
7.1 Introduction and Use Cases
This chapter is concerned with the adaptive solution of the generalized eigenvalue problems AΦ=BΦΛ, ABΦ=ΦΛ, and BAΦ=ΦΛ, where A and B are real, symmetric, nXn matrices and B is positive definite. In particular, we shall consider the problem AΦ=BΦΛ, although the remaining two problems are similar. The matrix pair (pencil) (A,B) is commonly referred to as a symmetric-definite pencil [Golub and VanLoan 83].
As seen before, the conventional (numerical analysis) method for evaluating Φ and Λ requires the computation of (A,B) after collecting all of the samples, and then the application of a numerical procedure [Golub and VanLoan 83]; in other words, the approach works in a batch fashion. In contrast, for the online case, matrices (A,B) are unknown. Instead, there are available two sequences of random matrices {Ak,Bk} with limk→∞E[Ak]=A and limk→∞E[Bk]=B. For every sample (Ak,Bk), we need to obtain the current estimates (Φk,Λk) of (Φ,Λ) respectively, such that (Φk,Λk) converge strongly to (Φ,Λ).
Application of GEVD in Pattern Recognition
In pattern recognition, there are problems where we are given samples (x∈ℜn) from different populations or pattern classes. The well-known problem of linear discriminant analysis (LDA) [Chatterjee et al. Nov 97, May 97, Mar 97] seeks a transform W∈ℜnXp (p≤n), such that the interclass distance (measured by the scatter of the patterns around their mixture mean) is maximized, while at the same time the intra-class distance (measured by the scatter of the patterns around their respective class means) is as small as possible. The objective of this transform is to group the classes into well-separated clusters. The former scatter matrix, known as the mixture scatter matrix, is denoted by A, and the latter matrix, known as the within-class scatter matrix, is denoted by B [Fukunaga 90]. When the first column w of W is needed (i.e., p=1), the problem can be formulated in the constrained optimization framework as
Maximize wTAw subject to wTBw = 1. (7.1)
A twin problem to (7.1) is to maximize the Rayleigh quotient criterion [Golub and VanLoan 83] with respect to w:
 . (7.2)
. (7.2)
A solution to (7.1) or (7.2) leads to the generalized eigen-decomposition problem Aw=λBw, where λ is the largest generalized eigenvalue of A with respect to B. In general, the p columns of W are the p≤n orthogonal unit generalized eigenvectors ϕ1,...,ϕp of A with respect to B where
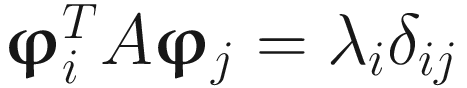 , and
, and  for i=1,…,p, (7.3)
for i=1,…,p, (7.3)
where λ1> ... >λp>λp+1≥ ... ≥λn>0 are the p largest generalized eigenvalues of A with respect to B in descending order of magnitude. In summary, LDA is a powerful feature extraction tool for the class separability feature [Chatterjee May 97], and our adaptive algorithms are suited to this.
Application of GEVD in Signal Processing
Next, let’s discuss an analogous problem of detecting a desired signal in the presence of interference. Here, we seek the optimum linear transform W for weighting the signal plus interference such that the desired signal is detected with maximum power and minimum interference. Given the matrix pair (A,B), where A is the correlation matrix of the signal plus interference plus noise and B is the correlation matrix of interference plus noise, we can formulate the signal detection problem as the constrained maximization problem in (7.1). Here, we maximize the signal power and minimize the power of the interference. The solution for W consists of the p≤n largest generalized eigenvectors of the matrix pencil (A,B). Adaptive generalized eigen-decomposition algorithms also allow the tracking of slow changes in the incoming data [Chatterjee et al. Nov 97, Mar 97; Chen et al. 2000].
Methods for Generalized Eigen-Decomposition
We first define the problem for the non-adaptive case. Each of the three generalized eigenvalue problems (AΦ=BΦΛ, ABΦ=ΦΛ, and BAΦ=ΦΛ, where A and B are real, symmetric, nXn matrices and B is positive definite) can be reduced to a standard symmetric eigenvalue problem using a Cholesky factorization of B as either B=LLT or B=UTU. With B = LLT, we can write AΦ=BΦΛ as
(L−1AL−T)(LTΦ) = (LTΦ)Λ or CΨ = ΨΛ. (7.4)
Types of Generalized Eigen-Decomposition problems and their solutions
Type of Problem | Factorization of B | Reduction | Generalized Eigenvectors |
|---|---|---|---|
AΦ=BΦΛ | B = LLT | C = L–1 A L–T | Φ = L–T Ψ |
B = UTU | C = U–T A U–1 | Φ = U–1 Ψ | |
ABΦ=ΦΛ | B = LLT | C = LT A L | Φ= L–T Ψ |
B = UTU | C = U A UT | Φ = U–1 Ψ | |
BAΦ=ΦΛ | B = LLT | C = LT A L | Φ = L Ψ |
B = UTU | C = U A UT | Φ = UT Ψ |
In the adaptive case, we can extend these techniques by first (adaptively) computing a matrix Wk for each sample Bk, where Wk tends to the inverse Cholesky factorization L–1 of B with probability one (w.p.1) as k→∞. Any of the algorithms in Chapter 3 can be considered here. Next, we consider a sequence {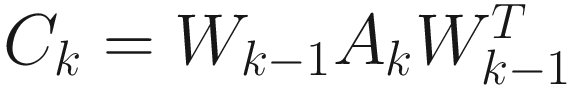 }, which is used to adaptively compute a matrix Vk, where Vk tends to the eigenvector matrix of limk→∞E[Ck] w.p.1 as k→∞. Any of the algorithms in Chapters 5 and 6 can be considered for this purpose. In conjunction, the two steps yield WkVk, which is proven to converge w.p.1 to Φ as k→∞. Thus, the two steps can proceed simultaneously and converge strongly to the eigenvector matrix Φ. A full description of this method is given in [Chatterjee et al. May 97, Mar 97]. In this chapter, I offer a variety of new techniques to solve the generalized eigen-decomposition problem for the adaptive case.
}, which is used to adaptively compute a matrix Vk, where Vk tends to the eigenvector matrix of limk→∞E[Ck] w.p.1 as k→∞. Any of the algorithms in Chapters 5 and 6 can be considered for this purpose. In conjunction, the two steps yield WkVk, which is proven to converge w.p.1 to Φ as k→∞. Thus, the two steps can proceed simultaneously and converge strongly to the eigenvector matrix Φ. A full description of this method is given in [Chatterjee et al. May 97, Mar 97]. In this chapter, I offer a variety of new techniques to solve the generalized eigen-decomposition problem for the adaptive case.
Outline of This Chapter
In Section 7.2, I list the objective functions from which I derive the adaptive generalized eigen-decomposition algorithms. In Sections 7.3, 7.4, and 7.5, I present adaptive algorithms for the homogeneous, deflation, and weighted variations, respectively, from the OJA objective function. In Sections 7.6, 7.7, and 7.8, I analyze the same three variations for the mean squared error (XU) objective function and convergence proofs for the deflation case. In Sections 7.9, 7.10, and 7.11, I discuss algorithms derived from the penalty function (PF) objective function. In Sections 7.12, 7.13, and 7.14, I consider the augmented Lagrangian 1 (AL1) objective function, and in Sections 7.15, 7.16, and 7.17, I present the augmented Lagrangian 2 (AL2) objective function. In Sections 7.18, 7.19, and 7.20, I present the information theory (IT) criterion, and in Sections 7.21, 7.22, and 7.23, I describe the Rayleigh quotient (RQ) criterion. In Section 7.24, I discusses the experimental results, and in Section 7.25, I present conclusions.
7.2 Algorithms and Objective Functions
Similar to the PCA algorithms (Chapter 5), in this chapter, I present several adaptive algorithms for generalized eigenvector computation. I consider two asymptotically stationary sequences {xk∈ℜn} and {yk∈ℜn} that have been centered to zero mean. We can represent the corresponding online correlation matrices {Ak,Bk} of {xk,yk} either by their instantaneous values { ,
, } or by their running averages by (2.3). If, however, {xk,yk} are non-stationary, we can construct correlation matrices {Ak,Bk} out of data samples {xk,yk} by (2.5).
} or by their running averages by (2.3). If, however, {xk,yk} are non-stationary, we can construct correlation matrices {Ak,Bk} out of data samples {xk,yk} by (2.5).
Summary of Objective Functions for Adaptive GEVD Algorithms
Oja’s objective function (OJA),
Xu’s mean squared error objective function (XU),
Penalty function method (PF),
Augmented Lagrangian Method 1 (AL1),
Augmented Lagrangian Method 2 (AL2),
Information theory criterion (IT), and
Rayleigh quotient criterion (RQ).
- 1.
Homogeneous Adaptive Rule: These algorithms do not compute the true normalized generalized eigenvectors with decreasing eigenvalues.
- 2.
Deflation Adaptive Rule: Here, we produce unit generalized eigenvectors with decreasing eigenvalues. However, the training is sequential, thereby making the training process harder for parallel implementations.
- 3.
Weighted Adaptive Rule: These algorithms are obtained by using a different scalar weight for each generalized eigenvector, making them normalized and in the order of decreasing eigenvalues.
Summary of Generalized Eigenvector Algorithms

