖. Largest computations per iteration (Flops=851). |
In summary, I discussed ten adaptive algorithms for PCA, some of them new, from a common framework with an objective function for each. Note that although I applied the gradient descent technique on these objective functions, I could have applied any other technique of nonlinear optimization such as steepest descent, conjugate direction, Newton-Raphson, or recursive least squares.