List of Adaptive Generalized Eigen-Decomposition Algorithms
Alg. | Type | Adaptive Algorithm h(Wk,Ak) |
|---|---|---|
OJA | Homogeneous |
|
Deflation |
| |
Weighted |
| |
XU | Homogeneous |
|
Deflation |
| |
Weighted |
| |
PF | Homogeneous |
|
Deflation |
| |
Weighted |
| |
AL1 | Homogeneous |
|
Deflation |
| |
Weighted |
| |
AL2 | Homogeneous |
|
Deflation |
| |
Weighted |
| |
IT | Homogeneous |
|
Deflation |
| |
Weighted |
| |
RQ | Homogeneous |
|
Deflation |
| |
Weighted |
|

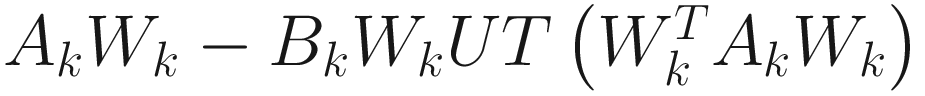
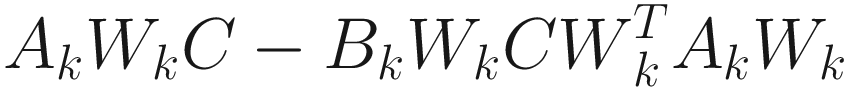




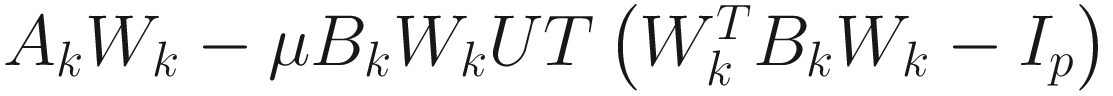
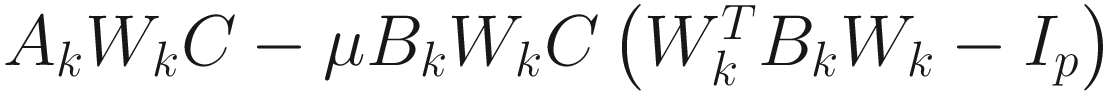




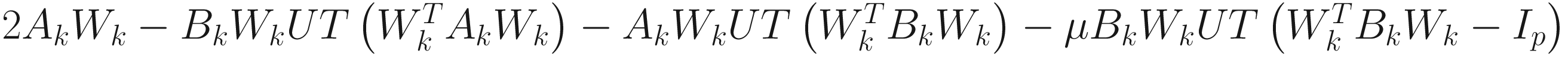
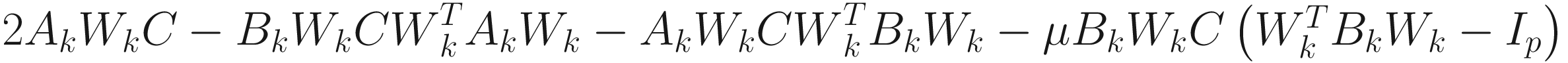






In the following discussions, I denote Φ=[ϕ1 ... ϕn]∈ℜnXn as the orthonormal generalized eigenvector matrix of A with respect to B, and Λ= diag(λ1,...,λn) as the generalized eigenvalue matrix, such that λ1>λ2>...>λp>λp+1≥...≥λn>0. I use the subscript (i) to denote the ith permutation of the indices {1,2,…,n}.
7.3 OJA GEVD Algorithms
OJA Homogeneous Algorithm
The objective function for the OJA homogeneous algorithm can be written as
 , (7.5)
, (7.5)
for i=1,…,p (p≤n). From the gradient of (7.5) with respect to 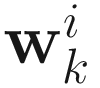 we obtain the following adaptive algorithm:
we obtain the following adaptive algorithm:
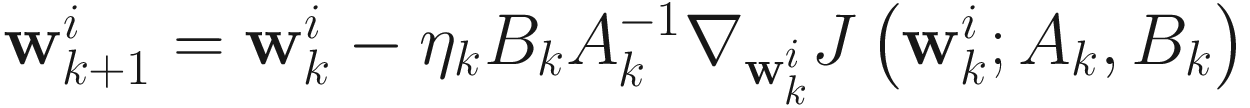 for i=1,…,p, (7.6)
for i=1,…,p, (7.6)
where ηk is a decreasing gain constant. Defining ![$$ {W}_k=left[{mathbf{w}}_k^1dots {mathbf{w}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_7_Chapter__522202_1_En_7_Chapter_TeX_IEq31.png) , from (7.6) we get
, from (7.6) we get
 . (7.7)
. (7.7)
OJA Deflation Algorithm
The objective function for the OJA deflation adaptive GEVD algorithm is
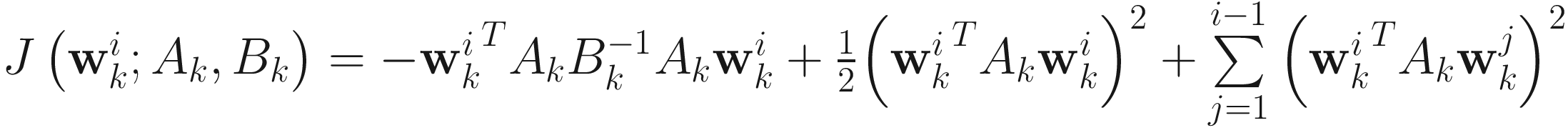 , (7.8)
, (7.8)
for i=1,…,p. From the gradient of (7.8) with respect to 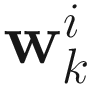 , we obtain the OJA deflation adaptive gradient descent algorithm as
, we obtain the OJA deflation adaptive gradient descent algorithm as
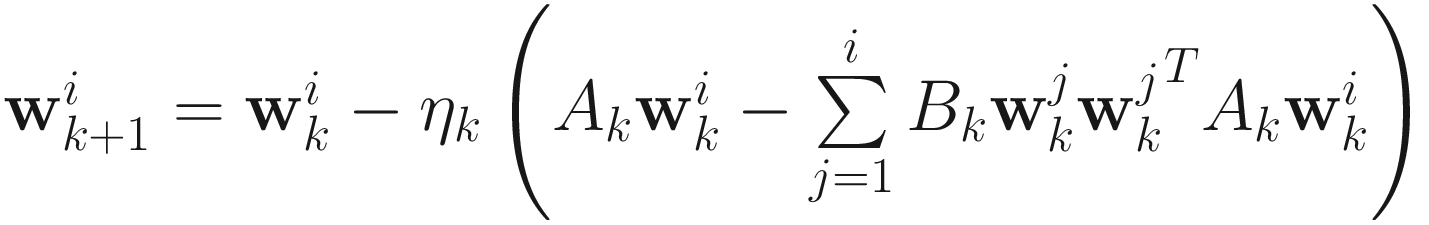 , (7.9)
, (7.9)
for i=1,…,p (p≤n). The matrix form of the algorithm is
 , (7.10)
, (7.10)
where UT[⋅] sets all elements below the diagonal of its matrix argument to zero.
OJA Weighted Algorithm
The objective function for the OJA weighted adaptive GEVD algorithm is
 (7.11)
(7.11)
for i=1,…,p, where c1,…,cp (p≤n) are small positive numbers satisfying
c1 > c2 > … > cp > 0, p ≤ n. (7.12)
Given a diagonal matrix C = diag (c1, …, cp), p ≤ n, the OJA weighted adaptive algorithm is
 . (7.13)
. (7.13)
OJA Algorithm Python Code
7.4 XU GEVD Algorithms
XU Homogeneous Algorithm
The objective function for the XU homogeneous adaptive GEVD algorithm is
 (7.14)
(7.14)
for i=1,…,p (p≤n). From the gradient of (7.14) with respect to  , we obtain the XU homogeneous adaptive gradient descent algorithm as
, we obtain the XU homogeneous adaptive gradient descent algorithm as
 (7.15)
(7.15)
for i=1,…,p, whose matrix form is
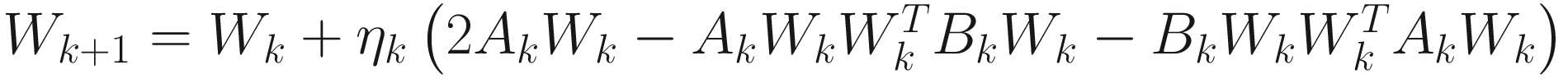 . (7.16)
. (7.16)
XU Deflation Algorithm
The objective function for the XU deflation adaptive GEVD algorithm is
 (7.17)
(7.17)
for i=1,…,p (p≤n). From the gradient of (7.17) with respect to  , we obtain
, we obtain
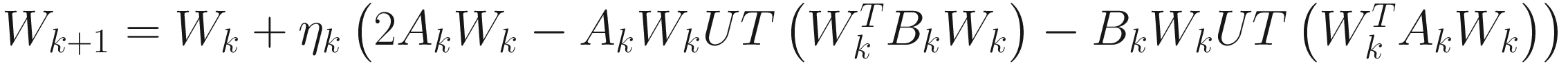 , (7.18)
, (7.18)
where UT[⋅] sets all elements below the diagonal of its matrix argument to zero. Chatterjee et al. [Mar 00, Thms 1, 2] proved that Wk converges with probability one to [±ϕ1 ±ϕ2 … ±ϕp] as k→∞.
XI Weighted Algorithm
The objective function for the XU weighted adaptive GEVD algorithm is
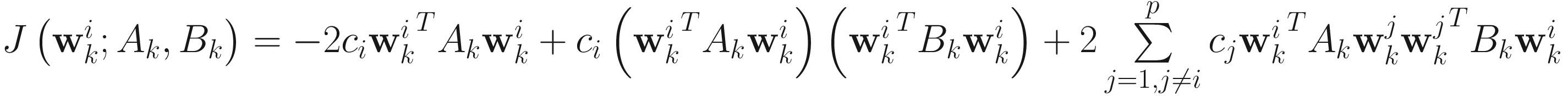 (7.19)
(7.19)
for i=1,…,p (p≤n), where c1,…,cp are small positive numbers satisfying (7.12). The adaptive algorithm is
 , (7.20)
, (7.20)
where C = diag(c1,…,cp).
XU Algorithm Python Code
7.5 PF GEVD Algorithms
PF Homogeneous Algorithm
We obtain the objective function for the PF homogeneous generalized eigenvector algorithm by writing the Rayleigh quotient criterion (7.2) as the following penalty function:
 , (7.21)
, (7.21)
where μ > 0 and i=1,…,p (p≤n). From the gradient of (7.21) with respect to  , we obtain the PF homogeneous adaptive algorithm:
, we obtain the PF homogeneous adaptive algorithm:
 , (7.22)
, (7.22)
where Ip is a pXp identity matrix.
PF Deflation Algorithm
The objective function for the PF deflation GEVD algorithm is
 , (7.23)
, (7.23)
where μ > 0 and i=1,…,p. The adaptive algorithm is
 , (7.24)
, (7.24)
where UT[⋅] sets all elements below the diagonal of its matrix argument to zero.
PF Weighted Algorithm
The objective function for the PF weighted GEVD algorithm is
 , (7.25)
, (7.25)
where c1 > c2 > … > cp > 0 (p ≤ n), μ > 0, and i=1,…,p. The corresponding adaptive algorithm is
 , (7.26)
, (7.26)
where C = diag (c1, …, cp).
PF Algorithm Python Code
7.6 AL1 GEVD Algorithms
AL1 Homogeneous Algorithm
We apply the augmented Lagrangian method of nonlinear optimization to the Rayleigh quotient criterion (7.4) to obtain the objective function for the AL1 homogeneous GEVD algorithm as
 ,
,
 , (7.27)
, (7.27)
for i=1,…,p (p≤n), where (α, β1, β2, …, βp) are Lagrange multipliers and μ is a positive penalty constant. Taking the gradient of 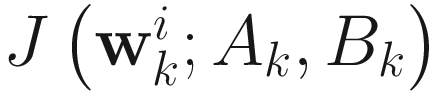 with respect to
with respect to  and equating the gradient to 0 and using the constraint
and equating the gradient to 0 and using the constraint  , we obtain
, we obtain
 and
and 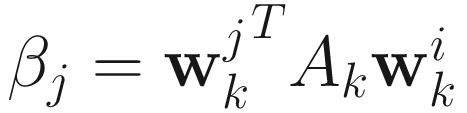 for j=1,…,p. (7.28)
for j=1,…,p. (7.28)
Replacing (α, β1, β2, …, βp) in the gradient of (7.27), we obtain the AL1 homogeneous adaptive gradient descent generalized eigenvector algorithm:
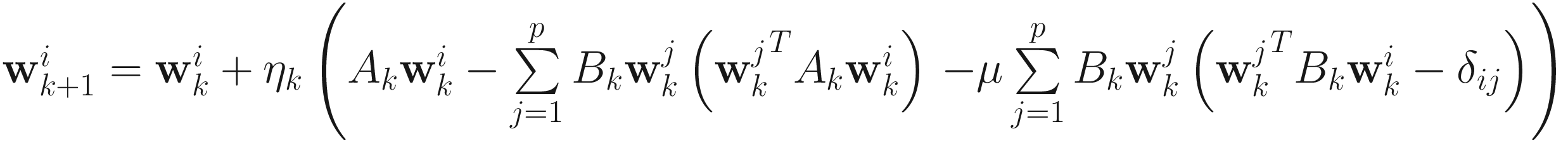 (7.29)
(7.29)
where μ > 0. Defining ![$$ {W}_k=left[{mathbf{w}}_k^1dots {mathbf{w}}_k^p
ight] $$](https://imgdetail.ebookreading.net/2023/10/9781484280171/9781484280171__9781484280171__files__images__522202_1_En_7_Chapter__522202_1_En_7_Chapter_TeX_IEq63.png) , we obtain
, we obtain
 , (7.30)
, (7.30)
where Ip is a pXp identity matrix.
AL1 Deflation Algorithm
The objective function for the AL1 deflation GEVD algorithm is

 , (7.31)
, (7.31)
for i=1,…,p (p≤n). Following the steps in Section 7.6.1 we obtain the adaptive algorithm:
 . (7.32)
. (7.32)
AL1 Weighted Algorithm
The objective function for the AL1 weighted GEVD algorithm is
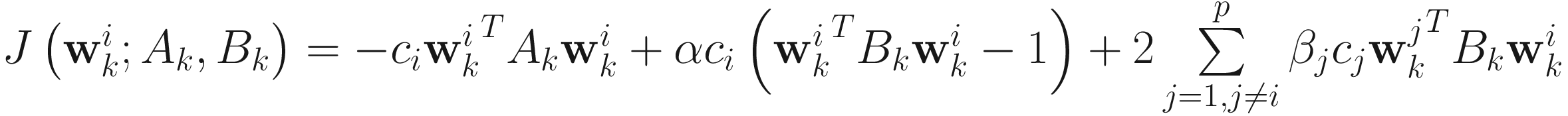 ,
,
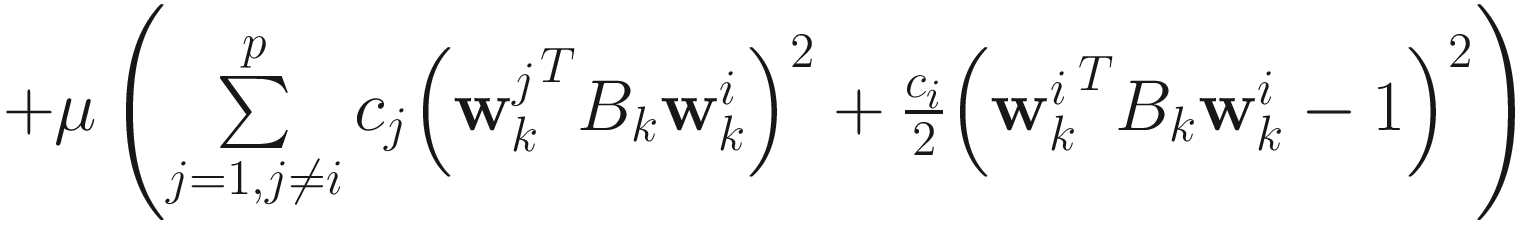 , (7.33)
, (7.33)
for i=1,…,p (p≤n), where (α, β1, β2, …, βp) are Lagrange multipliers, μ is a positive penalty constant, and c1 > c2 > … > cp > 0. The adaptive algorithm is
 , (7.34)
, (7.34)
where C = diag (c1, …, cp).
AL1 Algorithm Python Code
7.7 AL2 GEVD Algorithms
AL2 Homogeneous Algorithm
The unconstrained objective function for the AL2 homogeneous GEVD algorithm is

 , (7.35)
, (7.35)
for i=1,…,p, where μ is a positive penalty constant. From (7.35), we obtain the adaptive gradient descent algorithm:
 , (7.36)
, (7.36)
for i=1,…,p, the matrix version of which is
 . (7.37)
. (7.37)
AL2 Deflation Algorithm
The objective function for the AL2 deflation GEVD algorithm is
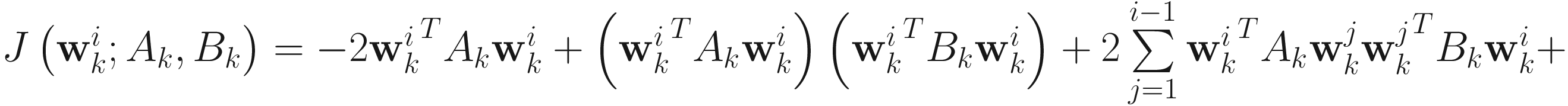
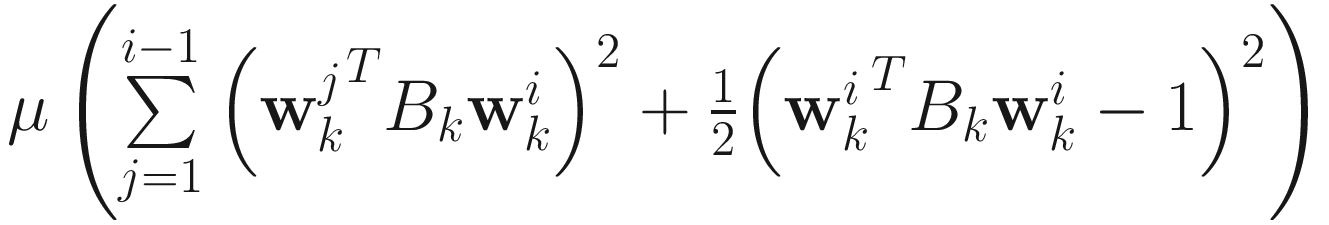 , (7.38)
, (7.38)
for i=1,…,p. The adaptive GEVD algorithm is
 . (7.39)
. (7.39)
AL2 Weighted Algorithm
The objective function for the AL2 weighted generalized eigenvector algorithm is

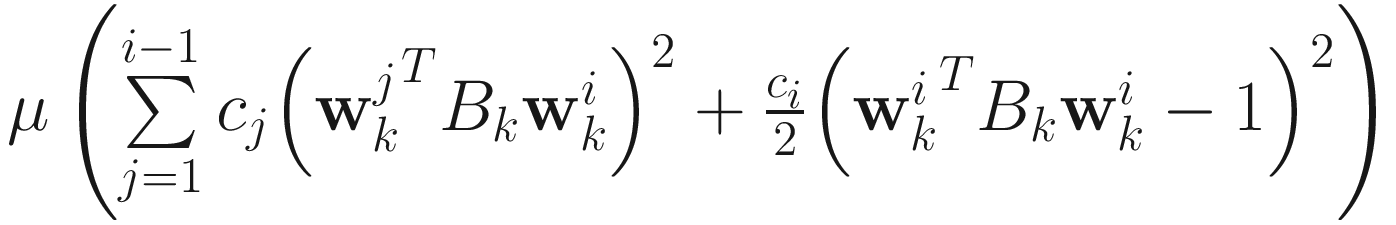 , (7.40)
, (7.40)
for i=1,…,p, where c1 > c2 > … > cp > 0 (p ≤ n). The adaptive algorithm is
 , (7.41)
, (7.41)
where C = diag (c1, …, cp), p ≤ n.
AL2 Algorithm Python Code
7.8 IT GEVD Algorithms
IT Homogeneous Algorithm
The objective function for the information theory homogeneous GEVD algorithm is
 (7.42)
(7.42)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers and ln(.) is logarithm base e. By equating the gradient of (7.42) with respect to 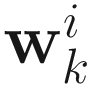 to 0 and using the constraint
to 0 and using the constraint  , we obtain
, we obtain
α = 0 and  , (7.43)
, (7.43)
for j=1,…,p. Replacing (α, β1, β2, …, βp) in the gradient of (7.42), we obtain the IT homogeneous adaptive gradient descent algorithm for the generalized eigenvector:
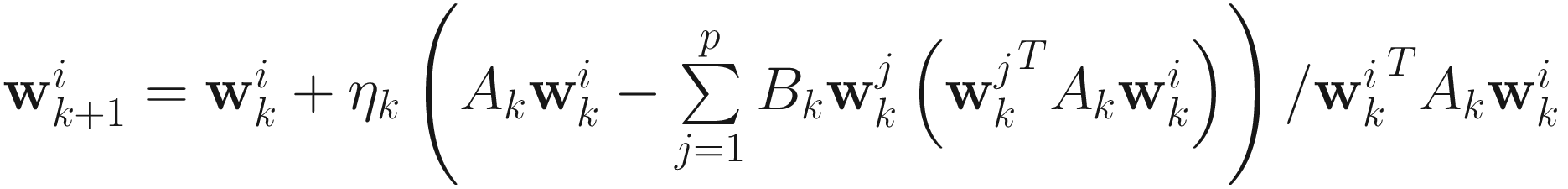 , (7.44)
, (7.44)
for i=1,…,p, whose matrix version is
 , (7.45)
, (7.45)
where DIAG[⋅] sets all elements except the diagonal of its matrix argument to zero.
IT Deflation Algorithm
The objective function for the IT deflation GEVD algorithm is
 (7.46)
(7.46)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers. From (7.43), we obtain the adaptive gradient algorithm:
 (7.47)
(7.47)
IT Weighted Algorithm
The objective function for the IT weighted GEVD algorithm is
 (7.48)
(7.48)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers. By solving (α, β1, β2, …, βk) and replacing them in the gradient of (7.48), we obtain the adaptive algorithm:
 . (7.49)
. (7.49)
IT Algorithm Python Code
7.9 RQ GEVD Algorithms
RQ Homogeneous Algorithm
We obtain the objective function for the Rayleigh quotient homogeneous GEVD algorithm from the Rayleigh quotient criterion (7.2) as follows:
 (7.50)
(7.50)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers. By equating the gradient (7.50) with respect to  to 0, and using the constraint
to 0, and using the constraint 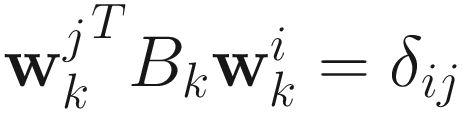 , we obtain
, we obtain
α = 0 and  for j=1,…,p. (7.51)
for j=1,…,p. (7.51)
Replacing (α, β1, β2, …, βp) in the gradient of (7.50) and making a small approximation, we obtain the RQ homogeneous adaptive gradient descent algorithm for the generalized eigenvector:
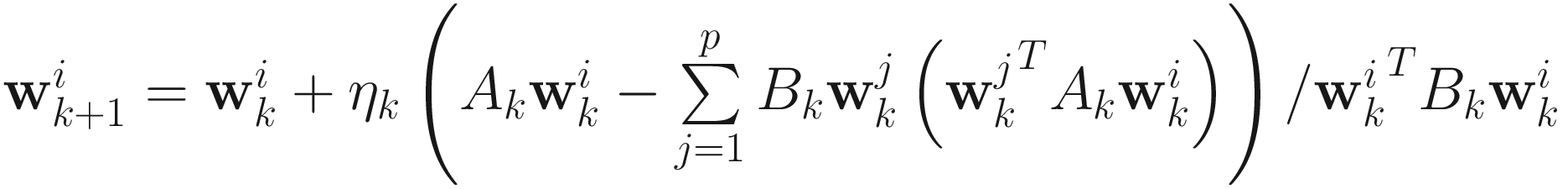 , (7.52)
, (7.52)
for i=1,…,p, whose matrix version is
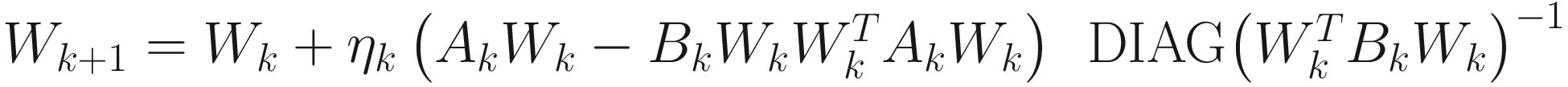 . (7.53)
. (7.53)
RQ Deflation Algorithm
The objective function for the RQ deflation GEVD algorithm is
 , (7.54)
, (7.54)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers. By solving (α, β1, β2, …, βk) and replacing them in the gradient of (7.54), we obtain the adaptive algorithm:
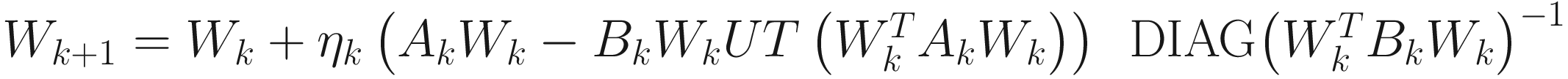 . (7.55)
. (7.55)
RQ Weighted Algorithm
The objective function for the RQ weighted GEVD algorithm is
 , (7.56)
, (7.56)
for i=1,…,p, where (α, β1, β2, …, βp) are Lagrange multipliers. By solving (α, β1, β2, …, βk) and replacing them in the gradient of (7.56), we obtain the adaptive algorithm:
 . (7.57)
. (7.57)
RQ Algorithm Python Code
7.10 Experimental Results
I generated 1,000 samples (of {xk} and {yk}) from 10-dimensional Gaussian data (i.e., n=10) with the mean zero and covariance given below. The covariance matrix A for {xk} is obtained from the second covariance matrix in [Okada and Tomita 85] multiplied by 3 as follows:

The covariance matrix B for {yk} is obtained from the third covariance matrix in [Okada and Tomita 85] multiplied by 2 as follows:

The generalized eigenvalues of (A,B) are
107.9186, 49.0448, 8.3176, 5.1564, 2.8814, 2.3958, 1.9872, 1.2371, 0.9371, 0.1096.
I computed the first four principal generalized eigenvectors (i.e., eigenvectors corresponding to the largest four eigenvalues) (i.e., p=4) by the adaptive algorithms described before. In order to compute the online data sequence {Ak}, I generated random data vectors {xk} from the above covariance matrix A. I generated {Ak} from {xk} by using algorithm (2.21) in Chapter 2. Similarly, I generated random data vectors {yk} from the covariance matrix B and then generated {Bk} from {yk}. I computed the correlation matrix Acomputed and Bcomputed after collecting all 500 samples xk and yk respectively as
 and
and  .
.
I referred to the generalized eigenvectors and eigenvalues computed from this A and B by a standard numerical analysis method [Golub and VanLoan 83] as the actual values .
I started all algorithms with w0 = 0.1*ONE, where ONE is a 10 X 4 matrix whose all elements are ones. In order to measure the convergence and accuracy of the algorithms, I computed the direction cosine at kth update of each adaptive algorithm as
Direction cosine (k) = 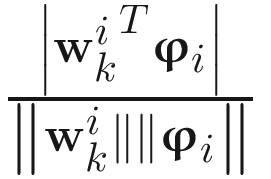 , (7.58)
, (7.58)
where  is the estimated generalized eigenvector of (Ak,Bk) at kth update and ϕi is the actual ith generalized eigenvector computed from all collected samples by a conventional numerical analysis method.
is the estimated generalized eigenvector of (Ak,Bk) at kth update and ϕi is the actual ith generalized eigenvector computed from all collected samples by a conventional numerical analysis method.

Convergence of the first two principal generalized eigenvectors of (A,B) by the OJA deflation (7.10) and OJA weighted (7.13) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the XU deflation (7.18) and XU weighted (7.20) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the PF deflation (7.24) and PF weighted (7.26) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the AL1 deflation (7.32) and AL1 weighted (7.34) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the AL2 deflation (7.39) and AL2 weighted (7.41) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the IT deflation (7.47) and IT weighted (7.49) adaptive algorithms

Convergence of the first two principal generalized eigenvectors of (A,B) by the RQ deflation (7.55) and RQ weighted (7.57) adaptive algorithms
For all algorithms, I used ηk=1/(140+k) for the deflation algorithms and ηk=1/(500+k) for the weighted algorithms. The diagonal weight matrix C used for the weighted algorithms is DIAG(2.6,2.3,2.0,1.7). I ran all algorithms for three epochs of the data, where one epoch means presenting all training data once in random order. I did not show the results for the homogeneous algorithms since the homogeneous method produces a linear combination of the actual generalized eigenvectors of (A,B). Thus, the direction cosines are not indicative of the performance of the algorithms for the homogeneous case.
7.11 Concluding Remarks
Observe that the convergence of all algorithms decreases progressively for the minor generalized eigenvectors and is best for principal generalized eigenvector. This is expected since the convergence of these adaptive algorithms is a function of the relative generalized eigenvalue. Furthermore, the weighted algorithms, which can be implemented in parallel hardware, performed very similarly to the deflation algorithms.
- 1.
For each algorithm, I rated the compute and convergence performance.
- 2.
I skipped the homogeneous algorithms because they are not useful for practical applications since they produce arbitrary rotations of the eigenvectors.
- 3.
Note that Ak∈ℜnXn, Bk∈ℜnXn and Wk∈ℜnXp. I presented the computation complexity of each algorithm in terms of the matrix dimensions n and p.
- 4.
The convergence performance is determined based on the speed of convergence of the principal and the minor components. I rated convergence in a scale of 1-10 where 10 is the fastest converging algorithm.
- 5.
I skipped the IT and RQ algorithms because they did not perform well compared to the remaining algorithms and the matrix inversion increases computational complexity. See Table 7-3.
List of Adaptive GEVD Algorithms, Complexity, and Performance
Alg | Type | Adaptive Algorithm h(Wk,Ak) | Comments |
|---|---|---|---|
OJA | Deflation |
| n3p6, 6 |
Weighted |
| n4p6, 6 | |
XU | Deflation |
| 2n3p6, 8 |
Weighted |
| 2n4p6, 8 | |
PF | Deflation |
| n2p4, 7 |
Weighted |
| n3p4, 7 | |
AL1 | Deflation |
| n3p6+ n2p4, 9 |
Weighted |
| n4p6+ n3p4, 9 | |
AL2 | Deflation |
| 2n3p6+ n2p4, 10 |
Weighted |
| 2n4p6+ n3p4, 10 | |
IT | Deflation |
| Not applicable |
Weighted |
| Not applicable | |
RQ | Deflation |
| Not applicable |
Weighted |
| Not applicable |




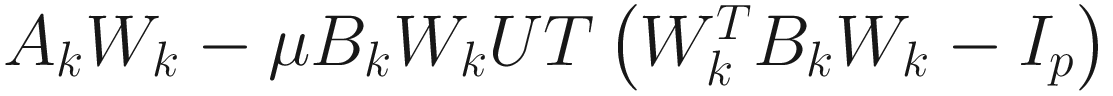


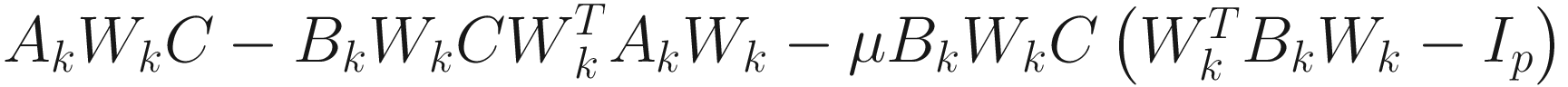

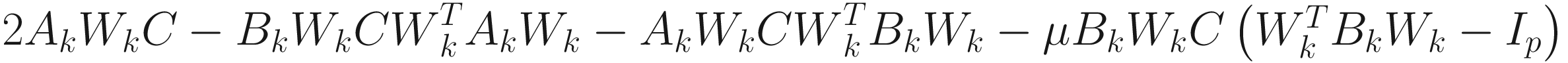




- 1.
The OJA algorithm has the least complexity and good performance.
- 2.
The AL2 algorithm has the most complexity and best performance.
- 3.
The AL1 algorithm is the next best after AL2, and PF and XU follow.
The complexity and accuracy tradeoffs will determine the algorithm to use in real-world scenarios. If you can afford the computation, the AL2 algorithm is the best. The XU algorithm is a good balance of complexity and performance.
In summary, I showed 21 algorithms, many of them new, from a common framework with an objective function for each. Note that although I applied the gradient descent technique on these objective functions, I could have applied any other technique of nonlinear optimization such as steepest descent, conjugate direction, Newton-Raphson, or recursive least squares. The availability of the objective functions allows us to derive new algorithms by using new optimization techniques on them and also to perform convergence analyses of the adaptive algorithms.